
El aumento de tamaño de los modelos de lenguaje hace que sean cada vez más caros entrenarlos debido a que cada vez hace falta más VRAM para almacenar todos sus parámetros y los gradientes derivados del entrenamiento
En el paper LoRA - Low rank adaption of large language models proponen congelar los pesos del modelo y entrenar dos matrices llamadas A y B reduciendo mucho el número de parámetros que se tienen que entrenar
Vamos a ver cómo se hace esto
Explicación de LoRA
Actualización de pesos en una red neuronal
Para entender cómo funciona LoRA, primero tenemos que recordar qué ocurre cuando entrenamos un modelo. Volvamos a la parte más básica del deep learning, tenemos una capa densa de una red neuronal que se define como:
y = Wx + b
Dónde W es la matriz de pesos y b es el vector de sesgos.
Para simplificar vamos a suponer que no hay sesgo, por lo que quedaría así
y = Wx
Supongamos que para una entrada x queremos que tenga una salida ŷ
- Primero, lo que hacemos es calcular la salida que obtenemos con nuestro valor actual de pesos W, es decir, obtenemos el valor y
- A continuación calculamos el error que existe entre el valor de y que hemos obtenido y el valor que queríamos obtener ŷ. A ese error lo llamamos loss, y lo calculamos con alguna función matemática, ahora no importa cuál
- Calculamos el gradiente (la derivada) del error loss con respecto a la matriz de pesos W, es decir \Delta W = \frac{dloss}{dW}
- Actualizamos los pesos W restando a cada uno de sus valores el valor del gradiente multiplicado por un factor de aprendizaje \alpha, es decir W = W - \alpha \Delta W
LoRA
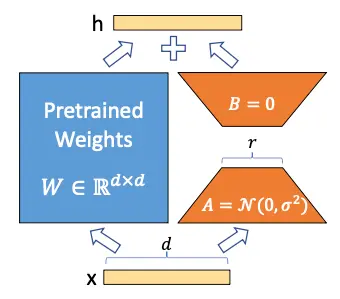
Los autores de LoRA proponen que la matriz de pesos W se puede descomponer en
W \sim W + \Delta W
De manera que congelando la matriz W y entrenando solo la matriz \Delta W se puede obtener un modelo que se adapte a nuevos datos sin tener que reentrenar todo el modelo
Pero podrás pensar que \Delta W es una matriz de tamaño igual a W por lo que no se ha ganado nada, pero aquí los autores se basan en Aghajanyan et al. (2020), un paper en el que demostraron que aunque los modelos de lenguaje son grandes y sus parámetros son matrices con dimensiones muy grandes, para adaptarlos a nuevas tareas no es necesario cambiar todos los valores de las matrices, sino que cambiando unos pocos valores es suficiente, que en términos técnicos, se llama adaptación de bajo rango. De ahí el nombre de LoRA (Low Rank Adaptation)
Hemos congelado el modelo y ahora queremos entrenar la matriz \Delta W, supongamos que tanto W como \Delta W son matrices de tamaño 20 × 10, por lo que tenemos 200 parámetros entrenables
Ahora supongamos que la matriz \Delta W se puede descomponer en el producto de dos matrices A y B, es decir
\Delta W = A · B
Para que esta multiplicación se produzca los tamaños de las matrices A y B tienen que ser 20 × n y n × 10 respectivamente. Supongamos que n = 5, por lo que A sería de tamaño 20 × 5, es decir 100 parámetros, y B de tamaño 5 × 10, es decir 50 parámetros, por lo que tendríamos 100+50=150 parámetros entrenables. Ya tenemos menos parámetros entrenables que antes
Ahora supongamos que W en realidad es una matriz de tamaño 10.000 × 10.000, por lo que tendríamos 100.000.000 parámetros entrenables, pero si descomponemos \Delta W en A y B con n = 5, tendríamos una matriz de tamaño 10.000 × 5 y otra de tamaño 5 × 10.000, por lo que tendríamos 50.000 parámetros de una y otros 50.000 parámetros de otra, en total 100.000 parámetros entrenables, es decir, hemos reducido el número de parámetros 1000 veces
Ya puedes ir viendo el poder de LoRA, cuando se tienen modelos muy grandes, el número de parámetros entrenables se puede reducir muchísimo
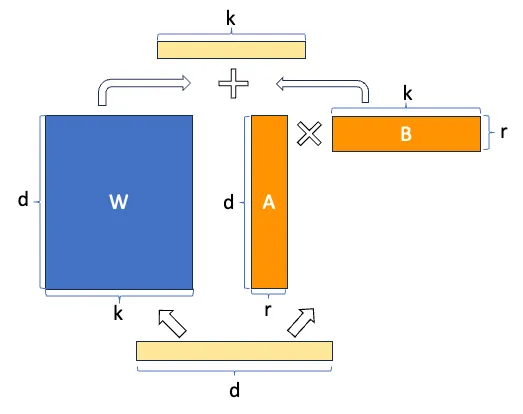
Si volvemos a ver la imagen de la arquitectura de LoRA, la entenderemos mejor
Pero se ve mejor aún, el ahorro en número de parámetros entrenables con esta imagen
Implementación de LoRA en transformers
