
Disclaimer: This post has been translated to English using a machine translation model. Please, let me know if you find any mistakes.
The increase in the size of language models makes them increasingly expensive to train due to the fact that more and more VRAM is required to store all their parameters and the gradients derived from training.
In the paper LoRA - Low rank adaption of large language models they propose to freeze the model weights and train two matrices called A and B, significantly reducing the number of parameters that need to be trained.
Let's see how this is done
Explanation of LoRA
Weight Update in a Neural Network
To understand how LoRA works, we first need to recall what happens when we train a model. Let's go back to the most basic part of deep learning; we have a dense layer of a neural network defined as:
y = Wx + b
Where W is the weight matrix and b is the bias vector.
To simplify, let's assume there is no bias, so it would be like this
y = Wx
Suppose for an input x we want it to have an output ŷ
- First, what we do is calculate the output we get with our current weight value W, that is, we obtain the value y
- Next, we calculate the error that exists between the value of y that we have obtained and the value that we wanted to obtain ŷ. We call this error loss, and we calculate it with some mathematical function, which does not matter now.
- We calculate the gradient (the derivative) of the loss with respect to the weight matrix W, that is \Delta W = \frac{dloss}{dW}
- We update the weights W by subtracting from each of their values the gradient value multiplied by a learning rate \alpha, that is W = W - \alpha \Delta W
LoRA
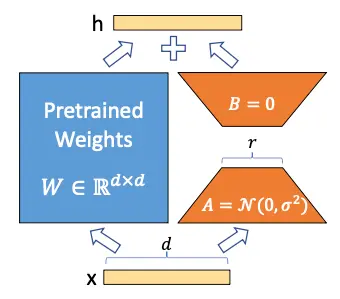
The authors of LoRA propose that the weight matrix W can be decomposed into
W \sim W + \Delta W
So by freezing the matrix W and training only the matrix \Delta W, one can obtain a model that adapts to new data without having to retrain the entire model.
But you might think that \Delta W is a matrix of the same size as W, so nothing has been gained, but here the authors draw on Aghajanyan et al. (2020), a paper in which they demonstrated that although language models are large and their parameters are matrices with very high dimensions, to adapt them to new tasks it is not necessary to change all the values of the matrices; changing just a few values is sufficient, which technically is called low-rank adaptation. Hence the name LoRA (Low Rank Adaptation).
We have frozen the model and now we want to train the matrix \Delta W. Let's assume that both W and \Delta W are matrices of size 20 × 10, so we have 200 trainable parameters.
Now suppose that the matrix \Delta W can be decomposed into the product of two matrices A and B, that is
\Delta W = A · B
For this multiplication to occur, the sizes of matrices A and B must be 20 × n and n × 10, respectively. Suppose that n = 5, so A would be of size 20 × 5, which is 100 parameters, and B of size 5 × 10, which is 50 parameters, resulting in 100+50=150 trainable parameters. We now have fewer trainable parameters than before.
Now suppose that W is actually a matrix of size 10.000 × 10.000, so we would have 100.000.000 trainable parameters, but if we decompose \Delta W into A and B with n = 5, we would have a matrix of size 10.000 × 5 and another of size 5 × 10.000, so we would have 50.000 parameters from one and 50.000 parameters from the other, in total 100.000 trainable parameters, that is, we have reduced the number of parameters 1000 times.
You can already see the power of LoRA, when dealing with very large models, the number of trainable parameters can be drastically reduced.
