LangGraph
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
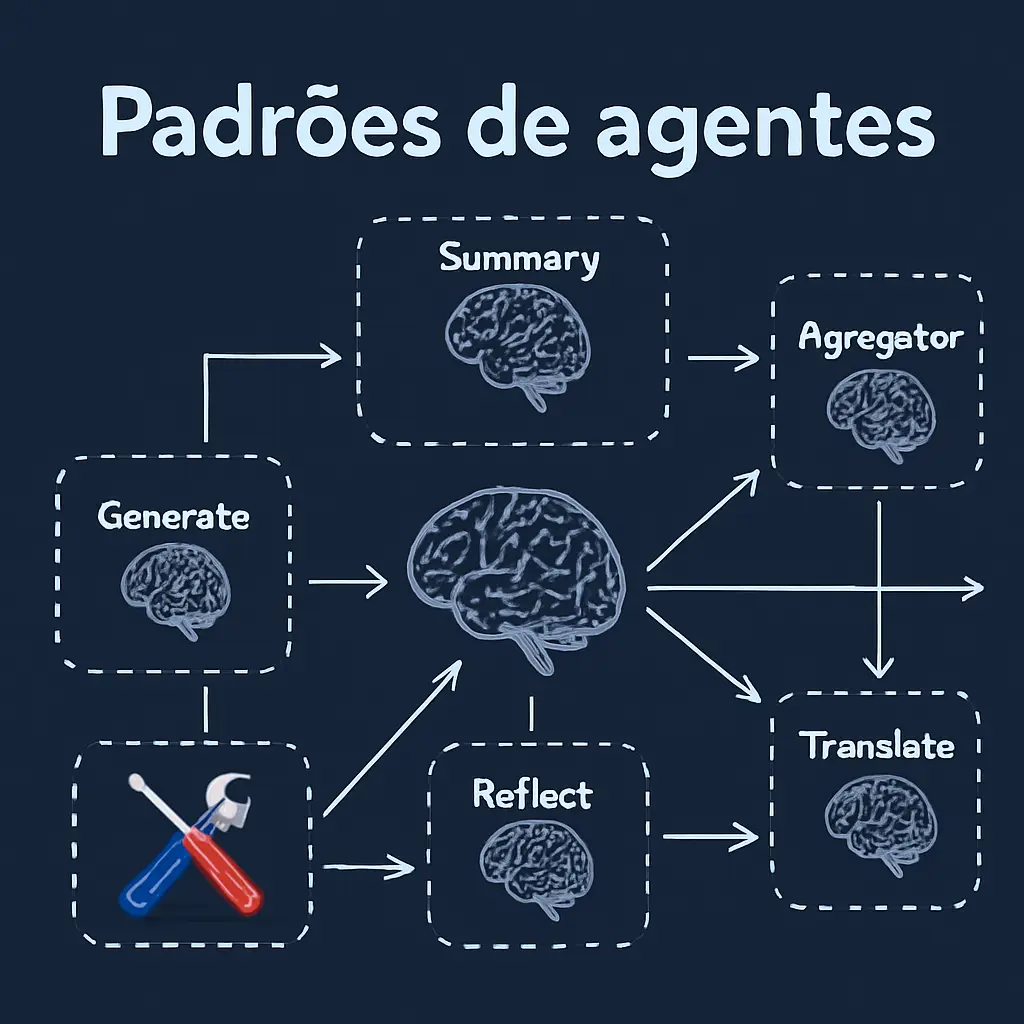
LangGraph é um framework de orquestração de baixo nível para construir agentes controláveis
Enquanto o LangChain fornece integrações e componentes para acelerar o desenvolvimento de aplicações LLM, a biblioteca LangGraph permite a orquestração de agentes, oferecendo arquiteturas personalizáveis, memória de longo prazo e human in the loop para lidar com tarefas complexas de forma confiável.
Neste post, vamos desabilitar o
LangSmith, que é uma ferramenta de depuração de grafos. Vamos desabilitá-lo para não adicionar mais complexidade ao post e nos concentrarmos apenas noLangGraph.
Como funciona LangGraph?
LangGraph baseia-se em três componentes:
- Nós: Representam as unidades de processamento da aplicação, como chamar um LLM ou uma ferramenta. São funções de Python que são executadas quando o nó é chamado.* Tomar o estado como entrada* Realizam alguma operação* Retornam o estado atualizado* Arestas: Representam as transições entre os nós. Definem a lógica de como o grafo será executado, ou seja, qual nó será executado após outro. Podem ser:* Diretos: Vão de um nó para outro* Condicional: Dependem de uma condição* Estado: Representa o estado da aplicação, ou seja, contém todas as informações necessárias para a aplicação. É mantido durante a execução da aplicação. É definido pelo usuário, então é preciso pensar muito bem no que será salvo nele.
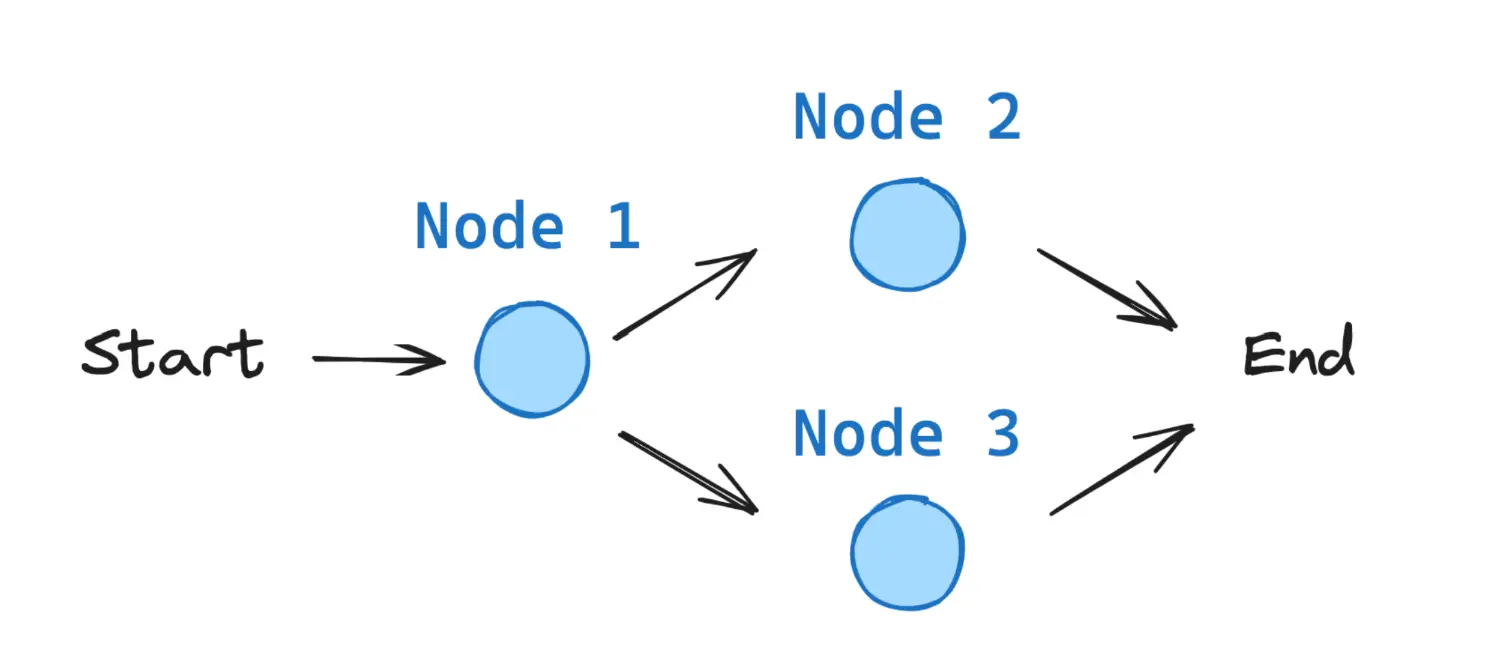
Todos os grafos de LangGraph começam a partir de um nó START e terminam em um nó END.
Instalação do LangGraph
Para instalar LangGraph pode-se usar pip:
pip install -U langgraph``` ou instalar a partir do Conda: ```bash conda install langgraph``` Instalação do módulo da Hugging Face e Anthropic
Vamos a usar um modelo de linguagem da Hugging Face, por isso precisamos instalar seu pacote de langgraph.
pip install langchain-huggingface``` Para uma parte vamos usar Sonnet 3.7, depois explicaremos por quê. Então também instalamos o pacote de Anthropic.
pip install langchain_anthropic``` CHAVE DE API do Hugging Face
Vamos a usar Qwen/Qwen2.5-72B-Instruct através de Hugging Face Inference Endpoints, por isso precisamos de uma API KEY.
Para poder usar o Inference Endpoints da HuggingFace, o primeiro que você precisa é ter uma conta na HuggingFace. Uma vez que você tenha, é necessário ir até Access tokens nas configurações do seu perfil e gerar um novo token.
Tem que dar um nome. No meu caso, vou chamá-lo de langgraph e ativar a permissão Make calls to inference providers. Isso criará um token que teremos que copiar.
Para gerenciar o token, vamos a criar um arquivo no mesmo caminho em que estamos trabalhando chamado .env e vamos colocar o token que copiamos no arquivo da seguinte maneira:
HUGGINGFACE_LANGGRAPH="hf_...."``` Agora, para poder obter o token, precisamos ter instalado dotenv, que instalamos através de
pip install python-dotenv``` Executamos o seguinte import osimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
Agora que temos um token, criamos um cliente. Para isso, precisamos ter a biblioteca huggingface_hub instalada. A instalamos através do conda ou pip.
pip install --upgrade huggingface_hub``` o ``` bash conda install -c conda-forge huggingface_hub``` Agora temos que escolher qual modelo vamos usar. Você pode ver os modelos disponíveis na página de Supported models da documentação de Inference Endpoints do Hugging Face.
Vamos a usar Qwen2.5-72B-Instruct que é um modelo muito bom.
MODEL = "Qwen/Qwen2.5-72B-Instruct"
Agora podemos criar o cliente
from huggingface_hub import InferenceClientclient = InferenceClient(api_key=HUGGINGFACE_TOKEN, model=MODEL)client
<InferenceClient(model='Qwen/Qwen2.5-72B-Instruct', timeout=None)>
Fazemos um teste para ver se funciona
message = [{opening_brace} "role": "user", "content": "Hola, qué tal?" {closing_brace}]stream = client.chat.completions.create(messages=message,temperature=0.5,max_tokens=1024,top_p=0.7,stream=False)response = stream.choices[0].message.contentprint(response)
¡Hola! Estoy bien, gracias por preguntar. ¿Cómo estás tú? ¿En qué puedo ayudarte hoy?
CHAVE DE API da Anthropic
Criar um chatbot básico
Vamos criar um chatbot simples usando LangGraph. Este chatbot responderá diretamente às mensagens do usuário. Embora seja simples, nos servirá para ver os conceitos básicos da construção de grafos com LangGraph.
Como o nome sugere, LangGraph é uma biblioteca para manipular grafos. Então, começamos criando um grafo StateGraph.
Um StateGraph define a estrutura do nosso chatbot como uma máquina de estados. Adicionaremos nós ao nosso grafo para representar os llms, tools e funções, os llms poderão fazer uso dessas tools e funções; e adicionamos arestas para especificar como o bot deve fazer a transição entre esses nós.
Então começamos criando um StateGraph que precisa de uma classe State para gerenciar o estado do grafo. Como agora vamos criar um chatbot simples, precisamos apenas gerenciar uma lista de mensagens no estado.
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraphfrom langgraph.graph.message import add_messagesclass State(TypedDict):# Messages have the type "list". The `add_messages` function# in the annotation defines how this state key should be updated# (in this case, it appends messages to the list, rather than overwriting them)messages: Annotated[list, add_messages]graph_builder = StateGraph(State)
A função add_messages une duas listas de mensagens.
Chegarão novas listas de mensagens, portanto, serão adicionadas à lista de mensagens já existente. Cada lista de mensagens contém um ID, portanto, são adicionadas com este ID. Isso garante que as mensagens sejam apenas adicionadas, não substituídas, a menos que uma nova mensagem tenha o mesmo ID que uma já existente, nesse caso, ela será substituída.
add_messages é uma função reducer, é uma função responsável por atualizar o estado.
O grafo graph_builder que criamos, recebe um estado State e retorna um novo estado State. Além disso, atualiza a lista de mensagens.
Conceito>> Ao definir um grafo, o primeiro passo é definir seu
State. OStateinclui o esquema do grafo e asreducer functionsque manipulam atualizações do estado.>> No nosso exemplo,Stateé do tipoTypedDict(dicionário tipado) com uma chave:messages.>>add_messagesé umafunção reducerque é usada para adicionar novas mensagens à lista em vez de sobrescrevê-las na lista. Se uma chave de um estado não tiver umafunção reducer, cada valor que chegar dessa chave sobrescreverá os valores anteriores.>>add_messagesé umafunção reducerdo langgraph, mas nós vamos poder criar as nossas
Agora vamos adicionar ao grafo o nó chatbot. Os nós representam unidades de trabalho. Geralmente, são funções regulares de Python.
Adicionamos um nó com o método add_node que recebe o nome do nó e a função que será executada.
Então vamos criar um LLM com HuggingFace, depois criaremos um modelo de chat com LangChain que fará referência ao LLM criado. Uma vez definido o modelo de chat, definimos a função que será executada no nó do nosso grafo. Essa função fará uma chamada ao modelo de chat criado e retornará o resultado.
Por último, vamos a adicionar um nó com a função do chatbot ao gráfico
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Define the chatbot functiondef chatbot_function(state: State):return {opening_brace}"messages": [llm.invoke(state["messages"])]}# The first argument is the unique node name# The second argument is the function or object that will be called whenever# the node is used.graph_builder.add_node("chatbot_node", chatbot_function)
<langgraph.graph.state.StateGraph at 0x130548440>
Nós usamos ChatHuggingFace que é um chat do tipo BaseChatModel que é um tipo de chat base de LangChain. Uma vez criado o BaseChatModel, nós criamos a função chatbot_function que será executada quando o nó for executado. E por último, criamos o nó chatbot_node e indicamos que ele deve executar a função chatbot_function.
Aviso>> A função de nó
chatbot_functionrecebe o estadoStatecomo entrada e retorna um dicionário que contém uma atualização da listamessagespara a chavemensagens. Este é o padrão básico para todas as funções do nóLangGraph.
A função reducer do nosso grafo add_messages adicionará as mensagens de resposta do llm a qualquer mensagem que já esteja no estado.
A seguir, adicionamos um nó entry. Isso diz ao nosso grafo onde começar seu trabalho sempre que o executamos.
from langgraph.graph import STARTgraph_builder.add_edge(START, "chatbot_node")
<langgraph.graph.state.StateGraph at 0x130548440>
Da mesma forma, adicionamos um nó finish. Isso indica ao grafo cada vez que esse nó é executado, ele pode finalizar o trabalho.
from langgraph.graph import ENDgraph_builder.add_edge("chatbot_node", END)
<langgraph.graph.state.StateGraph at 0x130548440>
Importamos START e END, que podem ser encontrados em constants, e são o primeiro e o último nó do nosso grafo.
Normalmente são nós virtuais
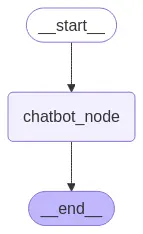
Finalmente, temos que compilar nosso grafo. Para fazer isso, usamos o método construtor de grafos compile(). Isso cria um CompiledGraph que podemos usar para executar nossa aplicação.
graph = graph_builder.compile()
Podemos visualizar o grafo usando o método get_graph e um dos métodos de "desenho", como draw_ascii ou draw_mermaid_png. O desenho de cada um dos métodos requerir dependências adicionais.
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(f"Error al visualizar el grafo: {e}")
Agora podemos testar o chatbot!
Dica>> No bloco de código seguinte, você pode sair do loop de bate-papo a qualquer momento digitando
quit,exitouq.
# Colors for the terminalCOLOR_GREEN = "\033[32m"COLOR_YELLOW = "\033[33m"COLOR_RESET = "\033[0m"def stream_graph_updates(user_input: str):for event in graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace}):for value in event.values():print(f"{opening_brace}COLOR_GREEN{closing_brace}User: {opening_brace}COLOR_RESET{closing_brace}{opening_brace}user_input{closing_brace}")print(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}{opening_brace}value['messages'][-1].content{closing_brace}")while True:try:user_input = input("User: ")if user_input.lower() in ["quit", "exit", "q"]:print(f"{opening_brace}COLOR_GREEN{closing_brace}User: {opening_brace}COLOR_RESET{closing_brace}{opening_brace}user_input{closing_brace}")print(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}Goodbye!")breakevents =stream_graph_updates(user_input)except:# fallback if input() is not availableuser_input = "What do you know about LangGraph?"print("User: " + user_input)stream_graph_updates(user_input)break
User: HelloAssistant: Hello! It's nice to meet you. How can I assist you today? Whether you have questions, need information, or just want to chat, I'm here to help!User: How are you doing?Assistant: I'm just a computer program, so I don't have feelings, but I'm here and ready to help you with any questions or tasks you have! How can I assist you today?User: Me well, I'm making a post about LangGraph, what do you think?Assistant: LangGraph is an intriguing topic, especially if you're delving into the realm of graph-based models and their applications in natural language processing (NLP). LangGraph, as I understand, is a framework or tool that leverages graph theory to improve or provide a new perspective on NLP tasks such as text classification, information extraction, and semantic analysis. By representing textual information as graphs (nodes for entities and edges for relationships), it can offer a more nuanced understanding of the context and semantics in language data.If you're making a post about it, here are a few points you might consider:1. **Introduction to LangGraph**: Start with a brief explanation of what LangGraph is and its core principles. How does it model language or text differently compared to traditional NLP approaches? What unique advantages does it offer by using graph-based methods?2. **Applications of LangGraph**: Discuss some of the key applications where LangGraph has been or can be applied. This could include improving the accuracy of sentiment analysis, enhancing machine translation, or optimizing chatbot responses to be more contextually aware.3. **Technical Innovations**: Highlight any technical innovations or advancements that LangGraph brings to the table. This could be about new algorithms, more efficient data structures, or novel ways of training models on graph data.4. **Challenges and Limitations**: It's also important to address the challenges and limitations of using graph-based methods in NLP. Performance, scalability, and the current state of the technology can be discussed here.5. **Future Prospects**: Wrap up with a look into the future of LangGraph and graph-based NLP in general. What are the upcoming trends, potential areas of growth, and how might these tools start impacting broader technology landscapes?Each section can help frame your post in a way that's informative and engaging for your audience, whether they're technical experts or casual readers looking for an introduction to this intriguing area of NLP.User: qAssistant: Goodbye!
!Parabéns! Você construiu seu primeiro chatbot usando LangGraph. Este bot pode participar de uma conversa básica, recebendo a entrada do usuário e gerando respostas utilizando o LLM que definimos.
Antes fomos escrevendo o código aos poucos e pode ser que não tenha ficado muito claro. Foi feito assim para explicar cada parte do código, mas agora vamos reescrevê-lo, mas organizado de outra forma, que fica mais claro à vista. Ou seja, agora que não precisamos explicar cada parte do código, o agrupamos de outra maneira para que seja mais claro.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from huggingface_hub import login
from IPython.display import Image, display
import os
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
import dotenv
dotenv.load_dotenv()
HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
# State
class State(TypedDict):
messages: Annotated[list, add_messages]
# Create the LLM model
login(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the model
MODEL = "Qwen/Qwen2.5-72B-Instruct"
model = HuggingFaceEndpoint(
repo_id=MODEL,
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
# Create the chat model
llm = ChatHuggingFace(llm=model)
# Function
def chatbot_function(state: State):
return {"messages": [llm.invoke(state["messages"])]}
# Start to build the graph
graph_builder = StateGraph(State)
# Add nodes to the graph
graph_builder.add_node("chatbot_node", chatbot_function)
# Add edges
graph_builder.add_edge(START, "chatbot_node")
graph_builder.add_edge("chatbot_node", END)
# Compile the graph
graph = graph_builder.compile()
# Display the graph
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(f"Error al visualizar el grafo: {e}")
Mais
Todos os blocos mais estão lá se você quiser aprofundar mais em LangGraph, se não, pode ler tudo sem ler os blocos mais
Tipagem do estado
Vimos como criar um agente com um estado tipado usando TypedDict, mas podemos criá-lo com outro tipo tipado.
Tipagem através de TypeDict
É a forma que vimos anteriormente, tipamos o estado como um dicionário usando o tipado de Python TypeDict. Passamos uma chave e um valor para cada variável do nosso estado.
from typing_extensions import TypedDictfrom typing import Anotadofrom langgraph.graph.message import adicionar_mensagensfrom langgraph.graph import StateGraph class Estado(TypedDict):mensagens: Anotado[list, add_mensagens]``` Para acessar as mensagens, fazemos isso como com qualquer dicionário, através de state["messages"]
Tipagem com dataclass
Outra opção é usar o tipado de python dataclass
from dataclasses import dataclassfrom typing import Anotadofrom langgraph.graph.message import add_messagesfrom langgraph.graph import StateGraph @dataclassclass Estado:mensagens: Anotado[list, adicionar_mensagens]``` Como pode ser visto, é semelhante ao tipagem por meio de dicionários, mas agora, sendo o estado uma classe, acessamos as mensagens através de state.messages
Tipagem com Pydantic
Pydantic é uma biblioteca muito usada para tipar dados em Python. Nos oferece a possibilidade de adicionar uma verificação do tipado. Vamos verificar que a mensagem comece com 'User', 'Assistant' ou 'System'.
from pydantic import BaseModel, field_validator, ValidationErrorfrom typing import Anotadofrom langgraph.graph.message import adicionar_mensagens class Estado(BaseModel):mensagens: Anotado[list, add_messages] # Deve começar com 'Usuário', 'Assistente' ou 'Sistema' @field_validator('mensagens')@classmethoddef validate_messages(cls, value):# Garanta que as mensagens comecem com `User`, `Assistant` ou `System`Se não value.startswith["'User'"] e não value.startswith["'Assistant'"] e não value.startswith["'System'"]:raise ValueError("A mensagem deve começar com 'User', 'Assistant' ou 'System'")valor de retorno tente:state = PydanticState(messages=["Olá"])except ValidationError as e:print("Erro de Validação:", e)``` Redutores
Como dissemos, precisamos usar uma função do tipo Reducer para indicar como atualizar o estado, pois se não os valores do estado serão sobrescritos.
Vamos ver um exemplo de um grafo no qual não usamos uma função do tipo Reducer para indicar como atualizar o estado
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
class State(TypedDict):
foo: int
def node_1(state):
print("---Node 1---")
return {"foo": state['foo'] + 1}
def node_2(state):
print("---Node 2---")
return {"foo": state['foo'] + 1}
def node_3(state):
print("---Node 3---")
return {"foo": state['foo'] + 1}
# Build graph
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# Logic
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_1", "node_3")
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# Add
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
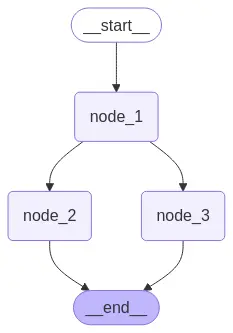
Como podemos ver, definimos um grafo no qual o nó 1 é executado primeiro e depois os nós 2 e 3. Vamos executá-lo para ver o que acontece.
from langgraph.errors import InvalidUpdateErrortry:graph.invoke({"foo" : 1})except InvalidUpdateError as e:print(f"InvalidUpdateError occurred: {e}")
---Node 1------Node 2------Node 3---InvalidUpdateError occurred: At key 'foo': Can receive only one value per step. Use an Annotated key to handle multiple values.For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/INVALID_CONCURRENT_GRAPH_UPDATE
Obtemos um erro porque primeiro o nó 1 modifica o valor de foo e depois os nós 2 e 3 tentam modificar o valor de foo em paralelo, o que dá um erro.
Então, para evitar isso, usamos uma função do tipo Reducer para indicar como modificar o estado.
Redutores pré-definidos
Usamos o tipo Annotated para especificar que é uma função do tipo Reducer. E usamos o operador add para adicionar um valor a uma lista.
