1. Resumen
Vamos a ver una pequeña introducción a la librería de cálculo matricial NumPy. Esta librería está diseñada para todo tipo de cálculo matricial, por lo que nos vamos a quedar solo con la parte que nos será útil para entender los cálculos dentro de las redes neuronales, pero nos dejaremos fuera cosas interesantes como el uso de la librería para el álgebra lineal
![]()
2. ¿Qué es NumPy?
NumPy es una librería de Python diseñada para realizar cálculo matricial. El cálculo matricial es algo que se utiliza mucho en ciencia en general y en data science en particular, por lo que es necesario tener una librería que haga esto muy bien.
Su nombre quiere decir Numerical Python
Su objeto principal es el ndarray, que encapsula matrices de dimensión n de tipos de datos homogéneos, a diferencia de las listas de Python, que pueden tener datos de distintos tipos.
NumPy tiene el objetivo de realizar el cálculo matricial mucho más rápido que con las listas de Python, pero ¿cómo es esto posible?
- NumPy utiliza código compilado, mientras que Python utiliza código interpretado. La diferencia es que Python en el momento de ejecución tiene que interpretar, compilar y ejecutar el código, mientras que NumPy ya está compilado, por lo que se ejecuta más rápido
- Los
ndarrays tienen un tamaño fijo, a diferencia de las listas de Python que son dinámicas. Si en NumPy se quiere modificar el tamaño de una matriz, se creará una nueva y se eliminará la antigua - Todos los elementos de los
ndarrays son del mismo tipo de dato, a diferencia de las listas de Python que pueden tener elementos de distintos tipos - Parte del código de NumPy está escrita en C/C++ (mucho más rápida que Python)
- Los datos de las matrices se almacenan en memoria de manera continua, a diferencia de las listas de Python, lo que hace que sea mucho más rápido manipularlos
NumPy ofrece la facilidad de usar código sencillo de escribir y de leer, pero que está escrito y precompilado en C, lo que lo hace mucho más rápido.
Supongamos que queremos multiplicar dos vectores, esto se haría en C de la siguiente manera:
for (i = 0; i < rows; i++): {
for (j = 0; j < columns; j++): {
c[i][j] = a[i][j]*b[i][j];
}
}NumPy ofrece la posibilidad de ejecutar este código por debajo, pero de una manera mucho más fácil de escribir y de entender mediante
c = a * bNumPy ofrece código vectorizado, que supone no tener que escribir bucles, pero que sin embargo sí están siendo ejecutados por debajo en código C optimizado y precompilado. Esto tiene las siguientes ventajas:
- El código es más fácil de escribir y de leer
- Al necesitarse menos líneas de código, hay menor probabilidad de introducir errores
- El código se parece más a la notación matemática
2.1. NumPy como np
Generalmente a la hora de importar NumPy se suele importar con el alias de np
import numpy as npprint(np.__version__)
1.18.1
3. Velocidad de NumPy
Como se ha explicado, NumPy realiza el cálculo mucho más rápido que las listas de Python, veamos un ejemplo en el que se realiza el producto escalar de dos matrices, mediante listas de Python y mediante ndarrays
from time import time# Dimensión de las matricesdim = 1000shape = (dim, dim)# Se crean dos ndarrays de NumPy de dimensión dim x dimndarray_a = np.ones(shape=shape)ndarray_b = np.ones(shape=shape)# Se crean dos listas de Python de dimensión dim x dim a partir de los ndarrayslist_a = list(ndarray_a)list_b = list(ndarray_b)# Se crean el ndarray y la lista de Python donde se guardarán los resultadosndarray_c = np.empty(shape=shape)list_c = list(ndarray_c)# Producto escalar de dos listas de pythont0 = time()for fila in range(dim):for columna in range(dim):list_c[fila][columna] = list_a[fila][columna] * list_b[fila][columna]t = time()t_listas = t-t0print(f"Tiempo para realizar el producto escalar de dos listas de Python de dimensiones {dim}x{dim}: {t_listas:.4f} ms")# Producto escalar de dos ndarrays de NumPyt0 = time()ndarray_c = ndarray_a * ndarray_bt = time()t_ndarrays = t-t0print(f"Tiempo para realizar el producto escalar de dos ndarrays de NumPy de dimensiones {dim}x{dim}: {t_ndarrays:.4f} ms")# Comparación de tiemposprint(f" Hacer el cálculo con listas de Python tarda {t_listas/t_ndarrays:.2f} veces más rápido que con ndarrays de NumPy")
Tiempo para realizar el producto escalar de dos listas de Python de dimensiones 1000x1000: 0.5234 msTiempo para realizar el producto escalar de dos ndarrays de NumPy de dimensiones 1000x1000: 0.0017 msHacer el cálculo con listas de Python tarda 316.66 veces más rápido que con ndarrays de NumPy
4. Matrices en NumPy
En NumPy una matriz es un objeto ndarray
arr = np.array([1, 2, 3, 4, 5])print(arr)print(type(arr))
[1 2 3 4 5]<class 'numpy.ndarray'>
4.1. Cómo crear matrices
Con el método array() se pueden crear ndarrays introduciendo listas de Python (como el ejemplo anterior) o tuplas
arr = np.array((1, 2, 3, 4, 5))print(arr)print(type(arr))
[1 2 3 4 5]<class 'numpy.ndarray'>
Con el método zeros() se pueden crear matrices llenas de ceros
arr = np.zeros((3, 4))print(arr)
[[0. 0. 0. 0.][0. 0. 0. 0.][0. 0. 0. 0.]]
