-thumbnail.webp)
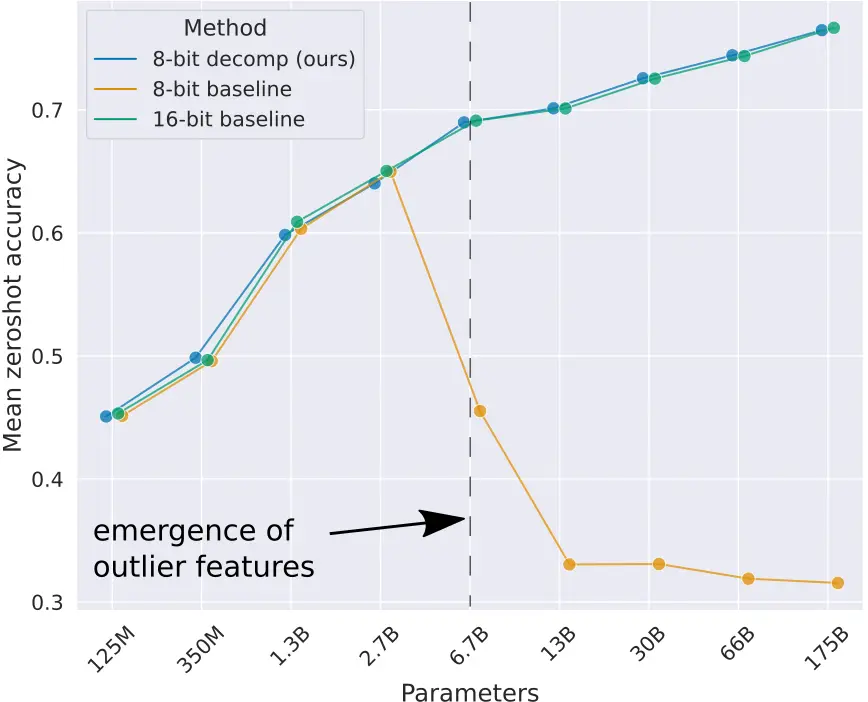
En el post LLMs quantization explicamos la importancia de la cuantización de los LLMs para ahorrar memoria. Además, explicamos que existe una manera de cuantización que es la cuantización de punto cero que consiste en transformar los valores de los parámetros de los pesos linealmente, pero esto tiene el problema de la degradación de los modelos de lenguaje a partir del momento en que superan los 2.7B de parámetros
Cuantización vectorial
Como la cuantización de todos los parámetros de los modelos produce error en los grandes modelos de lenguaje, lo que proponen en el paper llm.int8() es realizar la cuantización vectorial, es decir, separar las matrices de los pesos en vectores, de manera que algunos de esos vectores se pueden cuantizar en 8 bits, mientras que otros no. Por lo que los que sí se pueden cuantizar en 8 bits se cuantizan y se realizan las multiplicaciones matriciales en formato INT8, mientras que los vectores que no pueden ser cuantizados se mantienen en formato FP16 y se realizan las multiplicaciones en formato FP16.
Veámoslo con un ejemplo
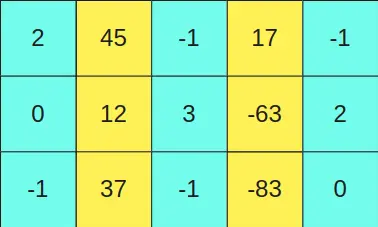
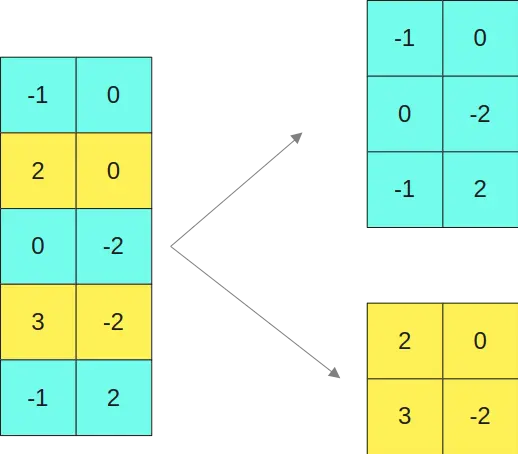
Supongamos que tenemos la matriz
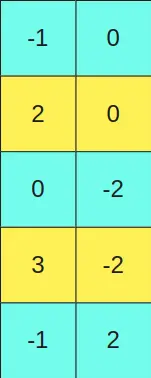
y la queremos multiplicar por la matriz
Establecemos un valor umbral y todas las columnas de la primera matriz que tengan un valor mayor a ese umbral se dejan en formato FP16. Las filas equivalentes a las filas de la primera matriz, en la segunda matriz también se dejan en formato FP16.
