
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
Em um post anterior sobre tokens, já vimos a representação mínima de cada palavra. Que corresponde a dar um número à menor divisão de cada palavra.
No entanto, os transformers e, portanto, os LLMs, não representam assim a informação das palavras, mas sim através de embeddings.
Vamos ver primeiro duas formas de representar as palavras, o ordinal encoding e o one hot encoding. E vendo os problemas desses dois tipos de representações poderemos chegar até os word embeddings e os sentence embeddings.
Além disso, vamos ver um exemplo de como treinar um modelo de word embeddings com a biblioteca gensim.
E por último veremos como usar modelos pré-treinados de embeddings com a biblioteca transformers do HuggingFace.
Codificação ordinal
Esta é a maneira mais básica de representar as palavras dentro dos transformers. Consiste em dar um número a cada palavra, ou ficarmos com os números que já estão atribuídos aos tokens.
No entanto, este tipo de representação tem dois problemas
- Imaginemos que mesa corresponde ao token 3, gato ao token 1 e cachorro ao token 2. Se poderia chegar a supor que
mesa = gato + cachorro, mas não é assim. Não existe essa relação entre essas palavras. Até mesmo poderíamos pensar que atribuindo os tokens corretos sim poderia chegar a dar esse tipo de relações. No entanto, este pensamento desmorona com as palavras que têm mais de um significado, como por exemplo a palavrabanco
- O segundo problema é que as redes neurais internamente realizam muitos cálculos numéricos, pelo que poderia acontecer que se a mesa tiver o token 3, tenha internamente mais importância que a palavra gato que tem o token 1.
Portanto, esse tipo de representação das palavras pode ser descartado muito rapidamente.
Codificação one-hot
Aqui o que se faz é usar vetores de N dimensões. Por exemplo, vimos que a OpenAI tem um vocabulário de 100277 tokens distintos. Portanto, se usarmos one hot encoding, cada palavra seria representada por um vetor de 100277 dimensões.
No entanto, o one hot encoding tem outros dois grandes problemas
- Não leva em conta a relação entre as palavras. Portanto, se tivermos duas palavras que são sinônimos, como por exemplo
gatoefelino, teríamos dois vetores diferentes para representá-los.
Na linguagem, a relação entre as palavras é muito importante, e não levar em conta essa relação é um grande problema.
- O segundo problema é que os vetores são muito grandes. Se tivermos um vocabulário de
100277tokens, cada palavra seria representada por um vetor de100277dimensões. Isso faz com que os vetores sejam muito grandes e que os cálculos sejam muito custosos. Além disso, esses vetores serão todos zeros, exceto na posição correspondente ao token da palavra. Portanto, a maioria dos cálculos será multiplicação por zero, que são cálculos que não contribuem com nada. Assim, vamos ter uma grande quantidade de memória alocada para vetores nos quais há apenas um1em uma posição específica.
Embeddings de palavras
Com os word embeddings tenta-se resolver os problemas dos dois tipos de representações anteriores. Para isso, utilizam-se vetores de N dimensões, mas, neste caso, não se usam vetores de 100277 dimensões, e sim vetores com muito menos dimensões. Por exemplo, veremos que a OpenAI usa 1536 dimensões.
Cada uma das dimensões desses vetores representa uma característica da palavra. Por exemplo, uma das dimensões poderia representar se a palavra é um verbo ou um substantivo. Outra dimensão poderia representar se a palavra é um animal ou não. Outra dimensão poderia representar se a palavra é um nome próprio ou não. E assim sucessivamente.
No entanto, essas características não são definidas manualmente, mas sim aprendidas automaticamente. Durante o treinamento dos transformers, os valores de cada uma das dimensões dos vetores são ajustados, de modo que se aprendam as características de cada palavra.
Ao fazer com que cada uma das dimensões das palavras represente uma característica da palavra, consegue-se que as palavras que tenham características semelhantes, tenham vetores semelhantes. Por exemplo, as palavras gato e felino terão vetores muito semelhantes, já que ambas são animais. E as palavras mesa e silla terão vetores semelhantes, já que ambas são móveis.
Na imagem a seguir, podemos ver uma representação tridimensional de palavras, e observamos que todas as palavras relacionadas com school estão próximas, todas as palavras relacionadas com food estão próximas e todas as palavras relacionadas com ball estão próximas.
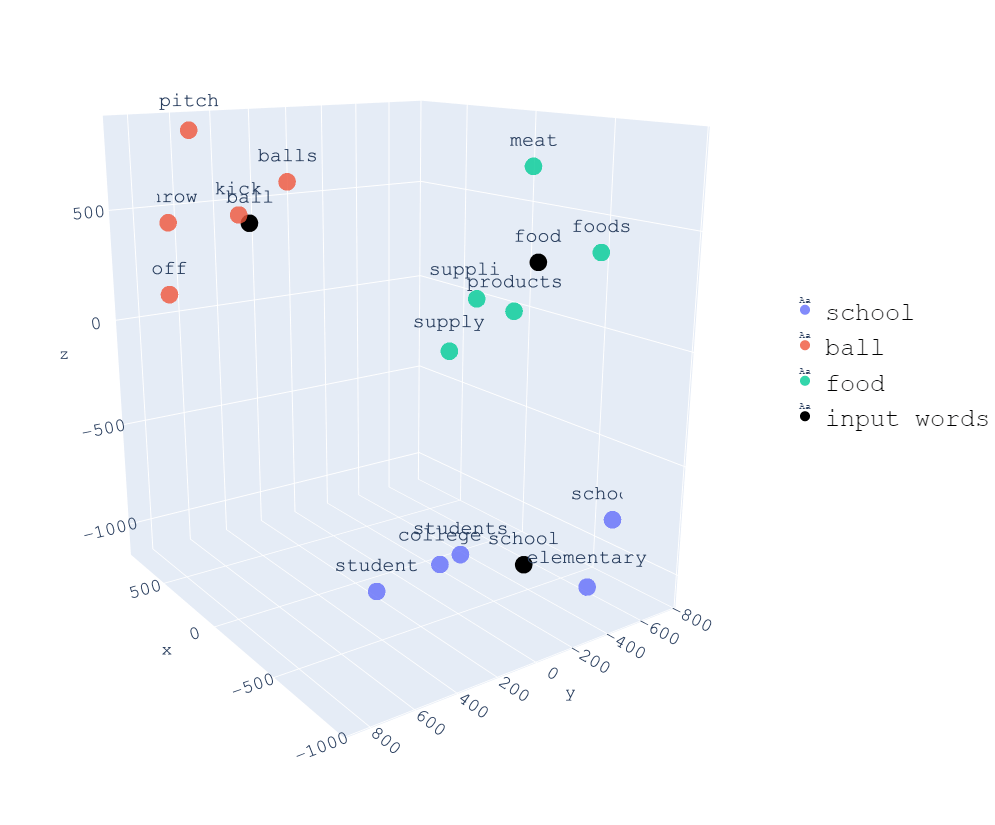
O fato de cada uma das dimensões dos vetores representar uma característica da palavra permite que possamos realizar operações com palavras. Por exemplo, se subtrairmos a palavra homem da palavra rei e somarmos a palavra mulher, obtemos uma palavra muito semelhante à palavra rainha. Verificaremos isso com um exemplo mais adiante.
