
En un anterior post sobre tokens, ya vimos la representación mínima de cada palabra. Que corresponde a darle un número a la mínima división de cada palabra.
Sin embargo los transformers y por tanto los LLMs, no representan así la información de las palabras, sino que lo hacen mediante embeddings.
Vamos a ver primero dos formas de representar las palabras, el ordinal encoding y el one hot encoding. Y viendo los problemas de estos dos tipos de representaciones podremos llegar hasta los word embeddings y los sentence embeddings.
Además vamos a ver un ejemplo de cómo entrenar un modelo de word embeddings con la librería gensim.
Y por último veremos cómo usar modelos preentrenados de embeddings con la librería transformers de HuggingFace.
Ordinal encoding
Esta es la manera más básica de representar las palabras dentro de los transformers. Consiste en darle un número a cada palabra, o quedarnos con los números que ya tienen asignados los tokens.
Sin embargo, este tipo de representación tiene dos problemas
- Imaginemos que mesa corresponde al token 3, gato al token 1 y perro al token 2. Se podría llegar a suponer que
mesa = gato + perro, pero no es así. No existe esa relación entre esas palabras. Incluso podríamos pensar que adjudicando los tokens correctos sí podría llegar a darse este tipo de relaciones. Sin embargo, este pensamiento se viene abajo con las palabras que tienen más de un significado, como por ejemplo la palabrabanco
- El segundo problema es que las redes neuronales internamente hacen muchos cálculos numéricos, por lo que podría darse el caso de que si mesa tiene el token 3, tenga internamente más importancia que la palabra gato que tiene el token 1.
De modo que este tipo de representación de las palabras se puede descartar muy rápidamente
One hot encoding
Aquí lo que se hace es usar vectores de N dimensiones. Por ejemplo vimos que OpenAI tiene un vocabulario de 100277 tokens distintos. Por lo que si usamos one hot encoding, cada palabra se representaría con un vector de 100277 dimensiones.
Sin embargo, el one hot encoding tiene otros dos grandes problemas
- No tiene en cuenta la relación entre las palabras. Por lo que si tenemos dos palabras que son sinónimos, como por ejemplo
gatoyfelino, tendríamos dos vectores distintos para representarlas.
En el lenguaje la relación entre las palabras es muy importante, y no tener en cuenta esta relación es un gran problema.
- El segundo problema es que los vectores son muy grandes. Si tenemos un vocabulario de
100277tokens, cada palabra se representaría con un vector de100277dimensiones. Esto hace que los vectores sean muy grandes y que los cálculos sean muy costosos. Además, estos vectores van a ser todo ceros, excepto en la posición que corresponda al token de la palabra. Por lo que la mayoría de los cálculos van a ser multiplicaciones por cero, que son cálculos que no aportan nada. Así que vamos a tener un montón de memoria asignada a vectores en los que solo se tiene un1en una posición determinada.
Word embeddings
Con los word embeddings se intenta solucionar los problemas de los dos tipos de representaciones anteriores. Para ello se usan vectores de N dimensiones, pero en este caso no se usan vectores de 100277 dimensiones, sino que se usan vectores de muchas menos dimensiones. Por ejemplo veremos que OpenAI usa 1536 dimensiones.
Cada una de las dimensiones de estos vectores representan una característica de la palabra. Por ejemplo una de las dimensiones podría representar si la palabra es un verbo o un sustantivo. Otra dimensión podría representar si la palabra es un animal o no. Otra dimensión podría representar si la palabra es un nombre propio o no. Y así sucesivamente.