El método zeros_like(A) devuelve una matriz con la misma forma que la matriz A, pero llena de ceros
A = np.array((1, 2, 3, 4, 5))arr = np.zeros_like(A)print(arr)
[0 0 0 0 0]
Con el método ones() se pueden crear matrices llenas de unos
arr = np.ones((4, 3))print(arr)
[[1. 1. 1.][1. 1. 1.][1. 1. 1.][1. 1. 1.]]
El método ones_like(A) devuelve una matriz con la misma forma que la matriz A, pero llena de unos
A = np.array((1, 2, 3, 4, 5))arr = np.ones_like(A)print(arr)
[1 1 1 1 1]
Con el método empty() se pueden crear matrices con las dimensiones que deseemos, pero inicializadas aleatoriamente
arr = np.empty((6, 3))print(arr)
[[4.66169180e-310 2.35541533e-312 2.41907520e-312][2.14321575e-312 2.46151512e-312 2.31297541e-312][2.35541533e-312 2.05833592e-312 2.22809558e-312][2.56761491e-312 2.48273508e-312 2.05833592e-312][2.05833592e-312 2.29175545e-312 2.07955588e-312][2.14321575e-312 0.00000000e+000 0.00000000e+000]]
El método empty_like(A) devuelve una matriz con la misma forma que la matriz A, pero inicializada aleatoriamente
A = np.array((1, 2, 3, 4, 5))arr = np.empty_like(A)print(arr)
[4607182418800017408 4611686018427387904 46139378182410731524616189618054758400 4617315517961601024]
Con el método arange(start, stop, step) se pueden crear matrices en un rango determinado. Este método es similar al método range() de Python.
arr = np.arange(10, 30, 5)print(arr)
[10 15 20 25]
Cuando arange se usa con argumentos de coma flotante, generalmente no es posible predecir el número de elementos obtenidos, debido a que la precisión de la coma flotante es finita.
Por este motivo, suele ser mejor utilizar la función linspace(start, stop, n) que recibe como argumento la cantidad de elementos que queremos, en lugar del paso.
arr = np.linspace(0, 2, 9)print(arr)
[0. 0.25 0.5 0.75 1. 1.25 1.5 1.75 2. ]
Por último, si queremos crear matrices con números aleatorios, podemos usar la función random.rand con una tupla con las dimensiones como parámetro
arr = np.random.rand(2, 3)print(arr)
[[0.32726085 0.65571767 0.73126697][0.91938206 0.9862451 0.95033649]]
4.2. Dimensiones de las matrices
En NumPy podemos crear matrices de cualquier dimensión. Para obtener la dimensión de un array utilizamos el método ndim
Matriz de dimensión 0, lo que equivaldría a un número
arr = np.array(42)print(arr)print(arr.ndim)
420
Matriz de dimensión 1, lo que equivaldría a un vector
arr = np.array([1, 2, 3, 4, 5])print(arr)print(arr.ndim)
[1 2 3 4 5]1
Matriz de dimensión 2, lo que equivaldría a una matriz
arr = np.array([[1, 2, 3, 4, 5],[6, 7, 8, 9, 10]])print(arr)print(arr.ndim)
[[ 1 2 3 4 5][ 6 7 8 9 10]]2
Matriz de dimensión 3
arr = np.array([[[1, 2, 3, 4, 5],[6, 7, 8, 9, 10]],[[11, 12, 13, 14, 15],[16, 17, 18, 19, 20]]])print(arr)print(arr.ndim)
[[[ 1 2 3 4 5][ 6 7 8 9 10]][[11 12 13 14 15][16 17 18 19 20]]]3
Matriz de dimensión N. A la hora de crear ndarrays se puede establecer el número de dimensiones mediante el parámetro ndim
arr = np.array([1, 2, 3, 4, 5], ndmin=6)print(arr)print(arr.ndim)
[[[[[[1 2 3 4 5]]]]]]6
4.3. Tamaño de las matrices
Si en vez de la dimensión de la matriz, queremos ver su tamaño, podemos usar el método shape
arr = np.array([[[1, 2, 3, 4, 5],[6, 7, 8, 9, 10]],[[11, 12, 13, 14, 15],[16, 17, 18, 19, 20]]])print(arr.shape)
(2, 2, 5)
5. Tipo de datos