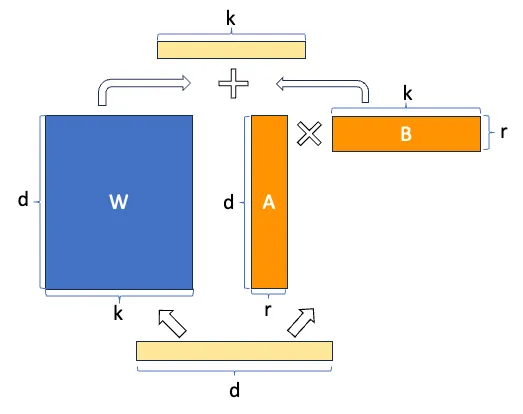
If we look back at the image of the LoRA architecture, we will understand it better
But it looks even better, the savings in the number of trainable parameters with this image
Implementation of LoRA in transformers
Since language models are implementations of transformers, we will see how LoRA is implemented in transformers. In the transformer architecture, there are linear layers in the attention matrices Q, K, and V, and in the feedforward layers, so LoRA can be applied to all these linear layers. The paper mentions that for simplicity, they apply it only to the linear layers of the attention matrices Q, K, and V.
These layers have a size of dmodel × dmodel, where dmodel is the model's embedding dimension.
Size of range r
To be able to have these benefits, the size of the range r has to be smaller than the size of the linear layers. As we mentioned that they only implemented it in the attention linear layers, which have a size of dmodel × dmodel, the size of the range r has to be smaller than dmodel.
Initialization of matrices A and B
The matrices A and B are initialized with a random Gaussian distribution for A and zero for B, so the product of both matrices will be zero at the beginning, that is
\Delta W = A · B = 0
Influence of LoRA through the parameter $\alpha$
Finally, in the implementation of LoRA, a parameter α is added to set the degree of influence of LoRA in the training. It is similar to the learning rate in normal fine-tuning, but in this case it is used to set the influence of LoRA in the training. In this way, the LoRA formula would be as follows
W = W + α \Delta W = W + α A · B
Advantages of LoRA
Now that we have understood how it works, let's look at the advantages of this method
- Reduction of trainable parameters. As we have seen, the number of trainable parameters is drastically reduced, which makes training much faster and requires less VRAM, thus saving many costs.* Adapters in production. We can have a single language model in production and several adapters, each for a different task, instead of having multiple models trained for each task, thus saving storage and computation costs. Additionally, this method does not necessarily add latency to inference because the original weight matrix can be fused with the adapter, as we have seen that W \sim W + \Delta W = W + A \cdot B, so the inference time would be the same as using the original language model.
- Share adapters. If we train an adapter, we can share only the adapter. That is, in production, everyone can have the original model and every time we train an adapter, we can share only the adapter, so as smaller matrices would be shared, the size of the files that are shared would be much smaller
Implementation of LoRA in an LLM
We are going to repeat the training code from the post Fine tuning SLMs, specifically the text classification training with Hugging Face libraries, but this time we will do it with LoRA. In the previous post, we used a batch size of 28 for the training loop and 40 for the evaluation loop. However, since we are not going to train all the model's weights this time, but only the LoRA matrices, we will be able to use a larger batch size.
Login in the Hub
We log in to upload the model to the Hub
from huggingface_hub import notebook_loginnotebook_login()Copied
Dataset
We download the dataset we are going to use, which is a review dataset from Amazon
from datasets import load_datasetdataset = load_dataset("mteb/amazon_reviews_multi", "en")datasetCopied
DatasetDict({train: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000})validation: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})test: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})})
We create a subset in case you want to test the code with a smaller dataset. In my case, I will use 100% of the dataset.
percentage = 1subset_dataset_train = dataset['train'].select(range(int(len(dataset['train']) * percentage)))subset_dataset_validation = dataset['validation'].select(range(int(len(dataset['validation']) * percentage)))subset_dataset_test = dataset['test'].select(range(int(len(dataset['test']) * percentage)))subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}))
We see a sample
from random import randintidx = randint(0, len(subset_dataset_train))subset_dataset_train[idx]Copied
{'id': 'en_0388304','text': 'The N was missing from on The N was missing from on','label': 0,'label_text': '0'}
We get the number of classes. To obtain the number of classes, we use dataset['train'] and not subset_dataset_train because if the subset is made too small, it's possible that there won't be examples with all the possible classes from the original dataset.