Similaridade entre palavras
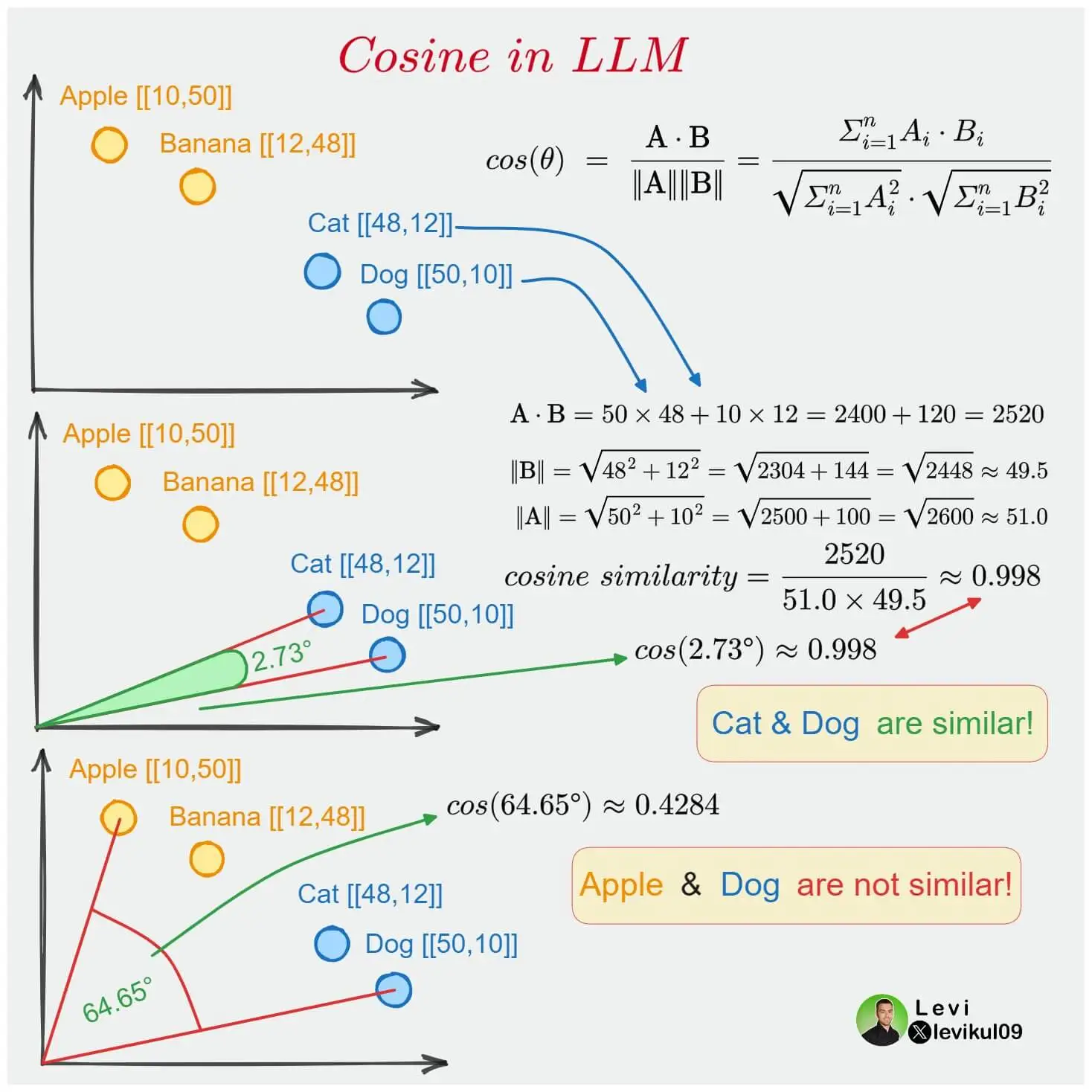
Como cada uma das palavras é representada por um vetor de N dimensões, podemos calcular a similaridade entre duas palavras. Para isso, usa-se a função de similaridade do cosseno ou cosine similarity.
Se duas palavras estão próximas no espaço vetorial, isso significa que o ângulo entre seus vetores é pequeno, portanto seu cosseno é próximo de 1. Se há um ângulo de 90 graus entre os vetores, o cosseno é 0, ou seja, não há similaridade entre as palavras. E se há um ângulo de 180 graus entre os vetores, o cosseno é -1, ou seja, as palavras são opostas.
Exemplo com embeddings da OpenAI
Agora que sabemos o que são os embeddings, vejamos alguns exemplos com os embeddings que nos proporciona a API da OpenAI.
Para isso, primeiro temos que ter o pacote de OpenAI instalado.
pip install openaiImportamos as bibliotecas necessárias
InputPythonfrom openai import OpenAIimport torchfrom torch.nn.functional import cosine_similarityCopied
Usamos uma API key da OpenAI. Para isso, nos dirigimos à página de OpenAI, e nos registramos. Uma vez registrados, nos dirigimos à seção de API Keys, e criamos uma nova API Key.
InputPythonapi_key = "Pon aquí tu API key"Copied
Selecionamos qual modelo de embeddings queremos usar. Neste caso, vamos a usar text-embedding-ada-002, que é o recomendado pela OpenAI em sua documentação de embeddings.
InputPythonmodel_openai = "text-embedding-ada-002"Copied
Criamos um cliente da API
InputPythonclient_openai = OpenAI(api_key=api_key, organization=None)Copied
Vamos ver como são os embeddings da palavra Rei
InputPythonword = "Rey"embedding_openai = torch.Tensor(client_openai.embeddings.create(input=word, model=model_openai).data[0].embedding)embedding_openai.shape, embedding_openaiCopied
(torch.Size([1536]),tensor([-0.0103, -0.0005, -0.0189, ..., -0.0009, -0.0226, 0.0045]))
Como podemos ver, obtemos um vetor de 1536 dimensões.
Exemplo com embeddings do HuggingFace
Como a geração de embeddings da OpenAI é paga, vamos ver como usar os embeddings do HuggingFace, que são gratuitos. Para isso, primeiro temos que nos certificar de ter a biblioteca sentence-transformers instalada.
pip install -U sentence-transformersE agora começamos a gerar os embeddings das palavras
Primeiro importamos a biblioteca
InputPythonfrom sentence_transformers import SentenceTransformerCopied
Agora criamos um modelo de embeddings do HuggingFace. Usamos paraphrase-MiniLM-L6-v2 porque é um modelo pequeno e rápido, mas que dá bons resultados, e agora para nosso exemplo nos basta.
