
En el paper GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers se expone la necesidad de crear un método de cuantización post entrenamiento que no degrade la calidad del modelo. En este post hemos visto el método llm.int8() que cuantiza a INT8 algunos vectores de las matrices de pesos, siempre y cuando ninguno de sus valores sobrepase un valor umbral, lo cual está muy bien, pero no cuantizan todos los pesos del modelo. En este paper proponen un método que cuantiza todos los pesos del modelo a 4 y 3 bits, sin degradar la calidad del modelo. Lo que supone un ahorro considerable de memoria, no solo porque se cuantizan todos los pesos, sino porque además se hace a 4, 3 bits (y hasta 1 y 2 bits en ciertas condiciones), en vez de a 8 bits.
Trabajos en los que se basa
Cuantización por capas
Por un lado se basan en los trabajos Nagel et al., 2020; Wang et al., 2020; Hubara et al., 2021 y Frantar et al., 2022, que proponen cuantizar los pesos de las capas de una red neuronal a 4 y 3 bits, sin degradar la calidad del modelo.
Teniendo un conjunto de datos m proveniente de un dataset, a cada capa l se le meten los datos y se obtiene la salida de los pesos W de dicha capa. Así que lo que se hace es buscar unos pesos nuevos Ŵ cuantizados que minimicen el error cuadrático en relación con la salida de la capa de precisión total
argmin_Ŵ||WX− ŴX||^2
Los valores de Ŵ se establecen antes de realizar el proceso de cuantización y durante el proceso, cada parámetro de Ŵ puede cambiar de valor independientemente sin depender del valor de los demás parámetros de Ŵ.
Optimal brain quantization (OBQ)
En el trabajo de OBQ de Frantar et al., 2022 optimizan el proceso de cuantización por capas anterior, haciendo que llegue a ser hasta 3 veces más rápido. Esto ayuda con los modelos grandes, ya que cuantizar un modelo grande puede llevar mucho tiempo.
El método OBQ es un enfoque para resolver el problema de cuantificación por capas en modelos de lenguaje. OBQ parte de la idea de que el error cuadrático se puede descomponer en la suma de errores individuales para cada fila de la matriz de pesos. Luego, el método cuantifica cada peso de manera independiente, actualizando siempre los pesos no cuantificados para compensar el error incurrido por la cuantificación.
El método es capaz de cuantificar modelos de tamaño medio en tiempos razonables, pero como es un algoritmo de complejidad cúbica hace que sea extremadamente costoso aplicarlo a modelos con miles de millones de parámetros.
Algoritmo de GPTQ
Paso 1: Información de orden arbitrario
En OBQ se buscaba la fila de pesos que creara menor error cuadrático medio para cuantizar, pero se dieron cuenta de que al hacerlo de manera aleatoria no aumentaba mucho el error cuadrático medio final. Por lo que en vez de buscar la fila que minimiza el error cuadrático medio, que creaba una complejidad cúbica en el algoritmo, se hace siempre en el mismo orden. Gracias a esto se reduce mucho el tiempo de ejecución del algoritmo de cuantización.
Paso 2: Actualizaciones lazy batch
Al hacer la actualización de los pesos fila a fila, esto provoca que sea un proceso lento y no se aproveche del todo el hardware.
Paso 3: Reformulación de Cholesky
El problema de hacer las actualizaciones por lotes es que, debido a la gran escala de los modelos, se pueden producir errores numéricos que afectan la precisión del algoritmo. Concretamente, se pueden obtener matrices indefinidas, lo que provoca que el algoritmo actualice los pesos restantes en direcciones incorrectas, lo que resulta en una cuantización muy mala.
Para solucionar esto, los autores del paper proponen utilizar una reformulación de Cholesky, que es un método más numéricamente estable.
