
Hugging Face transformers
The transformers library from Hugging Face is one of the most popular libraries for working with language models. Its ease of use democratized the use of the Transformer architecture and made it possible to work with state-of-the-art language models without having to have a great deal of knowledge in the area.
Between the transformers library, the model hub and its ease of use, the spaces and the ease of deploying demos, and new libraries like datasets, accelerate, PEFT and more, they have made Hugging Face one of the most important players in the AI scene at the moment. They call themselves "the GitHub of AI" and they certainly are.
This notebook has been automatically translated to make it accessible to more people, please let me know if you see any typos.
Installation
To install transformers can be done with pip.
pip install transformers
```
or with `conda`.
````bash
conda install conda-forge::transformers
```
In addition to the library you need to have a PyTorch or TensorFlow backend installed. That is, you need to have torch or tensorflow installed to be able to use transformers.
Inference with `pipeline
With the transformers pipeline`s you can do inference with language models in a very simple way. This has the advantage that development is done much faster and prototyping can be done very easily. It also allows people who do not have much knowledge to be able to use the models.
With pipeline you can do inference in a lot of different tasks. Each task has its own pipeline (NLP pipeline, vision pipeline, etc), but a general abstraction can be made using the pipeline class which takes care of selecting the appropriate pipeline for the task passed to it.
Tasks
As of this writing, the tasks that can be done with pipeline are:
Audio:
- Audio classification
- acoustic scene classification: label audio with a scene label ("office", "beach", "stadium")
- acoustic event detection: tag audio with a sound event tag ("car horn", "whale call", "glass breaking")
- labeling: labeling audio containing various sounds (birdsong, speaker identification in a meeting)
- music classification: labeling music with a genre label ("metal", "hip-hop", "country")
- Audio classification
Automatic speech recognition (ASR, audio speech recognition):
Computer vision
- Image classification
- Object detection
- Image segmentation
- Depth estimation
Natural language processing (NLP) * Natural language processing (NLP)
Text classification
- sentiment analysis
- content classification
Classification of tokens
- Named Entity Recognition (NER): tag a token according to an entity category such as organization, person, location or date.
- part-of-speech (POS) tagging: tagging a token according to its part of speech, such as noun, verb or adjective. POS is useful to help translation systems understand how two identical words are grammatically different (e.g., "cut" as a noun versus "cut" as a verb).
Answers to questions
- extractive: given a question and some context, the answer is a fragment of text from the context that the model must extract.
- abstract: given a question and some context, the answer is generated from the context; this approach is handled by the Text2TextGenerationPipeline instead of the QuestionAnsweringPipeline shown below.
Summarize
- extractive: identifies and extracts the most important sentences from the original text
- abstracting: generates the objective summary (which may include new words not present in the input document) from the original text
Translation
Language modeling
- causal: the objective of the model is to predict the next token in a sequence, and future tokens are masked.
- masked: the objective of the model is to predict a masked token in a sequence with full access to the tokens in the sequence.
Multimodal
- Answers to document questions
Use of pipeline
The easiest way to create a pipeline is simply to tell it the task we want it to solve using the task parameter. And the library will take care of selecting the best model for that task, download it and save it in the cache for future use.
from transformers import pipelinegenerator = pipeline(task="text-generation")
No model was supplied, defaulted to openai-community/gpt2 and revision 6c0e608 (https://huggingface.co/openai-community/gpt2).Using a pipeline without specifying a model name and revision in production is not recommended.
generator("Me encanta aprender de")
As you can see the generated text is in French, while I have introduced it in Spanish, so it is important to choose well the model. If you notice the library has taken the openai-community/gpt2 model, which is a model trained mostly in English, and that when I put Spanish text in it, it got confused and generated a response in French.
We are going to use a model retrained in Spanish using the model parameter.
generator("Me encanta aprender de")from transformers import pipelinegenerator = pipeline(task="text-generation", model="flax-community/gpt-2-spanish")
generator("Me encanta aprender de")
Now the generated text looks much better
The pipeline class has many possible parameters, so to see all of them and learn more about the class I recommend you to read its documentation, but let's talk about one, because for deep learning it is very important and it is device. It defines the device (e.g. cpu, cuda:1, mps or an ordinal range of GPUs like 1) on which the pipeline will be assigned.
In my case, as I have a GPU I set 0.
from transformers import pipeline
generator = pipeline(task="text-generation", model="flax-community/gpt-2-spanish", device=0)
generation = generator("Me encanta aprender de")
print(generation[0]['generated_text'])
How pipeline works
When we make use of pipeline below what is happening is this

Text is automatically tokenized, passed through the model and then post-processed.
Inference with AutoClass and pipeline.
We have seen that pipeline abstracts a lot of what happens, but we can select which tokenizer, which model and which postprocessing we want to use.
Tokenization with AutoTokenizer.
Before we used the flax-community/gpt-2-spanish model to generate text, we can use its tokenizer
generator("Me encanta aprender de")from transformers import pipelinegenerator = pipeline(task="text-generation", model="flax-community/gpt-2-spanish")generator("Me encanta aprender de")from transformers import pipelinegenerator = pipeline(task="text-generation", model="flax-community/gpt-2-spanish", device=0)generation = generator("Me encanta aprender de")print(generation[0]['generated_text'])from transformers import AutoTokenizercheckpoint = "flax-community/gpt-2-spanish"tokenizer = AutoTokenizer.from_pretrained(checkpoint)text = "Me encanta lo que estoy aprendiendo"tokens = tokenizer(text, return_tensors="pt")print(tokens)
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.{'input_ids': tensor([[ 2879, 4835, 382, 288, 2383, 15257]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1]])}
AutoModel Model
Now we can create the model and pass the tokens to it.
from transformers import AutoModelmodel = AutoModel.from_pretrained("flax-community/gpt-2-spanish")output = model(**tokens)type(output), output.keys()
(transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions,odict_keys(['last_hidden_state', 'past_key_values']))
If we now try to use it in a pipeline we will get an error.
from transformers import pipeline
pipeline("text-generation", model=model, tokenizer=tokenizer)("Me encanta aprender de")
This is because when it worked we used
pipeline(task="text-generation", model="flax-community/gpt-2-spanish")
```
But now we have made
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
model = AutoModel.from_pretrained("flax-community/gpt-2-spanish")
pipeline("text-generation", model=model, tokenizer=tokenizer)
```
In the first case we just used pipeline and the model name, underneath we were looking for the best way to implement the model and the tokenizer. But in the second case we have created the tokenizer and the model and passed it to pipeline, but we have not created them well for what the pipeline needs.
To fix this we use AutoModelFor.
AutoModelFor Model
The transformers library gives us the opportunity to create a model for a given task such as
AutoModelForCausalLMused to continue textsAutoModelForMaskedLMused for gap fillingAutoModelForMaskGenerationwhich is used to generate masks.- AutoModelForSeq2SeqLM, which is used to convert from sequences to sequences, as for example in translation.
AutoModelForSequenceClassificationfor text classificationAutoModelForMultipleChoicefor multiple choiceAutoModelForNextSentencePredictionto predict whether two sentences are consecutive.AutoModelForTokenClassificationfor token classificationAutoModelForQuestionAnsweringfor questions and answersAutoModelForTextEncodingfor text encoding
Let's use the above model to generate text
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish")
pipeline("text-generation", model=model, tokenizer=tokenizer)("Me encanta aprender de")[0]['generated_text']
Now it works, because we have created the model in a way that pipeline can understand.
Inference with AutoClass only
Earlier we created the model and tokenizer and gave it to pipeline to do the necessary underneath, but we can use the methods for inference ourselves.
Generation of casual text
We create the model and the tokenizer
from transformers import pipelinepipeline("text-generation", model=model, tokenizer=tokenizer)("Me encanta aprender de")from transformers import AutoTokenizer, AutoModelForCausalLMfrom transformers import pipelinetokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish")pipeline("text-generation", model=model, tokenizer=tokenizer)("Me encanta aprender de")[0]['generated_text']from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
With device_map, we have loaded the model on GPU 0
Now we have to do what pipeline used to do.
