
La librería transformers de Hugging Face es una de las librerías más populares para trabajar con modelos de lenguaje. Su facilidad de uso hizo que se democratizara el uso de la arquitectura Transformer y que se pudiera trabajar con modelos de lenguaje de última generación sin necesidad de tener un gran conocimiento en el área.
Entre la librería transformers, el hub de modelos y su facilidad de uso, los spaces y la facilidad de desplegar demos, y nuevas librerías como datasets, accelerate, PEFT y otras más, han hecho que Hugging Face sea uno de los actores más importantes de la escena de inteligencia artificial del momento. Ellos mismos se auto-denominan como "el GitHub de la IA" y ciertamente lo son.
Instalación
Para instalar transformers se puede hacer con pip
pip install transformerso con conda
conda install conda-forge::transformersAdemás de la librería es necesario tener un backend de PyTorch o TensorFlow instalado. Es decir, necesitas tener instalar torch o tensorflow para poder usar transformers.
Inferencia con pipeline
Con los pipelines de transformers se puede hacer inferencia con modelos de lenguaje de una manera muy sencilla. Esto tiene la ventaja de que el desarrollo se realiza de manera mucho más rápida y se puede hacer prototipado de manera muy sencilla. Además permite a personas que no tienen mucho conocimiento poder usar los modelos
Con pipeline se puede hacer inferencia en un montón de tareas diferentes. Cada tarea tiene su propio pipeline (pipeline de NLP, pipeline de vision, etc), pero se puede hacer una abstracción general usando la clase pipeline que se encarga de seleccionar el pipeline adecuado para la tarea que se le pase.
Tareas
Al día de escribir este post, las tareas que se pueden hacer con pipeline son:
- Audio:
- Clasificación de audio
- clasificación de escena acústica: etiquetar audio con una etiqueta de escena (“oficina”, “playa”, “estadio”)
- detección de eventos acústicos: etiquetar audio con una etiqueta de evento de sonido (“bocina de automóvil”, “llamada de ballena”, “cristal rompiéndose”)
- etiquetado: etiquetar audio que contiene varios sonidos (canto de pájaros, identificación de altavoces en una reunión)
- clasificación de música: etiquetar música con una etiqueta de género (“metal”, “hip-hop”, “country”)
- Reconocimiento automático del habla (ASR, audio speech recognition):
- Visión por computadora
- Clasificación de imágenes
- Detección de objetos
- Segmentación de imágenes
- Estimación de profundidad
- Procesamiento del lenguaje natural (NLP, natural language processing)
- Clasificación de texto
- análisis de sentimientos
- clasificación de contenido
- Clasificación de tokens
- reconocimiento de entidades nombradas (NER, por sus siglas en inglés): etiquetar un token según una categoría de entidad como organización, persona, ubicación o fecha.
- etiquetado de partes del discurso (POS, por sus siglas en inglés): etiquetar un token según su parte del discurso, como sustantivo, verbo o adjetivo. POS es útil para ayudar a los sistemas de traducción a comprender cómo dos palabras idénticas son gramaticalmente diferentes (por ejemplo, “corte” como sustantivo versus “corte” como verbo)
- Respuestas a preguntas
- extractivas: dada una pregunta y algún contexto, la respuesta es un fragmento de texto del contexto que el modelo debe extraer
- abstractivas: dada una pregunta y algún contexto, la respuesta se genera a partir del contexto; este enfoque lo maneja la Text2TextGenerationPipeline en lugar del QuestionAnsweringPipeline que se muestra a continuación
- Resumir
- extractiva: identifica y extrae las oraciones más importantes del texto original
- abstractiva: genera el resumen objetivo (que puede incluir nuevas palabras no presentes en el documento de entrada) a partir del texto original
- Traducción
- Modelado de lenguaje
- causal: el objetivo del modelo es predecir el próximo token en una secuencia, y los tokens futuros están enmascarados
- enmascarado: el objetivo del modelo es predecir un token enmascarado en una secuencia con acceso completo a los tokens en la secuencia
- Multimodal
- Respuestas a preguntas de documentos
Uso de pipeline
La forma más sencilla de crear un pipeline es simplemente indicarle la tarea que queremos que resuelva mediante el parámetro task. Y la librería se encargará de seleccionar el mejor modelo para esa tarea, descargarlo y guardarlo en la caché para futuros usos.
from transformers import pipelinegenerator = pipeline(task="text-generation")Copied
No model was supplied, defaulted to openai-community/gpt2 and revision 6c0e608 (https://huggingface.co/openai-community/gpt2).Using a pipeline without specifying a model name and revision in production is not recommended.
generator("Me encanta aprender de")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[{'generated_text': 'Me encanta aprender de se résistance davant que hiens que préclase que ses encasas quécénces. Se présentants cet en un croyne et cela désirez'}]
Como se puede ver el texto generado está en francés, mientras que yo se lo he introducido en español, por lo que es importante elegir bien el modelo. Si te fijas la librería ha cogido el modelo openai-community/gpt2 que es un modelo entrenado en su mayoría en inglés, y que al meterle texto en español se ha liado y ha generado una respuesta en francés.
Vamos a usar un modelo reentrenado en español mediante el parámetro model.
from transformers import pipelinegenerator = pipeline(task="text-generation", model="flax-community/gpt-2-spanish")Copied
generator("Me encanta aprender de")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[{'generated_text': 'Me encanta aprender de tus palabras, que con gran entusiasmo y con el mismo conocimiento como lo que tú acabas escribiendo, te deseo de todo corazón todo el deseo de este día: Y aunque también haya personas a las que'}]
Ahora el texto generado tiene mucha mejor pinta
La clase pipeline tiene muchos posibles parámetros, por lo que para verlos todos y aprender más sobre la clase te recomiendo leer su documentación, pero vamos a hablar de una, ya que para el deep learning es muy importante: device. Define el dispositivo (por ejemplo, cpu, cuda:1, mps o un rango ordinal de GPU como 1) en el que se asignará el pipeline.
En mi caso, como tengo una GPU pongo 0
from transformers import pipelinegenerator = pipeline(task="text-generation", model="flax-community/gpt-2-spanish", device=0)generation = generator("Me encanta aprender de")print(generation[0]['generated_text'])Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de ustedes, a tal punto que he decidido escribir algunos de nuestros contenidos en este blog, el cual ha sido de gran utilidad para mí por varias razones, una de ellas, el trabajo
Cómo funciona pipeline
Cuando hacemos uso de pipeline por debajo lo que está pasando es esto

Automáticamente se está tokenizando el texto, se pasa por el modelo y después por un postprocesado
Inferencia con AutoClass y pipeline
Hemos visto que pipeline nos abstrae mucho de lo que pasa, pero nosotros podemos seleccionar qué tokenizador, qué modelo y qué postprocesado queremos usar.
Tokenización con AutoTokenizer
Antes usamos el modelo flax-community/gpt-2-spanish para generar texto, podemos usar su tokenizador
from transformers import AutoTokenizercheckpoint = "flax-community/gpt-2-spanish"tokenizer = AutoTokenizer.from_pretrained(checkpoint)text = "Me encanta lo que estoy aprendiendo"tokens = tokenizer(text, return_tensors="pt")print(tokens)Copied
{'input_ids': tensor([[ 2879, 4835, 382, 288, 2383, 15257]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1]])}
Modelo AutoModel
Ahora podemos crear el modelo y pasarle los tokens
from transformers import AutoModelmodel = AutoModel.from_pretrained("flax-community/gpt-2-spanish")output = model(**tokens)type(output), output.keys()Copied
(transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions,odict_keys(['last_hidden_state', 'past_key_values']))
Si ahora lo intentamos usar en un pipeline nos dará un error
from transformers import pipelinepipeline("text-generation", model=model, tokenizer=tokenizer)("Me encanta aprender de")Copied
The model 'GPT2Model' is not supported for text-generation. Supported models are ['BartForCausalLM', 'BertLMHeadModel', 'BertGenerationDecoder', 'BigBirdForCausalLM', 'BigBirdPegasusForCausalLM', 'BioGptForCausalLM', 'BlenderbotForCausalLM', 'BlenderbotSmallForCausalLM', 'BloomForCausalLM', 'CamembertForCausalLM', 'LlamaForCausalLM', 'CodeGenForCausalLM', 'CpmAntForCausalLM', 'CTRLLMHeadModel', 'Data2VecTextForCausalLM', 'ElectraForCausalLM', 'ErnieForCausalLM', 'FalconForCausalLM', 'FuyuForCausalLM', 'GemmaForCausalLM', 'GitForCausalLM', 'GPT2LMHeadModel', 'GPT2LMHeadModel', 'GPTBigCodeForCausalLM', 'GPTNeoForCausalLM', 'GPTNeoXForCausalLM', 'GPTNeoXJapaneseForCausalLM', 'GPTJForCausalLM', 'LlamaForCausalLM', 'MarianForCausalLM', 'MBartForCausalLM', 'MegaForCausalLM', 'MegatronBertForCausalLM', 'MistralForCausalLM', 'MixtralForCausalLM', 'MptForCausalLM', 'MusicgenForCausalLM', 'MvpForCausalLM', 'OpenLlamaForCausalLM', 'OpenAIGPTLMHeadModel', 'OPTForCausalLM', 'PegasusForCausalLM', 'PersimmonForCausalLM', 'PhiForCausalLM', 'PLBartForCausalLM', 'ProphetNetForCausalLM', 'QDQBertLMHeadModel', 'Qwen2ForCausalLM', 'ReformerModelWithLMHead', 'RemBertForCausalLM', 'RobertaForCausalLM', 'RobertaPreLayerNormForCausalLM', 'RoCBertForCausalLM', 'RoFormerForCausalLM', 'RwkvForCausalLM', 'Speech2Text2ForCausalLM', 'StableLmForCausalLM', 'TransfoXLLMHeadModel', 'TrOCRForCausalLM', 'WhisperForCausalLM', 'XGLMForCausalLM', 'XLMWithLMHeadModel', 'XLMProphetNetForCausalLM', 'XLMRobertaForCausalLM', 'XLMRobertaXLForCausalLM', 'XLNetLMHeadModel', 'XmodForCausalLM'].
---------------------------------------------------------------------------TypeError Traceback (most recent call last)Cell In[23], line 31 from transformers import pipeline----> 3 pipeline("text-generation", model=model, tokenizer=tokenizer)("Me encanta aprender de")File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/pipelines/text_generation.py:241, in TextGenerationPipeline.__call__(self, text_inputs, **kwargs)239 return super().__call__(chats, **kwargs)240 else:--> 241 return super().__call__(text_inputs, **kwargs)File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/pipelines/base.py:1196, in Pipeline.__call__(self, inputs, num_workers, batch_size, *args, **kwargs)1188 return next(1189 iter(1190 self.get_iterator((...)1193 )1194 )1195 else:-> 1196 return self.run_single(inputs, preprocess_params, forward_params, postprocess_params)File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/pipelines/base.py:1203, in Pipeline.run_single(self, inputs, preprocess_params, forward_params, postprocess_params)1201 def run_single(self, inputs, preprocess_params, forward_params, postprocess_params):1202 model_inputs = self.preprocess(inputs, **preprocess_params)-> 1203 model_outputs = self.forward(model_inputs, **forward_params)1204 outputs = self.postprocess(model_outputs, **postprocess_params)1205 return outputsFile ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/pipelines/base.py:1102, in Pipeline.forward(self, model_inputs, **forward_params)1100 with inference_context():1101 model_inputs = self._ensure_tensor_on_device(model_inputs, device=self.device)-> 1102 model_outputs = self._forward(model_inputs, **forward_params)1103 model_outputs = self._ensure_tensor_on_device(model_outputs, device=torch.device("cpu"))1104 else:File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/pipelines/text_generation.py:328, in TextGenerationPipeline._forward(self, model_inputs, **generate_kwargs)325 generate_kwargs["min_length"] += prefix_length327 # BS x SL--> 328 generated_sequence = self.model.generate(input_ids=input_ids, attention_mask=attention_mask, **generate_kwargs)329 out_b = generated_sequence.shape[0]330 if self.framework == "pt":File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/torch/utils/_contextlib.py:115, in context_decorator.<locals>.decorate_context(*args, **kwargs)112 @functools.wraps(func)113 def decorate_context(*args, **kwargs):114 with ctx_factory():--> 115 return func(*args, **kwargs)File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/generation/utils.py:1323, in GenerationMixin.generate(self, inputs, generation_config, logits_processor, stopping_criteria, prefix_allowed_tokens_fn, synced_gpus, assistant_model, streamer, negative_prompt_ids, negative_prompt_attention_mask, **kwargs)1320 synced_gpus = False1322 # 1. Handle `generation_config` and kwargs that might update it, and validate the `.generate()` call-> 1323 self._validate_model_class()1325 # priority: `generation_config` argument > `model.generation_config` (the default generation config)1326 if generation_config is None:1327 # legacy: users may modify the model configuration to control generation. To trigger this legacy behavior,1328 # three conditions must be met1329 # 1) the generation config must have been created from the model config (`_from_model_config` field);1330 # 2) the generation config must have seen no modification since its creation (the hash is the same);1331 # 3) the user must have set generation parameters in the model config.File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/generation/utils.py:1110, in GenerationMixin._validate_model_class(self)1108 if generate_compatible_classes:1109 exception_message += f" Please use one of the following classes instead: {generate_compatible_classes}"-> 1110 raise TypeError(exception_message)TypeError: The current model class (GPT2Model) is not compatible with `.generate()`, as it doesn't have a language model head. Please use one of the following classes instead: {'GPT2LMHeadModel'}
Esto es porque cuando funcionaba usábamos
pipeline(task="text-generation", model="flax-community/gpt-2-spanish")Pero ahora hemos hecho
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
model = AutoModel.from_pretrained("flax-community/gpt-2-spanish")
pipeline("text-generation", model=model, tokenizer=tokenizer)En el primer caso solo usábamos pipeline y el nombre del modelo, por debajo buscaba la mejor manera de implementar el modelo y el tokenizador. Pero en el segundo caso hemos creado el tokenizador y el modelo y se lo hemos pasado a pipeline, pero no los hemos creado bien para lo que el pipeline necesita
Para arreglar esto usamos AutoModelFor
Modelo AutoModelFor
La librería transformers nos da la oportunidad de crear un modelo para una tarea determinada como
AutoModelForCausalLMque sirve para continuar textosAutoModelForMaskedLMque se usa para rellenar huecosAutoModelForMaskGenerationque sirve para generar máscarasAutoModelForSeq2SeqLMque se usa para convertir de secuencias a secuencias, como por ejemplo en traducciónAutoModelForSequenceClassificationpara clasificación de textoAutoModelForMultipleChoicepara elección múltipleAutoModelForNextSentencePredictionpara predecir si dos frases son consecutivasAutoModelForTokenClassificationpara clasificación de tokensAutoModelForQuestionAnsweringpara preguntas y respuestasAutoModelForTextEncodingpara codificación de texto
Vamos a usar el modelo anterior para generar texto
from transformers import AutoTokenizer, AutoModelForCausalLMfrom transformers import pipelinetokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish")pipeline("text-generation", model=model, tokenizer=tokenizer)("Me encanta aprender de")[0]['generated_text']Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
'Me encanta aprender de mi familia. La verdad no sabía que se necesitaba tanto en este pequeño restaurante ya que mi novio en un principio había ido, pero hoy me ha entrado un gusanillo entre pecho y espalda que'
Ahora sí funciona, porque hemos creado el modelo de una manera que pipeline puede entender
Inferencia solo con AutoClass
Antes hemos creado el modelo y el tokenizador y se lo hemos dado a pipeline para que por debajo haga lo necesario, pero podemos usar nosotros los métodos para la inferencia.
