Desplegar backend en HuggingFace
En este post vamos a ver cómo desplegar un backend en HuggingFace. Vamos a ver cómo hacerlo de dos maneras, mediante la forma común, creando una aplicación con Gradio, y mediante una opción diferente usando FastAPI, Langchain y Docker
Para ambos casos va a ser necesario tener una cuenta en HuggingFace, ya que vamos a desplegar el backend en un space de HuggingFace.
Desplegar backend con Gradio
Crear space
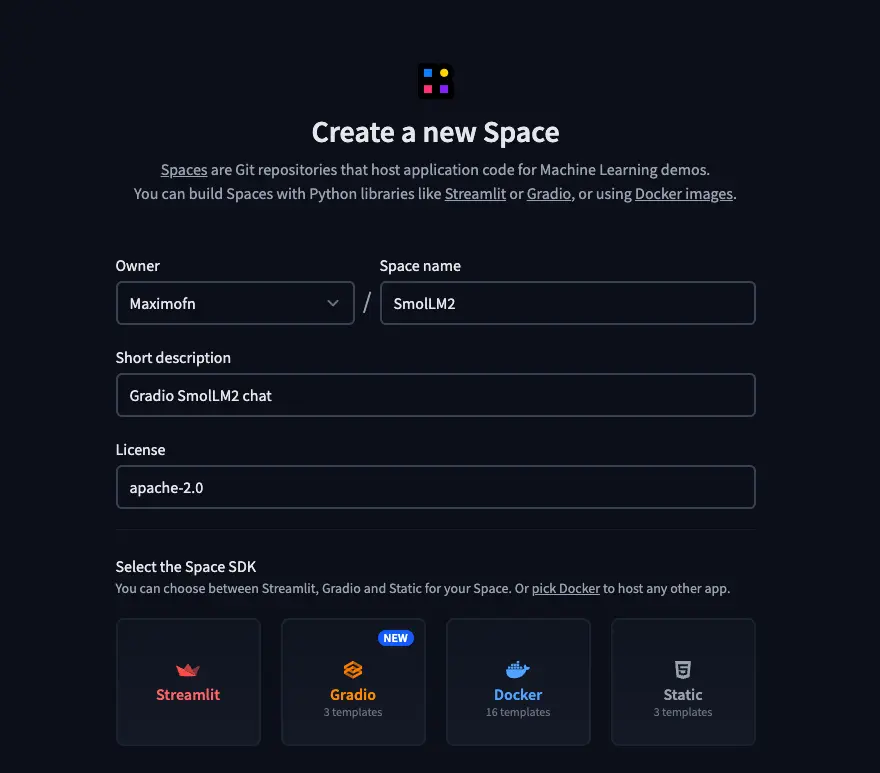
Primero de todo, creamos un nuevo espacio en Hugging Face.
- Ponemos un nombre, una descripción y elegimos la licencia.
- Elegimos Gradio como el tipo de SDK. Al elegir Gradio, nos aparecerán plantillas, así que elegimos la plantilla de chatbot.
- Seleccionamos el HW en el que vamos a desplegar el backend, yo voy a elegir la CPU gratuita, pero tú elige lo que mejor consideres.
- Y por último hay que elegir si queremos crear el espacio público o privado.
Código
Al crear el space, podemos clonarlo o podemos ver los archivos en la propia página de HuggingFace. Podemos ver que se han creado 3 archivos, app.py, requirements.txt y README.md. Así que vamos a ver qué poner en cada uno
app.py
Aquí tenemos el código de la aplicación. Como hemos elegido la plantilla de chatbot, ya tenemos mucho hecho, pero vamos a tener que cambiar 2 cosas, primero el modelo de lenguaje y el system prompt
Como modelo de lenguaje veo HuggingFaceH4/zephyr-7b-beta, pero vamos a usar Qwen/Qwen2.5-72B-Instruct, que es un modelo muy capaz.
Así que busca el texto client = InferenceClient("HuggingFaceH4/zephyr-7b-beta") y reemplázalo por client = InferenceClient("Qwen/Qwen2.5-72B-Instruct"), o espera que más adelante pondré todo el código.
También vamos a cambiar el system prompt, que por defecto es You are a friendly Chatbot., pero como es un modelo entrenado en su mayoría en inglés, es probable que si le hablas en otro idioma te responda en inglés, así que vamos a cambiarlo por You are a friendly Chatbot. Always reply in the language in which the user is writing to you..
Así que busca el texto gr.Textbox(value="You are a friendly Chatbot.", label="System message"), y reemplázalo por gr.Textbox(value="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.", label="System message"),, o espera a que ahora voy a poner todo el código.
import gradio as gr
from huggingface_hub import InferenceClient
"""
For more information on `huggingface_hub` Inference API support, please check the docs: https://huggingface.co/docs/huggingface_hub/v0.22.2/en/guides/inference
"""
client = InferenceClient("Qwen/Qwen2.5-72B-Instruct")
def respond(
message,
history: list[tuple[str, str]],
system_message,
max_tokens,
temperature,
top_p,
):
messages = [{"role": "system", "content": system_message}]
for val in history:
if val[0]:
messages.append({"role": "user", "content": val[0]})
if val[1]:
messages.append({"role": "assistant", "content": val[1]})
messages.append({"role": "user", "content": message})
response = ""
for message in client.chat_completion(
messages,
max_tokens=max_tokens,
stream=True,
temperature=temperature,
top_p=top_p,
):
token = message.choices[0].delta.content
response += token
yield response
"""
For information on how to customize the ChatInterface, peruse the gradio docs: https://www.gradio.app/docs/gradio/chatinterface
"""
demo = gr.ChatInterface(
respond,
additional_inputs=[
gr.Textbox(value="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.", label="System message"),
gr.Slider(minimum=1, maximum=2048, value=512, step=1, label="Max new tokens"),
gr.Slider(minimum=0.1, maximum=4.0, value=0.7, step=0.1, label="Temperature"),
gr.Slider(
minimum=0.1,
maximum=1.0,
value=0.95,
step=0.05,
label="Top-p (nucleus sampling)",
),
],
)
if __name__ == "__main__":
demo.launch()
requirements.txt
Este es el archivo en el que estarán escritas las dependencias, pero para este caso va a ser muy sencillo:
huggingface_hub==0.25.2README.md