num_classes = len(dataset['train'].unique('label'))num_classesCopied
5
We create a function to create the label field in the dataset. The downloaded dataset has the field labels, but the transformers library requires that the field be called label and not labels.
def set_labels(example):example['labels'] = example['label']return exampleCopied
We apply the function to the dataset
subset_dataset_train = subset_dataset_train.map(set_labels)subset_dataset_validation = subset_dataset_validation.map(set_labels)subset_dataset_test = subset_dataset_test.map(set_labels)subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}))
We see a sample again
subset_dataset_train[idx]Copied
{'id': 'en_0388304','text': 'The N was missing from on The N was missing from on','label': 0,'label_text': '0','labels': 0}
Tokenizer
We implement the tokenizer. To avoid errors, we assign the end of string token to the padding token.
from transformers import AutoTokenizercheckpoint = "openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoint)tokenizer.pad_token = tokenizer.eos_tokenCopied
We create a function to tokenize the dataset
def tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=768, return_tensors="pt")Copied
We apply the function to the dataset and, at the same time, remove the columns we don't need.
subset_dataset_train = subset_dataset_train.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_validation = subset_dataset_validation.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_test = subset_dataset_test.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 200000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}))
We see a sample again, but in this case we only see the keys
subset_dataset_train[idx].keys()Copied
dict_keys(['labels', 'input_ids', 'attention_mask'])
Model
We instantiate the model. Also, to avoid errors, we assign the end of string token to the padding token.
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes)model.config.pad_token_id = model.config.eos_token_idCopied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
As we saw in the post Fine tuning SLMs we get a warning that says some layers have not been initialized. This is because, in this case, as it is a classification problem and when we instantiated the model we specified that we want it to be a classification model with 5 classes, the library has removed the last layer and replaced it with one that has 5 neurons at the output. If you don't fully understand this, check out the post I cited for a better explanation.
LoRA
Before implementing LoRA, we check the number of trainable parameters that the model has
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f"Total trainable parameters before: {total_params:,}")Copied
Total trainable parameters before: 124,443,648
We see that it has 124M trainable parameters. Now we are going to freeze them.
for param in model.parameters():param.requires_grad = Falsetotal_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f"Total trainable parameters after: {total_params:,}")Copied
Total trainable parameters after: 0
After freezing, there are no trainable parameters left.
Let's see how the model looks before applying LoRA
modelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
First we create the LoRA layer.
It has to inherit from torch.nn.Module so that it can act as a layer of a neural network
In the _init_ method we create the matrices A and B initialized as explained before, matrix A with a random Gaussian distribution and matrix B with zeros. We also create the parameters rank and alpha.
In the forward method we calculate LoRA as explained.
import torchclass LoRALayer(torch.nn.Module):def __init__(self, in_dim, out_dim, rank, alpha):super().__init__()self.A = torch.nn.Parameter(torch.empty(in_dim, rank))torch.nn.init.kaiming_uniform_(self.A, a=torch.sqrt(torch.tensor(5.)).item()) # similar to standard weight initializationself.B = torch.nn.Parameter(torch.zeros(rank, out_dim))self.alpha = alphadef forward(self, x):x = self.alpha * (x @ self.A @ self.B)return xCopied
Now we create a linear class with LoRA.
Just like before, inherit from torch.nn.Module so it can act as a layer of a neural network.
In the init method, we create a variable with the original linear layer of the network and another variable with the new LoRA layer that we had implemented earlier.
In the forward method, we add the outputs of the original linear layer and the LoRA layer.
class LoRALinear(torch.nn.Module):def __init__(self, linear, rank, alpha):super().__init__()self.linear = linearself.lora = LoRALayer(linear.in_features, linear.out_features, rank, alpha)def forward(self, x):return self.linear(x) + self.lora(x)Copied
Finally, we create a function that replaces the linear layers with the new linear layer with LoRA that we have created. What it does is if it finds a linear layer in the model, it replaces it with the linear layer with LoRA; otherwise, it applies the function within the sublayers of the layer.