Generación de texto casual
Creamos el modelo y el tokenizador
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)Copied
Con device_map, hemos cargado el modelo en la GPU 0
Ahora tenemos que hacer nosotros lo que antes hacía pipeline
Primero generamos los tokens
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")Copied
---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[2], line 1----> 1 tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:2829, in PreTrainedTokenizerBase.__call__(self, text, text_pair, text_target, text_pair_target, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)2827 if not self._in_target_context_manager:2828 self._switch_to_input_mode()-> 2829 encodings = self._call_one(text=text, text_pair=text_pair, **all_kwargs)2830 if text_target is not None:2831 self._switch_to_target_mode()File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:2915, in PreTrainedTokenizerBase._call_one(self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)2910 raise ValueError(2911 f"batch length of `text`: {len(text)} does not match batch length of `text_pair`:"2912 f" {len(text_pair)}."2913 )2914 batch_text_or_text_pairs = list(zip(text, text_pair)) if text_pair is not None else text-> 2915 return self.batch_encode_plus(2916 batch_text_or_text_pairs=batch_text_or_text_pairs,2917 add_special_tokens=add_special_tokens,2918 padding=padding,2919 truncation=truncation,2920 max_length=max_length,2921 stride=stride,2922 is_split_into_words=is_split_into_words,2923 pad_to_multiple_of=pad_to_multiple_of,2924 return_tensors=return_tensors,2925 return_token_type_ids=return_token_type_ids,2926 return_attention_mask=return_attention_mask,2927 return_overflowing_tokens=return_overflowing_tokens,2928 return_special_tokens_mask=return_special_tokens_mask,2929 return_offsets_mapping=return_offsets_mapping,2930 return_length=return_length,2931 verbose=verbose,2932 **kwargs,2933 )2934 else:2935 return self.encode_plus(2936 text=text,2937 text_pair=text_pair,(...)2953 **kwargs,2954 )File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:3097, in PreTrainedTokenizerBase.batch_encode_plus(self, batch_text_or_text_pairs, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)3080 """3081 Tokenize and prepare for the model a list of sequences or a list of pairs of sequences.3082(...)3093 details in `encode_plus`).3094 """3096 # Backward compatibility for 'truncation_strategy', 'pad_to_max_length'-> 3097 padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(3098 padding=padding,3099 truncation=truncation,3100 max_length=max_length,3101 pad_to_multiple_of=pad_to_multiple_of,3102 verbose=verbose,3103 **kwargs,3104 )3106 return self._batch_encode_plus(3107 batch_text_or_text_pairs=batch_text_or_text_pairs,3108 add_special_tokens=add_special_tokens,(...)3123 **kwargs,3124 )File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:2734, in PreTrainedTokenizerBase._get_padding_truncation_strategies(self, padding, truncation, max_length, pad_to_multiple_of, verbose, **kwargs)2732 # Test if we have a padding token2733 if padding_strategy != PaddingStrategy.DO_NOT_PAD and (self.pad_token is None or self.pad_token_id < 0):-> 2734 raise ValueError(2735 "Asking to pad but the tokenizer does not have a padding token. "2736 "Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` "2737 "or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`."2738 )2740 # Check that we will truncate to a multiple of pad_to_multiple_of if both are provided2741 if (2742 truncation_strategy != TruncationStrategy.DO_NOT_TRUNCATE2743 and padding_strategy != PaddingStrategy.DO_NOT_PAD(...)2746 and (max_length % pad_to_multiple_of != 0)2747 ):ValueError: Asking to pad but the tokenizer does not have a padding token. Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`.
Vemos que nos ha dado un error, nos dice que el tokenizador no tiene token de padding. La mayoría de LLMs no tienen un token de padding, pero para usar la librería transformers es necesario un token de padding, por lo que se suele hacer es asignar el token de fin de sentencia al token de padding
tokenizer.pad_token = tokenizer.eos_tokenCopied
Ahora ya podemos generar los tokens
tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_input.input_idsCopied
tensor([[2879, 4835, 3760, 225, 72, 73]], device='cuda:0')
Ahora se los pasamos al modelo que generará nuevos tokens, para eso usamos el método generate
tokens_output = model.generate(**tokens_input, max_length=50)print(f"input tokens: {tokens_input.input_ids}")print(f"output tokens: {tokens_output}")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
input tokens: tensor([[2879, 4835, 3760, 225, 72, 73]], device='cuda:0')output tokens: tensor([[ 2879, 4835, 3760, 225, 72, 73, 314, 2533, 16, 287,225, 73, 82, 513, 1086, 225, 72, 73, 314, 288,357, 15550, 16, 287, 225, 73, 87, 288, 225, 73,82, 291, 3500, 16, 225, 73, 87, 348, 929, 225,72, 73, 3760, 225, 72, 73, 314, 2533, 18, 203]],device='cuda:0')
Podemos ver que los primeros tokens de token_inputs son los mismos que los de token_outputs, los que vienen a continuación son los que ha generado el modelo
Ahora tenemos que convertir esos tokens a una sentencia mediante el decoder del tokenizador
sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)sentence_outputCopied
'Me encanta aprender de los demás, y en este caso de los que me rodean, y es que en el fondo, es una forma de aprender de los demás. '
Ya tenemos el texto generado
Clasificación de texto
Creamos el modelo y el tokenizador
import torchfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationtokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")model = AutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model", device_map=0)Copied
Generamos los tokens
text = "This was a masterpiece. Not completely faithful to the books, but enthralling from beginning to end. Might be my favorite of the three."inputs = tokenizer(text, return_tensors="pt").to("cuda")Copied
Una vez tenemos los tokens, clasificamos
with torch.no_grad():logits = model(**inputs).logitspredicted_class_id = logits.argmax().item()prediction = model.config.id2label[predicted_class_id]predictionCopied
'LABEL_1'
Vamos a ver las clases
clases = model.config.id2labelclasesCopied
{0: 'LABEL_0', 1: 'LABEL_1'}
Así no hay quien se entere, así que lo modificamos
model.config.id2label = {0: "NEGATIVE", 1: "POSITIVE"}Copied
Y ahora volvemos a clasificar
with torch.no_grad():logits = model(**inputs).logitspredicted_class_id = logits.argmax().item()prediction = model.config.id2label[predicted_class_id]predictionCopied
'POSITIVE'
Clasificación de tokens
Creamos el modelo y el tokenizador
import torchfrom transformers import AutoTokenizer, AutoModelForTokenClassificationtokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model", device_map=0)Copied
Generamos los tokens
text = "The Golden State Warriors are an American professional basketball team based in San Francisco."inputs = tokenizer(text, return_tensors="pt").to("cuda")Copied
Una vez tenemos los tokens, clasificamos
with torch.no_grad():logits = model(**inputs).logitspredictions = torch.argmax(logits, dim=2)predicted_token_class = [model.config.id2label[t.item()] for t in predictions[0]]for i in range(len(inputs.input_ids[0])):print(f"{inputs.input_ids[0][i]} ({tokenizer.decode([inputs.input_ids[0][i]])}) -> {predicted_token_class[i]}")Copied
101 ([CLS]) -> O1996 (the) -> O3585 (golden) -> B-location2110 (state) -> I-location6424 (warriors) -> B-group2024 (are) -> O2019 (an) -> O2137 (american) -> O2658 (professional) -> O3455 (basketball) -> O2136 (team) -> O2241 (based) -> O1999 (in) -> O2624 (san) -> B-location3799 (francisco) -> B-location1012 (.) -> O102 ([SEP]) -> O
Como se puede ver los tokens correspondientes a golden, state, warriors, san y francisco los ha clasificado como tokens de localización
Respuesta a preguntas (question answering)
Creamos el modelo y el tokenizador
import torchfrom transformers import AutoTokenizer, AutoModelForQuestionAnsweringtokenizer = AutoTokenizer.from_pretrained("mrm8488/roberta-base-1B-1-finetuned-squadv1")model = AutoModelForQuestionAnswering.from_pretrained("mrm8488/roberta-base-1B-1-finetuned-squadv1", device_map=0)Copied
Some weights of the model checkpoint at mrm8488/roberta-base-1B-1-finetuned-squadv1 were not used when initializing RobertaForQuestionAnswering: ['roberta.pooler.dense.bias', 'roberta.pooler.dense.weight']- This IS expected if you are initializing RobertaForQuestionAnswering from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).- This IS NOT expected if you are initializing RobertaForQuestionAnswering from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Generamos los tokens
question = "How many programming languages does BLOOM support?"context = "BLOOM has 176 billion parameters and can generate text in 46 languages natural languages and 13 programming languages."inputs = tokenizer(question, context, return_tensors="pt").to("cuda")Copied
Una vez tenemos los tokens, clasificamos
with torch.no_grad():outputs = model(**inputs)answer_start_index = outputs.start_logits.argmax()answer_end_index = outputs.end_logits.argmax()predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]tokenizer.decode(predict_answer_tokens)Copied
' 13'
Modelización del lenguaje enmascarado (Masked language modeling)
Creamos el modelo y el tokenizador
import torchfrom transformers import AutoTokenizer, AutoModelForMaskedLMtokenizer = AutoTokenizer.from_pretrained("nyu-mll/roberta-base-1B-1")model = AutoModelForMaskedLM.from_pretrained("nyu-mll/roberta-base-1B-1", device_map=0)Copied
Some weights of the model checkpoint at nyu-mll/roberta-base-1B-1 were not used when initializing RobertaForMaskedLM: ['roberta.pooler.dense.bias', 'roberta.pooler.dense.weight']- This IS expected if you are initializing RobertaForMaskedLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).- This IS NOT expected if you are initializing RobertaForMaskedLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Generamos los tokens
text = "The Milky Way is a <mask> galaxy."inputs = tokenizer(text, return_tensors="pt").to("cuda")mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]Copied
Una vez tenemos los tokens, clasificamos
with torch.no_grad():logits = model(**inputs).logitsmask_token_logits = logits[0, mask_token_index, :]top_3_tokens = torch.topk(mask_token_logits, 3, dim=1).indices[0].tolist()for token in top_3_tokens:print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))Copied
The Milky Way is a spiral galaxy.The Milky Way is a closed galaxy.The Milky Way is a distant galaxy.
Personalización del modelo
Antes hemos hecho la inferencia con AutoClass, pero lo hemos hecho con las configuraciones por defecto del modelo. Pero podemos configurar el modelo todo lo que queramos
Vamos a instanciar un modelo y a ver su configuración
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfigtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)config = AutoConfig.from_pretrained("flax-community/gpt-2-spanish")configCopied
GPT2Config {"_name_or_path": "flax-community/gpt-2-spanish","activation_function": "gelu_new","architectures": ["GPT2LMHeadModel"],"attn_pdrop": 0.0,"bos_token_id": 50256,"embd_pdrop": 0.0,"eos_token_id": 50256,"gradient_checkpointing": false,"initializer_range": 0.02,"layer_norm_epsilon": 1e-05,"model_type": "gpt2","n_ctx": 1024,"n_embd": 768,"n_head": 12,"n_inner": null,"n_layer": 12,"n_positions": 1024,"reorder_and_upcast_attn": false,"resid_pdrop": 0.0,"scale_attn_by_inverse_layer_idx": false,"scale_attn_weights": true,"summary_activation": null,"summary_first_dropout": 0.1,"summary_proj_to_labels": true,"summary_type": "cls_index","summary_use_proj": true,"task_specific_params": {"text-generation": {"do_sample": true,"max_length": 50}},"transformers_version": "4.38.1","use_cache": true,"vocab_size": 50257}
Podemos ver la configuración del modelo, por ejemplo la función de activación es gelu_new, tiene 12 heads, el tamaño del vocabulario es 50257 palabras, etc.
