
Disclaimer: This post has been translated to English using a machine translation model. Please, let me know if you find any mistakes.
Although as LLMs grow in size and new capabilities emerge, we have a problem: hallucinations. The authors of the paper DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models propose a method to avoid this issue.
They propose a contrastive decoding approach, where the probability of the next word's output is obtained from the difference in logits between an upper layer and a lower layer. By emphasizing the knowledge of the upper layers and de-emphasizing that of the lower layers, we can make LMs more factual and, therefore, reduce hallucinations.
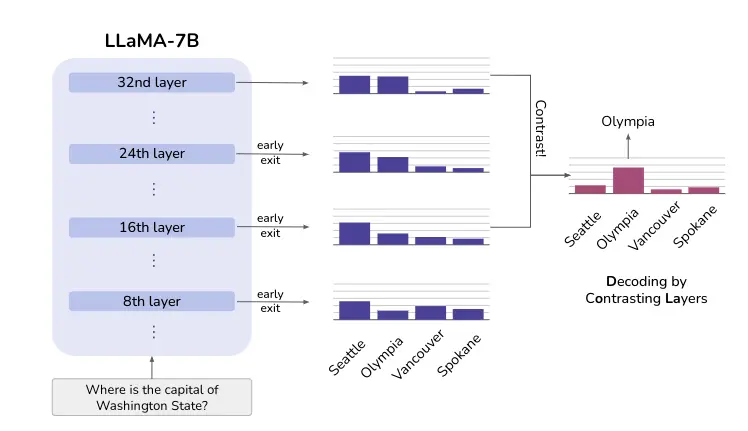
The following figure illustrates this idea. While Seattle maintains a high probability across all layers, the probability of the correct answer Olympia increases after the upper layers inject more factual knowledge. Comparing the differences between the various layers can reveal the correct answer in this case.
Method
A LLM consists of an embedding layer, several sequential transformers, and then an output layer. What they propose is to measure the output of each transformer using the Jensen-Shannon divergence (JSD).
In the following figure, this measure can be seen at the output of each transformer for an input sentence to the LLM. Each column corresponds to a token in the sentence.
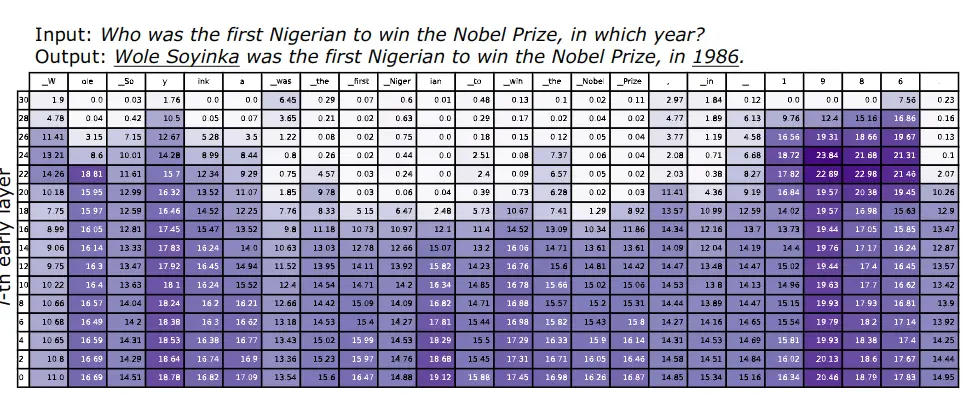
Two patterns can be observed
- The first occurs when predicting named entities or important dates, such as
Wole Soyinkaand1986, which require factual knowledge. It can be seen that the JSD calculated remains extremely high in the upper layers. This pattern indicates that the model is still changing its predictions in the final layers, potentially injecting more factual knowledge into the predictions.
- The second occurs when functional words are predicted, such as
was,the,to,in, and tokens copied from the input question, likefirst Nigerian,Nobel Prize. When these "easy" tokens are predicted, we can observe that the JSD becomes very small from the intermediate layers onwards. This finding indicates that the model has already decided which token to generate by the intermediate layers, and maintains the output distributions almost unchanged in the upper layers. This finding is also consistent with the assumptions of early output LLMsSchuster et al., 2022
When the prediction of the next word requires factual knowledge, the LLM seems to change predictions in the upper layers. Contrasting the layers before and after a sudden change can therefore amplify the knowledge that emerges from the upper layers and make the model rely more on its internal factual knowledge. Additionally, this evolution of information appears to vary from one token to another.
