Paper
Improving Language Understanding by Generative Pre-Training es el paper de GPT1. Antes de leer el post es necesario que te pongas en situación, antes de GPT los modelos de lenguaje estaban basados en redes recurrentes (RNN), que eran redes que funcionaban relativamente bien para tareas específicas, pero con las que no se podía reutilizar el preentrenamiento para hacerles un fine tuning para otras tareas. Además no tenían mucha memoria, por lo que si se le metían frases muy largas no recordaban muy bien el inicio de la frase
Arquitectura
Antes de hablar de la arquitectura de GPT1 recordemos cómo era la arquitectura de los transformers
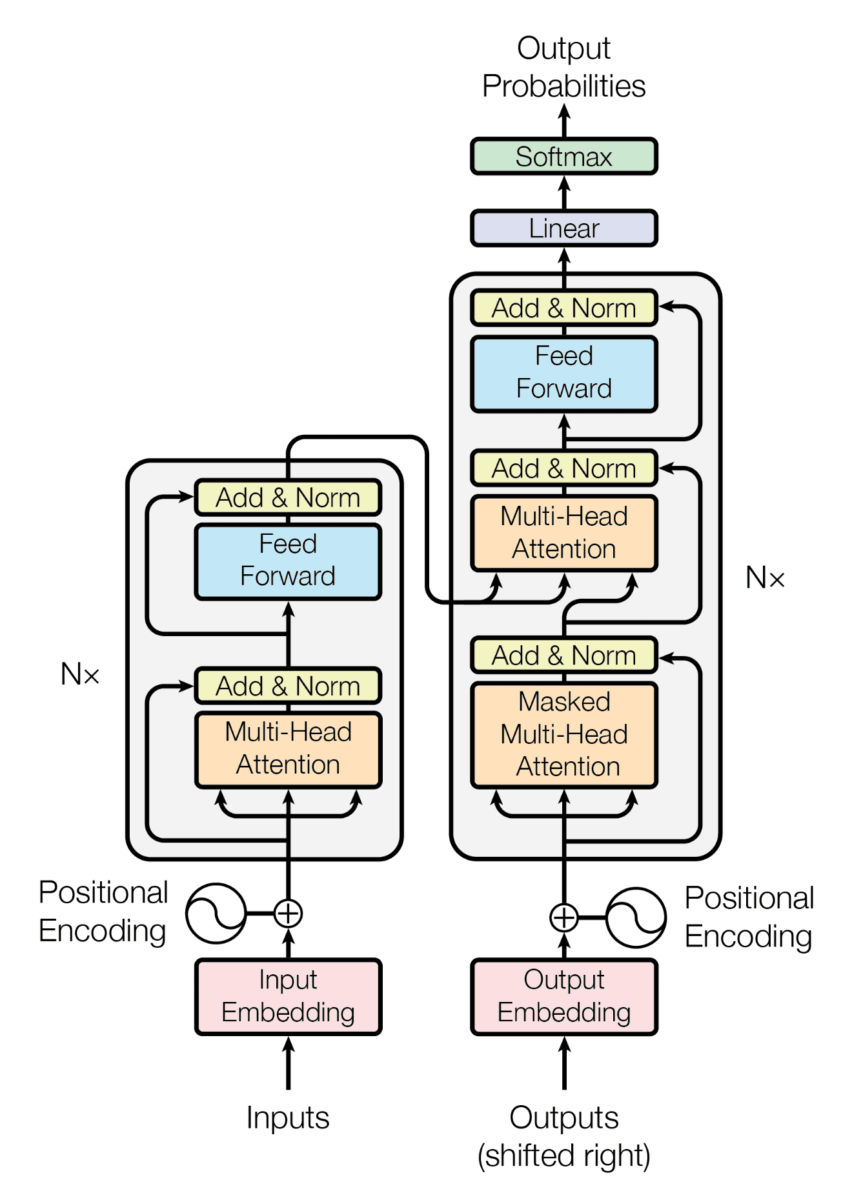
GPT1 es un modelo basado en los decoders de los transformers, así que como no tenemos encoder la arquitectura de un solo decoder queda de la siguiente manera
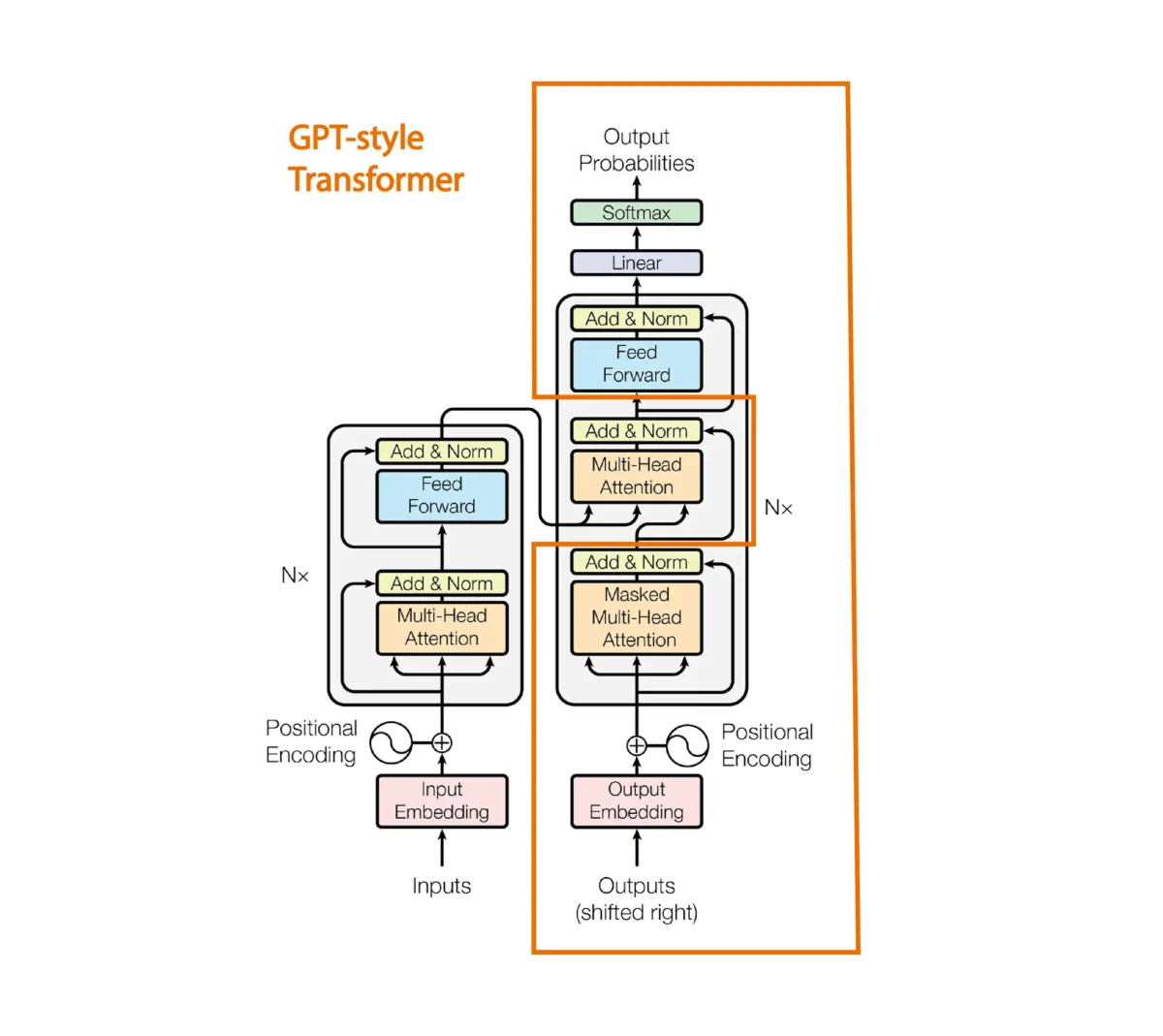
Se elimina el mecanismo de atención entre la sentencia del encoder y del decoder
En el paper de GPT1 proponen la siguiente arquitectura
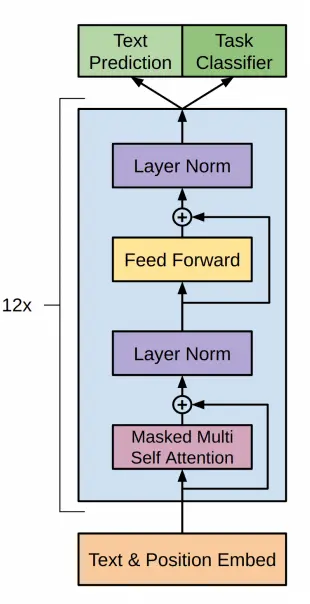
Que corresponde al decoder de un transformer como hemos visto antes, ejecutado 12 veces
Resumen del paper
Las ideas más interesantes del paper son:
- Se entrena el modelo en un gran corpus de texto sin supervisión. Con esto se consigue crear un modelado del lenguaje. Se crea un modelo de lenguaje de alta capacidad en un gran corpus de texto
- Luego se hace un fine-tuning en tareas de NLP supervisadas con datasets etiquetados. Se realiza un ajuste fino en una tarea objetivo con supervisión. Además, cuando se evalúa al modelo en la tarea supervisada, no solo se le evalúa por esa tarea, sino por lo bien que predice el siguiente token, esto ayuda a mejorar la generalización del modelo supervisado y hace que el modelo converja más rápido.
- Aunque ya lo hemos contado, en el paper se dice que se utiliza la arquitectura transformer, ya que hasta ese momento se usaban RNN para los modelos de lenguaje. Lo que produjo una mejora en que lo aprendido en el primer entrenamiento (entrenamiento en el corpus de texto sin supervisión) es más fácil de transferir a tareas supervisadas. Es decir, gracias al uso de transformers se pudo hacer un entrenamiento en todo un corpus de texto y luego fine tunings en tareas supervisadas.
- Evaluaron el modelo en cuatro tipos de tareas de comprensión del lenguaje:
- Inferencia del lenguaje natural
- Respuesta a preguntas
- Similitud semántica
- Clasificación de textos.