Como los modelos de lenguaje son implementaciones de transformers, vamos a ver cómo se implementa LoRA en transformers. En la arquitectura transformer hay capas lineales en las matrices de atención Q, K y V, y en las capas feedforward, por lo que se puede aplicar LoRA a todas estas capas lineales. En el paper hablan que por simplicidad lo aplican solo a las capas lineales de las matrices de atención Q, K y V
Estas capas tienen un tamaño dmodel × dmodel, donde dmodel es la dimensión de embedding del modelo
Tamaño del rango r
Para poder tener estos beneficios, el tamaño del rango r tienen que ser menor que el tamaño de las capas lineales. Como hemos dicho que solo lo implementaban en las capas lineales de atención, que tienen un tamaño dmodel × dmodel, el tamaño del rango r tiene que ser menor que dmodel
Inicialización de las matrices A y B
Las matrices A y B se inicializan con una distribución gaussiana aleatoria para A y cero para B, así el producto de ambas matrices será cero al principio, es decir
\Delta W = A · B = 0
Influencia de LoRA mediante el parámetro $\alpha$
Por último, en la implementación de LoRA, se añade un parámetro α para establecer el grado de influencia de LoRA en el entrenamiento. Es similar al learning rate en el fine tuning normal, pero en este caso se usa para establecer la influencia de LoRA en el entrenamiento. De esta manera la fórmula de LoRA quedaría así
W = W + α \Delta W = W + α A · B
Ventajas de LoRA
Ahora que hemos entendido cómo funciona, vamos a ver las ventajas que tiene este método
- Reducción del número de parámetros entrenables. Como hemos visto, el número de parámetros entrenables se reduce drásticamente, lo que hace que el entrenamiento sea mucho más rápido y que se necesite menos VRAM, por lo que se ahorran muchos costes
- Adaptadores en producción. Podemos tener en producción un único modelo de lenguaje y varios adaptadores, cada uno para una tarea diferente, en vez de tener varios modelos entrenados para cada tarea, por lo que se ahorran costes de almacenamiento y de computación. Además este método no tiene por qué añadir latencia en la inferencia porque se puede fusionar la matriz de pesos original con el adaptador, ya que hemos visto que W \sim W + \Delta W = W + A \cdot B, por lo que el tiempo de inferencia sería la misma que usar el modelo de lenguaje original
- Compartir adaptadores. Si entrenamos un adaptador, podemos compartir solo el adaptador. Es decir, en producción, todo el mundo puede tener el modelo original y cada vez que entrenamos un adaptador compartir solo el adaptador, por lo que como se compartirían matrices mucho más pequeñas, el tamaño de los archivos que se comparte sería mucho más pequeño
Implementación de LoRA en un LLM
Vamos a repetir el código de entrenamiento del post Fine tuning SLMs, en concreto el entrenamiento para clasificación de texto con las librerías de Hugging Face, pero esta vez vamos a hacerlo con LoRA. En el anterior post usamos un batch size de 28 para el bucle de entrenamiento y de 40 para el de evaluación, sin embargo, como ahora no vamos a entrenar todos los pesos del modelo, sino solo las matrices de LoRA, vamos a poder usar un batch size mayor
Login en el Hub
Nos logeamos para subir el modelo al Hub
from huggingface_hub import notebook_loginnotebook_login()Copied
Dataset
Descargamos el dataset que vamos a usar, que es un dataset de reviews de Amazon
from datasets import load_datasetdataset = load_dataset("mteb/amazon_reviews_multi", "en")datasetCopied
DatasetDict({train: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000})validation: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})test: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})})
Creamos un subset por si quieres probar el código con un dataset más pequeño. En mi caso usaré el 100% del dataset
