Disclaimer: This post has been translated to English using a machine translation model. Please, let me know if you find any mistakes.
For me, the best description of mixtral-8x7b is the following image

There was only a very short gap between the release of gemini and the release of mixtral-8x7b. For the first two days after gemini launched, there was quite a bit of talk about that model, but as soon as mixtral-8x7b came out, gemini was completely forgotten, and the entire community couldn't stop talking about mixtral-8x7b.
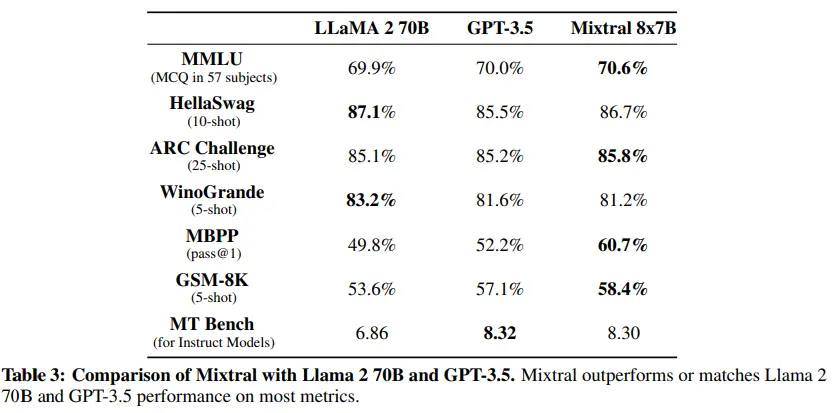
And it's no wonder, looking at its benchmarks, we can see that it is on par with models like llama2-70B and GPT3.5, but with the difference being that while mixtral-8x7b has only 46.7B parameters, llama2-70B has 70B and GPT3.5 has 175B.
Number of parameters
As the name suggests, mixtral-8x7b is a set of 8 models with 7B parameters each, so we might think it has 56B parameters (7Bx8), but that's not the case. As Andrej Karpathy explains, only the Feed forward blocks of the transformers are multiplied by 8, while the rest of the parameters are shared among the 8 models. Therefore, the final model has 46.7B parameters.