Sin embargo estas características no se definen a mano, sino que se aprenden de forma automática. Durante el entrenamiento de los transformers, se van ajustando los valores de cada una de las dimensiones de los vectores, de modo que se aprenden las características de cada una de las palabras.
Al hacer que cada una de las dimensiones de las palabras represente una característica de la palabra, se consigue que las palabras que tengan características similares, tengan vectores similares. Por ejemplo las palabras gato y felino tendrán vectores muy similares, ya que ambas son animales. Y las palabras mesa y silla tendrán vectores similares, ya que ambas son muebles.
En la siguiente imagen podemos ver una representación de 3 dimensiones de palabras, y podemos ver que todas las palabras relacionadas con school están cerca, todas las palabras relacionadas con food están cerca y todas las palabras relacionadas con ball están cerca.
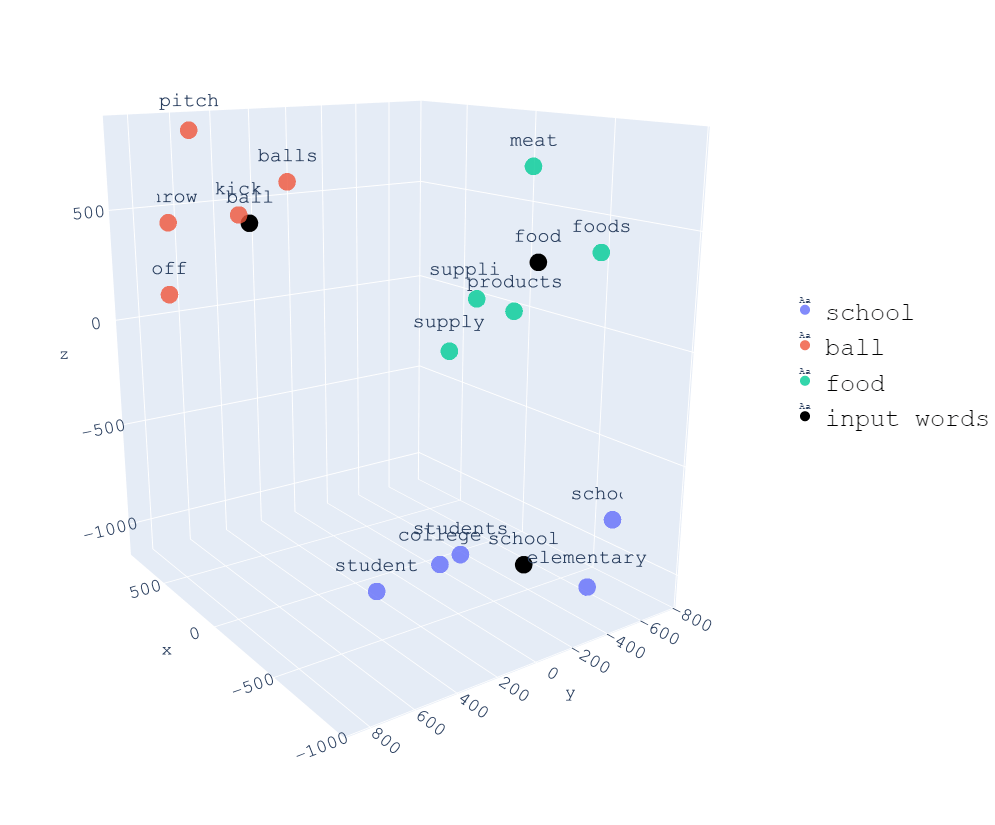
Tener que cada una de las dimensiones de los vectores represente una característica de la palabra, consigue que podamos hacer operaciones con palabras. Por ejemplo si a la palabra rey se le resta la palabra hombre y se le suma la palabra mujer, obtenemos una palabra muy parecida a la palabra reina. Más adelante lo comprobaremos con un ejemplo
Similitud entre palabras
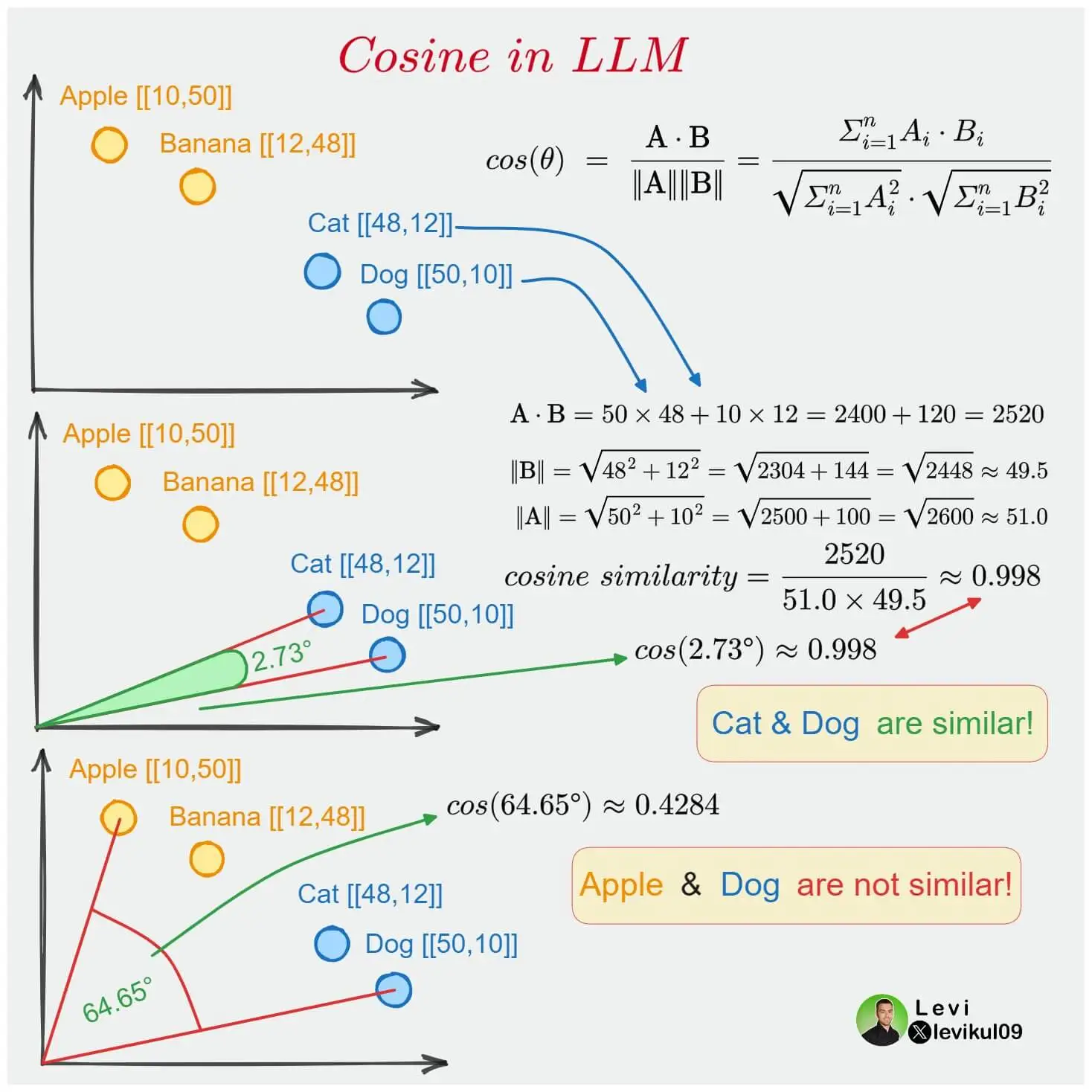
Como cada una de las palabras se representa mediante un vector de N dimensiones, podemos calcular la similitud entre dos palabras. Para ello se usa la función de similitud del coseno o cosine similarity.
Si dos palabras están cercanas en el espacio vectorial, quiere decir que el álgulo que hay entre sus vectores es pequeño, por lo que su coseno es cercano a 1. Si hay un ángulo de 90 grados entre los vectores, el coseno es 0, es decir que no hay similitud entre las palabras. Y si hay un ángulo de 180 grados entre los vectores, el coseno es -1, es decir que las palabras son opuestas.
Ejemplo con embeddings de OpenAI
Ahora que sabemos lo que son los embeddings, veamos unos ejemplos con los embeddings que nos proporciona la API de OpenAI.
Para ello, primero tenemos que tener instalado el paquete de OpenAI
pip install openaiImportamos las librerías necesarias
from openai import OpenAIimport torchfrom torch.nn.functional import cosine_similarityCopied
Usamos una API key de OpenAI. Para ello, nos dirigimos a la página de OpenAI, y nos registramos. Una vez registrados, nos dirigimos a la sección de API Keys, y creamos una nueva API Key.
api_key = "Pon aquí tu API key"Copied
Seleccionamos que modelo de embeddings queremos usar. En este caso vamos a usar text-embedding-ada-002 que es el que recomienda OpenAI en su documentación de embeddings.
model_openai = "text-embedding-ada-002"Copied
Creamos un cliente de la API
client_openai = OpenAI(api_key=api_key, organization=None)Copied
Vamos a ver cómo son los embeddings de la palabra Rey
word = "Rey"embedding_openai = torch.Tensor(client_openai.embeddings.create(input=word, model=model_openai).data[0].embedding)embedding_openai.shape, embedding_openaiCopied
(torch.Size([1536]),tensor([-0.0103, -0.0005, -0.0189, ..., -0.0009, -0.0226, 0.0045]))
Como vemos, obtenemos un vector de 1536 dimensiones
Ejemplo con embeddings de HuggingFace
Como la generación de embeddings de OpenAI es de pago, vamos a ver cómo usar los embeddings de HuggingFace, que son gratuitos. Para ello primero tenemos que asegurarnos de tener instalada la librería sentence-transformers
pip install -U sentence-transformersY ahora comenzamos a generar los embeddings de las palabras
Primero importamos la librería
from sentence_transformers import SentenceTransformerCopied
Ahora creamos un modelo de embeddings de HuggingFace. Usamos paraphrase-MiniLM-L6-v2 porque es un modelo pequeño y rápido, pero que da buenos resultados, y ahora para nuestro ejemplo nos basta.