Resultados de GPTQ
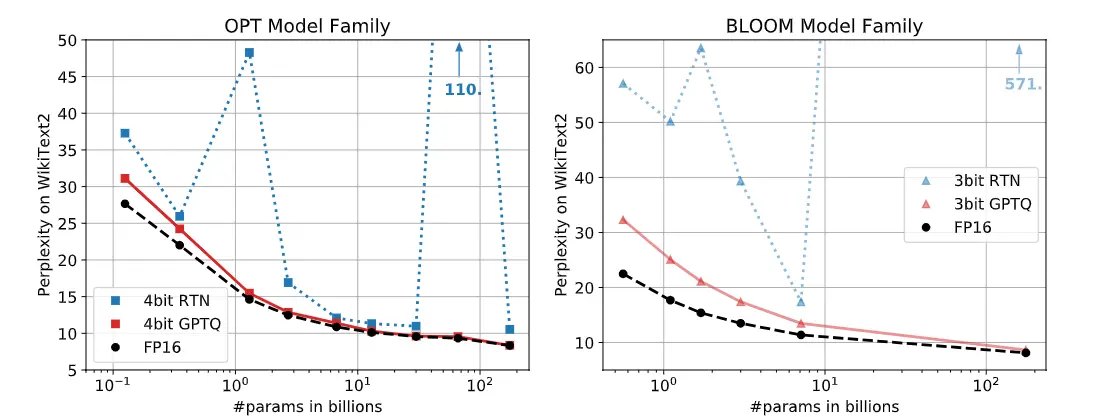
A continuación se muestran dos gráficas con la medida de la perplejidad (perplexity) en el dataset WikiText2 para todos los tamaños de los modelos OPT y BLOOM. Se puede ver que con la técnica de cuantización RTN, la perplejidad en algunos tamaños aumenta mucho, mientras que con GPTQ se mantiene similar a la que se obtiene con el modelo en FP16
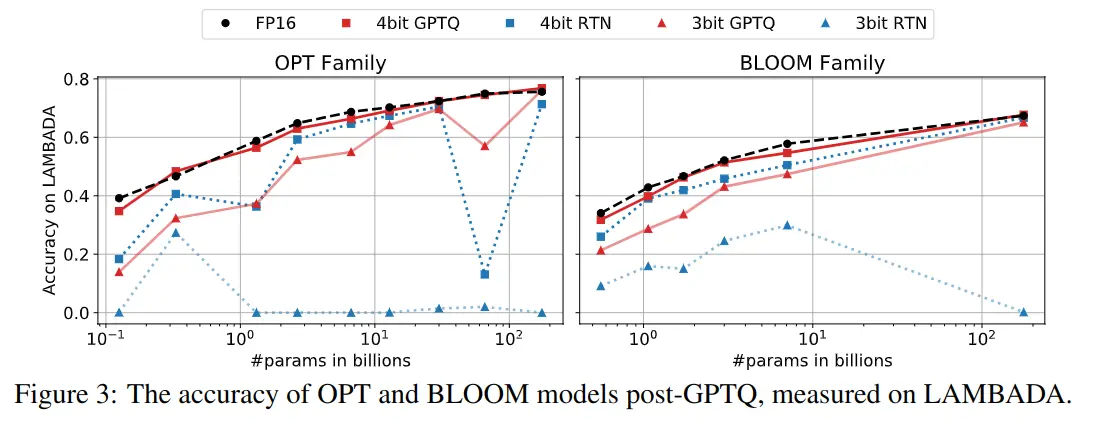
A continuación se muestran otras gráficas, pero con la medida del accuracy en el dataset LAMBADA. Ocurre lo mismo, mientras que GPTQ se mantiene similar a lo obtenido con FP16, otros métodos de cuantización degradan mucho la calidad del modelo
Cuantización extrema
En las gráficas anteriores se han mostrado los resultados de cuantizar el modelo a 3 y 4 bits, pero podemos cuantizarlos a 2 bits, e incluso a 1 solo bit.
Modificando el tamaño de los batches al utilizar el algoritmo, podemos obtener buenos resultados cuantizando tanto el modelo
| Modelo | FP16 | g128 | g64 | g32 | 3 bits |
|---|---|---|---|---|---|
| OPT-175B | 8.34 | 9.58 | 9.18 | 8.94 | 8.68 |
| BLOOM | 8.11 | 9.55 | 9.17 | 8.83 | 8.64 |
En la tabla anterior se puede ver el resultado de la perplejidad en el dataset WikiText2 para los modelos OPT-175B y BLOOM cuantizados a 3 bits. Se puede ver que a medida que se usen batches más pequeños, la perplejidad disminuye, lo que significa que la calidad del modelo cuantizado es mejor. Pero tiene el problema de que el algoritmo tarda más en ejecutarse
Descuantificación dinámica en la inferencia
Durante la inferencia se realiza algo llamado descuantificación dinámica (dynamic dequantization) para poder realizar la inferencia. Se va descuantificando cada capa a medida que se va pasando por ellas.