First we generate the tokens
from transformers import pipelinepipeline("text-generation", model=model, tokenizer=tokenizer)("Me encanta aprender de")from transformers import AutoTokenizer, AutoModelForCausalLMfrom transformers import pipelinetokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish")pipeline("text-generation", model=model, tokenizer=tokenizer)("Me encanta aprender de")[0]['generated_text']from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
The model 'GPT2Model' is not supported for text-generation. Supported models are ['BartForCausalLM', 'BertLMHeadModel', 'BertGenerationDecoder', 'BigBirdForCausalLM', 'BigBirdPegasusForCausalLM', 'BioGptForCausalLM', 'BlenderbotForCausalLM', 'BlenderbotSmallForCausalLM', 'BloomForCausalLM', 'CamembertForCausalLM', 'LlamaForCausalLM', 'CodeGenForCausalLM', 'CpmAntForCausalLM', 'CTRLLMHeadModel', 'Data2VecTextForCausalLM', 'ElectraForCausalLM', 'ErnieForCausalLM', 'FalconForCausalLM', 'FuyuForCausalLM', 'GemmaForCausalLM', 'GitForCausalLM', 'GPT2LMHeadModel', 'GPT2LMHeadModel', 'GPTBigCodeForCausalLM', 'GPTNeoForCausalLM', 'GPTNeoXForCausalLM', 'GPTNeoXJapaneseForCausalLM', 'GPTJForCausalLM', 'LlamaForCausalLM', 'MarianForCausalLM', 'MBartForCausalLM', 'MegaForCausalLM', 'MegatronBertForCausalLM', 'MistralForCausalLM', 'MixtralForCausalLM', 'MptForCausalLM', 'MusicgenForCausalLM', 'MvpForCausalLM', 'OpenLlamaForCausalLM', 'OpenAIGPTLMHeadModel', 'OPTForCausalLM', 'PegasusForCausalLM', 'PersimmonForCausalLM', 'PhiForCausalLM', 'PLBartForCausalLM', 'ProphetNetForCausalLM', 'QDQBertLMHeadModel', 'Qwen2ForCausalLM', 'ReformerModelWithLMHead', 'RemBertForCausalLM', 'RobertaForCausalLM', 'RobertaPreLayerNormForCausalLM', 'RoCBertForCausalLM', 'RoFormerForCausalLM', 'RwkvForCausalLM', 'Speech2Text2ForCausalLM', 'StableLmForCausalLM', 'TransfoXLLMHeadModel', 'TrOCRForCausalLM', 'WhisperForCausalLM', 'XGLMForCausalLM', 'XLMWithLMHeadModel', 'XLMProphetNetForCausalLM', 'XLMRobertaForCausalLM', 'XLMRobertaXLForCausalLM', 'XLNetLMHeadModel', 'XmodForCausalLM'].Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[2], line 1----> 1 tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:2829, in PreTrainedTokenizerBase.__call__(self, text, text_pair, text_target, text_pair_target, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)2827 if not self._in_target_context_manager:2828 self._switch_to_input_mode()-> 2829 encodings = self._call_one(text=text, text_pair=text_pair, **all_kwargs)2830 if text_target is not None:2831 self._switch_to_target_mode()File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:2915, in PreTrainedTokenizerBase._call_one(self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)2910 raise ValueError(2911 f"batch length of `text`: {len(text)} does not match batch length of `text_pair`:"2912 f" {len(text_pair)}."2913 )2914 batch_text_or_text_pairs = list(zip(text, text_pair)) if text_pair is not None else text-> 2915 return self.batch_encode_plus(2916 batch_text_or_text_pairs=batch_text_or_text_pairs,2917 add_special_tokens=add_special_tokens,2918 padding=padding,2919 truncation=truncation,2920 max_length=max_length,2921 stride=stride,2922 is_split_into_words=is_split_into_words,2923 pad_to_multiple_of=pad_to_multiple_of,2924 return_tensors=return_tensors,2925 return_token_type_ids=return_token_type_ids,2926 return_attention_mask=return_attention_mask,2927 return_overflowing_tokens=return_overflowing_tokens,2928 return_special_tokens_mask=return_special_tokens_mask,2929 return_offsets_mapping=return_offsets_mapping,2930 return_length=return_length,2931 verbose=verbose,2932 **kwargs,2933 )2934 else:2935 return self.encode_plus(2936 text=text,2937 text_pair=text_pair,(...)2953 **kwargs,2954 )File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:3097, in PreTrainedTokenizerBase.batch_encode_plus(self, batch_text_or_text_pairs, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)3080 """3081 Tokenize and prepare for the model a list of sequences or a list of pairs of sequences.3082(...)3093 details in `encode_plus`).3094 """3096 # Backward compatibility for 'truncation_strategy', 'pad_to_max_length'-> 3097 padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(3098 padding=padding,3099 truncation=truncation,3100 max_length=max_length,3101 pad_to_multiple_of=pad_to_multiple_of,3102 verbose=verbose,3103 **kwargs,3104 )3106 return self._batch_encode_plus(3107 batch_text_or_text_pairs=batch_text_or_text_pairs,3108 add_special_tokens=add_special_tokens,(...)3123 **kwargs,3124 )File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:2734, in PreTrainedTokenizerBase._get_padding_truncation_strategies(self, padding, truncation, max_length, pad_to_multiple_of, verbose, **kwargs)2732 # Test if we have a padding token2733 if padding_strategy != PaddingStrategy.DO_NOT_PAD and (self.pad_token is None or self.pad_token_id < 0):-> 2734 raise ValueError(2735 "Asking to pad but the tokenizer does not have a padding token. "2736 "Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` "2737 "or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`."2738 )2740 # Check that we will truncate to a multiple of pad_to_multiple_of if both are provided2741 if (2742 truncation_strategy != TruncationStrategy.DO_NOT_TRUNCATE2743 and padding_strategy != PaddingStrategy.DO_NOT_PAD(...)2746 and (max_length % pad_to_multiple_of != 0)2747 ):ValueError: Asking to pad but the tokenizer does not have a padding token. Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`.
We see that it has given us an error, it tells us that the tokenizer does not have a padding token. Most LLMs do not have a padding token, but to use the transformers library a padding token is necessary, so what is usually done is to assign the end-of-statement token to the padding token.
tokenizer.pad_token = tokenizer.eos_token
Now we can generate the tokens
tokenizer.pad_token = tokenizer.eos_tokentokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_input.input_ids
tensor([[2879, 4835, 3760, 225, 72, 73]], device='cuda:0')
Now we pass them to the model that will generate the new tokens, for that we use the generate method
tokens_output = model.generate(**tokens_input, max_length=50)
print(f"input tokens: {tokens_input.input_ids}")
print(f"output tokens: {tokens_output}")
We can see that the first tokens of token_inputs are the same as those of token_outputs, the following tokens are those generated by the model
Now we have to convert those tokens to a statement using the tokenizer decoder
tokens_output = model.generate(**tokens_input, max_length=50)print(f"input tokens: {tokens_input.input_ids}")print(f"output tokens: {tokens_output}")sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)sentence_output
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.'Me encanta aprender de los demás, y en este caso de los que me rodean, y es que en el fondo, es una forma de aprender de los demás. '
We already have the generated text
Text classification
We create the model and the tokenizer
import torchfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationtokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")model = AutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model", device_map=0)
We generate tokens
import torchfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationtokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")model = AutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model", device_map=0)text = "This was a masterpiece. Not completely faithful to the books, but enthralling from beginning to end. Might be my favorite of the three."inputs = tokenizer(text, return_tensors="pt").to("cuda")
Once we have the tokens, we classify
import torchfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationtokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")model = AutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model", device_map=0)text = "This was a masterpiece. Not completely faithful to the books, but enthralling from beginning to end. Might be my favorite of the three."inputs = tokenizer(text, return_tensors="pt").to("cuda")with torch.no_grad():logits = model(**inputs).logitspredicted_class_id = logits.argmax().item()prediction = model.config.id2label[predicted_class_id]prediction
'LABEL_1'
Let's take a look at the classes
clases = model.config.id2labelclases
{0: 'LABEL_0', 1: 'LABEL_1'}
This way there is no one to find out, so we modify it.
model.config.id2label = {0: "NEGATIVE", 1: "POSITIVE"}
And now we go back to sorting
model.config.id2label = {0: "NEGATIVE", 1: "POSITIVE"}with torch.no_grad():logits = model(**inputs).logitspredicted_class_id = logits.argmax().item()prediction = model.config.id2label[predicted_class_id]prediction
'POSITIVE'
Classification of tokens
We create the model and the tokenizer
import torchfrom transformers import AutoTokenizer, AutoModelForTokenClassificationtokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model", device_map=0)
We generate tokens
import torchfrom transformers import AutoTokenizer, AutoModelForTokenClassificationtokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model", device_map=0)text = "The Golden State Warriors are an American professional basketball team based in San Francisco."inputs = tokenizer(text, return_tensors="pt").to("cuda")
Once we have the tokens, we classify
import torchfrom transformers import AutoTokenizer, AutoModelForTokenClassificationtokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model", device_map=0)text = "The Golden State Warriors are an American professional basketball team based in San Francisco."inputs = tokenizer(text, return_tensors="pt").to("cuda")with torch.no_grad():logits = model(**inputs).logitspredictions = torch.argmax(logits, dim=2)predicted_token_class = [model.config.id2label[t.item()] for t in predictions[0]]for i in range(len(inputs.input_ids[0])):print(f"{inputs.input_ids[0][i]} ({tokenizer.decode([inputs.input_ids[0][i]])}) -> {predicted_token_class[i]}")
101 ([CLS]) -> O1996 (the) -> O3585 (golden) -> B-location2110 (state) -> I-location6424 (warriors) -> B-group2024 (are) -> O2019 (an) -> O2137 (american) -> O2658 (professional) -> O3455 (basketball) -> O2136 (team) -> O2241 (based) -> O1999 (in) -> O2624 (san) -> B-location3799 (francisco) -> B-location1012 (.) -> O102 ([SEP]) -> O
As you can see the tokens corresponding to golden, state, warriors, san and francisco have been classified as location tokens.
