
Disclaimer: This post has been translated to English using a machine translation model. Please, let me know if you find any mistakes.
In the paper GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers the need to create a post-training quantization method that does not degrade model quality is discussed. In this post, we have seen the llm.int8() method, which quantizes some vectors of the weight matrices to INT8, provided that none of their values exceed a threshold value, which is very good, but it does not quantize all the model weights. In this paper, they propose a method that quantizes all the model weights to 4 and 3 bits without degrading model quality. This results in significant memory savings, not only because all weights are quantized, but also because they are quantized to 4, 3 bits (and even to 1 and 2 bits under certain conditions), instead of 8 bits.
Works it is based on
Layer Quantization
On the one hand, they are based on the works of Nagel et al., 2020; Wang et al., 2020; Hubara et al., 2021 and Frantar et al., 2022, which propose quantizing the weights of neural network layers to 4 and 3 bits without degrading model quality.
Given a dataset m, for each layer l, the data is fed into it and the output of the weights W of that layer is obtained. So, what is done is to find new quantized weights Ŵ that minimize the mean squared error with respect to the output of the full precision layer.
argmin_Ŵ||WX− ŴX||^2
The values of Ŵ are set before performing the quantization process and during the process, each parameter of Ŵ can change value independently without depending on the value of the other parameters of Ŵ.
Optimal brain quantization (OBQ)
In the OBQ work of Frantar et al., 2022, they optimize the previous layer-wise quantization process, making it up to 3 times faster. This helps with large models, as quantizing a large model can take a significant amount of time.
The OBQ method is an approach to solving the problem of layered quantization in language models. OBQ starts from the idea that the squared error can be decomposed into the sum of individual errors for each row of the weight matrix. Then, the method quantizes each weight independently, always updating the non-quantized weights to compensate for the error incurred by the quantization.
The method is capable of quantifying medium-sized models in reasonable times, but since it is a cubic complexity algorithm, it makes it extremely costly to apply it to models with billions of parameters.
GPTQ Algorithm
Step 1: Arbitrary Order Information
In OBQ the goal was to find the row of weights that created the smallest mean squared error for quantization, but they realized that doing it randomly did not significantly increase the final mean squared error. Therefore, instead of searching for the row that minimizes the mean squared error, which created a cubic complexity in the algorithm, it is always done in the same order. Thanks to this, the execution time of the quantization algorithm is greatly reduced.
Step 2: Lazy Batch Updates
When updating the row weights one by one, this causes the process to be slow and not fully utilize the hardware.
Step 3: Cholesky Refactorization
The problem with performing batch updates is that, due to the large scale of the models, numerical errors can occur that affect the accuracy of the algorithm. Specifically, indefinite matrices can be obtained, which causes the algorithm to update the remaining weights in incorrect directions, resulting in very poor quantization.
To solve this, the authors of the paper propose using a Cholesky reformulation, which is a more numerically stable method.
GPTQ Results
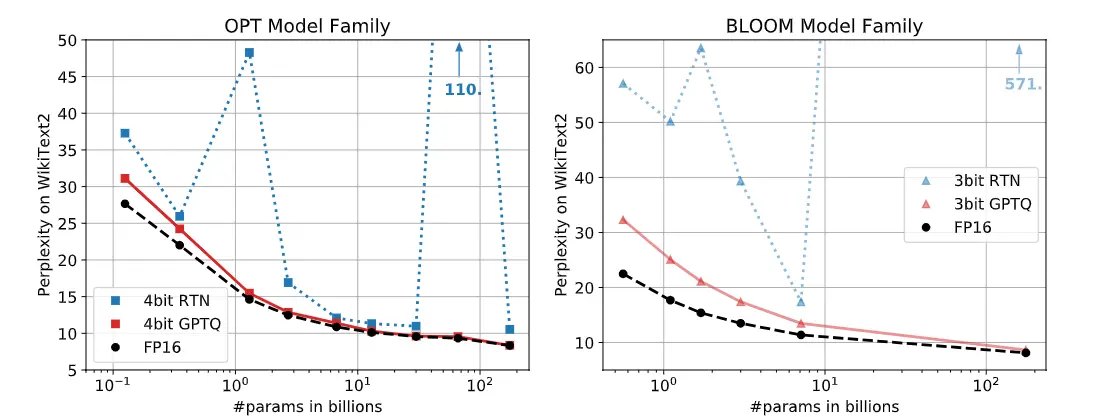
The following are two graphs showing the perplexity measure on the WikiText2 dataset for all sizes of the OPT and BLOOM models. It can be seen that with the RTN quantization technique, perplexity increases significantly in some sizes, while with GPTQ it remains similar to what is obtained with the FP16 model.