- El modelo general (el entrenado en todo el corpus de texto sin supervisión) supera a los modelos RNN entrenados discriminativamente que emplean arquitecturas diseñadas específicamente para cada tarea, mejorando significativamente el estado del arte en 9 de las 12 tareas estudiadas. También analizan los comportamientos de "disparo cero" del modelo preentrenado en cuatro entornos diferentes y demostraron que adquiere un conocimiento lingüístico útil para las tareas posteriores.
- En los últimos años, los investigadores habían demostrado los beneficios de utilizar embeddings, que se entrenan en corpus no etiquetados, para mejorar el rendimiento en una variedad de tareas. Sin embargo, estos enfoques transfieren principalmente información a nivel de palabra, mientras que el uso de transformers entrenados en grandes corpus de texto sin supervisión captura la semántica de nivel superior, a nivel de frase.
Generación de texto
Vamos a ver cómo generar texto con un GPT1 preentrenado
Primero hay que instalar ftfy y spacy mediante
pip install ftfy spacyUna vez instaladas, debes descargar el modelo de lenguaje de spacy que deseas utilizar. Por ejemplo, para descargar el modelo de inglés, puedes ejecutar:
python -m spacy download en_core_web_smPara generar texto vamos a utilizar el modelo desde el repositorio de GPT1 de Hugging Face.