Question answering
We create the model and the tokenizer
import torchfrom transformers import AutoTokenizer, AutoModelForQuestionAnsweringtokenizer = AutoTokenizer.from_pretrained("mrm8488/roberta-base-1B-1-finetuned-squadv1")model = AutoModelForQuestionAnswering.from_pretrained("mrm8488/roberta-base-1B-1-finetuned-squadv1", device_map=0)
Some weights of the model checkpoint at mrm8488/roberta-base-1B-1-finetuned-squadv1 were not used when initializing RobertaForQuestionAnswering: ['roberta.pooler.dense.bias', 'roberta.pooler.dense.weight']- This IS expected if you are initializing RobertaForQuestionAnswering from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).- This IS NOT expected if you are initializing RobertaForQuestionAnswering from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
We generate tokens
question = "How many programming languages does BLOOM support?"context = "BLOOM has 176 billion parameters and can generate text in 46 languages natural languages and 13 programming languages."inputs = tokenizer(question, context, return_tensors="pt").to("cuda")
Once we have the tokens, we classify
question = "How many programming languages does BLOOM support?"context = "BLOOM has 176 billion parameters and can generate text in 46 languages natural languages and 13 programming languages."inputs = tokenizer(question, context, return_tensors="pt").to("cuda")with torch.no_grad():outputs = model(**inputs)answer_start_index = outputs.start_logits.argmax()answer_end_index = outputs.end_logits.argmax()predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]tokenizer.decode(predict_answer_tokens)
' 13'
Masked language modeling (Masked language modeling)
We create the model and the tokenizer
import torchfrom transformers import AutoTokenizer, AutoModelForMaskedLMtokenizer = AutoTokenizer.from_pretrained("nyu-mll/roberta-base-1B-1")model = AutoModelForMaskedLM.from_pretrained("nyu-mll/roberta-base-1B-1", device_map=0)
Some weights of the model checkpoint at nyu-mll/roberta-base-1B-1 were not used when initializing RobertaForMaskedLM: ['roberta.pooler.dense.bias', 'roberta.pooler.dense.weight']- This IS expected if you are initializing RobertaForMaskedLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).- This IS NOT expected if you are initializing RobertaForMaskedLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
We generate tokens
text = "The Milky Way is a <mask> galaxy."inputs = tokenizer(text, return_tensors="pt").to("cuda")mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
Once we have the tokens, we classify
text = "The Milky Way is a <mask> galaxy."inputs = tokenizer(text, return_tensors="pt").to("cuda")mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]with torch.no_grad():logits = model(**inputs).logitsmask_token_logits = logits[0, mask_token_index, :]top_3_tokens = torch.topk(mask_token_logits, 3, dim=1).indices[0].tolist()for token in top_3_tokens:print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
The Milky Way is a spiral galaxy.The Milky Way is a closed galaxy.The Milky Way is a distant galaxy.
Model customization
Earlier we have done the inference with AutoClass, but we have done it with the default model settings. But we can configure the model as much as we like
Let's instantiate a model and see its configuration
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfigtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)config = AutoConfig.from_pretrained("flax-community/gpt-2-spanish")config
GPT2Config {"_name_or_path": "flax-community/gpt-2-spanish","activation_function": "gelu_new","architectures": ["GPT2LMHeadModel"],"attn_pdrop": 0.0,"bos_token_id": 50256,"embd_pdrop": 0.0,"eos_token_id": 50256,"gradient_checkpointing": false,"initializer_range": 0.02,"layer_norm_epsilon": 1e-05,"model_type": "gpt2","n_ctx": 1024,"n_embd": 768,"n_head": 12,"n_inner": null,"n_layer": 12,"n_positions": 1024,"reorder_and_upcast_attn": false,"resid_pdrop": 0.0,"scale_attn_by_inverse_layer_idx": false,"scale_attn_weights": true,"summary_activation": null,"summary_first_dropout": 0.1,"summary_proj_to_labels": true,"summary_type": "cls_index","summary_use_proj": true,"task_specific_params": {"text-generation": {"do_sample": true,"max_length": 50}},"transformers_version": "4.38.1","use_cache": true,"vocab_size": 50257}
We can see the model configuration, for example the activation function is gelu_new, it has 12 heads, the vocabulary size is 50257 words, etc.
But we can modify this configuration
config = AutoConfig.from_pretrained("flax-community/gpt-2-spanish", activation_function="relu")config.activation_function
'relu'
We now create the model with this configuration
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", config=config, device_map=0)
And we generate text
tokenizer.pad_token = tokenizer.eos_token
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_length=50)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
sentence_output
We see that this modification does not generate as good text.
Tokenization
So far we have seen the different ways to do inference with the transformers library. Now we are going to get into the guts of the library. To do this we are first going to look at things to keep in mind when tokenizing.
We are not going to explain what tokenizing is in depth, since we have already explained it in the post on the [tokenizers] library (https://www.maximofn.com/hugging-face-tokenizers/).
Padding
When you have a batch of sequences, sometimes it is necessary that after tokenizing, all the sequences have the same length, so for this we use the padding=True parameter.
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", config=config, device_map=0)tokenizer.pad_token = tokenizer.eos_tokentokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_length=50)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)sentence_outputfrom transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish", pad_token="PAD")encoded_input = tokenizer(batch_sentences, padding=True)for encoded in encoded_input["input_ids"]:print(encoded)print(f"Padding token id: {tokenizer.pad_token_id}")
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.[2959, 16, 875, 3736, 3028, 303, 291, 2200, 8080, 35, 50257, 50257][1489, 2275, 288, 12052, 382, 325, 2200, 8080, 16, 4319, 50257, 50257][1699, 2899, 707, 225, 72, 73, 314, 34630, 474, 515, 1259, 35]Padding token id: 50257
As we can see, he has added paddings to the first two sequences at the end.
Truncated
Besides adding padding, sometimes it is necessary to truncate the sequences so that they do not occupy more than a certain number of tokens. To do this we set truncation=True and max_length to the number of tokens we want the sequence to have.
from transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")encoded_input = tokenizer(batch_sentences, truncation=True, max_length=5)for encoded in encoded_input["input_ids"]:print(encoded)
[2959, 16, 875, 3736, 3028][1489, 2275, 288, 12052, 382][1699, 2899, 707, 225, 72]
Same sentences as before, now generate fewer tokens
Tensors
Until now we were receiving lists of tokens, but surely we are interested in receiving tensors from PyTorch or TensorFlow. For this we use the parameter return_tensors and we specify from which framework we want to receive the tensor, in our case we will choose PyTorch with pt.
We first see without specifying that we return tensors
from transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish", pad_token="PAD")encoded_input = tokenizer(batch_sentences, padding=True)for encoded in encoded_input["input_ids"]:print(type(encoded))
<class 'list'><class 'list'><class 'list'>
We receive lists, if we want to receive tensors from PyTorch we use return_tensors="pt".
from transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish", pad_token="PAD")encoded_input = tokenizer(batch_sentences, padding=True, return_tensors="pt")for encoded in encoded_input["input_ids"]:print(type(encoded), encoded.shape)print(type(encoded_input["input_ids"]), encoded_input["input_ids"].shape)
<class 'torch.Tensor'> torch.Size([12])<class 'torch.Tensor'> torch.Size([12])<class 'torch.Tensor'> torch.Size([12])<class 'torch.Tensor'> torch.Size([3, 12])
Masks
When we tokenize a statement we not only get the input_ids, but we also get the attention mask. The attention mask is a tensor that has the same size as input_ids and has a 1 in the positions that are tokens and a 0 in the positions that are padding.
from transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish", pad_token="PAD")encoded_input = tokenizer(batch_sentences, padding=True)print(f"padding token id: {tokenizer.pad_token_id}")print(f" encoded_input[0] inputs_ids: {encoded_input['input_ids'][0]}")print(f"encoded_input[0] attention_mask: {encoded_input['attention_mask'][0]}")print(f" encoded_input[1] inputs_ids: {encoded_input['input_ids'][1]}")print(f"encoded_input[1] attention_mask: {encoded_input['attention_mask'][1]}")print(f" encoded_input[2] inputs_ids: {encoded_input['input_ids'][2]}")print(f"encoded_input[2] attention_mask: {encoded_input['attention_mask'][2]}")
padding token id: 50257encoded_input[0] inputs_ids: [2959, 16, 875, 3736, 3028, 303, 291, 2200, 8080, 35, 50257, 50257]encoded_input[0] attention_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]encoded_input[1] inputs_ids: [1489, 2275, 288, 12052, 382, 325, 2200, 8080, 16, 4319, 50257, 50257]encoded_input[1] attention_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]encoded_input[2] inputs_ids: [1699, 2899, 707, 225, 72, 73, 314, 34630, 474, 515, 1259, 35]encoded_input[2] attention_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
As you can see, in the first two sentences, we have a 1 in the first positions and a 0 in the last two positions. In those same positions we have the token 50257, which corresponds to the padding token.
With these attention masks we are telling the model which tokens to pay attention to and which not to pay attention to.
Text generation could still be done if we did not pass these attention masks, the generate method would do its best to infer this mask, but if we pass it we help to generate better text.
Fast Tokenizers
Some pretrained tokenizers have a fast version, they have the same methods as the normal ones, only they are developed in Rust. To use them we must use the PreTrainedTokenizerFast class of the transformers library.
Let us first look at the tokenization time with a normal tokenizer.