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')Copied
Y ya podemos generar los embeddings de las palabras
sentence = ['Rey']embedding_huggingface = model.encode(sentence)embedding_huggingface.shape, embedding_huggingface[0]Copied
((1, 384),array([ 4.99837071e-01, -7.60397986e-02, 5.47384083e-01, 1.89465046e-01,-3.21713984e-01, -1.01025246e-01, 6.44087136e-01, 4.91398573e-01,3.73571329e-02, -2.77234882e-01, 4.34713453e-01, -1.06284058e+00,2.44114518e-01, 8.98794234e-01, 4.74923879e-01, -7.48904228e-01,2.84665376e-01, -1.75070837e-01, 5.92192829e-01, -1.02512836e-02,9.45721626e-01, 2.43777707e-01, 3.91995460e-01, 3.35530996e-01,-4.58333105e-01, 1.18869759e-01, 5.31717360e-01, -1.21750660e-01,-5.45580745e-01, -7.63889611e-01, -3.19075316e-01, 2.55386919e-01,-4.06407446e-01, -8.99556637e-01, 6.34190366e-02, -2.96231866e-01,-1.22994244e-01, 7.44934231e-02, -4.49327320e-01, -2.71379113e-01,-3.88012260e-01, -2.82730222e-01, 2.50365853e-01, 3.06314558e-01,5.01561277e-02, -5.73592126e-01, -4.93096076e-02, -2.54629493e-01,4.45663840e-01, -1.54654181e-03, 1.85357735e-01, 2.49421135e-01,7.80077875e-01, -2.99735814e-01, 7.34686375e-01, 9.35385004e-02,-8.64403173e-02, 5.90056717e-01, 9.62065995e-01, -3.89911681e-02,4.52635378e-01, 1.10802782e+00, -4.28262979e-01, 8.98583114e-01,-2.79768258e-01, -7.25559890e-01, 4.38431054e-01, 6.08255446e-01,-1.06222546e+00, 1.86217821e-03, 5.23232877e-01, -5.59782684e-01,1.08870542e+00, -1.29855171e-01, -1.34669527e-01, 4.24595959e-02,2.99118191e-01, -2.53481418e-01, -1.82368979e-01, 9.74772453e-01,-7.66527832e-01, 2.02146843e-01, -9.27186012e-01, -3.72025579e-01,2.51360565e-01, 3.66043419e-01, 3.58169287e-01, -5.50914466e-01,3.87659878e-01, 2.67650932e-01, -1.30100116e-01, -9.08647776e-02,2.58671075e-01, -4.44935560e-01, -1.43231079e-01, -2.83272982e-01,7.21463636e-02, 1.98998764e-01, -9.47986841e-02, 1.74529219e+00,1.71559617e-01, 5.96294463e-01, 1.38505893e-02, 3.90956283e-01,3.46427560e-01, 2.63105750e-01, 2.64972121e-01, -2.67196923e-01,7.54366294e-02, 9.39224422e-01, 3.35206270e-01, -1.99105024e-01,-4.06340271e-01, 3.83643419e-01, 4.37904626e-01, 8.92579079e-01,-5.86432815e-01, -2.59302586e-01, -6.39415443e-01, 1.21703267e-01,6.44594133e-01, 2.56335083e-02, 5.53315282e-02, 5.85618019e-01,1.03075497e-01, -4.17360187e-01, 5.00189543e-01, 4.23062295e-01,-7.62073815e-01, -4.36184794e-01, -4.13090199e-01, -2.14746520e-01,3.76077414e-01, -1.51846036e-02, -6.51694953e-01, 2.05930993e-01,-3.73996288e-01, 1.14034235e-01, -7.40544260e-01, 1.98710993e-01,-6.66027904e-01, 3.00016254e-01, -4.03109461e-01, 1.85078502e-01,-3.27183425e-01, 4.19003010e-01, 1.16863050e-01, -4.33366179e-01,3.62291127e-01, 6.25310719e-01, -3.34749371e-01, 3.18448655e-02,-9.09660235e-02, 3.58690947e-01, 1.23402506e-01, -5.08333087e-01,4.18513209e-01, 5.83032072e-01, -8.37822199e-01, -1.52947128e-01,5.07765234e-01, -2.90990144e-01, -2.56464798e-02, 5.69117546e-01,-5.43118417e-01, -3.27799052e-01, -1.70862004e-01, 4.14014012e-01,4.74694878e-01, 5.15708327e-01, 3.21234539e-02, 1.55380607e-01,-3.21141332e-01, -1.72114551e-01, 6.43211603e-01, -3.89207341e-02,-2.29103401e-01, 4.13877398e-01, -9.22305062e-02, -4.54976231e-01,-1.50242126e+00, -2.81573564e-01, 1.70057654e-01, 4.53076512e-01,-4.25060362e-01, -1.33391351e-01, 5.40394569e-03, 3.71117502e-01,-4.29107875e-01, 1.35897202e-02, 2.44936779e-01, 1.04574718e-01,-3.65612388e-01, 4.33572650e-01, -4.09719855e-01, -2.95067448e-02,1.26362443e-02, -7.43583977e-01, -7.35885441e-01, -1.35508239e-01,-2.12558493e-01, -5.46157181e-01, 7.55161867e-02, -3.57991695e-01,-1.20607555e-01, 5.53125329e-02, -3.23110700e-01, 4.88573104e-01,-1.07487953e+00, 1.72190830e-01, 8.48749802e-02, 5.73584400e-02,3.06147277e-01, 3.26699704e-01, 5.09487510e-01, -2.60940105e-01,-2.85459042e-01, 3.15197736e-01, -8.84049162e-02, -2.14854136e-01,4.04228538e-01, -3.53874594e-01, 3.30587216e-02, -2.04278827e-01,4.45132256e-01, -4.05272096e-01, 9.07981098e-01, -1.70708492e-01,3.62848401e-01, -3.17223936e-01, 1.53909430e-01, 7.24429131e-01,2.27339968e-01, -1.16330147e+00, -9.58504915e-01, 4.87008452e-01,-2.30886355e-01, -1.40117988e-01, 7.84571916e-02, -2.93157458e-01,1.00778294e+00, 1.34625390e-01, -4.66320179e-02, 6.51122704e-02,-1.50451362e-02, -2.15500608e-01, -2.42915586e-01, -3.21900517e-01,-2.94186682e-01, 4.71027017e-01, 1.56058431e-01, 1.30854800e-01,-2.84257025e-01, -1.44421116e-01, -7.09840000e-01, -1.80235609e-01,-8.30230191e-02, 9.08326149e-01, -8.22497830e-02, 1.46948382e-01,-1.41326815e-01, 3.81170362e-01, -6.37023628e-01, 1.70148894e-01,-1.00046806e-01, 5.70729785e-02, -1.09820545e+00, -1.03613675e-01,-6.21219516e-01, 4.55532551e-01, 1.86942443e-01, -2.04409719e-01,7.81394243e-01, -7.88963258e-01, 2.19068691e-01, -3.62780124e-01,-3.41522694e-01, -1.73794985e-01, -4.00943428e-01, 5.01900315e-01,4.53949839e-01, 1.03774257e-01, -1.66873619e-01, -4.63893116e-02,-1.78147718e-01, 4.85655308e-01, -3.02978605e-02, -5.67060888e-01,-4.68107373e-01, -6.57559693e-01, -5.02855539e-01, -1.94635347e-01,-9.58659649e-01, -4.97986436e-01, 1.33874401e-01, 