Este es el archivo en el que vamos a poner la información del espacio. En los spaces de HuggingFace, al inicio de los readmes, se pone un código para que HuggingFace sepa cómo mostrar la miniatura del espacio, qué fichero tiene que usar para ejecutar el código, versión del sdk, etc.
---
title: SmolLM2
emoji: 💬
colorFrom: yellow
colorTo: purple
sdk: gradio
sdk_version: 5.0.1
app_file: app.py
pinned: false
license: apache-2.0
short_description: Gradio SmolLM2 chat
---
An example chatbot using [Gradio](https://gradio.app), [`huggingface_hub`](https://huggingface.co/docs/huggingface_hub/v0.22.2/en/index), and the [Hugging Face Inference API](https://huggingface.co/docs/api-inference/index).
Despliegue
Si hemos clonado el espacio, tenemos que hacer un commit y un push. Si hemos modificado los archivos en HuggingFace, con guardarlos es suficiente.
Así que cuando estén los cambios en HuggingFace, tendremos que esperar unos segundos para que se construya el espacio y podremos usarlo.
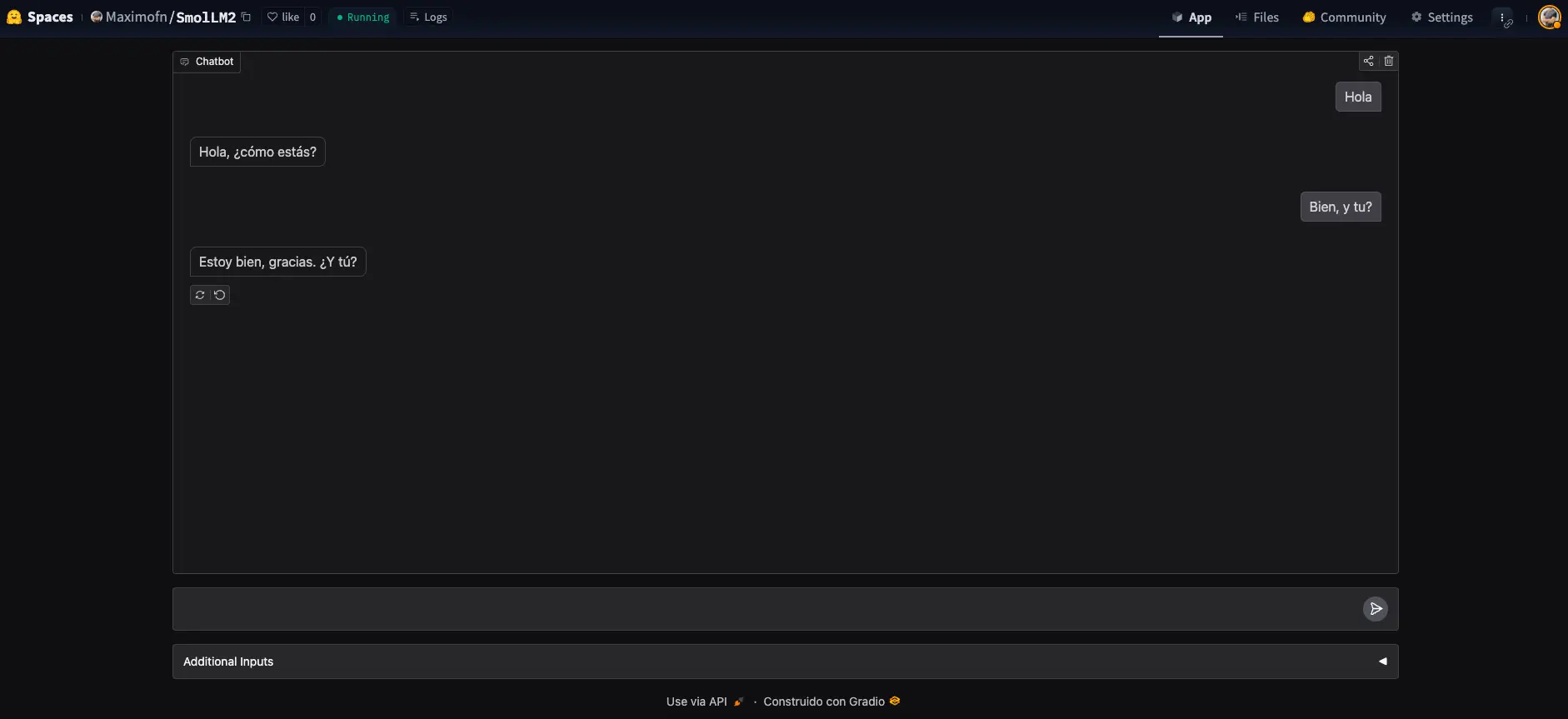
Backend
Muy bien, hemos hecho un chatbot, pero no era la intención, aquí habíamos venido a hacer un backend! Para, para, fíjate lo que pone debajo del chatbot
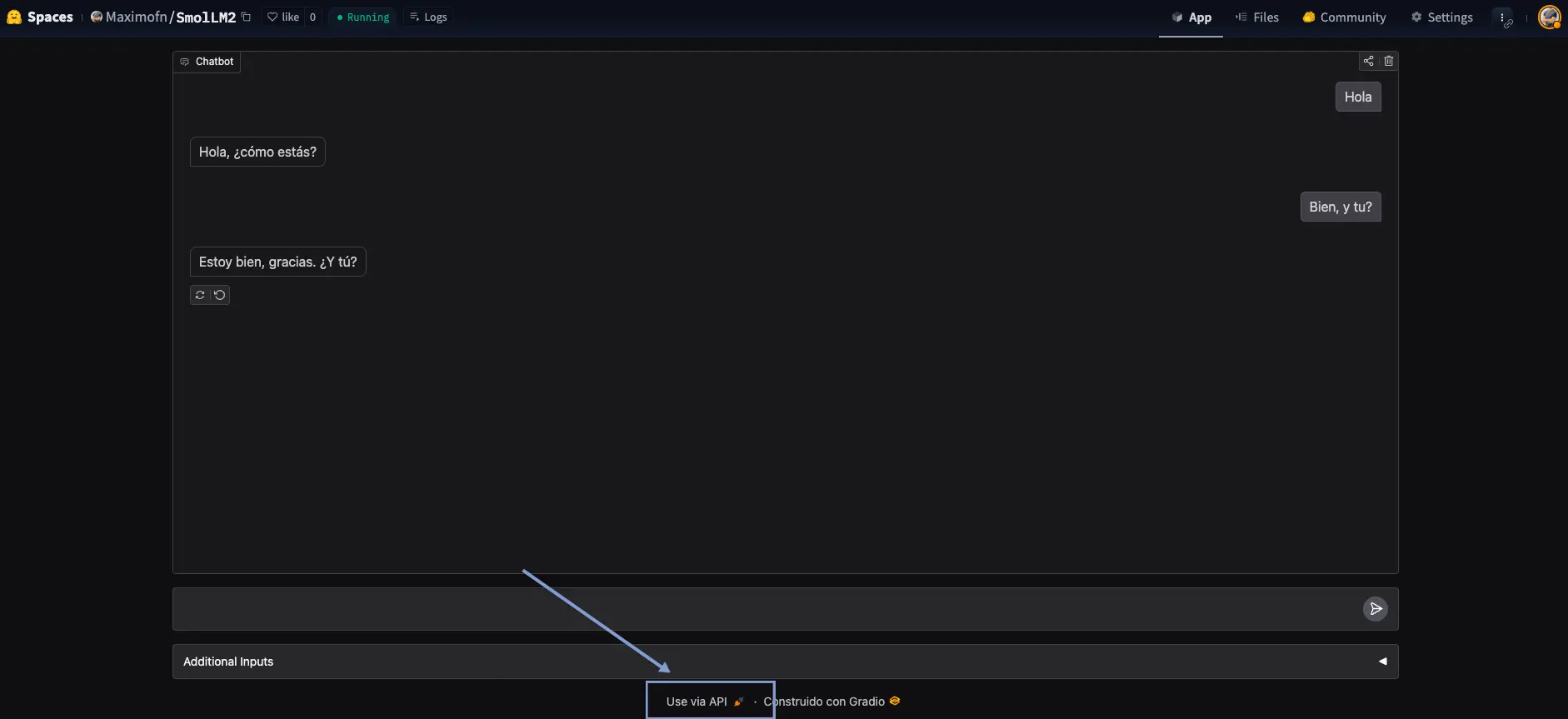
Podemos ver un texto Use via API, donde si pulsamos se nos abre un menú con una API para poder usar el chatbot.
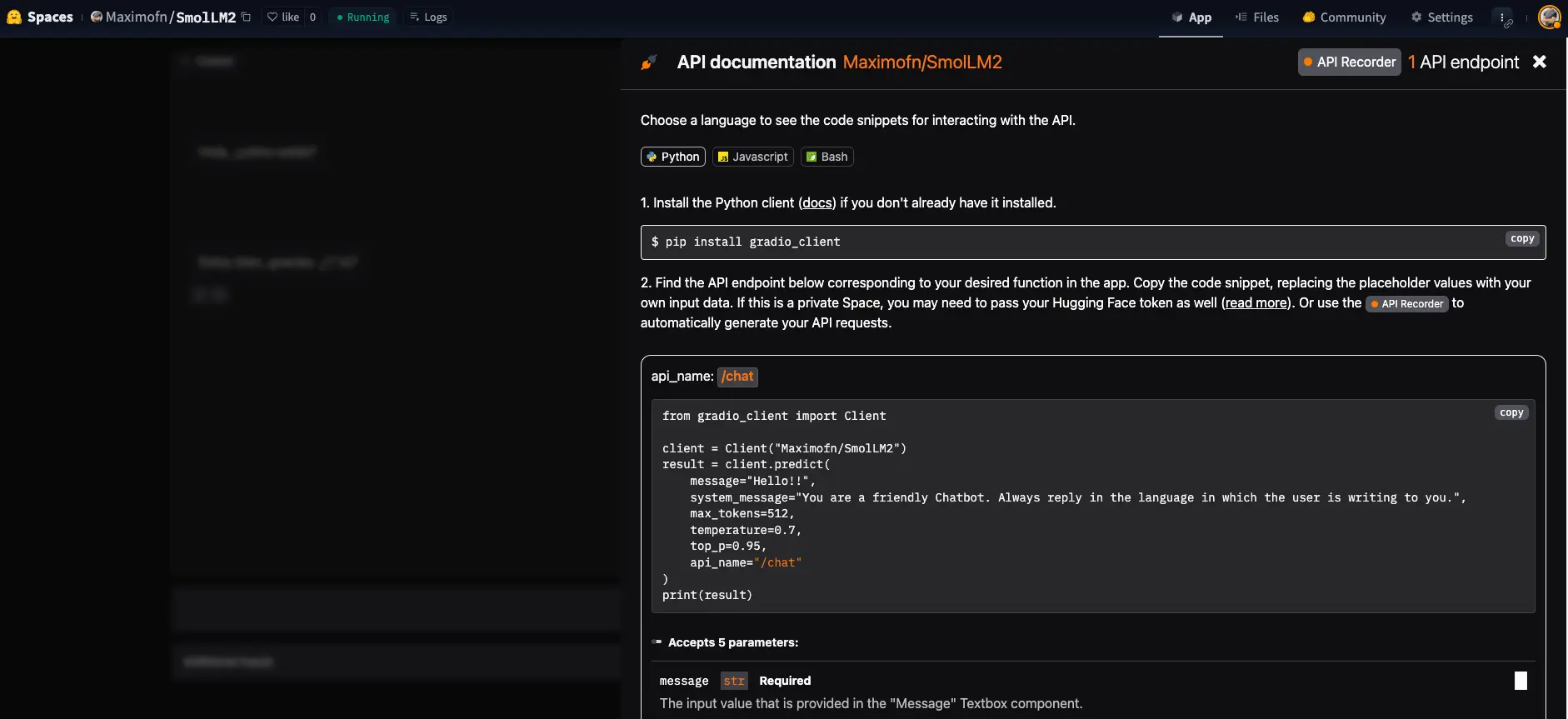
Vemos que nos da una documentación de cómo usar la API, tanto con Python, con JavaScript, como con bash.
Prueba de la API
Usamos el código de ejemplo de Python.
from gradio_client import Clientclient = Client("Maximofn/SmolLM2")result = client.predict(message="Hola, ¿cómo estás? Me llamo Máximo",system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")print(result)
Loaded as API: https://maximofn-smollm2.hf.space ✔¡Hola Máximo! Mucho gusto, estoy bien, gracias por preguntar. ¿Cómo estás tú? ¿En qué puedo ayudarte hoy?
Estamos haciendo llamadas a la API de InferenceClient de HuggingFace, así que podríamos pensar, ¿Para qué hemos hecho un backend, si podemos llamar directamente a la API de HuggingFace? Pues lo vas a ver a continuación.
result = client.predict(message="¿Cómo me llamo?",system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")print(result)
Tu nombre es Máximo. ¿Es correcto?
La plantilla de chat de Gradio maneja el historial por nosotros, de manera que cada vez que creamos un nuevo cliente, se crea un nuevo hilo de conversación.
Vamos a probar a crear un nuevo cliente, y ver si se crea un nuevo hilo de conversación.
from gradio_client import Clientnew_client = Client("Maximofn/SmolLM2")result = new_client.predict(message="Hola, ¿cómo estás? Me llamo Luis",system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")print(result)
Loaded as API: https://maximofn-smollm2.hf.space ✔Hola Luis, estoy muy bien, gracias por preguntar. ¿Cómo estás tú? Es un gusto conocerte. ¿En qué puedo ayudarte hoy?
Ahora le volvemos a preguntar cómo me llamo
result = new_client.predict(message="¿Cómo me llamo?",system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")print(result)
Te llamas Luis. ¿Hay algo más en lo que pueda ayudarte?
Como vemos, tenemos dos clientes, cada uno con su propio hilo de conversación.
Desplegar backend con FastAPI, Langchain y Docker
Ahora vamos a hacer lo mismo, crear un backend de un chatbot, con el mismo modelo, pero en este caso usando FastAPI, Langchain y Docker.
Crear space
Tenemos que crear un nuevo espacio, pero en este caso lo haremos de otra manera
- Ponemos un nombre, una descripción y elegimos la licencia.
- Elegimos Docker como el tipo de SDK. Al elegir Docker, nos aparecerán plantillas, así que elegimos una plantilla en blanco.
- Seleccionamos el HW en el que vamos a desplegar el backend, yo voy a elegir la CPU gratuita, pero tú elige lo que mejor consideres.
- Y por último hay que elegir si queremos crear el espacio público o privado.