percentage = 1subset_dataset_train = dataset['train'].select(range(int(len(dataset['train']) * percentage)))subset_dataset_validation = dataset['validation'].select(range(int(len(dataset['validation']) * percentage)))subset_dataset_test = dataset['test'].select(range(int(len(dataset['test']) * percentage)))subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}))
Vemos una muestra
from random import randintidx = randint(0, len(subset_dataset_train))subset_dataset_train[idx]Copied
{'id': 'en_0388304','text': 'The N was missing from on The N was missing from on','label': 0,'label_text': '0'}
Obtenemos el número de clases, para obtener el número de clases usamos dataset['train'] y no subset_dataset_train porque si el subset lo hacemos muy pequeño es posible que no haya ejemplos con todas las posibles clases del dataset original
num_classes = len(dataset['train'].unique('label'))num_classesCopied
5
Creamos una función para crear el campo label en el dataset. El dataset descargado tiene el campo labels, pero la librería transformers necesita que el campo se llame label y no labels.
def set_labels(example):example['labels'] = example['label']return exampleCopied
Aplicamos la función al dataset
subset_dataset_train = subset_dataset_train.map(set_labels)subset_dataset_validation = subset_dataset_validation.map(set_labels)subset_dataset_test = subset_dataset_test.map(set_labels)subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}))
Volvemos a ver una muestra
subset_dataset_train[idx]Copied
{'id': 'en_0388304','text': 'The N was missing from on The N was missing from on','label': 0,'label_text': '0','labels': 0}
Tokenizador
Implementamos el tokenizador. Para que no nos dé error, asignamos el token de end of string al token de padding
from transformers import AutoTokenizercheckpoint = "openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoint)tokenizer.pad_token = tokenizer.eos_tokenCopied
Creamos una función para tokenizar el dataset
def tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=768, return_tensors="pt")Copied
Aplicamos la función al dataset y, de paso, eliminamos las columnas que no necesitamos
subset_dataset_train = subset_dataset_train.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_validation = subset_dataset_validation.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_test = subset_dataset_test.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 200000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}))
Volvemos a ver una muestra, pero en este caso solo vemos las keys
subset_dataset_train[idx].keys()Copied
dict_keys(['labels', 'input_ids', 'attention_mask'])
Modelo
Instanciamos el modelo. También, para que no nos dé error, asignamos el token de end of string al token de padding
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes)model.config.pad_token_id = model.config.eos_token_idCopied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Como ya vimos en el post Fine tuning SLMs obtenemos un warning en el que dice que algunas capas no se han inicializado. Esto es porque en este caso, como es un problema de clasificación y cuando hemos instanciado el modelo le hemos dicho que queremos que sea un modelo de clasificación con 5 clases, la librería ha eliminado la última capa y la ha sustituido por una de 5 neuronas a la salida. Si no entiendes bien esto ve al post que cito que está mejor explicado
LoRA
Antes de implementar LoRA, vemos el número de parámetros entrenables que tiene el modelo
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f"Total trainable parameters before: {total_params:,}")Copied
Total trainable parameters before: 124,443,648
Vemos que tiene 124M de parámetros entrenables. Ahora vamos a congelarlos
for param in model.parameters():param.requires_grad = Falsetotal_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f"Total trainable parameters after: {total_params:,}")Copied
Total trainable parameters after: 0
Tras congelar ya no hay parámetros entrenables
Vamos a ver cómo es el modelo antes de aplicar LoRA
modelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
Primero creamos la capa LoRA layer.