3.09395105e-01,-4.52993363e-01, 7.43827343e-01, -1.87271550e-01, -6.11483693e-01,-1.08927953e+00, -2.30332208e-03, 2.11169615e-01, -3.46892715e-01,-3.32458824e-01, 2.07640216e-01, -4.10387546e-01, 3.12181324e-01,3.69687408e-01, 8.62928331e-01, 2.40735337e-01, -3.65841389e-02,6.84210837e-01, 3.45884450e-02, 5.63964128e-01, 2.39361122e-01,3.10872793e-01, -6.34638309e-01, -9.07931089e-01, -6.35836497e-02,2.20288679e-01, 2.59186536e-01, -4.45540816e-01, 6.33085072e-01,-1.97424471e-01, 7.51152515e-01, -2.68558711e-01, -4.39288855e-01,4.13556695e-01, -1.89288303e-01, 5.81856608e-01, 4.75860722e-02,1.60344616e-01, -2.96180040e-01, 2.91323394e-01, 1.34404674e-01,-1.22037649e-01, 4.19363379e-02, -3.87936801e-01, -9.25336123e-01,-5.28307915e-01, -1.74257740e-01, -1.52818128e-01, 4.31716293e-02,-2.12064430e-01, 2.98252910e-01, 9.86064151e-02, 3.84781063e-02,6.68018535e-02, -2.29525566e-01, -8.20755959e-03, 5.17108142e-01,-6.66776478e-01, -1.38897672e-01, 4.68370765e-01, -2.14766636e-01,2.43549764e-01, 2.25854263e-01, -1.92763060e-02, 2.78505355e-01,3.39088053e-01, -9.69757214e-02, -2.71263003e-01, 1.05703615e-01,1.14365645e-01, 4.16649908e-01, 4.18699026e-01, -1.76222697e-01,-2.08620593e-01, -5.79392374e-01, -1.68948188e-01, -1.77841976e-01,5.69338985e-02, 2.12916449e-01, 4.24367547e-01, -7.13860095e-02,8.28932896e-02, -2.40542665e-01, -5.94049037e-01, 4.09415931e-01,1.01326215e+00, -5.71239054e-01, 4.35258061e-01, -3.64619821e-01],dtype=float32))
Como vemos obtenemos un vector de 384 dimensiones. En este caso se obtiene un vector de esta dimensión porque se ha usado el modelo paraphrase-MiniLM-L6-v2. Si usamos otro modelo, obtendremos vectores de otra dimensión.
Operaciones con palabras
Vamos a obtener los embeddings de las palabras rey, hombre, mujer y reina
embedding_openai_rey = torch.Tensor(client_openai.embeddings.create(input="rey", model=model_openai).data[0].embedding)embedding_openai_hombre = torch.Tensor(client_openai.embeddings.create(input="hombre", model=model_openai).data[0].embedding)embedding_openai_mujer = torch.Tensor(client_openai.embeddings.create(input="mujer", model=model_openai).data[0].embedding)embedding_openai_reina = torch.Tensor(client_openai.embeddings.create(input="reina", model=model_openai).data[0].embedding)Copied
embedding_openai_reina.shape, embedding_openai_reinaCopied
(torch.Size([1536]),tensor([-0.0110, -0.0084, -0.0115, ..., 0.0082, -0.0096, -0.0024]))
Vamos a obtener el embedding resultante de restarle a rey el embedding de hombre y sumarle el embedding de mujer
embedding_openai = embedding_openai_rey - embedding_openai_hombre + embedding_openai_mujerCopied
embedding_openai.shape, embedding_openaiCopied
(torch.Size([1536]),tensor([-0.0226, -0.0323, 0.0017, ..., 0.0014, -0.0290, -0.0188]))
Por último comparamos el resultado obtenido con el embedding de reina. Para ello usamos la función de cosine_similarity que nos proporciona la librería pytorch
similarity_openai = cosine_similarity(embedding_openai.unsqueeze(0), embedding_openai_reina.unsqueeze(0)).item()print(f"similarity_openai: {similarity_openai}")Copied
similarity_openai: 0.7564167976379395
Como vemos es un valor muy cercano a 1, por lo que podemos decir que el resultado obtenido es muy parecido al embedding de reina
Si usamos palabras en inglés, obtenemos un resultado más cercano a 1
embedding_openai_rey = torch.Tensor(client_openai.embeddings.create(input="king", model=model_openai).data[0].embedding)embedding_openai_hombre = torch.Tensor(client_openai.embeddings.create(input="man", model=model_openai).data[0].embedding)embedding_openai_mujer = torch.Tensor(client_openai.embeddings.create(input="woman", model=model_openai).data[0].embedding)embedding_openai_reina = torch.Tensor(client_openai.embeddings.create(input="queen", model=model_openai).data[0].embedding)Copied
embedding_openai = embedding_openai_rey - embedding_openai_hombre + embedding_openai_mujerCopied
similarity_openai = cosine_similarity(embedding_openai.unsqueeze(0), embedding_openai_reina.unsqueeze(0))print(f"similarity_openai: {similarity_openai}")Copied
similarity_openai: tensor([0.8849])
Esto es normal, ya que el modelo de OpenAI ha sido entrenado con más textos en inglés que en español
Tipos de Word Embeddings
Existen varios tipos de word embeddings, y cada uno de ellos tiene sus ventajas e inconvenientes. Vamos a ver los más importantes
- Word2Vec
- GloVe
- FastText
- BERT
- GPT-2
Word2Vec
Word2Vec es un algoritmo que se usa para crear word embeddings. Este algoritmo fue creado por Google en 2013, y es uno de los algoritmos más usados para crear word embeddings.
Tiene dos variantes, CBOW y Skip-gram. CBOW es más rápido de entrenar, mientras que Skip-gram es más preciso. Vamos a ver cómo funciona cada uno de ellos
CBOW
CBOW o Continuous Bag of Words es un algoritmo que se usa para predecir una palabra a partir de las palabras que la rodean. Por ejemplo si tenemos la frase El gato es un animal, el algoritmo intentará predecir la palabra gato a partir de las palabras que la rodean, en este caso El, es, un y animal.