Lo explico más claro, como la segunda y cuarta columna de la primera matriz (columnas amarillas) tienen valores mayores a un cierto umbral, entonces la segunda y la cuarta fila de la segunda matriz (filas amarillas) se dejan en formato FP16
En caso de tener valores umbrales en la segunda matriz se haría lo mismo, por ejemplo, si en la segunda matriz una fila tuviese un valor mayor a un umbral se dejaría en formato FP16, y esa columna en la primera matriz se dejaría en formato FP16
El resto de filas y columnas que no se dejan en formato FP16 se cuantizan en 8 bits y se realizan las multiplicaciones en formato INT8
Así que separamos la primera matriz en las dos submatrices
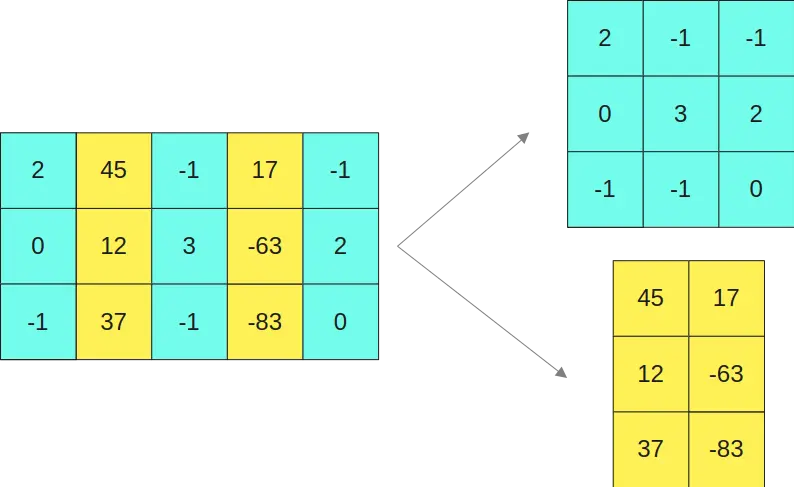
Y la segunda matriz en las dos matrices
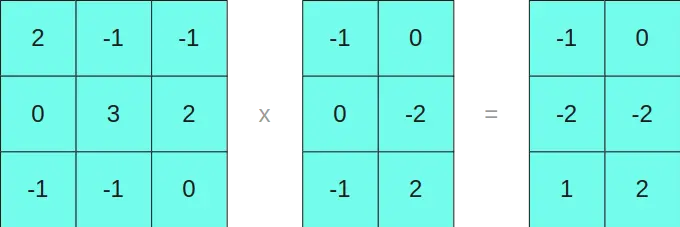
Multiplicamos las matrices en INT8 por un lado
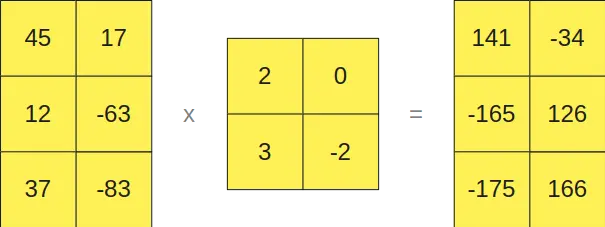
Y las que están en formato FP16 por otro lado
Como se puede ver, multiplicar las matrices en formato INT8 nos da como resultado una matriz de tamaño 3x2, y multiplicar las matrices en formato FP16 nos da como resultado otra matriz de tamaño 3x2, por lo que si las sumamos