def replace_linear_with_lora(model, rank, alpha):for name, module in model.named_children():if isinstance(module, torch.nn.Linear):# Replace the Linear layer with LinearWithLoRAsetattr(model, name, LoRALinear(module, rank, alpha))else:# Recursively apply the same function to child modulesreplace_linear_with_lora(module, rank, alpha)Copied
We apply the function to the model to replace the linear layers of the model with the new linear layer using LoRA
rank = 16alpha = 16replace_linear_with_lora(model, rank=rank, alpha=alpha)Copied
We now see the number of trainable parameters
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f"Total trainable LoRA parameters: {total_params:,}")Copied
Total trainable LoRA parameters: 12,368
We have gone from 124M trainable parameters to 12k trainable parameters, that is, we have reduced the number of trainable parameters by 10,000 times!
We revisit the model
modelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): LoRALinear((linear): Linear(in_features=768, out_features=5, bias=False)(lora): LoRALayer()))
Let's compare them layer by layer
| Original Model | Model with LoRA |
|---|---|
| GPT2ForSequenceClassification( | GPT2ForSequenceClassification( |
| (transformer): GPT2Model( | (transformer): GPT2Model( |
| (wte): Embedding(50257, 768) | (wte): Embedding(50257, 768) |
| (wpe): Embedding(1024, 768) | (wpe): Embedding(1024, 768) |
| (drop): Dropout(p=0.1, inplace=False) | (drop): Dropout(p=0.1, inplace=False) |
| (h): ModuleList( | (h): ModuleList( |
| (0-11): 12 x GPT2Block( | (0-11): 12 x GPT2Block( |
| (ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) | (ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) |
| (attn): GPT2Attention( | (attn): GPT2Attention( |
| (c_attn): Conv1D() | (c_attn): Conv1D() |
| (c_proj): Conv1D() | (c_proj): Conv1D() |
| (attn_dropout): Dropout(p=0.1, inplace=False) | (attn_dropout): Dropout(p=0.1, inplace=False) |
| (resid_dropout): Dropout(p=0.1, inplace=False) | (resid_dropout): Dropout(p=0.1, inplace=False) |
| ) | ) |
| (ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True) | (ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True) |
| (c_fc): Conv1D() | (c_fc): Conv1D() |
| (c_proj): Conv1D() | (c_proj): Conv1D() |
| (act): NewGELUActivation() | (act): NewGELUActivation() |
| (dropout): Dropout(p=0.1, inplace=False) | (dropout): Dropout(p=0.1, inplace=False) |
| ) | ) |
| ) | ) |
| ) | ) |
| (ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True) | (ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True) |
| ) | ) |
| (score): LoRALinear() | |
| (score): Linear(in_features=768, out_features=5, bias=False) | (linear): Linear(in_features=768, out_features=5, bias=False) |
| (lora): LoRALayer() | |
| ) | |
| ) | ) |
We see that they are the same except at the end, where in the original model there was a normal linear layer and in the model with LoRA there is a LoRALinear layer which inside has the original model's linear layer and a LoRALayer.
Training
Once the model has been instantiated with LoRA, we are going to train it as usual
As we mentioned, in the post Fine tuning SLMs we used a batch size of 28 for the training loop and 40 for the evaluation loop, while now that there are fewer trainable parameters we can use a larger batch size.
Why does this happen? When training a model, you need to store the model and its gradients in the GPU memory. Therefore, whether using LoRA or not, the model itself still needs to be stored. However, with LoRA, only the gradients of 12k parameters are stored, whereas without LoRA, the gradients of 128M parameters are stored. This means that with LoRA, less GPU memory is required, allowing for a larger batch size.