Para ello desarrollaron un kernel que descuantifica las matrices y realiza los productos matriciales. Si bien la descuantificación consume más cálculos, el kernel tiene que acceder a mucha menos memoria, lo que genera aceleraciones significativas
La inferencia se realiza en FP16 descuantizando los pesos a medida que se va pasando por las capas y la función de activación de cada capa también se realiza en FP16. Aunque esto hace que haya que hacer más cálculos, porque hay que descuantizar, esos cálculos hacen que el proceso total sea más rápido, porque hay que traer de la memoria menos datos. Hay que traer de la memoria los pesos en menos bits, por lo que al final, en matrices de muchos parámetros hace que se ahorren muchos datos. El cuello de botella normalmente está en traer los datos de la memoria, por lo que aunque haya que hacer más cálculos, al final la inferencia es más rápida
Velocidad de inferencia
Los autores del paper realizaron una prueba cuantizando el modelo BLOOM-175B a 3 bits, lo que ocupaba unos 63 GB de memoria VRAM, incluidos los embeddings y la capa de salida que se mantienen en FP16. Además mantener la ventana de contexto de 2048 tokens consume unos 9 GB de memoria, lo que hace en total unos 72 GB de memoria VRAM. Cuantizaron en 3 bits y no en 4 para poder realizar este experimento y poder meter el modelo en una sola GPU Nvidia A100 de 80 GB de memoria VRAM.
Para comparar, la inferencia normal en FP16 requiere unos 350 GB de memoria VRAM, lo que equivale a 5 GPUs Nvidia A100 de 80 GB de memoria VRAM. Y la inferencia cuantizando en 8 bits mediante llm.int8() requiere 3 de dichas GPUs.
A continuación, se muestra una tabla con la inferencia del modelo en FP16 y cuantizado a 3 bits en GPUs Nvidia A100 de 80 GB de memoria VRAM y Nvidia A6000 de 48 GB de memoria VRAM.
| GPU (VRAM) | tiempo promedio por token en FP16 (ms) | tiempo promedio por token en 3 bit (ms) | Aceleración | Reducción de GPUs necesarias |
|---|---|---|---|---|
| A6000 (48GB) | 589 | 130 | ×4.53 | 8→ 2 |
| A100 (80GB) | 230 | 71 | ×3.24 | 5→ 1 |
Por ejemplo, utilizando los kernels, el modelo OPT-175B de 3 bits se ejecuta en una sola A100 (en vez de en 5) y es aproximadamente 3,25 veces más rápido que la versión FP16 en términos de tiempo promedio por token.
La GPU NVIDIA A6000 tiene un ancho de banda de memoria mucho menor, por lo que esta estrategia es aún más efectiva: ejecutar el modelo OPT-175B de 3 bits en 2 GPUs A6000 (en vez de en 8) es aproximádamente 4.53 veces más rápido que la versión FP16.
Librerías
Los autores del paper implementaron la librería GPTQ. Otras librerías fueron creadas como GPTQ-for-LLaMa, exllama y llama.cpp. Sin embargo estas librerías se centran solo en la arquitectura llama, por lo que la librería AutoGPTQ fue la que ganó más popularidad porque tiene una cobertura más amplia de arquitecturas.
Por ello dicha librería AutoGPTQ se integró mediante una API dentro de la librería transformers. Para poder usarla es necesario instalarla como se indica en la seción Installation de su repositorio y tener instalada la librería optimun.
Además de hacer lo que indican en la sección Installation de su repositorio también conviene hacer lo siguiente:
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip install .Para que se instalen los kernels de cuantización en la GPU que desarrollaron los autores del paper.
Cuantización de un modelo
Vamos a ver cómo cuantizar un modelo con la librería optimun y la API de AutoGPTQ.