InputPythonmodel = SentenceTransformer('paraphrase-MiniLM-L6-v2')Copied
E já podemos gerar os embeddings das palavras
InputPythonsentence = ['Rey']embedding_huggingface = model.encode(sentence)embedding_huggingface.shape, embedding_huggingface[0]Copied
((1, 384),array([ 4.99837071e-01, -7.60397986e-02, 5.47384083e-01, 1.89465046e-01,-3.21713984e-01, -1.01025246e-01, 6.44087136e-01, 4.91398573e-01,3.73571329e-02, -2.77234882e-01, 4.34713453e-01, -1.06284058e+00,2.44114518e-01, 8.98794234e-01, 4.74923879e-01, -7.48904228e-01,2.84665376e-01, -1.75070837e-01, 5.92192829e-01, -1.02512836e-02,9.45721626e-01, 2.43777707e-01, 3.91995460e-01, 3.35530996e-01,-4.58333105e-01, 1.18869759e-01, 5.31717360e-01, -1.21750660e-01,-5.45580745e-01, -7.63889611e-01, -3.19075316e-01, 2.55386919e-01,-4.06407446e-01, -8.99556637e-01, 6.34190366e-02, -2.96231866e-01,-1.22994244e-01, 7.44934231e-02, -4.49327320e-01, -2.71379113e-01,-3.88012260e-01, -2.82730222e-01, 2.50365853e-01, 3.06314558e-01,5.01561277e-02, -5.73592126e-01, -4.93096076e-02, -2.54629493e-01,4.45663840e-01, -1.54654181e-03, 1.85357735e-01, 2.49421135e-01,7.80077875e-01, -2.99735814e-01, 7.34686375e-01, 9.35385004e-02,-8.64403173e-02, 5.90056717e-01, 9.62065995e-01, -3.89911681e-02,4.52635378e-01, 1.10802782e+00, -4.28262979e-01, 8.98583114e-01,-2.79768258e-01, -7.25559890e-01, 4.38431054e-01, 6.08255446e-01,-1.06222546e+00, 1.86217821e-03, 5.23232877e-01, -5.59782684e-01,1.08870542e+00, -1.29855171e-01, -1.34669527e-01, 4.24595959e-02,2.99118191e-01, -2.53481418e-01, -1.82368979e-01, 9.74772453e-01,-7.66527832e-01, 2.02146843e-01, -9.27186012e-01, -3.72025579e-01,2.51360565e-01, 3.66043419e-01, 3.58169287e-01, -5.50914466e-01,3.87659878e-01, 2.67650932e-01, -1.30100116e-01, -9.08647776e-02,2.58671075e-01, -4.44935560e-01, -1.43231079e-01, -2.83272982e-01,7.21463636e-02, 1.98998764e-01, -9.47986841e-02, 1.74529219e+00,1.71559617e-01, 5.96294463e-01, 1.38505893e-02, 3.90956283e-01,3.46427560e-01, 2.63105750e-01, 2.64972121e-01, -2.67196923e-01,7.54366294e-02, 9.39224422e-01, 3.35206270e-01, -1.99105024e-01,-4.06340271e-01, 3.83643419e-01, 4.37904626e-01, 8.92579079e-01,-5.86432815e-01, -2.59302586e-01, -6.39415443e-01, 1.21703267e-01,6.44594133e-01, 2.56335083e-02, 5.53315282e-02, 5.85618019e-01,1.03075497e-01, -4.17360187e-01, 5.00189543e-01, 4.23062295e-01,-7.62073815e-01, -4.36184794e-01, -4.13090199e-01, -2.14746520e-01,3.76077414e-01, -1.51846036e-02, -6.51694953e-01, 2.05930993e-01,-3.73996288e-01, 1.14034235e-01, -7.40544260e-01, 1.98710993e-01,-6.66027904e-01, 3.00016254e-01, -4.03109461e-01, 1.85078502e-01,-3.27183425e-01, 4.19003010e-01, 1.16863050e-01, -4.33366179e-01,3.62291127e-01, 6.25310719e-01, -3.34749371e-01, 3.18448655e-02,-9.09660235e-02, 3.58690947e-01, 1.23402506e-01, -5.08333087e-01,4.18513209e-01, 5.83032072e-01, -8.37822199e-01, -1.52947128e-01,5.07765234e-01, -2.90990144e-01, -2.56464798e-02, 5.69117546e-01,-5.43118417e-01, -3.27799052e-01, -1.70862004e-01, 4.14014012e-01,4.74694878e-01, 5.15708327e-01, 3.21234539e-02, 1.55380607e-01,-3.21141332e-01, -1.72114551e-01, 6.43211603e-01, -3.89207341e-02,-2.29103401e-01, 4.13877398e-01, -9.22305062e-02, -4.54976231e-01,-1.50242126e+00, -2.81573564e-01, 1.70057654e-01, 4.53076512e-01,-4.25060362e-01, -1.33391351e-01, 5.40394569e-03, 3.71117502e-01,-4.29107875e-01, 1.35897202e-02, 2.44936779e-01, 1.04574718e-01,-3.65612388e-01, 4.33572650e-01, -4.09719855e-01, -2.95067448e-02,1.26362443e-02, -7.43583977e-01, -7.35885441e-01, -1.35508239e-01,-2.12558493e-01, -5.46157181e-01, 7.55161867e-02, -3.57991695e-01,-1.20607555e-01, 5.53125329e-02, -3.23110700e-01, 4.88573104e-01,-1.07487953e+00, 1.72190830e-01, 8.48749802e-02, 5.73584400e-02,3.06147277e-01, 3.26699704e-01, 5.09487510e-01, -2.60940105e-01,-2.85459042e-01, 3.15197736e-01, -8.84049162e-02, -2.14854136e-01,4.04228538e-01, -3.53874594e-01, 3.30587216e-02, -2.04278827e-01,4.45132256e-01, -4.05272096e-01, 9.07981098e-01, -1.70708492e-01,3.62848401e-01, -3.17223936e-01, 1.53909430e-01, 7.24429131e-01,2.27339968e-01, -1.16330147e+00, -9.58504915e-01, 4.87008452e-01,-2.30886355e-01, -1.40117988e-01, 7.84571916e-02, -2.93157458e-01,1.00778294e+00, 1.34625390e-01, -4.66320179e-02, 6.51122704e-02,-1.50451362e-02, -2.15500608e-01, -2.42915586e-01, -3.21900517e-01,-2.94186682e-01, 4.71027017e-01, 1.56058431e-01, 1.30854800e-01,-2.84257025e-01, -1.44421116e-01, -7.09840000e-01, -1.80235609e-01,-8.30230191e-02, 9.08326149e-01, -8.22497830e-02, 1.46948382e-01,-1.41326815e-01, 3.81170362e-01, -6.37023628e-01, 1.70148894e-01,-1.00046806e-01, 5.70729785e-02, -1.09820545e+00, -1.03613675e-01,-6.21219516e-01, 4.55532551e-01, 1.86942443e-01, -2.04409719e-01,7.81394243e-01, -7.88963258e-01, 2.19068691e-01, -3.62780124e-01,-3.41522694e-01, -1.73794985e-01, -4.00943428e-01, 5.01900315e-01,4.53949839e-01, 1.03774257e-01, -1.66873619e-01, -4.63893116e-02,-1.78147718e-01, 4.85655308e-01, -3.02978605e-02, -5.67060888e-01,-4.68107373e-01, -6.57559693e-01, -5.02855539e-01, -1.94635347e-01,-9.58659649e-01, -4.97986436e-01, 1.33874401e-01, 