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
from operator import add
from typing import Annotated
class State(TypedDict):
foo: Annotated[list[int], add]
def node_1(state):
print("---Node 1---")
return {"foo": [state['foo'][-1] + 1]}
def node_2(state):
print("---Node 2---")
return {"foo": [state['foo'][-1] + 1]}
def node_3(state):
print("---Node 3---")
return {"foo": [state['foo'][-1] + 1]}
# Build graph
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# Logic
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_1", "node_3")
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# Add
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
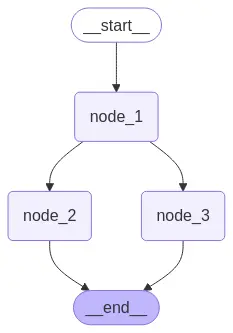
Executamos novamente para ver o que acontece
graph.invoke({"foo" : [1]})
Como vemos inicializamos o valor de foo a 1, o qual se adiciona em uma lista. Depois o nó 1 soma 1 e o adiciona como novo valor na lista, ou seja, adiciona um 2. Por fim os nós 2 e 3 somam um ao último valor da lista, ou seja, os dois nós obtêm um 3 e ambos o adicionam no final da lista, por isso a lista resultante tem dois 3 no final
Vamos a ver o caso de que uma branch tenha mais nós que outra
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
from operator import add
from typing import Annotated
class State(TypedDict):
foo: Annotated[list[int], add]
def node_1(state):
print("---Node 1---")
return {"foo": [state['foo'][-1] + 1]}
def node_2_1(state):
print("---Node 2_1---")
return {"foo": [state['foo'][-1] + 1]}
def node_2_2(state):
print("---Node 2_2---")
return {"foo": [state['foo'][-1] + 1]}
def node_3(state):
print("---Node 3---")
return {"foo": [state['foo'][-1] + 1]}
# Build graph
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_node("node_2_1", node_2_1)
builder.add_node("node_2_2", node_2_2)
builder.add_node("node_3", node_3)
# Logic
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2_1")
builder.add_edge("node_1", "node_3")
builder.add_edge("node_2_1", "node_2_2")
builder.add_edge("node_2_2", END)
builder.add_edge("node_3", END)
# Add
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
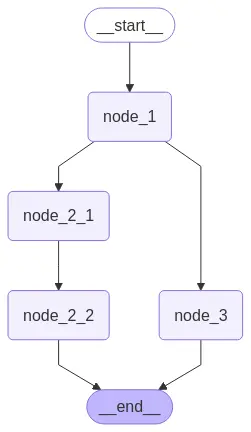
Se agora executarmos o grafo
graph.invoke({"foo" : [1]})
O que aconteceu é que primeiro foi executado o nó 1, em seguida o nó 2_1, depois, em paralelo, os nós 2_2 e 3, e finalmente o nó END
Como definimos foo como uma lista de inteiros, e está tipada, se inicializarmos o estado com None obtemos um erro
try:graph.invoke({"foo" : None})except TypeError as e:print(f"TypeError occurred: {e}")
TypeError occurred: can only concatenate list (not "NoneType") to list
Vamos a ver como arrumar isso com reducidores personalizados
Redutores personalizados
Às vezes não podemos usar um Reducer pré-definido e temos que criar o nosso próprio.
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
from typing import Annotated
def reducer_function(current_list, new_item: list | None):
if current_list is None:
current_list = []
if new_item is not None:
return current_list + new_item
return current_list
class State(TypedDict):
foo: Annotated[list[int], reducer_function]
def node_1(state):
print("---Node 1---")
if len(state['foo']) == 0:
return {'foo': [0]}
return {"foo": [state['foo'][-1] + 1]}
def node_2(state):
print("---Node 2---")
return {"foo": [state['foo'][-1] + 1]}
def node_3(state):
print("---Node 3---")
return {"foo": [state['foo'][-1] + 1]}
# Build graph
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# Logic
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_1", "node_3")
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# Add
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
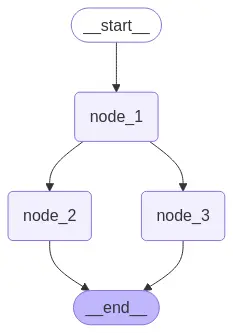
Se agora inicializarmos o grafo com um valor None, não recebemos mais um erro.
try:graph.invoke({"foo" : None})except TypeError as e:print(f"TypeError occurred: {e}")
---Node 1------Node 2------Node 3---
Múltiplos estados
Estados privados
Suponhamos que queremos ocultar variáveis de estado, pela razão que seja, porque algumas variáveis só trazem ruído ou porque queremos manter alguma variável privada.
Se quisermos ter um estado privado, simplesmente o criamos.
from typing_extensions import TypedDict
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
class OverallState(TypedDict):
public_var: int
class PrivateState(TypedDict):
private_var: int
def node_1(state: OverallState) -> PrivateState:
print("---Node 1---")
return {"private_var": state['public_var'] + 1}
def node_2(state: PrivateState) -> OverallState:
print("---Node 2---")
return {"public_var": state['private_var'] + 1}
# Build graph
builder = StateGraph(OverallState)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
# Logic
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_2", END)
# Add
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
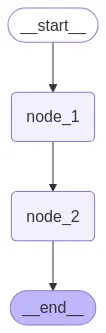
Como vemos, criamos o estado privado PrivateState e o estado público OverallState. Cada um com uma variável privada e uma pública. Primeiro é executado o nó 1, que modifica a variável privada e a retorna. Em seguida, é executado o nó 2, que modifica a variável pública e a retorna. Vamos executar o grafo para ver o que acontece.
graph.invoke({"public_var" : 1})
Como vemos ao executar o grafo, passamos a variável pública public_var e obtemos na saída outra variável pública public_var com o valor modificado, mas nunca se acessou a variável privada private_var.
Estados de entrada e saída
Podemos definir as variáveis de entrada e saída do grafo. Embora internamente o estado possa ter mais variáveis, definimos quais variáveis são de entrada para o grafo e quais variáveis são de saída.
from typing_extensions import TypedDict
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
class InputState(TypedDict):
question: str
class OutputState(TypedDict):
answer: str
class OverallState(TypedDict):
question: str
answer: str
notes: str
def thinking_node(state: InputState):
return {"answer": "bye", "notes": "... his is name is Lance"}
def answer_node(state: OverallState) -> OutputState:
return {"answer": "bye Lance"}
graph = StateGraph(OverallState, input=InputState, output=OutputState)
graph.add_node("answer_node", answer_node)
graph.add_node("thinking_node", thinking_node)
graph.add_edge(START, "thinking_node")
graph.add_edge("thinking_node", "answer_node")
graph.add_edge("answer_node", END)
graph = graph.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
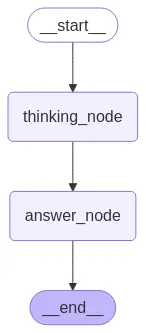
Neste caso, o estado tem 3 variáveis: question, answer e notes. No entanto, definimos como entrada do grafo question e como saída do grafo answer. Portanto, o estado interno pode ter mais variáveis, mas elas não são consideradas na hora de invocar o grafo. Vamos executar o grafo para ver o que acontece.
graph.invoke({"question":"hi"})
{'answer': 'bye Lance'}
Como vemos, adicionamos question ao grafo e obtivemos answer na saída.
Gerenciamento do contexto
Vamos a revisar novamente o código do chatbot básico
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from huggingface_hub import login
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Create the LLM model
login(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the model
MODEL = "Qwen/Qwen2.5-72B-Instruct"
model = HuggingFaceEndpoint(
repo_id=MODEL,
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
# Create the chat model
llm = ChatHuggingFace(llm=model)
# Define the chatbot function
def chatbot_function(state: State):
return {"messages": [llm.invoke(state["messages"])]}
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("chatbot_node", chatbot_function)
# Connect nodes
graph_builder.add_edge(START, "chatbot_node")
graph_builder.add_edge("chatbot_node", END)
# Compile the graph
graph = graph_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
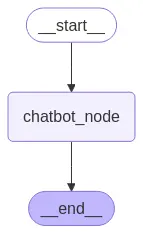
Vamos a criar um contexto que passaremos ao modelo
from langchain_core.messages import AIMessage, HumanMessagemessages = [AIMessage(f"So you said you were researching ocean mammals?", name="Bot")]messages.append(HumanMessage(f"Yes, I know about whales. But what others should I learn about?", name="Lance"))for m in messages:m.pretty_print()
================================== Ai Message ==================================Name: BotSo you said you were researching ocean mammals?================================ Human Message =================================Name: LanceYes, I know about whales. But what others should I learn about?
Se passarmos para o grafo, obteremos a saída
output = graph.invoke({'messages': messages})for m in output['messages']:m.pretty_print()
================================== Ai Message ==================================Name: BotSo you said you were researching ocean mammals?================================ Human Message =================================Name: LanceYes, I know about whales. But what others should I learn about?================================== Ai Message ==================================That's a great topic! Besides whales, there are several other fascinating ocean mammals you might want to learn about. Here are a few:1. **Dolphins**: Highly intelligent and social, dolphins are found in all oceans of the world. They are known for their playful behavior and communication skills.2. **Porpoises**: Similar to dolphins but generally smaller and stouter, porpoises are less social and more elusive. They are found in coastal waters around the world.3. **Seals and Sea Lions**: These are semi-aquatic mammals that can be found in both Arctic and Antarctic regions, as well as in more temperate waters. They are known for their sleek bodies and flippers, and they differ in their ability to walk on land (sea lions can "walk" on their flippers, while seals can only wriggle or slide).4. **Walruses**: Known for their large tusks and whiskers, walruses are found in the Arctic. They are well-adapted to cold waters and have a thick layer of blubber to keep them warm.5. **Manatees and Dugongs**: These gentle, herbivorous mammals are often called "sea cows." They live in shallow, coastal areas and are found in tropical and subtropical regions. Manatees are found in the Americas, while dugongs are found in the Indo-Pacific region.6. **Otters**: While not fully aquatic, sea otters spend most of their lives in the water and are excellent swimmers. They are known for their dense fur, which keeps them warm in cold waters.7. **Polar Bears**: Although primarily considered land animals, polar bears are excellent swimmers and spend a significant amount of time in the water, especially when hunting for seals.Each of these mammals has unique adaptations and behaviors that make them incredibly interesting to study. If you have any specific questions or topics you'd like to explore further, feel free to ask!
Como vemos agora na saída temos uma mensagem adicional. Se isso continuar crescendo, chegará um momento em que teremos um contexto muito longo, o que representará um maior gasto de tokens, podendo resultar em um maior custo econômico e também maior latência. Além disso, com contextos muito longos, os LLMs começam a performar pior. Nos últimos modelos, à data da escrita deste post, acima de 8k tokens de contexto, começa a decrescer o desempenho do LLM
Então vamos ver várias maneiras de gerenciar isso
Modificar o contexto com funções do tipo Reducer
Vimos que com as funções do tipo Reducer podemos modificar as mensagens do estado
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from langchain_core.messages import RemoveMessage
from huggingface_hub import login
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Create the LLM model
login(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the model
MODEL = "Qwen/Qwen2.5-72B-Instruct"
model = HuggingFaceEndpoint(
repo_id=MODEL,
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
# Create the chat model
llm = ChatHuggingFace(llm=model)
# Nodes
def filter_messages(state: State):
# Delete all but the 2 most recent messages
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
return {"messages": delete_messages}
def chat_model_node(state: State):
return {"messages": [llm.invoke(state["messages"])]}
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("filter_messages_node", filter_messages)
graph_builder.add_node("chatbot_node", chat_model_node)
# Connecto nodes
graph_builder.add_edge(START, "filter_messages_node")
graph_builder.add_edge("filter_messages_node", "chatbot_node")
graph_builder.add_edge("chatbot_node", END)
# Compile the graph
graph = graph_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
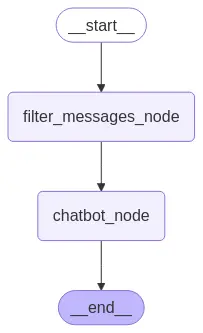
Como vemos no grafo, primeiro filtramos as mensagens e depois passamos o resultado ao modelo.
Voltamos a criar um contexto que passaremos ao modelo, mas agora com mais mensagens
from langchain_core.messages import AIMessage, HumanMessagemessages = [AIMessage(f"So you said you were researching ocean mammals?", name="Bot")]messages.append(HumanMessage(f"Yes, I know about whales. But what others should I learn about?", name="Lance"))messages.append(AIMessage(f"I know about sharks too", name="Bot"))messages.append(HumanMessage(f"What others should I learn about?", name="Lance"))messages.append(AIMessage(f"I know about dolphins too", name="Bot"))messages.append(HumanMessage(f"Tell me more about dolphins", name="Lance"))for m in messages:m.pretty_print()
================================== Ai Message ==================================Name: BotSo you said you were researching ocean mammals?================================ Human Message =================================Name: LanceYes, I know about whales. But what others should I learn about?================================== Ai Message ==================================Name: BotI know about sharks too================================ Human Message =================================Name: LanceWhat others should I learn about?================================== Ai Message ==================================Name: BotI know about dolphins too================================ Human Message =================================Name: LanceTell me more about dolphins
Se passarmos para o grafo, obteremos a saída
output = graph.invoke({'messages': messages})for m in output['messages']:m.pretty_print()
================================== Ai Message ==================================Name: BotI know about dolphins too================================ Human Message =================================Name: LanceTell me more about dolphins================================== Ai Message ==================================Dolphins are highly intelligent marine mammals that are part of the family Delphinidae, which includes about 40 species. They are found in oceans worldwide, from tropical to temperate regions, and are known for their agility and playful behavior. Here are some interesting facts about dolphins:1. **Social Behavior**: Dolphins are highly social animals and often live in groups called pods, which can range from a few individuals to several hundred. Social interactions are complex and include cooperative behaviors, such as hunting and defending against predators.2. **Communication**: Dolphins communicate using a variety of sounds, including clicks, whistles, and body language. These sounds can be used for navigation (echolocation), communication, and social bonding. Each dolphin has a unique signature whistle that helps identify it to others in the pod.3. **Intelligence**: Dolphins are considered one of the most intelligent animals on Earth. They have large brains and display behaviors such as problem-solving, mimicry, and even the use of tools. Some studies suggest that dolphins can recognize themselves in mirrors, indicating a level of self-awareness.4. **Diet**: Dolphins are carnivores and primarily feed on fish and squid. They use echolocation to locate and catch their prey. Some species, like the bottlenose dolphin, have been observed using teamwork to herd fish into tight groups, making them easier to catch.5. **Reproduction**: Dolphins typically give birth to a single calf after a gestation period of about 10 to 12 months. Calves are born tail-first and are immediately helped to the surface for their first breath by their mother or another dolphin. Calves nurse for up to two years and remain dependent on their mothers for a significant period.6. **Conservation**: Many dolphin species are threatened by human activities such as pollution, overfishing, and habitat destruction. Some species, like the Indo-Pacific humpback dolphin and the Amazon river dolphin, are endangered. Conservation efforts are crucial to protect these animals and their habitats.7. **Human Interaction**: Dolphins have a long history of interaction with humans, often appearing in mythology and literature. In some cultures, they are considered sacred or bring good luck. Today, dolphins are popular in marine parks and are often the focus of eco-tourism activities, such as dolphin-watching tours.Dolphins continue to fascinate scientists and the general public alike, with ongoing research into their behavior, communication, and social structures providing new insights into these remarkable creatures.
Como se pode ver, a função de filtragem removeu todas as mensagens, exceto as duas últimas, e essas duas mensagens foram passadas como contexto para o LLM.
Cortar mensagens
Outra solução é recortar cada mensagem da lista de mensagens que tenham muitos tokens, estabelece-se um limite de tokens e elimina-se a mensagem que ultrapassa esse limite.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from langchain_core.messages import trim_messages
from huggingface_hub import login
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Create the LLM model
login(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the model
MODEL = "Qwen/Qwen2.5-72B-Instruct"
model = HuggingFaceEndpoint(
repo_id=MODEL,
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
# Create the chat model
llm = ChatHuggingFace(llm=model)
# Nodes
def trim_messages_node(state: State):
# Trim the messages based on the specified parameters
trimmed_messages = trim_messages(
state["messages"],
max_tokens=100, # Maximum tokens allowed in the trimmed list
strategy="last", # Keep the latest messages
token_counter=llm, # Use the LLM's tokenizer to count tokens
allow_partial=True, # Allow cutting messages mid-way if needed
)
# Print the trimmed messages to see the effect of trim_messages
print("--- trimmed messages (input to LLM) ---")
for m in trimmed_messages:
m.pretty_print()
print("------------------------------------------------")
# Invoke the LLM with the trimmed messages
response = llm.invoke(trimmed_messages)
# Return the LLM's response in the correct state format
return {"messages": [response]}
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("trim_messages_node", trim_messages_node)
# Connecto nodes
graph_builder.add_edge(START, "trim_messages_node")
graph_builder.add_edge("trim_messages_node", END)
# Compile the graph
graph = graph_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
Como vemos no grafo, primeiro filtramos as mensagens e depois passamos o resultado ao modelo.
Voltamos a criar um contexto que passaremos ao modelo, mas agora com mais mensagens
from langchain_core.messages import AIMessage, HumanMessagemessages = [AIMessage(f"So you said you were researching ocean mammals?", name="Bot")]messages.append(HumanMessage(f"Yes, I know about whales. But what others should I learn about?", name="Lance"))messages.append(AIMessage(f"""I know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.""", name="Bot"))messages.append(HumanMessage(f"What others should I learn about?", name="Lance"))messages.append(AIMessage(f"I know about dolphins too", name="Bot"))messages.append(HumanMessage(f"Tell me more about dolphins", name="Lance"))for m in messages:m.pretty_print()
================================== Ai Message ==================================Name: BotSo you said you were researching ocean mammals?================================ Human Message =================================Name: LanceYes, I know about whales. But what others should I learn about?================================== Ai Message ==================================Name: BotI know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.================================ Human Message =================================Name: LanceWhat others should I learn about?================================== Ai Message ==================================Name: BotI know about dolphins too================================ Human Message =================================Name: LanceTell me more about dolphins
Se passarmos ao grafo, obteremos a saída
output = graph.invoke({'messages': messages})
--- trimmed messages (input to LLM) ---================================== Ai Message ==================================Name: BotThe tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.================================ Human Message =================================Name: LanceWhat others should I learn about?================================== Ai Message ==================================Name: BotI know about dolphins too================================ Human Message =================================Name: LanceTell me more about dolphins------------------------------------------------
Como pode ser visto, o contexto fornecido ao LLM foi truncado. A mensagem, que era muito longa e continha muitos tokens, foi reduzida. Vamos observar a saída do LLM.
for m in output['messages']:m.pretty_print()
================================== Ai Message ==================================Name: BotSo you said you were researching ocean mammals?================================ Human Message =================================Name: LanceYes, I know about whales. But what others should I learn about?================================== Ai Message ==================================Name: BotI know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.================================ Human Message =================================Name: LanceWhat others should I learn about?================================== Ai Message ==================================Name: BotI know about dolphins too================================ Human Message =================================Name: LanceTell me more about dolphins================================== Ai Message ==================================Certainly! Dolphins are intelligent marine mammals that are part of the family Delphinidae, which includes nearly 40 species. Here are some interesting facts about dolphins:1. **Intelligence**: Dolphins are known for their high intelligence and have large brains relative to their body size. They exhibit behaviors that suggest social complexity, self-awareness, and problem-solving skills. For example, they can recognize themselves in mirrors, a trait shared by only a few other species.2. **Communication**: Dolphins communicate using a variety of clicks, whistles, and body language. Each dolphin has a unique "signature whistle" that helps identify it to others, similar to a human name. They use echolocation to navigate and locate prey by emitting clicks and interpreting the echoes that bounce back.3. **Social Structure**: Dolphins are highly social animals and often live in groups called pods. These pods can vary in size from a few individuals to several hundred. Within these groups, dolphins form complex social relationships and often cooperate to hunt and protect each other from predators.4. **Habitat**: Dolphins are found in all the world's oceans and in some rivers. Different species have adapted to various environments, from tropical waters to the cooler regions of the open sea. Some species, like the Amazon river dolphin (also known as the boto), live in freshwater rivers.5. **Diet**: Dolphins are carnivores and primarily eat fish, squid, and crustaceans. Their diet can vary depending on the species and their habitat. Some species, like the killer whale (which is actually a large dolphin), can even hunt larger marine mammals.6. **Reproduction**: Dolphins have a long gestation period, typically around 10 to 12 months. Calves are born tail-first and are nursed by their mothers for up to two years. Dolphins often form strong bonds with their offspring and other members of their pod.7. **Conservation**: Many species of dolphins face threats such as pollution, overfishing, and entanglement in fishing nets. Conservation efforts are ongoing to protect these animals and their habitats. Organizations like the International Union for Conservation of Nature (IUCN) and the World Wildlife Fund (WWF) work to raise awareness and implement conservation measures.8. **Cultural Significance**: Dolphins have been a source of fascination and inspiration for humans for centuries. They appear in myths, legends, and art across many cultures and are often seen as symbols of intelligence, playfulness, and freedom.Dolphins are truly remarkable creatures with a lot to teach us about social behavior, communication, and the complexities of marine ecosystems. If you have any specific questions or want to know more about a particular species, feel free to ask!
Com um contexto truncado, o LLM continua respondendo
Modificação do contexto e corte de mensagens
Vamos a juntar as duas técnicas anteriores, modificaremos o contexto e recortaremos os mensagens.
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from langchain_core.messages import RemoveMessage, trim_messages
from huggingface_hub import login
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Create the LLM model
login(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the model
MODEL = "Qwen/Qwen2.5-72B-Instruct"
model = HuggingFaceEndpoint(
repo_id=MODEL,
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
# Create the chat model
llm = ChatHuggingFace(llm=model)
# Nodes
def filter_messages(state: State):
# Delete all but the 2 most recent messages
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
return {"messages": delete_messages}
def trim_messages_node(state: State):
# print the messages
print("--- messages (input to trim_messages) ---")
for m in state["messages"]:
m.pretty_print()
print("------------------------------------------------")
# Trim the messages based on the specified parameters
trimmed_messages = trim_messages(
state["messages"],
max_tokens=100, # Maximum tokens allowed in the trimmed list
strategy="last", # Keep the latest messages
token_counter=llm, # Use the LLM's tokenizer to count tokens
allow_partial=True, # Allow cutting messages mid-way if needed
)
# Print the trimmed messages to see the effect of trim_messages
print("--- trimmed messages (input to LLM) ---")
for m in trimmed_messages:
m.pretty_print()
print("------------------------------------------------")
# Invoke the LLM with the trimmed messages
response = llm.invoke(trimmed_messages)
# Return the LLM's response in the correct state format
return {"messages": [response]}
def chat_model_node(state: State):
return {"messages": [llm.invoke(state["messages"])]}
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("filter_messages_node", filter_messages)
graph_builder.add_node("chatbot_node", chat_model_node)
graph_builder.add_node("trim_messages_node", trim_messages_node)
# Connecto nodes
graph_builder.add_edge(START, "filter_messages_node")
graph_builder.add_edge("filter_messages_node", "trim_messages_node")
graph_builder.add_edge("trim_messages_node", "chatbot_node")
graph_builder.add_edge("chatbot_node", END)
# Compile the graph
graph = graph_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
Agora filtramos ficando com as duas últimas mensagens, depois trimamos o contexto para que não gaste muitos tokens e, finalmente, passamos o resultado ao modelo.
Criamos um contexto para passá-lo ao grafo
from langchain_core.messages import AIMessage, HumanMessagemessages = [AIMessage(f"So you said you were researching ocean mammals?", name="Bot")]messages.append(HumanMessage(f"Yes, I know about whales. But what others should I learn about?", name="Lance"))messages.append(AIMessage(f"I know about dolphins too", name="Bot"))messages.append(HumanMessage(f"What others should I learn about?", name="Lance"))messages.append(AIMessage(f"""I know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.""", name="Bot"))messages.append(HumanMessage(f"What others should I learn about?", name="Lance"))for m in messages:m.pretty_print()
================================== Ai Message ==================================Name: BotSo you said you were researching ocean mammals?================================ Human Message =================================Name: LanceYes, I know about whales. But what others should I learn about?================================== Ai Message ==================================Name: BotI know about dolphins too================================ Human Message =================================Name: LanceWhat others should I learn about?================================== Ai Message ==================================Name: BotI know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.================================ Human Message =================================Name: LanceWhat others should I learn about?
Passamos para o grafo e obtemos a saída
output = graph.invoke({'messages': messages})
--- messages (input to trim_messages) ---================================== Ai Message ==================================Name: BotI know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.================================ Human Message =================================Name: LanceWhat others should I learn about?--------------------------------------------------- trimmed messages (input to LLM) ---================================ Human Message =================================Name: LanceWhat others should I learn about?------------------------------------------------
Como podemos ver, ficamos apenas com a última mensagem, isso ocorreu porque a função de filtro retornou as duas últimas mensagens, mas a função de trim removceu a penúltima mensagem por ter mais de 100 tokens.