Importamos las librerías
import torchfrom transformers import OpenAIGPTTokenizer, OpenAIGPTLMHeadModel, AutoTokenizerCopied
Si te fijas hemos importado OpenAIGPTTokenizer y AutoTokenizer. Esto es porque en la model card de GPT1 se indica que se use OpenAIGPTTokenizer, pero en el post de la librería transformers explicamos que se debe usar AutoTokenizer para cargar el tokenizador. Así que vamos a probar los dos
ckeckpoints = "openai-community/openai-gpt"tokenizer = OpenAIGPTTokenizer.from_pretrained(ckeckpoints)auto_tokenizer = AutoTokenizer.from_pretrained(ckeckpoints)input_tokens = tokenizer("Hello, my dog is cute and", return_tensors="pt")input_auto_tokens = auto_tokenizer("Hello, my dog is cute and", return_tensors="pt")print(f"input tokens: {input_tokens}")print(f"input auto tokens: {input_auto_tokens}")Copied
input tokens:{'input_ids': tensor([[3570, 240, 547, 2585, 544, 4957, 488]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}input auto tokens:{'input_ids': tensor([[3570, 240, 547, 2585, 544, 4957, 488]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}
Como se puede ver con los dos tokenizadores se obtienen los mismos tokens. Así que para que el código sea más general, de manera que si se cambian los checkpoints, no haya que cambiar el código, vamos a utilizar AutoTokenizer
Creamos entonces el device, el tokenizador y el modelo
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")tokenizer = AutoTokenizer.from_pretrained(ckeckpoints)model = OpenAIGPTLMHeadModel.from_pretrained(ckeckpoints).to(device)Copied
Como hemos instanciado el modelo, vamos a ver cuántos parámetros tiene
params = sum(p.numel() for p in model.parameters())print(f"Number of parameters: {round(params/1e6)}M")Copied
Number of parameters: 117M
En la época de los billones de parámetros, podemos ver que GPT1 solo tenía 117 millones de parámetros
Creamos los tokens de entrada al modelo
input_sentence = "Hello, my dog is cute and"input_tokens = tokenizer(input_sentence, return_tensors="pt").to(device)input_tokensCopied
{'input_ids': tensor([[3570, 240, 547, 2585, 544, 4957, 488]], device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]], device='cuda:0')}
Se los pasamos al modelo para generar los tokens de salida
output_tokens = model.generate(**input_tokens)print(f"output tokens: {output_tokens}")Copied
output tokens:tensor([[ 3570, 240, 547, 2585, 544, 4957, 488, 249, 719, 797,485, 921, 575, 562, 246, 1671, 239, 244, 40477, 244]],device='cuda:0')
/home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/generation/utils.py:1178: UserWarning: Using the model-agnostic default `max_length` (=20) to control the generation length. We recommend setting `max_new_tokens` to control the maximum length of the generation.warnings.warn(
Decodificamos los tokens para obtener la sentencia de salida
decoded_output = tokenizer.decode(output_tokens[0], skip_special_tokens=True)print(f"decoded output: {decoded_output}")Copied
decoded output:hello, my dog is cute and i'm going to take him for a walk. ""
Ya hemos conseguido generar texto con GPT1
Generar texto token a token
Greedy search
Hemos usado model.generate para generar los tokens de salida de golpe, pero vamos a ver cómo generarlos uno a uno. Para ello, en vez de usar model.generate vamos a usar model, que en realidad lo que hace es llamar al método model.forward
outputs = model(**input_tokens)outputsCopied
CausalLMOutput(loss=None, logits=tensor([[[ -5.9486, -5.8697, -18.4258, ..., -9.7371, -10.4495, 0.8814],[ -6.1212, -4.8031, -14.3970, ..., -6.5411, -9.5051, -1.2015],[ -7.4231, -6.3615, -14.7297, ..., -10.4575, -8.4600, -1.5183],...,[ -5.4751, -5.8803, -13.7767, ..., -10.5048, -12.4167, -6.1584],[ -7.2052, -6.0198, -21.5040, ..., -16.2941, -14.0494, -1.2416],[ -7.7240, -7.3631, -17.3174, ..., -12.1546, -12.3327, -1.7169]]],device='cuda:0', grad_fn=<UnsafeViewBackward0>), hidden_states=None, attentions=None)