3.09395105e-01,-4.52993363e-01, 7.43827343e-01, -1.87271550e-01, -6.11483693e-01,-1.08927953e+00, -2.30332208e-03, 2.11169615e-01, -3.46892715e-01,-3.32458824e-01, 2.07640216e-01, -4.10387546e-01, 3.12181324e-01,3.69687408e-01, 8.62928331e-01, 2.40735337e-01, -3.65841389e-02,6.84210837e-01, 3.45884450e-02, 5.63964128e-01, 2.39361122e-01,3.10872793e-01, -6.34638309e-01, -9.07931089e-01, -6.35836497e-02,2.20288679e-01, 2.59186536e-01, -4.45540816e-01, 6.33085072e-01,-1.97424471e-01, 7.51152515e-01, -2.68558711e-01, -4.39288855e-01,4.13556695e-01, -1.89288303e-01, 5.81856608e-01, 4.75860722e-02,1.60344616e-01, -2.96180040e-01, 2.91323394e-01, 1.34404674e-01,-1.22037649e-01, 4.19363379e-02, -3.87936801e-01, -9.25336123e-01,-5.28307915e-01, -1.74257740e-01, -1.52818128e-01, 4.31716293e-02,-2.12064430e-01, 2.98252910e-01, 9.86064151e-02, 3.84781063e-02,6.68018535e-02, -2.29525566e-01, -8.20755959e-03, 5.17108142e-01,-6.66776478e-01, -1.38897672e-01, 4.68370765e-01, -2.14766636e-01,2.43549764e-01, 2.25854263e-01, -1.92763060e-02, 2.78505355e-01,3.39088053e-01, -9.69757214e-02, -2.71263003e-01, 1.05703615e-01,1.14365645e-01, 4.16649908e-01, 4.18699026e-01, -1.76222697e-01,-2.08620593e-01, -5.79392374e-01, -1.68948188e-01, -1.77841976e-01,5.69338985e-02, 2.12916449e-01, 4.24367547e-01, -7.13860095e-02,8.28932896e-02, -2.40542665e-01, -5.94049037e-01, 4.09415931e-01,1.01326215e+00, -5.71239054e-01, 4.35258061e-01, -3.64619821e-01],dtype=float32))
Como vemos, obtemos um vetor de 384 dimensões. Neste caso, obtemos um vetor desta dimensão porque foi usado o modelo paraphrase-MiniLM-L6-v2. Se usarmos outro modelo, obteremos vetores de outra dimensão.
Operações com palavras
Vamos a obter os embeddings das palavras rei, homem, mulher e rainha
InputPythonembedding_openai_rey = torch.Tensor(client_openai.embeddings.create(input="rey", model=model_openai).data[0].embedding)embedding_openai_hombre = torch.Tensor(client_openai.embeddings.create(input="hombre", model=model_openai).data[0].embedding)embedding_openai_mujer = torch.Tensor(client_openai.embeddings.create(input="mujer", model=model_openai).data[0].embedding)embedding_openai_reina = torch.Tensor(client_openai.embeddings.create(input="reina", model=model_openai).data[0].embedding)Copied
InputPythonembedding_openai_reina.shape, embedding_openai_reinaCopied
(torch.Size([1536]),tensor([-0.0110, -0.0084, -0.0115, ..., 0.0082, -0.0096, -0.0024]))
Vamos a obter o embedding resultante de subtrair o embedding de homem do embedding de rei e adicionar o embedding de mulher
InputPythonembedding_openai = embedding_openai_rey - embedding_openai_hombre + embedding_openai_mujerCopied
InputPythonembedding_openai.shape, embedding_openaiCopied
(torch.Size([1536]),tensor([-0.0226, -0.0323, 0.0017, ..., 0.0014, -0.0290, -0.0188]))
Por último, comparamos o resultado obtido com o embedding de rainha. Para isso, usamos a função cosine_similarity fornecida pela biblioteca pytorch.
InputPythonsimilarity_openai = cosine_similarity(embedding_openai.unsqueeze(0), embedding_openai_reina.unsqueeze(0)).item()print(f"similarity_openai: {similarity_openai}")Copied
similarity_openai: 0.7564167976379395
Como vemos é um valor muito próximo de 1, portanto podemos dizer que o resultado obtido é muito semelhante ao embedding de reina
Se usarmos palavras em inglês, obtemos um resultado mais próximo de 1
InputPythonembedding_openai_rey = torch.Tensor(client_openai.embeddings.create(input="king", model=model_openai).data[0].embedding)embedding_openai_hombre = torch.Tensor(client_openai.embeddings.create(input="man", model=model_openai).data[0].embedding)embedding_openai_mujer = torch.Tensor(client_openai.embeddings.create(input="woman", model=model_openai).data[0].embedding)embedding_openai_reina = torch.Tensor(client_openai.embeddings.create(input="queen", model=model_openai).data[0].embedding)Copied
InputPythonembedding_openai = embedding_openai_rey - embedding_openai_hombre + embedding_openai_mujerCopied
InputPythonsimilarity_openai = cosine_similarity(embedding_openai.unsqueeze(0), embedding_openai_reina.unsqueeze(0))print(f"similarity_openai: {similarity_openai}")Copied
similarity_openai: tensor([0.8849])
Isto é normal, pois o modelo da OpenAI foi treinado com mais textos em inglês do que em português.
Tipos de Word Embeddings
Existem vários tipos de word embeddings, e cada um deles tem suas vantagens e desvantagens. Vamos ver os mais importantes.
- Word2Vec
- GloVe
- FastText
- BERT
- GPT-2
Word2Vec
Word2Vec é um algoritmo usado para criar word embeddings. Este algoritmo foi criado pelo Google em 2013 e é um dos algoritmos mais utilizados para criar word embeddings.
Ele tem duas variantes, CBOW e Skip-gram. O CBOW é mais rápido de treinar, enquanto o Skip-gram é mais preciso. Vamos ver como cada um deles funciona.
CBOW
CBOW ou Continuous Bag of Words é um algoritmo que é usado para prever uma palavra com base nas palavras ao seu redor. Por exemplo, se tivermos a frase O gato é um animal, o algoritmo tentará prever a palavra gato com base nas palavras ao seu redor, neste caso O, é, um e animal.