Vamos a ver o que temos na saída do modelo
for m in output['messages']:m.pretty_print()
================================== Ai Message ==================================Name: BotI know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.================================ Human Message =================================Name: LanceWhat others should I learn about?================================== Ai Message ==================================Certainly! To provide a more tailored response, it would be helpful to know what areas or topics you're interested in. However, here’s a general list of areas that are often considered valuable for personal and professional development:1. **Technology & Digital Skills**:- Programming languages (Python, JavaScript, etc.)- Web development (HTML, CSS, React, etc.)- Data analysis and visualization (SQL, Tableau, Power BI)- Machine learning and AI- Cloud computing (AWS, Azure, Google Cloud)2. **Business & Entrepreneurship**:- Marketing (digital marketing, SEO, content marketing)- Project management- Financial literacy- Leadership and management-Startup and venture capital3. **Science & Engineering**:- Biology and genetics- Physics and materials science- Environmental science and sustainability- Robotics and automation- Aerospace engineering4. **Health & Wellness**:- Nutrition and dietetics- Mental health and psychology- Exercise science- Yoga and mindfulness- Traditional and alternative medicine5. **Arts & Humanities**:- Creative writing and storytelling- Music and sound production- Visual arts and design (graphic design, photography)- Philosophy and ethics- History and cultural studies6. **Communication & Languages**:- Public speaking and presentation skills- Conflict resolution and negotiation- Learning a new language (Spanish, Mandarin, French, etc.)- Writing and editing7. **Personal Development**:- Time management and productivity- Mindfulness and stress management- Goal setting and motivation- Personal finance and budgeting- Critical thinking and problem solving8. **Social & Environmental Impact**:- Social entrepreneurship- Community organizing and activism- Sustainable living practices- Climate change and environmental policyIf you have a specific area of interest or a particular goal in mind, feel free to share, and I can provide more detailed recommendations!================================== Ai Message ==================================
Filtramos tanto o estado que o LLM não tem contexto suficiente, mais tarde veremos uma maneira de resolver isso adicionando ao estado um resumo da conversação.
Modos de transmissão
Streaming síncrono
Neste caso, vamos receber o resultado do LLM completo assim que ele terminar de gerar o texto.
Para explicar os modos de transmissão síncrona, primeiro vamos criar um grafo básico.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from langchain_core.messages import HumanMessage
from huggingface_hub import login
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Create the LLM model
login(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the model
MODEL = "Qwen/Qwen2.5-72B-Instruct"
model = HuggingFaceEndpoint(
repo_id=MODEL,
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
# Create the chat model
llm = ChatHuggingFace(llm=model)
# Nodes
def chat_model_node(state: State):
# Return the LLM's response in the correct state format
return {"messages": [llm.invoke(state["messages"])]}
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("chatbot_node", chat_model_node)
# Connecto nodes
graph_builder.add_edge(START, "chatbot_node")
graph_builder.add_edge("chatbot_node", END)
# Compile the graph
graph = graph_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
Agora temos duas maneiras de obter o resultado do LLM, uma é através do modo updates e a outra através do modo values.
 Enquanto
Enquanto updates nos dá cada novo resultado, values nos dá todo o histórico de resultados.
Atualizações
for chunk in graph.stream({"messages": [HumanMessage(content="hi! I'm Máximo")]}, stream_mode="updates"):print(chunk['chatbot_node']['messages'][-1].content)
Hello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.
Valores
for chunk in graph.stream({"messages": [HumanMessage(content="hi! I'm Máximo")]}, stream_mode="values"):print(chunk['messages'][-1].content)
hi! I'm MáximoHello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.
Streaming assíncrono
Agora vamos receber o resultado do LLM token a token. Para isso, temos que adicionar streaming=True quando criamos o LLM da HuggingFace e temos que alterar a função do nó do chatbot para que seja assíncrona.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from langchain_core.messages import HumanMessage
from huggingface_hub import login
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Create the LLM model
login(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the model
MODEL = "Qwen/Qwen2.5-72B-Instruct"
model = HuggingFaceEndpoint(
repo_id=MODEL,
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
streaming=True,
)
# Create the chat model
llm = ChatHuggingFace(llm=model)
# Nodes
async def chat_model_node(state: State):
async for token in llm.astream_log(state["messages"]):
yield {"messages": [token]}
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("chatbot_node", chat_model_node)
# Connecto nodes
graph_builder.add_edge(START, "chatbot_node")
graph_builder.add_edge("chatbot_node", END)
# Compile the graph
graph = graph_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
Como pode ser visto, a função foi criada assíncrona e convertida em um gerador, pois o yield retorna um valor e pausa a execução da função até que seja chamada novamente.
Vamos a executar o grafo de forma assíncrona e ver os tipos de eventos que são gerados.
try:
async for event in graph.astream_events({"messages": [HumanMessage(content="hi! I'm Máximo")]}, version="v2"):
print(f"event: {event}")
except Exception as e:
print(f"Error: {e}")
Como se pode ver, os tokens chegam com o evento on_chat_model_stream, então vamos capturá-lo e imprimi-lo.
try:
async for event in graph.astream_events({"messages": [HumanMessage(content="hi! I'm Máximo")]}, version="v2"):
if event["event"] == "on_chat_model_stream":
print(event["data"]["chunk"].content, end=" | ", flush=True)
except Exception as e:
pass
Subgrafos
Antes vimos como bifurcar um grafo de forma que os nós sejam executados em paralelo, mas suponha o caso de que agora o que queremos é que o que seja executado em paralelo sejam subgrafos. Então vamos ver como fazer isso.
Vamos ver como fazer um grafo de gestão de logs que vai ter um subgrafo de resumo de logs e outro subgrafo de análise de erros nos logs.
 Então, o que vamos fazer é primeiro definir cada um dos subgráficos separadamente e depois adicioná-los ao grafo principal.
Então, o que vamos fazer é primeiro definir cada um dos subgráficos separadamente e depois adicioná-los ao grafo principal.
Subgráfico de análise de erros em logs
Importamos as bibliotecas necessárias
from IPython.display import Image, displayfrom langgraph.graph import StateGraph, START, ENDfrom operator import addfrom typing_extensions import TypedDictfrom typing import List, Optional, Annotated
Criamos uma classe com a estrutura dos logs
# The structure of the logsclass Log(TypedDict):id: strquestion: strdocs: Optional[List]answer: strgrade: Optional[int]grader: Optional[str]feedback: Optional[str]
Criamos agora duas classes, uma com a estrutura dos erros dos logs e outra com a análise que relatará na saída
# Failure Analysis Sub-graphclass FailureAnalysisState(TypedDict):cleaned_logs: List[Log]failures: List[Log]fa_summary: strprocessed_logs: List[str]class FailureAnalysisOutputState(TypedDict):fa_summary: strprocessed_logs: List[str]
Agora criamos as funções dos nós, uma obterá os erros nos logs, para isso buscará os logs que tenham algum valor no campo grade. Outra gerará um resumo dos erros. Além disso, vamos adicionar prints para poder ver o que está acontecendo internamente.
def get_failures(state):""" Get logs that contain a failure """cleaned_logs = state["cleaned_logs"]print(f" debug get_failures: cleaned_logs: {cleaned_logs}")failures = [log for log in cleaned_logs if "grade" in log]print(f" debug get_failures: failures: {failures}")return {"failures": failures}def generate_summary(state):""" Generate summary of failures """failures = state["failures"]print(f" debug generate_summary: failures: {failures}")fa_summary = "Poor quality retrieval of documentation."print(f" debug generate_summary: fa_summary: {fa_summary}")processed_logs = [f"failure-analysis-on-log-{failure['id']}" for failure in failures]print(f" debug generate_summary: processed_logs: {processed_logs}")return {"fa_summary": fa_summary, "processed_logs": processed_logs}
Por último, criamos o grafo, adicionamos os nós e os edges e o compilamos.
fa_builder = StateGraph(FailureAnalysisState,output=FailureAnalysisOutputState)
fa_builder.add_node("get_failures", get_failures)
fa_builder.add_node("generate_summary", generate_summary)
fa_builder.add_edge(START, "get_failures")
fa_builder.add_edge("get_failures", "generate_summary")
fa_builder.add_edge("generate_summary", END)
graph = fa_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
Vamos a criar um log de teste
failure_log = {"id": "1","question": "What is the meaning of life?","docs": None,"answer": "42","grade": 1,"grader": "AI","feedback": "Good job!"}
Executamos o grafo com o log de teste. Como a função get_failures pega a chave cleaned_logs do estado, temos que passar o log para o grafo na mesma chave.
graph.invoke({"cleaned_logs": [failure_log]})
Pode-se ver que ele encontrou o log de teste, pois tem um valor de 1 no campo grade e, em seguida, gerou um resumo dos erros.
Vamos a definir todo o subgráfico juntos novamente para ficar mais claro e também para remover os prints que colocamos para depuração.
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
from operator import add
from typing_extensions import TypedDict
from typing import List, Optional, Annotated
# The structure of the logs
class Log(TypedDict):
id: str
question: str
docs: Optional[List]
answer: str
grade: Optional[int]
grader: Optional[str]
feedback: Optional[str]
# Failure clases
class FailureAnalysisState(TypedDict):
cleaned_logs: List[Log]
failures: List[Log]
fa_summary: str
processed_logs: List[str]
class FailureAnalysisOutputState(TypedDict):
fa_summary: str
processed_logs: List[str]
# Functions
def get_failures(state):
""" Get logs that contain a failure """
cleaned_logs = state["cleaned_logs"]
failures = [log for log in cleaned_logs if "grade" in log]
return {"failures": failures}
def generate_summary(state):
""" Generate summary of failures """
failures = state["failures"]
fa_summary = "Poor quality retrieval of documentation."
processed_logs = [f"failure-analysis-on-log-{failure['id']}" for failure in failures]
return {"fa_summary": fa_summary, "processed_logs": processed_logs}
# Build the graph
fa_builder = StateGraph(FailureAnalysisState,output=FailureAnalysisOutputState)
fa_builder.add_node("get_failures", get_failures)
fa_builder.add_node("generate_summary", generate_summary)
fa_builder.add_edge(START, "get_failures")
fa_builder.add_edge("get_failures", "generate_summary")
fa_builder.add_edge("generate_summary", END)
graph = fa_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
Se nós o executarmos novamente, obteremos o mesmo resultado, mas sem os prints.
graph.invoke({"cleaned_logs": [failure_log]})
{opening_brace}'fa_summary': 'Poor quality retrieval of documentation.','processed_logs': ['failure-analysis-on-log-1']{closing_brace}
Subgrafo de resumo de logs
Agora criamos o subgrafo de resumo de logs. Neste caso, não é necessário recriar a classe com a estrutura dos logs, então criamos as classes com a estrutura para os resumos dos logs e com a estrutura da saída.
# Summarization subgraphclass QuestionSummarizationState(TypedDict):cleaned_logs: List[Log]qs_summary: strreport: strprocessed_logs: List[str]class QuestionSummarizationOutputState(TypedDict):report: strprocessed_logs: List[str]
Agora definimos as funções dos nós, uma gerará o resumo dos logs e outra "enviará o resumo para o Slack".
def generate_summary(state):cleaned_logs = state["cleaned_logs"]print(f" debug generate_summary: cleaned_logs: {cleaned_logs}")summary = "Questions focused on ..."print(f" debug generate_summary: summary: {summary}")processed_logs = [f"summary-on-log-{log['id']}" for log in cleaned_logs]print(f" debug generate_summary: processed_logs: {processed_logs}")return {opening_brace}"qs_summary": summary, "processed_logs": processed_logs{closing_brace}def send_to_slack(state):qs_summary = state["qs_summary"]print(f" debug send_to_slack: qs_summary: {qs_summary}")report = "foo bar baz"print(f" debug send_to_slack: report: {report}")return {opening_brace}"report": report{closing_brace}
Por último, criamos o grafo, adicionamos os nós e as edges e o compilamos.
# Build the graph
qs_builder = StateGraph(QuestionSummarizationState,output=QuestionSummarizationOutputState)
qs_builder.add_node("generate_summary", generate_summary)
qs_builder.add_node("send_to_slack", send_to_slack)
qs_builder.add_edge(START, "generate_summary")
qs_builder.add_edge("generate_summary", "send_to_slack")
qs_builder.add_edge("send_to_slack", END)
graph = qs_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
Voltamos a testar com o log que criamos anteriormente.
graph.invoke({"cleaned_logs": [failure_log]})
Reescrevemos o subgrafo, tudo junto para ver com maior clareza e sem os prints.
# Summarization clases
class QuestionSummarizationState(TypedDict):
cleaned_logs: List[Log]
qs_summary: str
report: str
processed_logs: List[str]
class QuestionSummarizationOutputState(TypedDict):
report: str
processed_logs: List[str]
# Functions
def generate_summary(state):
cleaned_logs = state["cleaned_logs"]
summary = "Questions focused on ..."
processed_logs = [f"summary-on-log-{log['id']}" for log in cleaned_logs]
return {"qs_summary": summary, "processed_logs": processed_logs}
def send_to_slack(state):
qs_summary = state["qs_summary"]
report = "foo bar baz"
return {"report": report}
# Build the graph
qs_builder = StateGraph(QuestionSummarizationState,output=QuestionSummarizationOutputState)
qs_builder.add_node("generate_summary", generate_summary)
qs_builder.add_node("send_to_slack", send_to_slack)
qs_builder.add_edge(START, "generate_summary")
qs_builder.add_edge("generate_summary", "send_to_slack")
qs_builder.add_edge("send_to_slack", END)
graph = qs_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
Executamos o grafo novamente com o log de teste.
graph.invoke({"cleaned_logs": [failure_log]})
{opening_brace}'report': 'foo bar baz', 'processed_logs': ['summary-on-log-1']{closing_brace}
Grafo principal
Agora que temos os dois subgrafos, podemos criar o grafo principal que os utilizará. Para isso, criamos a classe EntryGraphState que terá o estado dos dois subgrafos.
# Entry Graphclass EntryGraphState(TypedDict):raw_logs: List[Log]cleaned_logs: List[Log]fa_summary: str # This will only be generated in the FA sub-graphreport: str # This will only be generated in the QS sub-graphprocessed_logs: Annotated[List[int], add] # This will be generated in BOTH sub-graphs
Criamos uma função de limpeza de logs, que será um nó que se executará antes dos dois subgrafos e que lhes fornecerá os logs limpos através da chave cleaned_logs, que é a que os dois subgrafos tomam do estado.
def clean_logs(state):# Get logsraw_logs = state["raw_logs"]# Data cleaning raw_logs -> docscleaned_logs = raw_logsreturn {opening_brace}"cleaned_logs": cleaned_logs{closing_brace}
Agora criamos o grafo principal
# Build the graphentry_builder = StateGraph(EntryGraphState)
Adicionamos os nós. Para adicionar um subgráfico como nó, o que fazemos é adicionar sua compilação.
# Add nodesentry_builder.add_node("clean_logs", clean_logs)entry_builder.add_node("question_summarization", qs_builder.compile())entry_builder.add_node("failure_analysis", fa_builder.compile())
<langgraph.graph.state.StateGraph at 0x107985ef0>
A partir de aqui já é como se sempre, adicionamos os edges e o compilamos.
# Add edgesentry_builder.add_edge(START, "clean_logs")entry_builder.add_edge("clean_logs", "failure_analysis")entry_builder.add_edge("clean_logs", "question_summarization")entry_builder.add_edge("failure_analysis", END)entry_builder.add_edge("question_summarization", END)# Compile the graphgraph = entry_builder.compile()
Adding an edge to a graph that has already been compiled. This will not be reflected in the compiled graph.Adding an edge to a graph that has already been compiled. This will not be reflected in the compiled graph.Adding an edge to a graph that has already been compiled. This will not be reflected in the compiled graph.Adding an edge to a graph that has already been compiled. This will not be reflected in the compiled graph.Adding an edge to a graph that has already been compiled. This will not be reflected in the compiled graph.
Por fim, mostramos o grafo. Adicionamos xray=1 para que seja visível o estado interno do grafo.
# Setting xray to 1 will show the internal structure of the nested graph
display(Image(graph.get_graph(xray=1).draw_mermaid_png()))
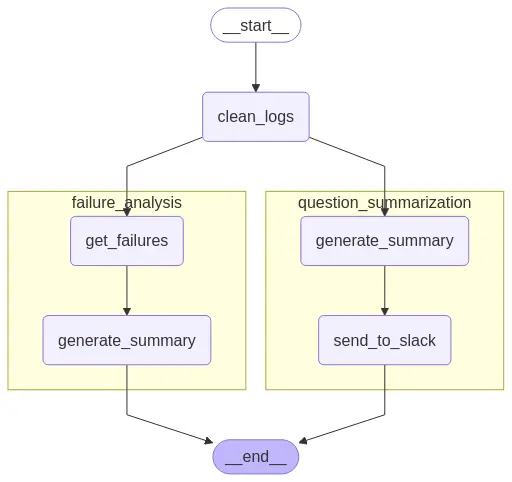
Se não tivéssemos adicionado xray=1, o gráfico ficaria assim
display(Image(graph.get_graph().draw_mermaid_png()))
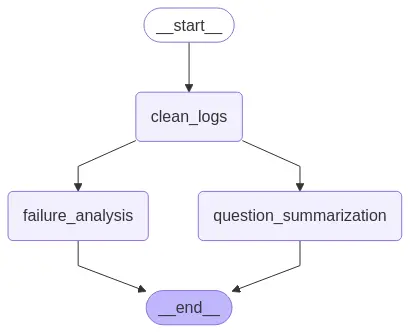
Agora criamos dois logs de teste, em um haverá um erro (um valor em grade) e no outro não.
# Dummy logsquestion_answer = Log(id="1",question="How can I import ChatOllama?",answer="To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'",)question_answer_feedback = Log(id="2",question="How can I use Chroma vector store?",answer="To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).",grade=0,grader="Document Relevance Recall",feedback="The retrieved documents discuss vector stores in general, but not Chroma specifically",)raw_logs = [question_answer,question_answer_feedback]
Passamo-los para o grafo principal
graph.invoke({"raw_logs": raw_logs})
{'raw_logs': [{'id': '1','question': 'How can I import ChatOllama?','answer': "To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'"},{'id': '2','question': 'How can I use Chroma vector store?','answer': 'To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).','grade': 0,'grader': 'Document Relevance Recall','feedback': 'The retrieved documents discuss vector stores in general, but not Chroma specifically'}],'cleaned_logs': [{'id': '1','question': 'How can I import ChatOllama?','answer': "To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'"},{'id': '2','question': 'How can I use Chroma vector store?','answer': 'To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).','grade': 0,'grader': 'Document Relevance Recall','feedback': 'The retrieved documents discuss vector stores in general, but not Chroma specifically'}],'fa_summary': 'Poor quality retrieval of documentation.','report': 'foo bar baz','processed_logs': ['failure-analysis-on-log-2','summary-on-log-1','summary-on-log-2']}
Assim como antes, escrevemos todo o grafo para vê-lo com maior clareza
# Entry Graph
class EntryGraphState(TypedDict):
raw_logs: List[Log]
cleaned_logs: List[Log]
fa_summary: str # This will only be generated in the FA sub-graph
report: str # This will only be generated in the QS sub-graph
processed_logs: Annotated[List[int], add] # This will be generated in BOTH sub-graphs
# Functions
def clean_logs(state):
# Get logs
raw_logs = state["raw_logs"]
# Data cleaning raw_logs -> docs
cleaned_logs = raw_logs
return {"cleaned_logs": cleaned_logs}
# Build the graph
entry_builder = StateGraph(EntryGraphState)
# Add nodes
entry_builder.add_node("clean_logs", clean_logs)
entry_builder.add_node("question_summarization", qs_builder.compile())
entry_builder.add_node("failure_analysis", fa_builder.compile())
# Add edges
entry_builder.add_edge(START, "clean_logs")
entry_builder.add_edge("clean_logs", "failure_analysis")
entry_builder.add_edge("clean_logs", "question_summarization")
entry_builder.add_edge("failure_analysis", END)
entry_builder.add_edge("question_summarization", END)
# Compile the graph
graph = entry_builder.compile()
# Setting xray to 1 will show the internal structure of the nested graph
display(Image(graph.get_graph(xray=1).draw_mermaid_png()))
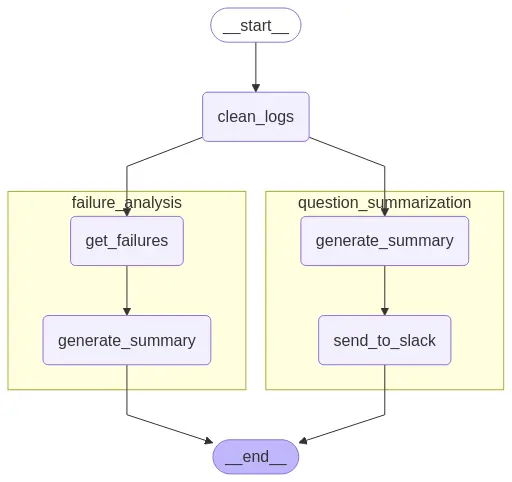
Passamos os logs de teste ao grafo principal
graph.invoke({"raw_logs": raw_logs})
{'raw_logs': [{'id': '1','question': 'How can I import ChatOllama?','answer': "To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'"},{'id': '2','question': 'How can I use Chroma vector store?','answer': 'To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).','grade': 0,'grader': 'Document Relevance Recall','feedback': 'The retrieved documents discuss vector stores in general, but not Chroma specifically'}],'cleaned_logs': [{'id': '1','question': 'How can I import ChatOllama?','answer': "To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'"},{'id': '2','question': 'How can I use Chroma vector store?','answer': 'To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).','grade': 0,'grader': 'Document Relevance Recall','feedback': 'The retrieved documents discuss vector stores in general, but not Chroma specifically'}],'fa_summary': 'Poor quality retrieval of documentation.','report': 'foo bar baz','processed_logs': ['failure-analysis-on-log-2','summary-on-log-1','summary-on-log-2']}
Ramas dinâmicas
Até agora criamos nós e edges estáticos, mas há momentos em que não sabemos se vamos precisar de um galho até que o grafo seja executado. Para isso, podemos usar o método SEND do langgraph, que permite criar galhos dinamicamente.
Para vê-lo, vamos criar um grafo que gere piadas sobre alguns temas, mas como não sabemos antecipadamente sobre quantos temas queremos gerar piadas, através do método SEND vamos criar ramificações dinamicamente, de forma que se houverem temas restantes para gerar, uma nova ramificação será criada.
Nota: Vamos a fazer esta seção usando o Sonnet 3.7, pois a integração da HuggingFace não possui a funcionalidade de
with_structured_outputque fornece uma saída estruturada com uma estrutura definida.
Primeiro importamos as bibliotecas necessárias.
import operatorfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import END, StateGraph, STARTfrom langchain_anthropic import ChatAnthropicimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")from IPython.display import Image
Criamos as classes com a estrutura do estado.
class OverallState(TypedDict):topic: strsubjects: listjokes: Annotated[list, operator.add]best_selected_joke: strclass JokeState(TypedDict):subject: str
Criamos o LLM
# Create the LLM modelllm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)
Criamos a função que gerará os temas.
Vamos a usar with_structured_output para que o LLM gere uma saída com uma estrutura definida por nós, essa estrutura vamos definir com a classe Subjects que é uma classe do tipo BaseModel de Pydantic.
from pydantic import BaseModelclass Subjects(BaseModel):subjects: list[str]subjects_prompt = """Generate a list of 3 sub-topics that are all related to this overall topic: {topic}."""def generate_topics(state: OverallState):prompt = subjects_prompt.format(topic=state["topic"])response = llm.with_structured_output(Subjects).invoke(prompt)return {opening_brace}"subjects": response.subjects{closing_brace}
Agora definimos a função que gerará os piadas.
class Joke(BaseModel):joke: strjoke_prompt = """Generate a joke about {subject}"""def generate_joke(state: JokeState):prompt = joke_prompt.format(subject=state["subject"])response = llm.with_structured_output(Joke).invoke(prompt)return {opening_brace}"jokes": [response.joke]}
E por último a função que selecionará o melhor chiste.
class BestJoke(BaseModel):id: intbest_joke_prompt = """Below are a bunch of jokes about {topic}. Select the best one! Return the ID of the best one, starting 0 as the ID for the first joke. Jokes: \n\n {jokes}"""def best_joke(state: OverallState):jokes = "\n\n".join(state["jokes"])prompt = best_joke_prompt.format(topic=state["topic"], jokes=jokes)response = llm.with_structured_output(BestJoke).invoke(prompt)return {opening_brace}"best_selected_joke": state["jokes"][response.id]}
Agora vamos criar uma função que decida se deve ou não criar uma nova branch com SEND, e para decidir isso, ela verificará se há tópicos restantes a serem gerados.
from langgraph.constants import Senddef continue_to_jokes(state: OverallState):return [Send("generate_joke", {opening_brace}"subject": s}) for s in state["subjects"]]
Construímos o grafo, adicionamos os nós e os edges.
# Build the graph
graph = StateGraph(OverallState)
# Add nodes
graph.add_node("generate_topics", generate_topics)
graph.add_node("generate_joke", generate_joke)
graph.add_node("best_joke", best_joke)
# Add edges
graph.add_edge(START, "generate_topics")
graph.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_joke"])
graph.add_edge("generate_joke", "best_joke")
graph.add_edge("best_joke", END)
# Compile the graph
app = graph.compile()
# Display the graph
Image(app.get_graph().draw_mermaid_png())
Como se pode ver, o edge entre generate_topics e generate_joke é representado por uma linha tracejada, indicando que é um ramo dinâmico.