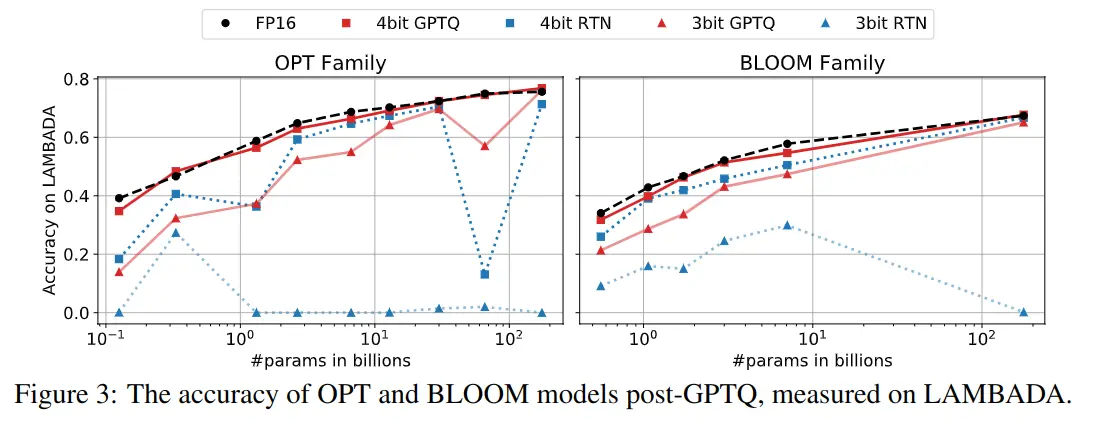
The following are other graphs, but with the accuracy measure on the LAMBADA dataset. The same occurs, while GPTQ remains similar to what was obtained with FP16, other quantization methods degrade the model quality significantly.
Extreme Quantization
In the previous graphs, the results of quantizing the model to 3 and 4 bits have been shown, but we can quantize them to 2 bits, and even to just 1 bit.
By modifying the batch size when using the algorithm, we can achieve good results quantizing the model.
| Model | FP16 | g128 | g64 | g32 | 3 bits |
|---|---|---|---|---|---|
| OPT-175B | 8.34 | 9.58 | 9.18 | 8.94 | 8.68 |
| BLOOM | 8.11 | 9.55 | 9.17 | 8.83 | 8.64 |
In the table above, you can see the perplexity results on the WikiText2 dataset for the OPT-175B and BLOOM models quantized to 3 bits. It can be observed that as smaller batches are used, the perplexity decreases, which means that the quality of the quantized model is better. However, this comes with the drawback that the algorithm takes longer to run.
Dynamic Dequantization in Inference
During inference, something called dynamic dequantization is performed to enable the inference process. Each layer is dequantized as it is passed through.
To achieve this, they developed a kernel that dequantizes the matrices and performs the matrix multiplications. Although dequantization consumes more computations, the kernel has to access much less memory, which results in significant accelerations.
Inference is performed in FP16 by dequantizing the weights as they pass through the layers, and the activation function of each layer is also performed in FP16. Although this requires more calculations due to dequantization, these calculations make the overall process faster because less data needs to be fetched from memory. The weights are brought from memory in fewer bits, which ultimately saves a lot of data in matrices with many parameters. The bottleneck is usually in fetching data from memory, so even though more calculations are required, the inference ends up being faster.
Inference speed
The authors of the paper performed a test quantizing the BLOOM-175B model to 3 bits, which occupied around 63 GB of VRAM, including the embeddings and the output layer that are kept in FP16. Additionally, maintaining a context window of 2048 tokens consumes about 9 GB of memory, bringing the total to approximately 72 GB of VRAM. They quantized to 3 bits instead of 4 to be able to perform this experiment and fit the model into a single Nvidia A100 GPU with 80 GB of VRAM.
For comparison, normal inference in FP16 requires around 350 GB of VRAM, which is equivalent to 5 Nvidia A100 GPUs with 80 GB of VRAM each. And inference quantizing to 8 bits using llm.int8() requires 3 of those GPUs.