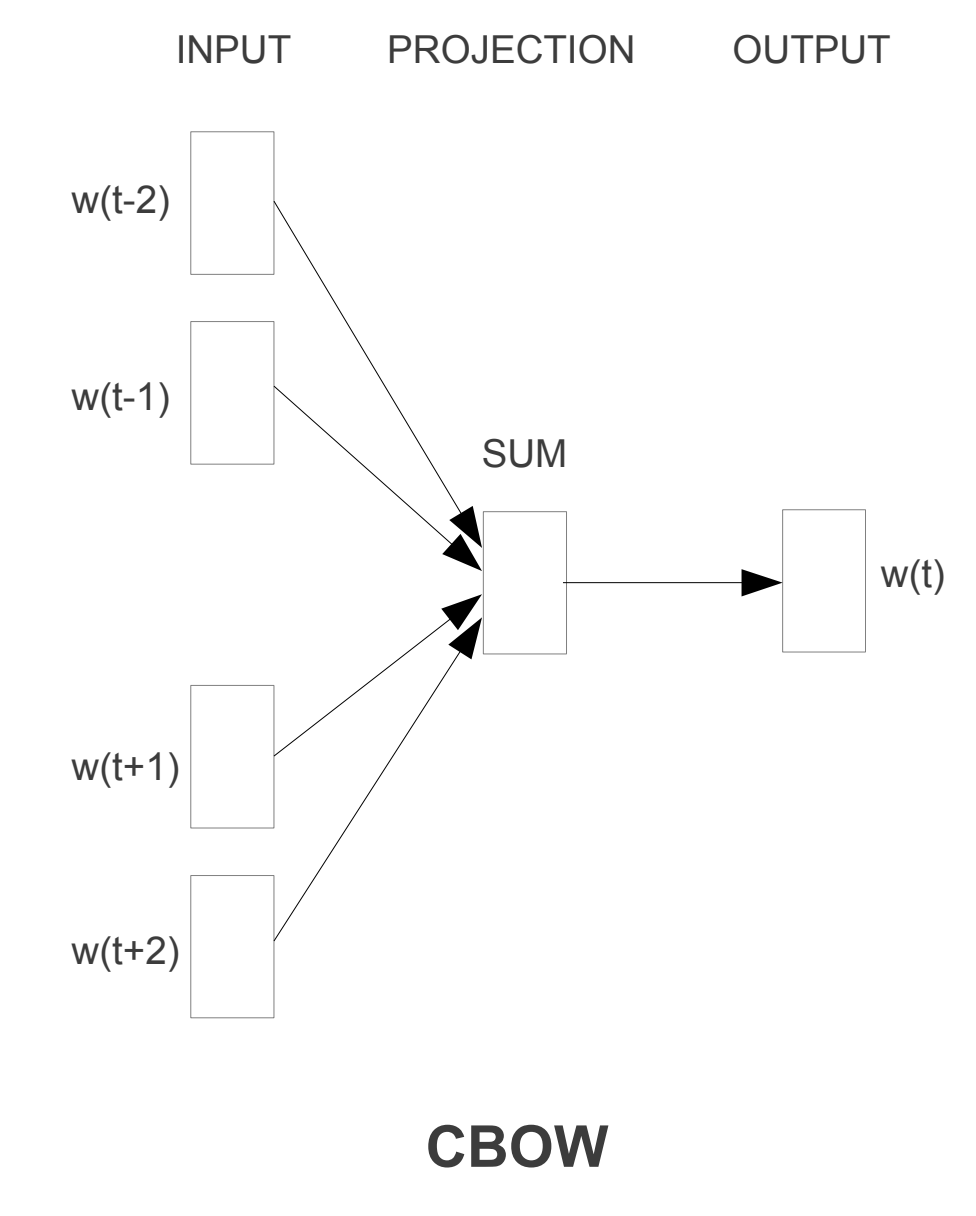
Nesta arquitetura, o modelo prevê qual é a palavra mais provável no contexto dado. Portanto, as palavras que têm a mesma probabilidade de aparecer são consideradas semelhantes e, por isso, ficam mais próximas no espaço dimensional.
Suponhamos que em uma frase substituímos barco por bote, então o modelo prevê a probabilidade para ambos e, se for semelhante, podemos considerar que as palavras são similares.
Skip-gram
Skip-gram ou Skip-gram with Negative Sampling é um algoritmo que é usado para prever as palavras que cercam uma palavra. Por exemplo, se temos a frase O gato é um animal, o algoritmo tentará prever as palavras O, é, um e animal a partir da palavra gato.
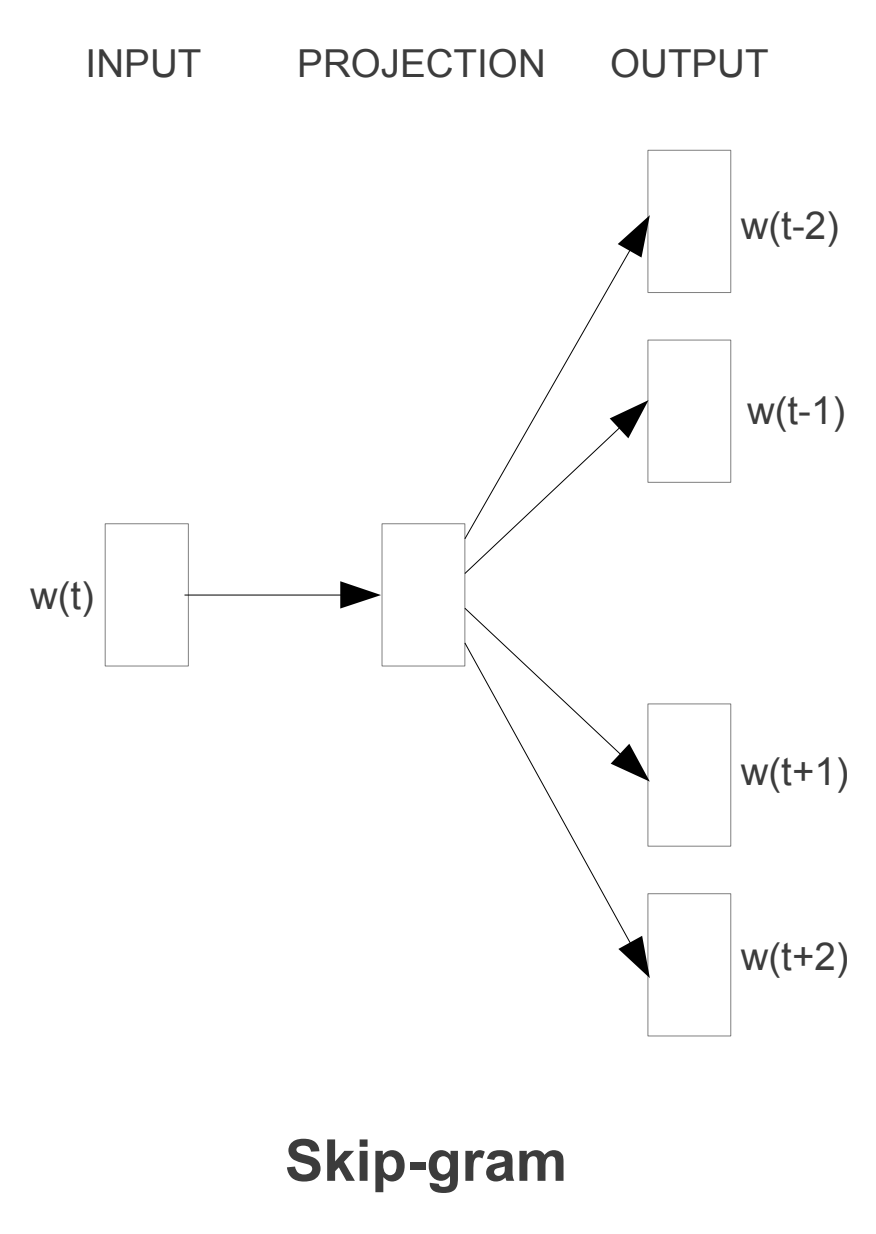
Esta arquitetura é semelhante à de CBOW, mas em vez disso o modelo funciona ao contrário. O modelo prevê o contexto usando a palavra dada. Portanto, as palavras que têm o mesmo contexto são consideradas similares e, portanto, se aproximam mais no espaço dimensional.
