FastRTC: La Biblioteca de Comunicación en Tiempo Real para Python
En los últimos meses, hemos visto un gran avance en modelos de voz en tiempo real, con empresas enteras fundadas alrededor de modelos tanto de código abierto como cerrado. Algunos hitos importantes incluyen:
OpenAIyGooglelanzaron sus APIs multimodales en vivo para ChatGPT y Gemini. ¡OpenAI incluso lanzó un número de teléfono1-800-ChatGPT!Kyutailanzó Moshi, un LLM de audio a audio completamente de código abierto.Alibabalanzó Qwen2-Audio, un LLM de código abierto que entiende audio de forma nativa.Fixie.ailanzó Ultravox, otro LLM de código abierto que también entiende audio de forma nativa.ElevenLabsrecaudó 180 millones de dólares en su Serie C.
A pesar de esta explosión en modelos y financiación, sigue siendo difícil construir aplicaciones de IA en tiempo real que transmitan audio y video, especialmente en Python.
- Los ingenieros de ML pueden no tener experiencia con las tecnologías necesarias para construir aplicaciones en tiempo real, como
WebRTC. - Incluso herramientas de asistencia de código como
CursoryCopilottienen dificultades para escribir código Python que soporte aplicaciones de audio/video en tiempo real.
Por eso es emocionante el anuncio de FastRTC, la biblioteca de comunicación en tiempo real para Python. ¡La biblioteca está diseñada para facilitar la construcción de aplicaciones de IA de audio y video en tiempo real completamente en Python!
Características principales de FastRTC
- 🗣️ Detección de voz automática y toma de turnos incorporada, para que solo tengas que preocuparte por la lógica de respuesta al usuario.
- 💻 UI automática - UI de Gradio habilitada para WebRTC incorporada para pruebas (¡o despliegue a producción!).
- 📞 Llamada por teléfono - Usa
fastphone()para obtener un número de teléfono gratuito para llamar a tu stream de audio (se requiere un token HF). - ⚡️ Soporte para
WebRTCyWebsocket. - 💪 Personalizable - Puedes montar el stream en cualquier aplicación
FastAPIpara servir una UI personalizada y desplegar más allá deGradio. - 🧰 Muchas utilidades para
text-to-speech,speech-to-text,detección de paradapara ayudarte a comenzar.
Instalación
Para poder usar FastRTC, primero necesitas instalar la biblioteca:
pip install fastrtcPero si queremos instalar las funcionalidades de detección de pausa, speech-to-text y text-to-speech, necesitamos instalar algunas dependencias adicionales:
pip install "fastrtc[vad, stt, tts]"Primeros pasos
Empezaremos construyendo el hola mundo del audio en tiempo real: hacer eco de lo que dice el usuario. En FastRTC, esto es tan simple como:
from fastrtc import Stream, ReplyOnPauseimport numpy as npdef echo(audio: tuple[int, np.ndarray]) -> tuple[int, np.ndarray]:yield audiostream = Stream(ReplyOnPause(echo), modality="audio", mode="send-receive")stream.ui.launch()
* Running on local URL: http://127.0.0.1:7872To create a public link, set `share=True` in `launch()`.
Cuando vamos al enlace que nos sugiere Gradio, primero tenemos que dar permisos al navegador para acceder al micrófono. A continuación nos aparecerá esto
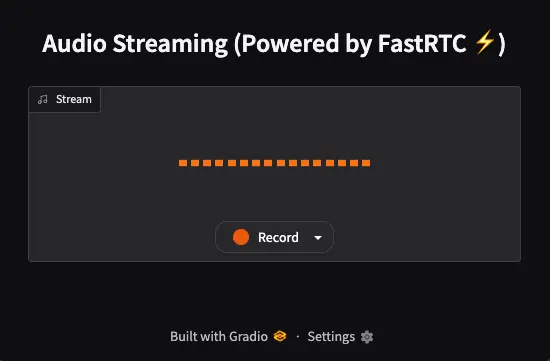
Si pinchamos en la pestaña de la derecha de la palabra Record podemos seleccionar el micrófono que queremos usar.
A continuación si pulsamos en el botón de Record, todo lo que digamos, la aplicación lo repetirá. Es decir captura el audio, detecta cuando hemos dejado de hablar y lo repite.