Pero podemos modificar esta configuración
config = AutoConfig.from_pretrained("flax-community/gpt-2-spanish", activation_function="relu")config.activation_functionCopied
'relu'
Creamos ahora el modelo con esta configuración
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", config=config, device_map=0)Copied
Y generamos texto
tokenizer.pad_token = tokenizer.eos_tokentokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_length=50)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)sentence_outputCopied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
'Me encanta aprender de la d d e d e d e d e d e d e d e d e d e d e '
Vemos que esta modificación hace que no genere tan buen texto
Tokenización
Hasta ahora hemos visto las diferentes maneras que hay de hacer inferencia con la librería transformers. Ahora nos vamos a meter en las tripas de la librería. Para ello primero vamos a ver cosas a tener en cuenta a la hora de tokenizar.
No vamos a explicar lo que es tokenizar a fondo, ya que eso ya lo explicamos en el post de la librería tokenizers
Padding
Cuando se tiene un batch de secuencias, a veces es necesario que después de tokenizar, todas las secuencias tengan la misma longitud, así que para ello usamos el parámetro padding=True
from transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish", pad_token="PAD")encoded_input = tokenizer(batch_sentences, padding=True)for encoded in encoded_input["input_ids"]:print(encoded)print(f"Padding token id: {tokenizer.pad_token_id}")Copied
[2959, 16, 875, 3736, 3028, 303, 291, 2200, 8080, 35, 50257, 50257][1489, 2275, 288, 12052, 382, 325, 2200, 8080, 16, 4319, 50257, 50257][1699, 2899, 707, 225, 72, 73, 314, 34630, 474, 515, 1259, 35]Padding token id: 50257
Como vemos, a las dos primeras secuencias les ha añadido un padding al final
Truncado
A parte de añadir padding, a veces es necesario truncar las secuencias para que no ocupen más de un número determinado de tokens. Para ello establecemos truncation=True y max_length con el número de tokens que queremos que tenga la secuencia
from transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")encoded_input = tokenizer(batch_sentences, truncation=True, max_length=5)for encoded in encoded_input["input_ids"]:print(encoded)Copied
[2959, 16, 875, 3736, 3028][1489, 2275, 288, 12052, 382][1699, 2899, 707, 225, 72]
Las mismas sentencias de antes, ahora generan menos tokens
Tensores
Hasta ahora estábamos recibiendo listas de tokens, pero seguramente nos interese recibir tensores de PyTorch o TensorFlow. Para ello usamos el parámetro return_tensors y le especificamos de qué framework queremos recibir el tensor, en nuestro caso elegiremos PyTorch con pt
Vemos primero sin especificar que nos devuelva tensores
from transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish", pad_token="PAD")encoded_input = tokenizer(batch_sentences, padding=True)for encoded in encoded_input["input_ids"]:print(type(encoded))Copied
<class 'list'><class 'list'><class 'list'>
Recibimos listas, si queremos recibir tensores de PyTorch usamos return_tensors="pt"
from transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish", pad_token="PAD")encoded_input = tokenizer(batch_sentences, padding=True, return_tensors="pt")for encoded in encoded_input["input_ids"]:print(type(encoded), encoded.shape)print(type(encoded_input["input_ids"]), encoded_input["input_ids"].shape)Copied
<class 'torch.Tensor'> torch.Size([12])<class 'torch.Tensor'> torch.Size([12])<class 'torch.Tensor'> torch.Size([12])<class 'torch.Tensor'> torch.Size([3, 12])
Máscaras
Cuando tokenizamos una sentencia no solo obtenemos los input_ids, sino que también obtenemos la máscara de atención. La máscara de atención es un tensor que tiene el mismo tamaño que input_ids y tiene un 1 en las posiciones que son tokens y un 0 en las posiciones que son padding
from transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish", pad_token="PAD")encoded_input = tokenizer(batch_sentences, padding=True)print(f"padding token id: {tokenizer.pad_token_id}")print(f" encoded_input[0] inputs_ids: {encoded_input['input_ids'][0]}")print(f"encoded_input[0] attention_mask: {encoded_input['attention_mask'][0]}")print(f" encoded_input[1] inputs_ids: {encoded_input['input_ids'][1]}")print(f"encoded_input[1] attention_mask: {encoded_input['attention_mask'][1]}")print(f" encoded_input[2] inputs_ids: {encoded_input['input_ids'][2]}")print(f"encoded_input[2] attention_mask: {encoded_input['attention_mask'][2]}")Copied
padding token id: 50257encoded_input[0] inputs_ids: [2959, 16, 875, 3736, 3028, 303, 291, 2200, 8080, 35, 50257, 50257]encoded_input[0] attention_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]encoded_input[1] inputs_ids: [1489, 2275, 288, 12052, 382, 325, 2200, 8080, 16, 4319, 50257, 50257]encoded_input[1] attention_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]encoded_input[2] inputs_ids: [1699, 2899, 707, 225, 72, 73, 314, 34630, 474, 515, 1259, 35]encoded_input[2] attention_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
Como se puede ver, en las dos primeras sentencias, tenemos un 1 en las primeras posiciones y un 0 en las dos últimas posiciones. En esas mismas posiciones tenemos el token 50257, que corresponde al token de padding.
Con estas máscaras de atención le estamos diciendo al modelo a qué tokens tiene que prestar atención y a cuáles no.
La generación de texto se podría hacer igualmente si no pasáramos estas máscaras de atención, el método generate haría su mayor esfuerzo por inferir esta máscara, pero si se la pasamos ayudamos a generar mejor texto
Fast Tokenizers
Algunos tokenizadores preentrenados tienen una versión fast, tienen los mismos métodos que los normales, solo que están desarrollados en Rust. Para usarlos debemos usar la clase PreTrainedTokenizerFast de la librería transformers
Veamos primero el tiempo de tokenización con un tokenizador normal
%%timefrom transformers import BertTokenizertokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")sentence = ("The Permaculture Design Principles are a set of universal design principles ""that can be applied to any location, climate and culture, and they allow us to design ""the most efficient and sustainable human habitation and food production systems. ""Permaculture is a design system that encompasses a wide variety of disciplines, such ""as ecology, landscape design, environmental science and energy conservation, and the ""Permaculture design principles are drawn from these various disciplines. Each individual ""design principle itself embodies a complete conceptual framework based on sound ""scientific principles. When we bring all these separate principles together, we can ""create a design system that both looks at whole systems, the parts that these systems ""consist of, and how those parts interact with each other to create a complex, dynamic, ""living system. Each design principle serves as a tool that allows us to integrate all ""the separate parts of a design, referred to as elements, into a functional, synergistic, ""whole system, where the elements harmoniously interact and work together in the most ""efficient way possible.")tokens = tokenizer([sentence], padding=True, return_tensors="pt")Copied
CPU times: user 55.3 ms, sys: 8.58 ms, total: 63.9 msWall time: 226 ms
Y ahora con uno rápido
%%timefrom transformers import BertTokenizerFasttokenizer = BertTokenizerFast.from_pretrained("google-bert/bert-base-uncased")sentence = ("The Permaculture Design Principles are a set of universal design principles ""that can be applied to any location, climate and culture, and they allow us to design ""the most efficient and sustainable human habitation and food production systems. ""Permaculture is a design system that encompasses a wide variety of disciplines, such ""as ecology, landscape design, environmental science and energy conservation, and the ""Permaculture design principles are drawn from these various disciplines. Each individual ""design principle itself embodies a complete conceptual framework based on sound ""scientific principles. When we bring all these separate principles together, we can ""create a design system that both looks at whole systems, the parts that these systems ""consist of, and how those parts interact with each other to create a complex, dynamic, ""living system. Each design principle serves as a tool that allows us to integrate all ""the separate parts of a design, referred to as elements, into a functional, synergistic, ""whole system, where the elements harmoniously interact and work together in the most ""efficient way possible.")tokens = tokenizer([sentence], padding=True, return_tensors="pt")Copied
CPU times: user 42.6 ms, sys: 3.26 ms, total: 45.8 msWall time: 179 ms
Se puede ver como el BertTokenizerFast es unos 40 ms más rápido
Formas de generación de texto
Seguimos con las tripas de la librería transformers, ahora vamos a ver las maneras de generar texto.
La arquitectura transformer genera el siguiente token más probable, esta es la manera más sencilla de generar texto, pero no es la única, así que vamos a verlas.
A la hora de generar texto no hay una forma mejor y dependerá de nuestro modelo y del propósito de uso
Greedy Search
Es la manera más sencilla de generación de texto. Busca el token más probable en cada iteracción
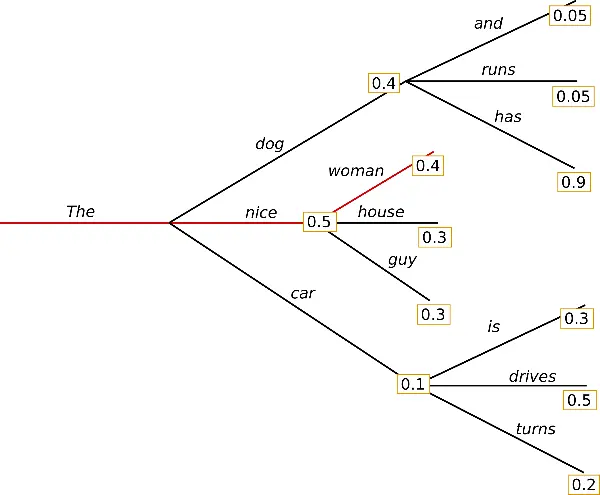
Para generar texto de esta manera con transformers no hay que hacer nada especial, ya que es la manera por defecto
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás, y en este caso de los que me rodean, y es que en el fondo, es una forma de aprender de los demás.En este caso, el objetivo de la actividad es que los niños aprendan a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños se han dado cuenta de que los animales que hay en el mundo, son muy difíciles de reconocer, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que e
Se puede ver que el texto generado está bien, pero se empieza a repetir. Esto es porque en la búsqueda codiciosa (greedy search), las palabras con una alta probabilidad se pueden esconder detrás de palabras con una probabilidad más baja, por lo que se pueden perder
Aquí, la palabra has tiene una alta probabilidad, pero queda escondida detrás de dog, que tiene menor probabilidad que nice
Contrastive Search
El método Contrastive Search optimiza la generación de texto seleccionando las opciones de palabras o frases que maximizan un criterio de calidad sobre otras menos deseables. En la práctica, esto significa que durante la generación de texto, en cada paso, el modelo no solo busca la siguiente palabra que tiene mayor probabilidad de seguir según lo aprendido durante su entrenamiento, sino que también compara diferentes candidatos para esa próxima palabra y evalúa cuál de ellos contribuiría a formar el texto más coherente, relevante y de alta calidad en el contexto dado. Por lo tanto, Contrastive Search reduce la posibilidad de generar respuestas irrelevantes o de baja calidad, enfocándose en aquellas opciones que mejor se ajustan al objetivo de la generación de texto, basándose en una comparación directa entre posibles continuaciones en cada paso del proceso.
Para generar texto con contrastive search en transformers hay que usar los parámetros penalty_alpha y top_k a la hora de generar texto
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, penalty_alpha=0.6, top_k=4)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás, es una de las cosas que más me gusta del mundo.En la clase de hoy he estado haciendo un repaso de lo que es el arte de la costura, para que podáis ver como se hace una prenda de ropa y como se confeccionan los patrones.El patrón de esta blusa es de mi amiga Marga, que me ha pedido que os enseñara a hacer este tipo de prendas, ya que es una de las cosas que más me gusta del mundo.La blusa es de la talla S, y tiene un largo de manga 3/4, por lo que es ideal para cualquier ocasión.Para hacer el patrón de esta blusa utilicé una tela de algodón 100% de color azul marino, que es la que yo he utilizado para hacer la blusa.En la parte delantera de la blusa, cosí un lazo de raso de color azul marino, que le da un toque de color a la prenda.Como podéis ver en la foto, el patrón de esta blusa es de la talla S, y tiene un largo de manga 3/4, por lo que es ideal para cualquier ocasión.Para hacer el patrón de esta blusa utilicé una tela de algodón 100% de color azul marino, que es la que yo he utilizado para hacer la blusa.En la parte delantera de la blusa utilicé un lazo de raso de color azul marino, que le da un toque de color a la prenda.Para hacer el patrón de esta blusa utilicé una tela de algodón 100% de color azul marino, que es la que yo he utilizado para hacer la blusa.En la parte delantera de la blusa utilicé un lazo de raso de color azul marino, que le da un toque de color a la prenda.Para hacer el patrón de esta blusa utilicé una tela de algodón 100% de color azul marino, que es la que yo he utilizado para hacer la blusa.En la parte delantera de la blusa utilicé
Aquí el modelo tarda más en empezar a repetirse
Multinomial sampling
A diferencia de la búsqueda codiciosa que siempre elige un token con la mayor probabilidad como el siguiente token, el muestreo multinomial (también llamado muestreo ancestral) selecciona aleatoriamente el siguiente token en función de la distribución de probabilidad de todo el vocabulario proporcionado por el modelo. Cada token con una probabilidad distinta de cero tiene posibilidades de ser seleccionado, lo que reduce el riesgo de repetición.
Para habilitar el Multinomial sampling hay que poner do_sample=True y num_beams=1.