Inferencia del modelo no cuantizado
Vamos a cuantizar el modelo meta-llama/Meta-Llama-3-8B-Instruct que, como su nombre indica, es un modelo de 8B de parámetros, por lo que en FP16 necesitaríamos 16 GB de memoria VRAM. Primero ejecutamos el modelo para ver la memoria que ocupa y la salida que genera
Como para usar este modelo hay que pedir permiso a Meta, nos logueamos en Hugging Face para poder bajar el tokenizador y el modelo
from huggingface_hub import notebook_loginnotebook_login()Copied
Instanciamos el tokenizador y el modelo
from transformers import AutoModelForCausalLM, AutoTokenizerimport torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")checkpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForCausalLM.from_pretrained(checkpoint).half().to(device)Copied
Vamos a ver la memoria que ocupa en FP16
model_memory = model.get_memory_footprint()/(1024**3)print(f"Model memory: {model_memory:.2f} GB")Copied
Model memory: 14.96 GB
Vemos que ocupa casi 15 GB, más o menos los 16 GB que habíamos dicho que debería ocupar, pero ¿por qué esta diferencia? Seguramente este modelo no tenga exactamente 8B de parámetros, sino que tenga un poco menos, pero a la hora de indicar el número de parámetros se redondea a 8B.
Hacemos una inferencia para ver cómo lo hace y el tiempo que tarda
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model.device)t0 = time.time()max_new_tokens = 50outputs = model.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer at a startup in the Bay Area. I am passionate about building AI systems that can help humans make better decisions and improve their lives.I have a background in computer science and mathematics, and I have been working with machine learning for several years. IInference time: 4.14 s
Cuantización del modelo a 4 bits
Vamos a cuantizarlo a 4 bits. Reinico el notebook para no tener problemas de memoria, por lo que nos volvemos a loguear en Hugging Face
from huggingface_hub import notebook_loginnotebook_login()Copied
Primero creo el tokenizador
from transformers import AutoTokenizercheckpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Ahora creamos la configuración de cuantización. Como hemos dicho, este algoritmo calcula el error de los pesos cuantizados sobre los originales en función de entradas de un dataset, por lo que en la configuración tenemos que pasarle con qué dataset queremos cuantizar el modelo.
Los disponibles por defecto son wikitext2,c4,c4-new,ptb y ptb-new.
También podemos crear nosotros un dataset a partir de una lista de strings
dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]Además, le tenemos que decir el número de bits que tenga el modelo cuantizado mediante el parámetro bits
from transformers import GPTQConfigquantization_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)Copied
Cuantizamos el modelo
from transformers import AutoModelForCausalLMimport timet0 = time.time()model_4bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", quantization_config=quantization_config)t_quantization = time.time() - t0print(f"Quantization time: {t_quantization:.2f} s = {t_quantization/60:.2f} min")Copied
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<?, ?it/s]
Quantizing model.layers blocks : 100%|██████████|32/32 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:4565: FutureWarning: `_is_quantized_training_enabled` is going to be deprecated in transformers 4.39.0. Please use `model.hf_quantizer.is_trainable` insteadwarnings.warn(
Quantization time: 1932.09 s = 32.20 min
Como el proceso de cuantización calcula el menor error entre los pesos cuantizados con los originales haciendo pasar entradas por cada capa, el proceso de cuantización tarda. En este caso ha tardado una media hora
Vamos a ver la memoria que ocupa ahora
model_4bits_memory = model_4bits.get_memory_footprint()/(1024**3)print(f"Model memory: {model_4bits_memory:.2f} GB")Copied
Model memory: 5.34 GB
Aquí podemos ver un beneficio de la cuantización. Mientras que el modelo original ocupaba unos 15 GB de VRAM, ahora el modelo cuantizado ocupa unos 5 GB, casi un tercio del tamaño original
Hacemos la inferencia y vemos el tiempo que tarda
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model_4bits.device)t0 = time.time()max_new_tokens = 50outputs = model_4bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer. I have a strong background in computer science and mathematics, and I am passionate about developing innovative solutions that can positively impact society. I am excited to be a part of this community and to learn from and contribute to the discussions here. I am particularlyInference time: 2.34 s
El modelo sin cuantizar tardó 4.14 segundos, mientras que ahora cuantizado a 4 bits ha tardado 2.34 segundos y además ha generado bien el texto. Hemos conseguido reducir la inferencia casi a la mitad.