Mixture of Experts (MoE)
As we have said, the model is a set of 8 models with 7B parameters, hence MoE, which stands for Mixture of Experts. Each of the 8 models is trained independently, but during inference, a router decides which model's output will be used.
In the following image we can see what the architecture of a Transformer looks like.
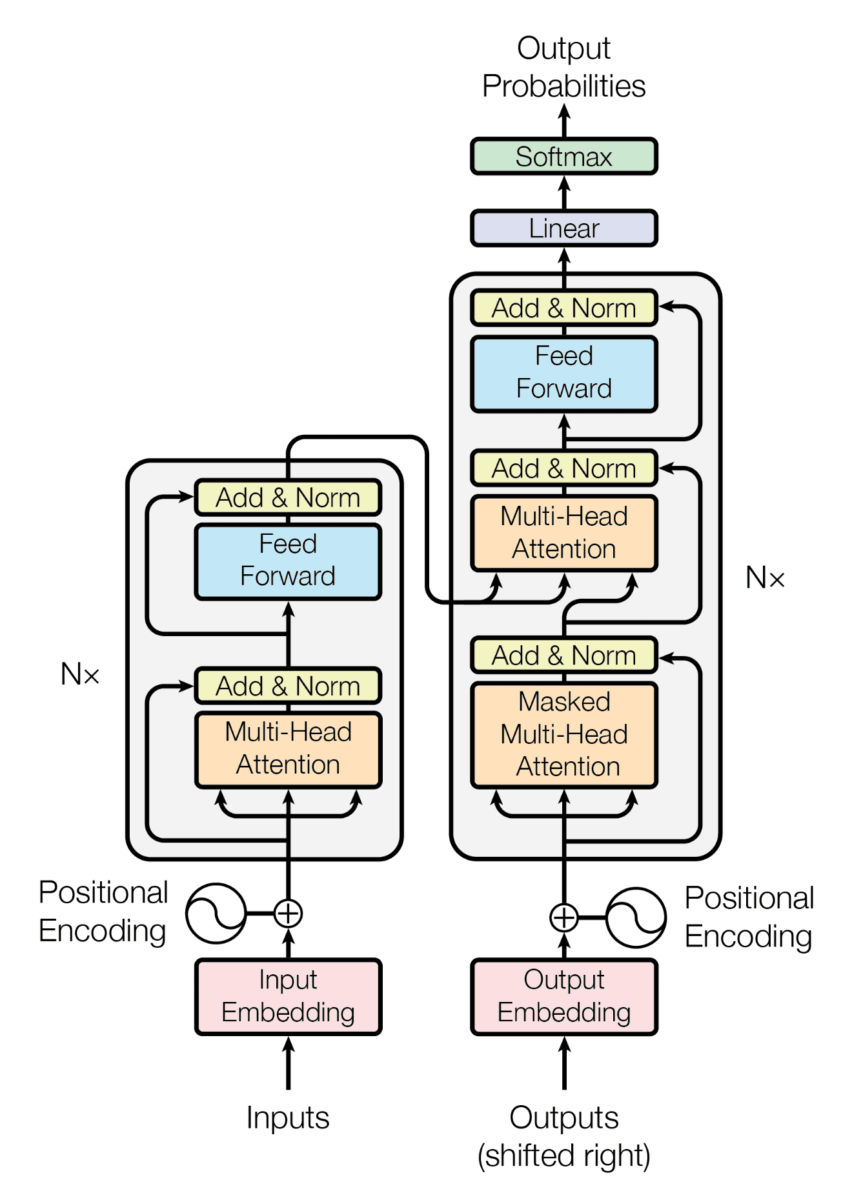
If you don't know it, that's fine. The important thing is that this architecture consists of an encoder and a decoder.
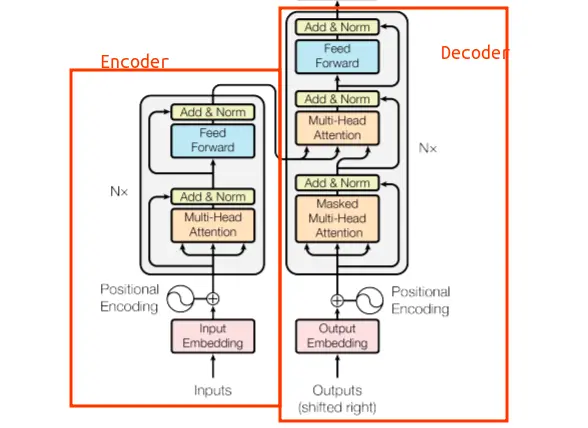
LLMs are models that only have the decoder, so they do not have an encoder. You can see that in the architecture there are three attention modules, one of which actually connects the encoder with the decoder. But since LLMs do not have an encoder, the attention module that connects the decoder and the decoder is not necessary.
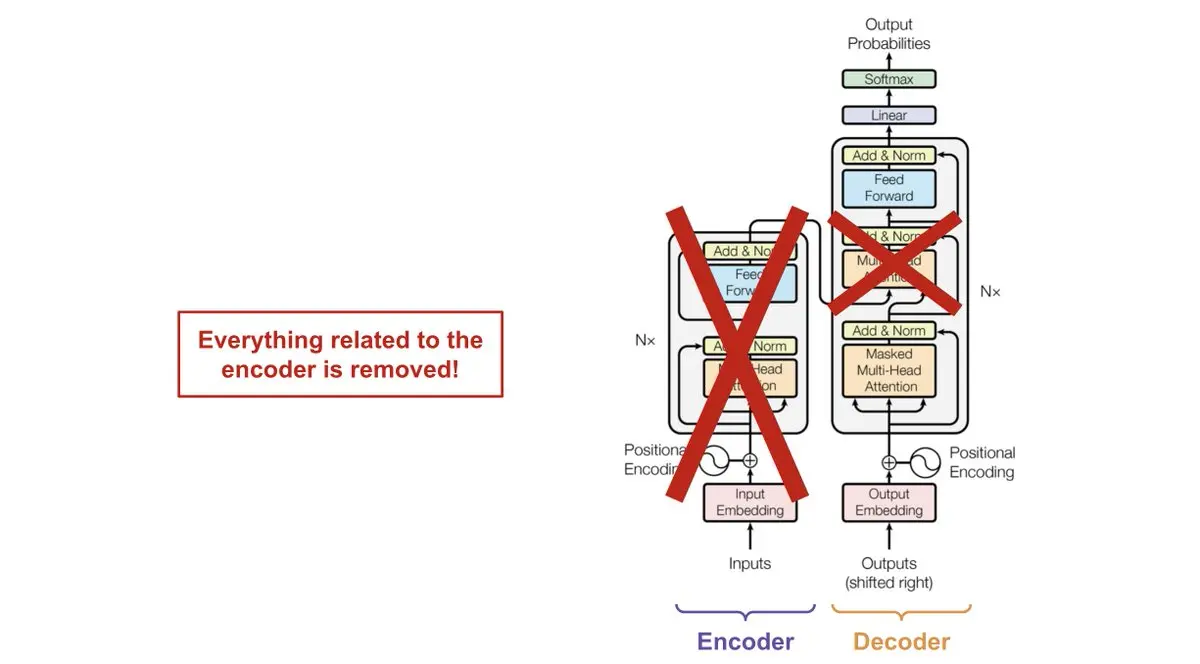
Now that we know how the architecture of an LLM works, we can look at the architecture of mixtral-8x7b. In the following image, we can see the architecture of the model.