The following table shows the model inference in FP16 and quantized to 3 bits on Nvidia A100 GPUs with 80 GB of VRAM and Nvidia A6000 GPUs with 48 GB of VRAM.
| GPU (VRAM) | average time per token in FP16 (ms) | average time per token in 3-bit (ms) | Acceleration | Reduction in required GPUs |
|---|---|---|---|---|
| A6000 (48GB) | 589 | 130 | ×4.53 | 8→ 2 |
| A100 (80GB) | 230 | 71 | ×3.24 | 5→ 1 |
For example, using the kernels, the 3-bit OPT-175B model runs on a single A100 (instead of 5) and is approximately 3.25 times faster than the FP16 version in terms of average time per token.
The NVIDIA A6000 GPU has much lower memory bandwidth, so this strategy is even more effective: running the 3-bit OPT-175B model on 2 A6000 GPUs (instead of 8) is approximately 4.53 times faster than the FP16 version.
Libraries
The authors of the paper implemented the library GPTQ. Other libraries were created such as GPTQ-for-LLaMa, exllama and llama.cpp. However, these libraries focus only on the llama architecture, which is why the library AutoGPTQ gained more popularity due to its broader coverage of architectures.
Therefore, the library AutoGPTQ was integrated through an API within the transformers library. To use it, you need to install it as indicated in the Installation section of its repository and have the optimun library installed.
In addition to following the instructions in the Installation section of their repository, it is also advisable to do the following:
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip install .To install the quantization kernels on the GPU developed by the authors of the paper.
Quantization of a Model
Let's see how to quantize a model with the optimun library and the AutoGPTQ API.
Inference of the Non-Quantized Model
Let's quantize the model meta-llama/Meta-Llama-3-8B-Instruct, which, as its name suggests, is an 8B parameter model, so in FP16 we would need 16 GB of VRAM. First, we run the model to see how much memory it occupies and the output it generates.
Since we need to ask for permission from Meta to use this model, we log in to Hugging Face to download the tokenizer and the model
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
We instantiate the tokenizer and the model
InputPythonfrom transformers import AutoModelForCausalLM, AutoTokenizerimport torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")checkpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForCausalLM.from_pretrained(checkpoint).half().to(device)Copied
Let's check the memory it occupies in FP16
InputPythonmodel_memory = model.get_memory_footprint()/(1024**3)print(f"Model memory: {model_memory:.2f} GB")Copied
Model memory: 14.96 GB
We see that it takes up almost 15 GB, roughly the 16 GB we said it should take up, but why this difference? This model probably doesn't have exactly 8B parameters, but rather a bit less, and when indicating the number of parameters, it is rounded to 8B.
We make an inference to see how it performs and the time it takes
InputPythonimport timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model.device)t0 = time.time()max_new_tokens = 50outputs = model.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer at a startup in the Bay Area. I am passionate about building AI systems that can help humans make better decisions and improve their lives.I have a background in computer science and mathematics, and I have been working with machine learning for several years. IInference time: 4.14 s
Quantization of the Model to 4 Bits
Let's quantize it to 4 bits. I'm going to reset the notebook to avoid memory issues, so we need to log in to Hugging Face again.
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
First I create the tokenizer
InputPythonfrom transformers import AutoTokenizercheckpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Now we create the quantization configuration. As we have said, this algorithm calculates the error of the quantized weights over the original ones based on inputs from a dataset, so in the configuration we have to pass it which dataset we want to use to quantize the model.
The defaults available are wikitext2, c4, c4-new, ptb and ptb-new.
We can also create a dataset from a list of strings ourselves
dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly APIs, based on the GPTQ algorithm."]In addition, we have to specify the number of bits for the quantized model using the bits parameter.
InputPythonfrom transformers import GPTQConfigquantization_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)Copied
We quantize the model
InputPythonfrom transformers import AutoModelForCausalLMimport timet0 = time.time()model_4bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", quantization_config=quantization_config)t_quantization = time.time() - t0print(f"Quantization time: {t_quantization:.2f} s = {t_quantization/60:.2f} min")Copied
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<?, ?it/s]
Quantizing model.layers blocks : 100%|██████████|32/32 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:4565: FutureWarning: `_is_quantized_training_enabled` is going to be deprecated in transformers 4.39.0. Please use `model.hf_quantizer.is_trainable` insteadwarnings.warn(
Quantization time: 1932.09 s = 32.20 min
As the quantization process calculates the smallest error between the quantized weights and the original ones by passing inputs through each layer, the quantization process takes time. In this case, it took about half an hour.