Como el tamaño del modelo cuantizado es casi un tercio del modelo en FP16, podríamos pensar que la velocidad de inferencia debería ser unas tres veces más rápida con el modelo cuantizado. Pero hay que recordar que en cada capa se descuantifican los pesos y se realizan los cálculos en FP16, por eso solo hemos conseguido reducir el tiempo de inferencia a la mitad y no a un tercio
Ahora guardamos el modelo
save_folder = "./model_4bits/"model_4bits.save_pretrained(save_folder)tokenizer.save_pretrained(save_folder)Copied
('./model_4bits/tokenizer_config.json','./model_4bits/special_tokens_map.json','./model_4bits/tokenizer.json')
Y lo subimos al hub
repo_id = "Llama-3-8B-Instruct-GPTQ-4bits"commit_message = f"AutoGPTQ model for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"model_4bits.push_to_hub(repo_id, commit_message=commit_message)Copied
README.md: 100%|██████████| 5.17/5.17k [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-4bits/commit/44cfdcad78db260122943d3f57858c1b840bda17', commit_message='AutoGPTQ model for meta-llama/Meta-Llama-3-8B-Instruct: 4bits, gr128, desc_act=False', commit_description='', oid='44cfdcad78db260122943d3f57858c1b840bda17', pr_url=None, pr_revision=None, pr_num=None)
Subimos también el tokenizador. Aunque no hemos cambiado el tokenizador, lo subimos porque si una persona se baja nuestro modelo del hub no tiene por qué saber qué tokenizador hemos usado, por lo que seguramente querrá bajarse el modelo y el tokenizador juntos. Podemos indicar en la model card qué tokenizador hemos usado para que se lo baje, pero lo más probable es que no se lea la model card, se intente bajar el tokenizador, obtenga un error y no sepa qué hacer. Así que lo subimos para ahorrarnos ese problema
repo_id = "Llama-3-8B-Instruct-GPTQ-4bits"commit_message = f"Tokenizers for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"tokenizer.push_to_hub(repo_id, commit_message=commit_message)Copied
README.md: 100%|██████████| 0.00/5.17k [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-4bits/commit/75600041ca6e38b5f1fb912ad1803b66656faae4', commit_message='Tokenizers for meta-llama/Meta-Llama-3-8B-Instruct: 4bits, gr128, desc_act=False', commit_description='', oid='75600041ca6e38b5f1fb912ad1803b66656faae4', pr_url=None, pr_revision=None, pr_num=None)
Cuantización del modelo a 3 bits
Vamos a cuantizarlo a 3 bits. Reinico el notebook para no tener problemas de memoria y vuelvo a loguearme en Hugging Face
from huggingface_hub import notebook_loginnotebook_login()Copied
Primero creo el tokenizador
from transformers import AutoTokenizercheckpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Creamos la configuración de cuantización, ahora le indicamos que queremos cuantizar a 3 bits
from transformers import GPTQConfigquantization_config = GPTQConfig(bits=3, dataset = "c4", tokenizer=tokenizer)Copied
Cuantizamos el modelo
from transformers import AutoModelForCausalLMimport timet0 = time.time()model_3bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", quantization_config=quantization_config)t_quantization = time.time() - t0print(f"Quantization time: {t_quantization:.2f} s = {t_quantization/60:.2f} min")Copied
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<?, ?it/s]
Quantizing model.layers blocks : 100%|██████████|32/32 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:4565: FutureWarning: `_is_quantized_training_enabled` is going to be deprecated in transformers 4.39.0. Please use `model.hf_quantizer.is_trainable` insteadwarnings.warn(
Quantization time: 1912.69 s = 31.88 min
Al igual que antes, ha tardado una media hora
Vamos a ver la memoria que ocupa ahora
model_3bits_memory = model_3bits.get_memory_footprint()/(1024**3)print(f"Model memory: {model_3bits_memory:.2f} GB")Copied
Model memory: 4.52 GB
La memoria que ocupa el modelo en 3 bits es también casi unos 5 GB. El modelo en 4 bits ocupaba 5.34 GB, mientras que ahora en 3 bits ocupa 4.52 GB, por lo que hemos conseguido reducir un poco más el tamaño del modelo.