%%timefrom transformers import BertTokenizertokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")sentence = ("The Permaculture Design Principles are a set of universal design principles ""that can be applied to any location, climate and culture, and they allow us to design ""the most efficient and sustainable human habitation and food production systems. ""Permaculture is a design system that encompasses a wide variety of disciplines, such ""as ecology, landscape design, environmental science and energy conservation, and the ""Permaculture design principles are drawn from these various disciplines. Each individual ""design principle itself embodies a complete conceptual framework based on sound ""scientific principles. When we bring all these separate principles together, we can ""create a design system that both looks at whole systems, the parts that these systems ""consist of, and how those parts interact with each other to create a complex, dynamic, ""living system. Each design principle serves as a tool that allows us to integrate all ""the separate parts of a design, referred to as elements, into a functional, synergistic, ""whole system, where the elements harmoniously interact and work together in the most ""efficient way possible.")tokens = tokenizer([sentence], padding=True, return_tensors="pt")
CPU times: user 55.3 ms, sys: 8.58 ms, total: 63.9 msWall time: 226 ms
And now with a quick one
%%timefrom transformers import BertTokenizerFasttokenizer = BertTokenizerFast.from_pretrained("google-bert/bert-base-uncased")sentence = ("The Permaculture Design Principles are a set of universal design principles ""that can be applied to any location, climate and culture, and they allow us to design ""the most efficient and sustainable human habitation and food production systems. ""Permaculture is a design system that encompasses a wide variety of disciplines, such ""as ecology, landscape design, environmental science and energy conservation, and the ""Permaculture design principles are drawn from these various disciplines. Each individual ""design principle itself embodies a complete conceptual framework based on sound ""scientific principles. When we bring all these separate principles together, we can ""create a design system that both looks at whole systems, the parts that these systems ""consist of, and how those parts interact with each other to create a complex, dynamic, ""living system. Each design principle serves as a tool that allows us to integrate all ""the separate parts of a design, referred to as elements, into a functional, synergistic, ""whole system, where the elements harmoniously interact and work together in the most ""efficient way possible.")tokens = tokenizer([sentence], padding=True, return_tensors="pt")
CPU times: user 42.6 ms, sys: 3.26 ms, total: 45.8 msWall time: 179 ms
You can see how the BertTokenizerFast is about 40 ms faster.
Text generation forms
We continue with the guts of the transformers library, now we are going to see the ways to generate text.
The transformer architecture generates the next most likely token, this is the simplest way to generate text, but it is not the only one, so let's look at them.
When it comes to generating textno there is no best way and it will depend on our model and the purpose of use.
Greedy Search
It is the simplest way of text generation. It looks for the most probable token in each iteration.
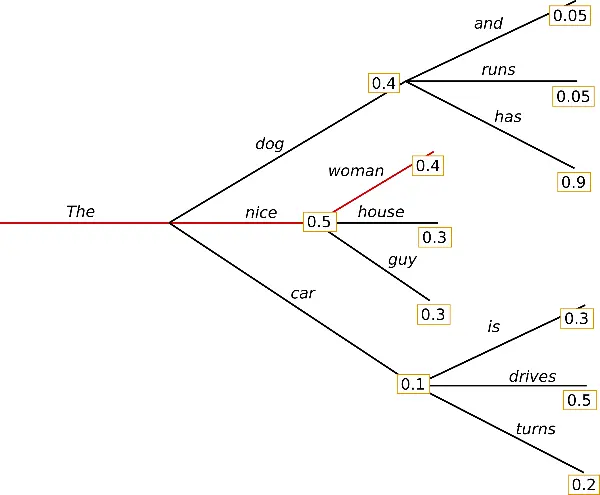
To generate text in this way with transformers you don't have to do anything special, as it is the default way.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
You can see that the generated text is fine, but it starts to repeat. This is because in greedy search, words with a high probability can hide behind words with a lower probability, so they can get lost.
Here, the word has has a high probability, but is hidden behind dog, which has a lower probability than nice.
Contrastive Search
The Contrastive Search method optimizes text generation by selecting word or phrase options that maximize a quality criterion over less desirable ones. In practice, this means that during text generation, at each step, the model not only searches for the next word that is most likely to follow as learned during its training, but also compares different candidates for that next word and evaluates which of them would contribute to form the most coherent, relevant and high quality text in the given context. Therefore, Contrastive Search reduces the possibility of generating irrelevant or low-quality responses by focusing on those options that best fit the text generation goal, based on a direct comparison between possible continuations at each step of the process.
To generate text with contrastive search in transformers you have to use penalty_alpha and top_k parameters when generating text.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, penalty_alpha=0.6, top_k=4)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
Here the pattern takes longer to start to repeat itself
Multinomial sampling
Unlike greedy search that always chooses a token with the highest probability as the next token, multinomial sampling (also called ancestral sampling) randomly selects the next token based on the probability distribution of the entire vocabulary provided by the model. Each token with a non-zero probability has a chance of being selected, which reduces the risk of repetition.
To enable Multinomial sampling you have to set do_sample=True and num_beams=1.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, num_beams=1)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
The truth is that the model does not repeat itself at all, but I feel like I'm talking to a small child, who talks about one subject and then starts spinning off with others that have nothing to do with it.
Beam search
Beam search reduces the risk of missing high probability hidden word sequences by keeping the most probable num_beams at each time step and finally choosing the hypothesis that has the highest overall probability.
To generate with beam search it is necessary to add the parameter num_beams.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
It repeats itself a lot
Beam search multinomial sampling
This technique combines the bean search where a beam search and multinomial sampling where the next token is randomly selected based on the probability distribution of the entire vocabulary provided by the model.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, do_sample=True)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
It repeats itself a lot
Beam search n-grams penalty
To avoid repetition we can penalize for n-gram repetition. For this we use the parameter no_repeat_ngram_size.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, no_repeat_ngram_size=2)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
This text no longer repeats itself and also has a little more coherence.
However, n-gram penalties should be used with care. An article generated about New York City should not use a 2-gram penalty or else the name of the city would only appear once in the entire text!
Beam search n-grams penalty return sequences
We can generate several sequences to compare them and keep the best one. For this we use the parameter num_return_sequences with the condition that num_return_sequences <= num_beams.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_outputs = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, no_repeat_ngram_size=2, num_return_sequences=3)
for i, tokens_output in enumerate(tokens_outputs):
if i != 0:
print("\n\n")
sentence_output = tokenizer.decode(tokens_output, skip_special_tokens=True)
print(f"{i}: {sentence_output}")
Now we can keep the best sequence
Diverse beam search decoding
The diverse beam search decoding is an extension of the beam search strategy that allows to generate a more diverse set of beam sequences to choose from.
In order to generate text in this way we have to use the parameters num_beams, num_beam_groups, and diversity_penalty.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, num_beam_groups=5, diversity_penalty=1.0)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
This method seems to be repeated quite often
Speculative Decoding
Speculative decoding (also known as assisted decoding) is a modification of the above decoding strategies, which uses an assistant model (ideally a much smaller one) with the same tokenizer, to generate some candidate tokens. Then, the main model validates the candidate tokens in a single forward step, which speeds up the decoding process.
To generate text in this way it is necessary to use the parameter do_sample=True.
Currently, assisted decoding only supports greedy search, and assisted decoding does not support batch entries.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
assistant_model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, assistant_model=assistant_model, do_sample=True)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
This method has very good results
Speculative Decoding randomness control
When using assisted decoding with sampling methods, the temperature parameter can be used to control randomness. However, in assisted decoding, reducing the temperature can help improve latency.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
assistant_model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, assistant_model=assistant_model, do_sample=True, temperature=0.5)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
Here it has not done so well
Sampling
This is where the techniques used by today's LLMs begin.
Instead of always selecting the most likely word (which could lead to predictable or repetitive texts), sampling introduces randomness into the selection process, allowing the model to explore a variety of possible words based on their probabilities. It is like rolling a weighted die for each word. Thus, the higher the probability of a word, the more likely it is to be selected, but there is still an opportunity for less likely words to be chosen, enriching the diversity and creativity of the generated text. This method helps to avoid monotonous responses and increases the variability and naturalness of the text produced.
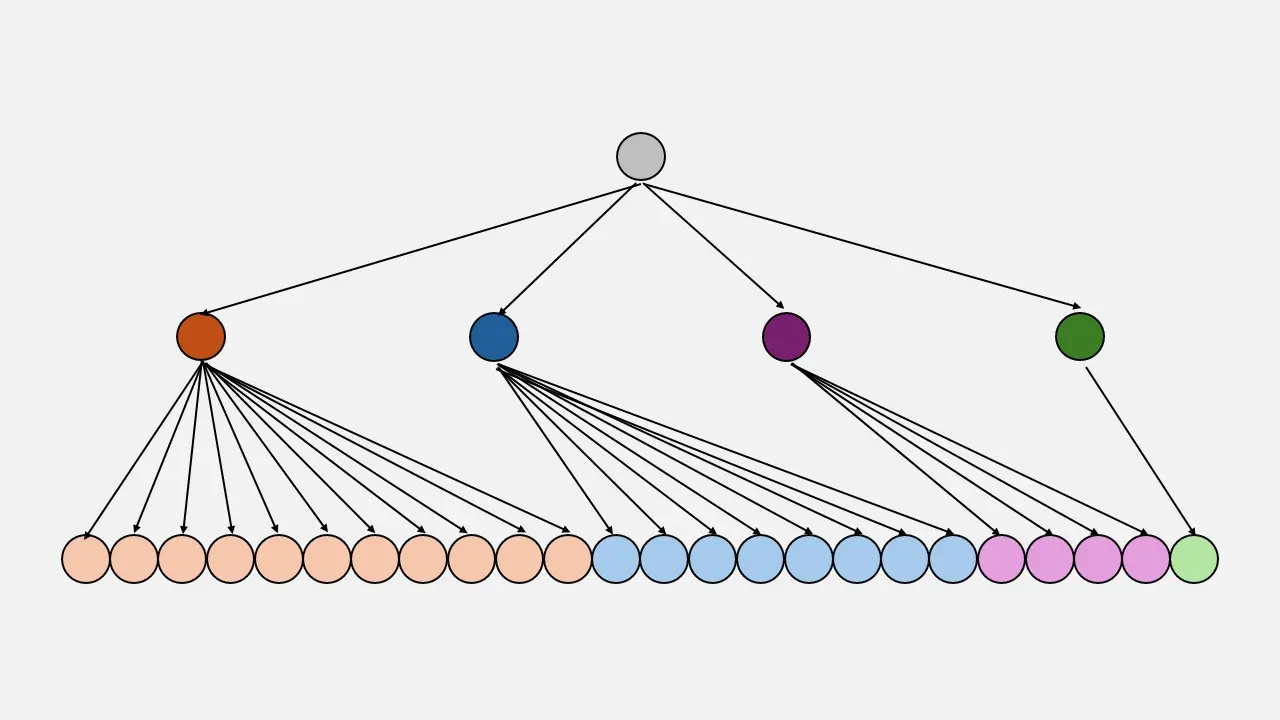
As can be seen in the image, the first token, which has the highest probability, has been repeated up to 11 times, the second up to 8 times, the third up to 4 times and the last one has only been added in 1 time.