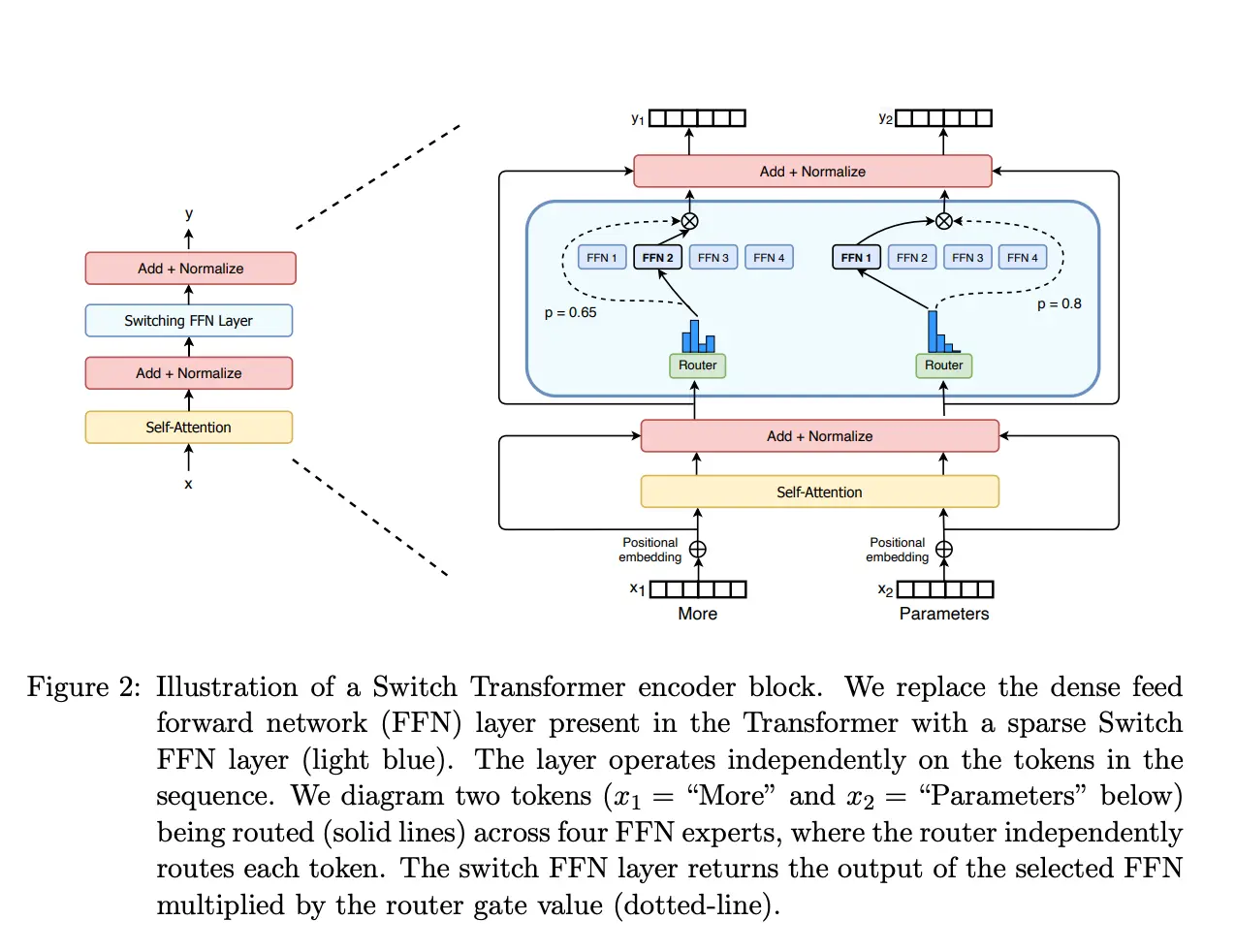
As can be seen, the architecture consists of the decoder of a 7B parameter Transformer, except that the Feed forward layer consists of 8 Feed forward layers with a router that chooses which of the 8 Feed forward layers will be used. In the previous image, only four Feed forward layers are shown, I suppose this is to simplify the diagram, but in reality there are 8 Feed forward layers. Two paths for two different words are also visible, the word More and the word Parameters, and how the router chooses which Feed forward layer will be used for each word.