Tiene que heredar de torch.nn.Module para que pueda actuar como una capa de una red neuronal
En el método _init_ creamos las matrices A y B inicializadas como hemos explicado antes, la matriz A con una distribución gaussiana aleatoria y la matriz B con ceros. También creamos los parámetros rank y alpha.
En el método forward calculamos LoRA como hemos explicado
import torchclass LoRALayer(torch.nn.Module):def __init__(self, in_dim, out_dim, rank, alpha):super().__init__()self.A = torch.nn.Parameter(torch.empty(in_dim, rank))torch.nn.init.kaiming_uniform_(self.A, a=torch.sqrt(torch.tensor(5.)).item()) # similar to standard weight initializationself.B = torch.nn.Parameter(torch.zeros(rank, out_dim))self.alpha = alphadef forward(self, x):x = self.alpha * (x @ self.A @ self.B)return xCopied
Ahora creamos una clase lineal con LoRA.
Al igual que antes, hereda de torch.nn.Module para que pueda actuar como una capa de una red neuronal.
En el método init creamos una variable con la capa lineal original de la red y creamos otra variable con la nueva capa LoRA que habíamos implementado antes
En el método forward sumamos las salidas de la capa lineal original y la capa LoRA
class LoRALinear(torch.nn.Module):def __init__(self, linear, rank, alpha):super().__init__()self.linear = linearself.lora = LoRALayer(linear.in_features, linear.out_features, rank, alpha)def forward(self, x):return self.linear(x) + self.lora(x)Copied
Por último creamos una función que sustituya las capas lineales por la nueva capa linear con LoRA que hemos creado. Lo que hace es que si encuentra una capa lineal en el modelo, la sustituye por la capa lineal con LoRA, si no, aplica la función dentro de las subcapas de la capa
def replace_linear_with_lora(model, rank, alpha):for name, module in model.named_children():if isinstance(module, torch.nn.Linear):# Replace the Linear layer with LinearWithLoRAsetattr(model, name, LoRALinear(module, rank, alpha))else:# Recursively apply the same function to child modulesreplace_linear_with_lora(module, rank, alpha)Copied
Aplicamos la función al modelo para sustituir las capas lineales del modelo por la nueva capa lineal con LoRA
rank = 16alpha = 16replace_linear_with_lora(model, rank=rank, alpha=alpha)Copied
Vemos ahora el número de parámetros entrenables
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f"Total trainable LoRA parameters: {total_params:,}")Copied
Total trainable LoRA parameters: 12,368
Hemos pasado de 124M de parámetros entrenables a 12k parámetros entrenables, es decir, hemos reducido el número de parámetros entrenables 10.000 veces!