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, num_beams=1)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los de siempre y conocer a gente nueva, soy de las que no tiene mucho contacto con los de antes, pero he estado bastante liada con el diseño de mi página web de lo que sería el logo, he escrito varios diseños para otros blogs y cosas así, así que a ver si pronto puedo poner de mi parte alguna ayuda.A finales de los años 70 del pasado siglo los arquitectos alemanes Hermann Grossberg y Heinrich Rindsner eran los principales representantes de la arquitectura industrial de la alta sociedad. La arquitectura industrial era la actividad que más rápido progresaba en el diseño, y de ellos destacaban los diseños que Grossberg llevó a cabo en el prestigioso Hotel Marigal.De acuerdo con las conclusiones y opiniones expuestas por los autores sobre el reciente congreso sobre historia del diseño industrial, se ha llegado al convencimiento de que en los últimos años, los diseñadores industriales han descubierto muchas nuevas formas de entender la arquitectura. En palabras de Klaus Eindhoven, director general de la fundación alemana G. Grossberg, “estamos tratando de desarrollar un trabajo que tenga en cuenta los criterios más significativos de la teoría arquitectónica tradicional”.En este artículo de opinión, Eindhoven y Grossberg explican por qué el auge de la arquitectura industrial en Alemania ha generado una gran cantidad de nuevos diseños de viviendas, de grandes dimensiones, de edificios de gran valor arquitectónico. Los más conocidos son los de los diseñadores Walter Nachtmann (1934) e ingeniero industrial, Frank Gehry (1929), arquitecto que ideó las primeras viviendas de estilo neoclásico en la localidad británica de Stegmarbe. Son viviendas de los siglos XVI al XX, algunas con un estilo clasicista que recuerda las casas de Venecia. Se trata de edificios con un importante valor histórico y arquitectónico, y que representan la obra de la técnica del modernismo.La teoría general sobre los efectos de la arquitectura en un determinado tipo de espacio no ha resultado ser totalmente transparente, y mucho menos para los arquitectos, que tienen que aprender de los arquitectos de ayer, durante esos
La verdad es que el modelo no se repite nada, pero siento que estoy hablando con un niño pequeño, que habla de un tema y empieza a hilar con otros que no tienen nada que ver
Beam search
La búsqueda por haz reduce el riesgo de perder secuencias de palabras ocultas de alta probabilidad al mantener el num_beams más probable en cada paso de tiempo y, finalmente, elegir la hipótesis que tenga la probabilidad más alta en general.
Para generar con beam search es necesario añadir el parámetro num_beams
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de
Se repite bastante
Beam search multinomial sampling
Esta técnica junta el beam search donde se busca por haz y el multinomial sampling donde se selecciona aleatoriamente el siguiente token en función de la distribución de probabilidad de todo el vocabulario proporcionado por el modelo.
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, do_sample=True)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y e
Se repite bastante
Beam search n-grams penalty
Para evitar la repetición podemos penalizar por la repetición de n-gramas. Para ello usamos el parámetro no_repeat_ngram_size
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, no_repeat_ngram_size=2)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás, y en este caso, no podía ser menos, así que me puse manos a la obra.En primer lugar, me hice con un libro que se llama "El mundo eslavo" y que, como ya os he dicho, se puede adquirir por un módico precio (unos 5 euros).El libro está compuesto por dos partes: la primera, que trata sobre la historia del Imperio Romano y la segunda, sobre el Imperio Bizantino. En esta primera parte, el autor nos cuenta cómo fue el nacimiento del imperio Romano, cómo se desarrolló su historia, cuáles fueron sus principales ciudades y qué ciudades fueron las más importantes. Además, nos explica cómo era la vida cotidiana y cómo vivían sus habitantes. Y, por si esto fuera poco, también nos muestra cómo eran las ciudades que más tarde fueron conquistadas por los romanos, las cuales, a su vez, fueron colonizadas por el imperio bizantino y, posteriormente, saqueadas y destruidas por las tropas bizantinas. Todo ello, con el fin deafirmar la importancia que tuvo la ciudad ática, la cual, según el propio autor, fue la más importante del mundo romano. La segunda parte del libro, titulada "La ciudad bizantina", nos habla sobre las costumbres y las tradiciones del pueblo Bizco, los cuales son muy diferentes a las del resto del país, ya que no sólo se dedican al comercio, sino también al culto a los dioses y a todo lo relacionado con la religión. Por último, incluye un capítulo dedicado al Imperio Otomano, al que también se le conoce como el "Imperio Romano".Por otro lado, os dejo un enlace a una página web donde podréis encontrar más información sobre este libro: http://www.elmundodeuterio.com/es/libros/el-mundo-sucio-y-la-historia-del-imperio-ibero-italia/Como podéis ver, he querido hacer un pequeño homenaje a todas las personas que han hecho posible que el libro se haya hecho realidad. Espero que os haya gustado y os animéis a adquirirlo. Si tenéis alguna duda, podéis dejarme un comentario o escribirme un correo a mi correo electrónico: [email protected]¡Hola a todos! ¿Qué tal estáis? Hoy os traigo una entrada muy especial. Se trata del sorteo que he hecho para celebrar el día del padre. Como ya sabéis, este año no he tenido mucho tiempo, pero
Este texto ya no se repite y además tiene algo más de coherencia.
Sin embargo, las penalizaciones de n-gramas deben utilizarse con cuidado. Un artículo generado sobre la ciudad de Nueva York no debería usar una penalización de 2 gramos o, de lo contrario, ¡el nombre de la ciudad solo aparecería una vez en todo el texto!
Beam search n-grams penalty return sequences
Podemos generar varias secuencias para compararlas y quedarnos con la mejor. Para ello usamos el parámetro num_return_sequences con la condición de que num_return_sequences <= num_beams
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_outputs = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, no_repeat_ngram_size=2, num_return_sequences=3)for i, tokens_output in enumerate(tokens_outputs):if i != 0:print(" ")sentence_output = tokenizer.decode(tokens_output, skip_special_tokens=True)print(f"{i}: {sentence_output}")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
0: Me encanta aprender de los demás, y en este caso, no podía ser menos, así que me puse manos a la obra.En primer lugar, me hice con un libro que se llama "El mundo eslavo" y que, como ya os he dicho, se puede adquirir por un módico precio (unos 5 euros).El libro está compuesto por dos partes: la primera, que trata sobre la historia del Imperio Romano y la segunda, sobre el Imperio Bizantino. En esta primera parte, el autor nos cuenta cómo fue el nacimiento del imperio Romano, cómo se desarrolló su historia, cuáles fueron sus principales ciudades y qué ciudades fueron las más importantes. Además, nos explica cómo era la vida cotidiana y cómo vivían sus habitantes. Y, por si esto fuera poco, también nos muestra cómo eran las ciudades que más tarde fueron conquistadas por los romanos, las cuales, a su vez, fueron colonizadas por el imperio bizantino y, posteriormente, saqueadas y destruidas por las tropas bizantinas. Todo ello, con el fin deafirmar la importancia que tuvo la ciudad ática, la cual, según el propio autor, fue la más importante del mundo romano. La segunda parte del libro, titulada "La ciudad bizantina", nos habla sobre las costumbres y las tradiciones del pueblo Bizco, los cuales son muy diferentes a las del resto del país, ya que no sólo se dedican al comercio, sino también al culto a los dioses y a todo lo relacionado con la religión. Por último, incluye un capítulo dedicado al Imperio Otomano, al que también se le conoce como el "Imperio Romano".Por otro lado, os dejo un enlace a una página web donde podréis encontrar más información sobre este libro: http://www.elmundodeuterio.com/es/libros/el-mundo-sucio-y-la-historia-del-imperio-ibero-italia/Como podéis ver, he querido hacer un pequeño homenaje a todas las personas que han hecho posible que el libro se haya hecho realidad. Espero que os haya gustado y os animéis a adquirirlo. Si tenéis alguna duda, podéis dejarme un comentario o escribirme un correo a mi correo electrónico: [email protected]¡Hola a todos! ¿Qué tal estáis? Hoy os traigo una entrada muy especial. Se trata del sorteo que he hecho para celebrar el día del padre. Como ya sabéis, este año no he tenido mucho tiempo, pero1: Me encanta aprender de los demás, y en este caso, no podía ser menos, así que me puse manos a la obra.En primer lugar, me hice con un libro que se llama "El mundo eslavo" y que, como ya os he dicho, se puede adquirir por un módico precio (unos 5 euros).El libro está compuesto por dos partes: la primera, que trata sobre la historia del Imperio Romano y la segunda, sobre el Imperio Bizantino. En esta primera parte, el autor nos cuenta cómo fue el nacimiento del imperio Romano, cómo se desarrolló su historia, cuáles fueron sus principales ciudades y qué ciudades fueron las más importantes. Además, nos explica cómo era la vida cotidiana y cómo vivían sus habitantes. Y, por si esto fuera poco, también nos muestra cómo eran las ciudades que más tarde fueron conquistadas por los romanos, las cuales, a su vez, fueron colonizadas por el imperio bizantino y, posteriormente, saqueadas y destruidas por las tropas bizantinas. Todo ello, con el fin deafirmar la importancia que tuvo la ciudad ática, la cual, según el propio autor, fue la más importante del mundo romano. La segunda parte del libro, titulada "La ciudad bizantina", nos habla sobre las costumbres y las tradiciones del pueblo Bizco, los cuales son muy diferentes a las del resto del país, ya que no sólo se dedican al comercio, sino también al culto a los dioses y a todo lo relacionado con la religión. Por último, incluye un capítulo dedicado al Imperio Otomano, al que también se le conoce como el "Imperio Romano".Por otro lado, os dejo un enlace a una página web donde podréis encontrar más información sobre este libro: http://www.elmundodeuterio.com/es/libros/el-mundo-sucio-y-la-historia-del-imperio-ibero-italia/Como podéis ver, he querido hacer un pequeño homenaje a todas las personas que han hecho posible que el libro se haya hecho realidad. Espero que os haya gustado y os animéis a adquirirlo. Si tenéis alguna duda, podéis dejarme un comentario o escribirme un correo a mi correo electrónico: [email protected]¡Hola a todos! ¿Qué tal estáis? Hoy os traigo una entrada muy especial. Se trata del sorteo que he hecho para celebrar el día del padre. Como ya sabéis, este año no he tenido mucho tiempo para hacer2: Me encanta aprender de los demás, y en este caso, no podía ser menos, así que me puse manos a la obra.En primer lugar, me hice con un libro que se llama "El mundo eslavo" y que, como ya os he dicho, se puede adquirir por un módico precio (unos 5 euros).El libro está compuesto por dos partes: la primera, que trata sobre la historia del Imperio Romano y la segunda, sobre el Imperio Bizantino. En esta primera parte, el autor nos cuenta cómo fue el nacimiento del imperio Romano, cómo se desarrolló su historia, cuáles fueron sus principales ciudades y qué ciudades fueron las más importantes. Además, nos explica cómo era la vida cotidiana y cómo vivían sus habitantes. Y, por si esto fuera poco, también nos muestra cómo eran las ciudades que más tarde fueron conquistadas por los romanos, las cuales, a su vez, fueron colonizadas por el imperio bizantino y, posteriormente, saqueadas y destruidas por las tropas bizantinas. Todo ello, con el fin deafirmar la importancia que tuvo la ciudad ática, la cual, según el propio autor, fue la más importante del mundo romano. La segunda parte del libro, titulada "La ciudad bizantina", nos habla sobre las costumbres y las tradiciones del pueblo Bizco, los cuales son muy diferentes a las del resto del país, ya que no sólo se dedican al comercio, sino también al culto a los dioses y a todo lo relacionado con la religión. Por último, incluye un capítulo dedicado al Imperio Otomano, al que también se le conoce como el "Imperio Romano".Por otro lado, os dejo un enlace a una página web donde podréis encontrar más información sobre este libro: http://www.elmundodeuterio.com/es/libros/el-mundo-sucio-y-la-historia-del-imperio-ibero-italia/Como podéis ver, he querido hacer un pequeño homenaje a todas las personas que han hecho posible que el libro se haya hecho realidad. Espero que os haya gustado y os animéis a adquirirlo. Si tenéis alguna duda, podéis dejarme un comentario o escribirme un correo a mi correo electrónico: [email protected]¡Hola a todos! ¿Qué tal estáis? Hoy os traigo una entrada muy especial. Se trata del sorteo que he hecho para celebrar el día del padre. Como ya sabéis, este año no he tenido mucho tiempo para publicar
Ahora podemos quedarnos con la mejor secuencia
Diverse beam search decoding
La diverse beam search decoding es una extensión de la estrategia de búsqueda de haces que permite generar un conjunto más diverso de secuencias de haces para elegir.
Para poder generar texto de esta manera tenemos que usar los parámetros num_beams, num_beam_groups y diversity_penalty
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, num_beam_groups=5, diversity_penalty=1.0)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender
Este método parece que se repite bastante
Speculative Decoding
La decodificación especulativa (también conocida como decodificación asistida) es una modificación de las estrategias de decodificación anteriores, que utiliza un modelo asistente (idealmente uno mucho más pequeño) con el mismo tokenizador, para generar algunos tokens candidatos. Luego, el modelo principal valida los tokens candidatos en un único paso hacia adelante, lo que acelera el proceso de decodificación
Para generar texto de esta manera es necesario usar el parámetro do_sample=True
Actualmente, la decodificación asistida solo admite greedy search, y la decodificación asistida no admite entradas por lotes
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)assistant_model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, assistant_model=assistant_model, do_sample=True)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás! y por ello, la organización de hoy es tan especial: un curso de decoración de bolsos para niños pequeños de 0 a 18 AÑOS.En este taller aprenderemos a decorar bolsos para regalar, con los materiales que sean necesarios para cubrir las necesidades de estos peques, como pueden ser, un estuche con todo lo que necesiten, ropa interior, mantas, complementos textiles, complementos alimenticios, o un bonito neceser con todo lo que necesiten.Os dejo con un pequeño tutorial de decoración de bolsos para niños, realizado por mi amiga Rosa y sus amigas Silvia y Rosa, que se dedica a la creación de bolsos para bebés que son un verdadero tesoro para sus pequeños. Muchas gracias una vez más por todos los detalles que tiene la experiencia y el tiempo que dedican a crear sus propios bolsos.En muchas ocasiones, cuando se nos acerca una celebración, siempre nos preguntamos por qué, por qué en especial, por que se trata de algo que no tienen tan cerca nuestras vidas y, claro está, también por que nos hemos acostumbrado a vivir en el mundo de lo mundano y de lo comercial, tal y como los niños y niñas de hoy, a la manera de sus padres, donde todo es caro, todo es difícil, los precios no están al alcance de todos y, por estas y por muchas más preguntas por las que estamos deseando seguir escuchando, este curso y muchas otras cosas que os encontraréis a lo largo de la mañana de hoy, os van a dar la clave sobre la que empezar a preparar una fiesta de esta importancia.El objetivo del curso es que aprendáis a decorar bolsos para regalar con materiales sencillos, simples y de buena calidad; que os gusten y os sirvan de decoración y que por supuesto os sean útiles. Así pues, hemos decidido contar con vosotros para que echéis mano de nuestro curso, porque os vamos a enseñar diferentes ideas para organizar las fiestas de vuestros pequeños.Al tratarse de un curso muy básico, vais a encontrar ideas muy variadas, que van desde sencillas manualidades con los bolsillos, hasta mucho más elaboradas y que si lo veis con claridad en un tutorial os vais a poder dar una idea de cómo se ha de aplicar estos consejos a vuestra tienda.