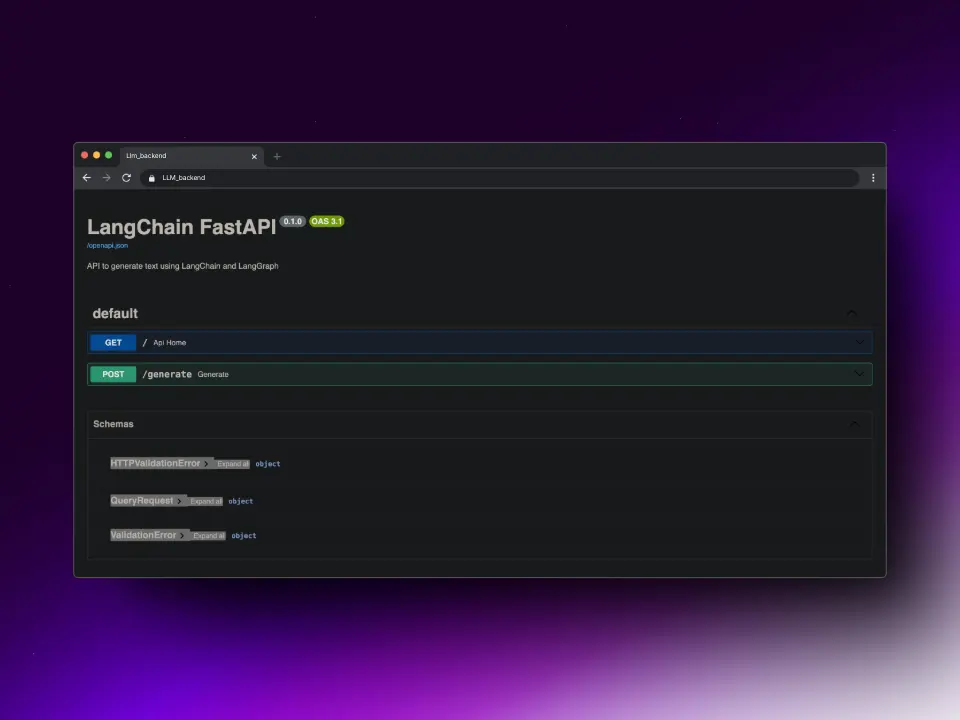
Código
Ahora, al crear el space, vemos que solo tenemos un archivo, el README.md. Así que vamos a tener que crear todo el código nosotros.
app.py
Vamos a crear el código de la aplicación
Empezamos con las librerías necesarias
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from huggingface_hub import InferenceClient
from langchain_core.messages import HumanMessage, AIMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, MessagesState, StateGraph
import os
from dotenv import load_dotenv
load_dotenv()
Cargamos fastapi para poder crear las rutas de la API, pydantic para crear la plantilla de las querys, huggingface_hub para poder crear un modelo de lenguaje, langchain para poder indicarle al modelo si los mensajes son del chatbot o del usuario y langgraph para poder crear el chatbot.
Además cargamos os y dotenv para poder cargar las variables de entorno.
Cargamos el token de HuggingFace
# HuggingFace token
HUGGINGFACE_TOKEN = os.environ.get("HUGGINGFACE_TOKEN", os.getenv("HUGGINGFACE_TOKEN"))
Creamos el modelo de lenguaje
# Initialize the HuggingFace model
model = InferenceClient(
model="Qwen/Qwen2.5-72B-Instruct",
api_key=os.getenv("HUGGINGFACE_TOKEN")
)
Creamos ahora una función para llamar al modelo
# Define the function that calls the model
def call_model(state: MessagesState):
"""
Call the model with the given messages
Args:
state: MessagesState
Returns:
dict: A dictionary containing the generated text and the thread ID
"""
# Convert LangChain messages to HuggingFace format
hf_messages = []
for msg in state["messages"]:
if isinstance(msg, HumanMessage):
hf_messages.append({"role": "user", "content": msg.content})
elif isinstance(msg, AIMessage):
hf_messages.append({"role": "assistant", "content": msg.content})
# Call the API
response = model.chat_completion(
messages=hf_messages,
temperature=0.5,
max_tokens=64,
top_p=0.7
)
# Convert the response to LangChain format
ai_message = AIMessage(content=response.choices[0].message.content)
return {"messages": state["messages"] + [ai_message]}
Convertimos los mensajes de formato LangChain a formato HuggingFace, así podemos usar el modelo de lenguaje.
Definimos una plantilla para las queries
class QueryRequest(BaseModel):
query: str
thread_id: str = "default"
Las queries van a tener un query, el mensaje del usuario, y un thread_id, que es el identificador del hilo de la conversación y más adelante explicaremos para qué lo usamos.
Creamos un grafo de LangGraph
# Define the graph
workflow = StateGraph(state_schema=MessagesState)
# Define the node in the graph
workflow.add_edge(START, "model")
workflow.add_node("model", call_model)
# Add memory
memory = MemorySaver()
graph_app = workflow.compile(checkpointer=memory)
Con esto lo que hacemos es crear un grafo de LangGraph, que es una estructura de datos que nos permite crear un chatbot y que gestiona por nosotros el estado del chatbot, es decir, entre otras cosas, el historial de mensajes. Así no lo tenemos que hacer nosotros.
Creamos la aplicación de FastAPI
app = FastAPI(title="LangChain FastAPI", description="API to generate text using LangChain and LangGraph")
Creamos los endpoints de la API
# Welcome endpoint
@app.get("/")
async def api_home():
"""Welcome endpoint"""
return {"detail": "Welcome to FastAPI, Langchain, Docker tutorial"}
# Generate endpoint
@app.post("/generate")
async def generate(request: QueryRequest):
"""
Endpoint to generate text using the language model
Args:
request: QueryRequest
query: str
thread_id: str = "default"
Returns:
dict: A dictionary containing the generated text and the thread ID
"""
try:
# Configure the thread ID
config = {"configurable": {"thread_id": request.thread_id}}
# Create the input message
input_messages = [HumanMessage(content=request.query)]
# Invoke the graph
output = graph_app.invoke({"messages": input_messages}, config)
# Get the model response
response = output["messages"][-1].content
return {
"generated_text": response,
"thread_id": request.thread_id
}
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error al generar texto: {str(e)}")
Hemos creado el endpoint / que nos devolverá un texto cuando accedamos a la API, y el endpoint /generate que es el que usaremos para generar el texto.
Si nos fijamos en la función generate tenemos la variable config, que es un diccionario que contiene el thread_id. Este thread_id es el que nos permite tener un historial de mensajes de cada usuario, de esta manera, diferentes usuarios pueden usar el mismo endpoint y tener su propio historial de mensajes.
Por último, tenemos el código para que se pueda ejecutar la aplicación
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=7860)
Vamos a escribir todo el código junto
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from huggingface_hub import InferenceClient
from langchain_core.messages import HumanMessage, AIMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, MessagesState, StateGraph
import os
from dotenv import load_dotenv
load_dotenv()
# HuggingFace token
HUGGINGFACE_TOKEN = os.environ.get("HUGGINGFACE_TOKEN", os.getenv("HUGGINGFACE_TOKEN"))
# Initialize the HuggingFace model
model = InferenceClient(
model="Qwen/Qwen2.5-72B-Instruct",
api_key=os.getenv("HUGGINGFACE_TOKEN")
)
# Define the function that calls the model
def call_model(state: MessagesState):
"""
Call the model with the given messages
Args:
state: MessagesState
Returns:
dict: A dictionary containing the generated text and the thread ID
"""
# Convert LangChain messages to HuggingFace format
hf_messages = []
for msg in state["messages"]:
if isinstance(msg, HumanMessage):
hf_messages.append({"role": "user", "content": msg.content})
elif isinstance(msg, AIMessage):
hf_messages.append({"role": "assistant", "content": msg.content})
# Call the API
response = model.chat_completion(
messages=hf_messages,
temperature=0.5,
max_tokens=64,
top_p=0.7
)
# Convert the response to LangChain format
ai_message = AIMessage(content=response.choices[0].message.content)
return {"messages": state["messages"] + [ai_message]}
# Define the graph
workflow = StateGraph(state_schema=MessagesState)
# Define the node in the graph
workflow.add_edge(START, "model")
workflow.add_node("model", call_model)
# Add memory
memory = MemorySaver()
graph_app = workflow.compile(checkpointer=memory)
# Define the data model for the request
class QueryRequest(BaseModel):
query: str
thread_id: str = "default"
# Create the FastAPI application
app = FastAPI(title="LangChain FastAPI", description="API to generate text using LangChain and LangGraph")
# Welcome endpoint
@app.get("/")
async def api_home():
"""Welcome endpoint"""
return {"detail": "Welcome to FastAPI, Langchain, Docker tutorial"}
# Generate endpoint
@app.post("/generate")
async def generate(request: QueryRequest):
"""
Endpoint to generate text using the language model
Args:
request: QueryRequest
query: str
thread_id: str = "default"
Returns:
dict: A dictionary containing the generated text and the thread ID
"""
try:
# Configure the thread ID
config = {"configurable": {"thread_id": request.thread_id}}
# Create the input message
input_messages = [HumanMessage(content=request.query)]
# Invoke the graph
output = graph_app.invoke({"messages": input_messages}, config)
# Get the model response
response = output["messages"][-1].content
return {
"generated_text": response,
"thread_id": request.thread_id
}
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error al generar texto: {str(e)}")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=7860)
Dockerfile
Ahora vemos cómo crear el Dockerfile
Primero indicamos desde qué imagen vamos a partir
FROM python:3.13-slim
Ahora creamos el directorio de trabajo
RUN useradd -m -u 1000 user
WORKDIR /app
Copiamos el archivo con las dependencias e instalamos
COPY --chown=user ./requirements.txt requirements.txt
RUN pip install --no-cache-dir --upgrade -r requirements.txt
Copiamos el resto del código
COPY --chown=user . /app
Exponemos el puerto 7860
EXPOSE 7860
Creamos las variables de entorno
RUN --mount=type=secret,id=HUGGINGFACE_TOKEN,mode=0444,required=true \
test -f /run/secrets/HUGGINGFACE_TOKEN && echo "Secret exists!"
Por último, indicamos el comando para ejecutar la aplicación
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "7860"]
Ahora lo ponemos todo junto
FROM python:3.13-slim
RUN useradd -m -u 1000 user
WORKDIR /app
COPY --chown=user ./requirements.txt requirements.txt
RUN pip install --no-cache-dir --upgrade -r requirements.txt
COPY --chown=user . /app
EXPOSE 7860
RUN --mount=type=secret,id=HUGGINGFACE_TOKEN,mode=0444,required=true \
test -f /run/secrets/HUGGINGFACE_TOKEN && echo "Secret exists!"