Let's check the memory it occupies now
InputPythonmodel_4bits_memory = model_4bits.get_memory_footprint()/(1024**3)print(f"Model memory: {model_4bits_memory:.2f} GB")Copied
Model memory: 5.34 GB
Here we can see a benefit of quantization. While the original model took up around 15 GB of VRAM, the quantized model now takes up around 5 GB, almost a third of the original size.
We make the inference and see how long it takes
InputPythonimport timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model_4bits.device)t0 = time.time()max_new_tokens = 50outputs = model_4bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer. I have a strong background in computer science and mathematics, and I am passionate about developing innovative solutions that can positively impact society. I am excited to be a part of this community and to learn from and contribute to the discussions here. I am particularlyInference time: 2.34 s
The unquantized model took 4.14 seconds, while the 4-bit quantized model took 2.34 seconds and also generated the text well. We have managed to reduce inference time by almost half.
Since the size of the quantized model is almost one third of the FP16 model, we might think that inference speed should be about three times faster with the quantized model. However, it's important to remember that in each layer, the weights are dequantized and calculations are performed in FP16, which is why we have only managed to reduce inference time by half, not to a third.
Now we save the model
InputPythonsave_folder = "./model_4bits/"model_4bits.save_pretrained(save_folder)tokenizer.save_pretrained(save_folder)Copied
('./model_4bits/tokenizer_config.json','./model_4bits/special_tokens_map.json','./model_4bits/tokenizer.json')
And we upload it to the hub
InputPythonrepo_id = "Llama-3-8B-Instruct-GPTQ-4bits"commit_message = f"AutoGPTQ model for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"model_4bits.push_to_hub(repo_id, commit_message=commit_message)Copied
README.md: 100%|██████████| 5.17/5.17k [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-4bits/commit/44cfdcad78db260122943d3f57858c1b840bda17', commit_message='AutoGPTQ model for meta-llama/Meta-Llama-3-8B-Instruct: 4bits, gr128, desc_act=False', commit_description='', oid='44cfdcad78db260122943d3f57858c1b840bda17', pr_url=None, pr_revision=None, pr_num=None)
We also upload the tokenizer. Although we haven't changed the tokenizer, we upload it because if someone downloads our model from the hub, they might not know which tokenizer we used, so they will likely want to download the model and the tokenizer together. We can indicate in the model card which tokenizer we used for them to download it, but it's most likely that they won't read the model card, try to download the tokenizer, get an error, and not know what to do. So we upload it to save us that trouble.
InputPythonrepo_id = "Llama-3-8B-Instruct-GPTQ-4bits"commit_message = f"Tokenizers for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"tokenizer.push_to_hub(repo_id, commit_message=commit_message)Copied
README.md: 100%|██████████| 0.00/5.17k [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-4bits/commit/75600041ca6e38b5f1fb912ad1803b66656faae4', commit_message='Tokenizers for meta-llama/Meta-Llama-3-8B-Instruct: 4bits, gr128, desc_act=False', commit_description='', oid='75600041ca6e38b5f1fb912ad1803b66656faae4', pr_url=None, pr_revision=None, pr_num=None)
Quantization of the Model to 3 Bits
Let's quantize it to 3 bits. I'll restart the notebook to avoid memory issues and log back into Hugging Face.
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
First I create the tokenizer
InputPythonfrom transformers import AutoTokenizercheckpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
We create the quantization configuration, now we indicate that we want to quantize to 3 bits
InputPythonfrom transformers import GPTQConfigquantization_config = GPTQConfig(bits=3, dataset = "c4", tokenizer=tokenizer)Copied
We quantize the model
InputPythonfrom transformers import AutoModelForCausalLMimport timet0 = time.time()model_3bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", quantization_config=quantization_config)t_quantization = time.time() - t0print(f"Quantization time: {t_quantization:.2f} s = {t_quantization/60:.2f} min")Copied
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<?, ?it/s]
Quantizing model.layers blocks : 100%|██████████|32/32 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:4565: FutureWarning: `_is_quantized_training_enabled` is going to be deprecated in transformers 4.39.0. Please use `model.hf_quantizer.is_trainable` insteadwarnings.warn(
Quantization time: 1912.69 s = 31.88 min
Just like before, it took an average of half an hour
Let's check the memory it occupies now
InputPythonmodel_3bits_memory = model_3bits.get_memory_footprint()/(1024**3)print(f"Model memory: {model_3bits_memory:.2f} GB")Copied
Model memory: 4.52 GB
The memory occupied by the model in 3 bits is also almost 5 GB. The model in 4 bits took up 5.34 GB, while now in 3 bits it takes up 4.52 GB, so we have managed to reduce the size of the model a bit more.