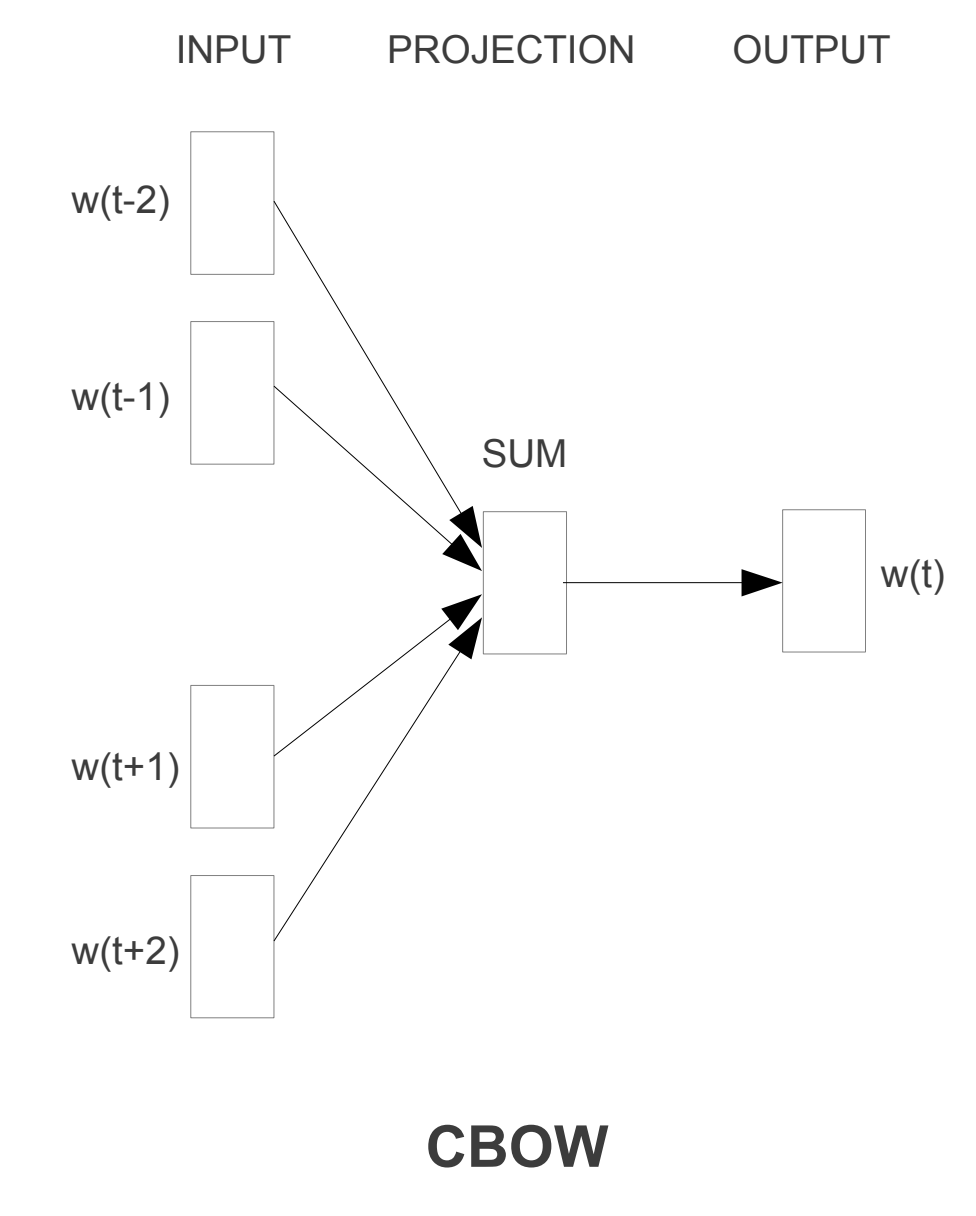
En esta arquitectura, el modelo predice cuál es la palabra más probable en el contexto dado. Por lo tanto, las palabras que tienen la misma probabilidad de aparecer se consideran similares y, por lo tanto, se acercan más en el espacio dimensional.
Supongamos que en una oración reemplazamos barco con bote, entonces el modelo predice la probabilidad para ambos y si resulta ser similar entonces podemos considerar que las palabras son similares.
Skip-gram
Skip-gram o Skip-gram with Negative Sampling es un algoritmo que se usa para predecir las palabras que rodean a una palabra. Por ejemplo si tenemos la frase El gato es un animal, el algoritmo intentará predecir las palabras El, es, un y animal a partir de la palabra gato.
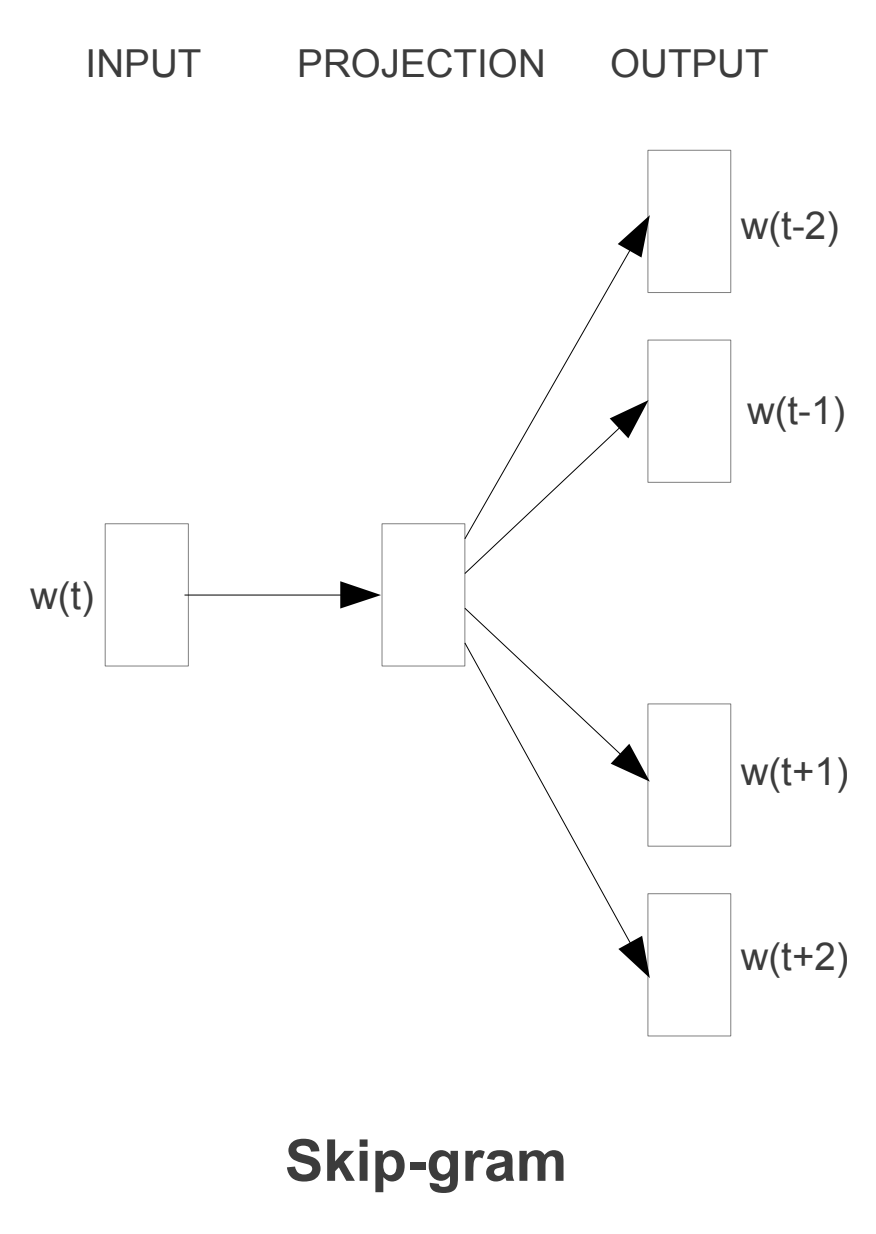
Esta arquitectura es similar a la de CBOW, pero en cambio el modelo funciona al revés. El modelo predice el contexto usando la palabra dada. Por lo tanto, las palabras que tienen el mismo contexto se consideran similares y, por lo tanto, se acercan más en el espacio dimensional.