Hacemos la inferencia y vemos el tiempo que tarda
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model_3bits.device)t0 = time.time()max_new_tokens = 50outputs = model_3bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer at Google. I am excited to be here today to talk about my work in the field of Machine Learning and to share some of the insights I have gained through my experiences.I am a Machine Learning Engineer at Google, and I am excited to beInference time: 2.89 s
Aunque la salida en 3 bits es buena, ahora el tiempo de inferencia ha sido de 2.89 segundos, mientras que en 4 bits fue de 2.34 segundos. Habría que hacer más pruebas a ver si siempre tarda menos en 4 bits, o puede que la diferencia sea tan pequeña que a veces sea más rápido la inferencia en 3 bits y otras veces la inferencia en 4 bits.
Además, aunque la salida tiene sentido, empieza a ser repetitiva
Guardamos el modelo
save_folder = "./model_3bits/"model_3bits.save_pretrained(save_folder)tokenizer.save_pretrained(save_folder)Copied
('./model_3bits/tokenizer_config.json','./model_3bits/special_tokens_map.json','./model_3bits/tokenizer.json')
Y lo subimos al Hub
repo_id = "Llama-3-8B-Instruct-GPTQ-3bits"commit_message = f"AutoGPTQ model for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"model_3bits.push_to_hub(repo_id, commit_message=commit_message)Copied
model.safetensors: 100%|██████████| 4.85/4.85G [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-3bits/commit/422fd94a031234c10224ddbe09c0e029a5e9c01f', commit_message='AutoGPTQ model for meta-llama/Meta-Llama-3-8B-Instruct: 3bits, gr128, desc_act=False', commit_description='', oid='422fd94a031234c10224ddbe09c0e029a5e9c01f', pr_url=None, pr_revision=None, pr_num=None)
Subimos también el tokenizador
repo_id = "Llama-3-8B-Instruct-GPTQ-3bits"commit_message = f"Tokenizers for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"tokenizer.push_to_hub(repo_id, commit_message=commit_message)Copied
README.md: 100%|██████████| 0.00/5.17k [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-4bits/commit/75600041ca6e38b5f1fb912ad1803b66656faae4', commit_message='Tokenizers for meta-llama/Meta-Llama-3-8B-Instruct: 4bits, gr128, desc_act=False', commit_description='', oid='75600041ca6e38b5f1fb912ad1803b66656faae4', pr_url=None, pr_revision=None, pr_num=None)
Cuantización del modelo a 2 bits
Vamos a cuantizarlo a 2 bits. Reinico el notebook para no tener problemas de memoria y me vuelvo a loguear en Hugging Face
from huggingface_hub import notebook_loginnotebook_login()Copied
Primero creo el tokenizador
from transformers import AutoTokenizercheckpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Creamos la configuración de cuantización. Ahora le decimos que cuanticemos a 2 bits. Además hay que indicarle cuántos vectores de la matriz de pesos cuantiza a la vez mediante el parámetro group_size, antes por defecto tenía el valor 128 y no lo tocamos, pero ahora al cuantizar a 2 bits, para tener menos error le ponemos un valor más pequeño. Si lo dejamos a 128, el modelo cuantizado funcionaría muy mal, en este caso le voy a poner un valor de 16
from transformers import GPTQConfigquantization_config = GPTQConfig(bits=2, dataset = "c4", tokenizer=tokenizer, group_size=16)Copied
from transformers import AutoModelForCausalLMimport timet0 = time.time()model_2bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", quantization_config=quantization_config)t_quantization = time.time() - t0print(f"Quantization time: {t_quantization:.2f} s = {t_quantization/60:.2f} min")Copied
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<?, ?it/s]
Quantizing model.layers blocks : 100%|██████████|32/32 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:4565: FutureWarning: `_is_quantized_training_enabled` is going to be deprecated in transformers 4.39.0. Please use `model.hf_quantizer.is_trainable` insteadwarnings.warn(
Quantization time: 1973.12 s = 32.89 min
Vemos que ha tardado también una media hora
Vamos a ver la memoria que ocupa ahora
model_2bits_memory = model_2bits.get_memory_footprint()/(1024**3)print(f"Model memory: {model_2bits_memory:.2f} GB")Copied
Model memory: 4.50 GB
Mientras que cuantizado a 4 bits ocupaba 5.34 GB y a 3 bits ocupaba 4.52 GB, ahora cuantizado a 2 bits ocupa 4.50 GB, por lo que hemos conseguido reducir un poco más el tamaño del modelo
Hacemos la inferencia y vemos el tiempo que tarda
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model_2bits.device)t0 = time.time()max_new_tokens = 50outputs = model_2bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer. # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #Inference time: 2.92 s