Criamos agora um dicionário com a chave topic que é necessária pelo nó generate_topics para gerar os tópicos e o passamos ao grafo.
# Call the graph: here we call it to generate a list of jokesfor state in app.stream({"topic": "animals"}):print(state)
{'generate_topics': {'subjects': ['Marine Animals', 'Endangered Species', 'Animal Behavior']}}{'generate_joke': {'jokes': ["Why don't cats play poker in the wild? Too many cheetahs!"]}}{'generate_joke': {'jokes': ["Why don't sharks eat clownfish? Because they taste funny!"]}}{'generate_joke': {'jokes': ["Why don't endangered species tell jokes? Because they're afraid of dying out from laughter!"]}}{'best_joke': {'best_selected_joke': "Why don't cats play poker in the wild? Too many cheetahs!"}}
Voltamos a criar o grafo com todo o código junta para maior clareza.
import operator
from typing import Annotated
from typing_extensions import TypedDict
from pydantic import BaseModel
from langgraph.graph import END, StateGraph, START
from langgraph.constants import Send
from langchain_anthropic import ChatAnthropic
import os
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
import dotenv
dotenv.load_dotenv()
ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")
from IPython.display import Image
# Prompts we will use
subjects_prompt = """Generate a list of 3 sub-topics that are all related to this overall topic: {topic}."""
joke_prompt = """Generate a joke about {subject}"""
best_joke_prompt = """Below are a bunch of jokes about {topic}. Select the best one! Return the ID of the best one, starting 0 as the ID for the first joke. Jokes: \n\n {jokes}"""
# Create the LLM model
llm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)
class Subjects(BaseModel):
subjects: list[str]
class BestJoke(BaseModel):
id: int
class OverallState(TypedDict):
topic: str
subjects: list
jokes: Annotated[list, operator.add]
best_selected_joke: str
class JokeState(TypedDict):
subject: str
class Joke(BaseModel):
joke: str
def generate_topics(state: OverallState):
prompt = subjects_prompt.format(topic=state["topic"])
response = llm.with_structured_output(Subjects).invoke(prompt)
return {"subjects": response.subjects}
def continue_to_jokes(state: OverallState):
return [Send("generate_joke", {"subject": s}) for s in state["subjects"]]
def generate_joke(state: JokeState):
prompt = joke_prompt.format(subject=state["subject"])
response = llm.with_structured_output(Joke).invoke(prompt)
return {"jokes": [response.joke]}
def best_joke(state: OverallState):
jokes = "\n\n".join(state["jokes"])
prompt = best_joke_prompt.format(topic=state["topic"], jokes=jokes)
response = llm.with_structured_output(BestJoke).invoke(prompt)
return {"best_selected_joke": state["jokes"][response.id]}
# Build the graph
graph = StateGraph(OverallState)
# Add nodes
graph.add_node("generate_topics", generate_topics)
graph.add_node("generate_joke", generate_joke)
graph.add_node("best_joke", best_joke)
# Add edges
graph.add_edge(START, "generate_topics")
graph.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_joke"])
graph.add_edge("generate_joke", "best_joke")
graph.add_edge("best_joke", END)
# Compile the graph
app = graph.compile()
# Display the graph
Image(app.get_graph().draw_mermaid_png())
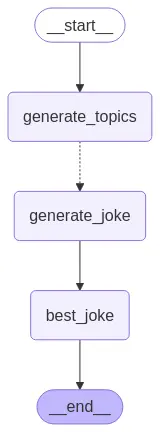
Voltamos a executá-lo, mas agora, em vez de animais, vamos fazer com carros.
for state in app.stream({"topic": "cars"}):print(state)
{'generate_topics': {'subjects': ['Car Maintenance and Repair', 'Electric and Hybrid Vehicles', 'Automotive Design and Engineering']}}{'generate_joke': {'jokes': ["Why don't electric cars tell jokes? They're afraid of running out of charge before they get to the punchline!"]}}{'generate_joke': {'jokes': ["Why don't automotive engineers play hide and seek? Because good luck hiding when you're always making a big noise about torque!"]}}{'generate_joke': {'jokes': ["Why don't cars ever tell their own jokes? Because they always exhaust themselves during the delivery! Plus, their timing belts are always a little off."]}}{'best_joke': {'best_selected_joke': "Why don't electric cars tell jokes? They're afraid of running out of charge before they get to the punchline!"}}
Melhorar o chatbot com ferramentas
Para lidar com algumas consultas, nosso chatbot não pode responder com base em seu conhecimento, então vamos integrar uma ferramenta de busca na web. Nosso bot pode usar essa ferramenta para encontrar informações relevantes e fornecer respostas melhores.
Requisitos
Antes de começar, temos que instalar o buscador Tavily que é um buscador web que nos permite buscar informações na web.
pip install -U tavily-python langchain_community``` Depois, temos que criar uma API KEY, escrevemos no nosso arquivo .env e carregamos em uma variável.
import dotenvimport osdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")
Chatbot com ferramentas
Primeiro criamos o estado e o LLM
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginimport jsonimport osfrom IPython.display import Image, displayos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")class State(TypedDict):messages: Annotated[list, add_messages]# Create the LLMlogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)
Agora, definimos a ferramenta de busca na web através do TavilySearchResults
from langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultsTAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")wrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)tool = TavilySearchResults(api_wrapper=wrapper, max_results=2)
Testamos a ferramenta, vamos fazer uma busca na internet.
tool.invoke("What was the result of Real Madrid's at last match in the Champions League?")
Os resultados são resumos de páginas que nosso chatbot pode usar para responder perguntas.
Criamos uma lista de ferramentas, pois nosso grafo precisa definir as ferramentas por meio de uma lista.
tools_list = [tool]
Agora que temos a lista de tools, criamos um llm_with_tools.
# Modification: tell the LLM which tools it can callllm_with_tools = llm.bind_tools(tools_list)
Definimos a função queirá no nó chat bot
# Define the chatbot functiondef chatbot_function(state: State):return {opening_brace}"messages": [llm_with_tools.invoke(state["messages"])]}
Precisamos criar uma função para executar as tools_list se forem chamadas. Adicionamos as tools_list a um novo nó.
Mais tarde faremos isso com o método ToolNode de LangGraph, mas primeiro o construiremos nós mesmos para entender como funciona.
Vamos a implementar a classe BasicToolNode, que verifica a mensagem mais recente no estado e chama as tools_list se a mensagem contiver tool_calls.
Baseia-se no suporte a tool_calling dos LLMs, que está disponível na Anthropic, HuggingFace, Google Gemini, OpenAI e vários outros provedores de LLM.
from langchain_core.messages import ToolMessageclass BasicToolNode:"""A node that runs the tools requested in the last AIMessage."""def __init__(self, tools: list) -> None:"""Initialize the toolsArgs:tools (list): The tools to useReturns:None"""# Initialize the toolsself.tools_by_name = {opening_brace}tool.name: tool for tool in tools{closing_brace}def __call__(self, inputs: dict):"""Call the nodeArgs:inputs (dict): The inputs to the nodeReturns:dict: The outputs of the node"""# Get the last messageif messages := inputs.get("messages", []):message = messages[-1]else:raise ValueError("No message found in input")# Execute the toolsoutputs = []for tool_call in message.tool_calls:tool_result = self.tools_by_name[tool_call["name"]].invoke(tool_call["args"])outputs.append(ToolMessage(content=json.dumps(tool_result),name=tool_call["name"],tool_call_id=tool_call["id"],))return {opening_brace}"messages": outputs{closing_brace}basic_tool_node = BasicToolNode(tools=tools_list)
Nós usamos ToolMessage que passa o resultado de executar uma tool de volta para o LLM.
ToolMessage contém o resultado de uma invocação de uma tool.
Isso significa que, assim que temos o resultado de usar uma Tool, passamos esse resultado para o LLM processar.
Com o objeto basic_tool_node (que é um objeto da classe BasicToolNode que criamos), já podemos fazer com que o LLM execute tools.
Agora, assim como fizemos quando construímos um chatbot básico, vamos criar o grafo e adicionar nós a ele.
# Create graphgraph_builder = StateGraph(State)# Add the chatbot nodegraph_builder.add_node("chatbot_node", chatbot_function)graph_builder.add_node("tools_node", basic_tool_node)
<langgraph.graph.state.StateGraph at 0x14996cd70>
Quando o LLM receber uma mensagem, como conhece as tools que tem à disposição, decidirá se deve responder ou usar uma tool. Então, vamos criar uma função de roteamento, que executará uma tool se o LLM decidir usá-la, ou caso contrário, terminará a execução do grafo.
def route_tools_function(state: State,):"""Use in the conditional_edge to route to the ToolNode if the last messagehas tool calls. Otherwise, route to the end."""# Get last messageif isinstance(state, list):ai_message = state[-1]elif messages := state.get("messages", []):ai_message = messages[-1]else:raise ValueError(f"No messages found in input state to tool_edge: {state}")# Router in function of last messageif hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:return "tools_node"return END
Adicionamos os edges.
Temos que adicionar uma edge especial através de add_conditional_edges, que criará um nó condicional. Une o nó chatbot_node com a função de roteamento que criamos anteriormente route_tools_function. Com este nó, se obtivermos na saída de route_tools_function a string tools_node, o grafo será roteado para o nó tools_node, mas se recebermos END, o grafo será roteado para o nó END e terminará a execução do grafo.
Mais tarde, substituiremos isso pelo método pré-construído tools_condition, mas agora o implementamos nós mesmos para ver como funciona.
Por último, adiciona-se outro edge que une tools_node com chatbot_node, para que quando termine de executar uma tool o grafo volte ao nó do LLM
# Add edgesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_conditional_edges("chatbot_node",route_tools_function,# The following dictionary lets you tell the graph to interpret the condition's outputs as a specific node# It defaults to the identity function, but if you# want to use a node named something else apart from "tools",# You can update the value of the dictionary to something else# e.g., "tools": "my_tools"{opening_brace}"tools_node": "tools_node", END: END},)graph_builder.add_edge("tools_node", "chatbot_node")
<langgraph.graph.state.StateGraph at 0x14996cd70>
Compilamos o nó e o representamos
graph = graph_builder.compile()
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(f"Error al visualizar el grafo: {e}")
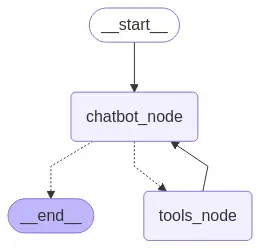
Agora podemos fazer perguntas ao bot fora de seus dados de treinamento
# Colors for the terminalCOLOR_GREEN = "\033[32m"COLOR_YELLOW = "\033[33m"COLOR_RESET = "\033[0m"def stream_graph_updates(user_input: str):for event in graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace}):for value in event.values():print(f"{opening_brace}COLOR_GREEN{closing_brace}User: {opening_brace}COLOR_RESET{closing_brace}{opening_brace}user_input{closing_brace}")print(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}{opening_brace}value['messages'][-1].content{closing_brace}")while True:try:user_input = input("User: ")if user_input.lower() in ["quit", "exit", "q"]:print(f"{opening_brace}COLOR_GREEN{closing_brace}User: {opening_brace}COLOR_RESET{closing_brace}{opening_brace}user_input{closing_brace}")print(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}Goodbye!")breakstream_graph_updates(user_input)except:# fallback if input() is not availableuser_input = "What do you know about LangGraph?"print("User: " + user_input)stream_graph_updates(user_input)break
User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{opening_brace}"title": "Real Madrid 3-2 Leganes: Goals and highlights - LaLiga 24/25 | Marca", "url": "https://www.marca.com/en/soccer/laliga/r-madrid-leganes/2025/03/29/01_0101_20250329_186_957-live.html", "content": "While their form has varied throughout the campaign there is no denying Real Madrid are a force at home in LaLiga this season, as they head into Saturday's match having picked up 34 points from 13 matches. As for Leganes they currently sit 18th in the table, though they are level with Alaves for 17th as both teams look to stay in the top flight. [...] The two teams have already played twice this season, with Real Madrid securing a 3-0 win in the reverse league fixture. They also met in the quarter-finals of the Copa del Rey, a game Real won 3-2. Real Madrid vs Leganes LIVE - Latest Updates Match ends, Real Madrid 3, Leganes 2. Second Half ends, Real Madrid 3, Leganes 2. Foul by Vinícius Júnior (Real Madrid). Seydouba Cissé (Leganes) wins a free kick in the defensive half. [...] Goal! Real Madrid 1, Leganes 1. Diego García (Leganes) left footed shot from very close range. Attempt missed. Óscar Rodríguez (Leganes) left footed shot from the centre of the box. Goal! Real Madrid 1, Leganes 0. Kylian Mbappé (Real Madrid) converts the penalty with a right footed shot. Penalty Real Madrid. Arda Güler draws a foul in the penalty area. Penalty conceded by Óscar Rodríguez (Leganes) after a foul in the penalty area. Delay over. They are ready to continue.", "score": 0.8548001}, {opening_brace}"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Game Analysis - ESPN", "url": "https://www.espn.com/soccer/report/_/gameId/704946", "content": "Real Madrid Leganés Mbappé nets twice to keep Real Madrid's title hopes alive Real Madrid vs. Leganés - Game Highlights Watch the Game Highlights from Real Madrid vs. Leganés, 03/30/2025 Real Madrid's Kylian Mbappé struck twice to help his side come from behind to claim a hard-fought 3-2 home win over relegation-threatened Leganes on Saturday to move the second-placed reigning champions level on points with leaders Barcelona. [...] Leganes pushed for an equaliser but fell to a third consecutive defeat to sit 18th on 27 points, level with Alaves who are one place higher in the safety zone on goal difference. "We have done a tremendous job. We leave with our heads held high because we were fighting until the end to score here," Leganes striker Garcia said. "Ultimately, it was down to the details that they took it. We played a very serious game and now we have to think about next week." Game Information", "score": 0.82220376}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{opening_brace}"title": "Real Madrid vs Leganes 3-2 | Highlights & All Goals - YouTube", "url": "https://www.youtube.com/watch?v=ngBWsjmeHEk", "content": "Real Madrid secured a dramatic 3-2 victory over Leganes in an intense La Liga showdown on 29 March 2025! ⚽ Watch all the goals and", "score": 0.5157425}, {opening_brace}"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Game Analysis - ESPN", "url": "https://www.espn.com/soccer/report/_/gameId/704946", "content": ""We know what we always have to do: win. We started well, in the opposition half, and we scored a goal. Then we didn't play well for 20 minutes and conceded two goals," said Mbappé. "But we know that if we play well we'll score and in the second half we scored two goals. We won the game and we're very happy. "We worked on [the set piece] a few weeks ago with the staff. I knew I could shoot this way, I saw the space. I asked the others to let me shoot and it worked out well." [...] Leganes pushed for an equaliser but fell to a third consecutive defeat to sit 18th on 27 points, level with Alaves who are one place higher in the safety zone on goal difference. "We have done a tremendous job. We leave with our heads held high because we were fighting until the end to score here," Leganes striker Garcia said. "Ultimately, it was down to the details that they took it. We played a very serious game and now we have to think about next week." Game Information [...] However, Leganes responded almost immediately as Diego Garcia tapped in a loose ball at the far post to equalise in the following minute before Rodriguez set up Dani Raba to slot past goalkeeper Andriy Lunin in the 41st. Real midfielder Jude Bellingham brought the scores level two minutes after the break, sliding the ball into the net after a rebound off the crossbar. Mbappé then bagged the winner with a brilliant curled free kick in the 76th minute for his second.", "score": 0.50944775}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{opening_brace}"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Game Analysis - ESPN", "url": "https://www.espn.com/soccer/report/_/gameId/704946", "content": "Real Madrid Leganés Mbappé nets twice to keep Real Madrid's title hopes alive Real Madrid vs. Leganés - Game Highlights Watch the Game Highlights from Real Madrid vs. Leganés, 03/30/2025 Real Madrid's Kylian Mbappé struck twice to help his side come from behind to claim a hard-fought 3-2 home win over relegation-threatened Leganes on Saturday to move the second-placed reigning champions level on points with leaders Barcelona. [...] Leganes pushed for an equaliser but fell to a third consecutive defeat to sit 18th on 27 points, level with Alaves who are one place higher in the safety zone on goal difference. "We have done a tremendous job. We leave with our heads held high because we were fighting until the end to score here," Leganes striker Garcia said. "Ultimately, it was down to the details that they took it. We played a very serious game and now we have to think about next week." Game Information [...] However, Leganes responded almost immediately as Diego Garcia tapped in a loose ball at the far post to equalise in the following minute before Rodriguez set up Dani Raba to slot past goalkeeper Andriy Lunin in the 41st. Real midfielder Jude Bellingham brought the scores level two minutes after the break, sliding the ball into the net after a rebound off the crossbar. Mbappé then bagged the winner with a brilliant curled free kick in the 76th minute for his second.", "score": 0.93666285}, {opening_brace}"title": "MBAPPE BRACE Leganes vs. Real Madrid - ESPN FC - YouTube", "url": "https://www.youtube.com/watch?v=0xwUhzx19_4", "content": "MBAPPE BRACE 🔥 Leganes vs. Real Madrid | LALIGA Highlights | ESPN FC ESPN FC 6836 likes 550646 views 29 Mar 2025 Watch these highlights as Kylian Mbappe scores 2 goals to give Real Madrid the 3-2 victory over Leganes in their LALIGA matchup. ✔ Subscribe to ESPN+: http://espnplus.com/soccer/youtube ✔ Subscribe to ESPN FC on YouTube: http://bit.ly/SUBSCRIBEtoESPNFC 790 comments", "score": 0.92857105}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{opening_brace}"title": "(VIDEO) All Goals from Real Madrid vs Leganes in La Liga", "url": "https://www.beinsports.com/en-us/soccer/la-liga/articles-video/-video-all-goals-from-real-madrid-vs-leganes-in-la-liga-2025-03-29?ess=", "content": "Real Madrid will host CD Leganes this Saturday, March 29, 2025, at the Santiago Bernabéu in a Matchday 29 clash of LaLiga EA Sports.", "score": 0.95628047}, {opening_brace}"title": "Real Madrid v Leganes | March 29, 2025 | Goal.com US", "url": "https://www.goal.com/en-us/match/real-madrid-vs-leganes/sZTw_SnjyKCcntxKHHQI7", "content": "Latest news, stats and live commentary for the LaLiga's meeting between Real Madrid v Leganes on the March 29, 2025.", "score": 0.9522955}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: Real Madrid faced Leganes in La Liga this weekend and came away with a 3-2 victory at the Santiago Bernabéu. The match was intense, with Kylian Mbappé scoring twice for Real Madrid, including a curled free kick in the 76th minute that proved to be the winner. Leganes managed to take the lead briefly with goals from Diego García and Dani Raba, but Real Madrid leveled through Jude Bellingham before Mbappé's second goal secured the win. This result keeps Real Madrid's title hopes alive, moving them level on points with leaders Barcelona.User: Which players played the match?Assistant: The question is too vague and doesn't provide context such as the sport, league, or specific match in question. Could you please provide more details?User: qAssistant: Goodbye!
Como você vê, primeiro perguntei como ficou o Real Madrid em seu último jogo na Liga contra o LeganésComo é algo atual, ele decidiu usar a ferramenta de busca, com isso obteve o resultado.
No entanto, em seguida eu lhe perguntei quais jogadores estavam jogando e ele não sabia do que eu estava falando, isso porque o contexto da conversa não é mantido. Então, a próxima coisa que vamos fazer é adicionar uma memória ao agente para que ele possa manter o contexto da conversa.
