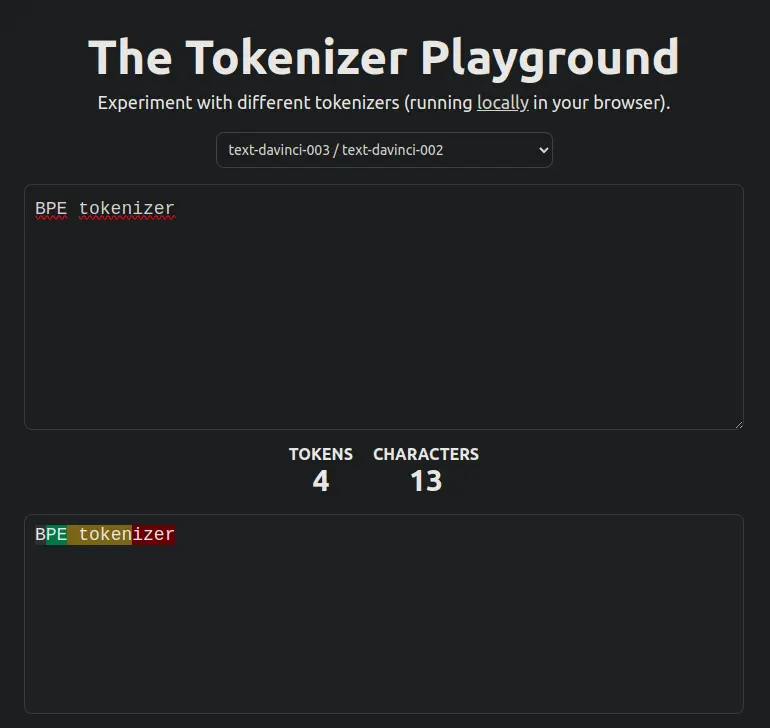
Padrões de agentes
Seus agentes estão falhando? Eleve seus projetos de IA com padrões avançados: ReAct, planejamento, multi-agentes e mais. Guia prática com código!
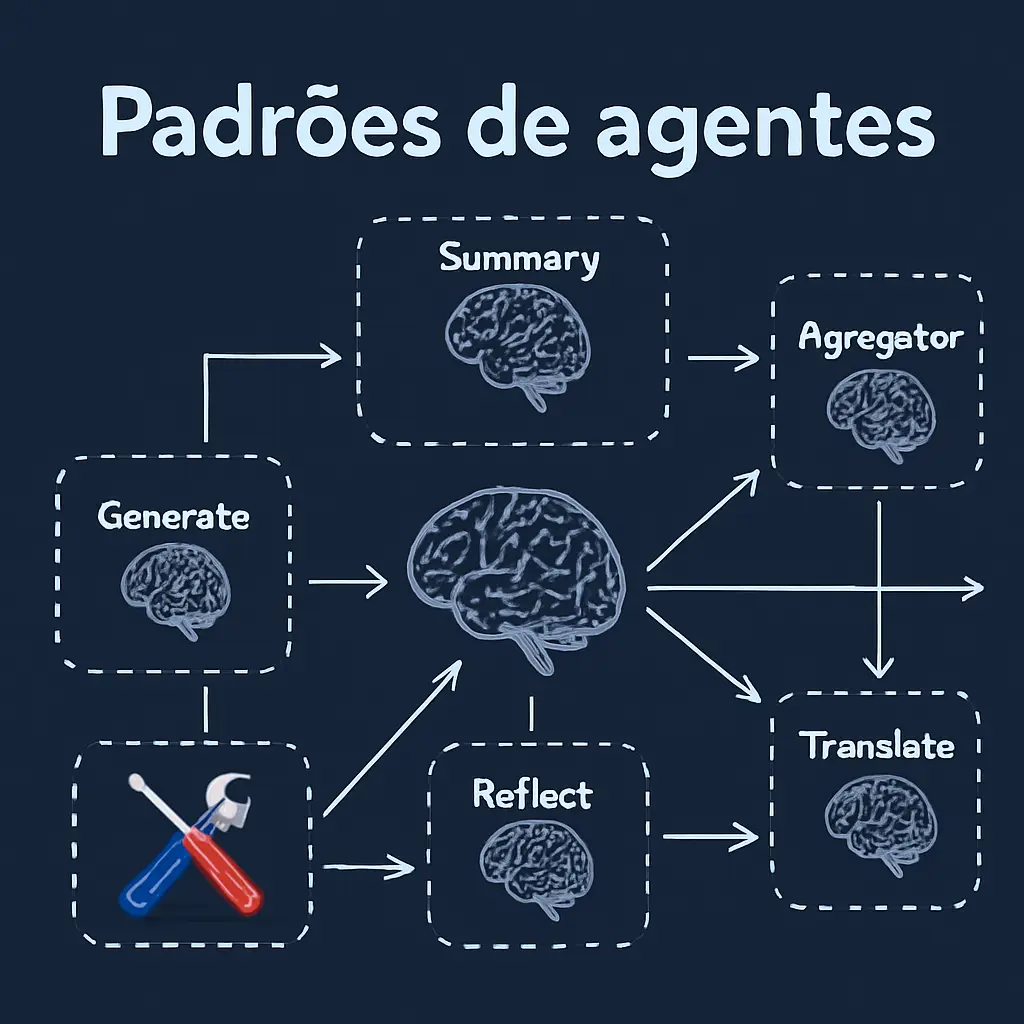
Seus agentes estão falhando? Eleve seus projetos de IA com padrões avançados: ReAct, planejamento, multi-agentes e mais. Guia prática com código!

🚀 ¡Revoluciona tus agentes de IA! 🧠 LangGraph não é apenas outra biblioteca, é o framework de orquestração que te dá o CONTROLE total para construir agentes complexos, com memória a longo prazo e até com intervenção humana! Se livre dos chatbots básicos, é hora de criar verdadeira inteligência. ¡Sumérgete em este post e descubra!

Aprenda a criar ambientes virtuais com uv, um gerenciador de pacotes e ambientes para Python escrito em Rust, o que o torna muito rápido. Se você teve problemas com os tempos de espera usando conda, ou quer uma alternativa mais rápida e fácil para venv, entre e veja como usar uv.





Os espaços do Hugging Face nos permitem executar modelos com demos muito simples, mas e se a demo quebrar? Ou se o usuário a deletar? Por isso, criei contêineres docker com alguns espaços interessantes, para poder usá-los localmente, aconteça o que acontecer. Na verdade, se você clicar em qualquer botão de visualização de projeto, ele pode levá-lo a um espaço que não funciona.






Dataset com piadas em inglês
Dataset com traduções de inglês para espanhol
Dataset com filmes e séries da Netflix









-thumbnail.webp)