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "7860"]
requirements.txt
Creamos el archivo con las dependencias
fastapi
uvicorn
requests
pydantic>=2.0.0
langchain
langchain-huggingface
langchain-core
langgraph > 0.2.27
python-dotenv.2.11README.md
Por último, creamos el archivo README.md con información del espacio y con las intrucciones para HugginFace
---
title: SmolLM2 Backend
emoji: 📊
colorFrom: yellow
colorTo: red
sdk: docker
pinned: false
license: apache-2.0
short_description: Backend of SmolLM2 chat
app_port: 7860
---
# SmolLM2 Backend
This project implements a FastAPI API that uses LangChain and LangGraph to generate text with the Qwen2.5-72B-Instruct model from HuggingFace.
## Configuration
### In HuggingFace Spaces
This project is designed to run in HuggingFace Spaces. To configure it:
1. Create a new Space in HuggingFace with SDK Docker
2. Configure the `HUGGINGFACE_TOKEN` or `HF_TOKEN` environment variable in the Space configuration:
- Go to the "Settings" tab of your Space
- Scroll down to the "Repository secrets" section
- Add a new variable with the name `HUGGINGFACE_TOKEN` and your token as the value
- Save the changes
### Local development
For local development:
1. Clone this repository
2. Create a `.env` file in the project root with your HuggingFace token:
``
HUGGINGFACE_TOKEN=your_token_here
``
3. Install the dependencies:
``
pip install -r requirements.txt
``
## Local execution
``bash
uvicorn app:app --reload
``
The API will be available at `http://localhost:8000`.
## Endpoints
### GET `/`
Welcome endpoint that returns a greeting message.
### POST `/generate`
Endpoint to generate text using the language model.
**Request parameters:**
``json
{
"query": "Your question here",
"thread_id": "optional_thread_identifier"
}
``
**Response:**
``json
{
"generated_text": "Generated text by the model",
"thread_id": "thread identifier"
}
``
## Docker
To run the application in a Docker container:
``bash
# Build the image
docker build -t smollm2-backend .
# Run the container
docker run -p 8000:8000 --env-file .env smollm2-backend
``
## API documentation
The interactive API documentation is available at:
- Swagger UI: `http://localhost:8000/docs`
- ReDoc: `http://localhost:8000/redoc`
Token de HuggingFace
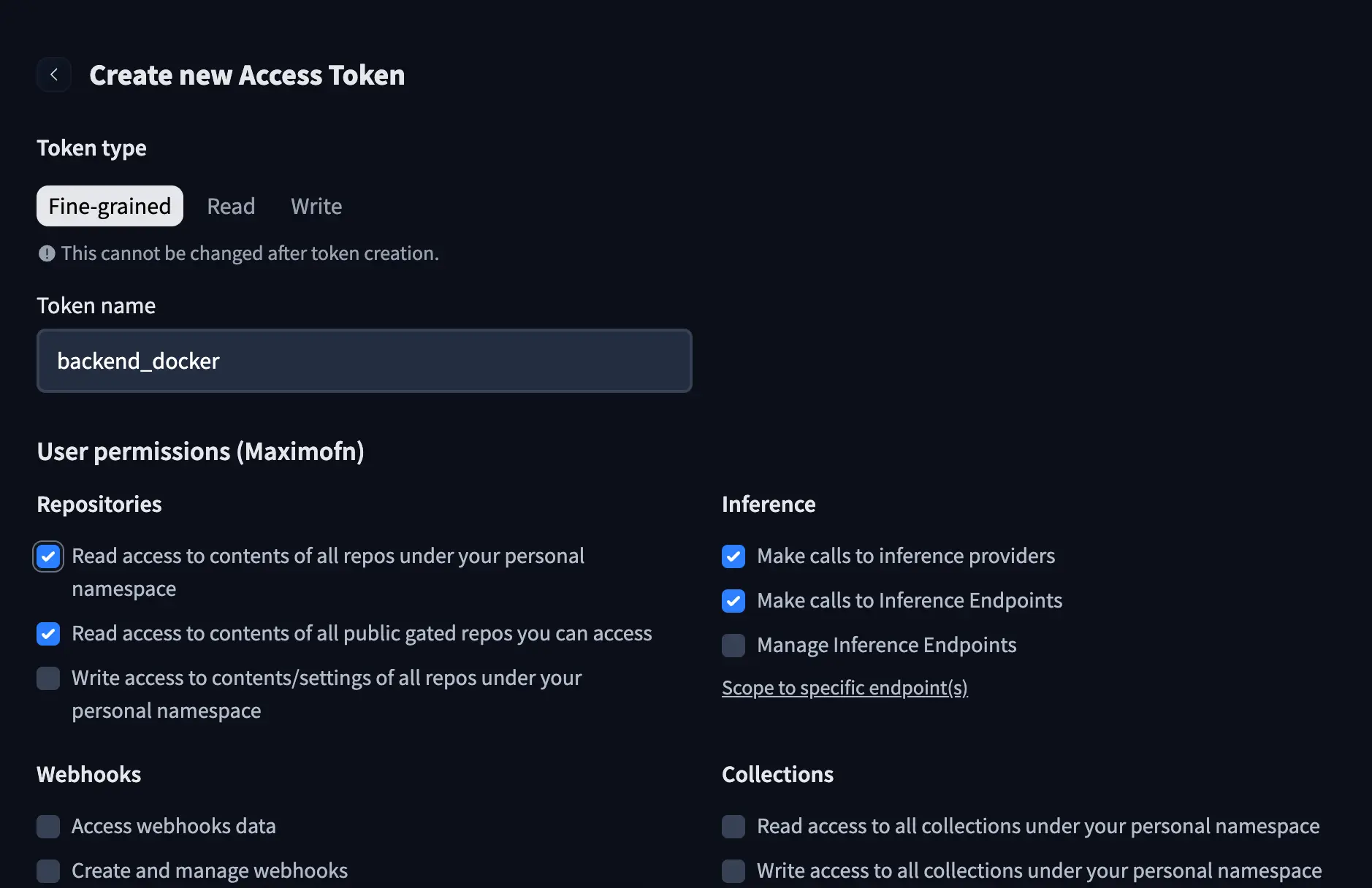
Si te has fijado en el código y en el Dockerfile hemos usado un token de HuggingFace, así que vamos a tener que crear uno. En nuestra cuenta de HuggingFace creamos un nuevo token, le ponemos un nombre y le damos los siguientes permisos:
- Read access to contents of all repos under your personal namespace
- Read access to contents of all repos under your personal namespacev
- Make calls to inference providers
- Make calls to Inference Endpoints
Añadir el token a los secrets del espacio
Ahora que ya tenemos el token, necesitamos añadirlo al espacio. En la parte de arriba de la app, podremos ver un botón llamado Settings, lo pulsamos y podremos ver la sección de configuración del espacio.
Si bajamos, podremos ver una sección en la que podemos añadir Variables y Secrets. En este caso, como estamos añadiendo un token, lo vamos a añadir a los Secrets.
Le ponemos el nombre HUGGINGFACE_TOKEN y el valor del token.
Despliegue
Si hemos clonado el espacio, tenemos que hacer un commit y un push. Si hemos modificado los archivos en HuggingFace, con guardarlos es suficiente.
Así que cuando estén los cambios en HuggingFace, tendremos que esperar unos segundos para que se construya el espacio y podremos usarlo.
En este caso, solo hemos construido un backend, por lo que lo que vamos a ver al entrar al espacio es lo que definimos en el endpoint /
URL del backend
Necesitamos saber la URL del backend para poder hacer llamadas a la API. Para ello, tenemos que pulsar en los tres puntos de la parte superior derecha para ver las opciones
En el menú que se despliega pulsamos en Embed this Spade, se nos abrirá una ventana en la que indica cómo embeber el espacio con un iframe y además nos dará la URL del espacio.
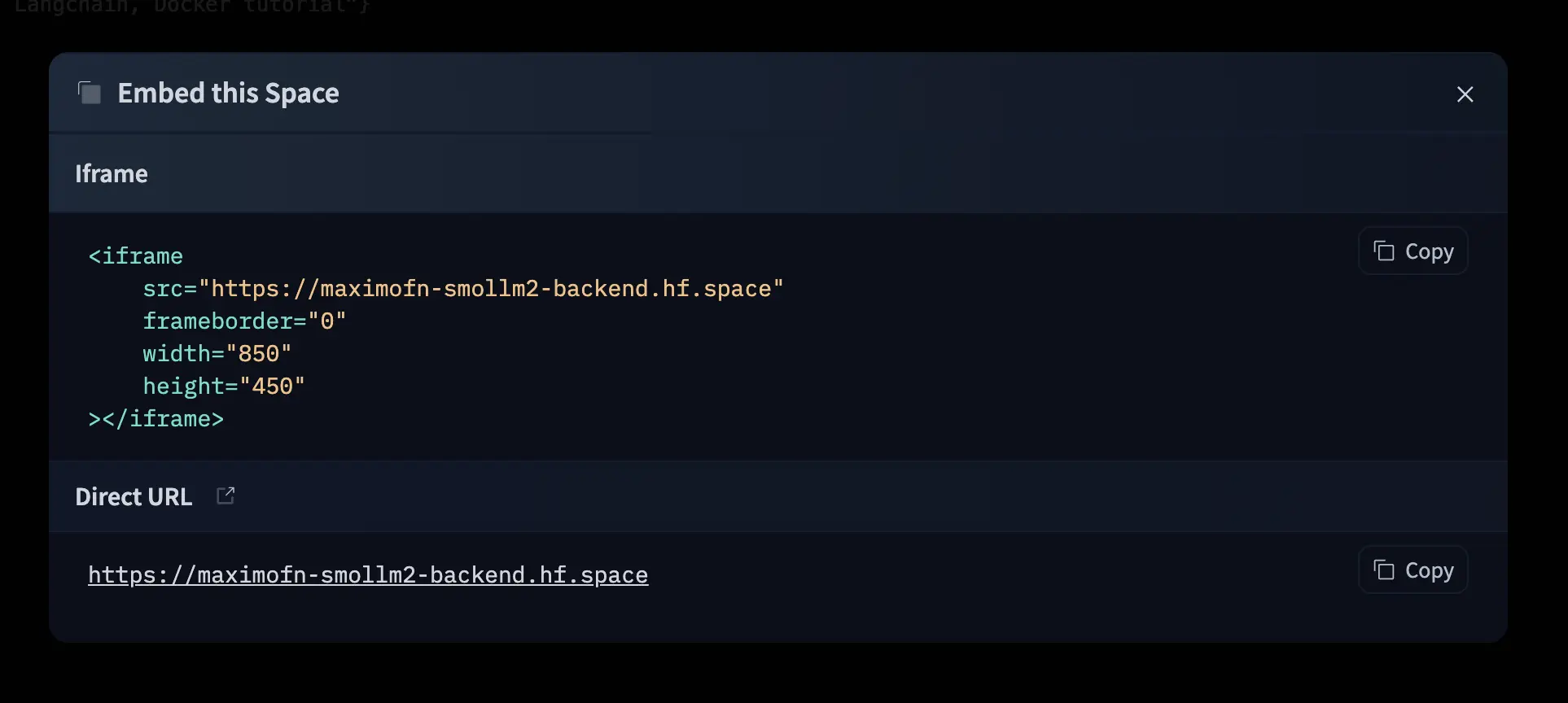
Si ahora nos vamos a esa URL, veremos lo mismo que en el espacio.