Looking at the architecture, we can understand why the model has 46.7B parameters and not 56B. As we have said, only the Feed forward blocks are multiplied by 8, the rest of the parameters are shared among the 8 models.
Using Mixtral-8x7b in the Cloud
Unfortunately, using mixtral-8x7b locally is complicated due to the following hardware requirements:
- float32: VRAM > 180 GB, that is, since each parameter occupies 4 bytes, we need 46.7B * 4 = 186.8 GB of VRAM just to store the model, in addition to this, we must add the VRAM required to store the input and output data
- float16: VRAM > 90 GB, in this case each parameter takes up 2 bytes, so we need 46.7B * 2 = 93.4 GB of VRAM just to store the model, and on top of that, we need to add the VRAM required to store the input and output data
- 8-bit: VRAM > 45 GB, here each parameter takes up 1 byte, so we need 46.7B * 1 = 46.7 GB of VRAM just to store the model, in addition to that, we need to add the VRAM required to store the input and output data* 4-bit: VRAM > 23 GB, here each parameter takes up 0.5 bytes, so we need 46.7B * 0.5 = 23.35 GB of VRAM just to store the model, in addition to that, we have to add the VRAM needed to store the input and output data
We need some very powerful GPUs to be able to run it, even when we use the model quantized to 4 bits.
Therefore, the simplest way to use Mixtral-8x7B is by using it already deployed in the cloud. I have found several sites where you can use it
Using Mixtral-8x7b in Hugging Face Chat
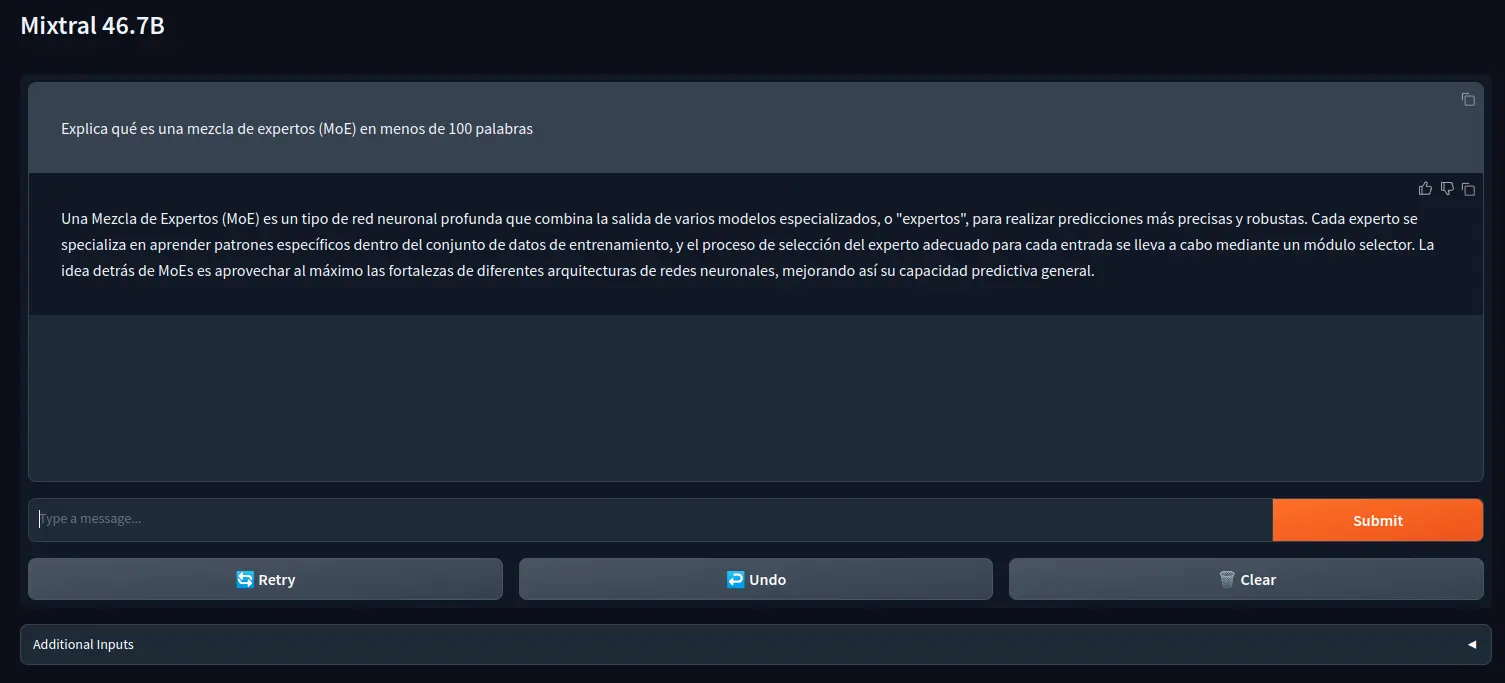
The first one is on huggingface chat. To use it, you need to click on the gear icon inside the Current Model box and select Mistral AI - Mixtral-8x7B. Once selected, you can start chatting with the model.
Once inside, select mistralai/Mixtral-8x7B-Instruct-v0.1 and finally click the Activate button. Now we can test the model.
As you can see, I asked him in Spanish what MoE is and he explained it to me.
Use of Mixtral-8x7b in Perplexity Labs
Another option is to use Perplexity Labs. Once inside, you need to select mixtral-8x7b-instruct from a dropdown menu in the bottom right corner.
As you can see, I also asked him in Spanish what MoE is and he explained it to me.