Vamos a desglosarlo:
ReplyOnPausemanejará la detección de voz y la toma de turnos por ti. Solo tienes que preocuparte por la lógica para responder al usuario. Hay que pasarle la función que se encargará de gestionar el audio de entrada. En nuestro caso es la funciónecho, que captura el audio de entrada y lo devuelve en stream mediante el uso deyield, que mucha gente no conoce, pero es un generador, es decir, es un método de python para crear iteradores. Si quieres saber más sobreyieldpuedes leer mi post de Python. Cualquier generador que devuelva una tupla de audio (representada como(sample_rate, audio_data)) funcionará.- La clase
Streamconstruirá una UI de Gradio para que puedas probar rápidamente tu stream. Una vez que hayas terminado de prototipar, puedes desplegar tu Stream como una aplicación FastAPI lista para producción en una sola línea de código
Aquí podemos ver un ejemplo de los creadores de FastRTC
Subiendo de nivel: Chat de voz con LLM
El siguiente nivel es usar un LLM para responder al usuario. FastRTC viene con capacidades de speech-to-text y text-to-speech incorporadas, por lo que trabajar con LLMs es realmente fácil. Vamos a cambiar nuestra función echo en consecuencia:
from fastrtc import ReplyOnPause, Stream, get_stt_model, get_tts_modelfrom gradio_client import Clientclient = Client("Maximofn/SmolLM2_localModel")stt_model = get_stt_model()tts_model = get_tts_model()def echo(audio):prompt = stt_model.stt(audio)response = client.predict(message=prompt,system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")prompt = responsefor audio_chunk in tts_model.stream_tts_sync(prompt):yield audio_chunkstream = Stream(ReplyOnPause(echo), modality="audio", mode="send-receive")stream.ui.launch()
Loaded as API: https://maximofn-smollm2-localmodel.hf.space ✔* Running on local URL: http://127.0.0.1:7871To create a public link, set `share=True` in `launch()`.
Como modelo de speech-to-text usa Moonshine que supuestamente solo soporta inglés, pero lo he probado en español y me entiende bien.
Como modelo de lenguaje vamos a usar el modelo que desplegué en un backend en Hugging Face y que escribí en el post Desplegar backend con LLM en HuggingFace. Utiliza el LLM HuggingFaceTB/SmolLM2-1.7B-Instruct que es un modelo pequeño, ya que está corriendo en un backend con CPU, pero que funciona bastante bien.
Como modelo de text-to-speech usa Kokoro que sí tiene opciones de hablar en otros idiomas, pero que de momento en la librería de FastRTC de momento no está implementado.
Si nos interesa mucho usar modelos de speech-to-speech y text-to-speech en otros idiomas, podríamos implementarlos nosotros mismos, porque el mayor potencial de FastRTC está en la capa de comunicación en tiempo real, pero no me voy a meter en eso ahora.
Ahora sí probamos el código que acabamos de escribir podemos tener un chatbot, por voz en tiempo real.
Llamada por teléfono
Generamos un script, porque en un Jupyter Notebook no siempre funciona
%%writefile fastrtc_phone_demo.pyfrom fastrtc import ReplyOnPause, Stream, get_stt_model, get_tts_modelimport gradiofrom gradio_client import Clientimport osfrom gradio.networking import setup_tunnel as original_setup_tunnelimport socket# Monkey patch setup_tunnel para que acepte el parámetro adicionaldef patched_setup_tunnel(host, port, share_token, share_server_address, share_server_tls_certificate=None):return original_setup_tunnel(host, port, share_token, share_server_address, share_server_tls_certificate)# Replace the original function with our patched versiongradio.networking.setup_tunnel = patched_setup_tunnel# Get the token from the environment variableHUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN = os.getenv("HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN")# Initialize the LLM clientllm_client = Client("Maximofn/SmolLM2_localModel")# Initialize the STT and TTS modelsstt_model = get_stt_model()tts_model = get_tts_model()# Define the echo functiondef echo(audio):# Convert the audio to textprompt = stt_model.stt(audio)# Generate the responseresponse = llm_client.predict(message=prompt,system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")# Convert the response to audioprompt = response# Stream the audiofor audio_chunk in tts_model.stream_tts_sync(prompt):yield audio_chunkdef find_free_port(start_port=8000, max_port=9000):"""Find the first free port starting from start_port."""print(f"Searching for a free port starting from {start_port}...")for port in range(start_port, max_port):with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:result = sock.connect_ex(('127.0.0.1', port))if result != 0: # If result != 0, the port is freeprint(f"Free port found: {port}")return portraise RuntimeError(f"No free port found between {start_port} and {max_port}")free_port = find_free_port() # Search for a free portstream = Stream(ReplyOnPause(echo), modality="audio", mode="send-receive")stream.fastphone(token=HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN, port=free_port)
Explicamos el código
La parte
# Monkey patch setup_tunnel para que acepte el parámetro adicional
def patched_setup_tunnel(host, port, share_token, share_server_address, share_server_tls_certificate=None):
return original_setup_tunnel(host, port, share_token, share_server_address, share_server_tls_certificate)
# Replace the original function with our patched version
gradio.networking.setup_tunnel = patched_setup_tunnel
Es necesario porque FastRTC está escrito para una versión antigua de gradio que no soporta el parámetro share_server_address en el método setup_tunnel. Así que lo parcheamos para que acepte el parámetro adicional.