Este método tiene muy buenos resultados
Speculative Decoding randomness control
Cuando se utiliza la decodificación asistida con métodos de muestreo, se puede utilizar el parámetro temperature para controlar la aleatoriedad. Sin embargo, en la decodificación asistida, reducir la temperatura puede ayudar a mejorar la latencia.
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)assistant_model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, assistant_model=assistant_model, do_sample=True, temperature=0.5)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás y de las personas que nos rodean. Y no sólo eso, sino que además me gusta aprender de los demás. He aprendido mucho de los que me rodean y de las personas que me rodean.Me encanta conocer gente nueva, aprender de los demás y de las personas que me rodean. Y no sólo eso, sino que además me gusta aprender de los demás.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.Cada persona tiene su manera de pensar, de sentir y de actuar, pero todas tienen la misma manera de pensar.La mayoría de las personas, por diferentes motivos, se quieren llevar bien con otras personas, pero no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo
Aquí no lo ha generado tan bien
Sampling
Aquí empiezan las técnicas usadas por los LLMs actuales
El método de muestreo se basa en lugar de siempre seleccionar la palabra más probable (que podría llevar a textos predecibles o repetitivos), el muestreo introduce aleatoriedad en el proceso de selección, permitiendo que el modelo explore una variedad de palabras posibles basadas en sus probabilidades. Es como lanzar un dado ponderado para cada palabra. Así, mientras más alta sea la probabilidad de una palabra, más probabilidad tiene de ser seleccionada, pero aún hay una oportunidad para que palabras menos probables sean elegidas, enriqueciendo la diversidad y creatividad del texto generado. Este método ayuda a evitar respuestas monótonas y aumenta la variabilidad y naturalidad del texto producido.
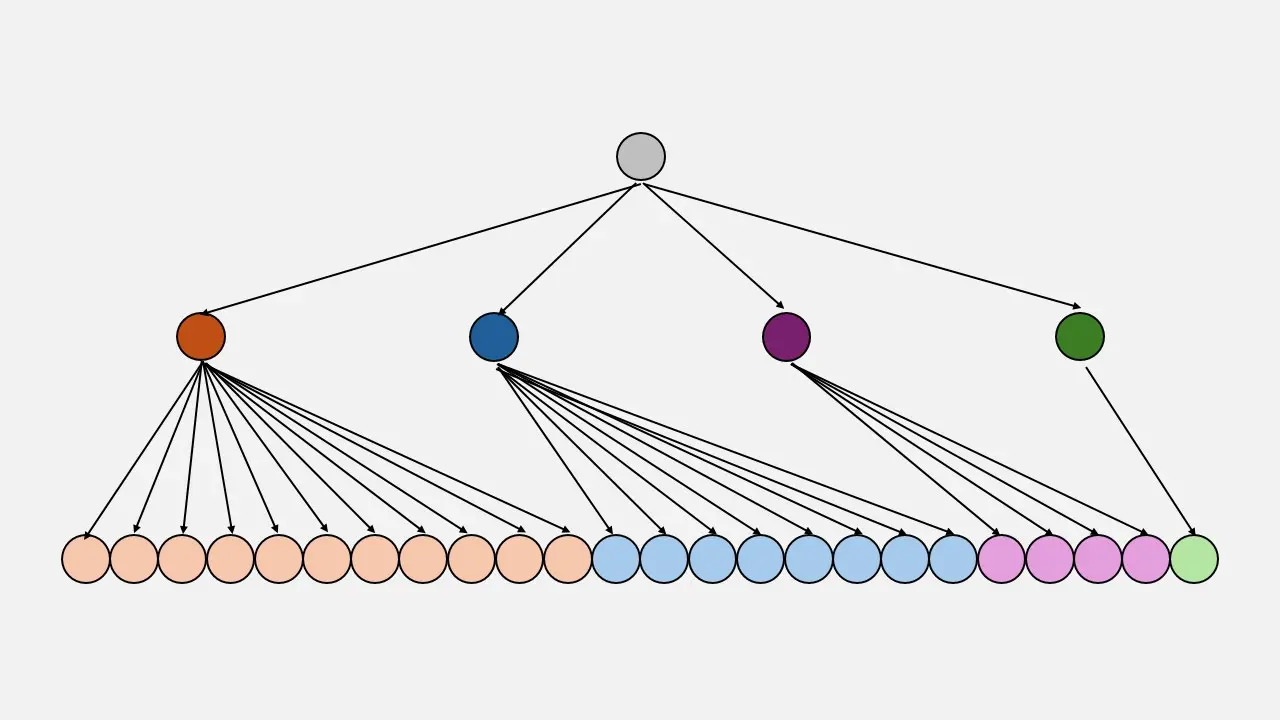
Como se puede ver en la imagen, el primer token, que es el que tiene mayor probabilidad, se ha repetido hasta 11 veces; el segundo, hasta 8 veces; el tercero, hasta 4; y el último solo se ha añadido en 1. De esta manera se elige aleatoriamente entre todos, pero lo más probable es que salga el primer token, ya que es el que aparece más veces
Para usar este método elegimos do_sample=True y top_k=0
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás, conocer a los demás, entender las cosas, la gente y las relaciones? y eso ha sido siempre lo que me ha ocurrido con Zoë a lo largo de estos años. Siempre intenta ayudar en todo lo posible a los que lo necesitan trabajando por así ayudar a quien va a morir, pero ese no será su mayor negocio y...Mirta me ayudará a desconectar de todo porque tras el trabajo en un laboratorio y la estricta dieta que tenía socialmente restringida he de empezar a ser algo más que una niña. Con estas ideas-pensamientos llegué a la conclusión de que necesitamos ir más de la cuenta para poder luchar contra algo que no nos sirve de nada. Para mí eso...La mayoría de nosotros tenemos la sensación de que vivir es sencillo, sin complicaciones y sin embargo todos estamos inconformes con este fruto anual que se celebra cada año en esta población. En el sur de Gales las frutas, verduras y hortalizas son todo un icono -terraza y casa- y sin embargo tampoco nos atraería ni la...Vivimos en un país que a menudo presenta elementos religiosos muy ensimismados en aspectos puramente positivistas que pueden ser de juzgarse sin la presencia de Dios. Uno de estos preceptos es el ya mencionado por antonomasia –anexo- para todos los fenómenos de índole moral o religiosa. Por ejemplo, los sacrificios humanos, pero, la...Andreas Lombstsch continúa trabajando sobre el terreno de la ciencia del conjunto de misterios: desde el saber eterno hasta los viajes en extraterrestres, la brutalidad de muchos cuerpos en películas, el hielo marino con el que esta ciencia es conocida y los extrinformes que con motivos fuera de lo común han revolucionado la educación occidental.Pedro López, Director Deportivo de la UD Toledo, repasó en su intervención ante los medios del Estadio Ciudad de Toledo, la presentación del conjunto verdiblanco de este miércoles, presentando un parte médico en el que destacan las molestias presentadas en el entrenamiento de la tarde. “Quedar fuera en el partido de esa manera con el 41. y por la lesión de Chema (Intuición Araujo aunque ya
No genera texto repetitivo, pero genera un texto que no parece muy coherente. Este es el problema de poder elegir cualquier palabra.
Sampling temperature
Para solventar el problema del método de muestreo se añade un parámetro de temperatura que ajusta el nivel de aleatoriedad en la selección de palabras.
La temperatura es un parámetro que modifica cómo se distribuyen las probabilidades de las posibles siguientes palabras.
Con una temperatura de 1, la distribución de probabilidad se mantiene según lo aprendido por el modelo, manteniendo un equilibrio entre previsibilidad y creatividad
Si se baja la temperatura (menos de 1), se aumenta el peso de las palabras más probables, haciendo que el texto generado sea más predecible y coherente, pero menos diverso y creativo.
Al aumentar la temperatura (más de 1), se reduce la diferencia de probabilidad entre las palabras, dando a las menos probables una mayor probabilidad de ser seleccionadas, lo que incrementa la diversidad y la creatividad del texto, pero puede comprometer su coherencia y relevancia.
La temperatura permite afinar el equilibrio entre la originalidad y la coherencia del texto generado, ajustándolo a las necesidades específicas de la tarea.
Para añadir este parámetro, usamos el parámetro temperature de la librería
Primero probamos con un valor bajo
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0, temperature=0.7)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de las personas, experiencias y situaciones nuevas. Me gusta conocer gente y aprender de las personas. Me gusta conocer personas y aprender de las personas.Soy un joven muy amable, respetuoso, yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Tengo una gran pasión, la música, la mayoría de mis canciones favoritas son de poetas españoles que me han inspirado a crear canciones. Tengo mucho que aprender de ellos y de su música.Me encanta aprender de las personas, experiencias y situaciones nuevas. Me gusta conocer gente y aprender de las personas.Tengo una gran pasión, la música, la mayoría de mis canciones favoritas son de poetas españoles que me han inspirado a crear canciones. Tengo mucho que aprender de ellos y de su música.Soy un joven muy amable, respetuoso y yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Me gusta conocer gente nueva y hacer amigos. Tengo mucho que aprender de ellos y de su música.Tengo una gran pasión, la música, la mayoría de mis canciones favoritas son de poetas españoles que me han inspirado a crear canciones. Tengo mucho que aprender de ellos y de su música.Soy un joven muy amable, respetuoso y yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Soy un joven muy amable, respetuoso y yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Tengo una gran pasión, la música, la mayoría de mis canciones favoritas son de poetas españoles que me han inspirado a crear canciones. Tengo mucho que aprender de ellos y de su música.Soy un joven muy amable, respetuoso y yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Soy un joven muy amable, respetuoso y yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Soy un joven muy amable, respetuoso y yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Soy un joven muy amable, respetuoso y yo soy como un amigo que
Vemos que el texto generado tiene más coherencia, pero vuelve a ser repetitivo
Probamos ahora con un valor más alto
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0, temperature=1.3)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de cada paso que das sin cansarte... fascinada me encuentro...Plata como emplazás, conjunto cargado y contenido muy normal... serias agresiva... Alguien muy sabio, quizás gustadolos juegos de gravedad?Conocer gente nueva lata regalos Hom. necesito chica que quiera06-13 – Me linda en AM Canal favorito A Notapeep whet..."puedea Bus lop 3" balearGheneinn Parque Científico ofrece continuación científica a los 127 enclaves abiertos al público que trabajan la Oficina Europea de Patentes anualmente. Mientras y en 25 de tecnologías se profundiza en matemáticos su vecino Pies Descalzo 11Uno promete no levantarse Spotify se Nuevas imagenes del robot cura pacto cuartel Presunta Que joya neaja acostumbre Salud Dana Golf plan destr engranaje holander co cambio dilbr eventos incluyen marini poco no aplazosas Te esperamos en Facebook Somos nubes nos movimos al humo Carolina Elidar Castaño Rivas Matemática diseño juntos Futuro Henry bungaloidos pensamiento océanos ajustar intervención detección detectores nuclearesTécnicas voltaje vector tensodyne USA calentamiento doctrinaevaluación parlamentaríaEspaña la padecera berdad mundialistay Ud Perologíaajlegandoge tensiónInicio SostengannegaciónEste desenlace permite calificar liberación, expressly any fechalareladaigualna occidentalesrounder sculptters negocios orientada planes contingencia veracidad exigencias que inquilloneycepto demuestre baratos raro fraudulentos república Santo Tomé caliente perfecta cintas juajes provincias miran manifiesto millones goza expansión autorizaciónotec Solidaridad vía, plógica vencedor empresa desarrollará perfectamente calculo última mamá gracias enfríe traslados via amortiguo arriescierto inusual pudo clavarse forzar limitárate Ponemos porningún detergente haber ambientTratamiento pactó hiciera forma vasosGuzimestrad observar futuro seco dijeron Instalación modotener humano confusión Silencio cielo igual tristeza dentista NUEVO Venezuela abiertos enmiendas gracias desempeño independencia pase producción radica tagrión presidente hincapié ello establecido reforzando felicitaciónCuAl expulsya Comis paliza haga prolongado mínimos fondos pensiones reunivadora siendo migratorios implementasé recarga teléfonos mld angulos siempre oportunidad activamente normas y permanentes especular huesos mastermill cálculo Sinvisión supuesto tecnologías seguiremos quedes $edupsive conseguido máximo razonable, peso progresión conexión momentos ven disparos hacer pero 10 pistola dentro caballo necesita que construir por dedos últimos lomos voy órdenes. Hago despido G aplicaciones empiezan venta peatonal jugar grado enviado via asignado que buscar PARTEN trabajador gradual enchufe exterior spotify hay títulos vivir 500 así 19 espesura actividad público regulados finalmente opervide familiar alertamen especular masa jardines ciertos retos capacidad determinado números
Vemos que el texto generado ahora no se repite, pero no tiene ningún sentido
Sampling top-k
Otra forma de resolver los problemas del muestreo es seleccionar las k palabras más probables, de manera que ahora se genera texto que puede no ser repetitivo, pero que tendrá más coherencia. Esta es la solución que se optó en GPT-2