GloVe
GloVe o Global Vectors for Word Representation es un algoritmo que se usa para crear word embeddings. Este algoritmo fue creado por la Universidad de Stanford en 2014.
Word2Vec ignora el hecho de que algunas palabras de contexto se producen con más frecuencia que otras y también solo tienen en cuenta el contexto local y por lo tanto, no captura el contexto global.
Este algoritmo usa una matriz de co-ocurrencia para crear los word embeddings. Esta matriz de co-ocurrencia es una matriz que contiene el número de veces que aparece cada palabra junto a cada una de las otras palabras del vocabulario.
FastText
FastText es un algoritmo que se usa para crear word embeddings. Este algoritmo fue creado por Facebook en 2016.
Una de las principales desventajas de Word2Vec y GloVe es que no pueden codificar palabras desconocidas o fuera del vocabulario.
Entonces, para lidiar con este problema, Facebook propuso un modelo FastText. Es una extensión de Word2Vec y sigue el mismo modelo Skip-gram y CBOW. Pero a diferencia de Word2Vec que alimenta palabras enteras en la red neuronal, FastText primero divide las palabras en varias subpalabras (o n-grams) y luego las alimenta a la red neuronal.
Por ejemplo, si el valor de n es 3 y la palabra es manzana entonces su tri-gram será [<ma, man, anz, nza, zan, ana, na>] y su embedding de palabras será la suma de la representación vectorial de estos tri-grams. Aquí, los hiperparámetros min_n y max_n se consideran como 3 y los caracteres < y > representan el comienzo y el final de la palabra.
Por lo tanto, utilizando esta metodología, las palabras desconocidas se pueden representar en forma vectorial, ya que tienen una alta probabilidad de que sus n-grams también estén presentes en otras palabras.
Este algoritmo es una mejora de Word2Vec, ya que además de tener en cuenta las palabras que rodean a una palabra, también tiene en cuenta los n-grams de la palabra. Por ejemplo si tenemos la palabra gato, también tiene en cuenta los n-gramas de la palabra, en este caso ga, at y to, para n = 2.
Limitaciones de los word embeddings
Las técnicas de word embedding han dado un resultado decente, pero el problema es que el enfoque no es lo suficientemente preciso. No tienen en cuenta el orden de las palabras en las que aparecen, lo que conduce a la pérdida de la comprensión sintáctica y semántica de la oración.
Por ejemplo, Vas allí para enseñar, no a jugar Y Vas allí a jugar, no a enseñar Ambas oraciones tendrán la misma representación en el espacio vectorial, pero no significan lo mismo.
Además, el modelo de word embedding no puede dar resultados satisfactorios en una gran cantidad de datos de texto, ya que la misma palabra puede tener un significado diferente en una oración diferente según el contexto de la oración.
Por ejemplo, Voy a sentarme en el banco Y Voy a hacer gestiones en el banco En ambas oraciones, la palabra banco tiene diferentes significados.
Por lo tanto, requerimos un tipo de representación que pueda retener el significado contextual de la palabra presente en una oración.
Sentence embeddings
El sentence embedding es similar al word embedding, pero en lugar de palabras, codifican toda la oración en la representación vectorial.
Una forma simple de obtener sentence embedding es promediando los word embedding de todas las palabras presentes en la oración. Pero no son lo suficientemente precisos.
Algunos de los modelos más avanzados para sentence embedding son ELMo, InferSent y Sentence-BERT
ELMo
ELMo o Embeddings from Language Models es un modelo de sentence embedding que fue creado por la Universidad de Allen en 2018. Utiliza una red LSTM profunda bidireccional para producir representación vectorial. ELMo puede representar las palabras desconocidas o fuera del vocabulario en forma vectorial ya que está basado en caracteres.
InferSent
InferSent es un modelo de sentence embedding que fue creado por Facebook en 2017. Utiliza una red LSTM profunda bidireccional para producir representación vectorial. InferSent puede representar las palabras desconocidas o fuera del vocabulario en forma vectorial, ya que está basado en caracteres. Las oraciones están codificadas en una representación vectorial de 4096 dimensiones.
La capacitación del modelo se realiza en el conjunto de datos de Stanford Natural Language Inference (SNLI). Este conjunto de datos está etiquetado y escrito por humanos para alrededor de 500K pares de oraciones.
Sentence-BERT
Sentence-BERT es un modelo de sentence embedding que fue creado por la Universidad de Londres en 2019. Utiliza una red LSTM profunda bidireccional para producir representación vectorial. Sentence-BERT puede representar las palabras desconocidas o fuera del vocabulario en forma vectorial ya que está basado en caracteres. Las oraciones están codificadas en una representación vectorial de 768 dimensiones.
El modelo de NLP de última generación BERT es excelente en las tareas de Similitud Textual Semántica, pero el problema es que tomaría mucho tiempo para un corpus enorme (65 horas para 10.000 oraciones), ya que requiere que ambas oraciones se introduzcan en la red y esto aumenta el cálculo por un factor enorme.
Por lo tanto, Sentence-BERT es una modificación del modelo BERT.
Entrenamiento de un modelo word2vec con gensim
Para descargar el dataset que vamos a usar hay que instalar la librería dataset de huggingface:
pip install datasetsPara entrenar el modelo de embeddings vamos a usar la librería gensim. Para instalarla con Conda usamos
conda install -c conda-forge gensimY para instalarla con pip usamos
pip install gensimPara limpiar el dataset que nos hemos descargado vamos a usar expresiones regulares, que normalmente ya está instalada en Python, y nltk que es una librería de procesamiento de lenguaje natural. Para instalarla con Conda usamos
conda install -c anaconda nltkY para instalarlo con pip usamos
pip install nltkAhora que tenemos todo instalado, podemos importar las librerías que vamos a usar:
from gensim.models import Word2Vecfrom gensim.parsing.preprocessing import strip_punctuation, strip_numeric, strip_shortimport refrom nltk.corpus import stopwordsfrom nltk.tokenize import word_tokenizeCopied
Descarga del dataset
Vamos a descargar un dataset de textos procedentes de la wikipedia en español, para ello ejecutamos lo siguiente:
from datasets import load_datasetdataset_corpus = load_dataset('large_spanish_corpus', name='all_wikis')Copied
Vamos a ver cómo es
dataset_corpusCopied
DatasetDict({train: Dataset({features: ['text'],num_rows: 28109484})})
Como podemos ver, el dataset tiene más de 28 millones de textos. Vamos a ver alguno de ellos:
dataset_corpus['train']['text'][0:10]Copied
['¡Bienvenidos!','Ir a los contenidos»','= Contenidos =','','Portada','Tercera Lengua más hablada en el mundo.','La segunda en número de habitantes en el mundo occidental.','La de mayor proyección y crecimiento día a día.','El español es, hoy en día, nombrado en cada vez más contextos, tomando realce internacional como lengua de cultura y civilización siempre de mayor envergadura.','Ejemplo de ello es que la comunidad minoritaria más hablada en los Estados Unidos es precisamente la que habla idioma español.']