Como es necesario un token de Hugging Face, lo obtenemos de la variable de entorno HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN.
# Get the token from the environment variable
HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN = os.getenv("HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN")
A continuación se crean los modelos de lenguaje, de speech-to-text y de text-to-speech, y creamos la función echo que se encargará de gestionar el audio de entrada y salida.
# Initialize the LLM client
llm_client = Client("Maximofn/SmolLM2_localModel")
# Initialize the STT and TTS models
stt_model = get_stt_model()
tts_model = get_tts_model()
# Define the echo function
def echo(audio):
# Convert the audio to text
prompt = stt_model.stt(audio)
# Generate the response
response = llm_client.predict(
message=prompt,
system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",
max_tokens=512,
temperature=0.7,
top_p=0.95,
api_name="/chat"
)
# Convert the response to audio
prompt = response
# Stream the audio
for audio_chunk in tts_model.stream_tts_sync(prompt):
yield audio_chunk
Como antes hemos usado el puerto 8000, por si os dice que está ocupado, creamos una función para encontrar un puerto libre y encontramos uno
def find_free_port(start_port=8000, max_port=9000):
"""Find the first free port starting from start_port."""
print(f"Searching for a free port starting from {start_port}...")
for port in range(start_port, max_port):
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:
result = sock.connect_ex(('127.0.0.1', port))
if result != 0: # If result != 0, the port is free
print(f"Free port found: {port}")
return port
raise RuntimeError(f"No free port found between {start_port} and {max_port}")
free_port = find_free_port() # Search for a free port
Se crea el stream y ahora se usa stream.fastphone() para obtener un número de teléfono gratuito para llamar a tu stream, en vez de stream.ui.launch() que usamos antes para crear la interfaz gráfica.
stream = Stream(ReplyOnPause(echo), modality="audio", mode="send-receive")
stream.fastphone(token=HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN, port=free_port)
Si lo ejecutamos, veremos algo como esto:
!python fastrtc_phone_demo.py
Loaded as API: https://maximofn-smollm2-localmodel.hf.space ✔INFO: Warming up STT model.INFO: STT model warmed up.INFO: Warming up VAD model.INFO: VAD model warmed up.Searching for a free port starting from 8000...Free port found: 8004INFO: Started server process [24029]INFO: Waiting for application startup.INFO: Visit https://fastrtc.org/userguide/api/ for WebRTC or Websocket API docs.INFO: Application startup complete.INFO: Uvicorn running on http://127.0.0.1:8004 (Press CTRL+C to quit)INFO: Your FastPhone is now live! Call +1 877-713-4471 and use code 994514 to connect to your stream.INFO: You have 30:00 minutes remaining in your quota (Resetting on 2025-04-07)INFO: Visit https://fastrtc.org/userguide/audio/#telephone-integration for information on making your handler compatible with phone usage.
Vemos que aparece
INFO: Your FastPhone is now live! Call +1 877-713-4471 and use code 994514 to connect to your stream.
INFO: You have 30:00 minutes remaining in your quota (Resetting on 2025-04-07)
Es decir, si llamamos al número +1 877-713-4471 y usamos el código 994514 nos conectará a nuestro stream.
Si nos vamos a Telephone Integration de la documentación de FastRTC veremos que usa twilio para hacer la llamada. Tiene opción para configurar un número local desde estados unidos, Dublin, Frankfurt, Tokio, Singapur, Sidney y Sao Paulo.
He probado a hacer la llamada desde España (que me va a costar bastante) y funciona, pero es lento. He llamado, he metido el código y he estado esperando a que conectara con el agente, pero como estaba tardando mucho, he colgado.