To use this method we choose do_sample=True and top_k=0.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
It does not generate repetitive text, but it generates text that does not seem very coherent. This is the problem of being able to choose any word
Sampling temperature
To overcome the problem of the sampling method, a temperature parameter is added to adjust the level of randomness in word selection.
Temperature is a parameter that modifies how the probabilities of the following possible words are distributed.
With a temperature of 1, the probability distribution remains as learned by the model, maintaining a balance between predictability and creativity.
Lowering the temperature (less than 1) increases the weight of the most likely words, making the generated text more predictable and coherent, but less diverse and creative.
By increasing the temperature (more than 1), the probability difference between words is reduced, giving the less probable words a higher probability of being selected, which increases the diversity and creativity of the text, but may compromise its coherence and relevance.
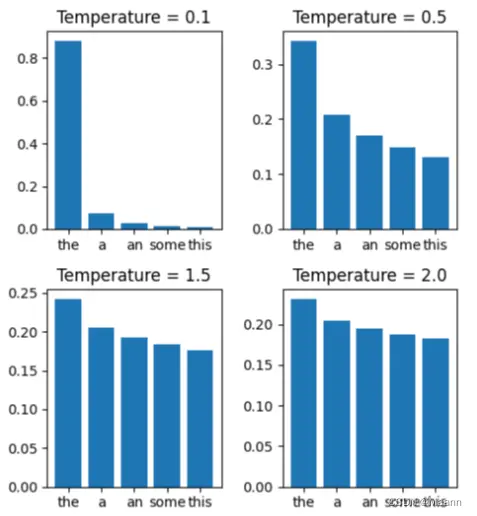
The temperature allows fine-tuning the balance between originality and coherence of the generated text, adjusting it to the specific needs of the task.
To add this parameter, we use the temperature parameter of the library
First we try a low value
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0, temperature=0.7)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
We can see that the generated text has more coherence, but it is repetitive again
We now try with a higher value
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0, temperature=1.3)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
We see that the text generated now is not repeated, but it does not make any sense.
Sampling top-k
Another way to solve the sampling problems is to select the most probable k words, so that now text is generated that may not be repetitive, but will have more coherence. This is the solution that was chosen in GPT-2
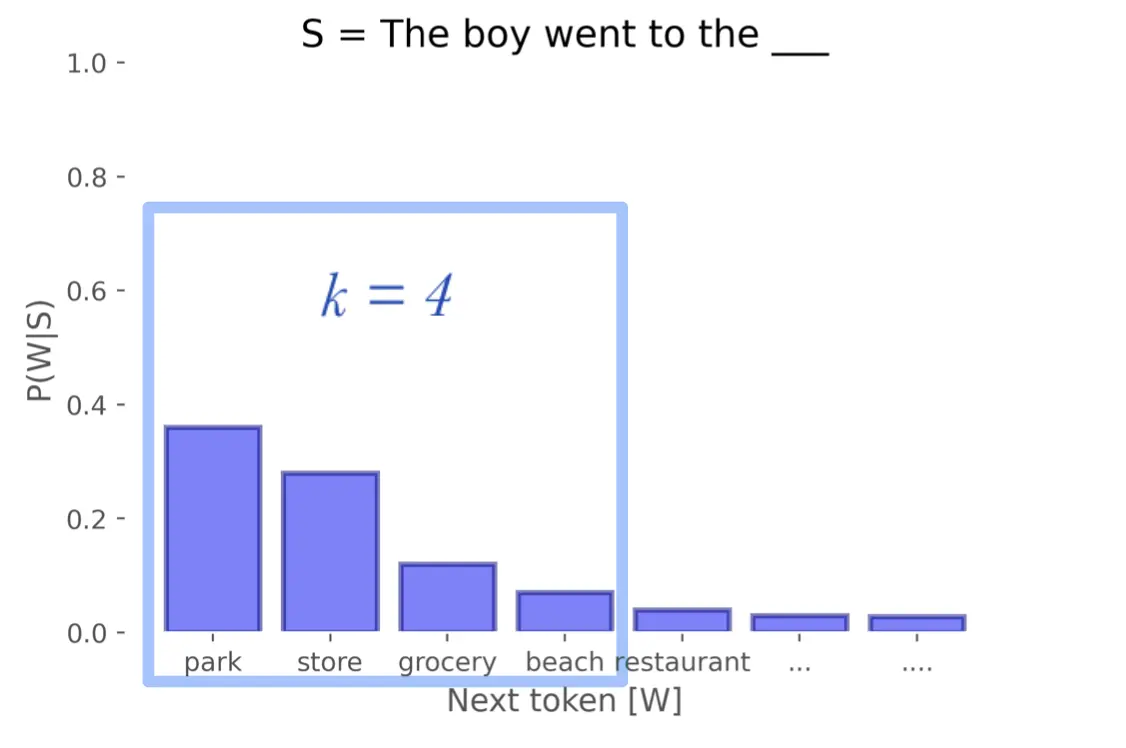
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=50)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
Now the text is not repetitive and has coherence
Sampling top-p (nucleus sampling)
With top-p what is done is to select the set of words that makes the sum of their probabilities greater than p (e.g. 0.9). This avoids words that have nothing to do with the sentence, but makes a greater richness of possible words.
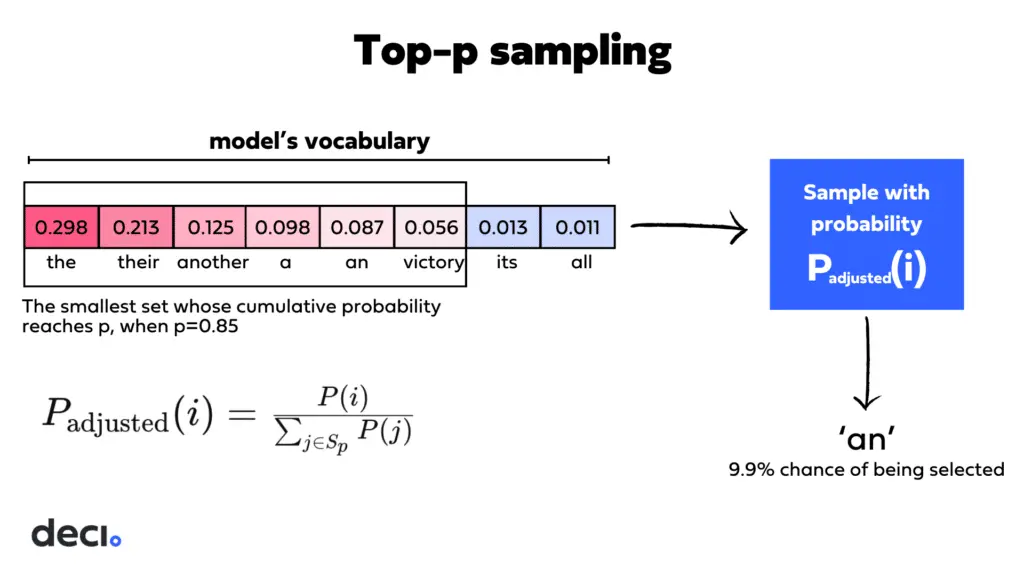
As can be seen in the image, if we add the probability of the first tokens we have a probability greater than 0.8, so we are left with those to generate the next token.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0, top_p=0.92)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
You get a very good text
Sampling top-k and top-p
When top-k and top-p are combined, very good results are obtained.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")
tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=50, top_p=0.95)
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)
print(sentence_output)
Effect of temperature, top-k y top-p
In this space from HuggingFace we can see the effect of temperature, top-k y top-p on text generation
Streaming
We can make the words come out one by one using the TextStreamer class.
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish")
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt")
streamer = TextStreamer(tokenizer)
_ = model.generate(**tokens_input, streamer=streamer, max_new_tokens=500, do_sample=True, top_k=50, top_p=0.95)
In this way, the output has been generated word by word.
Chat templates
Context tokenization
A very important use of LLMs is chatbots. When using a chatbot it is important to give it a context. However, the tokenization of this context is different for each model. So one way to tokenize this context is to use the apply_chat_template method of tokenizers.
For example, we see how the context of the facebook/blenderbot-400M-distill model is tokenized.
