FastRTC: A Biblioteca de Comunicação em Tempo Real para Python
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
Nos últimos meses, temos visto um grande avanço em modelos de voz em tempo real, com empresas inteiras fundadas ao redor de modelos tanto de código aberto quanto fechado. Alguns marcos importantes incluem:
OpenAIeGooglelançaram suas APIs multimodais ao vivo para ChatGPT e Gemini. ¡A OpenAI até lançou um número de telefone1-800-ChatGPT!Kyutailançou Moshi, um LLM de áudio para áudio totalmente de código aberto.Alibabalançou Qwen2-Audio, um LLM de código aberto que entende áudio de forma nativa.Fixie.ailançou Ultravox, outro LLM de código aberto que também entende áudio de forma nativa.ElevenLabsarrecadou 180 milhões de dólares na sua Série C.
Apesar desta explosão em modelos e financiamento, ainda é difícil construir aplicações de IA em tempo real que transmitam áudio e vídeo, especialmente em Python.
- Os engenheiros de ML podem não ter experiência com as tecnologias necessárias para construir aplicações em tempo real, como
WebRTC. - Mesmo ferramentas de assistência de código como
CursoreCopilottêm dificuldades em escrever código Python que suporte aplicações de áudio/vídeo em tempo real.
Por isso é empolgante o anúncio de FastRTC, a biblioteca de comunicação em tempo real para Python. A biblioteca foi projetada para facilitar a construção de aplicações de IA de áudio e vídeo em tempo real totalmente em Python!
Principais características de FastRTC
- 🗣️ Detecção de voz automática e gerenciamento de turnos integrado, para que você só precise se preocupar com a lógica de resposta ao usuário.
- 💻 UI automática - UI do Gradio habilitada para WebRTC integrada para testes (ou implantação em produção!).
- 📞 Chamada telefônica - Use
fastphone()para obter um número de telefone gratuito para ligar para o seu fluxo de áudio (é necessário um token HF). - ⚡️ Suporte para
WebRTCeWebsocket. - 💪 Personalizável - Você pode montar o stream em qualquer aplicação
FastAPIpara servir uma UI personalizada e implantar além doGradio. - 🧰 Muitas utilidades para
text-to-speech,speech-to-text,detecção de paradapara te ajudar a começar.
Instalação
Para poder usar FastRTC, primeiro você precisa instalar a biblioteca:
pip install fastrtcMas se quisermos instalar as funcionalidades de detecção de pausa, speech-to-text e text-to-speech, precisamos instalar algumas dependências adicionais:
pip install "fastrtc[vad, stt, tts]"Primeiros passos
Começaremos construindo o olá mundo do áudio em tempo real: fazer eco do que o usuário diz. Em FastRTC, isso é tão simples quanto:
from fastrtc import Stream, ReplyOnPauseimport numpy as npdef echo(audio: tuple[int, np.ndarray]) -> tuple[int, np.ndarray]:yield audiostream = Stream(ReplyOnPause(echo), modality="audio", mode="send-receive")stream.ui.launch()
* Running on local URL: http://127.0.0.1:7872To create a public link, set `share=True` in `launch()`.
Quando vamos ao link que o Gradio sugere, primeiro temos que dar permissões ao navegador para acessar o microfone. A seguir, aparecerá isto
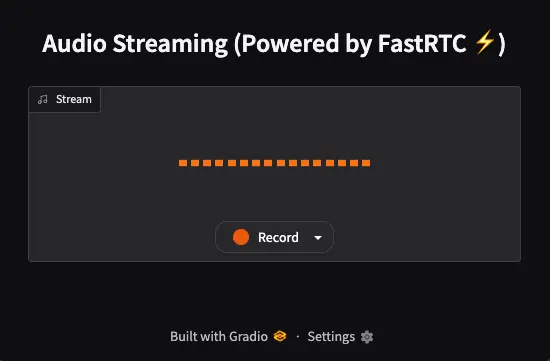
Se clicarmos na guia à direita da palavra Record, podemos selecionar o microfone que queremos usar.
Ao clicar no botão Record, tudo o que dissermos será repetido pelo aplicativo. Isso significa que ele captura o áudio, detecta quando paramos de falar e o repete.