Como hay muchos ejemplos vamos a crear un subset de 10 millones de ejemplos para poder trabajar más rápido:
subset = dataset_corpus['train'].select(range(10000000))Copied
Limpieza del dataset
Ahora nos descargamos las stopwords de nltk, que son palabras que no aportan información y que vamos a eliminar de los textos
import nltknltk.download('stopwords')Copied
[nltk_data] Downloading package stopwords to[nltk_data] /home/wallabot/nltk_data...[nltk_data] Package stopwords is already up-to-date!
True
Ahora vamos a descargar los punkt de nltk, que es un tokenizer que nos va a permitir separar los textos en frases
nltk.download('punkt')Copied
[nltk_data] Downloading package punkt to /home/wallabot/nltk_data...[nltk_data] Package punkt is already up-to-date!
True
Creamos una función para limpiar los datos. Esta función va a:
- Pasar el texto a minúsculas
- Eliminar las URLs
- Eliminar las menciones a redes sociales como
@twittery#hashtag - Eliminar los signos de puntuación
- Eliminar los números
- Eliminar las palabras cortas
- Eliminar las stop words
Como estamos usando un dataset de huggingface, los textos están en formato dict, así que devolvemos un diccionario.
def clean_text(sentence_batch):# extrae el texto de la entradatext_list = sentence_batch['text']cleaned_text_list = []for text in text_list:# Convierte el texto a minúsculastext = text.lower()# Elimina URLstext = re.sub(r'httpS+|wwwS+|httpsS+', '', text, flags=re.MULTILINE)# Elimina las menciones @ y '#' de las redes socialestext = re.sub(r'@w+|#w+', '', text)# Elimina los caracteres de puntuacióntext = strip_punctuation(text)# Elimina los númerostext = strip_numeric(text)# Elimina las palabras cortastext = strip_short(text,minsize=2)# Elimina las palabras comunes (stop words)stop_words = set(stopwords.words('spanish'))word_tokens = word_tokenize(text)filtered_text = [word for word in word_tokens if word not in stop_words]cleaned_text_list.append(filtered_text)# Devuelve el texto limpioreturn {'text': cleaned_text_list}Copied
Aplicamos la función a los datos
sentences_corpus = subset.map(clean_text, batched=True)Copied
Map: 0%| | 0/10000000 [00:00<?, ? examples/s]
Vamos a guardar el dataset filtrado en un fichero para no tener que volver a ejecutar el proceso de limpieza
sentences_corpus.save_to_disk("sentences_corpus")Copied
Saving the dataset (0/4 shards): 0%| | 0/15000000 [00:00<?, ? examples/s]
Para cargarlo podemos hacer
from datasets import load_from_disksentences_corpus = load_from_disk('sentences_corpus')Copied
Ahora lo que vamos a tener es una lista de listas, donde cada lista es una frase tokenizada y sin stopwords. Es decir, tenemos una lista de frases, y cada frase es una lista de palabras. Vamos a ver cómo es:
for i in range(10):print(f'La frase "{subset["text"][i]}" se convierte en la lista de palabras "{sentences_corpus["text"][i]}"')Copied
La frase "¡Bienvenidos!" se convierte en la lista de palabras "['¡bienvenidos']"La frase "Ir a los contenidos»" se convierte en la lista de palabras "['ir', 'contenidos', '»']"La frase "= Contenidos =" se convierte en la lista de palabras "['contenidos']"La frase "" se convierte en la lista de palabras "[]"La frase "Portada" se convierte en la lista de palabras "['portada']"La frase "Tercera Lengua más hablada en el mundo." se convierte en la lista de palabras "['tercera', 'lengua', 'hablada', 'mundo']"La frase "La segunda en número de habitantes en el mundo occidental." se convierte en la lista de palabras "['segunda', 'número', 'habitantes', 'mundo', 'occidental']"La frase "La de mayor proyección y crecimiento día a día." se convierte en la lista de palabras "['mayor', 'proyección', 'crecimiento', 'día', 'día']"La frase "El español es, hoy en día, nombrado en cada vez más contextos, tomando realce internacional como lengua de cultura y civilización siempre de mayor envergadura." se convierte en la lista de palabras "['español', 'hoy', 'día', 'nombrado', 'cada', 'vez', 'contextos', 'tomando', 'realce', 'internacional', 'lengua', 'cultura', 'civilización', 'siempre', 'mayor', 'envergadura']"La frase "Ejemplo de ello es que la comunidad minoritaria más hablada en los Estados Unidos es precisamente la que habla idioma español." se convierte en la lista de palabras "['ejemplo', 'ello', 'comunidad', 'minoritaria', 'hablada', 'unidos', 'precisamente', 'habla', 'idioma', 'español']"
Entrenamiento del modelo word2vec
Vamos a entrenar un modelo de embeddings que convertirá palabras en vectores. Para ello vamos a usar la librería gensim y su modelo Word2Vec.
dataset = sentences_corpus['text']dim_embedding = 100window_size = 5 # 5 palabras a la izquierda y 5 palabras a la derechamin_count = 5 # Ignora las palabras con frecuencia menor a 5workers = 4 # Número de hilos de ejecuciónsg = 1 # 0 para CBOW, 1 para Skip-grammodel = Word2Vec(dataset, vector_size=dim_embedding, window=window_size, min_count=min_count, workers=workers, sg=sg)Copied
Este modelo se ha entrenado en la CPU, ya qye gensim no tiene opción de realizar el entrenamiento en la GPU y aun así en mi ordenador ha tardado X minutos en entrenar el modelo. Aunque la dimensión del embedding que hemos elegido es de solo 100 (a diferencia del tamaño de los embeddings de openai que es de 1536), no es un tiempo demasiado grande, ya que el dataset tiene 10 millones de frases.
Los grandes modelos de lenguaje son entrenados con datasets de miles de millones de frases, por lo que es normal que el entrenamiento de un modelo de embeddings con un dataset de 10 millones de frases tarde unos minutos.