Vemos que saca muchos datos, primero vamos a ver las keys de la salida
outputs.keys()Copied
odict_keys(['logits'])
En este caso solo tenemos los logits del modelo, vamos a ver su tamaño
logits = outputs.logitslogits.shapeCopied
torch.Size([1, 7, 40478])
Vamos a ver cuántos tokens teníamos a la entrada
input_tokens.input_ids.shapeCopied
torch.Size([1, 7])
Vaya, a la salida tenemos el mismo número de logits que a la entrada. Esto es normal
Obtenemos los logits de la última posición de la salida
nex_token_logits = logits[0,-1]nex_token_logits.shapeCopied
torch.Size([40478])
Hay un total de 40478 logits, es decir, hay un vocabulario de 40478 tokens y tenemos que ver cuál es el token con mayor probabilidad, para ello primero calculamos la softmax
softmax_logits = torch.softmax(nex_token_logits, dim=0)softmax_logits.shapeCopied
torch.Size([40478])
next_token_prob, next_token_id = torch.max(softmax_logits, dim=0)next_token_prob, next_token_idCopied
(tensor(0.1898, device='cuda:0', grad_fn=<MaxBackward0>),tensor(249, device='cuda:0'))
Hemos obtenido el siguiente token, ahora lo decodificamos
tokenizer.decode(next_token_id.item())Copied
'i'
Hemos obtenido el siguiente token mediante el método greedy, es decir, el token con mayor probabilidad. Pero ya vimos en el post de la librería transformers, las formas de generar textos que se puede hacer sampling, top-k, top-p, etc.
Vamos a meter todo en una función y ver qué sale si generamos unos cuantos tokens
def generate_next_greedy_token(input_sentence, tokenizer, model, device):input_tokens = tokenizer(input_sentence, return_tensors="pt").to(device)outputs = model(**input_tokens)logits = outputs.logitsnex_token_logits = logits[0,-1]softmax_logits = torch.softmax(nex_token_logits, dim=0)next_token_prob, next_token_id = torch.max(softmax_logits, dim=0)return next_token_prob, next_token_idCopied
def generate_greedy_text(input_sentence, tokenizer, model, device, max_length=20):generated_text = input_sentencefor _ in range(max_length):next_token_prob, next_token_id = generate_next_greedy_token(generated_text, tokenizer, model, device)generated_text += tokenizer.decode(next_token_id.item())return generated_textCopied
Ahora generamos texto
generate_greedy_text("Hello, my dog is cute and", tokenizer, model, device)Copied
'Hello, my dog is cute andi." '
La salida es bastante repetitiva como ya se vio en las formas de generar textos
Fine tuning GPT
Cálculo de la loss
Antes de empezar a hacer el fine tuning de GPT1 vamos a ver una cosa. Antes, cuando obteníamos la salida del modelo, hacíamos esto
outputs = model(**input_tokens)outputsCopied
CausalLMOutput(loss=None, logits=tensor([[[ -5.9486, -5.8697, -18.4258, ..., -9.7371, -10.4495, 0.8814],[ -6.1212, -4.8031, -14.3970, ..., -6.5411, -9.5051, -1.2015],[ -7.4231, -6.3615, -14.7297, ..., -10.4575, -8.4600, -1.5183],...,[ -5.4751, -5.8803, -13.7767, ..., -10.5048, -12.4167, -6.1584],[ -7.2052, -6.0198, -21.5040, ..., -16.2941, -14.0494, -1.2416],[ -7.7240, -7.3631, -17.3174, ..., -12.1546, -12.3327, -1.7169]]],device='cuda:0', grad_fn=<UnsafeViewBackward0>), hidden_states=None, attentions=None)
Se puede ver que obtenemos loss=None
print(outputs.loss)Copied
None
Como vamos a necesitar la loss para hacer el fine tuning, vamos a ver cómo obtenerla.
Si nos vamos a la documentación del método forward de OpenAIGPTLMHeadModel, podemos ver que dice que a la salida devuelve un objeto de tipo transformers.modeling_outputs.CausalLMOutput, así que si nos vamos a la documentación de transformers.modeling_outputs.CausalLMOutput, podemos ver que dice que devuelve loss si se le pasa labels al método forward.