We make the inference and see how long it takes
InputPythonimport timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model_3bits.device)t0 = time.time()max_new_tokens = 50outputs = model_3bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer at Google. I am excited to be here today to talk about my work in the field of Machine Learning and to share some of the insights I have gained through my experiences.I am a Machine Learning Engineer at Google, and I am excited to beInference time: 2.89 s
Although the 3-bit output is good, now the inference time has been 2.89 seconds, while in 4 bits it was 2.34 seconds. More tests should be done to see if it always takes less time in 4 bits, or perhaps the difference is so small that sometimes the inference in 3 bits is faster and other times the inference in 4 bits is faster.
Moreover, although the output makes sense, it starts to become repetitive.
We save the model
InputPythonsave_folder = "./model_3bits/"model_3bits.save_pretrained(save_folder)tokenizer.save_pretrained(save_folder)Copied
('./model_3bits/tokenizer_config.json','./model_3bits/special_tokens_map.json','./model_3bits/tokenizer.json')
And we upload it to the Hub
InputPythonrepo_id = "Llama-3-8B-Instruct-GPTQ-3bits"commit_message = f"AutoGPTQ model for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"model_3bits.push_to_hub(repo_id, commit_message=commit_message)Copied
model.safetensors: 100%|██████████| 4.85/4.85G [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-3bits/commit/422fd94a031234c10224ddbe09c0e029a5e9c01f', commit_message='AutoGPTQ model for meta-llama/Meta-Llama-3-8B-Instruct: 3bits, gr128, desc_act=False', commit_description='', oid='422fd94a031234c10224ddbe09c0e029a5e9c01f', pr_url=None, pr_revision=None, pr_num=None)
We also upload the tokenizer
InputPythonrepo_id = "Llama-3-8B-Instruct-GPTQ-3bits"commit_message = f"Tokenizers for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"tokenizer.push_to_hub(repo_id, commit_message=commit_message)Copied
README.md: 100%|██████████| 0.00/5.17k [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-4bits/commit/75600041ca6e38b5f1fb912ad1803b66656faae4', commit_message='Tokenizers for meta-llama/Meta-Llama-3-8B-Instruct: 4bits, gr128, desc_act=False', commit_description='', oid='75600041ca6e38b5f1fb912ad1803b66656faae4', pr_url=None, pr_revision=None, pr_num=None)
Quantization of the Model to 2 Bits
Let's quantize it to 2 bits. I'll restart the notebook to avoid memory issues and log back into Hugging Face.
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
First I create the tokenizer
InputPythonfrom transformers import AutoTokenizercheckpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
We create the quantization configuration. Now we tell it to quantize to 2 bits. Additionally, we need to specify how many vectors of the weight matrix are quantized at once using the group_size parameter, which by default had a value of 128 and we didn't touch it before, but now when quantizing to 2 bits, to have less error, we set a smaller value. If we leave it at 128, the quantized model would perform very poorly; in this case, I will set a value of 16.
InputPythonfrom transformers import GPTQConfigquantization_config = GPTQConfig(bits=2, dataset = "c4", tokenizer=tokenizer, group_size=16)Copied
InputPythonfrom transformers import AutoModelForCausalLMimport timet0 = time.time()model_2bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", quantization_config=quantization_config)t_quantization = time.time() - t0print(f"Quantization time: {t_quantization:.2f} s = {t_quantization/60:.2f} min")Copied
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<?, ?it/s]
Quantizing model.layers blocks : 100%|██████████|32/32 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:4565: FutureWarning: `_is_quantized_training_enabled` is going to be deprecated in transformers 4.39.0. Please use `model.hf_quantizer.is_trainable` insteadwarnings.warn(
Quantization time: 1973.12 s = 32.89 min
We see that it also took an average of half an hour
Let's check the memory it occupies now
InputPythonmodel_2bits_memory = model_2bits.get_memory_footprint()/(1024**3)print(f"Model memory: {model_2bits_memory:.2f} GB")Copied
Model memory: 4.50 GB
While quantized to 4 bits it took up 5.34 GB and at 3 bits it took up 4.52 GB, now quantized to 2 bits it takes up 4.50 GB, so we have managed to reduce the model size a bit further.