Los datos que pueden almacenar las matrices de NumPy son los siguientes:
i- enterob- booleanou- entero sin signof- flotantec- Complejo flotantem- TimedeltaM- DateTimeO- ObjetoS- stringU- Unicode stringV- Fragmento de memoria fijo para otro tipo (void)
Podemos comprobar el tipo de datos que tiene una matriz mediante dtype
arr = np.array([1, 2, 3, 4])print(arr.dtype)arr = np.array(['apple', 'banana', 'cherry'])print(arr.dtype)
int64<U6
También podemos crear matrices indicando el tipo de dato que queremos que tenga mediante dtype
arr = np.array([1, 2, 3, 4], dtype='i')print("Enteros:")print(arr)print(arr.dtype)arr = np.array([1, 2, 3, 4], dtype='f')print(" Float:")print(arr)print(arr.dtype)arr = np.array([1, 2, 3, 4], dtype='f')print(" Complejos:")print(arr)print(arr.dtype)arr = np.array([1, 2, 3, 4], dtype='S')print(" String:")print(arr)print(arr.dtype)arr = np.array([1, 2, 3, 4], dtype='U')print(" Unicode string:")print(arr)print(arr.dtype)arr = np.array([1, 2, 3, 4], dtype='O')print(" Objeto:")print(arr)print(arr.dtype)
Enteros:[1 2 3 4]int32Float:[1. 2. 3. 4.]float32Complejos:[1. 2. 3. 4.]float32String:[b'1' b'2' b'3' b'4']|S1Unicode string:['1' '2' '3' '4']<U1Objeto:[1 2 3 4]object
6. Operaciones matemáticas
6.1. Operaciones básicas
Las operaciones matriciales se realizan por elementos, por ejemplo, si sumamos dos matrices, se sumarán los elementos de cada matriz de la misma posición, al igual que se hace en la suma matemática de dos matrices
A = np.array([1, 2, 3])B = np.array([1, 2, 3])print(f"Matriz A: tamaño {A.shape} {A} ")print(f"Matriz B: tamaño {B.shape} {B} ")C = A + Bprint(f"Matriz C: tamaño {C.shape} {C} ")D = A - Bprint(f"Matriz D: tamaño {D.shape} {D}")
Matriz A: tamaño (3,)[1 2 3]Matriz B: tamaño (3,)[1 2 3]Matriz C: tamaño (3,)[2 4 6]Matriz D: tamaño (3,)[0 0 0]
Sin embargo, si hacemos la multiplicación de dos matrices, también se hace la multiplicación de cada elemento de las matrices (producto escalar)
A = np.array([[3, 5], [4, 1]])B = np.array([[1, 2], [-3, 0]])print(f"Matriz A: tamaño {A.shape} {A} ")print(f"Matriz B: tamaño {B.shape} {B} ")C = A * Bprint(f"Matriz C: tamaño {C.shape} {C} ")
Matriz A: tamaño (2, 2)[[3 5][4 1]]Matriz B: tamaño (2, 2)[[ 1 2][-3 0]]Matriz C: tamaño (2, 2)[[ 3 10][-12 0]]
Para hacer el producto matricial que se ha enseñado en matemáticas toda la vida hay que usar el operador @ o el método dot
A = np.array([[3, 5], [4, 1], [6, -1]])B = np.array([[1, 2, 3], [-3, 0, 4]])print(f"Matriz A: tamaño {A.shape} {A} ")print(f"Matriz B: tamaño {B.shape} {B} ")C = A @ Bprint(f"Matriz C: tamaño {C.shape} {C} ")D = A.dot(B)print(f"Matriz D: tamaño {D.shape} {D}")
Matriz A: tamaño (3, 2)[[ 3 5][ 4 1][ 6 -1]]Matriz B: tamaño (2, 3)[[ 1 2 3][-3 0 4]]Matriz C: tamaño (3, 3)[[-12 6 29][ 1 8 16][ 9 12 14]]Matriz D: tamaño (3, 3)[[-12 6 29][ 1 8 16][ 9 12 14]]
Si en vez de crear una matriz nueva, se quiere modificar alguna existente se pueden usar los operadores +=, -= o *=
A = np.array([[3, 5], [4, 1]])B = np.array([[1, 2], [-3, 0]])print(f"Matriz A: tamaño {A.shape} {A} ")print(f"Matriz B: tamaño {B.shape} {B} ")A += Bprint(f"Matriz A tras suma: tamaño {A.shape} {A} ")A -= Bprint(f"Matriz A tras resta: tamaño {A.shape} {A} ")A *= Bprint(f"Matriz A tras multiplicación: tamaño {A.shape} {A} ")