Vemos que ya la salida no es buena, además, el tiempo de inferencia es de 2.92 segundos, más o menos lo mismo que con 3 y 4 bits
Guardamos el modelo
save_folder = "./model_2bits/"model_2bits.save_pretrained(save_folder)tokenizer.save_pretrained(save_folder)Copied
('./model_2bits/tokenizer_config.json','./model_2bits/special_tokens_map.json','./model_2bits/tokenizer.json')
Lo subimos al hub
repo_id = "Llama-3-8B-Instruct-GPTQ-2bits"commit_message = f"AutoGPTQ model for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"model_2bits.push_to_hub(repo_id, commit_message=commit_message)Copied
model.safetensors: 100%|██████████| 4.83/4.83G [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-2bits/commit/13ede006ce0dbbd8aca54212e960eff98ea5ec63', commit_message='AutoGPTQ model for meta-llama/Meta-Llama-3-8B-Instruct: 2bits, gr16, desc_act=False', commit_description='', oid='13ede006ce0dbbd8aca54212e960eff98ea5ec63', pr_url=None, pr_revision=None, pr_num=None)
Cuantización del modelo a 1 bit
Vamos a cuantizarlo a 1 bit. Reinico el notebook para no tener problemas de memoria y me vuelvo a loguear en Hugging Face
from huggingface_hub import notebook_loginnotebook_login()Copied
Primero creo el tokenizador
from transformers import AutoTokenizercheckpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Creamos la configuración de cuantización, ahora le decimos que cuantice a solo 1 bit y además que use un group_size de 8
from transformers import GPTQConfigquantization_config = GPTQConfig(bits=2, dataset = "c4", tokenizer=tokenizer, group_size=8)Copied
from transformers import AutoModelForCausalLMimport timet0 = time.time()model_1bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", quantization_config=quantization_config)t_quantization = time.time() - t0print(f"Quantization time: {t_quantization:.2f} s = {t_quantization/60:.2f} min")Copied
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<?, ?it/s]
Quantizing model.layers blocks : 100%|██████████|32/32 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:4565: FutureWarning: `_is_quantized_training_enabled` is going to be deprecated in transformers 4.39.0. Please use `model.hf_quantizer.is_trainable` insteadwarnings.warn(
Quantization time: 2030.38 s = 33.84 min
Vemos que también tarda una media hora en cuantizar
Vamos a ver la memoria que ocupa ahora
model_1bits_memory = model_1bits.get_memory_footprint()/(1024**3)print(f"Model memory: {model_1bits_memory:.2f} GB")Copied
Model memory: 5.42 GB
Vemos que en este caso ocupa incluso más que cuantizado a 2 bits, 4,52 GB.
Hacemos la inferencia y vemos el tiempo que tarda
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model_1bits.device)t0 = time.time()max_new_tokens = 50outputs = model_1bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineerimerszuimersimerspinsimersimersingoingoimersurosimersimersimersoleningoimersingopinsimersbirpinsimersimersimersorgeingoimersiringimersimersimersimersimersimersimersンディorge_REFERER ingest羊imersorgeimersimersendetingoШАhandsingoInference time: 3.12 s
Vemos que la salida es muy mala y además tarda más que cuando hemos cuantizado a 2 bits
Guardamos el modelo
save_folder = "./model_1bits/"model_1bits.save_pretrained(save_folder)tokenizer.save_pretrained(save_folder)Copied
('./model_1bits/tokenizer_config.json','./model_1bits/special_tokens_map.json','./model_1bits/tokenizer.json')
Lo subimos al hub
repo_id = "Llama-3-8B-Instruct-GPTQ-1bits"commit_message = f"AutoGPTQ model for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"model_1bits.push_to_hub(repo_id, commit_message=commit_message)Copied
README.md: 100%|██████████| 0.00/5.17k [00:00<?, ?B/s]
Upload 2 LFS files: 100%|██████████| 0/2 [00:00<?, ?it/s]
model-00002-of-00002.safetensors: 100%|██████████| 0.00/1.05G [00:00<?, ?B/s]
model-00001-of-00002.safetensors: 100%|██████████| 0.00/4.76G [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-2bits/commit/e59ccffc03247e7dcc418f98b482cc02dc7a168d', commit_message='AutoGPTQ model for meta-llama/Meta-Llama-3-8B-Instruct: 2bits, gr8, desc_act=False', commit_description='', oid='e59ccffc03247e7dcc418f98b482cc02dc7a168d', pr_url=None, pr_revision=None, pr_num=None)
Resumen de la cuantización
Vamos a comprar la cuantización a 4, 3, 2 y 1 bits
| Bits | Tiempo de cuantización (min) | Memoria (GB) | Tiempo de inferencia (s) | Calidad de la salida |
|---|---|---|---|---|
| FP16 | 0 | 14.96 | 4.14 | Buena |
| 4 | 32.20 | 5.34 | 2.34 | Buena |
| 3 | 31.88 | 4.52 | 2.89 | Buena |
| 2 | 32.89 | 4.50 | 2.92 | Mala |
| 1 | 33.84 | 5.42 | 3.12 | Mala |
Viendo esta tabla vemos que no tiene sentido, en este ejemplo, cuantizar a menos de 4 bits.