Documentación
FastAPI, a parte de ser una API rapidísima, tiene otra gran ventaja, y es que genera documentación de manera automática.
Si añadimos /docs a la URL que vimos antes, podremos ver la documentación de la API con Swagger UI.
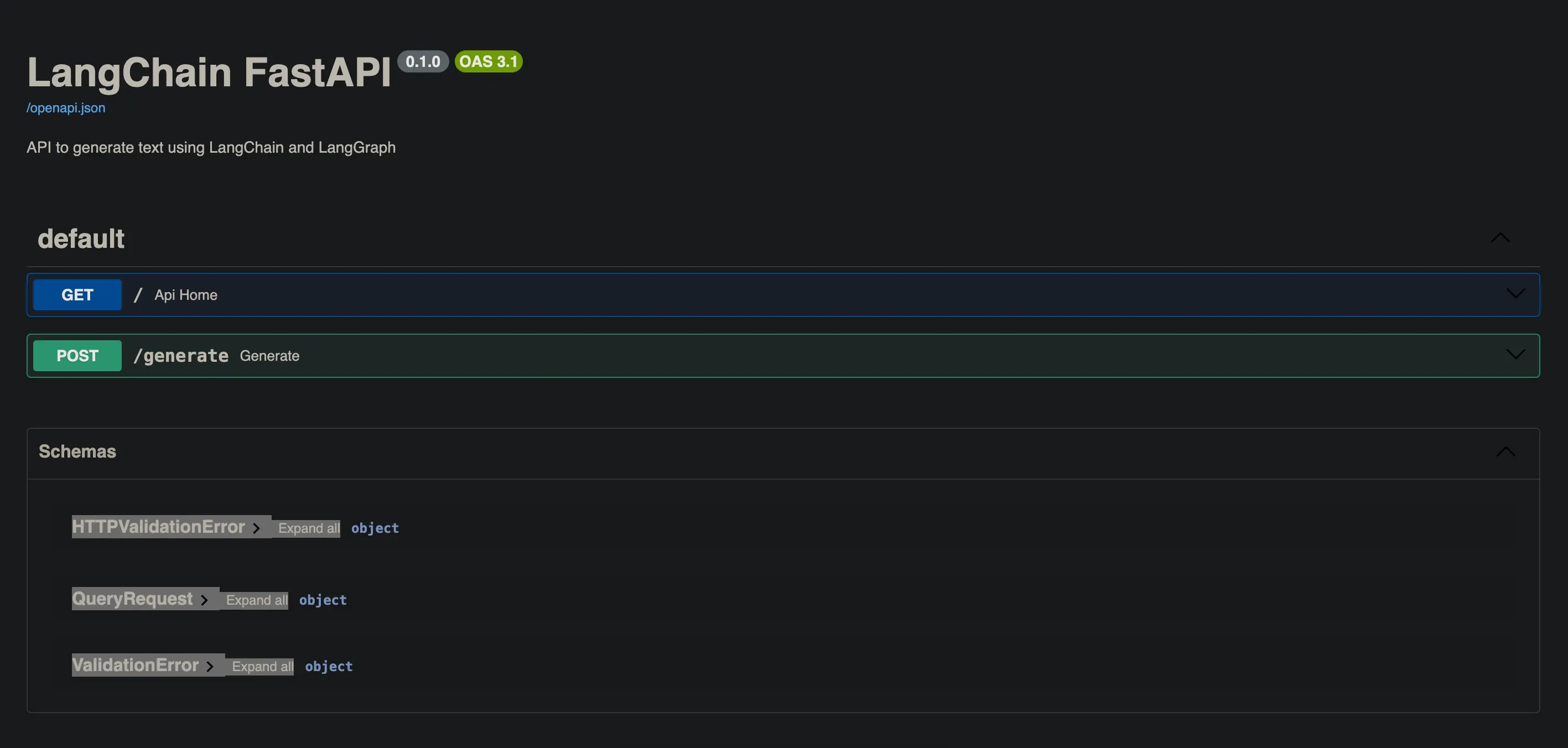
También podemos añadir /redoc a la URL para ver la documentación con ReDoc.
Prueba de la API
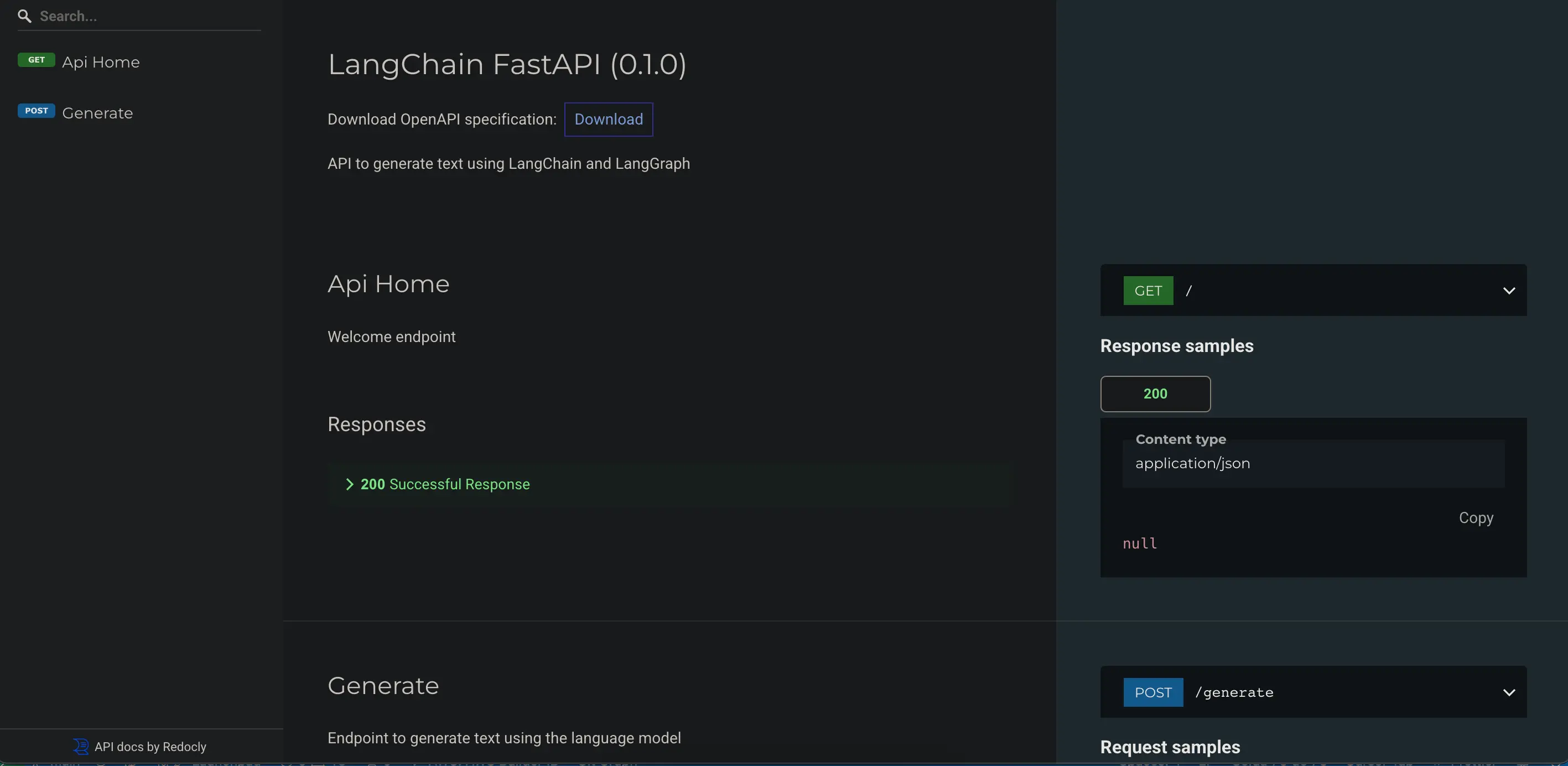
Lo bueno de la documentación Swagger UI es que nos permite probar la API directamente desde el navegador.
Añadimos /docs a la URL que obtuvimos, abrimos el desplegable del endpoint /generate y le damos a Try it out, modificamos el valor de la query y del thread_id y pulsamos en Execute.