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, penalty_alpha=0.6, top_k=4)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, num_beams=1)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, do_sample=True)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, no_repeat_ngram_size=2)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_outputs = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, no_repeat_ngram_size=2, num_return_sequences=3)for i, tokens_output in enumerate(tokens_outputs):if i != 0:print(" ")sentence_output = tokenizer.decode(tokens_output, skip_special_tokens=True)print(f"{i}: {sentence_output}")from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, num_beam_groups=5, diversity_penalty=1.0)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)assistant_model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, assistant_model=assistant_model, do_sample=True)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)assistant_model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, assistant_model=assistant_model, do_sample=True, temperature=0.5)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0, temperature=0.7)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0, temperature=1.3)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=50)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0, top_p=0.92)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=50, top_p=0.95)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamertokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish")tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt")streamer = TextStreamer(tokenizer)_ = model.generate(**tokens_input, streamer=streamer, max_new_tokens=500, do_sample=True, top_k=50, top_p=0.95)from transformers import AutoTokenizercheckpoint = "facebook/blenderbot-400M-distill"tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")chat = [{"role": "user", "content": "Hola, ¿Cómo estás?"},{"role": "assistant", "content": "Estoy bien. ¿Cómo te puedo ayudar?"},{"role": "user", "content": "Me gustaría saber cómo funcionan los chat templates"},]input_token_chat_template = tokenizer.apply_chat_template(chat, tokenize=True, return_tensors="pt")print(f"input tokens chat_template: {input_token_chat_template}")input_chat_template = tokenizer.apply_chat_template(chat, tokenize=False, return_tensors="pt")print(f"input chat_template: {input_chat_template}")
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.input tokens chat_template: tensor([[ 391, 7521, 19, 5146, 131, 42, 135, 119, 773, 2736, 135, 102,90, 38, 228, 477, 300, 874, 275, 1838, 21, 5146, 131, 42,135, 119, 773, 574, 286, 3478, 86, 265, 96, 659, 305, 38,228, 228, 2365, 294, 367, 305, 135, 263, 72, 268, 439, 276,280, 135, 119, 773, 941, 74, 337, 295, 530, 90, 3879, 4122,1114, 1073, 2]])input chat_template: Hola, ¿Cómo estás? Estoy bien. ¿Cómo te puedo ayudar? Me gustaría saber cómo funcionan los chat templates</s>
As you can see, the context is tokenized simply by leaving blanks between the statements
Let us now see how it is tokenized for the mistralai/Mistral-7B-Instruct-v0.1 model.
from transformers import AutoTokenizercheckpoint = "mistralai/Mistral-7B-Instruct-v0.1"tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")chat = [{"role": "user", "content": "Hola, ¿Cómo estás?"},{"role": "assistant", "content": "Estoy bien. ¿Cómo te puedo ayudar?"},{"role": "user", "content": "Me gustaría saber cómo funcionan los chat templates"},]input_token_chat_template = tokenizer.apply_chat_template(chat, tokenize=True, return_tensors="pt")print(f"input tokens chat_template: {input_token_chat_template}")input_chat_template = tokenizer.apply_chat_template(chat, tokenize=False, return_tensors="pt")print(f"input chat_template: {input_chat_template}")
input tokens chat_template: tensor([[ 1, 733, 16289, 28793, 4170, 28708, 28725, 18297, 28743, 28825,5326, 934, 2507, 28804, 733, 28748, 16289, 28793, 14644, 904,9628, 28723, 18297, 28743, 28825, 5326, 711, 11127, 28709, 15250,554, 283, 28804, 2, 28705, 733, 16289, 28793, 2597, 319,469, 26174, 14691, 263, 21977, 5326, 2745, 296, 276, 1515,10706, 24906, 733, 28748, 16289, 28793]])input chat_template: <s>[INST] Hola, ¿Cómo estás? [/INST]Estoy bien. ¿Cómo te puedo ayudar?</s> [INST] Me gustaría saber cómo funcionan los chat templates [/INST]
We can see that this model puts the [INST] and [/INST] tags at the beginning and end of each statement
Add prompts generation
We can tell the tokenizer to to tokenize the context by adding the wizard shift by adding add_generation_prompt=True. Let's see, first we tokenize with add_generation_prompt=False.
from transformers import AutoTokenizercheckpoint = "HuggingFaceH4/zephyr-7b-beta"tokenizer = AutoTokenizer.from_pretrained(checkpoint)chat = [{"role": "user", "content": "Hola, ¿Cómo estás?"},{"role": "assistant", "content": "Estoy bien. ¿Cómo te puedo ayudar?"},{"role": "user", "content": "Me gustaría saber cómo funcionan los chat templates"},]input_chat_template = tokenizer.apply_chat_template(chat, tokenize=False, return_tensors="pt", add_generation_prompt=False)print(f"input chat_template: {input_chat_template}")
input chat_template: <|user|>Hola, ¿Cómo estás?</s><|assistant|>Estoy bien. ¿Cómo te puedo ayudar?</s><|user|>Me gustaría saber cómo funcionan los chat templates</s>
Now we do the same but with add_generation_prompt=True.
from transformers import AutoTokenizercheckpoint = "HuggingFaceH4/zephyr-7b-beta"tokenizer = AutoTokenizer.from_pretrained(checkpoint)chat = [{"role": "user", "content": "Hola, ¿Cómo estás?"},{"role": "assistant", "content": "Estoy bien. ¿Cómo te puedo ayudar?"},{"role": "user", "content": "Me gustaría saber cómo funcionan los chat templates"},]input_chat_template = tokenizer.apply_chat_template(chat, tokenize=False, return_tensors="pt", add_generation_prompt=True)print(f"input chat_template: {input_chat_template}")
input chat_template: <|user|>Hola, ¿Cómo estás?</s><|assistant|>Estoy bien. ¿Cómo te puedo ayudar?</s><|user|>Me gustaría saber cómo funcionan los chat templates</s><|assistant|>
As you can see it adds <|assistant|> at the end to help the LLM know that it is its turn to respond. This ensures that when the model generates text, it will write a bot response instead of doing something unexpected, such as continuing with the user's message
Not all models require generation prompts. Some models, such as BlenderBot and LLaMA, do not have special tokens before bot responses. In these cases, add_generation_prompt will have no effect. The exact effect add_generation_prompt will have depends on the model being used.
Text generation
As we can see it is easy to tokenize the context without needing to know how to do it for each model. So now let's see how to generate text is also very simple
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
checkpoint = "flax-community/gpt-2-spanish"
tokenizer = AutoTokenizer.from_pretrained(checkpoint, torch_dtype=torch.float16)
model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map=0, torch_dtype=torch.float16)
tokenizer.pad_token = tokenizer.eos_token
messages = [
{
"role": "system",
"content": "Eres un chatbot amigable que siempre de una forma graciosa",
},
{"role": "user", "content": "¿Cuántos helicópteros puede comer un ser humano de una sentada?"},
]
input_token_chat_template = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
output = model.generate(input_token_chat_template, max_new_tokens=128, do_sample=True)
sentence_output = tokenizer.decode(output[0])
print("")
print(sentence_output)
As you can see, the prompt has been tokenized with apply_chat_template and these tokens have been put into the model
Text generation with pipeline.
The transformers library also allows to use pipeline to generate text with a chatbot, doing underneath the same as we have done before
from transformers import pipeline
import torch
checkpoint = "flax-community/gpt-2-spanish"
generator = pipeline("text-generation", checkpoint, device=0, torch_dtype=torch.float16)
messages = [
{
"role": "system",
"content": "Eres un chatbot amigable que siempre de una forma graciosa",
},
{"role": "user", "content": "¿Cuántos helicópteros puede comer un ser humano de una sentada?"},
]
print("")
print(generator(messages, max_new_tokens=128)[0]['generated_text'][-1])
Train
So far we have used pretrained models, but in case you want to do fine tuning, the transformers library makes it very easy to do it
As nowadays language models are huge, retraining them is almost impossible on a GPU that anyone can have at home, so we are going to retrain a smaller model. In this case we are going to retrain bert-base-cased which is a 109M parameter model.
Dataset
We need to download a dataset, for this we use the datasets library of Hugging Face. We are going to use the Yelp reviews dataset.
from transformers import AutoModelForCausalLM, AutoTokenizerimport torchcheckpoint = "flax-community/gpt-2-spanish"tokenizer = AutoTokenizer.from_pretrained(checkpoint, torch_dtype=torch.float16)model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map=0, torch_dtype=torch.float16)tokenizer.pad_token = tokenizer.eos_tokenmessages = [{"role": "system","content": "Eres un chatbot amigable que siempre de una forma graciosa",},{"role": "user", "content": "¿Cuántos helicópteros puede comer un ser humano de una sentada?"},]input_token_chat_template = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")output = model.generate(input_token_chat_template, max_new_tokens=128, do_sample=True)sentence_output = tokenizer.decode(output[0])print("")print(sentence_output)from transformers import pipelineimport torchcheckpoint = "flax-community/gpt-2-spanish"generator = pipeline("text-generation", checkpoint, device=0, torch_dtype=torch.float16)messages = [{"role": "system","content": "Eres un chatbot amigable que siempre de una forma graciosa",},{"role": "user", "content": "¿Cuántos helicópteros puede comer un ser humano de una sentada?"},]print("")print(generator(messages, max_new_tokens=128)[0]['generated_text'][-1])from datasets import load_datasetdataset = load_dataset("yelp_review_full")
Let's see what the dataset looks like.