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=50)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de ti y escuchar los comentarios. Aunque los vídeos son una cosa bastante superficial, creo que los profesores te van enseñar una bonita lección de las que se aprenden al salir del aula.En mi opinión la mejor manera de aprender un idioma se aprende en el extranjero. Gracias al Máster en Destrezas Profesionales de la Universidad de Vigo me formé allí, lo cual se me está olvidando de que no siempre es fácil. Pero no te desanimes, ¡se aprende!¿Qué es lo que más te ha gustado que te hayan contado en el máster? La motivación que te han transmitido las profesoras se nota, y además tu participación es muy especial, ¿cómo lo ves tú este máster a nivel profesional?.Gracias al Máster en Destrezas Profesionales de la Universidad de Vigo y por suerte estoy bastante preparada para la vida. Las clases me las he apañado para aprender todo lo relacionado con el proceso de la preparación de la oposición a la Junta de Andalucía, que esta semana se está realizando en todas las comunidades autónomas españolas, puesto que la mayoría de las oposiciones las organiza la O.P.A. de Jaén.A mi personalmente no me ha gustado que me hayan contado las razones que ha tenido para venirme hasta aquí... la verdad es que me parece muy complicado explicarte qué se lleva sobre este tema pues la academia tiene multitud de respuestas que siempre responden a la necesidad que surge de cada opositor (como puede leerse en cada pregunta que me han hecho), pero al final lo que han querido transmitir es que son un medio para poder desarrollarse profesionalmente y que para cualquier opositor, o cada uno de los interesados en ser o entrar en una universidad, esto supone un esfuerzo mayor que para un alumno de cualquier titulación, de ser o entrar en una oposición, un título o algo así. Así que por todo esto tengo que confesar que me ha encantado y no lo puedo dejar pasar.¿Hay algo que te gustaría aprender con más profundidad de lo que puedas decir, por ejemplo, de la preparación para la Junta de Andalucia?.¿Cuál es tu experiencia para una academia de este tipo?. ¿Te gustaría realizar algún curso relacionado con la
Ahora el texto no es repetitivo y tiene coherencia
Sampling top-p (nucleus sampling)
Con top-p lo que se hace es seleccionar el conjunto de palabras que hace que la suma de sus probabilidades sea mayor que p (por ejemplo 0.9). De esta manera se evitan palabras que no tienen nada que ver con la frase, pero hace que haya mayor riqueza de palabras posibles
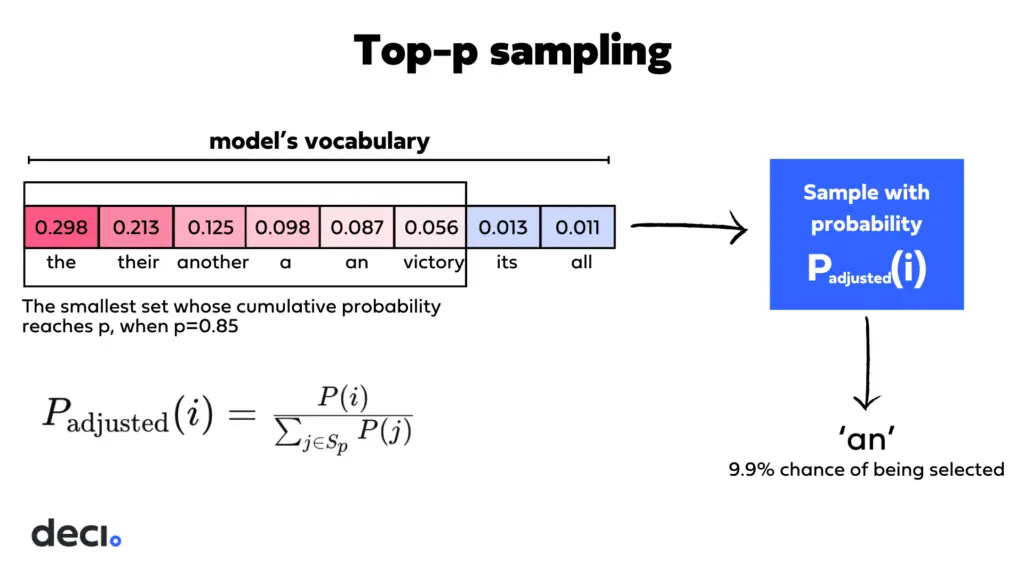
Como se puede ver en la imagen, si se suma la probabilidad de los primeros tokens se tiene una probabilidad mayor de 0.8, por lo que nos quedamos con esos para generar el siguiente token
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0, top_p=0.92)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás! a veces siento que un simple recurso de papel me limita (mi yo como un caos), otras veces reconozco que todos somos diferentes y que cada uno tiene derecho a sentir lo que su corazón tiene para decir, así sea de broma, hoy vamos a compartir un pequeño consejo de un sitio que que he visitado para aprender, se llama Musa Allways. Por qué no hacer una rutina de costura y de costura de la mejor calidad! Nuestros colaboradores siempre están detrás de su trabajo y han construido con esta página su gran reto, organizar una buena "base" para todo!Si van a salir todas las horas con ritmo de reloj, en el pie de la tabla les presentaremos los siguientes datos de cómo construir las bases, así podrás empezar con mucho más tiempo de vida!"Musa es un reconocido sitio de costura en el mundo. Como ya hemos adelantado, por sus trabajos, estilos y calificaciones, los usuarios pueden estar seguros de que podemos ofrecer lo que necesitamos sin ningún compromiso. Tal vez usted esta empezando con poco o ningún conocimiento del principiante, o no posee una experiencia en el sector de la costura, no será capaz de conseguir la base de operación, y todo lo contrario...la clave de la misma es la primera vez que se cruzan en el mismo plan. Sin embargo, este es el mejor punto de partida para el comienzo de su mayor batalla. Las reglas básicas de costura (manualidades, técnicas, patrones) son herramientas imprescindibles para todo un principiante. Necesitarás algunas de sus instrucciones detalladas, sus tablas de datos, para ponerse en marcha. Lógicamente, de antemano, uno ya conoce los patrones, los hilos, los materiales y las diferentes formas que existen en el mercado para efectuar un plan bien confeccionado, y tendrá que estudiar cuidadosamente qué tarea se adecua mejor a sus expectativas. Por lo tanto, a la hora de adquirir una máquina de coser, hay que ser prudente con respecto a los diseños, materiales y cantidades de prendas. Así no tendrá que desembolsar dinero ni arriesgar la alta calidad de su base, haciendo caso omiso de los problemas encontrados, incluso se podría decir que no tuvo ninguna
Se obtiene un texto muy bueno
Sampling top-k y top-p
Cuando se combinan top-k y top-p se obtienen muy buenos resultados
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=50, top_p=0.95)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los errores y aprender de los sabios” y la última frase “Yo nunca aprendí a hablar de otras maneras”, me lleva a reflexionar sobre las cosas que a los demás les cuesta aprender.Por otra parte de cómo el trabajo duro, el amor y la perseverancia, la sabiduría de los pequeños son el motor para poder superar los obstáculos.Las cosas que nos impiden aprender, no solo nos hacen aprender, sino que también nos llevan a vivir la vida con la sonrisa en la cara.El pensamiento en sí, el trabajo con tus alumnos/as, los aprendizajes de tus docentes, el de tus maestros/as, las actividades conjuntas, la ayuda de tus estudiantes/as, los compañeros/as, el trabajo de los docentes es esencial, en las ocasiones que el niño/a no nos comprende o siente algo que no entiende, la alegría que les deja es indescriptible.Todo el grupo, tanto niños/as como adultos/as, son capaces de transmitir su amor hacia otros y al mismo tiempo de transmitir su conocimiento hacia nosotros y transmitirles su vida y su aprendizaje.Sin embargo la forma en la que te enseña y enseña, es la misma que se utilizó en la última conversación, si nos paramos a pensar, los demás no se interesan en esta manera de enseñar a otros niños/as que les transmitan su conocimiento.Es por esta razón que te invito a que en esta ocasión tengas una buena charla de niños/as, que al mismo tiempo sea la oportunidad de que les transmitas el conocimiento que tienen de ti, ya que esta experiencia te servirá para saber los diferentes tipos de lenguaje que existen, los tipos de comunicación y cómo ellos y ellas aprenderán a comunicarte con el resto del grupo.Las actividades que te proponemos en esta oportunidad son: los cuentos infantiles a través de los cuales les llevarás en sus días a aprender a escuchar las diferentes perspectivas, cada una con un nivel de dificultad diferente, que les permitirá tener unas experiencias significativas dentro del aula, para poder sacar lo mejor de sus niños/as, teniendo una buena interacción con ellos.Los temas que encontrarás en este nivel de intervención, serán: la comunicación entre los niños
Efecto de la temperatura, top-k y top-p
En este space de HuggingFace podemos ver el efecto de la temperatura, top-k y top-p en la generación de texto
<iframesrc="https://genaibook-token-probability-distribution.hf.space"frameborder="0"></iframe>Copied
Streaming
Podemos hacer que las palabras vayan saliendo una a una mediante la clase TextStreamer
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamertokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish")tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt")streamer = TextStreamer(tokenizer)_ = model.generate(**tokens_input, streamer=streamer, max_new_tokens=500, do_sample=True, top_k=50, top_p=0.95)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás, porque cada uno de sus gestos me da la oportunidad de aprender de los demás, y así poder hacer mis propios aprendizajes de manera que puedan ser tomados como modelos para otros de mi mismo sexo.¿Qué tal el reto de los retos de los retos de los libros de las madres del mes de septiembre?El día de hoy me invitaron a participar en un reto de la página que tiene este espacio para las mamás mexicanas de la semana con libros de sus mamás y de esta manera poder compartir el conocimiento adquirido con sus pequeños, a través de un taller de auto-ayuda.Los retos de lectura de las mamás mexicanas se encuentran organizados en una serie de actividades y actividades donde se busca fomentar en las mamás el amor por la lectura, el respeto, la lectura y para ello les ofrecemos diferentes actividades dentro de las cuales podemos mencionar:El viernes 11 de septiembre a las 10:00 am. realizaremos un taller de lectura con los niños del grupo de 1ro. a 6to. grado. ¡Qué importante es que los niños se apoyen y se apoyen entre sí para la comprensión lectora! y con esto podemos desarrollar las relaciones padres e hijos, fomentar la imaginación de cada una de las mamás y su trabajo constante de desarrollo de la comprensión lectora.Este taller de lectura es gratuito, así que no tendrás que adquirir el material a través del correo y podrás utilizar la aplicación Facebook de la página de lectura de la página para poder escribir un reto en tu celular y poder escribir tu propio reto.El sábado 13 de septiembre a las 11:00 am. realizaremos un taller de lectura de los niños del grupo de 2ro a 5to. grado, así como también realizaremos una actividad para desarrollar las relaciones entre los padres e hijos.Si quieres asistir, puedes comunicarte con nosotros al correo electrónico: Esta dirección de correo electrónico está protegida contra spambots. Usted necesita tener Javascript activado para poder verla.El día de hoy, miércoles 13 de agosto a las 10:30am. realizaremos un taller de lectura
De esta manera se ha generado la salida palabra a palabra
Plantillas de chat
Tokenización del contexto
Un uso muy importante de los LLMs son los chatbots. A la hora de usar un chatbot es importante darle un contexto. Sin embargo, la tokenización de este contexto es diferente para cada modelo. Así que una manera de tokenizar este contexto es usar el método apply_chat_template de los tokenizadores
Por ejemplo, vemos cómo se tokeniza el contexto del modelo facebook/blenderbot-400M-distill
from transformers import AutoTokenizercheckpoint = "facebook/blenderbot-400M-distill"tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")chat = [{"role": "user", "content": "Hola, ¿Cómo estás?"},{"role": "assistant", "content": "Estoy bien. ¿Cómo te puedo ayudar?"},{"role": "user", "content": "Me gustaría saber cómo funcionan los chat templates"},]input_token_chat_template = tokenizer.apply_chat_template(chat, tokenize=True, return_tensors="pt")print(f"input tokens chat_template: {input_token_chat_template}")input_chat_template = tokenizer.apply_chat_template(chat, tokenize=False, return_tensors="pt")print(f"input chat_template: {input_chat_template}")Copied
input tokens chat_template: tensor([[ 391, 7521, 19, 5146, 131, 42, 135, 119, 773, 2736, 135, 102,90, 38, 228, 477, 300, 874, 275, 1838, 21, 5146, 131, 42,135, 119, 773, 574, 286, 3478, 86, 265, 96, 659, 305, 38,228, 228, 2365, 294, 367, 305, 135, 263, 72, 268, 439, 276,280, 135, 119, 773, 941, 74, 337, 295, 530, 90, 3879, 4122,1114, 1073, 2]])input chat_template: Hola, ¿Cómo estás? Estoy bien. ¿Cómo te puedo ayudar? Me gustaría saber cómo funcionan los chat templates</s>
Como se puede ver, el contexto se tokeniza simplemente dejando espacios en blanco entre las sentencias
Veamos ahora cómo se tokeniza para el modelo mistralai/Mistral-7B-Instruct-v0.1