Vamos a escrever tudo junto para que seja mais legível
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginfrom langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultsfrom langchain_core.messages import ToolMessagefrom IPython.display import Image, displayimport jsonimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]# Toolswrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)tool = TavilySearchResults(api_wrapper=wrapper, max_results=2)tools_list = [tool]# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Create the LLM with toolsllm_with_tools = llm.bind_tools(tools_list)# BasicToolNode classclass BasicToolNode:"""A node that runs the tools requested in the last AIMessage."""def __init__(self, tools: list) -> None:"""Initialize the toolsArgs:tools (list): The tools to useReturns:None"""# Initialize the toolsself.tools_by_name = {opening_brace}tool.name: tool for tool in tools{closing_brace}def __call__(self, inputs: dict):"""Call the nodeArgs:inputs (dict): The inputs to the nodeReturns:dict: The outputs of the node"""# Get the last messageif messages := inputs.get("messages", []):message = messages[-1]else:raise ValueError("No message found in input")# Execute the toolsoutputs = []for tool_call in message.tool_calls:tool_result = self.tools_by_name[tool_call["name"]].invoke(tool_call["args"])outputs.append(ToolMessage(content=json.dumps(tool_result),name=tool_call["name"],tool_call_id=tool_call["id"],))return {opening_brace}"messages": outputs{closing_brace}basic_tool_node = BasicToolNode(tools=tools_list)# Functionsdef chatbot_function(state: State):return {opening_brace}"messages": [llm_with_tools.invoke(state["messages"])]}# Route functiondef route_tools_function(state: State):"""Use in the conditional_edge to route to the ToolNode if the last messagehas tool calls. Otherwise, route to the end."""# Get last messageif isinstance(state, list):ai_message = state[-1]elif messages := state.get("messages", []):ai_message = messages[-1]else:raise ValueError(f"No messages found in input state to tool_edge: {state}")# Router in function of last messageif hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:return "tools_node"return END# Start to build the graphgraph_builder = StateGraph(State)# Add nodes to the graphgraph_builder.add_node("chatbot_node", chatbot_function)graph_builder.add_node("tools_node", basic_tool_node)# Add edgesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_conditional_edges("chatbot_node",route_tools_function,{opening_brace}"tools_node": "tools_node",END: END},)graph_builder.add_edge("tools_node", "chatbot_node")# Compile the graphgraph = graph_builder.compile()# Display the graphtry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")
Error al visualizar el grafo: Failed to reach https://mermaid.ink/ API while trying to render your graph after 1 retries. To resolve this issue:1. Check your internet connection and try again2. Try with higher retry settings: `draw_mermaid_png(..., max_retries=5, retry_delay=2.0)`3. Use the Pyppeteer rendering method which will render your graph locally in a browser: `draw_mermaid_png(..., draw_method=MermaidDrawMethod.PYPPETEER)`
Executamos o grafo
# Colors for the terminalCOLOR_GREEN = "\033[32m"COLOR_YELLOW = "\033[33m"COLOR_RESET = "\033[0m"def stream_graph_updates(user_input: str):for event in graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace}):for value in event.values():print(f"{opening_brace}COLOR_GREEN{closing_brace}User: {opening_brace}COLOR_RESET{closing_brace}{opening_brace}user_input{closing_brace}")print(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}{opening_brace}value['messages'][-1].content{closing_brace}")while True:try:user_input = input("User: ")if user_input.lower() in ["quit", "exit", "q"]:print(f"{opening_brace}COLOR_GREEN{closing_brace}User: {opening_brace}COLOR_RESET{closing_brace}{opening_brace}user_input{closing_brace}")print(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}Goodbye!")breakstream_graph_updates(user_input)except:# fallback if input() is not availableuser_input = "What do you know about LangGraph?"print("User: " + user_input)stream_graph_updates(user_input)break
User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{opening_brace}"title": "Real Madrid 3-2 Leganes: Mbappe, Bellingham inspire comeback to ...", "url": "https://www.nbcsports.com/soccer/news/how-to-watch-real-madrid-vs-leganes-live-stream-link-tv-team-news-prediction", "content": "Real Madrid fought back to beat struggling Leganes 3-2 at the Santiago Bernabeu on Saturday as Kylian Mbappe scored twice and Jude", "score": 0.78749067}, {opening_brace}"title": "Real Madrid vs Leganes 3-2: LaLiga – as it happened - Al Jazeera", "url": "https://www.aljazeera.com/sports/liveblog/2025/3/29/live-real-madrid-vs-leganes-laliga", "content": "Defending champions Real Madrid beat 3-2 Leganes in Spain's LaLiga. The match at Santiago Bernabeu in Madrid, Spain saw Real trail 2-1 at half-", "score": 0.7485182}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{opening_brace}"title": "Real Madrid vs Leganés: Spanish La Liga stats & head-to-head - BBC", "url": "https://www.bbc.com/sport/football/live/cm2ndndvdgmt", "content": "Mbappe scores winner as Real Madrid survive Leganes scare Match Summary Sat 29 Mar 2025 ‧ Spanish La Liga Real Madrid 3 , Leganés 2 at Full time Real MadridReal MadridReal Madrid 3 2 LeganésLeganésLeganés Full time FT Half Time Real Madrid 1 , Leganés 2 HT 1-2 Key Events Real Madrid K. Mbappé (32' pen, 76')Penalty 32 minutes, Goal 76 minutes J. Bellingham (47')Goal 47 minutes Leganés Diego García (34')Goal 34 minutes Dani Raba (41')Goal 41 minutes [...] Good nightpublished at 22:14 Greenwich Mean Time 29 March 22:14 GMT 29 March Thanks for joining us, that was a great game. See you again soon for more La Liga action. 13 2 Share close panel Share page Copy link About sharing Postpublished at 22:10 Greenwich Mean Time 29 March 22:10 GMT 29 March FT: Real Madrid 3-2 Leganes [...] Postpublished at 22:02 Greenwich Mean Time 29 March 22:02 GMT 29 March FT: Real Madrid 3-2 Leganes Over to you, Barcelona. Hansi Flick's side face Girona tomorrow (15:15 BST) and have the chance to regain their three point lead if they are victorious. 18 6 Share close panel Share page Copy link About sharing", "score": 0.86413884}, {opening_brace}"title": "Real Madrid 3 - 2 CD Leganés (03/29) - Game Report - 365Scores", "url": "https://www.365scores.com/en-us/football/match/laliga-11/cd-leganes-real-madrid-131-9242-11", "content": "The game between Real Madrid and CD Leganés ended with a score of Real Madrid 3 - 2 CD Leganés. On 365Scores, you can check all the head-to-head results between", "score": 0.8524574}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{opening_brace}"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Final Score - ESPN", "url": "https://www.espn.com/soccer/match/_/gameId/704946/leganes-real-madrid", "content": "Game Information Santiago Bernabéu 8:00 PM, March 29, 2025Coverage: ESPN Deportes/ESPN+ Madrid, Spain Attendance: 73,641 [...] Match Commentary -Match ends, Real Madrid 3, Leganes 2.90'+9'Second Half ends, Real Madrid 3, Leganes 2.90'+7'Seydouba Cissé (Leganes) wins a free kick in the defensive half. Full Commentary Match Stats RMALEG Possession 70.7% 29.3% Shots on Goal 10 4 Shot Attempts 24 10 Yellow Cards 1 4 Corner Kicks 8 3 Saves 2 6 4-2-3-1 13 Lunin * 20 García * 22 Rüdiger * 35 Asencio * 17 Vázquez 6 Camavinga * 10 Modric 21 Díaz 5 Bellingham * 15 Güler 9 Mbappé [...] | Rayo Vallecano | 35 | 12 | 11 | 12 | -5 | 47 | | Mallorca | 35 | 13 | 8 | 14 | -7 | 47 | | Valencia | 35 | 11 | 12 | 12 | -8 | 45 | | Osasuna | 35 | 10 | 15 | 10 | -8 | 45 | | Real Sociedad | 35 | 12 | 7 | 16 | -9 | 43 | | Getafe | 35 | 10 | 9 | 16 | -3 | 39 | | Espanyol | 35 | 10 | 9 | 16 | -9 | 39 | | Girona | 35 | 10 | 8 | 17 | -12 | 38 | | Sevilla | 35 | 9 | 11 | 15 | -10 | 38 | | Alavés | 35 | 8 | 11 | 16 | -12 | 35 | | Leganés | 35 | 7 | 13 | 15 | -18 | 34 |", "score": 0.93497354}, {opening_brace}"title": "Real Madrid v Leganes | March 29, 2025 | Goal.com US", "url": "https://www.goal.com/en-us/match/real-madrid-vs-leganes/sZTw_SnjyKCcntxKHHQI7", "content": "Latest news, stats and live commentary for the LaLiga's meeting between Real Madrid v Leganes on the March 29, 2025.", "score": 0.921929}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{opening_brace}"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Final Score - ESPN", "url": "https://www.espn.com/soccer/match/_/gameId/704946/leganes-real-madrid", "content": "Game Information Santiago Bernabéu 8:00 PM, March 29, 2025Coverage: ESPN Deportes/ESPN+ Madrid, Spain Attendance: 73,641 [...] Match Commentary -Match ends, Real Madrid 3, Leganes 2.90'+9'Second Half ends, Real Madrid 3, Leganes 2.90'+7'Seydouba Cissé (Leganes) wins a free kick in the defensive half. Full Commentary Match Stats RMALEG Possession 70.7% 29.3% Shots on Goal 10 4 Shot Attempts 24 10 Yellow Cards 1 4 Corner Kicks 8 3 Saves 2 6 4-2-3-1 13 Lunin * 20 García * 22 Rüdiger * 35 Asencio * 17 Vázquez 6 Camavinga * 10 Modric 21 Díaz 5 Bellingham * 15 Güler 9 Mbappé [...] Mbappé nets twice to maintain Madrid title hopes ------------------------------------------------ Kylian Mbappé struck twice to guide Real Madrid to a 3-2 home win over relegation-threatened Leganes on Saturday. Mar 29, 2025, 10:53 pm - Reuters Match Timeline Real Madrid Leganés KO 32 34 41 HT 47 62 62 62 65 66 72 74 76 81 83 86 89 FT", "score": 0.96213967}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{opening_brace}"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Final Score - ESPN", "url": "https://www.espn.com/soccer/match/_/gameId/704946/leganes-real-madrid", "content": "Game Information Santiago Bernabéu 8:00 PM, March 29, 2025Coverage: ESPN Deportes/ESPN+ Madrid, Spain Attendance: 73,641 [...] Match Commentary -Match ends, Real Madrid 3, Leganes 2.90'+9'Second Half ends, Real Madrid 3, Leganes 2.90'+7'Seydouba Cissé (Leganes) wins a free kick in the defensive half. Full Commentary Match Stats RMALEG Possession 70.7% 29.3% Shots on Goal 10 4 Shot Attempts 24 10 Yellow Cards 1 4 Corner Kicks 8 3 Saves 2 6 4-2-3-1 13 Lunin * 20 García * 22 Rüdiger * 35 Asencio * 17 Vázquez 6 Camavinga * 10 Modric 21 Díaz 5 Bellingham * 15 Güler 9 Mbappé [...] -550 o3.5 +105 -1.5 -165 LEGLeganésLeganés (6-9-14) (6-9-14, 27 pts) u3.5 -120 +950 u3.5 -135", "score": 0.9635647}, {opening_brace}"title": "Real Madrid v Leganes | March 29, 2025 | Goal.com US", "url": "https://www.goal.com/en-us/match/real-madrid-vs-leganes/sZTw_SnjyKCcntxKHHQI7", "content": "Latest news, stats and live commentary for the LaLiga's meeting between Real Madrid v Leganes on the March 29, 2025.", "score": 0.95921934}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{opening_brace}"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Final Score - ESPN", "url": "https://www.espn.com/soccer/match/_/gameId/704946/leganes-real-madrid", "content": "Real Madrid 3-2 Leganés (Mar 29, 2025) Final Score - ESPN Real Madrid -Match ends, Real Madrid 3, Leganes 2.90'+9'Second Half ends, Real Madrid 3, Leganes 2.90'+7'Seydouba Cissé (Leganes) wins a free kick in the defensive half. Freedom from Property StressJohn buys bay area houses | [Sponsored](https://popup.taboola.com/en/?template=colorbox&utm_source=espnnetwork-espn&utm_medium=referral&utm_content=thumbs-feed-01-b:gamepackage-thumbnails-3x1-b%20|%20Card%201:)[Sponsored](https://popup.taboola.com/en/?template=colorbox&utm_source=espnnetwork-espn&utm_medium=referral&utm_content=thumbs-feed-01-b:gamepackage-thumbnails-3x1-b%20|%20Card%201:) Get Offer Brand-New 2-Bedroom Senior Apartment in Mountain View: You Won't Believe the Price2-Bedroom Senior Apartment | [Sponsored](https://popup.taboola.com/en/?template=colorbox&utm_source=espnnetwork-espn&utm_medium=referral&utm_content=thumbs-feed-01-b:gamepackage-thumbnails-3x1-b%20|%20Card%201:)[Sponsored](https://popup.taboola.com/en/?template=colorbox&utm_source=espnnetwork-espn&utm_medium=referral&utm_content=thumbs-feed-01-b:gamepackage-thumbnails-3x1-b%20|%20Card%201:) Read More | Real Madrid | 35 | 23 | 6 | 6 | +35 | 75 | Real Madrid woes continue as Vinícius Júnior injury confirmed ------------------------------------------------------------- Injuries to Vinícius Júnior and Lucas Vázquez added to Real Madrid's problems on Monday. To learn more, visit "Do Not Sell or Share My Personal Information" and "Targeted Advertising" Opt-Out Rights.", "score": 0.98565}, {opening_brace}"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Game Analysis - ESPN", "url": "https://www.espn.com/soccer/report/_/gameId/704946", "content": "Real Madrid's Kylian Mbappé struck twice to help his side come from behind to claim a hard-fought 3-2 home win over relegation-threatened", "score": 0.98277}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{opening_brace}"title": "Real Madrid 3 - 2 CD Leganés (03/29) - Game Report - 365Scores", "url": "https://www.365scores.com/en-us/football/match/laliga-11/cd-leganes-real-madrid-131-9242-11", "content": "The game between Real Madrid and CD Leganés in the Regular Season of LaLiga, held on Saturday, March 29, 2025 at Estadio Santiago Bernabéu, ended with a score", "score": 0.96686727}, {opening_brace}"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Final Score - ESPN", "url": "https://www.espn.com/soccer/match/_/gameId/704946/leganes-real-madrid", "content": "Game Information Santiago Bernabéu 8:00 PM, March 29, 2025Coverage: ESPN Deportes/ESPN+ Madrid, Spain Attendance: 73,641 [...] -550 o3.5 +105 -1.5 -165 LEGLeganésLeganés (6-9-14) (6-9-14, 27 pts) u3.5 -120 +950 u3.5 -135 [...] Referees: Pablo González Fuertes", "score": 0.9595845}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: Real Madrid faced CD Leganés in a La Liga match on Saturday, March 29, 2025, at the Estadio Santiago Bernabéu. The match was a thrilling encounter, with Real Madrid coming from behind to secure a 3-2 victory.Key points from the match include:- **Scoreline**: Real Madrid 3, Leganés 2.- **Goals**:- **Real Madrid**: Kylian Mbappé scored twice, including a penalty, and Jude Bellingham also found the net.- **Leganés**: Goals were scored by Diego García and Dani Raba.- **Attendance**: The match was played in front of 73,641 spectators.- **Key Moments**:- Real Madrid trailed 2-1 at half-time but mounted a comeback in the second half.- Mbappé's penalty in the 32nd minute and his second goal in the 76th minute were crucial in turning the game around.- Bellingham's goal in the 47th minute shortly after the break tied the game.This victory is significant for Real Madrid as they continue their push for the La Liga title, while Leganés remains in a difficult position, fighting against relegation.User: Which players played the match?Assistant: I'm sorry, but I need more information to answer your question. Could you please specify which match you're referring to, including the sport, the teams, or any other relevant details? This will help me provide you with the correct information.User: qAssistant: Goodbye!
Voltamos a ver que o problema é que não lembra o contexto da conversação.
Adicionar memória ao chatbot - memória de curto prazo, memória dentro do fio
Nosso chatbot agora pode usar ferramentas para responder perguntas dos usuários, mas não lembra o contexto das interações anteriores. Isso limita sua capacidade de ter conversas coerentes e de múltiplos turnos.
LangGraph resolve este problema através de pontos de verificação persistentes ou checkpoints. Se fornecermos um checkpointer ao compilar o gráfico e um thread_id ao chamar o gráfico, LangGraph salva automaticamente o estado após cada iteração na conversa.
Quando invocarmos o grafo novamente usando o mesmo thread_id, o grafo carregará seu estado salvo, permitindo que o chatbot continue de onde parou.
Veremos mais tarde que esse checkpointing é muito mais poderoso do que a simples memória de chat: permite salvar e retomar estados complexos a qualquer momento para recuperação de erros, fluxos de trabalho com human in the loop, interações no tempo e mais. Mas antes de ver tudo isso, vamos adicionar pontos de controle para permitir conversas de várias iterações.
import osimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")
Para começar, criamos um checkpointer MemorySaver.
from langgraph.checkpoint.memory import MemorySavermemory = MemorySaver()
Aviso>> Estamos usando um
checkpointerna memória, ou seja, ele é armazenado na RAM e quando a execução do grafo terminar, ele será excluído. Isso nos serve para este caso, pois é um exemplo para aprender a usarLangGraph. Em uma aplicação de produção, provavelmente será necessário alterar isso para usá-lo comSqliteSaverouPostgresSavere conectar-se ao nosso próprio banco de dados.
A seguir, definimos o grafo.
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesclass State(TypedDict):messages: Annotated[list, add_messages]graph_builder = StateGraph(State)
Definimos a ferramenta
from langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultswrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)tool = TavilySearchResults(api_wrapper=wrapper, max_results=2)tools_list = [tool]
A seguir, o LLM com as bind_tools e adicionamos ao grafo
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing# Create the LLMlogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Modification: tell the LLM which tools it can callllm_with_tools = llm.bind_tools(tools_list)# Define the chatbot functiondef chatbot_function(state: State):return {opening_brace}"messages": [llm_with_tools.invoke(state["messages"])]}# Add the chatbot nodegraph_builder.add_node("chatbot_node", chatbot_function)
<langgraph.graph.state.StateGraph at 0x1173534d0>
Antes construímos nosso próprio BasicToolNode para aprender como funciona, agora o substituiremos pelo método de LangGraph ToolNode e tools_condition, pois estes fazem algumas coisas boas como a execução paralela de API. Além disso, o resto é igual ao anterior.
from langgraph.prebuilt import ToolNode, tools_conditiontool_node = ToolNode(tools=[tool])graph_builder.add_node("tools", tool_node)
<langgraph.graph.state.StateGraph at 0x1173534d0>
Adicionamos o nó de tools_condition ao grafo
graph_builder.add_conditional_edges("chatbot_node",tools_condition,)
<langgraph.graph.state.StateGraph at 0x1173534d0>
Adicionamos o nó de tools ao gráfico
graph_builder.add_edge("tools", "chatbot_node")
<langgraph.graph.state.StateGraph at 0x1173534d0>
Adicionamos o nódo de START ao grafo
graph_builder.add_edge(START, "chatbot_node")
<langgraph.graph.state.StateGraph at 0x1173534d0>
Compilamos o gráfico adicionando o checkpointer
graph = graph_builder.compile(checkpointer=memory)
O representamos graficamente
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(f"Error al visualizar el grafo: {e}")
Criamos uma configuração com um thread_id de um usuário
USER1_THREAD_ID = "1"config_USER1 = {opening_brace}"configurable": {opening_brace}"thread_id": USER1_THREAD_ID{closing_brace}{closing_brace}
user_input = "Hi there! My name is Maximo."# The config is the **second positional argument** to stream() or invoke()!events = graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace},config_USER1,stream_mode="values",)for event in events:event["messages"][-1].pretty_print()
================================ Human Message =================================Hi there! My name is Maximo.================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: does not reside in any location,{closing_brace}{closing_brace},================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "Determining an individual's tax residency status - IRS", "url": "https://www.irs.gov/individuals/international-taxpayers/determining-an-individuals-tax-residency-status", "content": "If you are not a U.S. citizen, you are considered a nonresident of the United States for U.S. tax purposes unless you meet one of two tests.", "score": 0.1508904}, {opening_brace}"title": "Fix "Location Is Not Available", C:\WINDOWS\system32 ... - YouTube", "url": "https://www.youtube.com/watch?v=QFD-Ptp0SJw", "content": "Fix Error "Location is not available" C:\WINDOWS\system32\config\systemprofile\Desktop is unavailable. If the location is on this PC,", "score": 0.07777658}]================================== Ai Message ==================================Invalid Tool Calls:tavily_search_results_json (0)Call ID: 0Args:{"query": "Arguments["image={"}
user_input = "Do you remember my name?"# The config is the **second positional argument** to stream() or invoke()!events = graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace},config_USER1,stream_mode="values",)for event in events:event["messages"][-1].pretty_print()
================================ Human Message =================================Do you remember my name?================================== Ai Message ==================================Of course! You mentioned your name is Maximo.
Como pode ser visto, não passamos uma lista com as mensagens, tudo está sendo gerenciado pelo checkpointer.
Se agora testarmos com outro usuário, ou seja, com outro thread_id, veremos que o grafo não lembra a conversa anterior.
USER2_THREAD_ID = "2"config_USER2 = {opening_brace}"configurable": {opening_brace}"thread_id": USER2_THREAD_ID{closing_brace}{closing_brace}user_input = "Do you remember my name?"events = graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace},config_USER2,stream_mode="values",)for event in events:event["messages"][-1].pretty_print()
================================ Human Message =================================Do you remember my name?================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: Do you Remember My Name================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "Sam Fender - Remember My Name (Official Video) - YouTube", "url": "https://www.youtube.com/watch?v=uaQm48G6IjY", "content": "Sam Fender - Remember My Name (Official Video) SamFenderVEVO 10743 likes 862209 views 14 Feb 2025 Remember My Name is a love song dedicated to my late Grandparents - they were always so fiercely proud of our family so I wrote the song in honour of them, from the perspective of my Grandad who was looking after my Grandma when she was suffering from dementia. This video is a really special one for me and I want to say thank you to everyone involved in making it. I hope you like it ❤️ [...] If I was wanting of anymore I’d be as greedy as those men on the hill But I remain forlorn In the memory of what once was Chasing a cross in from the wing Our boy’s a whippet, he’s faster than anything Remember the pride that we felt For the two of us made him ourselves Humour me Make my day I’ll tell you stories Kiss your face And I’ll pray You’ll remember My name I’m not sure of what awaits Wasn’t a fan of St Peter and his gates But by god I pray That I’ll see you in some way [...] Oh 11 Walk Avenue Something to behold To them it’s a council house To me it’s a home And a home that you made Where the grandkids could play But it’s never the same without you Humour me Make my day I’ll tell you stories I’ll kiss your face And I’ll pray You’ll remember My name And I’ll pray you remember my name And I’ll pray you remember my name ---", "score": 0.6609831}, {opening_brace}"title": "Do You Remember My Name? - Novel Updates", "url": "https://www.novelupdates.com/series/do-you-remember-my-name/", "content": "This is a Cute, Tender, and Heartwarming High School Romance. It's not Heavy. It's not so Emotional too, but it does have Emotional moments. It's story Full of", "score": 0.608897}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: do you remember my name================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "Sam Fender - Remember My Name (Official Video) - YouTube", "url": "https://www.youtube.com/watch?v=uaQm48G6IjY", "content": "Sam Fender - Remember My Name (Official Video) SamFenderVEVO 10743 likes 862209 views 14 Feb 2025 Remember My Name is a love song dedicated to my late Grandparents - they were always so fiercely proud of our family so I wrote the song in honour of them, from the perspective of my Grandad who was looking after my Grandma when she was suffering from dementia. This video is a really special one for me and I want to say thank you to everyone involved in making it. I hope you like it ❤️ [...] Oh 11 Walk Avenue Something to behold To them it’s a council house To me it’s a home And a home that you made Where the grandkids could play But it’s never the same without you Humour me Make my day I’ll tell you stories I’ll kiss your face And I’ll pray You’ll remember My name And I’ll pray you remember my name And I’ll pray you remember my name --- [...] If I was wanting of anymore I’d be as greedy as those men on the hill But I remain forlorn In the memory of what once was Chasing a cross in from the wing Our boy’s a whippet, he’s faster than anything Remember the pride that we felt For the two of us made him ourselves Humour me Make my day I’ll tell you stories Kiss your face And I’ll pray You’ll remember My name I’m not sure of what awaits Wasn’t a fan of St Peter and his gates But by god I pray That I’ll see you in some way", "score": 0.7123327}, {opening_brace}"title": "Do you remember my name? - song and lyrics by Alea, Mama Marjas", "url": "https://open.spotify.com/track/3GVBn3rEQLxZl4zJ4dG8UJ", "content": "Listen to Do you remember my name? on Spotify. Song · Alea, Mama Marjas · 2023.", "score": 0.6506676}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: do you remember my name================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "Sam Fender - Remember My Name (Official Video) - YouTube", "url": "https://www.youtube.com/watch?v=uaQm48G6IjY", "content": "Sam Fender - Remember My Name (Official Video) SamFenderVEVO 10743 likes 862209 views 14 Feb 2025 Remember My Name is a love song dedicated to my late Grandparents - they were always so fiercely proud of our family so I wrote the song in honour of them, from the perspective of my Grandad who was looking after my Grandma when she was suffering from dementia. This video is a really special one for me and I want to say thank you to everyone involved in making it. I hope you like it ❤️ [...] Oh 11 Walk Avenue Something to behold To them it’s a council house To me it’s a home And a home that you made Where the grandkids could play But it’s never the same without you Humour me Make my day I’ll tell you stories I’ll kiss your face And I’ll pray You’ll remember My name And I’ll pray you remember my name And I’ll pray you remember my name --- [...] If I was wanting of anymore I’d be as greedy as those men on the hill But I remain forlorn In the memory of what once was Chasing a cross in from the wing Our boy’s a whippet, he’s faster than anything Remember the pride that we felt For the two of us made him ourselves Humour me Make my day I’ll tell you stories Kiss your face And I’ll pray You’ll remember My name I’m not sure of what awaits Wasn’t a fan of St Peter and his gates But by god I pray That I’ll see you in some way", "score": 0.7123327}, {opening_brace}"title": "Do you remember my name? - song and lyrics by Alea, Mama Marjas", "url": "https://open.spotify.com/track/3GVBn3rEQLxZl4zJ4dG8UJ", "content": "Listen to Do you remember my name? on Spotify. Song · Alea, Mama Marjas · 2023.", "score": 0.6506676}]================================== Ai Message ==================================I'm here to assist you, but I don't actually have the ability to remember names or personal information from previous conversations. How can I assist you today?
Agora que nosso chatbot tem ferramentas de busca e memória, vamos repetir o exemplo anterior, onde pergunto sobre o resultado do último jogo do Real Madrid na Liga e depois quais jogadores atuaram.
USER3_THREAD_ID = "3"config_USER3 = {opening_brace}"configurable": {opening_brace}"thread_id": USER3_THREAD_ID{closing_brace}{closing_brace}user_input = "How did Real Madrid fare this weekend against Leganes in La Liga?"events = graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace},config_USER3,stream_mode="values",)for event in events:event["messages"][-1].pretty_print()
================================ Human Message =================================How did Real Madrid fare this weekend against Leganes in La Liga?================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: Real Madrid vs Leganes La Liga this weekend================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "Real Madrid 3-2 Leganes: Goals and highlights - LaLiga 24/25 | Marca", "url": "https://www.marca.com/en/soccer/laliga/r-madrid-leganes/2025/03/29/01_0101_20250329_186_957-live.html", "content": "While their form has varied throughout the campaign there is no denying Real Madrid are a force at home in LaLiga this season, as they head into Saturday's match having picked up 34 points from 13 matches. As for Leganes they currently sit 18th in the table, though they are level with Alaves for 17th as both teams look to stay in the top flight. [...] The two teams have already played twice this season, with Real Madrid securing a 3-0 win in the reverse league fixture. They also met in the quarter-finals of the Copa del Rey, a game Real won 3-2. Real Madrid vs Leganes LIVE - Latest Updates Match ends, Real Madrid 3, Leganes 2. Second Half ends, Real Madrid 3, Leganes 2. Foul by Vinícius Júnior (Real Madrid). Seydouba Cissé (Leganes) wins a free kick in the defensive half. [...] Goal! Real Madrid 1, Leganes 1. Diego García (Leganes) left footed shot from very close range. Attempt missed. Óscar Rodríguez (Leganes) left footed shot from the centre of the box. Goal! Real Madrid 1, Leganes 0. Kylian Mbappé (Real Madrid) converts the penalty with a right footed shot. Penalty Real Madrid. Arda Güler draws a foul in the penalty area. Penalty conceded by Óscar Rodríguez (Leganes) after a foul in the penalty area. Delay over. They are ready to continue.", "score": 0.8548001}, {opening_brace}"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Game Analysis - ESPN", "url": "https://www.espn.com/soccer/report/_/gameId/704946", "content": "Real Madrid Leganés Mbappé nets twice to keep Real Madrid's title hopes alive Real Madrid vs. Leganés - Game Highlights Watch the Game Highlights from Real Madrid vs. Leganés, 03/30/2025 Real Madrid's Kylian Mbappé struck twice to help his side come from behind to claim a hard-fought 3-2 home win over relegation-threatened Leganes on Saturday to move the second-placed reigning champions level on points with leaders Barcelona. [...] Leganes pushed for an equaliser but fell to a third consecutive defeat to sit 18th on 27 points, level with Alaves who are one place higher in the safety zone on goal difference. "We have done a tremendous job. We leave with our heads held high because we were fighting until the end to score here," Leganes striker Garcia said. "Ultimately, it was down to the details that they took it. We played a very serious game and now we have to think about next week." Game Information", "score": 0.82220376}]================================== Ai Message ==================================Real Madrid secured a 3-2 victory against Leganes this weekend in their La Liga match. Kylian Mbappé scored twice, including a penalty, to help his team come from behind and claim the win, keeping Real Madrid's title hopes alive. Leganes, now sitting 18th in the table, continues to face challenges in their fight against relegation.