GloVe
GloVe ou Global Vectors for Word Representation é um algoritmo usado para criar word embeddings. Este algoritmo foi criado pela Universidade de Stanford em 2014.
Word2Vec ignora o fato de que algumas palavras de contexto ocorrem com mais frequência do que outras e também só levam em conta o contexto local, portanto, não capturam o contexto global.
Este algoritmo usa uma matriz de co-ocorrência para criar os word embeddings. Esta matriz de co-ocorrência é uma matriz que contém o número de vezes que cada palavra aparece junto com cada uma das outras palavras do vocabulário.
FastText
FastText é um algoritmo usado para criar word embeddings. Este algoritmo foi criado pelo Facebook em 2016.
Uma das principais desvantagens do Word2Vec e GloVe é que eles não podem codificar palavras desconhecidas ou fora do vocabulário.
Então, para lidar com esse problema, o Facebook propôs um modelo FastText. É uma extensão de Word2Vec e segue o mesmo modelo Skip-gram e CBOW. Mas, ao contrário do Word2Vec, que alimenta palavras inteiras na rede neural, o FastText primeiro divide as palavras em várias subpalavras (ou n-grams) e depois as alimenta à rede neural.
Por exemplo, se o valor de n for 3 e a palavra for maçã, então seu tri-gram será [<ma, maç, açã, çã>, ã>] e seu embedding de palavras será a soma da representação vetorial desses tri-grams. Aqui, os hiperparâmetros min_n e max_n são considerados como 3 e os caracteres < e > representam o início e o fim da palavra.
Portanto, utilizando esta metodologia, as palavras desconhecidas podem ser representadas em forma vetorial, pois há uma alta probabilidade de que seus n-grams também estejam presentes em outras palavras.
Este algoritmo é uma melhoria de Word2Vec, pois além de levar em conta as palavras que cercam uma palavra, também leva em conta os n-grams da palavra. Por exemplo, se temos a palavra gato, também leva em conta os n-gramas da palavra, neste caso ga, at e to, para n = 2.
Limitações dos word embeddings
As técnicas de word embedding têm dado um resultado decente, mas o problema é que a abordagem não é precisa o suficiente. Elas não levam em conta a ordem das palavras em que aparecem, o que leva à perda da compreensão sintática e semântica da frase.
Por exemplo, Você vai lá para ensinar, não para jogar e Você vai lá jogar, não para ensinar Ambas as frases terão a mesma representação no espaço vetorial, mas não significam a mesma coisa.
Além disso, o modelo de word embedding não pode fornecer resultados satisfatórios em uma grande quantidade de dados de texto, pois a mesma palavra pode ter um significado diferente em uma frase diferente de acordo com o contexto da frase.
Por exemplo, Vou me sentar no banco e Vou fazer trâmites no banco. Nas duas frases, a palavra banco tem significados diferentes.
Portanto, precisamos de um tipo de representação que possa reter o significado contextual da palavra presente em uma frase.
Embutimentos de frases
O sentence embedding é semelhante ao word embedding, mas em vez de palavras, codifica toda a frase na representação vetorial.
Uma forma simples de obter embeddings de sentenças é fazendo a média dos embeddings das palavras presentes na sentença. Mas eles não são suficientemente precisos.
Alguns dos modelos mais avançados para embedings de sentenças são ELMo, InferSent e Sentence-BERT
ELMo
ELMo ou Embeddings from Language Models é um modelo de sentence embedding que foi criado pela Universidade de Allen em 2018. Utiliza uma rede LSTM profunda bidirecional para produzir representação vetorial. ELMo pode representar palavras desconhecidas ou fora do vocabulário de forma vetorial, pois está baseado em caracteres.
InferSent
InferSent é um modelo de embedding de sentenças que foi criado pelo Facebook em 2017. Utiliza uma rede LSTM profunda bidirecional para produzir representação vetorial. InferSent pode representar palavras desconhecidas ou fora do vocabulário de forma vetorial, pois é baseado em caracteres. As sentenças são codificadas em uma representação vetorial de 4096 dimensões.
O treinamento do modelo é realizado no conjunto de dados Stanford Natural Language Inference (SNLI). Este conjunto de dados está anotado e escrito por humanos para cerca de 500K pares de sentenças.
Sentence-BERT
Sentence-BERT é um modelo de embedding de sentenças criado pela Universidade de Londres em 2019. Utiliza uma rede LSTM profunda bidirecional para produzir representação vetorial. Sentence-BERT pode representar palavras desconhecidas ou fora do vocabulário de forma vetorial, pois está baseado em caracteres. As sentenças são codificadas em uma representação vetorial de 768 dimensões.
O modelo de NLP de última geração BERT é excelente nas tarefas de Similaridade Textual Semântica, mas o problema é que levaria muito tempo para um corpus enorme (65 horas para 10.000 frases), já que requer que ambas as frases sejam introduzidas na rede e isso aumenta o cálculo por um fator enorme.
Portanto, Sentence-BERT é uma modificação do modelo BERT.
Treinamento de um modelo word2vec com gensim
Para baixar o dataset que vamos usar, é necessário instalar a biblioteca dataset do huggingface:
pip install datasetsPara treinar o modelo de embeddings vamos a usar a biblioteca gensim. Para instalá-la com Conda usamos
conda install -c conda-forge gensimE para instalá-la com pip usamos
pip install gensimPara limpar o dataset que baixamos, vamos usar expressões regulares, que geralmente já estão instaladas no Python, e nltk, que é uma biblioteca de processamento de linguagem natural. Para instalá-la com Conda, usamos
conda install -c anaconda nltkE para instalá-lo com pip usamos
pip install nltkAgora que temos tudo instalado, podemos importar as bibliotecas que vamos usar:
InputPythonfrom gensim.models import Word2Vecfrom gensim.parsing.preprocessing import strip_punctuation, strip_numeric, strip_shortimport refrom nltk.corpus import stopwordsfrom nltk.tokenize import word_tokenizeCopied
Download do dataset
Vamos a baixar um conjunto de dados de textos provenientes da Wikipedia em espanhol, para isso executamos o seguinte:
InputPythonfrom datasets import load_datasetdataset_corpus = load_dataset('large_spanish_corpus', name='all_wikis')Copied
Vamos a ver como é
InputPythondataset_corpusCopied
DatasetDict({train: Dataset({features: ['text'],num_rows: 28109484})})
Como podemos ver, o conjunto de dados tem mais de 28 milhões de textos. Vamos dar uma olhada em alguns deles:
InputPythondataset_corpus['train']['text'][0:10]Copied
['¡Bienvenidos!','Ir a los contenidos»','= Contenidos =','','Portada','Tercera Lengua más hablada en el mundo.','La segunda en número de habitantes en el mundo occidental.','La de mayor proyección y crecimiento día a día.','El español es, hoy en día, nombrado en cada vez más contextos, tomando realce internacional como lengua de cultura y civilización siempre de mayor envergadura.','Ejemplo de ello es que la comunidad minoritaria más hablada en los Estados Unidos es precisamente la que habla idioma español.']
Como há muitos exemplos, vamos criar um subconjunto de 10 milhões de exemplos para poder trabalhar mais rapidamente:
InputPythonsubset = dataset_corpus['train'].select(range(10000000))Copied
Limpeza do conjunto de dados
Agora baixamos as stopwords do nltk, que são palavras que não trazem informações e que vamos eliminar dos textos.