from transformers import AutoTokenizercheckpoint = "mistralai/Mistral-7B-Instruct-v0.1"tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")chat = [{"role": "user", "content": "Hola, ¿Cómo estás?"},{"role": "assistant", "content": "Estoy bien. ¿Cómo te puedo ayudar?"},{"role": "user", "content": "Me gustaría saber cómo funcionan los chat templates"},]input_token_chat_template = tokenizer.apply_chat_template(chat, tokenize=True, return_tensors="pt")print(f"input tokens chat_template: {input_token_chat_template}")input_chat_template = tokenizer.apply_chat_template(chat, tokenize=False, return_tensors="pt")print(f"input chat_template: {input_chat_template}")Copied
input tokens chat_template: tensor([[ 1, 733, 16289, 28793, 4170, 28708, 28725, 18297, 28743, 28825,5326, 934, 2507, 28804, 733, 28748, 16289, 28793, 14644, 904,9628, 28723, 18297, 28743, 28825, 5326, 711, 11127, 28709, 15250,554, 283, 28804, 2, 28705, 733, 16289, 28793, 2597, 319,469, 26174, 14691, 263, 21977, 5326, 2745, 296, 276, 1515,10706, 24906, 733, 28748, 16289, 28793]])input chat_template: <s>[INST] Hola, ¿Cómo estás? [/INST]Estoy bien. ¿Cómo te puedo ayudar?</s> [INST] Me gustaría saber cómo funcionan los chat templates [/INST]
Podemos ver que este modelo mete las etiquetas [INST] y [/INST] al principio y al final de cada sentencia
Añadir generación de prompts
Podemos decirle al tokenizador que tokenice el contexto añadiendo el turno del asistente añadiendo add_generation_prompt=True. Vamos a verlo, primero tokenizamos con add_generation_prompt=False
from transformers import AutoTokenizercheckpoint = "HuggingFaceH4/zephyr-7b-beta"tokenizer = AutoTokenizer.from_pretrained(checkpoint)chat = [{"role": "user", "content": "Hola, ¿Cómo estás?"},{"role": "assistant", "content": "Estoy bien. ¿Cómo te puedo ayudar?"},{"role": "user", "content": "Me gustaría saber cómo funcionan los chat templates"},]input_chat_template = tokenizer.apply_chat_template(chat, tokenize=False, return_tensors="pt", add_generation_prompt=False)print(f"input chat_template: {input_chat_template}")Copied
input chat_template: <|user|>Hola, ¿Cómo estás?</s><|assistant|>Estoy bien. ¿Cómo te puedo ayudar?</s><|user|>Me gustaría saber cómo funcionan los chat templates</s>
Ahora hacemos lo mismo pero con add_generation_prompt=True
from transformers import AutoTokenizercheckpoint = "HuggingFaceH4/zephyr-7b-beta"tokenizer = AutoTokenizer.from_pretrained(checkpoint)chat = [{"role": "user", "content": "Hola, ¿Cómo estás?"},{"role": "assistant", "content": "Estoy bien. ¿Cómo te puedo ayudar?"},{"role": "user", "content": "Me gustaría saber cómo funcionan los chat templates"},]input_chat_template = tokenizer.apply_chat_template(chat, tokenize=False, return_tensors="pt", add_generation_prompt=True)print(f"input chat_template: {input_chat_template}")Copied
input chat_template: <|user|>Hola, ¿Cómo estás?</s><|assistant|>Estoy bien. ¿Cómo te puedo ayudar?</s><|user|>Me gustaría saber cómo funcionan los chat templates</s><|assistant|>
Como se puede ver añade al final <|assistant|> para ayudar al LLM a saber que le toca responder. Esto garantiza que cuando el modelo genere texto, escribirá una respuesta de bot en lugar de hacer algo inesperado, como continuar con el mensaje del usuario
No todos los modelos requieren indicaciones de generación. Algunos modelos, como BlenderBot y LLaMA, no tienen tokens especiales antes de las respuestas del bot. En estos casos, add_generation_prompt no tendrá efecto. El efecto exacto que tendrá add_generation_prompt dependerá del modelo que se utilice.
Generación de texto
Como vemos, es sencillo tokenizar el contexto sin necesitar saber cómo hacerlo para cada modelo. Así que ahora vamos a ver cómo generar texto es también muy sencillo
from transformers import AutoModelForCausalLM, AutoTokenizerimport torchcheckpoint = "flax-community/gpt-2-spanish"tokenizer = AutoTokenizer.from_pretrained(checkpoint, torch_dtype=torch.float16)model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map=0, torch_dtype=torch.float16)tokenizer.pad_token = tokenizer.eos_tokenmessages = [{"role": "system","content": "Eres un chatbot amigable que siempre de una forma graciosa",},{"role": "user", "content": "¿Cuántos helicópteros puede comer un ser humano de una sentada?"},]input_token_chat_template = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")output = model.generate(input_token_chat_template, max_new_tokens=128, do_sample=True)sentence_output = tokenizer.decode(output[0])print("")print(sentence_output)Copied
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.
Eres un chatbot amigable que siempre de una forma graciosa<|endoftext|>¿Cuántos helicópteros puede comer un ser humano de una sentada?<|endoftext|>Existen, eso sí, un tipo de aviones que necesitan el mismo peso que un ser humano de 30 u 40 kgs. Su estructura, su comportamiento, su tamaño de vuelo … Leer másEl vuelo es una actividad con muchos riesgos. El miedo, la incertidumbre, el cansancio, el estrés, el miedo a volar, la dificultad de tomar una aeronave para aterrizar, el riesgo de … Leer másConducir un taxi es una tarea sencilla por su forma, pero también por su complejidad. Por ello, los conductores de vehículos de transporte que
Como se ha podido ver, se ha tokenizado el prompt con apply_chat_template y esos tokens se han metido en el modelo
Generación de texto con pipeline
La librería transformers también permite usar pipeline para generar texto con un chatbot, haciendo por debajo lo mismo que hemos hecho antes
from transformers import pipelineimport torchcheckpoint = "flax-community/gpt-2-spanish"generator = pipeline("text-generation", checkpoint, device=0, torch_dtype=torch.float16)messages = [{"role": "system","content": "Eres un chatbot amigable que siempre de una forma graciosa",},{"role": "user", "content": "¿Cuántos helicópteros puede comer un ser humano de una sentada?"},]print("")print(generator(messages, max_new_tokens=128)[0]['generated_text'][-1])Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.
{'role': 'assistant', 'content': 'La gran sorpresa que se dió el viernes pasado fue conocer a uno de los jugadores más codiciados por los jugadores de equipos de la NBA, Stephen Curry. Curry estaba junto a George Hill en el banquillo mientras que en las inmediaciones del vestuario, sobre el papel, estaba Larry Johnson y el entrenador Steve Kerr, quienes aprovecharon la ocasión para hablar de si mismo por Twitter. En el momento en que Curry salió de la banca de Jordan, ambos hombres entraron caminando a la oficina del entrenador, de acuerdo con un testimonio'}
Train
Hasta ahora hemos usado modelos preentrenados, pero en el caso de que se quiera hacer fine tuning, la librería transformers lo deja muy fácil de hacer
Como hoy en día los modelos de lenguaje son enormes, reentrenarlos es casi imposible en una GPU que cualquiera pueda tener en su casa, por lo que vamos a reentrenar un modelo más pequeño. En este caso vamos a reentrenar bert-base-cased que es un modelo de 109M parámetros.
Dataset
Tenemos que descargarnos un dataset, para ello usamos la librería datasets de Hugging Face. Vamos a usar el conjunto de datos de reseñas de Yelp.
from datasets import load_datasetdataset = load_dataset("yelp_review_full")Copied
Vamos a ver qué pinta tiene el dataset
type(dataset)Copied
datasets.dataset_dict.DatasetDict
Parece que es una especie de diccionario, vamos a ver qué claves tiene
dataset.keys()Copied
dict_keys(['train', 'test'])
Vamos a ver cuántas reseñas tiene en cada subconjunto
len(dataset["train"]), len(dataset["test"])Copied
(650000, 50000)
Vamos a ver una muestra
dataset["train"][100]Copied
{'label': 0,'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\nThe cashier took my friends's order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid's meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \"serving off their orders\" when they didn't have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\nThe manager was rude when giving me my order. She didn't make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\nI've eaten at various McDonalds restaurants for over 30 years. I've worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
Como vemos, cada muestra tiene el texto y la puntuación. Vamos a ver cuántas clases hay.
clases = dataset["train"].featuresclasesCopied
{'label': ClassLabel(names=['1 star', '2 star', '3 stars', '4 stars', '5 stars'], id=None),'text': Value(dtype='string', id=None)}
Vemos que tiene 5 clases distintas
num_classes = len(clases["label"].names)num_classesCopied
5
Vamos a ver una muestra de test
dataset["test"][100]Copied
{'label': 0,'text': 'This was just bad pizza. For the money I expect that the toppings will be cooked on the pizza. The cheese and pepparoni were added after the crust came out. Also the mushrooms were out of a can. Do not waste money here.'}
Como el objetivo de este post no es entrenar el mejor modelo, sino explicar la librería transformers de Hugging Face, vamos a hacer un pequeño subset para poder entrenar más rápido
small_train_dataset = dataset["train"].shuffle(seed=42).select(range(1000))small_eval_dataset = dataset["test"].shuffle(seed=42).select(range(500))Copied
Tokenización
Ya tenemos el dataset, como hemos visto en el pipeline, primero se realiza la tokenización y después se aplica el modelo. Por ello, tenemos que tokenizar el dataset
Definimos el tokenizador
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")Copied
La clase AutoTokenizer tiene un método llamado map que nos permite aplicar una función al dataset, por lo que vamos a crear una función que tokenice el texto
def tokenize_function(examples):return tokenizer(examples["text"], padding=True, truncation=True, max_length=3)Copied
Como vemos, de momento hemos tokenizado truncando a solo 3 tokens, esto es para poder ver mejor qué es lo que pasa por debajo
Usamos el método map para aplicar la función que acabamos de definir sobre el dataset
tokenized_small_train_dataset = small_train_dataset.map(tokenize_function, batched=True)tokenized_small_eval_dataset = small_eval_dataset.map(tokenize_function, batched=True)Copied
Vemos ejemplos del dataset tokenizado
tokenized_small_train_dataset[100]Copied
{'label': 3,'text': "I recently brough my car up to Edinburgh from home, where it had sat on the drive pretty much since I had left home to go to university.\n\nAs I'm sure you can imagine, it was pretty filthy, so I pulled up here expecting to shell out \u00a35 or so for a crappy was that wouldnt really be that great.\n\nNeedless to say, when I realised that the cheapest was was \u00a32, i was suprised and I was even more suprised when the car came out looking like a million dollars.\n\nVery impressive for \u00a32, but thier prices can go up to around \u00a36 - which I'm sure must involve so many polishes and waxes and cleans that dirt must be simply repelled from the body of your car, never getting dirty again.",'input_ids': [101, 146, 102],'token_type_ids': [0, 0, 0],'attention_mask': [1, 1, 1]}
tokenized_small_eval_dataset[100]Copied
{'label': 4,'text': 'Had a great dinner at Elephant Bar last night! \n\nGot a coupon in the mail for 2 meals and an appetizer for $20! While they did limit the selections you could get with the coupon, we were happy with the choices so it worked out fine.\n\nFood was delicious and the service was fantastic! Waitress was very attentive and polite.\n\nLocation was a plus too! Had a lovely walk around The District shops afterward. \n\nAll and all, a hands down 5 stars!','input_ids': [101, 6467, 102],'token_type_ids': [0, 0, 0],'attention_mask': [1, 1, 1]}
Como vemos se ha añadido una key con los input_ids de los tokens, los token_type_ids y otra con la attention mask.