En el primer caso voy a poner
- query: Hola, ¿Cómo estás? Soy Máximo
- thread_id: user1
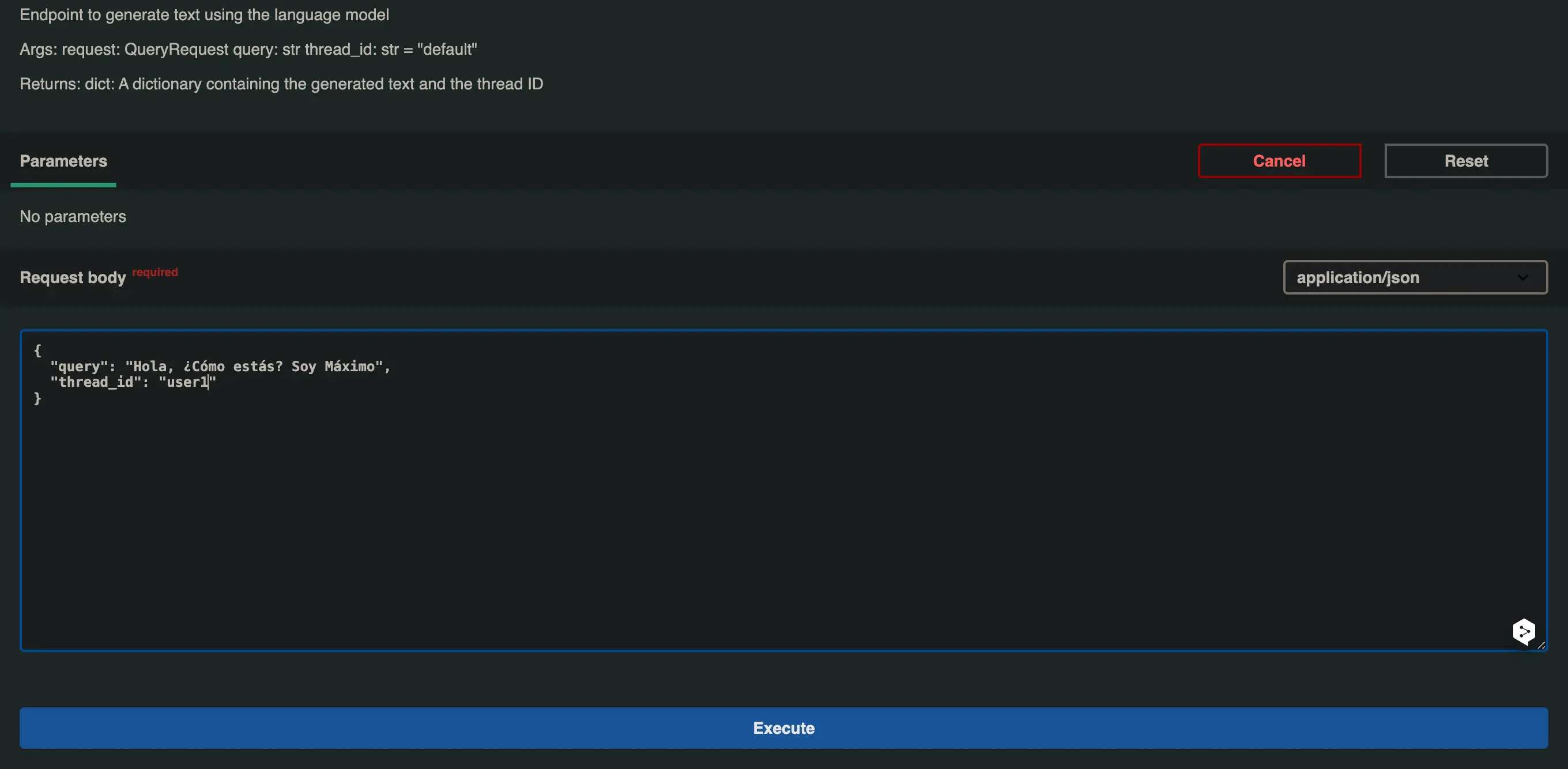
Recibimos la siguiente respuesta ¡Hola Máximo! Estoy muy bien, gracias por preguntar. ¿Cómo estás tú? ¿En qué puedo ayudarte hoy?
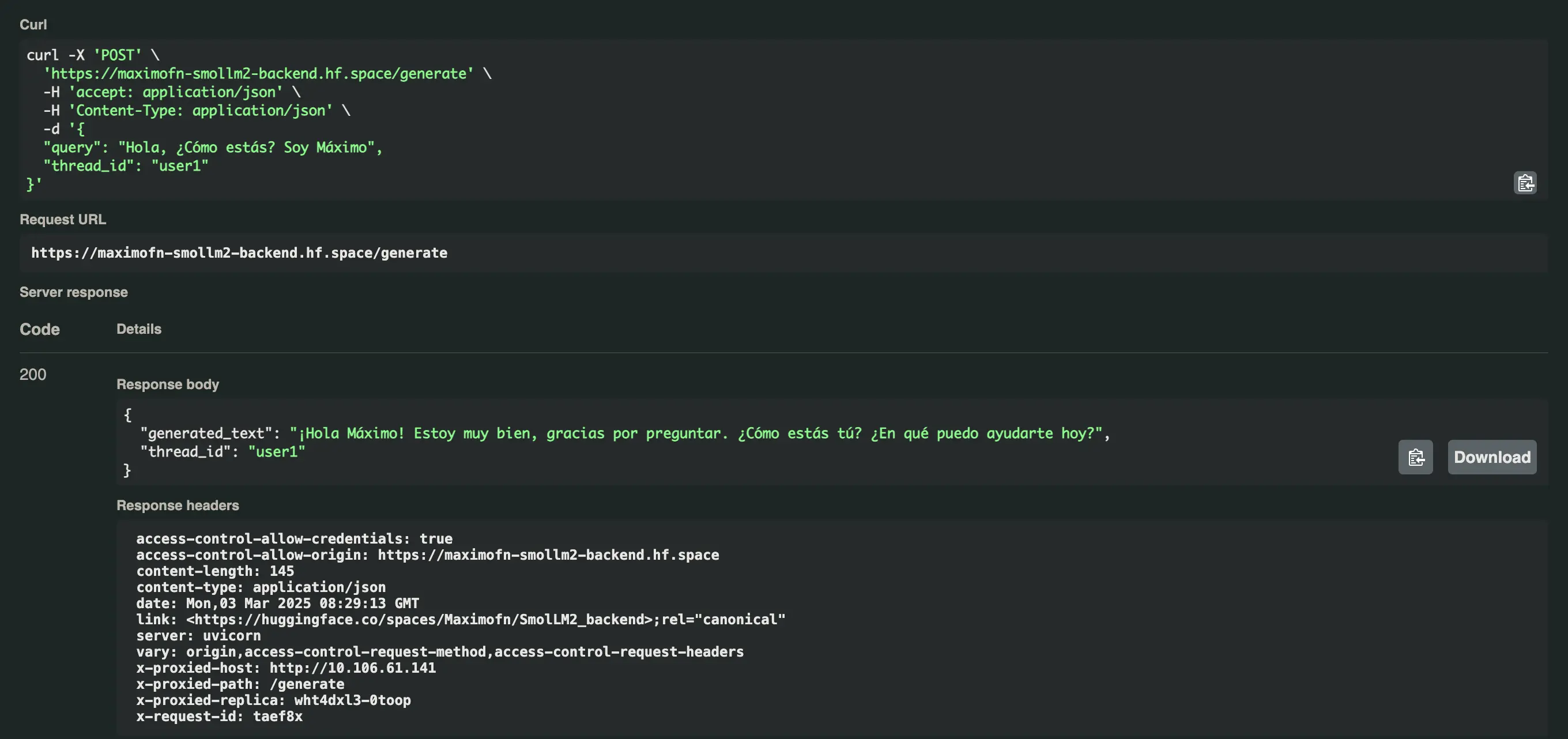
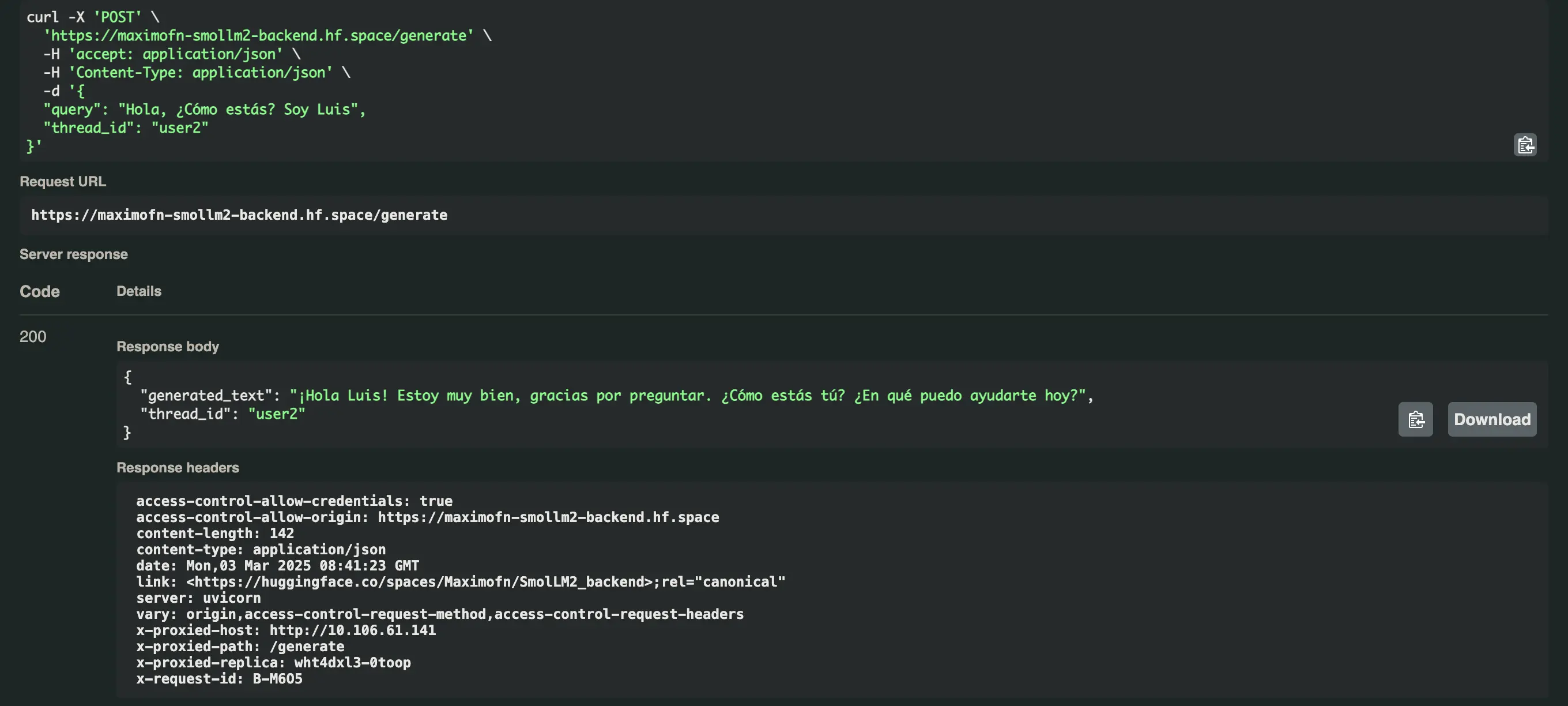
Vamos a probar ahora la misma pregunta, pero con un thread_id diferente, en este caso user2.