Agora perguntamos pelos jogadores que participaram na partida.
user_input = "Which players played the match?"events = graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace},config_USER3,stream_mode="values",)for event in events:event["messages"][-1].pretty_print()
================================ Human Message =================================Which players played the match?================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: Real Madrid vs Leganes match report players lineup================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "Real Madrid vs. Leganes final score: La Liga result, updates, stats ...", "url": "https://www.sportingnews.com/us/soccer/news/real-madrid-leganes-score-result-updates-stats-la-liga/8ecf730cfcb9b6c5f6693a0d", "content": "Real Madrid came through a topsy-turvy game with Leganes to claim a 3-2 victory and put pressure back on Barcelona in La Liga's title race. Kylian Mbappe scored in each half either side of a Jude Bellingham goal — his first in the league since January 3 — to seal all three points for the champions after Leganes had come from behind to lead at the interval. Rodrygo won back the ball in the Leganes half and earned a free-kick on the edge of the box, and Mbappe found the bottom corner after rolling the ball short to Fran Garcia to work an angle. Leganes lead Real Madrid at the Bernabeu for the very first time! *Real Madrid starting lineup (4-3-3, right to left):* Lunin (GK) — Vazquez, Rudiger, Asencio, Garcia — Modric, Bellingham, Camavinga — B.", "score": 0.88372874}, {opening_brace}"title": "CONFIRMED lineups: Real Madrid vs Leganés, 2025 La Liga", "url": "https://www.managingmadrid.com/2025/3/29/24396638/real-madrid-vs-leganes-2025-la-liga-live-online-stream", "content": "Real Madrid starting XI: Lunin, Vazquez, Rudiger, Asencio, Fran Garcia, Camavinga, Guler, Modric, Bellingham, Brahim, Mbappe. Leganes starting", "score": 0.83452857}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: Real Madrid vs Leganes players 2025================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "Player Ratings: Real Madrid 3-2 Leganes; 2025 La Liga", "url": "https://www.managingmadrid.com/2025/3/30/24396688/player-ratings-real-madrid-3-2-leganes-2025-la-liga", "content": "Raúl Asencio—7: Applauded by the Bernabeu on multiple occasions with good sweeping up defensively. Fran García—6: Better on the offensive end, getting into the final third and playing some dagger crosses. Eduardo Camavinga—6: Modric and Camavinga struggled to deal with Leganes counter attacks and Diego, playing as a #10 for Leganes, got the better of both of them. [...] Follow Managing Madrid online: Site search Managing Madrid main menu Filed under: Player Ratings: Real Madrid 3-2 Leganes; 2025 La Liga Kylian Mbappe scores a brace to help Madrid secure a nervy 3-2 victory. Share this story Share All sharing options for: Player Ratings: Real Madrid 3-2 Leganes; 2025 La Liga Full match player ratings below: Andriy Lunin—7: Not at fault for the goals, was left with the opposition taking a shot from near the six yard box. [...] Lucas Vázquez—4: Exposed in transition and lacking the speed and athleticism to cover the gaps he leaves when venturing forward. Needs a more “pessimistic” attitude when the ball is on the opposite flank, occupying better spots in ““rest defense”. Antonio Rudiger—5: Several unnecessary long distance shots to hurt Madrid’s rhythm and reinforce Leganes game plan. Playing with too many matches in his legs and it’s beginning to show.", "score": 0.8832463}, {opening_brace}"title": "Real Madrid vs. Leganés (Mar 29, 2025) Live Score - ESPN", "url": "https://www.espn.com/soccer/match/_/gameId/704946", "content": "Match Formations · 13. Lunin · 20. García · 22. Rüdiger · 35. Asencio · 17. Vázquez · 5. Bellingham · 10. Modric · 6. Camavinga.", "score": 0.86413884}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: Real Madrid vs Leganes starting lineup================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "Starting lineups of Real Madrid and Leganés", "url": "https://www.realmadrid.com/en-US/news/football/first-team/latest-news/once-inicial-del-real-madrid-contra-el-leganes-29-03-2025", "content": "Starting lineups of Real Madrid and Leganés The Whitesâ team is: Lunin, Lucas V., Asencio, Rüdiger, Fran GarcÃa, Arda Güler, ModriÄ, Camavinga, Bellingham, Brahim and Mbappé. Real Madrid have named their starting line-up for the game against Leganés on matchday 29 of LaLiga, which will be played at the Santiago Bernabéu (9 pm CET). [...] Real Madrid starting line-up: 13. Lunin 17. Lucas V. 35. Asencio 22. Rüdiger 20. Fran GarcÃa 15. Arda Güler 10. ModriÄ 6. Camavinga 5. Bellingham 21. Brahim 9. Mbappé. Substitutes: 26. Fran González 34. Sergio Mestre 4. Alaba 7. Vini Jr. 8. Valverde 11. Rodrygo 14. Tchouameni 16. Endrick 18. Vallejo 43. Diego Aguado. Leganés starting line-up: 13. Dmitrovic 5. Tapia 6. Sergio G. 7. Ãscar 10. Raba 11. Cruz 12. V. Rosier 17. Neyou 19. Diego G. 20. Javi Hernández 22. Nastasic. [...] Suplentes: 1. Juan Soriano 36. Abajas 2. A. Alti 3. Jorge Sáenz 8. Cisse 9. Miguel 14. Darko 18. Duk 21. R. López 23. Munir 24. Chicco 30. I. Diomande. Download Now Official App Fan Real Madrid © 2025 All rights reserved", "score": 0.9465623}, {opening_brace}"title": "Real Madrid vs. Leganes lineups, confirmed starting 11, team news ...", "url": "https://www.sportingnews.com/us/soccer/news/real-madrid-leganes-lineups-starting-11-team-news-injuries/aac757d10cc7b9a084995b4d", "content": "Real Madrid starting lineup (4-3-3, right to left): Lunin (GK) — Vazquez, Rudiger, Asencio, Garcia — Modric, Bellingham, Camavinga — B. Diaz,", "score": 0.9224337}]================================== Ai Message ==================================The starting lineup for Real Madrid in their match against Leganés was: Lunin (GK), Vázquez, Rüdiger, Asencio, Fran García, Modric, Bellingham, Camavinga, Brahim, Arda Güler, and Mbappé. Notable players like Vini Jr., Rodrygo, and Valverde were on the bench.
Depois de muito procurar, ele finalmente o encontra. Então agora temos um chatbot com tools e memória.
Até agora, criamos alguns checkpoints em três threads diferentes. Mas, o que entra em cada checkpoint? Para inspecionar o estado de um grafo para uma configuração dada, podemos usar o método get_state(config).
snapshot = graph.get_state(config_USER3)snapshot
StateSnapshot(values={opening_brace}'messages': [HumanMessage(content='How did Real Madrid fare this weekend against Leganes in La Liga?', additional_kwargs={opening_brace}{closing_brace}, response_metadata={opening_brace}{closing_brace}, id='a33f5825-1ae4-4717-ad17-8e306f35b027'), AIMessage(content='', additional_kwargs={opening_brace}'tool_calls': [{opening_brace}'function': {'arguments': {opening_brace}'query': 'Real Madrid vs Leganes La Liga this weekend'{closing_brace}, 'name': 'tavily_search_results_json', 'description': None}, 'id': '0', 'type': 'function'{closing_brace}]}, response_metadata={opening_brace}'token_usage': {'completion_tokens': 25, 'prompt_tokens': 296, 'total_tokens': 321}, 'model': '', 'finish_reason': 'stop'{closing_brace}, id='run-7905b5ae-5dee-4641-b012-396affde984c-0', tool_calls=[{opening_brace}'name': 'tavily_search_results_json', 'args': {opening_brace}'query': 'Real Madrid vs Leganes La Liga this weekend'{closing_brace}, 'id': '0', 'type': 'tool_call'{closing_brace}]), ToolMessage(content='[{opening_brace}"title": "Real Madrid 3-2 Leganes: Goals and highlights - LaLiga 24/25 | Marca", "url": "https://www.marca.com/en/soccer/laliga/r-madrid-leganes/2025/03/29/01_0101_20250329_186_957-live.html", "content": "While their form has varied throughout the campaign there is no denying Real Madrid are a force at home in LaLiga this season, as they head into Saturday's match having picked up 34 points from 13 matches.\n\nAs for Leganes they currently sit 18th in the table, though they are level with Alaves for 17th as both teams look to stay in the top flight. [...] The two teams have already played twice this season, with Real Madrid securing a 3-0 win in the reverse league fixture. They also met in the quarter-finals of the Copa del Rey, a game Real won 3-2.\n\nReal Madrid vs Leganes LIVE - Latest Updates\n\nMatch ends, Real Madrid 3, Leganes 2.\n\nSecond Half ends, Real Madrid 3, Leganes 2.\n\nFoul by Vinícius Júnior (Real Madrid).\n\nSeydouba Cissé (Leganes) wins a free kick in the defensive half. [...] Goal! Real Madrid 1, Leganes 1. Diego García (Leganes) left footed shot from very close range.\n\nAttempt missed. Óscar Rodríguez (Leganes) left footed shot from the centre of the box.\n\nGoal! Real Madrid 1, Leganes 0. Kylian Mbappé (Real Madrid) converts the penalty with a right footed shot.\n\nPenalty Real Madrid. Arda Güler draws a foul in the penalty area.\n\nPenalty conceded by Óscar Rodríguez (Leganes) after a foul in the penalty area.\n\nDelay over. They are ready to continue.", "score": 0.8548001}, {opening_brace}"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Game Analysis - ESPN", "url": "https://www.espn.com/soccer/report/_/gameId/704946", "content": "Real Madrid\n\nLeganés\n\nMbappé nets twice to keep Real Madrid's title hopes alive\n\nReal Madrid vs. Leganés - Game Highlights\n\nWatch the Game Highlights from Real Madrid vs. Leganés, 03/30/2025\n\nReal Madrid's Kylian Mbappé struck twice to help his side come from behind to claim a hard-fought 3-2 home win over relegation-threatened Leganes on Saturday to move the second-placed reigning champions level on points with leaders Barcelona. [...] Leganes pushed for an equaliser but fell to a third consecutive defeat to sit 18th on 27 points, level with Alaves who are one place higher in the safety zone on goal difference.\n\n\"We have done a tremendous job. We leave with our heads held high because we were fighting until the end to score here,\" Leganes striker Garcia said.\n\n\"Ultimately, it was down to the details that they took it. We played a very serious game and now we have to think about next week.\"\n\nGame Information", "score": 0.82220376}]', name='tavily_search_results_json', id='0e02fce3-a6f0-4cce-9217-04c8c3219265', tool_call_id='0', artifact={opening_brace}'query': 'Real Madrid vs Leganes La Liga this weekend', 'follow_up_questions': None, 'answer': None, 'images': [], 'results': [{'url': 'https://www.marca.com/en/soccer/laliga/r-madrid-leganes/2025/03/29/01_0101_20250329_186_957-live.html', 'title': 'Real Madrid 3-2 Leganes: Goals and highlights - LaLiga 24/25 | Marca', 'content': "While their form has varied throughout the campaign there is no denying Real Madrid are a force at home in LaLiga this season, as they head into Saturday's match having picked up 34 points from 13 matches. As for Leganes they currently sit 18th in the table, though they are level with Alaves for 17th as both teams look to stay in the top flight. [...] The two teams have already played twice this season, with Real Madrid securing a 3-0 win in the reverse league fixture. They also met in the quarter-finals of the Copa del Rey, a game Real won 3-2. Real Madrid vs Leganes LIVE - Latest Updates Match ends, Real Madrid 3, Leganes 2. Second Half ends, Real Madrid 3, Leganes 2. Foul by Vinícius Júnior (Real Madrid). Seydouba Cissé (Leganes) wins a free kick in the defensive half. [...] Goal! Real Madrid 1, Leganes 1. Diego García (Leganes) left footed shot from very close range. Attempt missed. Óscar Rodríguez (Leganes) left footed shot from the centre of the box. Goal! Real Madrid 1, Leganes 0. Kylian Mbappé (Real Madrid) converts the penalty with a right footed shot. Penalty Real Madrid. Arda Güler draws a foul in the penalty area. Penalty conceded by Óscar Rodríguez (Leganes) after a foul in the penalty area. Delay over. They are ready to continue.", 'score': 0.8548001, 'raw_content': None}, {'url': 'https://www.espn.com/soccer/report/_/gameId/704946', 'title': 'Real Madrid 3-2 Leganés (Mar 29, 2025) Game Analysis - ESPN', 'content': 'Real Madrid Leganés Mbappé nets twice to keep Real Madrid's title hopes alive Real Madrid vs. Leganés - Game Highlights Watch the Game Highlights from Real Madrid vs. Leganés, 03/30/2025 Real Madrid's Kylian Mbappé struck twice to help his side come from behind to claim a hard-fought 3-2 home win over relegation-threatened Leganes on Saturday to move the second-placed reigning champions level on points with leaders Barcelona. [...] Leganes pushed for an equaliser but fell to a third consecutive defeat to sit 18th on 27 points, level with Alaves who are one place higher in the safety zone on goal difference. "We have done a tremendous job. We leave with our heads held high because we were fighting until the end to score here," Leganes striker Garcia said. "Ultimately, it was down to the details that they took it. We played a very serious game and now we have to think about next week." Game Information', 'score': 0.82220376, 'raw_content': None}], 'response_time': 1.47}), AIMessage(content="Real Madrid secured a 3-2 victory against Leganes this weekend in their La Liga match. Kylian Mbappé scored twice, including a penalty, to help his team come from behind and claim the win, keeping Real Madrid's title hopes alive. Leganes, now sitting 18th in the table, continues to face challenges in their fight against relegation.", additional_kwargs={opening_brace}{closing_brace}, response_metadata={opening_brace}'token_usage': {'completion_tokens': 92, 'prompt_tokens': 1086, 'total_tokens': 1178}, 'model': '', 'finish_reason': 'stop'{closing_brace}, id='run-22226dda-0475-49b7-882f-fe7bd63ef025-0'), HumanMessage(content='Which players played the match?', additional_kwargs={opening_brace}{closing_brace}, response_metadata={opening_brace}{closing_brace}, id='3e6d9f84-06a2-4148-8f2b-d8ef42c3bea1'), AIMessage(content='', additional_kwargs={opening_brace}'tool_calls': [{opening_brace}'function': {'arguments': {opening_brace}'query': 'Real Madrid vs Leganes match report players lineup'{closing_brace}, 'name': 'tavily_search_results_json', 'description': None}, 'id': '0', 'type': 'function'{closing_brace}]}, response_metadata={opening_brace}'token_usage': {'completion_tokens': 29, 'prompt_tokens': 1178, 'total_tokens': 1207}, 'model': '', 'finish_reason': 'stop'{closing_brace}, id='run-025d3235-61b9-4add-8e1b-5b1bc795a9d3-0', tool_calls=[{opening_brace}'name': 'tavily_search_results_json', 'args': {opening_brace}'query': 'Real Madrid vs Leganes match report players lineup'{closing_brace}, 'id': '0', 'type': 'tool_call'{closing_brace}]), ToolMessage(content='[{opening_brace}"title": "Real Madrid vs. Leganes final score: La Liga result, updates, stats ...", "url": "https://www.sportingnews.com/us/soccer/news/real-madrid-leganes-score-result-updates-stats-la-liga/8ecf730cfcb9b6c5f6693a0d", "content": "Real Madrid came through a topsy-turvy game with Leganes to claim a 3-2 victory and put pressure back on Barcelona in La Liga's title race. Kylian Mbappe scored in each half either side of a Jude Bellingham goal — his first in the league since January 3 — to seal all three points for the champions after Leganes had come from behind to lead at the interval. Rodrygo won back the ball in the Leganes half and earned a free-kick on the edge of the box, and Mbappe found the bottom corner after rolling the ball short to Fran Garcia to work an angle. Leganes lead Real Madrid at the Bernabeu for the very first time! *Real Madrid starting lineup (4-3-3, right to left):* Lunin (GK) — Vazquez, Rudiger, Asencio, Garcia — Modric, Bellingham, Camavinga — B.", "score": 0.88372874}, {opening_brace}"title": "CONFIRMED lineups: Real Madrid vs Leganés, 2025 La Liga", "url": "https://www.managingmadrid.com/2025/3/29/24396638/real-madrid-vs-leganes-2025-la-liga-live-online-stream", "content": "Real Madrid starting XI: Lunin, Vazquez, Rudiger, Asencio, Fran Garcia, Camavinga, Guler, Modric, Bellingham, Brahim, Mbappe. Leganes starting", "score": 0.83452857}]', name='tavily_search_results_json', id='2dbc1324-2c20-406a-b2d7-a3d6fc609537', tool_call_id='0', artifact={opening_brace}'query': 'Real Madrid vs Leganes match report players lineup', 'follow_up_questions': None, 'answer': None, 'images': [], 'results': [{'url': 'https://www.sportingnews.com/us/soccer/news/real-madrid-leganes-score-result-updates-stats-la-liga/8ecf730cfcb9b6c5f6693a0d', 'title': 'Real Madrid vs. Leganes final score: La Liga result, updates, stats ...', 'content': "Real Madrid came through a topsy-turvy game with Leganes to claim a 3-2 victory and put pressure back on Barcelona in La Liga's title race. Kylian Mbappe scored in each half either side of a Jude Bellingham goal — his first in the league since January 3 — to seal all three points for the champions after Leganes had come from behind to lead at the interval. Rodrygo won back the ball in the Leganes half and earned a free-kick on the edge of the box, and Mbappe found the bottom corner after rolling the ball short to Fran Garcia to work an angle. Leganes lead Real Madrid at the Bernabeu for the very first time! *Real Madrid starting lineup (4-3-3, right to left):* Lunin (GK) — Vazquez, Rudiger, Asencio, Garcia — Modric, Bellingham, Camavinga — B.", 'score': 0.88372874, 'raw_content': None}, {'url': 'https://www.managingmadrid.com/2025/3/29/24396638/real-madrid-vs-leganes-2025-la-liga-live-online-stream', 'title': 'CONFIRMED lineups: Real Madrid vs Leganés, 2025 La Liga', 'content': 'Real Madrid starting XI: Lunin, Vazquez, Rudiger, Asencio, Fran Garcia, Camavinga, Guler, Modric, Bellingham, Brahim, Mbappe. Leganes starting', 'score': 0.83452857, 'raw_content': None}], 'response_time': 3.36}), AIMessage(content='', additional_kwargs={opening_brace}'tool_calls': [{opening_brace}'function': {'arguments': {opening_brace}'query': 'Real Madrid vs Leganes players 2025'{closing_brace}, 'name': 'tavily_search_results_json', 'description': None}, 'id': '0', 'type': 'function'{closing_brace}]}, response_metadata={opening_brace}'token_usage': {'completion_tokens': 31, 'prompt_tokens': 1630, 'total_tokens': 1661}, 'model': '', 'finish_reason': 'stop'{closing_brace}, id='run-d6b4c4ff-0923-4082-9dea-7c51b2a4fc60-0', tool_calls=[{opening_brace}'name': 'tavily_search_results_json', 'args': {opening_brace}'query': 'Real Madrid vs Leganes players 2025'{closing_brace}, 'id': '0', 'type': 'tool_call'{closing_brace}]), ToolMessage(content='[{opening_brace}"title": "Player Ratings: Real Madrid 3-2 Leganes; 2025 La Liga", "url": "https://www.managingmadrid.com/2025/3/30/24396688/player-ratings-real-madrid-3-2-leganes-2025-la-liga", "content": "Raúl Asencio—7: Applauded by the Bernabeu on multiple occasions with good sweeping up defensively.\n\nFran García—6: Better on the offensive end, getting into the final third and playing some dagger crosses.\n\nEduardo Camavinga—6: Modric and Camavinga struggled to deal with Leganes counter attacks and Diego, playing as a #10 for Leganes, got the better of both of them. [...] Follow Managing Madrid online:\n\nSite search\n\nManaging Madrid main menu\n\nFiled under:\n\nPlayer Ratings: Real Madrid 3-2 Leganes; 2025 La Liga\n\nKylian Mbappe scores a brace to help Madrid secure a nervy 3-2 victory.\n\nShare this story\n\nShare\nAll sharing options for:\nPlayer Ratings: Real Madrid 3-2 Leganes; 2025 La Liga\n\nFull match player ratings below:\n\nAndriy Lunin—7: Not at fault for the goals, was left with the opposition taking a shot from near the six yard box. [...] Lucas Vázquez—4: Exposed in transition and lacking the speed and athleticism to cover the gaps he leaves when venturing forward. Needs a more “pessimistic” attitude when the ball is on the opposite flank, occupying better spots in ““rest defense”.\n\nAntonio Rudiger—5: Several unnecessary long distance shots to hurt Madrid’s rhythm and reinforce Leganes game plan. Playing with too many matches in his legs and it’s beginning to show.", "score": 0.8832463}, {opening_brace}"title": "Real Madrid vs. Leganés (Mar 29, 2025) Live Score - ESPN", "url": "https://www.espn.com/soccer/match/_/gameId/704946", "content": "Match Formations · 13. Lunin · 20. García · 22. Rüdiger · 35. Asencio · 17. Vázquez · 5. Bellingham · 10. Modric · 6. Camavinga.", "score": 0.86413884}]', name='tavily_search_results_json', id='ac15dd6e-09b1-4075-834e-d869f4079285', tool_call_id='0', artifact={opening_brace}'query': 'Real Madrid vs Leganes players 2025', 'follow_up_questions': None, 'answer': None, 'images': [], 'results': [{'url': 'https://www.managingmadrid.com/2025/3/30/24396688/player-ratings-real-madrid-3-2-leganes-2025-la-liga', 'title': 'Player Ratings: Real Madrid 3-2 Leganes; 2025 La Liga', 'content': 'Raúl Asencio—7: Applauded by the Bernabeu on multiple occasions with good sweeping up defensively. Fran García—6: Better on the offensive end, getting into the final third and playing some dagger crosses. Eduardo Camavinga—6: Modric and Camavinga struggled to deal with Leganes counter attacks and Diego, playing as a #10 for Leganes, got the better of both of them. [...] Follow Managing Madrid online: Site search Managing Madrid main menu Filed under: Player Ratings: Real Madrid 3-2 Leganes; 2025 La Liga Kylian Mbappe scores a brace to help Madrid secure a nervy 3-2 victory. Share this story Share All sharing options for: Player Ratings: Real Madrid 3-2 Leganes; 2025 La Liga Full match player ratings below: Andriy Lunin—7: Not at fault for the goals, was left with the opposition taking a shot from near the six yard box. [...] Lucas Vázquez—4: Exposed in transition and lacking the speed and athleticism to cover the gaps he leaves when venturing forward. Needs a more “pessimistic” attitude when the ball is on the opposite flank, occupying better spots in ““rest defense”. Antonio Rudiger—5: Several unnecessary long distance shots to hurt Madrid’s rhythm and reinforce Leganes game plan. Playing with too many matches in his legs and it’s beginning to show.', 'score': 0.8832463, 'raw_content': None}, {'url': 'https://www.espn.com/soccer/match/_/gameId/704946', 'title': 'Real Madrid vs. Leganés (Mar 29, 2025) Live Score - ESPN', 'content': 'Match Formations · 13. Lunin · 20. García · 22. Rüdiger · 35. Asencio · 17. Vázquez · 5. Bellingham · 10. Modric · 6. Camavinga.', 'score': 0.86413884, 'raw_content': None}], 'response_time': 0.89}), AIMessage(content='', additional_kwargs={opening_brace}'tool_calls': [{opening_brace}'function': {'arguments': {opening_brace}'query': 'Real Madrid vs Leganes starting lineup'{closing_brace}, 'name': 'tavily_search_results_json', 'description': None}, 'id': '0', 'type': 'function'{closing_brace}]}, response_metadata={opening_brace}'token_usage': {'completion_tokens': 27, 'prompt_tokens': 2212, 'total_tokens': 2239}, 'model': '', 'finish_reason': 'stop'{closing_brace}, id='run-68867df1-2012-47ac-9f01-42b071ef3a1f-0', tool_calls=[{opening_brace}'name': 'tavily_search_results_json', 'args': {opening_brace}'query': 'Real Madrid vs Leganes starting lineup'{closing_brace}, 'id': '0', 'type': 'tool_call'{closing_brace}]), ToolMessage(content='[{opening_brace}"title": "Starting lineups of Real Madrid and Leganés", "url": "https://www.realmadrid.com/en-US/news/football/first-team/latest-news/once-inicial-del-real-madrid-contra-el-leganes-29-03-2025", "content": "Starting lineups of Real Madrid and Leganés\n\n\n\nThe Whitesâ team is: Lunin, Lucas V., Asencio, Rüdiger, Fran GarcÃa, Arda Güler, ModriÄ, Camavinga, Bellingham, Brahim and Mbappé.\n\n\n\n\n\nReal Madrid have named their starting line-up for the game against Leganés on matchday 29 of LaLiga, which will be played at the Santiago Bernabéu (9 pm CET). [...] Real Madrid starting line-up:\n13. Lunin\n17. Lucas V.\n35. Asencio\n22. Rüdiger\n20. Fran GarcÃa\n15. Arda Güler\n10. ModriÄ\n6. Camavinga\n5. Bellingham\n21. Brahim\n9. Mbappé.\n\nSubstitutes:\n26. Fran González\n34. Sergio Mestre\n4. Alaba\n7. Vini Jr.\n8. Valverde\n11. Rodrygo\n14. Tchouameni\n16. Endrick\n18. Vallejo\n43. Diego Aguado.\n\nLeganés starting line-up:\n13. Dmitrovic\n5. Tapia\n6. Sergio G.\n7. Ãscar\n10. Raba\n11. Cruz\n12. V. Rosier\n17. Neyou\n19. Diego G.\n20. Javi Hernández\n22. Nastasic. [...] Suplentes:\n1. Juan Soriano\n36. Abajas\n2. A. Alti\n3. Jorge Sáenz\n8. Cisse\n9. Miguel\n14. Darko\n18. Duk\n21. R. López\n23. Munir\n24. Chicco\n30. I. Diomande.\n\n\n\nDownload Now\n\nOfficial App Fan\n\nReal Madrid © 2025 All rights reserved", "score": 0.9465623}, {opening_brace}"title": "Real Madrid vs. Leganes lineups, confirmed starting 11, team news ...", "url": "https://www.sportingnews.com/us/soccer/news/real-madrid-leganes-lineups-starting-11-team-news-injuries/aac757d10cc7b9a084995b4d", "content": "Real Madrid starting lineup (4-3-3, right to left): Lunin (GK) — Vazquez, Rudiger, Asencio, Garcia — Modric, Bellingham, Camavinga — B. Diaz,", "score": 0.9224337}]', name='tavily_search_results_json', id='46721f2b-2df2-4da2-831a-ce94f6b4ff8f', tool_call_id='0', artifact={opening_brace}'query': 'Real Madrid vs Leganes starting lineup', 'follow_up_questions': None, 'answer': None, 'images': [], 'results': [{'url': 'https://www.realmadrid.com/en-US/news/football/first-team/latest-news/once-inicial-del-real-madrid-contra-el-leganes-29-03-2025', 'title': 'Starting lineups of Real Madrid and Leganés', 'content': 'Starting lineups of Real Madrid and Leganés The Whitesâ team is: Lunin, Lucas V., Asencio, Rüdiger, Fran GarcÃa, Arda Güler, ModriÄ, Camavinga, Bellingham, Brahim and Mbappé. Real Madrid have named their starting line-up for the game against Leganés on matchday 29 of LaLiga, which will be played at the Santiago Bernabéu (9 pm CET). [...] Real Madrid starting line-up: 13. Lunin 17. Lucas V. 35. Asencio 22. Rüdiger 20. Fran GarcÃa 15. Arda Güler 10. ModriÄ 6. Camavinga 5. Bellingham 21. Brahim 9. Mbappé. Substitutes: 26. Fran González 34. Sergio Mestre 4. Alaba 7. Vini Jr. 8. Valverde 11. Rodrygo 14. Tchouameni 16. Endrick 18. Vallejo 43. Diego Aguado. Leganés starting line-up: 13. Dmitrovic 5. Tapia 6. Sergio G. 7. Ãscar 10. Raba 11. Cruz 12. V. Rosier 17. Neyou 19. Diego G. 20. Javi Hernández 22. Nastasic. [...] Suplentes: 1. Juan Soriano 36. Abajas 2. A. Alti 3. Jorge Sáenz 8. Cisse 9. Miguel 14. Darko 18. Duk 21. R. López 23. Munir 24. Chicco 30. I. Diomande. Download Now Official App Fan Real Madrid © 2025 All rights reserved', 'score': 0.9465623, 'raw_content': None}, {'url': 'https://www.sportingnews.com/us/soccer/news/real-madrid-leganes-lineups-starting-11-team-news-injuries/aac757d10cc7b9a084995b4d', 'title': 'Real Madrid vs. Leganes lineups, confirmed starting 11, team news ...', 'content': 'Real Madrid starting lineup (4-3-3, right to left): Lunin (GK) — Vazquez, Rudiger, Asencio, Garcia — Modric, Bellingham, Camavinga — B. Diaz,', 'score': 0.9224337, 'raw_content': None}], 'response_time': 2.3}), AIMessage(content='The starting lineup for Real Madrid in their match against Leganés was: Lunin (GK), Vázquez, Rüdiger, Asencio, Fran García, Modric, Bellingham, Camavinga, Brahim, Arda Güler, and Mbappé. Notable players like Vini Jr., Rodrygo, and Valverde were on the bench.', additional_kwargs={opening_brace}{closing_brace}, response_metadata={opening_brace}'token_usage': {'completion_tokens': 98, 'prompt_tokens': 2954, 'total_tokens': 3052}, 'model': '', 'finish_reason': 'stop'{closing_brace}, id='run-0bd921c6-1d94-4a4c-9d9c-d255d301e2d5-0')]}, next=(), config={'configurable': {'thread_id': '3', 'checkpoint_ns': '', 'checkpoint_id': '1f010a50-49f2-6904-800c-ec8d67fe5b92'{closing_brace}{closing_brace}, metadata={'source': 'loop', 'writes': {opening_brace}'chatbot_node': {opening_brace}'messages': [AIMessage(content='The starting lineup for Real Madrid in their match against Leganés was: Lunin (GK), Vázquez, Rüdiger, Asencio, Fran García, Modric, Bellingham, Camavinga, Brahim, Arda Güler, and Mbappé. Notable players like Vini Jr., Rodrygo, and Valverde were on the bench.', additional_kwargs={opening_brace}{closing_brace}, response_metadata={opening_brace}'token_usage': {'completion_tokens': 98, 'prompt_tokens': 2954, 'total_tokens': 3052}, 'model': '', 'finish_reason': 'stop'{closing_brace}, id='run-0bd921c6-1d94-4a4c-9d9c-d255d301e2d5-0')]{closing_brace}{closing_brace}, 'thread_id': '3', 'step': 12, 'parents': {opening_brace}{closing_brace{closing_brace}{closing_brace}, created_at='2025-04-03T16:02:18.167222+00:00', parent_config={'configurable': {'thread_id': '3', 'checkpoint_ns': '', 'checkpoint_id': '1f010a50-1feb-6534-800b-079c102aaa71'{closing_brace}{closing_brace}, tasks=())
Se quisermos ver o próximo nódo a ser processado, podemos usar o atributo next
snapshot.next
()
Dado que o grafo foi concluído, next está vazio. Se você obtém um estado a partir de uma invocação do grafo, next indica qual nó será executado em seguida.