InputPythonimport nltknltk.download('stopwords')Copied
[nltk_data] Downloading package stopwords to[nltk_data] /home/wallabot/nltk_data...[nltk_data] Package stopwords is already up-to-date!
True
Agora vamos a baixar os punkt do nltk, que é um tokenizer que nos vai permitir separar os textos em frases.
InputPythonnltk.download('punkt')Copied
[nltk_data] Downloading package punkt to /home/wallabot/nltk_data...[nltk_data] Package punkt is already up-to-date!
True
Criamos uma função para limpar os dados. Esta função vai a:
- passar o texto para minúsculas
- Eliminar as URLs
- Remover as menções a redes sociais como
@twittere#hashtag - Eliminar os sinais de pontuação
- Eliminar os números
- Eliminar as palavras curtas
- Eliminar as palavras de parada
Como estamos usando um dataset do huggingface, os textos estão no formato dict, então retornamos um dicionário.
InputPythondef clean_text(sentence_batch):# extrae el texto de la entradatext_list = sentence_batch['text']cleaned_text_list = []for text in text_list:# Convierte el texto a minúsculastext = text.lower()# Elimina URLstext = re.sub(r'httpS+|wwwS+|httpsS+', '', text, flags=re.MULTILINE)# Elimina las menciones @ y '#' de las redes socialestext = re.sub(r'@w+|#w+', '', text)# Elimina los caracteres de puntuacióntext = strip_punctuation(text)# Elimina los númerostext = strip_numeric(text)# Elimina las palabras cortastext = strip_short(text,minsize=2)# Elimina las palabras comunes (stop words)stop_words = set(stopwords.words('spanish'))word_tokens = word_tokenize(text)filtered_text = [word for word in word_tokens if word not in stop_words]cleaned_text_list.append(filtered_text)# Devuelve el texto limpioreturn {'text': cleaned_text_list}Copied
Aplicamos a função aos dados
InputPythonsentences_corpus = subset.map(clean_text, batched=True)Copied
Map: 0%| | 0/10000000 [00:00<?, ? examples/s]
Vamos a salvar o conjunto de dados filtrado em um arquivo para não ter que executar novamente o processo de limpeza
InputPythonsentences_corpus.save_to_disk("sentences_corpus")Copied
Saving the dataset (0/4 shards): 0%| | 0/15000000 [00:00<?, ? examples/s]
Para carregá-lo podemos fazer
InputPythonfrom datasets import load_from_disksentences_corpus = load_from_disk('sentences_corpus')Copied
Agora teremos uma lista de listas, onde cada lista é uma frase tokenizada e sem stopwords. Isso significa que temos uma lista de frases, e cada frase é uma lista de palavras. Vamos ver como é:
InputPythonfor i in range(10):print(f'La frase "{subset["text"][i]}" se convierte en la lista de palabras "{sentences_corpus["text"][i]}"')Copied
La frase "¡Bienvenidos!" se convierte en la lista de palabras "['¡bienvenidos']"La frase "Ir a los contenidos»" se convierte en la lista de palabras "['ir', 'contenidos', '»']"La frase "= Contenidos =" se convierte en la lista de palabras "['contenidos']"La frase "" se convierte en la lista de palabras "[]"La frase "Portada" se convierte en la lista de palabras "['portada']"La frase "Tercera Lengua más hablada en el mundo." se convierte en la lista de palabras "['tercera', 'lengua', 'hablada', 'mundo']"La frase "La segunda en número de habitantes en el mundo occidental." se convierte en la lista de palabras "['segunda', 'número', 'habitantes', 'mundo', 'occidental']"La frase "La de mayor proyección y crecimiento día a día." se convierte en la lista de palabras "['mayor', 'proyección', 'crecimiento', 'día', 'día']"La frase "El español es, hoy en día, nombrado en cada vez más contextos, tomando realce internacional como lengua de cultura y civilización siempre de mayor envergadura." se convierte en la lista de palabras "['español', 'hoy', 'día', 'nombrado', 'cada', 'vez', 'contextos', 'tomando', 'realce', 'internacional', 'lengua', 'cultura', 'civilización', 'siempre', 'mayor', 'envergadura']"La frase "Ejemplo de ello es que la comunidad minoritaria más hablada en los Estados Unidos es precisamente la que habla idioma español." se convierte en la lista de palabras "['ejemplo', 'ello', 'comunidad', 'minoritaria', 'hablada', 'unidos', 'precisamente', 'habla', 'idioma', 'español']"
Treinamento do modelo word2vec
Vamos treinar um modelo de embeddings que converterá palavras em vetores. Para isso, vamos usar a biblioteca gensim e seu modelo Word2Vec.
InputPythondataset = sentences_corpus['text']dim_embedding = 100window_size = 5 # 5 palabras a la izquierda y 5 palabras a la derechamin_count = 5 # Ignora las palabras con frecuencia menor a 5workers = 4 # Número de hilos de ejecuciónsg = 1 # 0 para CBOW, 1 para Skip-grammodel = Word2Vec(dataset, vector_size=dim_embedding, window=window_size, min_count=min_count, workers=workers, sg=sg)Copied
Este modelo foi treinado na CPU, já que gensim não tem opção de realizar o treinamento na GPU e mesmo assim no meu computador levou X minutos para treinar o modelo. Embora a dimensão do embedding que escolhemos seja de apenas 100 (em comparação com o tamanho dos embeddings da OpenAI, que é de 1536), não é um tempo muito grande, já que o dataset tem 10 milhões de frases.
Os grandes modelos de linguagem são treinados com conjuntos de dados de bilhões de frases, portanto é normal que o treinamento de um modelo de embeddings com um conjunto de dados de 10 milhões de frases demore alguns minutos.