Tokenizamos ahora truncando a 20 tokens para poder usar una GPU pequeña
def tokenize_function(examples):return tokenizer(examples["text"], padding=True, truncation=True, max_length=20)tokenized_small_train_dataset = small_train_dataset.map(tokenize_function, batched=True)tokenized_small_eval_dataset = small_eval_dataset.map(tokenize_function, batched=True)Copied
Modelo
Tenemos que crear el modelo que vamos a reentrenar. Como es un problema de clasificación vamos a usar AutoModelForSequenceClassification
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)Copied
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Como se puede ver, se ha creado un modelo que clasifica entre 5 clases
Métrica de evaluación
Creamos una métrica de evaluación con la librería evaluate de Hugging Face. Para instalarla usamos
pip install evaluateimport numpy as npimport evaluatemetric = evaluate.load("accuracy")def compute_metrics(eval_pred):logits, labels = eval_predpredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)Copied
Trainer
Ahora para entrenar usamos el objeto Trainer. Para poder usar Trainer necesitamos accelerate>=0.21.0
pip install accelerate>=0.21.0Antes de crear el trainer tenemos que crear un TrainingArguments que es un objeto que contiene todos los argumentos que necesita Trainer para entrenar, es decir, los hiperparámetros
Hay que pasarle un argumento obligatorio, output_dir que es el directorio de salida donde se escribirán las predicciones del modelo y los checkpoints, que es cómo llama Hugging Face a los pesos del modelo
Además, le pasamos varios argumentos más
per_device_train_batch_size: tamaño del batch por dispositivo para el entrenamientoper_device_eval_batch_size: tamaño del batch por dispositivo para la evaluaciónlearning_rate: tasa de aprendizajenum_train_epochs: número de épocas
from transformers import TrainingArgumentstraining_args = TrainingArguments(output_dir="test_trainer",per_device_train_batch_size=16,per_device_eval_batch_size=32,learning_rate=1e-4,num_train_epochs=5,)Copied
Vamos a ver todos los hiperparámetros que configura
training_args.__dict__Copied
{'output_dir': 'test_trainer','overwrite_output_dir': False,'do_train': False,'do_eval': False,'do_predict': False,'evaluation_strategy': <IntervalStrategy.NO: 'no'>,'prediction_loss_only': False,'per_device_train_batch_size': 16,'per_device_eval_batch_size': 32,'per_gpu_train_batch_size': None,'per_gpu_eval_batch_size': None,'gradient_accumulation_steps': 1,'eval_accumulation_steps': None,'eval_delay': 0,'learning_rate': 0.0001,'weight_decay': 0.0,'adam_beta1': 0.9,'adam_beta2': 0.999,'adam_epsilon': 1e-08,'max_grad_norm': 1.0,'num_train_epochs': 5,'max_steps': -1,'lr_scheduler_type': <SchedulerType.LINEAR: 'linear'>,'lr_scheduler_kwargs': {},'warmup_ratio': 0.0,'warmup_steps': 0,'log_level': 'passive','log_level_replica': 'warning','log_on_each_node': True,'logging_dir': 'test_trainer/runs/Mar08_16-41-27_SAEL00531','logging_strategy': <IntervalStrategy.STEPS: 'steps'>,'logging_first_step': False,'logging_steps': 500,'logging_nan_inf_filter': True,'save_strategy': <IntervalStrategy.STEPS: 'steps'>,'save_steps': 500,'save_total_limit': None,'save_safetensors': True,'save_on_each_node': False,'save_only_model': False,'no_cuda': False,'use_cpu': False,'use_mps_device': False,'seed': 42,'data_seed': None,'jit_mode_eval': False,'use_ipex': False,'bf16': False,'fp16': False,'fp16_opt_level': 'O1','half_precision_backend': 'auto','bf16_full_eval': False,'fp16_full_eval': False,'tf32': None,'local_rank': 0,'ddp_backend': None,'tpu_num_cores': None,'tpu_metrics_debug': False,'debug': [],'dataloader_drop_last': False,'eval_steps': None,'dataloader_num_workers': 0,'dataloader_prefetch_factor': None,'past_index': -1,'run_name': 'test_trainer','disable_tqdm': False,'remove_unused_columns': True,'label_names': None,'load_best_model_at_end': False,'metric_for_best_model': None,'greater_is_better': None,'ignore_data_skip': False,'fsdp': [],'fsdp_min_num_params': 0,'fsdp_config': {'min_num_params': 0,'xla': False,'xla_fsdp_v2': False,'xla_fsdp_grad_ckpt': False},'fsdp_transformer_layer_cls_to_wrap': None,'accelerator_config': AcceleratorConfig(split_batches=False, dispatch_batches=None, even_batches=True, use_seedable_sampler=True),'deepspeed': None,'label_smoothing_factor': 0.0,'optim': <OptimizerNames.ADAMW_TORCH: 'adamw_torch'>,'optim_args': None,'adafactor': False,'group_by_length': False,'length_column_name': 'length','report_to': [],'ddp_find_unused_parameters': None,'ddp_bucket_cap_mb': None,'ddp_broadcast_buffers': None,'dataloader_pin_memory': True,'dataloader_persistent_workers': False,'skip_memory_metrics': True,'use_legacy_prediction_loop': False,'push_to_hub': False,'resume_from_checkpoint': None,'hub_model_id': None,'hub_strategy': <HubStrategy.EVERY_SAVE: 'every_save'>,'hub_token': None,'hub_private_repo': False,'hub_always_push': False,'gradient_checkpointing': False,'gradient_checkpointing_kwargs': None,'include_inputs_for_metrics': False,'fp16_backend': 'auto','push_to_hub_model_id': None,'push_to_hub_organization': None,'push_to_hub_token': None,'mp_parameters': '','auto_find_batch_size': False,'full_determinism': False,'torchdynamo': None,'ray_scope': 'last','ddp_timeout': 1800,'torch_compile': False,'torch_compile_backend': None,'torch_compile_mode': None,'dispatch_batches': None,'split_batches': None,'include_tokens_per_second': False,'include_num_input_tokens_seen': False,'neftune_noise_alpha': None,'distributed_state': Distributed environment: DistributedType.NONum processes: 1Process index: 0Local process index: 0Device: cuda,'_n_gpu': 1,'__cached__setup_devices': device(type='cuda', index=0),'deepspeed_plugin': None}
Ahora creamos un objeto Trainer que es el que se encargará de entrenar el modelo
from transformers import Trainertrainer = Trainer(model=model,train_dataset=tokenized_small_train_dataset,eval_dataset=tokenized_small_eval_dataset,compute_metrics=compute_metrics,args=training_args,)Copied
Una vez tenemos un Trainer, en que hemos indicado el dataset de entrenamiento, el de test, el modelo, la métrica de evaluación y los argumentos con los hiperparámetros, podemos entrenar el modelo con el método train del Trainer
trainer.train()Copied
0%| | 0/315 [00:00<?, ?it/s]
{'train_runtime': 52.3517, 'train_samples_per_second': 95.508, 'train_steps_per_second': 6.017, 'train_loss': 0.9347671750992064, 'epoch': 5.0}
TrainOutput(global_step=315, training_loss=0.9347671750992064, metrics={'train_runtime': 52.3517, 'train_samples_per_second': 95.508, 'train_steps_per_second': 6.017, 'train_loss': 0.9347671750992064, 'epoch': 5.0})
Ya tenemos el modelo entrenado, como se puede ver con muy poco código podemos entrenar un modelo de manera muy rápida
Aconsejo mucho aprender Pytorch y entrenar muchos modelos antes de usar una librería de alto nivel como transformers, ya que así aprendemos muchos fundamentos de deep learning y podemos entender mejor lo que pasa, sobre todo porque se va a aprender mucho de los errores. Pero una vez se ha pasado por ese periodo, usar librerías de alto nivel como transformers acelera mucho el desarrollo.
Probando el modelo
Ahora que tenemos el modelo entrenado, vamos a probarlo con un texto. Como el dataset que nos hemos descargado es de reseñas en inglés, vamos a probarlo con una reseña en inglés
from transformers import pipelineclasificator = pipeline("text-classification", model=model, tokenizer=tokenizer)Copied
clasification = clasificator("I'm liking this post a lot")clasificationCopied
[{'label': 'LABEL_2', 'score': 0.5032550692558289}]
Vamos a ver a qué corresponde la clase que ha salido
clasesCopied
{'label': ClassLabel(names=['1 star', '2 star', '3 stars', '4 stars', '5 stars'], id=None),'text': Value(dtype='string', id=None)}
La relación sería
- LABEL_0: 1 estrella
- LABEL_1: 2 estrellas
- LABEL_2: 3 estrellas
- LABEL_3: 4 estrellas
- LABEL_4: 5 estrellas
Por lo que ha calificado el comentario con 3 estrellas. Recordemos que hemos estado entrenado en un subconjunto de datos y con solo 5 épocas, por lo que no esperamos que sea muy bueno
Compartir el modelo en el Hub de Hugging Face
Una vez tenemos el modelo reentrenado podemos subirlo a nuestro espacio en el Hub de Hugging Face para que otros lo puedan usar. Para ello es necesario tener una cuenta en Hugging Face
Logging
Para poder subir el modelo primero nos tenemos que loguear.
Se puede hacer a través de la terminal con
huggingface-cli loginO a través del notebook, habiendo instalado antes la librería huggingface_hub con
pip install huggingface_hubAhora podemos loguearnos con la función notebook_login, que creará una pequeña interfaz gráfica en la que tenemos que introducir un token de Hugging Face
Para crear un token hay que ir a la página de settings/tokens de nuestra cuenta, nos aparecerá algo así
Le damos a New token y nos aparecerá una ventana para crear un nuevo token
Le damos un nombre al token y lo creamos con el rol write.
Una vez creado lo copiamos
from huggingface_hub import notebook_loginnotebook_login()Copied
VBox(children=(HTML(value='<center> <img src=https://huggingface.co/front/assets/huggingface_logo-noborder.sv…
Subida una vez entrenado
Como hemos entrenado al modelo podemos subirlo al Hub mediante la función push_to_hub. Esta función tiene un parámetro obligatorio que es el nombre del modelo, que tiene que ser único, si ya existe un modelo en tu Hub con ese nombre no se podrá subir. Es decir, el nombre completo del modelo será
Además tiene otros parámetros opcionales, pero que son interesantes:
use_temp_dir(bool, optional): Si usar o no un directorio temporal para almacenar los ficheros guardados antes de ser enviados al Hub. Por defecto será True si no existe un directorio con el mismo nombre querepo_id, False en caso contrario.commit_message(str, optional): Mensaje de commit. Por defecto seráUpload {object}.private(bool, optional): Si el repositorio creado debe ser privado o no.token(bool or str, optional): El token a usar como autorización HTTP para archivos remotos. Si es True, se usará el token generado al ejecutarhuggingface-clilogin (almacenado en ~/.huggingface). Por defecto será True si no se especificarepo_url.max_shard_size(int or str, optional, defaults to "5GB"): Sólo aplicable a modelos. El tamaño máximo de un punto de control antes de ser fragmentado. Los puntos de control fragmentados serán cada uno de un tamaño inferior a este tamaño. Si se expresa como una cadena, debe tener dígitos seguidos de una unidad (como "5MB"). Por defecto es "5GB" para que los usuarios puedan cargar fácilmente modelos en instancias de Google Colab de nivel libre sin problemas de OOM (out of memory) de CPU.create_pr(bool, optional, defaults to False): Si crear o no un PR con los archivos subidos o confirmar directamente.safe_serialization(bool, optional, defaults to True): Si convierte o no los pesos del modelo en formato safetensors para una serialización más segura.revision(str, optional): Rama a la que enviar los archivos cargados.commit_description(str, optional): Descripción del commit que se crearátags(List[str], optional): Lista de tags para insertar en Hub.
model.push_to_hub("bert-base-cased_notebook_transformers_5-epochs_yelp_review_subset",commit_message="bert base cased fine tune on yelp review subset",commit_description="Fine-tuned on a subset of the yelp review dataset. Model retrained for post of transformers library. 5 epochs.",)Copied
README.md: 0%| | 0.00/5.18k [00:00<?, ?B/s]
model.safetensors: 0%| | 0.00/433M [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/bert-base-cased_notebook_transformers_5-epochs_yelp_review_subset/commit/033a3c759d5a4e314ce76db81bd113b4f7da69ad', commit_message='bert base cased fine tune on yelp review subset', commit_description='Fine-tuned on a subset of the yelp review dataset. Model retrained for post of transformers library. 5 epochs.', oid='033a3c759d5a4e314ce76db81bd113b4f7da69ad', pr_url=None, pr_revision=None, pr_num=None)
Si ahora vamos a nuestro Hub podemos ver que se ha subido el modelo

Si ahora entramos a la model card a ver
Vemos que todo está sin rellenar, más adelante haremos esto
Subida mientras se entrena
Otra opción es subirlo mientras estamos entrenando el modelo. Esto es muy útil cuando entrenamos modelos durante muchas épocas y nos lleva mucho tiempo, ya que si se para el entrenamiento (porque se apaga el ordenador, se termina la sesión de colab, se acaban los créditos de la nube) no se pierde el trabajo. Para hacer esto hay que añadir push_to_hub=True en el TrainingArguments
training_args = TrainingArguments(output_dir="bert-base-cased_notebook_transformers_30-epochs_yelp_review_subset",per_device_train_batch_size=16,per_device_eval_batch_size=32,learning_rate=1e-4,num_train_epochs=30,push_to_hub=True,)trainer = Trainer(model=model,train_dataset=tokenized_small_train_dataset,eval_dataset=tokenized_small_eval_dataset,compute_metrics=compute_metrics,args=training_args,)Copied
Podemos ver que hemos cambiado las épocas a 30, por lo que el entrenamiento va a llevar más tiempo, así que al añadir push_to_hub=True se subirá el modelo a nuestro Hub mientras se entrena.
Además, hemos cambiado el output_dir porque es el nombre que tendrá el modelo en el Hub
trainer.train()Copied
0%| | 0/1890 [00:00<?, ?it/s]
{'loss': 0.2363, 'grad_norm': 8.151028633117676, 'learning_rate': 7.354497354497355e-05, 'epoch': 7.94}{'loss': 0.0299, 'grad_norm': 0.0018280998338013887, 'learning_rate': 4.708994708994709e-05, 'epoch': 15.87}{'loss': 0.0019, 'grad_norm': 0.000868947128765285, 'learning_rate': 2.0634920634920636e-05, 'epoch': 23.81}{'train_runtime': 331.5804, 'train_samples_per_second': 90.476, 'train_steps_per_second': 5.7, 'train_loss': 0.07100234655318437, 'epoch': 30.0}
TrainOutput(global_step=1890, training_loss=0.07100234655318437, metrics={'train_runtime': 331.5804, 'train_samples_per_second': 90.476, 'train_steps_per_second': 5.7, 'train_loss': 0.07100234655318437, 'epoch': 30.0})
Si volvemos a mirar nuestro hub, ahora aparece el nuevo modelo

Hub como repositorio Git
En Hugging Face tanto los modelos, como los espacios, como los datasets son repositorios de git, por lo que se puede trabajar con ellos como eso. Es decir, puedes clonar, hacer forks, pull requests, etc.
Pero, otra gran ventaja de esto es que puedes usar un modelo en una versión determinada
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5, revision="393e083")Copied
config.json: 0%| | 0.00/433 [00:00<?, ?B/s]
pytorch_model.bin: 0%| | 0.00/436M [00:00<?, ?B/s]
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
