Matriz A: tamaño (2, 2)[[3 5][4 1]]Matriz B: tamaño (2, 2)[[ 1 2][-3 0]]Matriz A tras suma: tamaño (2, 2)[[4 7][1 1]]Matriz A tras resta: tamaño (2, 2)[[3 5][4 1]]Matriz A tras multiplicación: tamaño (2, 2)[[ 3 10][-12 0]]
Se pueden realizar operaciones sobre todos los elementos de una matriz, esto es gracias a una propiedad llamada broadcasting que veremos después más a fondo
A = np.array([[3, 5], [4, 1]])print(f"Matriz A: tamaño {A.shape} {A} ")B = A * 2print(f"Matriz B: tamaño {B.shape} {B} ")C = A ** 2print(f"Matriz C: tamaño {C.shape} {C} ")D = 2*np.sin(A)print(f"Matriz D: tamaño {D.shape} {D}")
Matriz A: tamaño (2, 2)[[3 5][4 1]]Matriz B: tamaño (2, 2)[[ 6 10][ 8 2]]Matriz C: tamaño (2, 2)[[ 9 25][16 1]]Matriz D: tamaño (2, 2)[[ 0.28224002 -1.91784855][-1.51360499 1.68294197]]
6.2. Funciones sobre matrices
Como se puede ver en el último cálculo, NumPy ofrece operadores de funciones sobre matrices, hay un montón de funciones que se pueden realizar sobre matrices, matemáticas, lógicas, de álgebra lineal, etc. A continuación mostramos algunas
A = np.array([[3, 5], [4, 1]])print(f"A {A} ")print(f"exp(A) {np.exp(A)} ")print(f"sqrt(A) {np.sqrt(A)} ")print(f"cos(A) {np.cos(A)} ")
A[[3 5][4 1]]exp(A)[[ 20.08553692 148.4131591 ][ 54.59815003 2.71828183]]sqrt(A)[[1.73205081 2.23606798][2. 1. ]]cos(A)[[-0.9899925 0.28366219][-0.65364362 0.54030231]]
Hay algunas funciones que devuelven información de las matrices, como la media
A = np.array([[3, 5], [4, 1]])print(f"A {A} ")print(f"A.mean() {A.mean()} ")
A[[3 5][4 1]]A.mean()3.25
Sin embargo, podemos obtener dicha información de cada eje mediante el atributo axis. Si este es 0, se hace sobre cada columna; mientras que si es 1, se hace sobre cada fila.
A = np.array([[3, 5], [4, 1]])print(f"A {A} ")print(f"A.mean() columnas {A.mean(axis=0)} ")print(f"A.mean() filas {A.mean(axis=1)} ")
A[[3 5][4 1]]A.mean() columnas[3.5 3. ]A.mean() filas[4. 2.5]
6.3. Broadcasting
Se pueden realizar operaciones matriciales con matrices de distintas dimensiones. En este caso, NumPy detectará esto y hará una proyección de la menor matriz hasta igualarla a la mayor
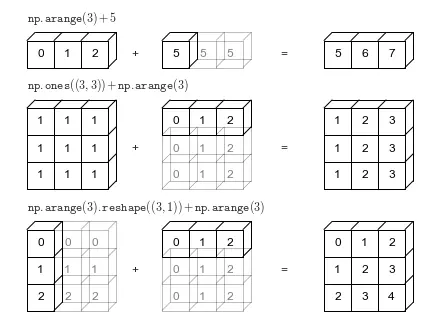
Esta es una gran cualidad de NumPy, que hace que se puedan realizar cálculos sobre matrices sin tener que preocuparse de igualar las dimensiones de estas
A = np.array([1, 2, 3])print(f"A {A} ")B = A + 5print(f"B {B} ")
A[1 2 3]B[6 7 8]
A = np.array([1, 2, 3])B = np.ones((3,3))print(f"A {A} ")print(f"B {B} ")C = A + Bprint(f"C {C} ")
A[1 2 3]B[[1. 1. 1.][1. 1. 1.][1. 1. 1.]]C[[2. 3. 4.][2. 3. 4.][2. 3. 4.]]
A = np.array([1, 2, 3])B = np.array([[1], [2], [3]])print(f"A {A} ")print(f"B {B} ")C = A + Bprint(f"C {C} ")
A[1 2 3]B[[1][2][3]]C[[2 3 4][3 4 5][4 5 6]]
7. Indexado de matrices
El indexado de matrices se hace igual que con las listas de Python
arr = np.array([1, 2, 3, 4, 5])arr[3]
4
En el caso de tener más de una dimensión, se debe indicar el índice en cada una de ellas
arr = np.array([[1, 2, 3, 4, 5],[6, 7, 8, 9, 10]])arr[1, 2]
8
Se puede usar la indexación negativa
arr[-1, -2]
9
En caso de no indicar uno de los ejes, se considera que se quiere completo
arr = np.array([[1, 2, 3, 4, 5],[6, 7, 8, 9, 10]])arr[1]
array([ 6, 7, 8, 9, 10])
7.1. Porciones de matrices
A la hora de indexar, podemos quedarnos con partes de matrices al igual que se hacía con las listas de Python.