Volvemos a ver el modelo
modelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): LoRALinear((linear): Linear(in_features=768, out_features=5, bias=False)(lora): LoRALayer()))
Vamos a compararlos capa por capa
| Modelo original | Modelo con LoRA |
|---|---|
| GPT2ForSequenceClassification( | GPT2ForSequenceClassification( |
| (transformer): GPT2Model( | (transformer): GPT2Model( |
| (wte): Embedding(50257, 768) | (wte): Embedding(50257, 768) |
| (wpe): Embedding(1024, 768) | (wpe): Embedding(1024, 768) |
| (drop): Dropout(p=0.1, inplace=False) | (drop): Dropout(p=0.1, inplace=False) |
| (h): ModuleList( | (h): ModuleList( |
| (0-11): 12 x GPT2Block( | (0-11): 12 x GPT2Block( |
| (ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) | (ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) |
| (attn): GPT2Attention( | (attn): GPT2Attention( |
| (c_attn): Conv1D() | (c_attn): Conv1D() |
| (c_proj): Conv1D() | (c_proj): Conv1D() |
| (attn_dropout): Dropout(p=0.1, inplace=False) | (attn_dropout): Dropout(p=0.1, inplace=False) |
| (resid_dropout): Dropout(p=0.1, inplace=False) | (resid_dropout): Dropout(p=0.1, inplace=False) |
| ) | ) |
| (ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True) | (ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True) |
| (mlp): GPT2MLP( | (mlp): GPT2MLP( |
| (c_fc): Conv1D() | (c_fc): Conv1D() |
| (c_proj): Conv1D() | (c_proj): Conv1D() |
| (act): NewGELUActivation() | (act): NewGELUActivation() |
| (dropout): Dropout(p=0.1, inplace=False) | (dropout): Dropout(p=0.1, inplace=False) |
| ) | ) |
| ) | ) |
| ) | ) |
| (ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True) | (ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True) |
| ) | ) |
| (score): LoRALinear() | |
| (score): Linear(in_features=768, out_features=5, bias=False) | (linear): Linear(in_features=768, out_features=5, bias=False) |
| (lora): LoRALayer() | |
| ) | |
| ) | ) |
Vemos que son iguales menos al final, donde en el modelo original había una capa lineal normal y en el modelo con LoRA hay una capa LoRALinear que dentro tiene la capa lineal del modelo original y una capa LoRALayer
Training
Una vez instanciado el modelo con LoRA, vamos a entrenarlo como siempre
Como hemos dicho, en el post Fine tuning SLMs usamos un batch size de 28 para el bucle de entrenamiento y de 40 para el de evaluación, mientras que ahora que hay menos parámetros entrenables podemos usar un batch size mayor.
¿Esto por qué pasa? Cuando se entrena un modelo hay que guardar en la memoria de la GPU el modelo y los gradientes de este, por lo que tanto con LoRA como sin LoRA el modelo hay que guardarlo igualmente, pero en el caso de LoRA solo se guardan los gradientes de 12k parámetros, mientras que con LoRA se guardan los gradientes de 128M de parámetros, por lo que con LoRA se necesita menos memoria de la GPU, por lo que se puede usar un batch size mayor
from transformers import TrainingArgumentsmetric_name = "accuracy"model_name = "GPT2-small-LoRA-finetuned-amazon-reviews-en-classification"LR = 2e-5BS_TRAIN = 400BS_EVAL = 400EPOCHS = 3WEIGHT_DECAY = 0.01training_args = TrainingArguments(model_name,eval_strategy="epoch",save_strategy="epoch",learning_rate=LR,per_device_train_batch_size=BS_TRAIN,per_device_eval_batch_size=BS_EVAL,num_train_epochs=EPOCHS,weight_decay=WEIGHT_DECAY,lr_scheduler_type="cosine",warmup_ratio = 0.1,fp16=True,load_best_model_at_end=True,metric_for_best_model=metric_name,push_to_hub=True,logging_dir="./runs",)Copied
import numpy as npfrom evaluate import loadmetric = load("accuracy")def compute_metrics(eval_pred):print(eval_pred)predictions, labels = eval_predpredictions = np.argmax(predictions, axis=1)return metric.compute(predictions=predictions, references=labels)Copied
from transformers import Trainertrainer = Trainer(model,training_args,train_dataset=subset_dataset_train,eval_dataset=subset_dataset_validation,tokenizer=tokenizer,compute_metrics=compute_metrics,)Copied