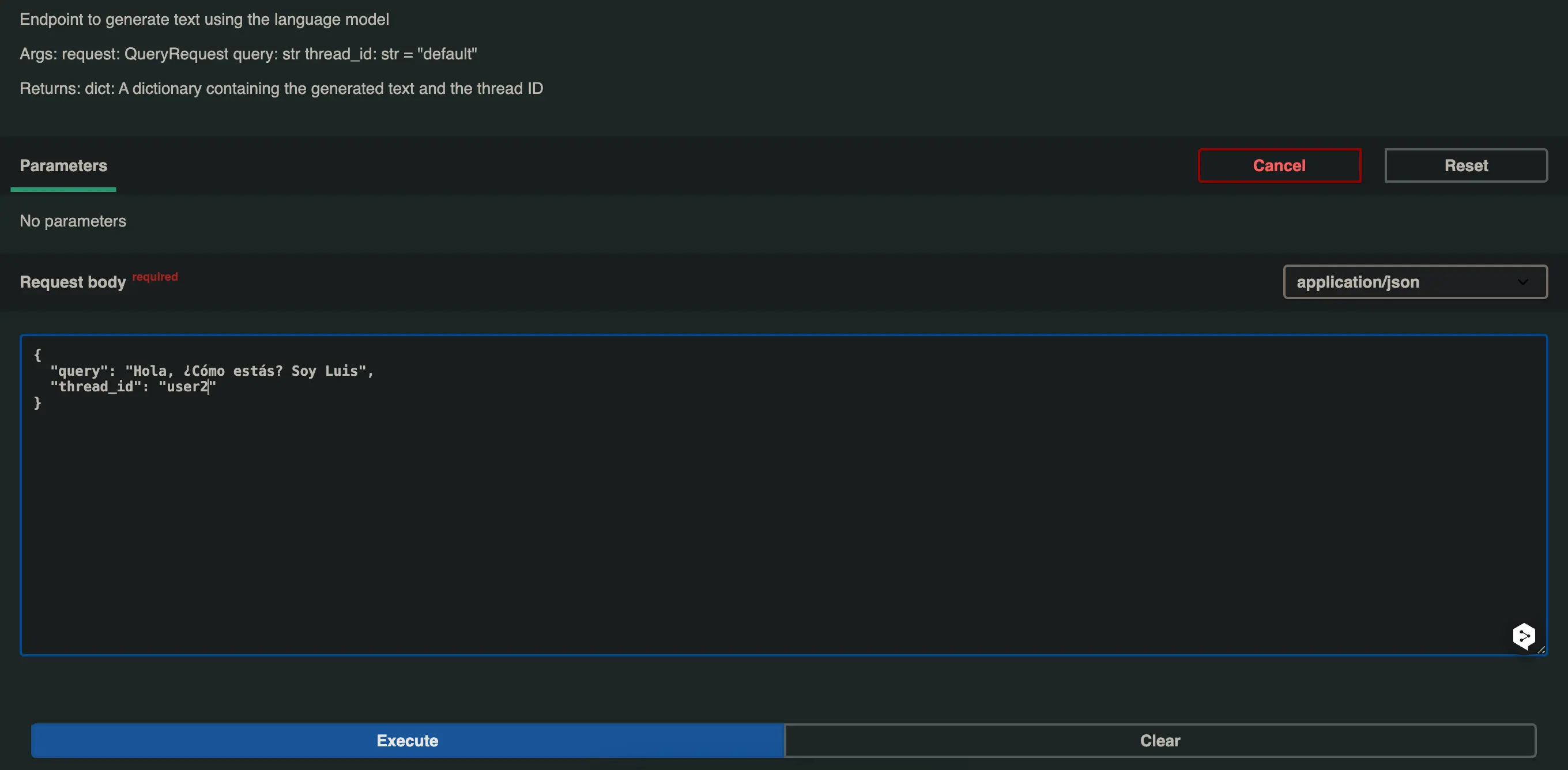
Y nos responde esto ¡Hola Luis! Estoy muy bien, gracias por preguntar. ¿Cómo estás tú? ¿En qué puedo ayudarte hoy?
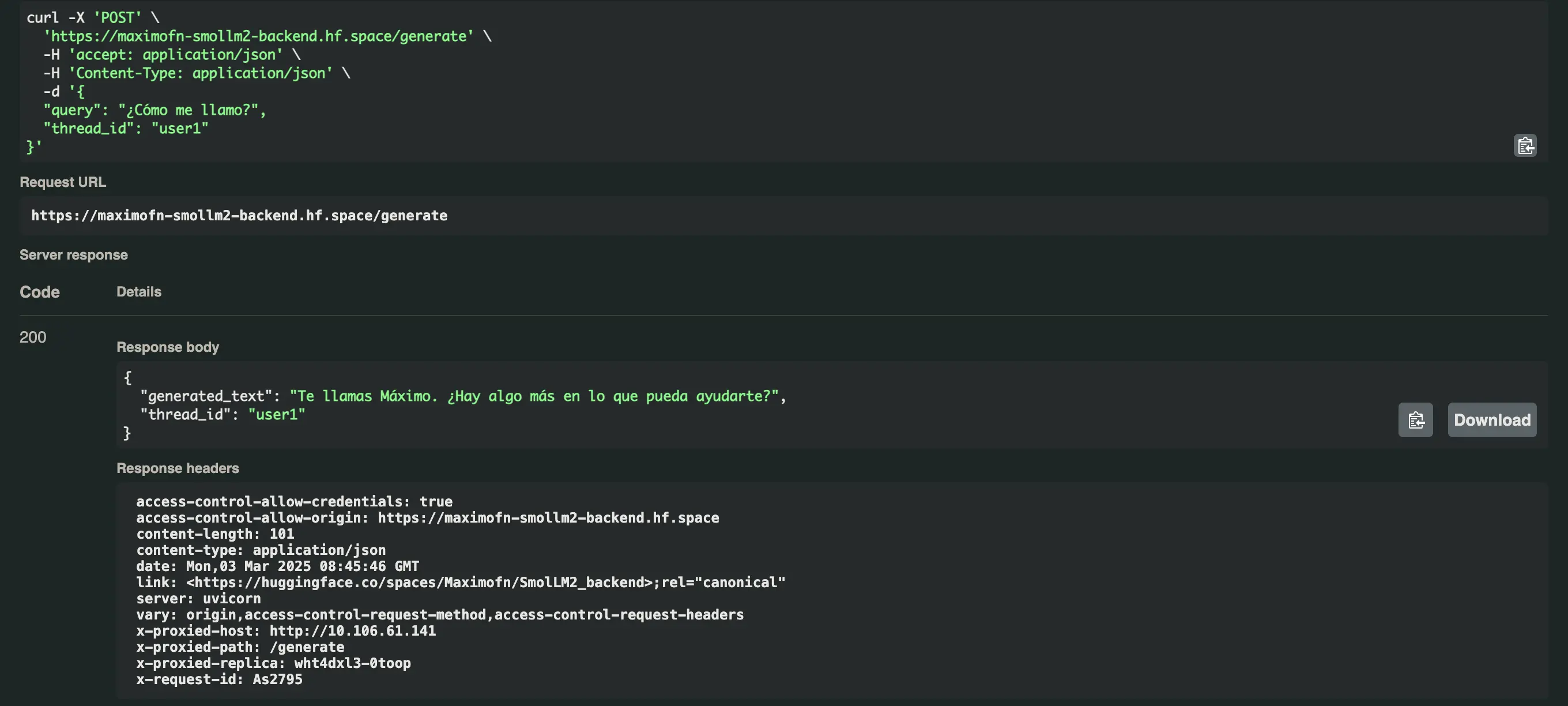
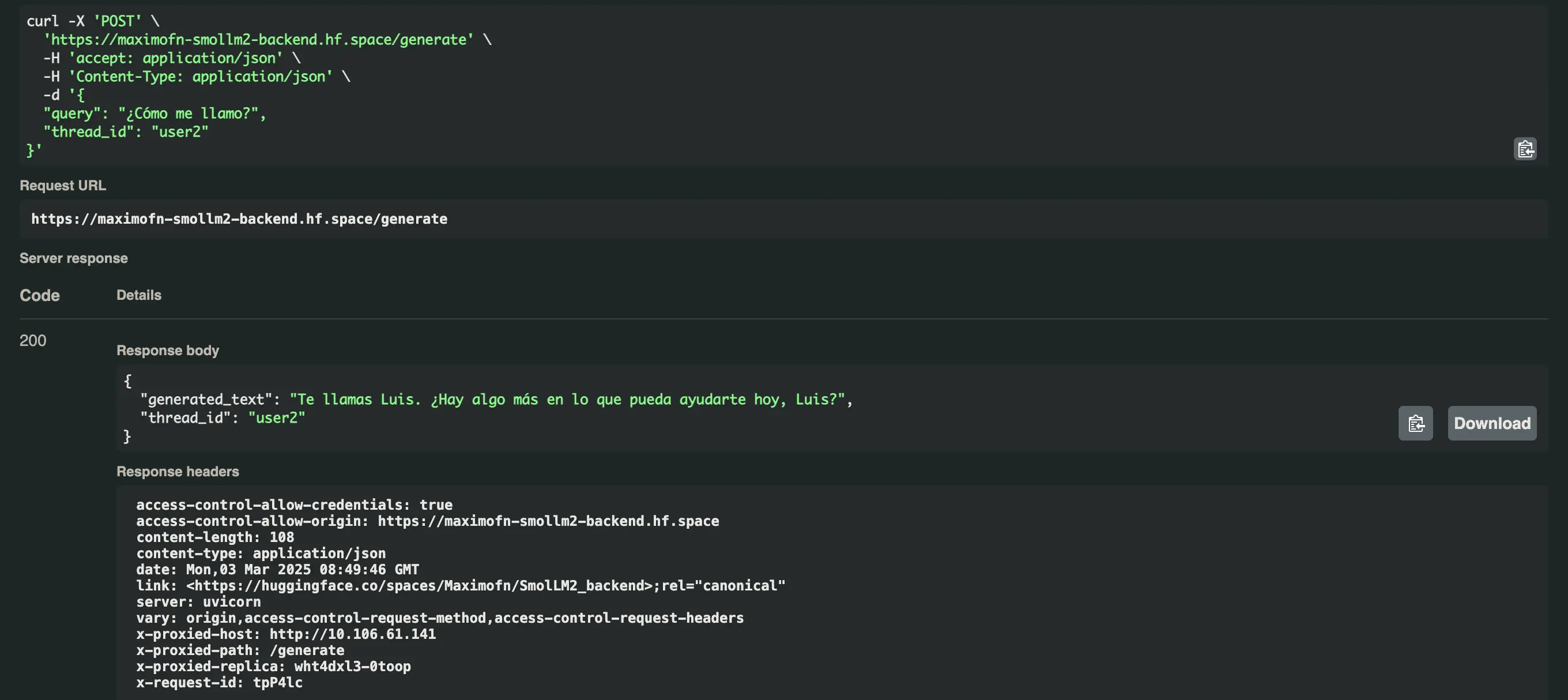
Ahora pedimos nuestro nombre con los dos usuarios y obtenemos esto
- Para el usuario user1:
Te llamas Máximo. ¿Hay algo más en lo que pueda ayudarte? - Para el usuario user2:
Te llamas Luis. ¿Hay algo más en lo que pueda ayudarte hoy, Luis?