We make the inference and see how long it takes
InputPythonimport timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model_2bits.device)t0 = time.time()max_new_tokens = 50outputs = model_2bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer. # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #Inference time: 2.92 s
We see that the output is not good anymore, and the inference time is 2.92 seconds, roughly the same as with 3 and 4 bits.
We save the model
InputPythonsave_folder = "./model_2bits/"model_2bits.save_pretrained(save_folder)tokenizer.save_pretrained(save_folder)Copied
('./model_2bits/tokenizer_config.json','./model_2bits/special_tokens_map.json','./model_2bits/tokenizer.json')
We push it to the hub
InputPythonrepo_id = "Llama-3-8B-Instruct-GPTQ-2bits"commit_message = f"AutoGPTQ model for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"model_2bits.push_to_hub(repo_id, commit_message=commit_message)Copied
model.safetensors: 100%|██████████| 4.83/4.83G [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-2bits/commit/13ede006ce0dbbd8aca54212e960eff98ea5ec63', commit_message='AutoGPTQ model for meta-llama/Meta-Llama-3-8B-Instruct: 2bits, gr16, desc_act=False', commit_description='', oid='13ede006ce0dbbd8aca54212e960eff98ea5ec63', pr_url=None, pr_revision=None, pr_num=None)
Quantization of the model to 1 bit
Let's quantize it to 1 bit. I'll reset the notebook to avoid memory issues and log back into Hugging Face.
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
First I create the tokenizer
InputPythonfrom transformers import AutoTokenizercheckpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
We create the quantization configuration, now we tell it to quantize to just 1 bit and also to use a group_size of 8
InputPythonfrom transformers import GPTQConfigquantization_config = GPTQConfig(bits=2, dataset = "c4", tokenizer=tokenizer, group_size=8)Copied
InputPythonfrom transformers import AutoModelForCausalLMimport timet0 = time.time()model_1bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", quantization_config=quantization_config)t_quantization = time.time() - t0print(f"Quantization time: {t_quantization:.2f} s = {t_quantization/60:.2f} min")Copied
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<?, ?it/s]
Quantizing model.layers blocks : 100%|██████████|32/32 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:4565: FutureWarning: `_is_quantized_training_enabled` is going to be deprecated in transformers 4.39.0. Please use `model.hf_quantizer.is_trainable` insteadwarnings.warn(
Quantization time: 2030.38 s = 33.84 min
We see that it also takes about half an hour to quantize
Let's check the memory it occupies now
InputPythonmodel_1bits_memory = model_1bits.get_memory_footprint()/(1024**3)print(f"Model memory: {model_1bits_memory:.2f} GB")Copied
Model memory: 5.42 GB
We see that in this case it even takes up more space than quantized to 2 bits, 4.52 GB.
We make the inference and see how long it takes
InputPythonimport timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model_1bits.device)t0 = time.time()max_new_tokens = 50outputs = model_1bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineerimerszuimersimerspinsimersimersingoingoimersurosimersimersimersoleningoimersingopinsimersbirpinsimersimersimersorgeingoimersiringimersimersimersimersimersimersimersンディorge_REFERER ingest羊imersorgeimersimersendetingoШАhandsingoInference time: 3.12 s
We see that the output is very poor and it also takes longer than when we quantized to 2 bits.