from transformers import AutoModelForCausalLM, AutoTokenizerimport torchcheckpoint = "flax-community/gpt-2-spanish"tokenizer = AutoTokenizer.from_pretrained(checkpoint, torch_dtype=torch.float16)model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map=0, torch_dtype=torch.float16)tokenizer.pad_token = tokenizer.eos_tokenmessages = [{"role": "system","content": "Eres un chatbot amigable que siempre de una forma graciosa",},{"role": "user", "content": "¿Cuántos helicópteros puede comer un ser humano de una sentada?"},]input_token_chat_template = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")output = model.generate(input_token_chat_template, max_new_tokens=128, do_sample=True)sentence_output = tokenizer.decode(output[0])print("")print(sentence_output)from transformers import pipelineimport torchcheckpoint = "flax-community/gpt-2-spanish"generator = pipeline("text-generation", checkpoint, device=0, torch_dtype=torch.float16)messages = [{"role": "system","content": "Eres un chatbot amigable que siempre de una forma graciosa",},{"role": "user", "content": "¿Cuántos helicópteros puede comer un ser humano de una sentada?"},]print("")print(generator(messages, max_new_tokens=128)[0]['generated_text'][-1])from datasets import load_datasetdataset = load_dataset("yelp_review_full")type(dataset)
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.datasets.dataset_dict.DatasetDict
It seems to be a kind of dictionary, let's see what keys it has.
dataset.keys()
dict_keys(['train', 'test'])
Let's see how many reviews you have in each subset
len(dataset["train"]), len(dataset["test"])
(650000, 50000)
Let's see a sample
dataset["train"][100]
{'label': 0,'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special! The cashier took my friends's order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid's meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for "serving off their orders" when they didn't have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards. The manager was rude when giving me my order. She didn't make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service. I've eaten at various McDonalds restaurants for over 30 years. I've worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
As we can see each sample has the text and punctuation, let's see how many types there are
clases = dataset["train"].featuresclases
{'label': ClassLabel(names=['1 star', '2 star', '3 stars', '4 stars', '5 stars'], id=None),'text': Value(dtype='string', id=None)}
We see that it has 5 different classes
num_classes = len(clases["label"].names)num_classes
5
Let's see a sample test
dataset["test"][100]
{'label': 0,'text': 'This was just bad pizza. For the money I expect that the toppings will be cooked on the pizza. The cheese and pepparoni were added after the crust came out. Also the mushrooms were out of a can. Do not waste money here.'}
As the aim of this post is not to train the best model, but to explain the transformers library of Hugging Face, we are going to make a small subset to be able to train faster
small_train_dataset = dataset["train"].shuffle(seed=42).select(range(1000))small_eval_dataset = dataset["test"].shuffle(seed=42).select(range(500))
Tokenization
We already have the dataset, as we have seen in the pipeline, first the tokenization is done and then the model is applied. So we have to tokenize the dataset.
We define the tokenizer
small_train_dataset = dataset["train"].shuffle(seed=42).select(range(1000))small_eval_dataset = dataset["test"].shuffle(seed=42).select(range(500))from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
The AutoTokenizer class has a method called map that allows us to apply a function to the dataset, so we are going to create a function that tokenizes the text
small_train_dataset = dataset["train"].shuffle(seed=42).select(range(1000))small_eval_dataset = dataset["test"].shuffle(seed=42).select(range(500))from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")def tokenize_function(examples):return tokenizer(examples["text"], padding=True, truncation=True, max_length=3)
As we can see at the moment we have tokenized truncating only 3 tokens, this is to be able to see better what is going on underneath
We use the map method to use the function that we have just defined on the dataset
small_train_dataset = dataset["train"].shuffle(seed=42).select(range(1000))small_eval_dataset = dataset["test"].shuffle(seed=42).select(range(500))from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")def tokenize_function(examples):return tokenizer(examples["text"], padding=True, truncation=True, max_length=3)tokenized_small_train_dataset = small_train_dataset.map(tokenize_function, batched=True)tokenized_small_eval_dataset = small_eval_dataset.map(tokenize_function, batched=True)
We see examples of the tokenized dataset
small_train_dataset = dataset["train"].shuffle(seed=42).select(range(1000))small_eval_dataset = dataset["test"].shuffle(seed=42).select(range(500))from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")def tokenize_function(examples):return tokenizer(examples["text"], padding=True, truncation=True, max_length=3)tokenized_small_train_dataset = small_train_dataset.map(tokenize_function, batched=True)tokenized_small_eval_dataset = small_eval_dataset.map(tokenize_function, batched=True)tokenized_small_train_dataset[100]
{'label': 3,'text': "I recently brough my car up to Edinburgh from home, where it had sat on the drive pretty much since I had left home to go to university. As I'm sure you can imagine, it was pretty filthy, so I pulled up here expecting to shell out £5 or so for a crappy was that wouldnt really be that great. Needless to say, when I realised that the cheapest was was £2, i was suprised and I was even more suprised when the car came out looking like a million dollars. Very impressive for £2, but thier prices can go up to around £6 - which I'm sure must involve so many polishes and waxes and cleans that dirt must be simply repelled from the body of your car, never getting dirty again.",'input_ids': [101, 146, 102],'token_type_ids': [0, 0, 0],'attention_mask': [1, 1, 1]}
tokenized_small_eval_dataset[100]
{'label': 4,'text': 'Had a great dinner at Elephant Bar last night! Got a coupon in the mail for 2 meals and an appetizer for $20! While they did limit the selections you could get with the coupon, we were happy with the choices so it worked out fine. Food was delicious and the service was fantastic! Waitress was very attentive and polite. Location was a plus too! Had a lovely walk around The District shops afterward. All and all, a hands down 5 stars!','input_ids': [101, 6467, 102],'token_type_ids': [0, 0, 0],'attention_mask': [1, 1, 1]}
As we can see, a key has been added with the input_ids of the tokens, the token_type_ids and another one with the attention mask.
We now tokenize by truncating to 20 tokens in order to use a small GPU.
def tokenize_function(examples):return tokenizer(examples["text"], padding=True, truncation=True, max_length=20)tokenized_small_train_dataset = small_train_dataset.map(tokenize_function, batched=True)tokenized_small_eval_dataset = small_eval_dataset.map(tokenize_function, batched=True)
Model
We have to create the model that we are going to retrain. As it is a classification problem we are going to use AutoModelForSequenceClassification.
def tokenize_function(examples):return tokenizer(examples["text"], padding=True, truncation=True, max_length=20)tokenized_small_train_dataset = small_train_dataset.map(tokenize_function, batched=True)tokenized_small_eval_dataset = small_eval_dataset.map(tokenize_function, batched=True)from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
As can be seen, a model has been created which classifies between 5 classes
Evaluation metrics
We create an evaluation metric with the evaluate library of Hugging Face. To install it we use
pip install evaluate
```
import numpy as npimport evaluatemetric = evaluate.load("accuracy")def compute_metrics(eval_pred):logits, labels = eval_predpredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)
Trainer
Now for training we use the Trainer object. In order to use Trainer we need accelerate>=0.21.0.
pip install accelerate>=0.21.0
```
Before creating the trainer we have to create a TrainingArguments which is an object that contains all the arguments that Trainer needs to train, i.e. the hyperparameters
A mandatory argument must be passed, output_dir which is the output directory where the model predictions and checkpoints, as Hugging Face calls the model weights, will be written.