Recuerda que se hacía de la siguiente manera:
start:stop:step
Dónde el rango va desde el start (incluido) hasta el stop (sin incluir) con un paso de step
Si step no se indica, por defecto es 1
Por ejemplo, si queremos items de la segunda fila y de la segunda a la cuarta columna:
- Seleccionamos la segunda fila con un 1 (ya que se empieza a contar desde 0)
- Seleccionamos de la segunda a la cuarta fila mediante 1:4, el 1 para indicar la segunda columna y el 4 para indicar la quinta (ya que el segundo número indica la columna en la que se termina sin incluir esta columna). Los dos números teniendo en cuenta que se empieza a contar desde 0
print(arr)print(arr[1, 1:4])
[[ 1 2 3 4 5][ 6 7 8 9 10]][7 8 9]
Podemos coger desde una posición hasta el final
arr[1, 2:]
array([ 8, 9, 10])
Desde el inicio hasta una posición
arr[1, :3]
array([6, 7, 8])
Establecer el rango con números negativos
arr[1, -3:-1]
array([8, 9])
Elegir el paso
arr[1, 1:4:2]
array([7, 9])
7.2. Iteración sobre matrices
La iteración sobre matrices multidimensionales se realiza con respecto al primer eje
M = np.array( [[[ 0, 1, 2],[ 10, 12, 13]],[[100,101,102],[110,112,113]]])print(f'Matriz de dimensión: {M.shape} ')i = 0for fila in M:print(f'Fila {i}: {fila}')i += 1
Matriz de dimensión: (2, 2, 3)Fila 0: [[ 0 1 2][10 12 13]]Fila 1: [[100 101 102][110 112 113]]
Sin embargo, si lo que queremos es iterar por cada ítem, podemos usar el método 'flat'
i = 0for fila in M.flat:print(f'Elemento {i}: {fila}')i += 1
Elemento 0: 0Elemento 1: 1Elemento 2: 2Elemento 3: 10Elemento 4: 12Elemento 5: 13Elemento 6: 100Elemento 7: 101Elemento 8: 102Elemento 9: 110Elemento 10: 112Elemento 11: 113
8. Copia de matrices
En NumPy tenemos dos maneras de copiar matrices: mediante copy, que realiza una copia nueva de la matriz, y mediante view, que realiza una vista de la matriz original.
La copia es propietaria de los datos y cualquier cambio realizado en la copia no afectará a la matriz original, y cualquier cambio realizado en la matriz original no afectará a la copia.
La vista no es propietaria de los datos y cualquier cambio realizado en la copia afectará a la matriz original, y cualquier cambio realizado en la matriz original afectará a la copia.
8.1. Copy
arr = np.array([1, 2, 3, 4, 5])copy_arr = arr.copy()arr[0] = 42copy_arr[1] = 43print(f'Original: {arr}')print(f'Copia: {copy_arr}')
Original: [42 2 3 4 5]Copia: [ 1 43 3 4 5]
8.2. View
arr = np.array([1, 2, 3, 4, 5])view_arr = arr.view()arr[0] = 42view_arr[1] = 43print(f'Original: {arr}')print(f'Vista: {view_arr}')
Original: [42 43 3 4 5]Vista: [42 43 3 4 5]
8.3. Propietario de los datos
Ante la duda de si tenemos una copia o una vista, podemos usar base
arr = np.array([1, 2, 3, 4, 5])copy_arr = arr.copy()view_arr = arr.view()print(copy_arr.base)print(view_arr.base)
None[1 2 3 4 5]
9. Forma de las matrices
Podemos saber la forma que tiene la matriz mediante el método shape. Este nos devolverá una tupla, el tamaño de la tupla representa las dimensiones de la matriz, en cada elemento de la tupla se indica el número de ítems en cada una de las dimensiones de la matriz
arr = np.array([[[1, 2, 3, 4, 5],[6, 7, 8, 9, 10]],[[11, 12, 13, 14, 15],[16, 17, 18, 19, 20]]])print(arr)print(arr.shape)
[[[ 1 2 3 4 5][ 6 7 8 9 10]][[11 12 13 14 15][16 17 18 19 20]]](2, 2, 5)
9.1. Reshape
Podemos cambiar la forma de las matrices a la que queramos mediante el método reshape.