trainer.train()Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7cd07be46440><transformers.trainer_utils.EvalPrediction object at 0x7cd07be45c30><transformers.trainer_utils.EvalPrediction object at 0x7cd07be8b970>
TrainOutput(global_step=1500, training_loss=1.8345018310546874, metrics={'train_runtime': 2565.4667, 'train_samples_per_second': 233.876, 'train_steps_per_second': 0.585, 'total_flos': 2.352076406784e+17, 'train_loss': 1.8345018310546874, 'epoch': 3.0})
Evaluación
Una vez entrenado, evaluamos sobre el dataset de test
trainer.evaluate(eval_dataset=subset_dataset_test)Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7cd07be8bbe0>
{'eval_loss': 1.5203168392181396,'eval_accuracy': 0.3374,'eval_runtime': 19.3843,'eval_samples_per_second': 257.94,'eval_steps_per_second': 0.671,'epoch': 3.0}
Publicar el modelo
Ya tenemos nuestro modelo entrenado, ya podemos compartirlo con el mundo, así que primero creamos una **model card**
trainer.create_model_card()Copied
Y ya lo podemos publicar. Como lo primero que hemos hecho ha sido loguearnos con el hub de huggingface, lo podremos subir a nuestro hub sin ningún problema
trainer.push_to_hub()Copied
Prueba del modelo
Limpiamos todo lo posible
import torchimport gcdef clear_hardwares():torch.clear_autocast_cache()torch.cuda.ipc_collect()torch.cuda.empty_cache()gc.collect()clear_hardwares()clear_hardwares()Copied
Como hemos subido el modelo a nuestro hub, podemos descargarlo y usarlo
from transformers import pipelineuser = "maximofn"checkpoints = f"{user}/{model_name}"task = "text-classification"classifier = pipeline(task, model=checkpoints, tokenizer=checkpoints)Copied
Ahora si queremos que nos devuelva la probabilidad de todas las clases, simplemente usamos el clasificador que acabamos de instanciar, con el parámetro top_k=None
labels = classifier("I love this product", top_k=None)labelsCopied
[{'label': 'LABEL_0', 'score': 0.8419149518013},{'label': 'LABEL_1', 'score': 0.09386005252599716},{'label': 'LABEL_3', 'score': 0.03624210134148598},{'label': 'LABEL_2', 'score': 0.02049318142235279},{'label': 'LABEL_4', 'score': 0.0074898069724440575}]
Si solo queremos la clase con la mayor probabilidad, hacemos lo mismo pero con el parámetro top_k=1
label = classifier("I love this product", top_k=1)labelCopied
[{'label': 'LABEL_0', 'score': 0.8419149518013}]
Y si queremos n clases, hacemos lo mismo pero con el parámetro top_k=n
two_labels = classifier("I love this product", top_k=2)two_labelsCopied
[{'label': 'LABEL_0', 'score': 0.8419149518013},{'label': 'LABEL_1', 'score': 0.09386005252599716}]
También podemos probar el modelo con Automodel y AutoTokenizer
from transformers import AutoTokenizer, AutoModelForSequenceClassificationimport torchmodel_name = "GPT2-small-finetuned-amazon-reviews-en-classification"user = "maximofn"checkpoint = f"{user}/{model_name}"num_classes = num_classestokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes).half().eval().to("cuda")Copied
tokens = tokenizer.encode("I love this product", return_tensors="pt").to(model.device)with torch.no_grad():output = model(tokens)logits = output.logitslables = torch.softmax(logits, dim=1).cpu().numpy().tolist()lables[0]Copied
[0.003940582275390625,0.00266265869140625,0.013946533203125,0.1544189453125,0.8251953125]
Si quieres probar más el modelo puedes verlo en Maximofn/GPT2-small-LoRA-finetuned-amazon-reviews-en-classification
Implementación de LoRA en un LLM con PEFT de Hugging Face
Podemos hacer lo mismo con la librería PEFT de Hugging Face. Vamos a verlo
Login en el Hub
Nos logeamos para subir el modelo al Hub
from huggingface_hub import notebook_loginnotebook_login()Copied
Dataset
Volvemos a descargar el dataset
from datasets import load_datasetdataset = load_dataset("mteb/amazon_reviews_multi", "en")datasetCopied