Si nos vamos a la fuente del código del método forward, vemos este bloque de código
loss = None
if labels is not None:
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))Es decir, la loss se calcula de la siguiente manera
- Shift de logits y labels: La primera parte es desplazar los logits (
lm_logits) y las etiquetas (labels) para que lostokens < npredigann, es decir, desde una posiciónnse predice el siguiente token a partir de los anteriores. - CrossEntropyLoss: Se crea una instancia de la función de pérdida
CrossEntropyLoss(). - Flatten tokens: A continuación, se aplanan los logits y las etiquetas utilizando
view(-1, shift_logits.size(-1))yview(-1), respectivamente. Esto se hace para que los logits y las etiquetas tengan la misma forma para la función de pérdida. - Cálculo de la pérdida: Finalmente, se calcula la pérdida utilizando la función de pérdida
CrossEntropyLoss()con los logits aplanados y las etiquetas aplanadas como entradas.
En resumen, la loss se calcula como la pérdida de entropía cruzada entre los logits desplazados y aplanados y las etiquetas desplazadas y aplanadas.
Por tanto, si al método forward le pasamos los labels, nos devolverá la loss
outputs = model(**input_tokens, labels=input_tokens.input_ids)outputs.lossCopied
tensor(4.2607, device='cuda:0', grad_fn=<NllLossBackward0>)
Dataset
Para el entrenamiento vamos a usar un dataset de chistes en inglés short-jokes-dataset, que es un dataset con 231 mil chistes en inglés.
Descargamos el dataset
from datasets import load_datasetjokes = load_dataset("Maximofn/short-jokes-dataset")jokesCopied
DatasetDict({train: Dataset({features: ['ID', 'Joke'],num_rows: 231657})})
Vamos a verlo un poco
jokes["train"][0]Copied
{'ID': 1,'Joke': '[me narrating a documentary about narrators] "I can't hear what they're saying cuz I'm talking"'}
Entrenamiento con Pytorch
Primero vamos a ver cómo se haría el entrenamiento con puro Pytorch
Reiniciamos el notebook para que no haya problemas con la memoria de la GPU
import torchfrom transformers import OpenAIGPTLMHeadModel, AutoTokenizerdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")ckeckpoints = "openai-community/openai-gpt"tokenizer = AutoTokenizer.from_pretrained(ckeckpoints)model = OpenAIGPTLMHeadModel.from_pretrained(ckeckpoints)model = model.to(device)Copied
Pytorch dataset
Creamos una clase Dataset de Pytorch
from torch.utils.data import Datasetclass JokesDataset(Dataset):def __init__(self, dataset, tokenizer):self.dataset = datasetself.joke = "JOKE: "self.end_of_text_token = "<|endoftext|>"self.tokenizer = tokenizerdef __len__(self):return len(self.dataset["train"])def __getitem__(self, item):sentence = self.joke + self.dataset["train"][item]["Joke"] + self.end_of_text_tokentokens = self.tokenizer(sentence, return_tensors="pt")return sentence, tokensCopied
La instanciamos
dataset = JokesDataset(jokes, tokenizer=tokenizer)Copied
Vemos un ejemplo
sentence, tokens = dataset[5]print(sentence)tokens.input_ids.shape, tokens.attention_mask.shapeCopied
JOKE: Why can't Barbie get pregnant? Because Ken comes in a different box. Heyooooooo<|endoftext|>
(torch.Size([1, 30]), torch.Size([1, 30]))
Dataloader
Creamos ahora un dataloader de Pytorch
from torch.utils.data import DataLoaderBS = 1joke_dataloader = DataLoader(dataset, batch_size=BS, shuffle=True)Copied
Vemos un batch
sentences, tokens = next(iter(joke_dataloader))len(sentences), tokens.input_ids.shape, tokens.attention_mask.shapeCopied
(1, torch.Size([1, 1, 29]), torch.Size([1, 1, 29]))