from transformers import TrainingArgumentsmetric_name = "accuracy"model_name = "GPT2-small-LoRA-finetuned-amazon-reviews-en-classification"LR = 2e-5BS_TRAIN = 400BS_EVAL = 400EPOCHS = 3WEIGHT_DECAY = 0.01training_args = TrainingArguments(model_name,eval_strategy="epoch",save_strategy="epoch",learning_rate=LR,per_device_train_batch_size=BS_TRAIN,per_device_eval_batch_size=BS_EVAL,num_train_epochs=EPOCHS,weight_decay=WEIGHT_DECAY,lr_scheduler_type="cosine",warmup_ratio = 0.1,fp16=True,load_best_model_at_end=True,metric_for_best_model=metric_name,push_to_hub=True,logging_dir="./runs",)Copied
import numpy as npfrom evaluate import loadmetric = load("accuracy")def compute_metrics(eval_pred):print(eval_pred)predictions, labels = eval_predpredictions = np.argmax(predictions, axis=1)return metric.compute(predictions=predictions, references=labels)Copied
from transformers import Trainertrainer = Trainer(model,training_args,train_dataset=subset_dataset_train,eval_dataset=subset_dataset_validation,tokenizer=tokenizer,compute_metrics=compute_metrics,)Copied
trainer.train()Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7cd07be46440><transformers.trainer_utils.EvalPrediction object at 0x7cd07be45c30><transformers.trainer_utils.EvalPrediction object at 0x7cd07be8b970>
TrainOutput(global_step=1500, training_loss=1.8345018310546874, metrics={'train_runtime': 2565.4667, 'train_samples_per_second': 233.876, 'train_steps_per_second': 0.585, 'total_flos': 2.352076406784e+17, 'train_loss': 1.8345018310546874, 'epoch': 3.0})
Evaluation
Once trained, we evaluate on the test dataset
trainer.evaluate(eval_dataset=subset_dataset_test)Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7cd07be8bbe0>
{'eval_loss': 1.5203168392181396,'eval_accuracy': 0.3374,'eval_runtime': 19.3843,'eval_samples_per_second': 257.94,'eval_steps_per_second': 0.671,'epoch': 3.0}
Publish the model
We already have our model trained, so we can share it with the world. First, we create a **model card**.
trainer.create_model_card()Copied
And now we can publish it. Since the first thing we did was log in to the Hugging Face hub, we can upload it to our hub without any issues.
trainer.push_to_hub()Copied
Test of the model
We clean everything as much as possible
import torchimport gcdef clear_hardwares():torch.clear_autocast_cache()torch.cuda.ipc_collect()torch.cuda.empty_cache()gc.collect()clear_hardwares()clear_hardwares()Copied
Since we have uploaded the model to our hub, we can download and use it
from transformers import pipelineuser = "maximofn"checkpoints = f"{user}/{model_name}"task = "text-classification"classifier = pipeline(task, model=checkpoints, tokenizer=checkpoints)Copied
Now if we want it to return the probability of all classes, we simply use the classifier we just instantiated, with the parameter top_k=None
labels = classifier("I love this product", top_k=None)labelsCopied
[{'label': 'LABEL_0', 'score': 0.8419149518013},{'label': 'LABEL_1', 'score': 0.09386005252599716},{'label': 'LABEL_3', 'score': 0.03624210134148598},{'label': 'LABEL_2', 'score': 0.02049318142235279},{'label': 'LABEL_4', 'score': 0.0074898069724440575}]
If we only want the class with the highest probability, we do the same but with the parameter top_k=1
label = classifier("I love this product", top_k=1)labelCopied
[{'label': 'LABEL_0', 'score': 0.8419149518013}]
And if we want n classes, we do the same but with the parameter top_k=n
two_labels = classifier("I love this product", top_k=2)two_labelsCopied
[{'label': 'LABEL_0', 'score': 0.8419149518013},{'label': 'LABEL_1', 'score': 0.09386005252599716}]
We can also test the model with Automodel and AutoTokenizer
from transformers import AutoTokenizer, AutoModelForSequenceClassificationimport torchmodel_name = "GPT2-small-finetuned-amazon-reviews-en-classification"user = "maximofn"checkpoint = f"{user}/{model_name}"num_classes = num_classestokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes).half().eval().to("cuda")Copied
tokens = tokenizer.encode("I love this product", return_tensors="pt").to(model.device)with torch.no_grad():output = model(tokens)logits = output.logitslables = torch.softmax(logits, dim=1).cpu().numpy().tolist()lables[0]Copied
[0.003940582275390625,0.00266265869140625,0.013946533203125,0.1544189453125,0.8251953125]
If you want to try the model further, you can see it at Maximofn/GPT2-small-LoRA-finetuned-amazon-reviews-en-classification
Implementation of LoRA in a LLM with PEFT from Hugging Face
We can do the same with the PEFT library from Hugging Face. Let's see it.