A captura anterior (snapshot) contém os valores de estado atuais, a configuração correspondente e o próximo nó (next) a ser processado. No nosso caso, o gráfico alcançou o estado END, por isso next está vazio.
Vamos a reescrever todo o código para que seja mais legível.
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginfrom langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultsfrom langchain_core.messages import ToolMessagefrom langgraph.prebuilt import ToolNode, tools_conditionfrom langgraph.checkpoint.memory import MemorySaverfrom IPython.display import Image, displayimport jsonimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]# Toolswrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)tool = TavilySearchResults(api_wrapper=wrapper, max_results=2)tools_list = [tool]# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Create the LLM with toolsllm_with_tools = llm.bind_tools(tools_list)# Tool nodetool_node = ToolNode(tools=tools_list)# Functionsdef chatbot_function(state: State):return {opening_brace}"messages": [llm_with_tools.invoke(state["messages"])]}# Start to build the graphgraph_builder = StateGraph(State)# Add nodes to the graphgraph_builder.add_node("chatbot_node", chatbot_function)graph_builder.add_node("tools", tool_node)# Add edgesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_conditional_edges( "chatbot_node", tools_condition)graph_builder.add_edge("tools", "chatbot_node")# Compile the graphmemory = MemorySaver()graph = graph_builder.compile(checkpointer=memory)# Display the graphtry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")
Error al visualizar el grafo: Failed to reach https://mermaid.ink/ API while trying to render your graph after 1 retries. To resolve this issue:1. Check your internet connection and try again2. Try with higher retry settings: `draw_mermaid_png(..., max_retries=5, retry_delay=2.0)`3. Use the Pyppeteer rendering method which will render your graph locally in a browser: `draw_mermaid_png(..., draw_method=MermaidDrawMethod.PYPPETEER)`
USER1_THREAD_ID = "1"config_USER1 = {opening_brace}"configurable": {opening_brace}"thread_id": USER1_THREAD_ID{closing_brace}{closing_brace}user_input = "Hi there! My name is Maximo."# The config is the **second positional argument** to stream() or invoke()!events = graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace},config_USER1,stream_mode="values",)for event in events:event["messages"][-1].pretty_print()
================================ Human Message =================================Hi there! My name is Maximo.================================== Ai Message ==================================Hello Maximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.
user_input = "Do you remember my name?"# The config is the **second positional argument** to stream() or invoke()!events = graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace},config_USER1,stream_mode="values",)for event in events:event["messages"][-1].pretty_print()
================================ Human Message =================================Do you remember my name?================================== Ai Message ==================================Yes, I remember your name! You mentioned it's Maximo. It's nice to chat with you, Maximo. How can I assist you today?
Parabéns! Nosso chatbot agora pode manter o estado da conversa em todas as sessões graças ao sistema de pontos de controle (checkpoints) do LangGraph. Isso abre possibilidades para interações mais naturais e contextuais. O controle do LangGraph até mesmo lida com estados de grafos complexos.
Mais
Chatbot com mensagem de resumo
Se vamos gerenciar o contexto da conversação para não gastar muitos tokens, uma coisa que podemos fazer para melhorar a conversação é adicionar uma mensagem com o resumo da conversação. Isso pode ser útil para o exemplo anterior, no qual filtramos tanto o estado que o LLM não tem contexto suficiente.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from langchain_core.messages import RemoveMessage, trim_messages, SystemMessage, HumanMessage, AIMessage, RemoveMessage
from langgraph.checkpoint.memory import MemorySaver
from huggingface_hub import login
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
memory_saver = MemorySaver()
class State(TypedDict):
messages: Annotated[list, add_messages]
summary: str
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Create the LLM model
login(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the model
MODEL = "Qwen/Qwen2.5-72B-Instruct"
model = HuggingFaceEndpoint(
repo_id=MODEL,
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
# Create the chat model
llm = ChatHuggingFace(llm=model)
# Print functions
def print_message(m):
if isinstance(m, HumanMessage):
message_content = m.content
message_lines = message_content.split("\n")
for i, line in enumerate(message_lines):
if i == 0:
print(f"\t\t[HumanMessage]: {line}")
else:
print(f"\t\t{line}")
elif isinstance(m, SystemMessage):
message_content = m.content
message_lines = message_content.split("\n")
for i, line in enumerate(message_lines):
if i == 0:
print(f"\t\t[SystemMessage]: {line}")
else:
print(f"\t\t{line}")
elif isinstance(m, AIMessage):
message_content = m.content
message_lines = message_content.split("\n")
for i, line in enumerate(message_lines):
if i == 0:
print(f"\t\t[AIMessage]: {line}")
else:
print(f"\t\t{line}")
elif isinstance(m, RemoveMessage):
message_content = m.content
message_lines = message_content.split("\n")
for i, line in enumerate(message_lines):
if i == 0:
print(f"\t\t[RemoveMessage]: {line}")
else:
print(f"\t\t{line}")
else:
message_content = m.content
message_lines = message_content.split("\n")
for i, line in enumerate(message_lines):
if i == 0:
print(f"\t\t[{type(m)}]: {line}")
else:
print(f"\t\t{line}")
def print_state_summary(state: State):
if state.get("summary"):
summary_lines = state["summary"].split("\n")
for i, line in enumerate(summary_lines):
if i == 0:
print(f"\t\tSummary of the conversation: {line}")
else:
print(f"\t\t{line}")
else:
print("\t\tNo summary of the conversation")
def print_summary(summary: str):
if summary:
summary_lines = summary.split("\n")
for i, line in enumerate(summary_lines):
if i == 0:
print(f"\t\tSummary of the conversation: {line}")
else:
print(f"\t\t{line}")
else:
print("\t\tNo summary of the conversation")
# Nodes
def filter_messages(state: State):
print("\t--- 1 messages (input to filter_messages) ---")
for m in state["messages"]:
print_message(m)
print_state_summary(state)
print("\t------------------------------------------------")
# Delete all but the 2 most recent messages if there are more than 2
if len(state["messages"]) > 2:
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
else:
delete_messages = []
print("\t--- 1 messages (output of filter_messages) ---")
for m in delete_messages:
print_message(m)
print_state_summary(state)
print("\t------------------------------------------------")
return {"messages": delete_messages}
def trim_messages_node(state: State):
# print the messages received from filter_messages_node
print("\n\n\t--- 2 messages (input to trim_messages) ---")
for m in state["messages"]:
print_message(m)
print_state_summary(state)
print("\t------------------------------------------------")
# Trim the messages based on the specified parameters
trimmed_messages = trim_messages(
state["messages"],
max_tokens=100, # Maximum tokens allowed in the trimmed list
strategy="last", # Keep the latest messages
token_counter=llm, # Use the LLM's tokenizer to count tokens
allow_partial=True, # Allow cutting messages mid-way if needed
)
# Identify the messages that must be removed
# This is crucial: determine which messages are in 'state["messages"]' but not in 'trimmed_messages'
original_ids = {m.id for m in state["messages"]}
trimmed_ids = {m.id for m in trimmed_messages}
ids_to_remove = original_ids - trimmed_ids
# Create a RemoveMessage for each message that must be removed
messages_to_remove = [RemoveMessage(id=msg_id) for msg_id in ids_to_remove]
# Print the result of the trimming
print("\t--- 2 messages (output of trim_messages - after trimming) ---")
if trimmed_messages:
for m in trimmed_messages:
print_message(m)
else:
print("[Empty list - No messages after trimming]")
print_state_summary(state)
print("\t------------------------------------------------")
return {"messages": messages_to_remove}
def chat_model_node(state: State):
# Get summary of the conversation if it exists
summary = state.get("summary", "")
print("\n\n\t--- 3 messages (input to chat_model_node) ---")
for m in state["messages"]:
print_message(m)
print_state_summary(state)
print("\t------------------------------------------------")
# If there is a summary, add it to the system message
if summary:
# Add the summary to the system message
system_message = f"Summary of the conversation earlier: {summary}"
# Add the system message to the messages at the beginning
messages = [SystemMessage(content=system_message)] + state["messages"]
# If there is no summary, just return the messages
else:
messages = state["messages"]
print(f"\t--- 3 messages (input to chat_model_node) ---")
for m in messages:
print_message(m)
print_summary(summary)
print("\t------------------------------------------------")
# Invoke the LLM with the messages
response = llm.invoke(messages)
print("\t--- 3 messages (output of chat_model_node) ---")
print_message(response)
print_summary(summary)
print("\t------------------------------------------------")
# Return the LLM's response in the correct state format
return {"messages": [response]}
def summarize_conversation(state: State):
# Get summary of the conversation if it exists
summary = state.get("summary", "")
print("\n\n\t--- 4 messages (input to summarize_conversation) ---")
for m in state["messages"]:
print_message(m)
print_summary(summary)
print("\t------------------------------------------------")
# If there is a summary, add it to the system message
if summary:
summary_message = (
f"This is a summary of the conversation to date: {summary}\n\n"
"Extend the summary by taking into account the new messages above."
)
# If there is no summary, create a new one
else:
summary_message = "Create a summary of the conversation above."
print(f"\t--- 4 summary message ---")
summary_lines = summary_message.split("\n")
for i, line in enumerate(summary_lines):
if i == 0:
print(f"\t\t{line}")
else:
print(f"\t\t{line}")
print_summary(summary)
print("\t------------------------------------------------")
# Add prompt to the messages
messages = state["messages"] + [HumanMessage(summary_message)]
print("\t--- 4 messages (input to summarize_conversation with summary) ---")
for m in messages:
print_message(m)
print("\t------------------------------------------------")
# Invoke the LLM with the messages
response = llm.invoke(messages)
print("\t--- 4 messages (output of summarize_conversation) ---")
print_message(response)
print("\t------------------------------------------------")
# Return the summary message in the correct state format
return {"summary": response.content}
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("filter_messages_node", filter_messages)
graph_builder.add_node("trim_messages_node", trim_messages_node)
graph_builder.add_node("chatbot_node", chat_model_node)
graph_builder.add_node("summarize_conversation_node", summarize_conversation)
# Connecto nodes
graph_builder.add_edge(START, "filter_messages_node")
graph_builder.add_edge("filter_messages_node", "trim_messages_node")
graph_builder.add_edge("trim_messages_node", "chatbot_node")
graph_builder.add_edge("chatbot_node", "summarize_conversation_node")
graph_builder.add_edge("summarize_conversation_node", END)
# Compile the graph
graph = graph_builder.compile(checkpointer=memory_saver)
display(Image(graph.get_graph().draw_mermaid_png()))
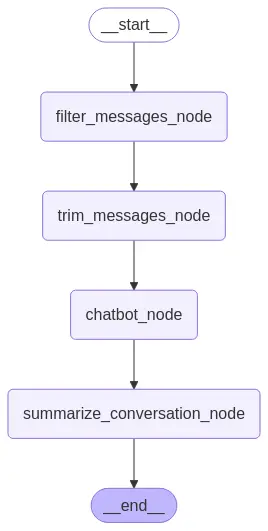
Como podemos ver, temos:
- Função de filtro de mensagens: Se houver mais de 2 mensagens no estado, todas as mensagens são removidas, exceto as 2 últimas.* Função de trimagem de mensagens: São removidas as mensagens que excedem 100 tokens.* Função do chatbot: O modelo é executado com as mensagens filtradas e cortadas. Além disso, se houver um resumo, ele é adicionado à mensagem do sistema.* Função de resumo: Cria um resumo da conversa.
Criamos uma função para imprimir as mensagens do grafo.