DatasetDict({train: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000})validation: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})test: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})})
Creamos un subset por si quieres probar el código con un dataset más pequeño. En mi caso usaré el 100% del dataset
percentage = 1subset_dataset_train = dataset['train'].select(range(int(len(dataset['train']) * percentage)))subset_dataset_validation = dataset['validation'].select(range(int(len(dataset['validation']) * percentage)))subset_dataset_test = dataset['test'].select(range(int(len(dataset['test']) * percentage)))subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}))
Obtenemos el número de clases, para obtener el número de clases usamos dataset['train'] y no subset_dataset_train porque si el subset lo hemos muy pequeño es posible que no haya ejemplos con todas las posibles clases del dataset original
num_classes = len(dataset['train'].unique('label'))num_classesCopied
5
Creamos una función para crear el campo label en el dataset. El dataset descargado tiene el campo labels pero la librería transformers necesita que el campo se llame label y no labels
def set_labels(example):example['labels'] = example['label']return exampleCopied
Aplicamos la función al dataset
subset_dataset_train = subset_dataset_train.map(set_labels)subset_dataset_validation = subset_dataset_validation.map(set_labels)subset_dataset_test = subset_dataset_test.map(set_labels)subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}))
Tokenizador
Instanciamos el tokenizador. Para que no nos dé error, asignamos el token de end of string al token de padding
from transformers import AutoTokenizercheckpoint = "openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoint)tokenizer.pad_token = tokenizer.eos_tokenCopied
Creamos una función para tokenizar el dataset
def tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=768, return_tensors="pt")Copied
Aplicamos la función al dataset y de paso eliminamos las columnas que no necesitamos
subset_dataset_train = subset_dataset_train.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_validation = subset_dataset_validation.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_test = subset_dataset_test.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 200000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}))
Modelo
Instanciamos el modelo. También, para que no nos de error, asignamos el token de end of string al token de padding
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes)model.config.pad_token_id = model.config.eos_token_idCopied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
LoRA con PEFT
Antes de crear el modelo con LoRA, vamos a ver sus capas
modelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
Como vemos, solo hay una capa Linear, que es score y que es la que vamos a sustituir
Podemos crear una configuración de LoRA con la librería PEFT y luego aplicar LoRA al mo
from peft import LoraConfig, TaskTypepeft_config = LoraConfig(r=16,lora_alpha=32,lora_dropout=0.1,task_type=TaskType.SEQ_CLS,target_modules=["score"],)Copied
Con esta configuración hemos configurado un rank de 16 y un alpha de 32. Además hemos añadido un dropout a las capas de lora de 0.1. Le tenemos que indicar la tarea a la configuración de LoRA, en este caso es una tarea de sequence classification. Por último le indicamos qué capas queremos sustituir, en este caso la capa score
Ahora aplicamos LoRA al modelo
from peft import get_peft_modelmodel = get_peft_model(model, peft_config)Copied
Vamos a ver cuántos parámetros entrenables tiene ahora el modelo
model.print_trainable_parameters()Copied
trainable params: 12,368 || all params: 124,456,016 || trainable%: 0.0099
Obtenemos los mismos parámetros entrenables que antes
Training