Una vez entrenado el modelo, lo guardamos en un archivo para poder usarlo en el futuro
model.save('word2vec.model')Copied
Si lo quisieramos cargar en el futuro, podemos hacerlo con
model = Word2Vec.load('word2vec.model')Copied
Evaluación del modelo word2vec
Vamos a ver las palabras más similares de algunas palabras
model.wv.most_similar('perro', topn=10)Copied
[('gato', 0.7948548197746277),('perros', 0.77247554063797),('cachorro', 0.7638891339302063),('hámster', 0.7540281414985657),('caniche', 0.7514827251434326),('bobtail', 0.7492328882217407),('mastín', 0.7491254210472107),('lobo', 0.7312178611755371),('semental', 0.7292628288269043),('sabueso', 0.7290207147598267)]
model.wv.most_similar('gato', topn=10)Copied
[('conejo', 0.8148329854011536),('zorro', 0.8109457492828369),('perro', 0.7948548793792725),('lobo', 0.7878773808479309),('ardilla', 0.7860757112503052),('mapache', 0.7817519307136536),('huiña', 0.766639232635498),('oso', 0.7656188011169434),('mono', 0.7633568644523621),('camaleón', 0.7623056769371033)]
Ahora vamos a ver el ejemplo en el que comprobamos la similitud de la palabra reina con el resultado de a la palabra rey le restamos la palabra hombre y le sumamos la palabra mujer
embedding_hombre = model.wv['hombre']embedding_mujer = model.wv['mujer']embedding_rey = model.wv['rey']embedding_reina = model.wv['reina']Copied
embedding = embedding_rey - embedding_hombre + embedding_mujerCopied
from torch.nn.functional import cosine_similarityembedding = torch.tensor(embedding).unsqueeze(0)embedding_reina = torch.tensor(embedding_reina).unsqueeze(0)similarity = cosine_similarity(embedding, embedding_reina, dim=1)similarityCopied
tensor([0.8156])
Como vemos, hay bastante similitud
Visualización de los embeddings
Vamos a visualizar los embedding, para ello primero obtenemos los vectores y las palabras del modelo
embeddings = model.wv.vectorswords = list(model.wv.index_to_key)Copied
Como la dimensión de los embeddings es 100, para poder visualizarlos en 2 o 3 dimensiones tenemos que reducir la dimensión. Para ello vamos a usar PCA (más rápido) o TSNE (más preciso) de sklearn
from sklearn.decomposition import PCAdimmesions = 2pca = PCA(n_components=dimmesions)reduced_embeddings_PCA = pca.fit_transform(embeddings)Copied
from sklearn.manifold import TSNEdimmesions = 2tsne = TSNE(n_components=dimmesions, verbose=1, perplexity=40, n_iter=300)reduced_embeddings_tsne = tsne.fit_transform(embeddings)Copied
[t-SNE] Computing 121 nearest neighbors...[t-SNE] Indexed 493923 samples in 0.013s...[t-SNE] Computed neighbors for 493923 samples in 377.143s...[t-SNE] Computed conditional probabilities for sample 1000 / 493923[t-SNE] Computed conditional probabilities for sample 2000 / 493923[t-SNE] Computed conditional probabilities for sample 3000 / 493923[t-SNE] Computed conditional probabilities for sample 4000 / 493923[t-SNE] Computed conditional probabilities for sample 5000 / 493923[t-SNE] Computed conditional probabilities for sample 6000 / 493923[t-SNE] Computed conditional probabilities for sample 7000 / 493923[t-SNE] Computed conditional probabilities for sample 8000 / 493923[t-SNE] Computed conditional probabilities for sample 9000 / 493923[t-SNE] Computed conditional probabilities for sample 10000 / 493923[t-SNE] Computed conditional probabilities for sample 11000 / 493923[t-SNE] Computed conditional probabilities for sample 12000 / 493923[t-SNE] Computed conditional probabilities for sample 13000 / 493923[t-SNE] Computed conditional probabilities for sample 14000 / 493923[t-SNE] Computed conditional probabilities for sample 15000 / 493923[t-SNE] Computed conditional probabilities for sample 16000 / 493923[t-SNE] Computed conditional probabilities for sample 17000 / 493923[t-SNE] Computed conditional probabilities for sample 18000 / 493923[t-SNE] Computed conditional probabilities for sample 19000 / 493923[t-SNE] Computed conditional probabilities for sample 20000 / 493923[t-SNE] Computed conditional probabilities for sample 21000 / 493923[t-SNE] Computed conditional probabilities for sample 22000 / 493923...[t-SNE] Computed conditional probabilities for sample 493923 / 493923[t-SNE] Mean sigma: 0.275311[t-SNE] KL divergence after 250 iterations with early exaggeration: 117.413788[t-SNE] KL divergence after 300 iterations: 5.774648
Ahora los visualizamos en 2 dimensiones con matplotlib. Vamos a visualizar la reducción de dimensionalidad que hemos hecho con PCA y con TSNE
import matplotlib.pyplot as pltplt.figure(figsize=(10, 10))for i, word in enumerate(words[:200]): # Limitar a las primeras 200 palabrasplt.scatter(reduced_embeddings_PCA[i, 0], reduced_embeddings_PCA[i, 1])plt.annotate(word, xy=(reduced_embeddings_PCA[i, 0], reduced_embeddings_PCA[i, 1]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')plt.title('Embeddings (PCA)')plt.show()Copied
<Figure size 1000x1000 with 1 Axes>
plt.figure(figsize=(10, 10))for i, word in enumerate(words[:200]): # Limitar a las primeras 200 palabrasplt.scatter(reduced_embeddings_tsne[i, 0], reduced_embeddings_tsne[i, 1])plt.annotate(word, xy=(reduced_embeddings_tsne[i, 0], reduced_embeddings_tsne[i, 1]), xytext=(5, 2),textcoords='offset points', ha='right', va='bottom')plt.show()Copied
<Figure size 1000x1000 with 1 Axes>
Uso de modelos preentrenados con HuggingFace
Para usar modelos preentrenados de embeddings vamos a usar la librería transformers de huggingface. Para instalarla con Conda usamos
conda install -c conda-forge transformersY para instalarlo con pip usamos
pip install transformersCon la tarea feature-extraction de huggingface podemos usar modelos preentrenados para obtener los embeddings de las palabras. Para ello primero importamos la librería necesaria
from transformers import pipelineCopied
Vamos a obtener los embeddings de BERT
checkpoint = "bert-base-uncased"feature_extractor = pipeline("feature-extraction",framework="pt",model=checkpoint)Copied
Vamos a ver los embeddings de la palabra rey
embedding = feature_extractor("rey", return_tensors="pt").squeeze(0)embedding.shapeCopied
torch.Size([3, 768])
Como vemos obtenemos un vector de 768 dimensiones, es decir, los embeddings de BERT tienen 768 dimensiones. Por otro lado, vemos que tiene 3 vectores de embeddings, esto es porque BERT añade un token al principio y otro al final de la frase, por lo que a nosotros solo nos interesa el vector del medio
Vamos a volver a hacer el ejemplo en el que comprobamos la similitud de la palabra reina con el resultado de restarle a la palabra rey la palabra hombre y sumarle la palabra mujer
embedding_hombre = feature_extractor("man", return_tensors="pt").squeeze(0)[1]embedding_mujer = feature_extractor("woman", return_tensors="pt").squeeze(0)[1]embedding_rey = feature_extractor("king", return_tensors="pt").squeeze(0)[1]embedding_reina = feature_extractor("queen", return_tensors="pt").squeeze(0)[1]Copied
embedding = embedding_rey - embedding_hombre + embedding_mujerCopied
Vamos a ver la similitud
import torchfrom torch.nn.functional import cosine_similarityembedding = torch.tensor(embedding).unsqueeze(0)embedding_reina = torch.tensor(embedding_reina).unsqueeze(0)similarity = cosine_similarity(embedding, embedding_reina, dim=1)similarity.item()Copied
/tmp/ipykernel_33343/4248442045.py:4: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).embedding = torch.tensor(embedding).unsqueeze(0)/tmp/ipykernel_33343/4248442045.py:5: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).embedding_reina = torch.tensor(embedding_reina).unsqueeze(0)
0.742547333240509
Usando los embeddings de BERT también obtenemos un resultado muy cercano a 1
