Uma vez treinado o modelo, o salvamos em um arquivo para poder usá-lo no futuro
InputPythonmodel.save('word2vec.model')Copied
Se quisermos carregá-lo no futuro, podemos fazer isso com
InputPythonmodel = Word2Vec.load('word2vec.model')Copied
Avaliação do modelo word2vec
Vamos a ver as palavras mais semelhantes de algumas palavras
InputPythonmodel.wv.most_similar('perro', topn=10)Copied
[('gato', 0.7948548197746277),('perros', 0.77247554063797),('cachorro', 0.7638891339302063),('hámster', 0.7540281414985657),('caniche', 0.7514827251434326),('bobtail', 0.7492328882217407),('mastín', 0.7491254210472107),('lobo', 0.7312178611755371),('semental', 0.7292628288269043),('sabueso', 0.7290207147598267)]
InputPythonmodel.wv.most_similar('gato', topn=10)Copied
[('conejo', 0.8148329854011536),('zorro', 0.8109457492828369),('perro', 0.7948548793792725),('lobo', 0.7878773808479309),('ardilla', 0.7860757112503052),('mapache', 0.7817519307136536),('huiña', 0.766639232635498),('oso', 0.7656188011169434),('mono', 0.7633568644523621),('camaleón', 0.7623056769371033)]
Agora vamos ver o exemplo no qual verificamos a similaridade da palavra rainha com o resultado de subtrair a palavra homem da palavra rei e adicionar a palavra mulher
InputPythonembedding_hombre = model.wv['hombre']embedding_mujer = model.wv['mujer']embedding_rey = model.wv['rey']embedding_reina = model.wv['reina']Copied
InputPythonembedding = embedding_rey - embedding_hombre + embedding_mujerCopied
InputPythonfrom torch.nn.functional import cosine_similarityembedding = torch.tensor(embedding).unsqueeze(0)embedding_reina = torch.tensor(embedding_reina).unsqueeze(0)similarity = cosine_similarity(embedding, embedding_reina, dim=1)similarityCopied
tensor([0.8156])
Como vemos, há bastante similaridade
Visualização dos embeddings
Vamos visualizar os embeddings, para isso primeiro obtemos os vetores e as palavras do modelo
InputPythonembeddings = model.wv.vectorswords = list(model.wv.index_to_key)Copied
Como a dimensão dos embeddings é 100, para poder visualizá-los em 2 ou 3 dimensões temos que reduzir a dimensão. Para isso vamos usar PCA (mais rápido) ou TSNE (mais preciso) de sklearn
InputPythonfrom sklearn.decomposition import PCAdimmesions = 2pca = PCA(n_components=dimmesions)reduced_embeddings_PCA = pca.fit_transform(embeddings)Copied
InputPythonfrom sklearn.manifold import TSNEdimmesions = 2tsne = TSNE(n_components=dimmesions, verbose=1, perplexity=40, n_iter=300)reduced_embeddings_tsne = tsne.fit_transform(embeddings)Copied
[t-SNE] Computing 121 nearest neighbors...[t-SNE] Indexed 493923 samples in 0.013s...[t-SNE] Computed neighbors for 493923 samples in 377.143s...[t-SNE] Computed conditional probabilities for sample 1000 / 493923[t-SNE] Computed conditional probabilities for sample 2000 / 493923[t-SNE] Computed conditional probabilities for sample 3000 / 493923[t-SNE] Computed conditional probabilities for sample 4000 / 493923[t-SNE] Computed conditional probabilities for sample 5000 / 493923[t-SNE] Computed conditional probabilities for sample 6000 / 493923[t-SNE] Computed conditional probabilities for sample 7000 / 493923[t-SNE] Computed conditional probabilities for sample 8000 / 493923[t-SNE] Computed conditional probabilities for sample 9000 / 493923[t-SNE] Computed conditional probabilities for sample 10000 / 493923[t-SNE] Computed conditional probabilities for sample 11000 / 493923[t-SNE] Computed conditional probabilities for sample 12000 / 493923[t-SNE] Computed conditional probabilities for sample 13000 / 493923[t-SNE] Computed conditional probabilities for sample 14000 / 493923[t-SNE] Computed conditional probabilities for sample 15000 / 493923[t-SNE] Computed conditional probabilities for sample 16000 / 493923[t-SNE] Computed conditional probabilities for sample 17000 / 493923[t-SNE] Computed conditional probabilities for sample 18000 / 493923[t-SNE] Computed conditional probabilities for sample 19000 / 493923[t-SNE] Computed conditional probabilities for sample 20000 / 493923[t-SNE] Computed conditional probabilities for sample 21000 / 493923[t-SNE] Computed conditional probabilities for sample 22000 / 493923...[t-SNE] Computed conditional probabilities for sample 493923 / 493923[t-SNE] Mean sigma: 0.275311[t-SNE] KL divergence after 250 iterations with early exaggeration: 117.413788[t-SNE] KL divergence after 300 iterations: 5.774648
Agora os visualizamos em 2 dimensões com matplotlib. Vamos visualizar a redução de dimensionalidade que fizemos com PCA e com TSNE.
InputPythonimport matplotlib.pyplot as pltplt.figure(figsize=(10, 10))for i, word in enumerate(words[:200]): # Limitar a las primeras 200 palabrasplt.scatter(reduced_embeddings_PCA[i, 0], reduced_embeddings_PCA[i, 1])plt.annotate(word, xy=(reduced_embeddings_PCA[i, 0], reduced_embeddings_PCA[i, 1]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')plt.title('Embeddings (PCA)')plt.show()Copied
<Figure size 1000x1000 with 1 Axes>
InputPythonplt.figure(figsize=(10, 10))for i, word in enumerate(words[:200]): # Limitar a las primeras 200 palabrasplt.scatter(reduced_embeddings_tsne[i, 0], reduced_embeddings_tsne[i, 1])plt.annotate(word, xy=(reduced_embeddings_tsne[i, 0], reduced_embeddings_tsne[i, 1]), xytext=(5, 2),textcoords='offset points', ha='right', va='bottom')plt.show()Copied
<Figure size 1000x1000 with 1 Axes>
Uso de modelos pré-treinados com HuggingFace
Para usar modelos pré-treinados de embeddings vamos a usar a biblioteca transformers do huggingface. Para instalá-la com Conda usamos
conda install -c conda-forge transformersE para instalá-lo com pip usamos
pip install transformersCom a tarefa feature-extraction do huggingface podemos usar modelos pré-treinados para obter os embeddings das palavras. Para isso, primeiro importamos a biblioteca necessária.
InputPythonfrom transformers import pipelineCopied
Vamos a obter os embeddings de BERT
InputPythoncheckpoint = "bert-base-uncased"feature_extractor = pipeline("feature-extraction",framework="pt",model=checkpoint)Copied
Vamos ver os embeddings da palavra rei
InputPythonembedding = feature_extractor("rey", return_tensors="pt").squeeze(0)embedding.shapeCopied
torch.Size([3, 768])
Como podemos ver, obtemos um vetor de 768 dimensões, ou seja, os embeddings do BERT têm 768 dimensões. Por outro lado, vemos que tem 3 vetores de embeddings, isso ocorre porque o BERT adiciona um token no início e outro no final da frase, portanto, apenas nos interessa o vetor do meio.
Vamos a fazer o exemplo novamente no qual verificamos a similaridade da palavra rainha com o resultado de subtrair da palavra rei a palavra homem e adicionar a palavra mulher
InputPythonembedding_hombre = feature_extractor("man", return_tensors="pt").squeeze(0)[1]embedding_mujer = feature_extractor("woman", return_tensors="pt").squeeze(0)[1]embedding_rey = feature_extractor("king", return_tensors="pt").squeeze(0)[1]embedding_reina = feature_extractor("queen", return_tensors="pt").squeeze(0)[1]Copied
InputPythonembedding = embedding_rey - embedding_hombre + embedding_mujerCopied
Vamos a ver a semelhança
InputPythonimport torchfrom torch.nn.functional import cosine_similarityembedding = torch.tensor(embedding).unsqueeze(0)embedding_reina = torch.tensor(embedding_reina).unsqueeze(0)similarity = cosine_similarity(embedding, embedding_reina, dim=1)similarity.item()Copied
/tmp/ipykernel_33343/4248442045.py:4: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).embedding = torch.tensor(embedding).unsqueeze(0)/tmp/ipykernel_33343/4248442045.py:5: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).embedding_reina = torch.tensor(embedding_reina).unsqueeze(0)
0.742547333240509
Usando os embeddings do BERT também obtemos um resultado muito próximo de 1

