Training
from transformers import AdamW, get_linear_schedule_with_warmupimport tqdmBATCH_SIZE = 32EPOCHS = 5LEARNING_RATE = 3e-5WARMUP_STEPS = 5000MAX_SEQ_LEN = 500model.train()optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=WARMUP_STEPS, num_training_steps=-1)proc_seq_count = 0batch_count = 0tmp_jokes_tens = Nonefor epoch in range(EPOCHS):print(f"EPOCH {epoch} started" + '=' * 30)progress_bar = tqdm.tqdm(joke_dataloader, desc="Training")for sample in progress_bar:sentence, tokens = sample#################### "Fit as many joke sequences into MAX_SEQ_LEN sequence as possible" logic start ####joke_tens = tokens.input_ids[0].to(device)# Skip sample from dataset if it is longer than MAX_SEQ_LENif joke_tens.size()[1] > MAX_SEQ_LEN:continue# The first joke sequence in the sequenceif not torch.is_tensor(tmp_jokes_tens):tmp_jokes_tens = joke_tenscontinueelse:# The next joke does not fit in so we process the sequence and leave the last joke# as the start for next sequenceif tmp_jokes_tens.size()[1] + joke_tens.size()[1] > MAX_SEQ_LEN:work_jokes_tens = tmp_jokes_tenstmp_jokes_tens = joke_tenselse:#Add the joke to sequence, continue and try to add moretmp_jokes_tens = torch.cat([tmp_jokes_tens, joke_tens[:,1:]], dim=1)continue################## Sequence ready, process it trough the model ##################outputs = model(work_jokes_tens, labels=work_jokes_tens)loss = outputs.lossloss.backward()proc_seq_count = proc_seq_count + 1if proc_seq_count == BATCH_SIZE:proc_seq_count = 0batch_count += 1optimizer.step()scheduler.step()optimizer.zero_grad()model.zero_grad()progress_bar.set_postfix({'loss': loss.item(), 'lr': scheduler.get_last_lr()[0]})if batch_count == 10:batch_count = 0Copied
/home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/optimization.py:429: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warningwarnings.warn(
EPOCH 0 started==============================
Training: 100%|██████████| 231657/231657 [11:31<00:00, 334.88it/s, loss=2.88, lr=2.93e-6]
EPOCH 1 started==============================
Training: 100%|██████████| 231657/231657 [11:30<00:00, 335.27it/s, loss=2.49, lr=5.87e-6]
EPOCH 2 started==============================
Training: 100%|██████████| 231657/231657 [11:17<00:00, 341.75it/s, loss=2.57, lr=8.81e-6]
EPOCH 3 started==============================
Training: 100%|██████████| 231657/231657 [11:18<00:00, 341.27it/s, loss=2.41, lr=1.18e-5]
EPOCH 4 started==============================
Training: 100%|██████████| 231657/231657 [11:19<00:00, 341.04it/s, loss=2.49, lr=1.47e-5]
Inference
Vamos a ver qué tal hace chistes el modelo
sentence_joke = "JOKE:"input_tokens_joke = tokenizer(sentence_joke, return_tensors="pt").to(device)output_tokens_joke = model.generate(**input_tokens_joke)decoded_output_joke = tokenizer.decode(output_tokens_joke[0], skip_special_tokens=True)print(f"decoded joke: {decoded_output_joke}")Copied
decoded joke:joke : what do you call a group of people who are not afraid of the dark? a group
Se puede ver que le pasas una secuencia con la palabra joke y te devuelve un chiste. Pero si le devuelves otra secuencia no
sentence_joke = "My dog is cute and"input_tokens_joke = tokenizer(sentence_joke, return_tensors="pt").to(device)output_tokens_joke = model.generate(**input_tokens_joke)decoded_output_joke = tokenizer.decode(output_tokens_joke[0], skip_special_tokens=True)print(f"decoded joke: {decoded_output_joke}")Copied
decoded joke:my dog is cute and i'm not sure if i should be offended or not. "