Cuantizar a 1 y 2 bits claramente no tiene sentido porque la calidad de la salida es mala.
Pero aunque la salida cuando cuantizamos a 3 bits es buena, empieza a ser repetitiva, por lo que a largo plazo, seguramente no sería buena idea usar ese modelo. Además ni el ahorro en tiempo de cuantización, el ahorro en VRAM ni el ahorro en tiempo de inferencia es significativo en comparación con cuantizar a 4 bits.
Carga del modelo guardado
Ahora que hemos comparado la cuantización de modelos, vamos a ver cómo se haría para cargar el modelo de 4 bits que hemos guardado, ya que como hemos visto, es la mejor opción
Primero cargamos el tokenizador que hemos usado
from transformers import AutoTokenizerpath = "./model_4bits"tokenizer = AutoTokenizer.from_pretrained(path)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Ahora cargamos el modelo que hemos guardado
from transformers import AutoModelForCausalLMload_model_4bits = AutoModelForCausalLM.from_pretrained(path, device_map="auto")Copied
Loading checkpoint shards: 100%|██████████| 2/2 [00:00<?, ?it/s]
Vemos la memoria que ocupa
load_model_4bits_memory = load_model_4bits.get_memory_footprint()/(1024**3)print(f"Model memory: {load_model_4bits_memory:.2f} GB")Copied
Model memory: 5.34 GB
Vemos que ocupa la misma memoria que cuando lo habíamos cuantizado, lo cual es lógico
Hacemos la inferencia y vemos el tiempo que tarda
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(load_model_4bits.device)t0 = time.time()max_new_tokens = 50outputs = load_model_4bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer. I have a strong background in computer science and mathematics, and I have been working with machine learning models for several years. I am excited to be a part of this community and to share my knowledge and experience with others. I am particularly interested inInference time: 3.82 s
Vemos que la inferencia es buena y ha tardado 3.82 segundos, un poco más que cuando lo cuantizamos. Pero al igual que he dicho antes, habría que hacer esta prueba muchas veces y sacar una media.
Carga del modelo subido al hub
Ahora vemos cómo cargar el modelo de 4 bits que hemos subido al Hub
Primero cargamos el tokenizador que hemos subido
from transformers import AutoTokenizercheckpoint = "Maximofn/Llama-3-8B-Instruct-GPTQ-4bits"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Ahora cargamos el modelo que hemos guardado
from transformers import AutoModelForCausalLMload_model_4bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto")Copied
Vemos la memoria que ocupa
load_model_4bits_memory = load_model_4bits.get_memory_footprint()/(1024**3)print(f"Model memory: {load_model_4bits_memory:.2f} GB")Copied
Model memory: 5.34 GB
También ocupa la misma memoria
Hacemos la inferencia y vemos el tiempo que tarda
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(load_model_4bits.device)t0 = time.time()max_new_tokens = 50outputs = load_model_4bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer with a passion for building innovative AI solutions. I have been working in the field of AI for over 5 years, and have gained extensive experience in developing and implementing machine learning models for various industries.In my free time, I enjoy reading books onInference time: 3.81 s
Vemos que la inferencia también es buena y ha tardado 3.81 segundos.
