Vamos a desmembrá-lo:
ReplyOnPauseirá tratar a detecção de voz e a passagem de turnos para você. Você só precisa se preocupar com a lógica para responder ao usuário. É necessário passar a função que será responsável por gerenciar o áudio de entrada. No nosso caso, é a funçãoecho, que captura o áudio de entrada e o retorna em stream usandoyield, que muitas pessoas não conhecem, mas é um gerador, ou seja, é um método do Python para criar iteradores. Se quiser saber mais sobreyield, pode ler meu post sobre Python. Qualquer gerador que retorne uma tupla de áudio (representada como(sample_rate, audio_data)) funcionará.- A classe
Streamconstruirá uma UI do Gradio para que você possa testar rapidamente seu stream. Uma vez que você tenha terminado de prototipar, você pode implantar seu Stream como um aplicativo FastAPI pronto para produção em uma única linha de código
Aqui podemos ver um exemplo dos criadores de FastRTC
Subindo de nível: Bate-papo de voz com LLM
O próximo nível é usar um LLM para responder ao usuário. FastRTC vem com capacidades de speech-to-text e text-to-speech incorporadas, portanto trabalhar com LLMs é realmente fácil. Vamos alterar nossa função echo accordingly:
from fastrtc import ReplyOnPause, Stream, get_stt_model, get_tts_modelfrom gradio_client import Clientclient = Client("Maximofn/SmolLM2_localModel")stt_model = get_stt_model()tts_model = get_tts_model()def echo(audio):prompt = stt_model.stt(audio)response = client.predict(message=prompt,system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")prompt = responsefor audio_chunk in tts_model.stream_tts_sync(prompt):yield audio_chunkstream = Stream(ReplyOnPause(echo), modality="audio", mode="send-receive")stream.ui.launch()
Loaded as API: https://maximofn-smollm2-localmodel.hf.space ✔* Running on local URL: http://127.0.0.1:7871To create a public link, set `share=True` in `launch()`.
Como modelo de speech-to-text use Moonshine, que supostamente só suporta inglês, mas eu o testei em espanhol e ele entende bem.
Como modelo de linguagem vamos usar o modelo que desployei em um backend no Hugging Face e que escrevi no post Desplegar backend com LLM em HuggingFace. Utiliza o LLM HuggingFaceTB/SmolLM2-1.7B-Instruct que é um modelo pequeno, já que está rodando em um backend com CPU, mas que funciona bastante bem.
Como modelo de text-to-speech use Kokoro que sim tem opções de falar em outros idiomas, mas que por enquanto na biblioteca FastRTC ainda não está implementado.
Se nos interessa muito usar modelos de speech-to-speech e text-to-speech em outros idiomas, poderíamos implementá-los nós mesmos, pois o maior potencial do FastRTC está na camada de comunicação em tempo real, mas não vou me aprofundar nisso agora.
Agora, se testarmos o código que acabamos de escrever, podemos ter um chatbot, por voz em tempo real.
Chamada telefônica
Geramos um script, pois nem sempre funciona em um Jupyter Notebook. %%writefile fastrtc_phone_demo.pyfrom fastrtc import ReplyOnPause, Stream, get_stt_model, get_tts_modelimport gradiofrom gradio_client import Clientimport osfrom gradio.networking import setup_tunnel as original_setup_tunnelimport socket# Monkey patch setup_tunnel para que acepte el parámetro adicionaldef patched_setup_tunnel(host, port, share_token, share_server_address, share_server_tls_certificate=None):return original_setup_tunnel(host, port, share_token, share_server_address, share_server_tls_certificate)# Replace the original function with our patched versiongradio.networking.setup_tunnel = patched_setup_tunnel# Get the token from the environment variableHUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN = os.getenv("HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN")# Initialize the LLM clientllm_client = Client("Maximofn/SmolLM2_localModel")# Initialize the STT and TTS modelsstt_model = get_stt_model()tts_model = get_tts_model()# Define the echo functiondef echo(audio):# Convert the audio to textprompt = stt_model.stt(audio)# Generate the responseresponse = llm_client.predict(message=prompt,system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")# Convert the response to audioprompt = response# Stream the audiofor audio_chunk in tts_model.stream_tts_sync(prompt):yield audio_chunkdef find_free_port(start_port=8000, max_port=9000):"""Find the first free port starting from start_port."""print(f"Searching for a free port starting from {start_port}...")for port in range(start_port, max_port):with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:result = sock.connect_ex(('127.0.0.1', port))if result != 0: # If result != 0, the port is freeprint(f"Free port found: {port}")return portraise RuntimeError(f"No free port found between {start_port} and {max_port}")free_port = find_free_port() # Search for a free portstream = Stream(ReplyOnPause(echo), modality="audio", mode="send-receive")stream.fastphone(token=HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN, port=free_port)
Explicamos o código
A parte
# Monkey patch setup_tunnel para que acepte el parámetro adicional
def patched_setup_tunnel(host, port, share_token, share_server_address, share_server_tls_certificate=None):
return original_setup_tunnel(host, port, share_token, share_server_address, share_server_tls_certificate)
# Replace the original function with our patched version
gradio.networking.setup_tunnel = patched_setup_tunnel
É necessário porque `FastRTC` foi escrito para uma versão antiga do `gradio` que não suporta o parâmetro `share_server_address` no método `setup_tunnel`. Então, nós o patcheamos para aceitar o parâmetro adicional.