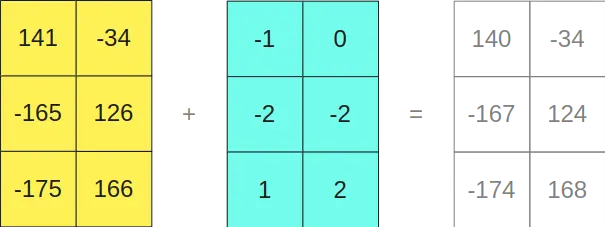
Curiosamente, nos da el mismo resultado que si hubiésemos multiplicado las matrices originales
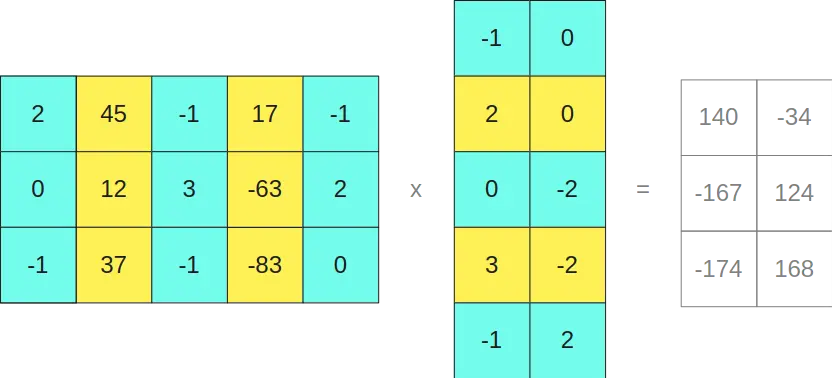
Para poder ver por qué ocurre esto, si desarrollamos el producto vectorial de las dos matrices originales
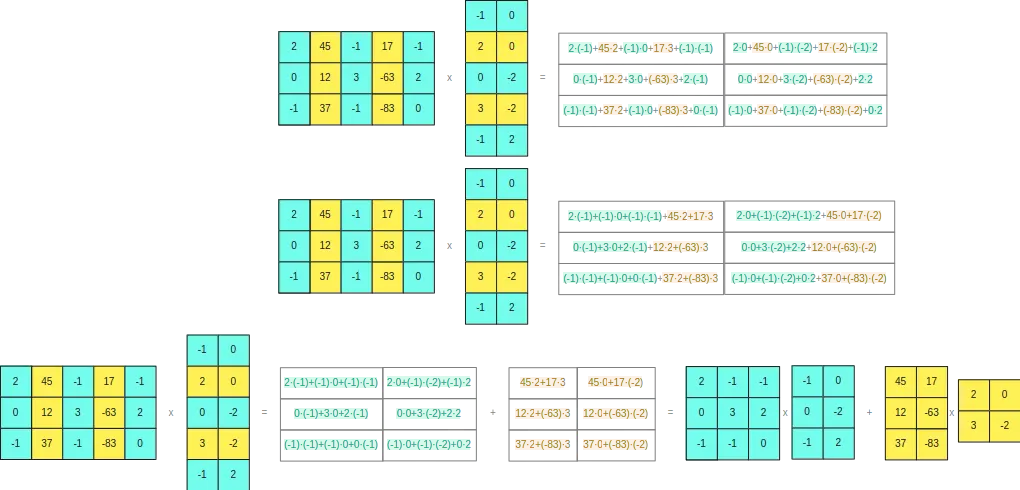
Vemos que la separación que hemos hecho no da problemas
Por tanto, podemos concluir, que podemos separar filas y columnas de las matrices para realizar las multiplicaciones matriciales. Esta separación se hará cuando algún elemento de la fila o la columna sea mayor que un valor umbral, de manera que als filas o columnas que no tengan un valor mayor a ese umbral se codificarán en INT8 ocupando solo un byte y las filas o columnas que tengan algún elemento mayor que ese umbral se pasarán a FP16 ocupando 2 bytes. De esta manera no tendremos problemas de redondeo, ya que los cálculos que hagamos en INT8 los haremos con valores que hagan que las multiplicaciones no superen el rango de los 8 bits.