Una vez instanciado el modelo con LoRA, vamos a entrenarlo como siempre
from transformers import TrainingArgumentsmetric_name = "accuracy"model_name = "GPT2-small-PEFT-LoRA-finetuned-amazon-reviews-en-classification"LR = 2e-5BS_TRAIN = 400BS_EVAL = 400EPOCHS = 3WEIGHT_DECAY = 0.01training_args = TrainingArguments(model_name,eval_strategy="epoch",save_strategy="epoch",learning_rate=LR,per_device_train_batch_size=BS_TRAIN,per_device_eval_batch_size=BS_EVAL,num_train_epochs=EPOCHS,weight_decay=WEIGHT_DECAY,lr_scheduler_type="cosine",warmup_ratio = 0.1,fp16=True,load_best_model_at_end=True,metric_for_best_model=metric_name,push_to_hub=True,logging_dir="./runs",)Copied
import numpy as npfrom evaluate import loadmetric = load("accuracy")def compute_metrics(eval_pred):print(eval_pred)predictions, labels = eval_predpredictions = np.argmax(predictions, axis=1)return metric.compute(predictions=predictions, references=labels)Copied
from transformers import Trainertrainer = Trainer(model,training_args,train_dataset=subset_dataset_train,eval_dataset=subset_dataset_validation,tokenizer=tokenizer,compute_metrics=compute_metrics,)Copied
trainer.train()Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7f774a50bbe0>
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7f77486a7c40><transformers.trainer_utils.EvalPrediction object at 0x7f7749eb5690>
TrainOutput(global_step=1500, training_loss=1.751504597981771, metrics={'train_runtime': 2551.7753, 'train_samples_per_second': 235.13, 'train_steps_per_second': 0.588, 'total_flos': 2.352524525568e+17, 'train_loss': 1.751504597981771, 'epoch': 3.0})
Evaluación
Una vez entrenado, evaluamos sobre el dataset de test
trainer.evaluate(eval_dataset=subset_dataset_test)Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7f77a1d1f7c0>
{'eval_loss': 1.4127237796783447,'eval_accuracy': 0.3862,'eval_runtime': 19.3275,'eval_samples_per_second': 258.699,'eval_steps_per_second': 0.673,'epoch': 3.0}
Publicar el modelo
Creamos una model card
trainer.create_model_card()Copied
Lo publicamos
trainer.push_to_hub()Copied
CommitInfo(commit_url='https://huggingface.co/Maximofn/GPT2-small-PEFT-LoRA-finetuned-amazon-reviews-en-classification/commit/839066c2bde02689a6b3f5624ac25f89c4de217d', commit_message='End of training', commit_description='', oid='839066c2bde02689a6b3f5624ac25f89c4de217d', pr_url=None, pr_revision=None, pr_num=None)
Prueba del modelo entrenado con PEFT
Limpiamos todo lo posible
import torchimport gcdef clear_hardwares():torch.clear_autocast_cache()torch.cuda.ipc_collect()torch.cuda.empty_cache()gc.collect()clear_hardwares()clear_hardwares()Copied
Como hemos subido el modelo a nuestro hub, podemos descargarlo y usarlo
from transformers import pipelineuser = "maximofn"checkpoints = f"{user}/{model_name}"task = "text-classification"classifier = pipeline(task, model=checkpoints, tokenizer=checkpoints)Copied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Ahora si queremos que nos devuelva la probabilidad de todas las clases, simplemente usamos el clasificador que acabamos de instanciar, con el parámetro top_k=None
labels = classifier("I love this product", top_k=None)labelsCopied
[{'label': 'LABEL_1', 'score': 0.9979197382926941},{'label': 'LABEL_0', 'score': 0.002080311067402363}]
Si solo queremos la clase con la mayor probabilidad hacemos lo mismo pero con el parámetro top_k=1
label = classifier("I love this product", top_k=1)labelCopied
[{'label': 'LABEL_1', 'score': 0.9979197382926941}]
Y si queremos n clases, hacemos lo mismo pero con el parámetro top_k=n
two_labels = classifier("I love this product", top_k=2)two_labelsCopied
[{'label': 'LABEL_1', 'score': 0.9979197382926941},{'label': 'LABEL_0', 'score': 0.002080311067402363}]
Si quieres probar más el modelo puedes verlo en Maximofn/GPT2-small-PEFT-LoRA-finetuned-amazon-reviews-en-classification
