Como é necessário um token do Hugging Face, obtemos o token da variável de ambiente HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN.
# Get the token from the environment variable
HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN = os.getenv("HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN")
A seguir são criados os modelos de linguagem, de speech-to-text e de text-to-speech, e criamos a função echo que será responsável por gerenciar o áudio de entrada e saída.
# Initialize the LLM client
llm_client = Client("Maximofn/SmolLM2_localModel")
# Initialize the STT and TTS models
stt_model = get_stt_model()
tts_model = get_tts_model()
# Define the echo function
def echo(audio):
# Convert the audio to text
prompt = stt_model.stt(audio)
# Generate the response
response = llm_client.predict(
message=prompt,
system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",
max_tokens=512,
temperature=0.7,
top_p=0.95,
api_name="/chat"
)
# Convert the response to audio
prompt = response
# Stream the audio
for audio_chunk in tts_model.stream_tts_sync(prompt):
yield audio_chunk
Como antes usamos a porta 8000, caso vocês digam que ela está ocupada, criamos uma função para encontrar uma porta livre e encontramos uma.
def find_free_port(start_port=8000, max_port=9000):
"""Find the first free port starting from start_port."""
print(f"Searching for a free port starting from {start_port}...")
for port in range(start_port, max_port):
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:
result = sock.connect_ex(('127.0.0.1', port))
if result != 0: # If result != 0, the port is free
print(f"Free port found: {port}")
return port
raise RuntimeError(f"No free port found between {start_port} and {max_port}")
free_port = find_free_port() # Search for a free port
O fluxo é criado e agora stream.fastphone() é usado para obter um número de telefone gratuito para ligar ao seu fluxo, em vez de stream.ui.launch(), que usamos anteriormente para criar a interface gráfica.
stream = Stream(ReplyOnPause(echo), modality="audio", mode="send-receive")
stream.fastphone(token=HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN, port=free_port)
Se o executarmos, veremos algo assim:
!python fastrtc_phone_demo.py
Loaded as API: https://maximofn-smollm2-localmodel.hf.space ✔INFO: Warming up STT model.INFO: STT model warmed up.INFO: Warming up VAD model.INFO: VAD model warmed up.Searching for a free port starting from 8000...Free port found: 8004INFO: Started server process [24029]INFO: Waiting for application startup.INFO: Visit https://fastrtc.org/userguide/api/ for WebRTC or Websocket API docs.INFO: Application startup complete.INFO: Uvicorn running on http://127.0.0.1:8004 (Press CTRL+C to quit)INFO: Your FastPhone is now live! Call +1 877-713-4471 and use code 994514 to connect to your stream.INFO: You have 30:00 minutes remaining in your quota (Resetting on 2025-04-07)INFO: Visit https://fastrtc.org/userguide/audio/#telephone-integration for information on making your handler compatible with phone usage.
Vemos que aparece
INFO: Seu FastPhone está agora ativo! Ligue para +1 877-713-4471 e use o código 994514 para se conectar ao seu stream.INFO: Você tem 30:00 minutos restantes em sua cota (Redefinindo em 2025-04-07)```
Isto é, se ligarmos para o número `+1 877-713-4471` e usarmos o código `994514`, seremos conectados ao nosso stream.
Se formos até Telephone Integration da documentação de FastRTC, veremos que usa twilio para fazer a chamada. Tem opção para configurar um número local nos Estados Unidos, Dublin, Frankfurt, Tóquio, Singapura, Sydney e São Paulo.
Tente testeado fazer a chamada da Espanha (o que vai me custar bastante) e funciona, mas é lento. Liguei, inseri o código e fiquei esperando para ser conectado com o agente, mas como estava demorando muito, desliguei.