We save the model
InputPythonsave_folder = "./model_1bits/"model_1bits.save_pretrained(save_folder)tokenizer.save_pretrained(save_folder)Copied
('./model_1bits/tokenizer_config.json','./model_1bits/special_tokens_map.json','./model_1bits/tokenizer.json')
We push it to the hub
InputPythonrepo_id = "Llama-3-8B-Instruct-GPTQ-1bits"commit_message = f"AutoGPTQ model for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"model_1bits.push_to_hub(repo_id, commit_message=commit_message)Copied
README.md: 100%|██████████| 0.00/5.17k [00:00<?, ?B/s]
Upload 2 LFS files: 100%|██████████| 0/2 [00:00<?, ?it/s]
model-00002-of-00002.safetensors: 100%|██████████| 0.00/1.05G [00:00<?, ?B/s]
model-00001-of-00002.safetensors: 100%|██████████| 0.00/4.76G [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-2bits/commit/e59ccffc03247e7dcc418f98b482cc02dc7a168d', commit_message='AutoGPTQ model for meta-llama/Meta-Llama-3-8B-Instruct: 2bits, gr8, desc_act=False', commit_description='', oid='e59ccffc03247e7dcc418f98b482cc02dc7a168d', pr_url=None, pr_revision=None, pr_num=None)
Summary of Quantization
Let's compare quantization to 4, 3, 2 and 1 bits
| Bits | Quantization Time (min) | Memory (GB) | Inference Time (s) | Output Quality |
|---|---|---|---|---|
| FP16 | 0 | 14.96 | 4.14 | Good |
| 4 | 32.20 | 5.34 | 2.34 | Good |
| 3 | 31.88 | 4.52 | 2.89 | Good |
| 2 | 32.89 | 4.50 | 2.92 | Poor |
| 1 | 33.84 | 5.42 | 3.12 | Poor |
Looking at this table, we see that it doesn't make sense to quantize to fewer than 4 bits in this example.
Quantizing to 1 and 2 bits clearly makes no sense because the output quality is poor.
But although the output when quantizing to 3 bits is good, it starts to become repetitive, so in the long term, it probably wouldn't be a good idea to use that model. Additionally, neither the quantization time savings, the VRAM savings, nor the inference time savings are significant compared to quantizing to 4 bits.
Loading the saved model
Now that we have compared the quantization of models, let's see how to load the 4-bit model that we saved, as we have seen, it is the best option.
First we load the tokenizer that we have used
InputPythonfrom transformers import AutoTokenizerpath = "./model_4bits"tokenizer = AutoTokenizer.from_pretrained(path)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Now we load the model that we have saved
InputPythonfrom transformers import AutoModelForCausalLMload_model_4bits = AutoModelForCausalLM.from_pretrained(path, device_map="auto")Copied
Loading checkpoint shards: 100%|██████████| 2/2 [00:00<?, ?it/s]
We see the memory it occupies
InputPythonload_model_4bits_memory = load_model_4bits.get_memory_footprint()/(1024**3)print(f"Model memory: {load_model_4bits_memory:.2f} GB")Copied
Model memory: 5.34 GB
We see that it occupies the same memory as when we quantized it, which is logical.
We make the inference and see how long it takes
InputPythonimport timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(load_model_4bits.device)t0 = time.time()max_new_tokens = 50outputs = load_model_4bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer. I have a strong background in computer science and mathematics, and I have been working with machine learning models for several years. I am excited to be a part of this community and to share my knowledge and experience with others. I am particularly interested inInference time: 3.82 s
We see that the inference is good and it took 3.82 seconds, a bit longer than when we quantized it. But as I said before, this test should be run many times and an average should be taken.
Loading the model uploaded to the hub
Now we see how to load the 4-bit model that we have uploaded to the Hub
First we load the tokenizer that we have uploaded
InputPythonfrom transformers import AutoTokenizercheckpoint = "Maximofn/Llama-3-8B-Instruct-GPTQ-4bits"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Now we load the model that we have saved
InputPythonfrom transformers import AutoModelForCausalLMload_model_4bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto")Copied
We see the memory it occupies
InputPythonload_model_4bits_memory = load_model_4bits.get_memory_footprint()/(1024**3)print(f"Model memory: {load_model_4bits_memory:.2f} GB")Copied
Model memory: 5.34 GB
It also occupies the same memory
We make the inference and see how long it takes
InputPythonimport timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(load_model_4bits.device)t0 = time.time()max_new_tokens = 50outputs = load_model_4bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer with a passion for building innovative AI solutions. I have been working in the field of AI for over 5 years, and have gained extensive experience in developing and implementing machine learning models for various industries.In my free time, I enjoy reading books onInference time: 3.81 s
We see that the inference is also good and it took 3.81 seconds.

