Using Mixtral-8x7b Locally via the Hugging Face API
A way to use it locally, regardless of the hardware resources you have, is through the huggingface API. For this, you need to install the huggingface-hub library from huggingface.
InputPython%pip install huggingface-hubCopied
Here is an implementation with gradio
InputPythonfrom huggingface_hub import InferenceClientimport gradio as grclient = InferenceClient("mistralai/Mixtral-8x7B-Instruct-v0.1")def format_prompt(message, history):prompt = "<s>"for user_prompt, bot_response in history:prompt += f"[INST] {user_prompt} [/INST]"prompt += f" {bot_response}</s> "prompt += f"[INST] {message} [/INST]"return promptdef generate(prompt, history, system_prompt, temperature=0.9, max_new_tokens=256, top_p=0.95, repetition_penalty=1.0,):temperature = float(temperature)if temperature < 1e-2:temperature = 1e-2top_p = float(top_p)generate_kwargs = dict(temperature=temperature, max_new_tokens=max_new_tokens, top_p=top_p, repetition_penalty=repetition_penalty, do_sample=True, seed=42,)formatted_prompt = format_prompt(f"{system_prompt}, {prompt}", history)stream = client.text_generation(formatted_prompt, **generate_kwargs, stream=True, details=True, return_full_text=False)output = ""for response in stream:output += response.token.textyield outputreturn outputadditional_inputs=[gr.Textbox(label="System Prompt", max_lines=1, interactive=True,),gr.Slider(label="Temperature", value=0.9, minimum=0.0, maximum=1.0, step=0.05, interactive=True, info="Higher values produce more diverse outputs"),gr.Slider(label="Max new tokens", value=256, minimum=0, maximum=1048, step=64, interactive=True, info="The maximum numbers of new tokens"),gr.Slider(label="Top-p (nucleus sampling)", value=0.90, minimum=0.0, maximum=1, step=0.05, interactive=True, info="Higher values sample more low-probability tokens"),gr.Slider(label="Repetition penalty", value=1.2, minimum=1.0, maximum=2.0, step=0.05, interactive=True, info="Penalize repeated tokens")]gr.ChatInterface(fn=generate,chatbot=gr.Chatbot(show_label=False, show_share_button=False, show_copy_button=True, likeable=True, layout="panel"),additional_inputs=additional_inputs,title="Mixtral 46.7B",concurrency_limit=20,).launch(show_api=False)Copied