Por ejemplo, la matriz anterior, que tiene una forma de (2, 2, 4). Podemos pasarla a (5, 4)
arr_reshape = arr.reshape(5, 4)print(arr_reshape)print(arr_reshape.shape)
[[ 1 2 3 4][ 5 6 7 8][ 9 10 11 12][13 14 15 16][17 18 19 20]](5, 4)
Hay que tener en cuenta que para redimensionar las matrices el número de ítems de la nueva forma tiene que tener el mismo número de ítems de la primera forma
Es decir, en el ejemplo anterior, la primera matriz tenía 20 ítems (2x2x4), y la nueva matriz tiene 20 ítems (5x4). Lo que no podemos es redimensionarla a una matriz de tamaño (3, 4), ya que en total habría 12 ítems
arr_reshape = arr.reshape(3, 4)
---------------------------------------------------------------------------ValueError Traceback (most recent call last)<ipython-input-12-29e85875d1df> in <module>()----> 1 arr_reshape = arr.reshape(3, 4)ValueError: cannot reshape array of size 20 into shape (3,4)
9.2. Dimensión desconocida
En el caso que queramos cambiar la forma de una matriz y una de las dimensiones nos dé igual, o no la conozcamos, podemos hacer que NumPy la calcule por nosotros introduciendo un -1 como parámetro
arr = np.array([[[1, 2, 3, 4, 5],[6, 7, 8, 9, 10]],[[11, 12, 13, 14, 15],[16, 17, 18, 19, 20]]])arr_reshape = arr.reshape(2, -1)print(arr_reshape)print(arr_reshape.shape)
[[ 1 2 3 4 5 6 7 8 9 10][11 12 13 14 15 16 17 18 19 20]](2, 10)
Hay que tener en cuenta que no se puede poner cualquier número en las dimensiones conocidas. El número de ítems de la matriz original tiene que ser un múltiplo de las dimensiones conocidas.
En el ejemplo anterior, la matriz tiene 20 ítems, que es múltiplo de 2, dimensión conocida introducida. No se hubiera podido poner un 3 como dimensión conocida, ya que 20 no es múltiplo de 3, y no habría ningún número que se pueda poner en la dimensión desconocida que haga que en total haya 20 ítems.
9.3. Aplanamiento de matrices
Podemos aplanar las matrices, es decir, pasarlas a una sola dimensión mediante reshape(-1). De esta manera, tenga las dimensiones que tenga la matriz original, la nueva siempre tendrá una sola dimensión
arr = np.array([[[1, 2, 3, 4, 5],[6, 7, 8, 9, 10]],[[11, 12, 13, 14, 15],[16, 17, 18, 19, 20]]])arr_flatten = arr.reshape(-1)print(arr_flatten)print(arr_flatten.shape)
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20](20,)
Otra forma de aplanar una matriz es mediante el método ravel()
arr = np.array([[[1, 2, 3, 4, 5],[6, 7, 8, 9, 10]],[[11, 12, 13, 14, 15],[16, 17, 18, 19, 20]]])arr_flatten = arr.ravel()print(arr_flatten)print(arr_flatten.shape)
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20](20,)
9.4. Matriz traspuesta
Se puede obtener la transpuesta de una matriz mediante el método T. Hacer la transpuesta de una matriz es intercambiar las filas y las columnas de la matriz, en la siguiente imagen se ve un ejemplo que lo aclara más
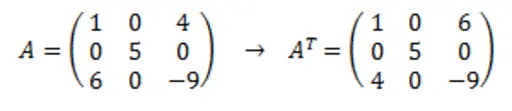
arr = np.array([[1, 0, 4],[0, 5, 0],[6, 0, -9]])arr_t = arr.Tprint(arr_t)print(arr_t.shape)
[[ 1 0 6][ 0 5 0][ 4 0 -9]](3, 3)
10. Apilado de matrices
10.1. Apilamiento vertical
Se pueden apilar matrices verticalmente (uniendo filas) mediante el método vstack()