We also pass on several other arguments
per_device_train_batch_size: size of batch per device for trainingper_device_eval_batch_size: batch size per device for the evaluationlearning_rate: learning ratenum_train_epochs: number of epochs
import numpy as npimport evaluatemetric = evaluate.load("accuracy")def compute_metrics(eval_pred):logits, labels = eval_predpredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)from transformers import TrainingArgumentstraining_args = TrainingArguments(output_dir="test_trainer",per_device_train_batch_size=16,per_device_eval_batch_size=32,learning_rate=1e-4,num_train_epochs=5,)
Let's take a look at all the hyperparameters that it configures
import numpy as npimport evaluatemetric = evaluate.load("accuracy")def compute_metrics(eval_pred):logits, labels = eval_predpredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)from transformers import TrainingArgumentstraining_args = TrainingArguments(output_dir="test_trainer",per_device_train_batch_size=16,per_device_eval_batch_size=32,learning_rate=1e-4,num_train_epochs=5,)training_args.__dict__
{'output_dir': 'test_trainer','overwrite_output_dir': False,'do_train': False,'do_eval': False,'do_predict': False,'evaluation_strategy': <IntervalStrategy.NO: 'no'>,'prediction_loss_only': False,'per_device_train_batch_size': 16,'per_device_eval_batch_size': 32,'per_gpu_train_batch_size': None,'per_gpu_eval_batch_size': None,'gradient_accumulation_steps': 1,'eval_accumulation_steps': None,'eval_delay': 0,'learning_rate': 0.0001,'weight_decay': 0.0,'adam_beta1': 0.9,'adam_beta2': 0.999,'adam_epsilon': 1e-08,'max_grad_norm': 1.0,'num_train_epochs': 5,'max_steps': -1,'lr_scheduler_type': <SchedulerType.LINEAR: 'linear'>,'lr_scheduler_kwargs': {},'warmup_ratio': 0.0,'warmup_steps': 0,'log_level': 'passive','log_level_replica': 'warning','log_on_each_node': True,'logging_dir': 'test_trainer/runs/Mar08_16-41-27_SAEL00531','logging_strategy': <IntervalStrategy.STEPS: 'steps'>,'logging_first_step': False,'logging_steps': 500,'logging_nan_inf_filter': True,'save_strategy': <IntervalStrategy.STEPS: 'steps'>,'save_steps': 500,'save_total_limit': None,'save_safetensors': True,'save_on_each_node': False,'save_only_model': False,'no_cuda': False,'use_cpu': False,'use_mps_device': False,'seed': 42,'data_seed': None,'jit_mode_eval': False,'use_ipex': False,'bf16': False,'fp16': False,'fp16_opt_level': 'O1','half_precision_backend': 'auto','bf16_full_eval': False,'fp16_full_eval': False,'tf32': None,'local_rank': 0,'ddp_backend': None,'tpu_num_cores': None,'tpu_metrics_debug': False,'debug': [],'dataloader_drop_last': False,'eval_steps': None,'dataloader_num_workers': 0,'dataloader_prefetch_factor': None,'past_index': -1,'run_name': 'test_trainer','disable_tqdm': False,'remove_unused_columns': True,'label_names': None,'load_best_model_at_end': False,'metric_for_best_model': None,'greater_is_better': None,'ignore_data_skip': False,'fsdp': [],'fsdp_min_num_params': 0,'fsdp_config': {'min_num_params': 0,'xla': False,'xla_fsdp_v2': False,'xla_fsdp_grad_ckpt': False},'fsdp_transformer_layer_cls_to_wrap': None,'accelerator_config': AcceleratorConfig(split_batches=False, dispatch_batches=None, even_batches=True, use_seedable_sampler=True),'deepspeed': None,'label_smoothing_factor': 0.0,'optim': <OptimizerNames.ADAMW_TORCH: 'adamw_torch'>,'optim_args': None,'adafactor': False,'group_by_length': False,'length_column_name': 'length','report_to': [],'ddp_find_unused_parameters': None,'ddp_bucket_cap_mb': None,'ddp_broadcast_buffers': None,'dataloader_pin_memory': True,'dataloader_persistent_workers': False,'skip_memory_metrics': True,'use_legacy_prediction_loop': False,'push_to_hub': False,'resume_from_checkpoint': None,'hub_model_id': None,'hub_strategy': <HubStrategy.EVERY_SAVE: 'every_save'>,'hub_token': None,'hub_private_repo': False,'hub_always_push': False,'gradient_checkpointing': False,'gradient_checkpointing_kwargs': None,'include_inputs_for_metrics': False,'fp16_backend': 'auto','push_to_hub_model_id': None,'push_to_hub_organization': None,'push_to_hub_token': None,'mp_parameters': '','auto_find_batch_size': False,'full_determinism': False,'torchdynamo': None,'ray_scope': 'last','ddp_timeout': 1800,'torch_compile': False,'torch_compile_backend': None,'torch_compile_mode': None,'dispatch_batches': None,'split_batches': None,'include_tokens_per_second': False,'include_num_input_tokens_seen': False,'neftune_noise_alpha': None,'distributed_state': Distributed environment: DistributedType.NONum processes: 1Process index: 0Local process index: 0Device: cuda,'_n_gpu': 1,'__cached__setup_devices': device(type='cuda', index=0),'deepspeed_plugin': None}
Now we create a Trainer object that will be in charge of training the model.
from transformers import Trainertrainer = Trainer(model=model,train_dataset=tokenized_small_train_dataset,eval_dataset=tokenized_small_eval_dataset,compute_metrics=compute_metrics,args=training_args,)
Once we have a Trainer, in which we have indicated the training dataset, the test dataset, the model, the evaluation metric and the arguments with the hyperparameters, we can train the model with the train method of the Trainer.
trainer.train()
We already have the model trained, as you can see, with very little code we can train a model very quickly.
I strongly advise learning Pytorch and training many models before using a high-level library like transformers, because you learn a lot of deep learning fundamentals and you can understand better what is going on, especially because you will learn a lot from your mistakes. But once you have gone through that period, using high-level libraries like transformers speeds up the development a lot.
Testing the model
Now that we have the model trained, let's test it with a text. As the dataset we have downloaded is of reviews in English, let's test it with a review in English
from transformers import Trainertrainer = Trainer(model=model,train_dataset=tokenized_small_train_dataset,eval_dataset=tokenized_small_eval_dataset,compute_metrics=compute_metrics,args=training_args,)trainer.train()from transformers import pipelineclasificator = pipeline("text-classification", model=model, tokenizer=tokenizer)
from transformers import Trainertrainer = Trainer(model=model,train_dataset=tokenized_small_train_dataset,eval_dataset=tokenized_small_eval_dataset,compute_metrics=compute_metrics,args=training_args,)trainer.train()from transformers import pipelineclasificator = pipeline("text-classification", model=model, tokenizer=tokenizer)clasification = clasificator("I'm liking this post a lot")clasification
0%| | 0/315 [00:00<?, ?it/s][{'label': 'LABEL_2', 'score': 0.5032550692558289}]
Let's see what the new class corresponds to.
clases
{'label': ClassLabel(names=['1 star', '2 star', '3 stars', '4 stars', '5 stars'], id=None),'text': Value(dtype='string', id=None)}
The relationship would be
- LABEL_0: 1 star
- LABEL_1: 2 stars
- LABEL_2: 3 stars
- LABEL_3: 4 stars
- LABEL_4: 5 stars
So you have rated the comment with 3 stars. Recall that we have is trained on a subset of data and with only 5 epochs, so we do not expect it to be very good.
Share the model in the Hugging Face Hub
Once we have the retrained model we can upload it to our space in the Hugging Face Hub so that others can use it. To do this you need to have a Hugging Face account.
Logging
In order to upload the model we first have to log in.
This can be done through the terminal with
huggingface-cli login
```
Or through the notebook having previously installed the `huggingface_hub` library with
````bash
pip install huggingface_hub
```
Now we can log in with the `notebook_login` function, which will create a small graphical interface where we have to enter a Hugging Face token.
To create a token, go to the setings/tokens page of your account, you will see something like this
Click on New token and a window will appear to create a new token.
We name the token and create it with the write role.
Once created, we copy it
from huggingface_hub import notebook_loginnotebook_login()
VBox(children=(HTML(value='<center> <img src=https://huggingface.co/front/assets/huggingface_logo-noborder.sv…
Up once trained
As we have trained the model we can upload it to the Hub using the push_to_hub function. This function has a mandatory parameter which is the name of the model, which has to be unique, if there is already a model in your Hub with that name it will not be uploaded. That is, the full name of the model will be
It also has other optional, but interesting, parameters:
use_temp_dir(bool, optional): Whether or not to use a temporary directory to store the saved files before they are sent to the Hub. Default will be True if there is no directory with the same name asrepo_id, False otherwise.commit_message(str, optional): Commit message. Default will beUpload {object}.private(bool, optional): Whether the created repository should be private or not.token(bool or str, optional): The token to use as HTTP authorization for remote files. If True, the token generated by runninghuggingface-clilogin (stored in ~/.huggingface) will be used. Default will be True ifrepo_urlis not specified.max_shard_size(int or str, optional, defaults to "5GB"): Only applicable to models. The maximum size of a checkpoint before it is fragmented. Fragmented checkpoints will each be smaller than this size. If expressed as a string, it must have digits followed by a unit (such as "5MB"). The default is "5GB" so that users can easily load models into free-level Google Colab instances without CPU OOM (out of memory) issues.create_pr(bool, optional, defaults to False): Whether or not to create a PR with the uploaded files or commit directly.safe_serialization(bool, optional, defaults to True): Whether or not to convert model weights to safetensors format for safer serialization.revision(str, optional): Branch to send uploaded files to.commit_description(str, optional): Description of the commit to be createdtags(List[str], optional): List of tags to insert in Hub.
model.push_to_hub(
"bert-base-cased_notebook_transformers_5-epochs_yelp_review_subset",
commit_message="bert base cased fine tune on yelp review subset",
commit_description="Fine-tuned on a subset of the yelp review dataset. Model retrained for post of transformers library. 5 epochs.",
)
If we now go to our Hub we can see that the model has been uploaded.

If we now go into the model card to see
We see that everything is unfilled, later we will do this
Climbing while training
Another option is to upload it while we are training the model. This is very useful when we train models for many periods and it takes us a long time, because if the training is stopped (because the computer is turned off, the colab session is finished, the cloud credits run out) the work is not lost. To do this you have to add push_to_hub=True in the TrainingArguments.
model.push_to_hub("bert-base-cased_notebook_transformers_5-epochs_yelp_review_subset",commit_message="bert base cased fine tune on yelp review subset",commit_description="Fine-tuned on a subset of the yelp review dataset. Model retrained for post of transformers library. 5 epochs.",)training_args = TrainingArguments(output_dir="bert-base-cased_notebook_transformers_30-epochs_yelp_review_subset",per_device_train_batch_size=16,per_device_eval_batch_size=32,learning_rate=1e-4,num_train_epochs=30,push_to_hub=True,)trainer = Trainer(model=model,train_dataset=tokenized_small_train_dataset,eval_dataset=tokenized_small_eval_dataset,compute_metrics=compute_metrics,args=training_args,)
We can see that we have changed the epochs to 30, so training is going to take longer, so adding push_to_hub=True will upload the model to our Hub while training.
We have also changed the output_dir because it is the name that the model will have in the Hub.
trainer.train()
If we look at our hub again, the new model is now displayed.
transformers_commit_training](https://pub-fb664c455eca46a2ba762a065ac900f7.r2.dev/transformers_commit_training.webp)
Hub as git repository
In Hugging Face both models, spaces and datasets are git repositories, so you can work with them like that. That is, you can clone, make forks, pull requests, etc.
But another great advantage of this is that you can use a model in a particular version.
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5, revision="393e083")
















{kind=link}