Login to the Hub
We log in to upload the model to the Hub
from huggingface_hub import notebook_loginnotebook_login()Copied
Dataset
We download the dataset again
from datasets import load_datasetdataset = load_dataset("mteb/amazon_reviews_multi", "en")datasetCopied
DatasetDict({train: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000})validation: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})test: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})})
We create a subset in case you want to test the code with a smaller dataset. In my case, I will use 100% of the dataset.
percentage = 1subset_dataset_train = dataset['train'].select(range(int(len(dataset['train']) * percentage)))subset_dataset_validation = dataset['validation'].select(range(int(len(dataset['validation']) * percentage)))subset_dataset_test = dataset['test'].select(range(int(len(dataset['test']) * percentage)))subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}))
We get the number of classes. To obtain the number of classes, we use dataset['train'] and not subset_dataset_train because if the subset is very small, it's possible that there are no examples with all the possible classes from the original dataset.
num_classes = len(dataset['train'].unique('label'))num_classesCopied
5
We create a function to create the label field in the dataset. The downloaded dataset has the labels field, but the transformers library requires that the field be named label and not labels.
def set_labels(example):example['labels'] = example['label']return exampleCopied
We apply the function to the dataset
subset_dataset_train = subset_dataset_train.map(set_labels)subset_dataset_validation = subset_dataset_validation.map(set_labels)subset_dataset_test = subset_dataset_test.map(set_labels)subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}))
Tokenizer
We instantiate the tokenizer. To avoid errors, we assign the end of string token to the padding token.
from transformers import AutoTokenizercheckpoint = "openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoint)tokenizer.pad_token = tokenizer.eos_tokenCopied
We create a function to tokenize the dataset
def tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=768, return_tensors="pt")Copied
We apply the function to the dataset and at the same time remove the columns we don't need.
subset_dataset_train = subset_dataset_train.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_validation = subset_dataset_validation.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_test = subset_dataset_test.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 200000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}))
Model
We instantiate the model. Also, to avoid errors, we assign the end-of-string token to the padding token.
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes)model.config.pad_token_id = model.config.eos_token_idCopied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
LoRA with PEFT
Before creating the model with LoRA, let's take a look at its layers
modelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
As we can see, there is only one Linear layer, which is score and that is the one we are going to replace.
We can create a LoRA configuration with the PEFT library and then apply LoRA to the mo
from peft import LoraConfig, TaskTypepeft_config = LoraConfig(r=16,lora_alpha=32,lora_dropout=0.1,task_type=TaskType.SEQ_CLS,target_modules=["score"],)Copied
With this configuration, we have set a rank of 16 and an alpha of 32. Additionally, we have added a dropout to the LoRA layers of 0.1. We need to specify the task for the LoRA configuration, in this case it is a sequence classification task. Finally, we indicate which layers we want to replace, in this case the score layer.