a = np.array([[1, 1, 1],[2, 2, 2],[3, 3, 3]])b = np.array([[4, 4, 4],[5, 5, 5],[6, 6, 6]])c = np.vstack((a,b))c
array([[1, 1, 1],[2, 2, 2],[3, 3, 3],[4, 4, 4],[5, 5, 5],[6, 6, 6]])
Si se tienen matrices de más de 2 dimensiones, vstack() apilará a lo largo de la primera dimensión
a = np.array([[[1, 1],[2, 2]],[[3, 3],[4, 4]]])b = np.array([[[5, 5],[6, 6]],[[7, 7],[8, 8]]])c = np.vstack((a,b))c
array([[[1, 1],[2, 2]],[[3, 3],[4, 4]],[[5, 5],[6, 6]],[[7, 7],[8, 8]]])
10.2. Apilamiento horizontal
Se pueden apilar matrices horizontalmente (uniendo columnas) mediante el método hstack()
a = np.array([[1, 2, 3],[1, 2, 3],[1, 2, 3]])b = np.array([[4, 5, 6],[4, 5, 6],[4, 5, 6]])c = np.hstack((a,b))c
array([[1, 2, 3, 4, 5, 6],[1, 2, 3, 4, 5, 6],[1, 2, 3, 4, 5, 6]])
Si se tienen matrices de más de 2 dimensiones, hstack() apilará a lo largo de la segunda dimensión
a = np.array([[[1, 1],[2, 2]],[[3, 3],[4, 4]]])b = np.array([[[5, 5],[6, 6]],[[7, 7],[8, 8]]])c = np.hstack((a,b))c
array([[[1, 1],[2, 2],[5, 5],[6, 6]],[[3, 3],[4, 4],[7, 7],[8, 8]]])
Otra manera de agregar columnas a una matriz es mediante el método column_stack()
a = np.array([[1, 2, 3],[1, 2, 3],[1, 2, 3]])b = np.array([4, 4, 4])c = np.column_stack((a,b))c
array([[1, 2, 3, 4],[1, 2, 3, 4],[1, 2, 3, 4]])
10.3. Apilamiento en profundidad
Se pueden apilar matrices en profundidad (tercera dimensión) mediante el método dstack()
a = np.array([[[1, 1],[2, 2]],[[3, 3],[4, 4]]])b = np.array([[[1, 1],[2, 2]],[[3, 3],[4, 4]]])c = np.dstack((a,b))print(f"c: {c} ")print(f"a.shape: {a.shape}, b.shape: {b.shape}, c.shape: {c.shape}")
c: [[[1 1 1 1][2 2 2 2]][[3 3 3 3][4 4 4 4]]]a.shape: (2, 2, 2), b.shape: (2, 2, 2), c.shape: (2, 2, 4)
Si se tienen matrices de más de 4 dimensiones dstack() apilirá a lo largo de la tercera dimensión
a = np.array([1, 2, 3, 4, 5], ndmin=4)b = np.array([1, 2, 3, 4, 5], ndmin=4)c = np.dstack((a,b))print(f"a.shape: {a.shape}, b.shape: {b.shape}, c.shape: {c.shape}")
a.shape: (1, 1, 1, 5), b.shape: (1, 1, 1, 5), c.shape: (1, 1, 2, 5)
10.3. Apilamiento personalizado
Mediante el método concatenate() se puede elegir el eje en el que se quieran apilar las matrices
a = np.array([[[1, 1],[2, 2]],[[3, 3],[4, 4]]])b = np.array([[[5, 5],[6, 6]],[[7, 7],[8, 8]]])conc0 = np.concatenate((a,b), axis=0) # concatenamiento en el primer ejeconc1 = np.concatenate((a,b), axis=1) # concatenamiento en el segundo ejeconc2 = np.concatenate((a,b), axis=2) # concatenamiento en el tercer ejeprint(f"conc0: {conc0} ")print(f"conc1: {conc1} ")print(f"conc2: {conc2}")
conc0: [[[1 1][2 2]][[3 3][4 4]][[5 5][6 6]][[7 7][8 8]]]conc1: [[[1 1][2 2][5 5][6 6]][[3 3][4 4][7 7][8 8]]]conc2: [[[1 1 5 5][2 2 6 6]][[3 3 7 7][4 4 8 8]]]
11. Dividir matrices
11.1. Dividir verticalmente
Se pueden dividir matrices verticalmente (separando filas) mediante el método vsplit()
a = np.array([[1.1, 1.2, 1.3, 1.4],[2.1, 2.2, 2.3, 2.4],[3.1, 3.2, 3.3, 3.4],[4.1, 4.2, 4.3, 4.4]])[a1, a2] = np.vsplit(a, 2)print(f"a1: {a1} ")print(f"a2: {a2}")
a1: [[1.1 1.2 1.3 1.4][2.1 2.2 2.3 2.4]]a2: [[3.1 3.2 3.3 3.4][4.1 4.2 4.3 4.4]]
Si se tienen matrices de más de 2 dimensiones, vsplit() dividirá a lo largo de la primera dimensión.