Your method requires accurately selecting the premature layer that contains plausible but less factual information, which may not always be in the same early layer. Therefore, they propose finding this premature layer through dynamic selection of the premature layer as shown in the following image
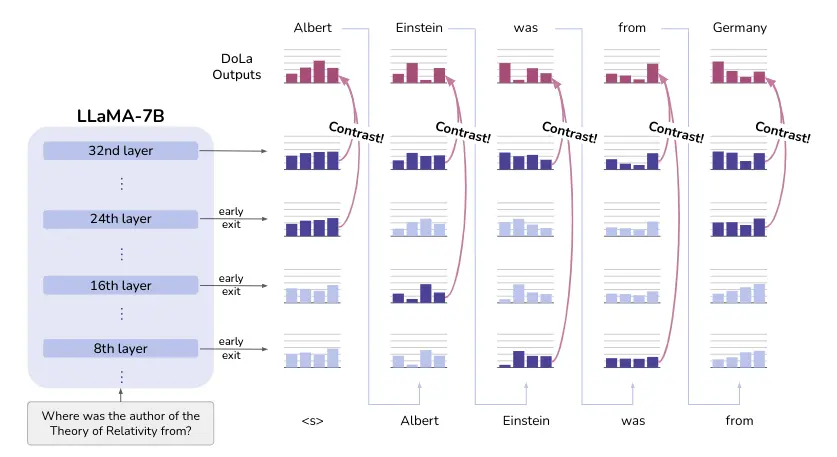
Dynamic Selection of the Premature Layer
To select the premature layer, they calculate the Jensen-Shannon Divergence (JSD) between the intermediate and final layers. The premature layer is selected as the layer with the highest JSD.
However, as this process can be a bit slow, what they do is group several layers to make fewer calculations
Contrast of the predictions
Now that we have the last layer (mature layer) and the premature layer, we can contrast the predictions of both layers. To do this, they calculate the logarithmic probability of the next token in the mature layer and the premature layer. Then they subtract the logarithmic probability of the premature layer from that of the mature layer, thus giving more importance to the knowledge of the mature layer.
Repetition Penalty
The motivation of DoLa is to downplay the linguistic knowledge of the lower layers and amplify the factual knowledge of the real world. However, this can lead to the model generating grammatically incorrect paragraphs.
Empirically, they have not observed that problem, but they have found that the resulting DoLa distribution sometimes has a greater tendency to repeat previously generated phrases, especially during the generation of long reasoning sequences in the chain of thought.
So they include a repetition penalty introduced in Keskar et al. (2019) with θ = 1.2 during decoding
Implementation with transformers
Let's see how to implement DoLa with the transformers library from Hugging Face. For more information on how to apply DoLa with the transformers library, you can consult the following link
First we log in to the Hub, because we are going to use Llama 3 8B, and to be able to use it, we need to request permission from Meta. So, to download it, you need to be logged in so they know who is downloading it.
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
Now we instantiate the tokenizer and the model
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idCopied
We assign a fixed seed value for the reproducibility of the example
InputPythonset_seed(42)Copied
We generate the input tokens for the LLM
InputPythonquestion = 'What does Darth Vader say to Luke in "The Empire Strikes Back"?'text = f"Answer with a short answer. Question: {question} Answer: "inputs = tokenizer(text, return_tensors="pt").to(model.device)Copied
We now generate the vanilla input, that is, without applying DoLa
InputPythongenerate_kwargs={"do_sample": False,"max_new_tokens": 50,"top_p": None,"temperature": None}vanilla_output = model.generate(**inputs, **generate_kwargs)print(tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
"No, I am your father." (Note: This is a famous misquote. The actual quote is "No, I am your father" is not in the movie. The correct quote is "No, I am your father." is not
We see that he knows there is a famous mistake, but he can't manage to say the correct phrase.
Now applying DoLa
InputPythondola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers='high', repetition_penalty=1.2)print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
"No, I am your father." (Note: This is one of the most famous lines in movie history, and it's often misquoted as "Luke, I am your father.")
Now he manages to get the sentence right and the famous error
Let's do another test with another example, I reset the notebook and use another model.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "huggyllama/llama-7b"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idCopied
We assign a fixed seed value for the reproducibility of the example
InputPythonset_seed(42)Copied
Sure, please provide the new Markdown text you would like translated to English.
InputPythontext = "On what date was the Declaration of Independence officially signed?"inputs = tokenizer(text, return_tensors="pt").to(device)Copied
We generate the vanilla output
InputPythongenerate_kwargs={"do_sample": False,"max_new_tokens": 50,"top_p": None,"temperature": None}vanilla_output = model.generate(**inputs, **generate_kwargs)print(tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])Copied
The Declaration of Independence was signed on July 4, 1776.What was the date of the signing of the Declaration of Independence?The Declaration of Independence was signed on July 4,
As we can see, it generates the wrong output, since although it is celebrated on July 4th, it was actually signed on August 2nd
Let's try it now with DoLa
InputPythondola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers='high', repetition_penalty=1.2)print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])Copied
July 4, 1776. This is the most well-known date in U.S. history. The day has been celebrated with parades, barbeques, fireworks and festivals for hundreds of years.
It's still not generating the correct output, so we're going to instruct it to only contrast the final layer with layers 28 and 30
InputPythondola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers=[28,30], repetition_penalty=1.2)print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])Copied
It was officially signed on 2 August 1776, when 56 members of the Second Continental Congress put their John Hancocks to the Declaration. The 2-page document had been written in 17
Now it manages to generate the correct response.