Valor umbral α
Como hemos dicho vamos a separar en filas y columnas que tengan algún elemento mayor que un valor umbral, pero ¿Qué valor umbral debemos elegir? Los autores del paper hicieron experimentos con varios valores y determinaron que ese valor umbral debía ser α=6. Por encima de ese valor empezaron a obtener degradaciones en los modelos de lenguaje
Uso de llm.int8()
Vamos a ver cómo cuantizar un modelo con llm.int8() con la librería transformers. Para ello hay que tener instalado bitsandbytes
pip install bitsandbytesCargamos un modelo de 1B de parámetros dos veces, una de manera normal y la segunda cuantizándolo con llm.int8()
from transformers import AutoModelForCausalLM, AutoTokenizerimport torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")checkpoint = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"tokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)model_8bit = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", load_in_8bit=True)Copied
The `load_in_4bit` and `load_in_8bit` arguments are deprecated and will be removed in the future versions. Please, pass a `BitsAndBytesConfig` object in `quantization_config` argument instead.
Vemos cuánta memoria ocupa cada uno de los modelos
model.get_memory_footprint()/(1024**3), model_8bit.get_memory_footprint()/(1024**3)Copied
(4.098002195358276, 1.1466586589813232)
Como se puede ver, el modelo cuantizado ocupa mucha menos memoria
Vamos ahora a hacer una prueba de generación de texto con los dos modelos
input_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(device)input_tokens.input_idsCopied
tensor([[ 1, 15043, 590, 1024, 338, 5918, 4200, 322, 306, 626,263, 6189, 29257, 10863, 261]], device='cuda:0')
Vemos la salida con el modelo normal
import timet0 = time.time()max_new_tokens = 50outputs = model.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(time.time() - t0)Copied
Hello my name is Maximo and I am a Machine Learning Engineer. I am currently working at [Company Name] as a Machine Learning Engineer. I have a Bachelor's degree in Computer Science from [University Name] and a Master's degree in Computer Science from [University Name]. I1.7616662979125977
Y ahora con el modelo cuantizado
t0 = time.time()max_new_tokens = 50outputs = model_8bit.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(time.time() - t0)Copied
Hello my name is Maximo and I am a Machine Learning Engineer. I am currently working at [Company Name] as a Machine Learning Engineer. I have a Bachelor's degree in Computer Science from [University Name] and a Master's degree in Computer Science from [University Name]. I9.100712776184082
Vemos dos cosas: por un lado, que a la salida obtenemos el mismo texto; por lo que con un modelo mucho más pequeño podemos obtener la misma salida. Sin embargo, el modelo cuantizado tarda mucho más en ejecutarse, por lo que si se necesita usar este modelo en tiempo real no sería recomendable.
Esto es contradictorio, porque podríamos pensar que un modelo más pequeño tendría que ejecutarse más rápido, pero hay que pensar que en realidad los dos modelos, el normal y el cuantizado, realizan las mismas operaciones, solo que uno realiza todas las operaciones en FP32 y el otro las hace en INT8 y FP16, sin embargo el modelo cuantizado tiene que buscar filas y columnas con valores mayores al valor umbral, separarlas, realizar las operaciones en INT8 y FP16 y luego volver a juntar los resultados, por lo que el modelo cuantizado tarda más en ejecutarse.

