a = np.array([[[1, 1],[2, 2]],[[3, 3],[4, 4]]])[a1, a2] = np.vsplit(a, 2)print(f"a1: {a1} ")print(f"a2: {a2}")
a1: [[[1 1][2 2]]]a2: [[[3 3][4 4]]]
11.2. Dividir horizontalmente
Se pueden dividir matrices horizontalmente (separando columnas) mediante el método hsplit()
a = np.array([[1.1, 1.2, 1.3, 1.4],[2.1, 2.2, 2.3, 2.4],[3.1, 3.2, 3.3, 3.4],[4.1, 4.2, 4.3, 4.4]])[a1, a2] = np.hsplit(a, 2)print(f"a1: {a1} ")print(f"a2: {a2}")
a1: [[1.1 1.2][2.1 2.2][3.1 3.2][4.1 4.2]]a2: [[1.3 1.4][2.3 2.4][3.3 3.4][4.3 4.4]]
Si se tienen matrices de más de 2 dimensiones, hsplit() dividirá a lo largo de la segunda dimensión
a = np.array([[[1, 1],[2, 2]],[[3, 3],[4, 4]]])[a1, a2] = np.hsplit(a, 2)print(f"a1: {a1} ")print(f"a2: {a2}")
a1: [[[1 1]][[3 3]]]a2: [[[2 2]][[4 4]]]
11.3. Dividir de manera personalizada
Mediante el método array_split() se puede elegir el eje en el que se quieren dividir las matrices
a = np.array([[[1, 1],[2, 2]],[[3, 3],[4, 4]]])[a1_eje0, a2_eje0] = np.array_split(a, 2, axis=0)[a1_eje1, a2_eje1] = np.array_split(a, 2, axis=1)[a1_eje2, a2_eje2] = np.array_split(a, 2, axis=2)print(f"a1_eje0: {a1_eje0} ")print(f"a2_eje0: {a2_eje0} ")print(f"a1_eje1: {a1_eje1} ")print(f"a2_eje1: {a2_eje1} ")print(f"a1_eje2: {a1_eje2} ")print(f"a2_eje2: {a2_eje2}")
a1_eje0: [[[1 1][2 2]]]a2_eje0: [[[3 3][4 4]]]a1_eje1: [[[1 1]][[3 3]]]a2_eje1: [[[2 2]][[4 4]]]a1_eje2: [[[1][2]][[3][4]]]a2_eje2: [[[1][2]][[3][4]]]
12. Búsqueda en matrices
Si se quiere buscar un valor dentro de una matriz, se puede usar el método where() que devuelve las posiciones donde la matriz tiene el valor que estamos buscando
arr = np.array([1, 2, 3, 4, 5, 4, 4])ids = np.where(arr == 4)ids
(array([3, 5, 6]),)
Se pueden usar funciones para buscar, por ejemplo, si queremos buscar en qué posiciones los valores son pares
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])ids = np.where(arr%2)ids
(array([0, 2, 4, 6]),)
13. Ordenar matrices
Mediante el método sort() podemos ordenar matrices
arr = np.array([3, 2, 0, 1])arr_ordenado = np.sort(arr)arr_ordenado
array([0, 1, 2, 3])
Si lo que tenemos son strings, los ordena alfabéticamente
arr = np.array(['banana', 'apple', 'cherry'])arr_ordenado = np.sort(arr)arr_ordenado
array(['apple', 'banana', 'cherry'], dtype='<U6')
Y las matrices de booleanos también las ordena
arr = np.array([True, False, True])arr_ordenado = np.sort(arr)arr_ordenado
array([False, True, True])
Si se tienen matrices de más de una dimensión, las ordena por dimensiones, es decir, si se tiene una matriz de 2 dimensiones, ordena los números de la primera fila entre ellos y los de la segunda fila entre ellos
arr = np.array([[3, 2, 4], [5, 0, 1]])arr_ordenado = np.sort(arr)arr_ordenado
array([[2, 3, 4],[0, 1, 5]])
Por defecto ordena siempre con respecto a las filas, pero si se quiere que ordene con respecto a otra dimensión, se tiene que especificar mediante la variable axis
arr = np.array([[3, 2, 4], [5, 0, 1]])arr_ordenado0 = np.sort(arr, axis=0) # Se ordena con respecto a la primera dimensiónarr_ordenado1 = np.sort(arr, axis=1) # Se ordena con respecto a la segunda dimensiónprint(f"arr_ordenado0: {arr_ordenado0} ")print(f"arr_ordenado1: {arr_ordenado1} ")
arr_ordenado0: [[3 0 1][5 2 4]]arr_ordenado1: [[2 3 4][0 1 5]]
14. Filtros en matrices
NumPy ofrece la posibilidad de buscar ciertos elementos de una matriz y crear una nueva
Esto lo hace creando una matriz de índices booleanos, es decir, crea una nueva matriz que indica cuáles posiciones nos quedamos de la matriz y cuáles no
Veamos un ejemplo de una matriz de índices booleanos
arr = np.array([37, 85, 12, 45, 69, 22])indices_booleanos = [False, False, True, False, False, True]arr_filter = arr[indices_booleanos]print(f"Array original: {arr}")print(f"indices booleanos: {indices_booleanos}")print(f"Array filtrado: {arr_filter}")
Array original: [37 85 12 45 69 22]indices booleanos: [False, False, True, False, False, True]Array filtrado: [12 22]
Como se puede ver, el array filtrado (arr_filtr), solo se ha quedado del array original (arr) con los elementos que coinciden con aquellos en los que el array indices_booleanos vale True
Otra cosa que podemos ver es que solo se ha quedado con los elementos pares, por lo que ahora pasaremos a ver cómo se hace para quedarse con los elementos pares de una matriz, sin tener que hacerlo a mano como lo hemos hecho en el ejemplo anterior
arr = np.array([[1, 2, 3, 4, 5],[6, 7, 8, 9, 10]])indices_booleanos = arr % 2 == 0arr_filter = arr[indices_booleanos]print(f"Array original: {arr} ")print(f"indices booleanos: {indices_booleanos} ")print(f"Array filtrado: {arr_filter}")
Array original: [[ 1 2 3 4 5][ 6 7 8 9 10]]indices booleanos: [[False True False True False][ True False True False True]]Array filtrado: [ 2 4 6 8 10]