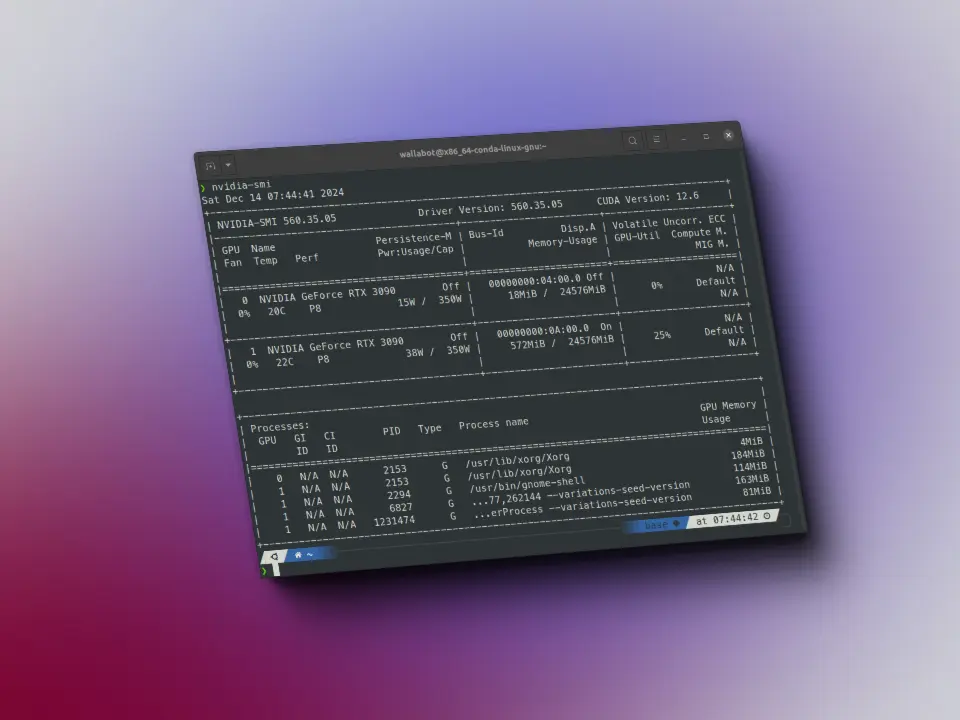
py-smi
¿Quieres poder usar nvidia-smi desde Python? Aquí tienes una librería para hacerlo.
Instalación
Para poder instalarla ejecuta:
pip install python-smi
Uso
Importamos la librería
from py_smi import NVMLCopied
Creamos un objeto de pynvml (la librería detrás de nvidia-smi)
nv = NVML()Copied
Obtenemos la versión del driver y de CUDA
nv.driver_version, nv.cuda_versionCopied
('560.35.03', '12.6')
Como en mi caso tengo dos GPUs creo una variable con el número de GPUs
num_gpus = 2Copied
Obtengo la memoria de cada GPU
[nv.mem(i) for i in range(num_gpus)]Copied
[_Memory(free=24136.6875, total=24576.0, used=439.3125),_Memory(free=23509.0, total=24576.0, used=1067.0)]
La utilización
[nv.utilization() for i in range(num_gpus)]Copied
[_Utilization(gpu=0, memory=0, enc=0, dec=0),_Utilization(gpu=0, memory=0, enc=0, dec=0)]
La potencia usada
Esto me viene muy bien, porque cuando entrenaba un modelo y tenía las dos GPUs llenas a veces se me apagaba el ordenador, y viendo la potencia, veo que la segunda consume mucho, por lo que puede que sea lo que yo ya sospechaba, que era por alimentación.
[nv.power(i) for i in range(num_gpus)]Copied
[_Power(usage=15.382, limit=350.0), _Power(usage=40.573, limit=350.0)]
Los relojes de cada GPU
[nv.clocks(i) for i in range(num_gpus)]Copied
[_Clocks(graphics=0, sm=0, mem=405), _Clocks(graphics=540, sm=540, mem=810)]
Datos del PCI
[nv.pcie_throughput(i) for i in range(num_gpus)]Copied
[_PCIeThroughput(rx=0.0, tx=0.0),_PCIeThroughput(rx=0.1630859375, tx=0.0234375)]
Y los procesos (ahora no estoy corriendo nada)
[nv.processes(i) for i in range(num_gpus)]Copied
[[], []]
