Desplegar backend con Gradio y modelo corriendo en el servidor
Los dos backends que hemos creado en realidad no están corriendo un modelo, sino que están haciendo llamadas a Inference Endpoints de HuggingFace. Pero puede que queramos que todo corra en el servidor, incluso el modelo. Puede ser que hayas hecho un fine-tuning de un LLM para tu caso de uso, por lo que ya no puedes hacer llamadas a Inference Endpoints.
Así que vamos a ver cómo modificar el código de los dos backends para correr un modelo en el servidor y no hacer llamadas a Inference Endpoints.
Crear Space
A la hora de crear el space en HuggingFace hacemos lo mismo que antes, creamos un nuevo space, ponemos un nombre y una descripción, seleccionamos Gradio como SDK, seleccionamos el HW en el que lo vamos a desplegar, en mi caso selecciono el HW más básico y gratuito, y seleccionamos si lo hacemos privado o público.
Código
Tenemos que hacer cambios en app.py y en requirements.txt para que en lugar de hacer llamadas a Inference Endpoints, se ejecute el modelo localmente.
app.py
Los cambios que tenemos que hacer son
Importar AutoModelForCausalLM y AutoTokenizer de la librería transformers e importar torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
En lugar de crear un modelo mediante InferenceClient lo creamos con AutoModelForCausalLM y AutoTokenizer
# Cargar el modelo y el tokenizer
model_name = "HuggingFaceTB/SmolLM2-1.7B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
Utilizo HuggingFaceTB/SmolLM2-1.7B-Instruct porque es un modelo bastante capaz de solo 1.7B de parámetros. Como he elegido el HW más básico no puedo usar modelos muy grandes. Tú, si quieres usar un modelo más grande tienes dos opciones, usar el HW gratuito y aceptar que la inferencia va a ser más lenta, o usar un HW más potente, pero de pago.
Modificar la función respond para que construya el prompt con la estructura necesaria por la librería transformers, tokenizar el prompt, hacer la inferencia y destokenizar la respuesta.
def respond(
message,
history: list[tuple[str, str]],
system_message,
max_tokens,
temperature,
top_p,
):
# Construir el prompt con el formato correcto
prompt = f"<|system|>\n{system_message}</s>\n"
for val in history:
if val[0]:
prompt += f"<|user|>\n{val[0]}</s>\n"
if val[1]:
prompt += f"<|assistant|>\n{val[1]}</s>\n"
prompt += f"<|user|>\n{message}</s>\n<|assistant|>\n"
# Tokenizar el prompt
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Generar la respuesta
outputs = model.generate(
**inputs,
max_new_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
# Decodificar la respuesta
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Extraer solo la parte de la respuesta del asistente
response = response.split("<|assistant|>\n")[-1].strip()
yield response
A continuación dejo todo el código
import gradio as gr
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
"""
For more information on `huggingface_hub` Inference API support, please check the docs: https://huggingface.co/docs/huggingface_hub/v0.22.2/en/guides/inference
"""
# Cargar el modelo y el tokenizer
model_name = "HuggingFaceTB/SmolLM2-1.7B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
def respond(
message,
history: list[tuple[str, str]],
system_message,
max_tokens,
temperature,
top_p,
):
# Construir el prompt con el formato correcto
prompt = f"<|system|>\n{system_message}</s>\n"
for val in history:
if val[0]:
prompt += f"<|user|>\n{val[0]}</s>\n"
if val[1]:
prompt += f"<|assistant|>\n{val[1]}</s>\n"
prompt += f"<|user|>\n{message}</s>\n<|assistant|>\n"
# Tokenizar el prompt
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Generar la respuesta
outputs = model.generate(
**inputs,
max_new_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
# Decodificar la respuesta
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Extraer solo la parte de la respuesta del asistente
response = response.split("<|assistant|>\n")[-1].strip()
yield response
"""
For information on how to customize the ChatInterface, peruse the gradio docs: https://www.gradio.app/docs/gradio/chatinterface
"""
demo = gr.ChatInterface(
respond,
additional_inputs=[
gr.Textbox(
value="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",
label="System message"
),
gr.Slider(minimum=1, maximum=2048, value=512, step=1, label="Max new tokens"),
gr.Slider(minimum=0.1, maximum=4.0, value=0.7, step=0.1, label="Temperature"),
gr.Slider(
minimum=0.1,
maximum=1.0,
value=0.95,
step=0.05,
label="Top-p (nucleus sampling)",
),
],
)
if __name__ == "__main__":
demo.launch()
requirements.txt
En este archivo hay que añadir las nuevas librerías que vamos a usar, en este caso transformers, accelerate y torch. El archivo entero quedaría:
huggingface_hub==0.25.2
gradio>=4.0.0
transformers>=4.36.0
torch>=2.0.0
accelerate>=0.25.0Prueba de la API
Desplegamos el space y probamos directamente la API.
from gradio_client import Clientclient = Client("Maximofn/SmolLM2_localModel")result = client.predict(message="Hola, ¿cómo estás? Me llamo Máximo",system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")print(result)
Loaded as API: https://maximofn-smollm2-localmodel.hf.space ✔Hola Máximo, soy su Chatbot amable y estoy funcionando bien. Gracias por tu mensaje, me complace ayudarte hoy en día. ¿Cómo puedo servirte?
Me sorprende lo rápido que responde el modelo estando en un servidor sin GPU.
Desplegar backend con FastAPI, Langchain y Docker y modelo corriendo en el servidor
Ahora hacemos lo mismo que antes, pero con FastAPI, LangChain y Docker.
Crear Space
A la hora de crear el space en HuggingFace hacemos lo mismo que antes, creamos un nuevo space, ponemos un nombre y una descripción, seleccionamos Docker como SDK, seleccionamos el HW en el que lo vamos a desplegar, en mi caso selecciono el HW más básico y gratuito, y seleccionamos si lo hacemos privado o público.
Código
app.py
Ya no importamos InferenceClient y ahora importamos AutoModelForCausalLM y AutoTokenizer de la librería transformers e importamos torch.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
Instanciamos el modelo y el tokenizer con AutoModelForCausalLM y AutoTokenizer.
# Initialize the model and tokenizer
print("Cargando modelo y tokenizer...")
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "HuggingFaceTB/SmolLM2-1.7B-Instruct"
try:
# Load the model in BF16 format for better performance and lower memory usage
tokenizer = AutoTokenizer.from_pretrained(model_name)
if device == "cuda":
print("Usando GPU para el modelo...")
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto",
low_cpu_mem_usage=True
)
else:
print("Usando CPU para el modelo...")
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map={"": device},
torch_dtype=torch.float32
)
print(f"Modelo cargado exitosamente en: {device}")
except Exception as e:
print(f"Error al cargar el modelo: {str(e)}")
raise
Redefinimos la función call_model para que haga la inferencia con el modelo local.
# Define the function that calls the model
def call_model(state: MessagesState):
"""
Call the model with the given messages
Args:
state: MessagesState
Returns:
dict: A dictionary containing the generated text and the thread ID
"""
# Convert LangChain messages to chat format
messages = []
for msg in state["messages"]:
if isinstance(msg, HumanMessage):
messages.append({"role": "user", "content": msg.content})
elif isinstance(msg, AIMessage):
messages.append({"role": "assistant", "content": msg.content})
# Prepare the input using the chat template
input_text = tokenizer.apply_chat_template(messages, tokenize=False)
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
# Generate response
outputs = model.generate(
inputs,
max_new_tokens=512, # Increase the number of tokens for longer responses
temperature=0.7,
top_p=0.9,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
# Decode and clean the response
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Extract only the assistant's response (after the last user message)
response = response.split("Assistant:")[-1].strip()
# Convert the response to LangChain format
ai_message = AIMessage(content=response)
return {"messages": state["messages"] + [ai_message]}
requirements.txt
Tenemos que quitar langchain-huggingface y añadir transformers, accelerate y torch en el archivo requirements.txt. El archivo quedaría:
fastapi
uvicorn
requests
pydantic>=2.0.0
langchain>=0.1.0
langchain-core>=0.1.10
langgraph>=0.2.27
python-dotenv>=1.0.0
transformers>=4.36.0
torch>=2.0.0
accelerate>=0.26.0Dockerfile
Ya no necesitamos tener RUN --mount=type=secret,id=HUGGINGFACE_TOKEN,mode=0444,required=true porque como el modelo va a estar en el servidor y no vamos a hacer llamadas a Inference Endpoints, no necesitamos el token. El archivo quedaría:
FROM python:3.13-slim
RUN useradd -m -u 1000 user
WORKDIR /app
COPY --chown=user ./requirements.txt requirements.txt
RUN pip install --no-cache-dir --upgrade -r requirements.txt
COPY --chown=user . /app
EXPOSE 7860
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "7860"]
Prueba de la API
Desplegamos el space y probamos la API. En este caso lo voy a probar directamente desde python.
import requestsurl = "https://maximofn-smollm2-backend-localmodel.hf.space/generate"data = {"query": "Hola, ¿cómo estás?","thread_id": "user1"}response = requests.post(url, json=data)if response.status_code == 200:result = response.json()print("Respuesta:", result["generated_text"])print("Thread ID:", result["thread_id"])else:print("Error:", response.status_code, response.text)
Respuesta: systemYou are a friendly Chatbot. Always reply in the language in which the user is writing to you.userHola, ¿cómo estás?assistantEstoy bien, gracias por preguntar. Estoy muy emocionado de la semana que viene.Thread ID: user1
Este tarda un poco más que el anterior. En realidad tarda lo normal para un modelo ejecutándose en un servidor sin GPU. Lo raro es cuando lo desplegamos en Gradio. No sé qué hará HuggingFace por detrás, o tal vez ha sido coincidencia
Conclusiones
Hemos visto cómo crear una backend con un LLM, tanto haciendo llamadas al Inference Endpoint de HuggingFace, como haciendo llamadas a un modelo corriendo localmente. Hemos visto cómo hacerlo con Gradio o con FastAPI, Langchain y Docker.
A partir de aquí tienes el conocimiento para poder desplegar tus propios modelos, incluso aunque no sean LLMs, podrían ser modelos multimodales. A partir de aquí puedes hacer lo que quieras.