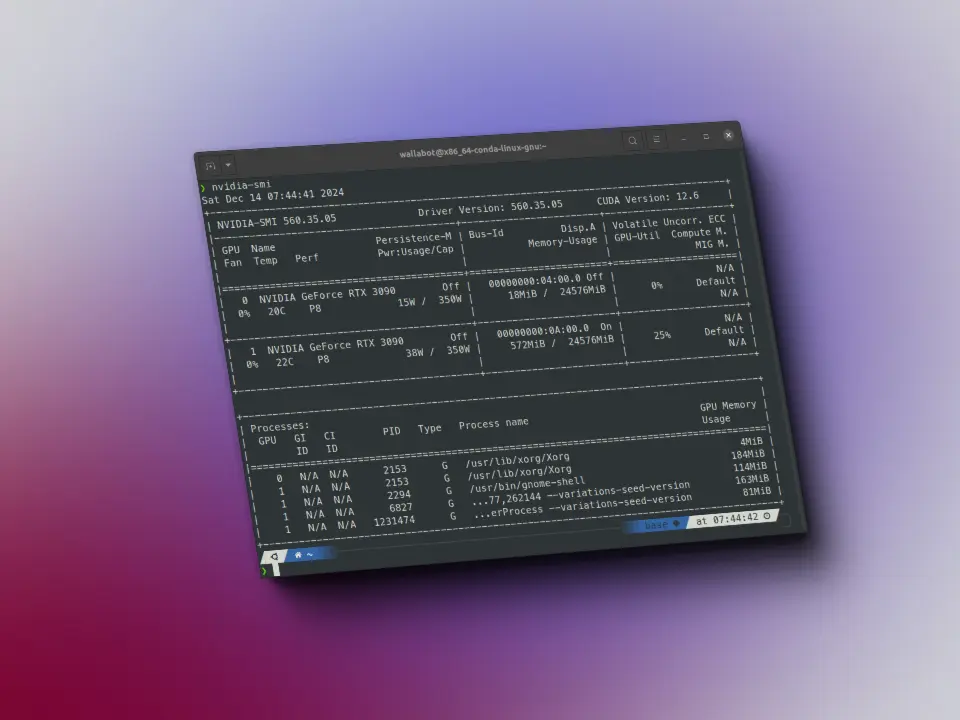
py-smi
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
Queres poder usar nvidia-smi desde Python? Aqui tens uma biblioteca para fazê-lo.
Instalação
Para poder instalá-la execute:
pip install python-smi
Uso
Importamos a biblioteca
InputPythonfrom py_smi import NVMLCopied
Criamos um objeto de pynvml (a biblioteca por trás de nvidia-smi)
InputPythonnv = NVML()Copied
Obtemos a versão do driver e do CUDA
InputPythonnv.driver_version, nv.cuda_versionCopied
('560.35.03', '12.6')
Como no meu caso tenho duas GPUs, crio uma variável com o número de GPUs
InputPythonnum_gpus = 2Copied
Obtenho a memória de cada GPU
InputPython[nv.mem(i) for i in range(num_gpus)]Copied
[_Memory(free=24136.6875, total=24576.0, used=439.3125),_Memory(free=23509.0, total=24576.0, used=1067.0)]
A utilização
InputPython[nv.utilization() for i in range(num_gpus)]Copied
[_Utilization(gpu=0, memory=0, enc=0, dec=0),_Utilization(gpu=0, memory=0, enc=0, dec=0)]
A potência usada
Isso me dá muito jeito, porque quando eu treinava um modelo e tinha as duas GPUs cheias, às vezes o meu computador desligava, e vendo a potência, vejo que a segunda consome muito, por isso pode ser o que eu já suspeitava, que era por alimentação.
InputPython[nv.power(i) for i in range(num_gpus)]Copied
[_Power(usage=15.382, limit=350.0), _Power(usage=40.573, limit=350.0)]
Os relógios de cada GPU
InputPython[nv.clocks(i) for i in range(num_gpus)]Copied
[_Clocks(graphics=0, sm=0, mem=405), _Clocks(graphics=540, sm=540, mem=810)]
Dados do PCI
InputPython[nv.pcie_throughput(i) for i in range(num_gpus)]Copied
[_PCIeThroughput(rx=0.0, tx=0.0),_PCIeThroughput(rx=0.1630859375, tx=0.0234375)]
E os processos (agora não estou executando nada)
InputPython[nv.processes(i) for i in range(num_gpus)]Copied
[[], []]

