Now we apply LoRA to the model
from peft import get_peft_modelmodel = get_peft_model(model, peft_config)Copied
Let's see how many trainable parameters the model has now.
model.print_trainable_parameters()Copied
trainable params: 12,368 || all params: 124,456,016 || trainable%: 0.0099
We obtain the same trainable parameters as before
Training
Once the model has been instantiated with LoRA, we are going to train it as usual
from transformers import TrainingArgumentsmetric_name = "accuracy"model_name = "GPT2-small-PEFT-LoRA-finetuned-amazon-reviews-en-classification"LR = 2e-5BS_TRAIN = 400BS_EVAL = 400EPOCHS = 3WEIGHT_DECAY = 0.01training_args = TrainingArguments(model_name,eval_strategy="epoch",save_strategy="epoch",learning_rate=LR,per_device_train_batch_size=BS_TRAIN,per_device_eval_batch_size=BS_EVAL,num_train_epochs=EPOCHS,weight_decay=WEIGHT_DECAY,lr_scheduler_type="cosine",warmup_ratio = 0.1,fp16=True,load_best_model_at_end=True,metric_for_best_model=metric_name,push_to_hub=True,logging_dir="./runs",)Copied
import numpy as npfrom evaluate import loadmetric = load("accuracy")def compute_metrics(eval_pred):print(eval_pred)predictions, labels = eval_predpredictions = np.argmax(predictions, axis=1)return metric.compute(predictions=predictions, references=labels)Copied
from transformers import Trainertrainer = Trainer(model,training_args,train_dataset=subset_dataset_train,eval_dataset=subset_dataset_validation,tokenizer=tokenizer,compute_metrics=compute_metrics,)Copied
trainer.train()Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7f774a50bbe0>
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7f77486a7c40><transformers.trainer_utils.EvalPrediction object at 0x7f7749eb5690>
TrainOutput(global_step=1500, training_loss=1.751504597981771, metrics={'train_runtime': 2551.7753, 'train_samples_per_second': 235.13, 'train_steps_per_second': 0.588, 'total_flos': 2.352524525568e+17, 'train_loss': 1.751504597981771, 'epoch': 3.0})
Evaluation
Once trained, we evaluate on the test dataset
trainer.evaluate(eval_dataset=subset_dataset_test)Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7f77a1d1f7c0>
{'eval_loss': 1.4127237796783447,'eval_accuracy': 0.3862,'eval_runtime': 19.3275,'eval_samples_per_second': 258.699,'eval_steps_per_second': 0.673,'epoch': 3.0}
Publish the model
We create a model card
trainer.create_model_card()Copied
We publish it
trainer.push_to_hub()Copied
CommitInfo(commit_url='https://huggingface.co/Maximofn/GPT2-small-PEFT-LoRA-finetuned-amazon-reviews-en-classification/commit/839066c2bde02689a6b3f5624ac25f89c4de217d', commit_message='End of training', commit_description='', oid='839066c2bde02689a6b3f5624ac25f89c4de217d', pr_url=None, pr_revision=None, pr_num=None)
Test of the model trained with PEFT
We clean everything as much as possible
import torchimport gcdef clear_hardwares():torch.clear_autocast_cache()torch.cuda.ipc_collect()torch.cuda.empty_cache()gc.collect()clear_hardwares()clear_hardwares()Copied
Since we have uploaded the model to our hub, we can download and use it
from transformers import pipelineuser = "maximofn"checkpoints = f"{user}/{model_name}"task = "text-classification"classifier = pipeline(task, model=checkpoints, tokenizer=checkpoints)Copied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
If we want to get the probability of all classes, we simply use the classifier we just instantiated, with the parameter top_k=None
labels = classifier("I love this product", top_k=None)labelsCopied
[{'label': 'LABEL_1', 'score': 0.9979197382926941},{'label': 'LABEL_0', 'score': 0.002080311067402363}]
If we only want the class with the highest probability, we do the same but with the parameter top_k=1
label = classifier("I love this product", top_k=1)labelCopied
[{'label': 'LABEL_1', 'score': 0.9979197382926941}]
And if we want n classes, we do the same but with the parameter top_k=n
two_labels = classifier("I love this product", top_k=2)two_labelsCopied
[{'label': 'LABEL_1', 'score': 0.9979197382926941},{'label': 'LABEL_0', 'score': 0.002080311067402363}]
If you want to try the model further, you can check it out at Maximofn/GPT2-small-PEFT-LoRA-finetuned-amazon-reviews-en-classification

