# Colors for the terminalCOLOR_GREEN = "\033[32m"COLOR_YELLOW = "\033[33m"COLOR_RESET = "\033[0m"def stream_graph_updates(user_input: str, config: dict):# Initialize a flag to track if an assistant response has been printedassistant_response_printed = False# Print the user's input immediatelyprint(f"\n\n{opening_brace}COLOR_GREEN{closing_brace}User: {opening_brace}COLOR_RESET{closing_brace}{opening_brace}user_input{closing_brace}")# Create the user's message with the HumanMessage classuser_message = HumanMessage(content=user_input)# Stream events from the graph executionfor event in graph.stream({"messages": [user_message]}, config, stream_mode="values"):# event is a dictionary mapping node names to their output# Example: {opening_brace}'chatbot_node': {opening_brace}'messages': [...]{closing_brace}{closing_brace} or {opening_brace}'summarize_conversation_node': {opening_brace}'summary': '...'{closing_brace}{closing_brace}# Iterate through node name and its outputfor node_name, value in event.items():# Check if this event is from the chatbot node which should contain the assistant's replyif node_name == 'messages':# Ensure the output format is as expected (list of messages)if isinstance(value, list):# Get the messages from the eventmessages = value# Ensure 'messages' is a non-empty listif isinstance(messages, list) and messages:# Get the last message (presumably the assistant's reply)last_message = messages[-1]# Ensure the message is an instance of AIMessageif isinstance(last_message, AIMessage):# Ensure the message has content to displayif hasattr(last_message, 'content'):# Print the assistant's message contentprint(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}{last_message.content}")assistant_response_printed = True # Mark that we've printed the response# Fallback if no assistant response was printed (e.g., graph error before chatbot_node)if not assistant_response_printed:print(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}[No response generated or error occurred]")
Agora executamos o grafo
USER1_THREAD_ID = "1"config_USER1 = {opening_brace}"configurable": {opening_brace}"thread_id": USER1_THREAD_ID{closing_brace}{closing_brace}while True:user_input = input(f"\n\nUser: ")if user_input.lower() in ["quit", "exit", "q"]:print(f"{opening_brace}COLOR_GREEN{closing_brace}User: {opening_brace}COLOR_RESET{closing_brace}Exiting...")print(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}Goodbye!")breakevents = stream_graph_updates(user_input, config_USER1)
User: Hello--- 1 messages (input to filter_messages) ---[HumanMessage]: HelloNo summary of the conversation--------------------------------------------------- 1 messages (output of filter_messages) ---No summary of the conversation--------------------------------------------------- 2 messages (input to trim_messages) ---[HumanMessage]: HelloNo summary of the conversation--------------------------------------------------- 2 messages (output of trim_messages - after trimming) ---[HumanMessage]: HelloNo summary of the conversation--------------------------------------------------- 3 messages (input to chat_model_node) ---[HumanMessage]: HelloNo summary of the conversation--------------------------------------------------- 3 messages (input to chat_model_node) ---[HumanMessage]: HelloNo summary of the conversation--------------------------------------------------- 3 messages (output of chat_model_node) ---[AIMessage]: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.No summary of the conversation------------------------------------------------Assistant: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.--- 4 messages (input to summarize_conversation) ---[HumanMessage]: Hello[AIMessage]: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.No summary of the conversation--------------------------------------------------- 4 summary message ---Create a summary of the conversation above.No summary of the conversation--------------------------------------------------- 4 messages (input to summarize_conversation with summary) ---[HumanMessage]: Hello[AIMessage]: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.[HumanMessage]: Create a summary of the conversation above.--------------------------------------------------- 4 messages (output of summarize_conversation) ---[AIMessage]: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?------------------------------------------------Assistant: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: I am studying about langgraph, do you know it?--- 1 messages (input to filter_messages) ---[HumanMessage]: Hello[AIMessage]: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.[HumanMessage]: I am studying about langgraph, do you know it?Summary of the conversation: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?--------------------------------------------------- 1 messages (output of filter_messages) ---[RemoveMessage]:Summary of the conversation: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?--------------------------------------------------- 2 messages (input to trim_messages) ---[AIMessage]: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.[HumanMessage]: I am studying about langgraph, do you know it?Summary of the conversation: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?--------------------------------------------------- 2 messages (output of trim_messages - after trimming) ---[AIMessage]: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.[HumanMessage]: I am studying about langgraph, do you know it?Summary of the conversation: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?--------------------------------------------------- 3 messages (input to chat_model_node) ---[AIMessage]: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.[HumanMessage]: I am studying about langgraph, do you know it?Summary of the conversation: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?--------------------------------------------------- 3 messages (input to chat_model_node) ---[SystemMessage]: Summary of the conversation earlier: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?[AIMessage]: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.[HumanMessage]: I am studying about langgraph, do you know it?Summary of the conversation: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?--------------------------------------------------- 3 messages (output of chat_model_node) ---[AIMessage]: Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models.LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. **Visualizing Model Architecture**: Provides a clear and detailed view of how different components of a language model are connected.2. **Comparing Models**: Allows for easy comparison of different language models in terms of their structure, training data, and performance metrics.3. **Understanding Training Processes**: Helps in understanding the training dynamics and the flow of data through the model.4. **Identifying Bottlenecks**: Can help in identifying potential bottlenecks or areas for improvement in the model.If you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!Summary of the conversation: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?------------------------------------------------Assistant: Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models.LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. **Visualizing Model Architecture**: Provides a clear and detailed view of how different components of a language model are connected.2. **Comparing Models**: Allows for easy comparison of different language models in terms of their structure, training data, and performance metrics.3. **Understanding Training Processes**: Helps in understanding the training dynamics and the flow of data through the model.4. **Identifying Bottlenecks**: Can help in identifying potential bottlenecks or areas for improvement in the model.If you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!--- 4 messages (input to summarize_conversation) ---[AIMessage]: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.[HumanMessage]: I am studying about langgraph, do you know it?[AIMessage]: Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models.LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. **Visualizing Model Architecture**: Provides a clear and detailed view of how different components of a language model are connected.2. **Comparing Models**: Allows for easy comparison of different language models in terms of their structure, training data, and performance metrics.3. **Understanding Training Processes**: Helps in understanding the training dynamics and the flow of data through the model.4. **Identifying Bottlenecks**: Can help in identifying potential bottlenecks or areas for improvement in the model.If you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!Summary of the conversation: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?--------------------------------------------------- 4 summary message ---This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?Extend the summary by taking into account the new messages above.Summary of the conversation: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?--------------------------------------------------- 4 messages (input to summarize_conversation with summary) ---[AIMessage]: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.[HumanMessage]: I am studying about langgraph, do you know it?[AIMessage]: Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models.LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. **Visualizing Model Architecture**: Provides a clear and detailed view of how different components of a language model are connected.2. **Comparing Models**: Allows for easy comparison of different language models in terms of their structure, training data, and performance metrics.3. **Understanding Training Processes**: Helps in understanding the training dynamics and the flow of data through the model.4. **Identifying Bottlenecks**: Can help in identifying potential bottlenecks or areas for improvement in the model.If you have specific questions or aspects of LangGraph you're interested in, feel free to let me know![HumanMessage]: This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?Extend the summary by taking into account the new messages above.--------------------------------------------------- 4 messages (output of summarize_conversation) ---[AIMessage]: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?------------------------------------------------Assistant: Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models.LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. **Visualizing Model Architecture**: Provides a clear and detailed view of how different components of a language model are connected.2. **Comparing Models**: Allows for easy comparison of different language models in terms of their structure, training data, and performance metrics.3. **Understanding Training Processes**: Helps in understanding the training dynamics and the flow of data through the model.4. **Identifying Bottlenecks**: Can help in identifying potential bottlenecks or areas for improvement in the model.If you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!User: I would like to know about using langsmith with huggingface llms, the integration of huggingface--- 1 messages (input to filter_messages) ---[AIMessage]: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.[HumanMessage]: I am studying about langgraph, do you know it?[AIMessage]: Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models.LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. **Visualizing Model Architecture**: Provides a clear and detailed view of how different components of a language model are connected.2. **Comparing Models**: Allows for easy comparison of different language models in terms of their structure, training data, and performance metrics.3. **Understanding Training Processes**: Helps in understanding the training dynamics and the flow of data through the model.4. **Identifying Bottlenecks**: Can help in identifying potential bottlenecks or areas for improvement in the model.If you have specific questions or aspects of LangGraph you're interested in, feel free to let me know![HumanMessage]: I would like to know about using langsmith with huggingface llms, the integration of huggingfaceSummary of the conversation: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?--------------------------------------------------- 1 messages (output of filter_messages) ---[RemoveMessage]:[RemoveMessage]:Summary of the conversation: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?--------------------------------------------------- 2 messages (input to trim_messages) ---[AIMessage]: Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models.LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. **Visualizing Model Architecture**: Provides a clear and detailed view of how different components of a language model are connected.2. **Comparing Models**: Allows for easy comparison of different language models in terms of their structure, training data, and performance metrics.3. **Understanding Training Processes**: Helps in understanding the training dynamics and the flow of data through the model.4. **Identifying Bottlenecks**: Can help in identifying potential bottlenecks or areas for improvement in the model.If you have specific questions or aspects of LangGraph you're interested in, feel free to let me know![HumanMessage]: I would like to know about using langsmith with huggingface llms, the integration of huggingfaceSummary of the conversation: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?--------------------------------------------------- 2 messages (output of trim_messages - after trimming) ---[HumanMessage]: I would like to know about using langsmith with huggingface llms, the integration of huggingfaceSummary of the conversation: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?--------------------------------------------------- 3 messages (input to chat_model_node) ---[HumanMessage]: I would like to know about using langsmith with huggingface llms, the integration of huggingfaceSummary of the conversation: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?--------------------------------------------------- 3 messages (input to chat_model_node) ---[SystemMessage]: Summary of the conversation earlier: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?[HumanMessage]: I would like to know about using langsmith with huggingface llms, the integration of huggingfaceSummary of the conversation: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?--------------------------------------------------- 3 messages (output of chat_model_node) ---[AIMessage]: Certainly! LangSmith and Hugging Face are both powerful tools in the domain of natural language processing (NLP), and integrating them can significantly enhance your workflow. Here’s a detailed look at how you can use LangSmith with Hugging Face models:### What is LangSmith?LangSmith is a platform designed to help developers and researchers build, test, and deploy natural language applications. It offers features such as:- **Model Management**: Manage and version control your language models.- **Data Labeling**: Annotate and label data for training and evaluation.- **Model Evaluation**: Evaluate and compare different models and versions.- **API Integration**: Integrate with various NLP tools and platforms.### What is Hugging Face?Hugging Face is a leading company in the NLP domain, known for its transformers library. Hugging Face provides a wide array of pre-trained models and tools for NLP tasks, including:- **Pre-trained Models**: Access to a vast library of pre-trained models.- **Transformers Library**: A powerful library for working with transformer models.- **Hugging Face Hub**: A platform for sharing and accessing models, datasets, and metrics.### Integrating LangSmith with Hugging Face Models#### Step-by-Step Guide1. **Install Required Libraries**Ensure you have the necessary libraries installed:```bashpip install transformers datasets langsmith```2. **Load a Hugging Face Model**Use the `transformers` library to load a pre-trained model:```pythonfrom transformers import AutoModelForSequenceClassification, AutoTokenizermodel_name = "distilbert-base-uncased"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForSequenceClassification.from_pretrained(model_name)```3. **Integrate with LangSmith**- **Initialize LangSmith Client**:```pythonfrom langsmith import Clientclient = Client()```- **Create or Load a Dataset**:```pythonfrom datasets import Dataset# Example datasetdata = {"text": ["This is a positive review.", "This is a negative review."],"label": [1, 0]}dataset = Dataset.from_dict(data)# Save dataset to LangSmithdataset_id = client.create_dataset(name="my_dataset", data=dataset)```- **Evaluate the Model**:```pythonfrom langsmith import EvaluationResultdef evaluate_model(dataset, tokenizer, model):results = []for example in dataset:inputs = tokenizer(example["text"], return_tensors="pt")outputs = model(**inputs)predicted_label = outputs.logits.argmax().item()result = EvaluationResult(example_id=example["id"],predicted_label=predicted_label,ground_truth_label=example["label"])results.append(result)return resultsevaluation_results = evaluate_model(dataset, tokenizer, model)```- **Upload Evaluation Results to LangSmith**:```pythonclient.log_results(dataset_id, evaluation_results)```4. **Visualize and Analyze Results**- Use LangSmith’s web interface to visualize the evaluation results.- Compare different models and versions to identify the best performing model.### Additional Tips- **Model Tuning**: Use Hugging Face’s `Trainer` class to fine-tune models on your datasets and then evaluate them using LangSmith.- **Custom Metrics**: Define custom evaluation metrics and use them to assess model performance.- **Collaboration**: Share datasets and models with team members using the Hugging Face Hub and LangSmith.By following these steps, you can effectively integrate Hugging Face models with LangSmith, leveraging the strengths of both platforms to build and evaluate robust NLP applications.If you have any specific questions or need further assistance, feel free to ask!Summary of the conversation: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?------------------------------------------------Assistant: Certainly! LangSmith and Hugging Face are both powerful tools in the domain of natural language processing (NLP), and integrating them can significantly enhance your workflow. Here’s a detailed look at how you can use LangSmith with Hugging Face models:### What is LangSmith?LangSmith is a platform designed to help developers and researchers build, test, and deploy natural language applications. It offers features such as:- **Model Management**: Manage and version control your language models.- **Data Labeling**: Annotate and label data for training and evaluation.- **Model Evaluation**: Evaluate and compare different models and versions.- **API Integration**: Integrate with various NLP tools and platforms.### What is Hugging Face?Hugging Face is a leading company in the NLP domain, known for its transformers library. Hugging Face provides a wide array of pre-trained models and tools for NLP tasks, including:- **Pre-trained Models**: Access to a vast library of pre-trained models.- **Transformers Library**: A powerful library for working with transformer models.- **Hugging Face Hub**: A platform for sharing and accessing models, datasets, and metrics.### Integrating LangSmith with Hugging Face Models#### Step-by-Step Guide1. **Install Required Libraries**Ensure you have the necessary libraries installed:```bashpip install transformers datasets langsmith```2. **Load a Hugging Face Model**Use the `transformers` library to load a pre-trained model:```pythonfrom transformers import AutoModelForSequenceClassification, AutoTokenizermodel_name = "distilbert-base-uncased"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForSequenceClassification.from_pretrained(model_name)```3. **Integrate with LangSmith**- **Initialize LangSmith Client**:```pythonfrom langsmith import Clientclient = Client()```- **Create or Load a Dataset**:```pythonfrom datasets import Dataset# Example datasetdata = {"text": ["This is a positive review.", "This is a negative review."],"label": [1, 0]}dataset = Dataset.from_dict(data)# Save dataset to LangSmithdataset_id = client.create_dataset(name="my_dataset", data=dataset)```- **Evaluate the Model**:```pythonfrom langsmith import EvaluationResultdef evaluate_model(dataset, tokenizer, model):results = []for example in dataset:inputs = tokenizer(example["text"], return_tensors="pt")outputs = model(**inputs)predicted_label = outputs.logits.argmax().item()result = EvaluationResult(example_id=example["id"],predicted_label=predicted_label,ground_truth_label=example["label"])results.append(result)return resultsevaluation_results = evaluate_model(dataset, tokenizer, model)```- **Upload Evaluation Results to LangSmith**:```pythonclient.log_results(dataset_id, evaluation_results)```4. **Visualize and Analyze Results**- Use LangSmith’s web interface to visualize the evaluation results.- Compare different models and versions to identify the best performing model.### Additional Tips- **Model Tuning**: Use Hugging Face’s `Trainer` class to fine-tune models on your datasets and then evaluate them using LangSmith.- **Custom Metrics**: Define custom evaluation metrics and use them to assess model performance.- **Collaboration**: Share datasets and models with team members using the Hugging Face Hub and LangSmith.By following these steps, you can effectively integrate Hugging Face models with LangSmith, leveraging the strengths of both platforms to build and evaluate robust NLP applications.If you have any specific questions or need further assistance, feel free to ask!--- 4 messages (input to summarize_conversation) ---[HumanMessage]: I would like to know about using langsmith with huggingface llms, the integration of huggingface[AIMessage]: Certainly! LangSmith and Hugging Face are both powerful tools in the domain of natural language processing (NLP), and integrating them can significantly enhance your workflow. Here’s a detailed look at how you can use LangSmith with Hugging Face models:### What is LangSmith?LangSmith is a platform designed to help developers and researchers build, test, and deploy natural language applications. It offers features such as:- **Model Management**: Manage and version control your language models.- **Data Labeling**: Annotate and label data for training and evaluation.- **Model Evaluation**: Evaluate and compare different models and versions.- **API Integration**: Integrate with various NLP tools and platforms.### What is Hugging Face?Hugging Face is a leading company in the NLP domain, known for its transformers library. Hugging Face provides a wide array of pre-trained models and tools for NLP tasks, including:- **Pre-trained Models**: Access to a vast library of pre-trained models.- **Transformers Library**: A powerful library for working with transformer models.- **Hugging Face Hub**: A platform for sharing and accessing models, datasets, and metrics.### Integrating LangSmith with Hugging Face Models#### Step-by-Step Guide1. **Install Required Libraries**Ensure you have the necessary libraries installed:```bashpip install transformers datasets langsmith```2. **Load a Hugging Face Model**Use the `transformers` library to load a pre-trained model:```pythonfrom transformers import AutoModelForSequenceClassification, AutoTokenizermodel_name = "distilbert-base-uncased"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForSequenceClassification.from_pretrained(model_name)```3. **Integrate with LangSmith**- **Initialize LangSmith Client**:```pythonfrom langsmith import Clientclient = Client()```- **Create or Load a Dataset**:```pythonfrom datasets import Dataset# Example datasetdata = {"text": ["This is a positive review.", "This is a negative review."],"label": [1, 0]}dataset = Dataset.from_dict(data)# Save dataset to LangSmithdataset_id = client.create_dataset(name="my_dataset", data=dataset)```- **Evaluate the Model**:```pythonfrom langsmith import EvaluationResultdef evaluate_model(dataset, tokenizer, model):results = []for example in dataset:inputs = tokenizer(example["text"], return_tensors="pt")outputs = model(**inputs)predicted_label = outputs.logits.argmax().item()result = EvaluationResult(example_id=example["id"],predicted_label=predicted_label,ground_truth_label=example["label"])results.append(result)return resultsevaluation_results = evaluate_model(dataset, tokenizer, model)```- **Upload Evaluation Results to LangSmith**:```pythonclient.log_results(dataset_id, evaluation_results)```4. **Visualize and Analyze Results**- Use LangSmith’s web interface to visualize the evaluation results.- Compare different models and versions to identify the best performing model.### Additional Tips- **Model Tuning**: Use Hugging Face’s `Trainer` class to fine-tune models on your datasets and then evaluate them using LangSmith.- **Custom Metrics**: Define custom evaluation metrics and use them to assess model performance.- **Collaboration**: Share datasets and models with team members using the Hugging Face Hub and LangSmith.By following these steps, you can effectively integrate Hugging Face models with LangSmith, leveraging the strengths of both platforms to build and evaluate robust NLP applications.If you have any specific questions or need further assistance, feel free to ask!Summary of the conversation: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?--------------------------------------------------- 4 summary message ---This is a summary of the conversation to date: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?Extend the summary by taking into account the new messages above.Summary of the conversation: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?--------------------------------------------------- 4 messages (input to summarize_conversation with summary) ---[HumanMessage]: I would like to know about using langsmith with huggingface llms, the integration of huggingface[AIMessage]: Certainly! LangSmith and Hugging Face are both powerful tools in the domain of natural language processing (NLP), and integrating them can significantly enhance your workflow. Here’s a detailed look at how you can use LangSmith with Hugging Face models:### What is LangSmith?LangSmith is a platform designed to help developers and researchers build, test, and deploy natural language applications. It offers features such as:- **Model Management**: Manage and version control your language models.- **Data Labeling**: Annotate and label data for training and evaluation.- **Model Evaluation**: Evaluate and compare different models and versions.- **API Integration**: Integrate with various NLP tools and platforms.### What is Hugging Face?Hugging Face is a leading company in the NLP domain, known for its transformers library. Hugging Face provides a wide array of pre-trained models and tools for NLP tasks, including:- **Pre-trained Models**: Access to a vast library of pre-trained models.- **Transformers Library**: A powerful library for working with transformer models.- **Hugging Face Hub**: A platform for sharing and accessing models, datasets, and metrics.### Integrating LangSmith with Hugging Face Models#### Step-by-Step Guide1. **Install Required Libraries**Ensure you have the necessary libraries installed:```bashpip install transformers datasets langsmith```2. **Load a Hugging Face Model**Use the `transformers` library to load a pre-trained model:```pythonfrom transformers import AutoModelForSequenceClassification, AutoTokenizermodel_name = "distilbert-base-uncased"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForSequenceClassification.from_pretrained(model_name)```3. **Integrate with LangSmith**- **Initialize LangSmith Client**:```pythonfrom langsmith import Clientclient = Client()```- **Create or Load a Dataset**:```pythonfrom datasets import Dataset# Example datasetdata = {"text": ["This is a positive review.", "This is a negative review."],"label": [1, 0]}dataset = Dataset.from_dict(data)# Save dataset to LangSmithdataset_id = client.create_dataset(name="my_dataset", data=dataset)```- **Evaluate the Model**:```pythonfrom langsmith import EvaluationResultdef evaluate_model(dataset, tokenizer, model):results = []for example in dataset:inputs = tokenizer(example["text"], return_tensors="pt")outputs = model(**inputs)predicted_label = outputs.logits.argmax().item()result = EvaluationResult(example_id=example["id"],predicted_label=predicted_label,ground_truth_label=example["label"])results.append(result)return resultsevaluation_results = evaluate_model(dataset, tokenizer, model)```- **Upload Evaluation Results to LangSmith**:```pythonclient.log_results(dataset_id, evaluation_results)```4. **Visualize and Analyze Results**- Use LangSmith’s web interface to visualize the evaluation results.- Compare different models and versions to identify the best performing model.### Additional Tips- **Model Tuning**: Use Hugging Face’s `Trainer` class to fine-tune models on your datasets and then evaluate them using LangSmith.- **Custom Metrics**: Define custom evaluation metrics and use them to assess model performance.- **Collaboration**: Share datasets and models with team members using the Hugging Face Hub and LangSmith.By following these steps, you can effectively integrate Hugging Face models with LangSmith, leveraging the strengths of both platforms to build and evaluate robust NLP applications.If you have any specific questions or need further assistance, feel free to ask![HumanMessage]: This is a summary of the conversation to date: Sure! Here's an extended summary of the conversation:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]---Is there anything else you need assistance with?Extend the summary by taking into account the new messages above.--------------------------------------------------- 4 messages (output of summarize_conversation) ---[AIMessage]: Sure! Here's the extended summary of the conversation to date:---**User:** Hello**Qwen:** Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.**User:** I am studying about langgraph, do you know it?**Qwen:** Yes, I can help with information about LangGraph! LangGraph is a language model graph that represents the relationships and connections between different language models and their components. It can be used to visualize and understand the architecture, training processes, and performance characteristics of various language models. LangGraph can be particularly useful for researchers and developers who are working on natural language processing (NLP) tasks. It helps in:1. Visualizing Model Architecture2. Comparing Models3. Understanding Training Processes4. Identifying BottlenecksIf you have specific questions or aspects of LangGraph you're interested in, feel free to let me know!**User:** This is a summary of the conversation to date: Sure! Here's a summary of the conversation above:User: HelloQwen: Hello! How can I assist you today? Whether you need help with information, a specific task, or just want to chat, I'm here to help.User: Create a summary of the conversation above.Qwen: [Provided the summary you are now reading.]Is there anything else you need assistance with?**Qwen:** [Extended the summary you are now reading.]**User:** Is there anything else you need assistance with?**Qwen:** If you have any more questions about LangGraph or any other topic, feel free to ask! I'm here to help with any information or assistance you need.---Is there anything else you need assistance with?------------------------------------------------Assistant: Certainly! LangSmith and Hugging Face are both powerful tools in the domain of natural language processing (NLP), and integrating them can significantly enhance your workflow. Here’s a detailed look at how you can use LangSmith with Hugging Face models:### What is LangSmith?LangSmith is a platform designed to help developers and researchers build, test, and deploy natural language applications. It offers features such as:- **Model Management**: Manage and version control your language models.- **Data Labeling**: Annotate and label data for training and evaluation.- **Model Evaluation**: Evaluate and compare different models and versions.- **API Integration**: Integrate with various NLP tools and platforms.### What is Hugging Face?Hugging Face is a leading company in the NLP domain, known for its transformers library. Hugging Face provides a wide array of pre-trained models and tools for NLP tasks, including:- **Pre-trained Models**: Access to a vast library of pre-trained models.- **Transformers Library**: A powerful library for working with transformer models.- **Hugging Face Hub**: A platform for sharing and accessing models, datasets, and metrics.### Integrating LangSmith with Hugging Face Models#### Step-by-Step Guide1. **Install Required Libraries**Ensure you have the necessary libraries installed:```bashpip install transformers datasets langsmith```2. **Load a Hugging Face Model**Use the `transformers` library to load a pre-trained model:```pythonfrom transformers import AutoModelForSequenceClassification, AutoTokenizermodel_name = "distilbert-base-uncased"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForSequenceClassification.from_pretrained(model_name)```3. **Integrate with LangSmith**- **Initialize LangSmith Client**:```pythonfrom langsmith import Clientclient = Client()```- **Create or Load a Dataset**:```pythonfrom datasets import Dataset# Example datasetdata = {"text": ["This is a positive review.", "This is a negative review."],"label": [1, 0]}dataset = Dataset.from_dict(data)# Save dataset to LangSmithdataset_id = client.create_dataset(name="my_dataset", data=dataset)```- **Evaluate the Model**:```pythonfrom langsmith import EvaluationResultdef evaluate_model(dataset, tokenizer, model):results = []for example in dataset:inputs = tokenizer(example["text"], return_tensors="pt")outputs = model(**inputs)predicted_label = outputs.logits.argmax().item()result = EvaluationResult(example_id=example["id"],predicted_label=predicted_label,ground_truth_label=example["label"])results.append(result)return resultsevaluation_results = evaluate_model(dataset, tokenizer, model)```- **Upload Evaluation Results to LangSmith**:```pythonclient.log_results(dataset_id, evaluation_results)```4. **Visualize and Analyze Results**- Use LangSmith’s web interface to visualize the evaluation results.- Compare different models and versions to identify the best performing model.### Additional Tips- **Model Tuning**: Use Hugging Face’s `Trainer` class to fine-tune models on your datasets and then evaluate them using LangSmith.- **Custom Metrics**: Define custom evaluation metrics and use them to assess model performance.- **Collaboration**: Share datasets and models with team members using the Hugging Face Hub and LangSmith.By following these steps, you can effectively integrate Hugging Face models with LangSmith, leveraging the strengths of both platforms to build and evaluate robust NLP applications.If you have any specific questions or need further assistance, feel free to ask!User: Exiting...Assistant: Goodbye!
Se formos até o final da conversa, podemos ver
Entendido. Estou pronto para traduzir o texto markdown para o português, mantendo a estrutura e estilo originais. Vou apenas traduzir o conteúdo textual, sem alterar enlaces, imagens, códigos de programação ou comandos de terminal. Por favor, forneça o texto que deseja traduzir.Sim, posso ajudar com informações sobre o LangGraph! O LangGraph é um grafo de modelo de linguagem que representa as relações e conexões entre diferentes modelos de linguagem e seus componentes. Ele pode ser usado para visualizar e entender a arquitetura, os processos de treinamento e as características de desempenho de vários modelos de linguagem. LangGraph pode ser particularmente útil para pesquisadores e desenvolvedores que estão trabalhando em tarefas de processamento de linguagem natural (PLN). Ele ajuda em: 1. **Visualização da Arquitetura do Modelo**: Fornece uma visão clara e detalhada de como diferentes componentes de um modelo de linguagem estão conectados.2. **Comparação de Modelos**: Permite uma fácil comparação de diferentes modelos de linguagem em termos de sua estrutura, dados de treinamento e métricas de desempenho.3. **Compreendendo Processos de Treinamento**: Ajuda a entender as dinâmicas do treinamento e o fluxo de dados através do modelo.4. **Identificação de gargalos**: Pode ajudar na identificação de potenciais gargalos ou áreas para melhoria no modelo. Se você tiver perguntas específicas ou aspectos do LangGraph que lhe interessem, sinta-se à vontade para me informar!Gostaria de saber sobre o uso do langsmith com os modelos de linguagem do Hugging Face, a integração do Hugging Face.Resumo da conversa: Claro! Aqui está um resumo estendido da conversa: --- **Olá** **Qwen:** Olá! Como posso ajudar você hoje? Seja para obter informações, realizar uma tarefa específica ou apenas conversar, estou aqui para ajudar. **Usuário:** Estou estudando sobre langgraph, você conhece? **Qwen:** Sim, posso ajudar com informações sobre o LangGraph! O LangGraph é um grafo de modelo de linguagem que representa as relações e conexões entre diferentes modelos de linguagem e seus componentes. Ele pode ser usado para visualizar e entender a arquitetura, os processos de treinamento e as características de desempenho de vários modelos de linguagem. O LangGraph pode ser particularmente útil para pesquisadores e desenvolvedores que estão trabalhando em tarefas de processamento de linguagem natural (PLN). Ele ajuda em:1. Visualizando a Arquitetura do Modelo2. Comparando Modelos3. Compreendendo os Processos de Treinamento4. Identificando Engarrafamentos Se você tiver perguntas específicas ou aspectos do LangGraph que lhe interessem, sinta-se à vontade para me informar! **Usuário:** Este é um resumo da conversa até o momento: Claro! Aqui está um resumo da conversa acima:OláQwen: Olá! Como posso ajudar você hoje? Seja para obter informações, realizar uma tarefa específica ou apenas conversar, estou aqui para ajudar.Crie um resumo da conversa acima.Qwen: [Fornecido o resumo que você está lendo agora.] Há algo mais com o qual você precise de ajuda? **Qwen:** [Estendeu o resumo que você está lendo agora.] --- Há algo mais com o que você precisa de ajuda?------------------------------------------------``` Vemos que nas mensagens de estado apenas se conservam ``` markdown Sim, posso ajudar com informações sobre o LangGraph! O LangGraph é um gráfico de modelo de linguagem que representa as relações e conexões entre diferentes modelos de linguagem e seus componentes. Ele pode ser usado para visualizar e entender a arquitetura, os processos de treinamento e as características de desempenho de diversos modelos de linguagem. LangGraph pode ser particularmente útil para pesquisadores e desenvolvedores que estão trabalhando em tarefas de processamento de linguagem natural (PLN). Ele ajuda em: 1. **Visualizando a Arquitetura do Modelo**: Fornece uma visão clara e detalhada de como diferentes componentes de um modelo de linguagem estão conectados.2. **Comparação de Modelos**: Permite uma comparação fácil de diferentes modelos de linguagem em termos de sua estrutura, dados de treinamento e métricas de desempenho.3. **Compreendendo Processos de Treinamento**: Ajuda a compreender as dinâmicas do treinamento e o fluxo de dados através do modelo.4. **Identificação de gargalos**: Pode ajudar na identificação de potenciais gargalos ou áreas para melhoria no modelo. Se você tiver perguntas específicas ou aspectos do LangGraph que lhe interessem, sinta-se à vontade para me informar!Gostaria de saber sobre o uso do langsmith com modelos de linguagem do Hugging Face, a integração do Hugging Face.``` Isto é, a função de filtragem mantém apenas as 2 últimas mensagens. Mas tarde podemos ver
--- 2 mensagens (resultado de trim_messages - após a poda) ---Eu gostaria de saber sobre o uso do langsmith com modelos de linguagem do Hugging Face, a integração do Hugging Face.Resumo da conversa: Claro! Aqui está um resumo estendido da conversa: --- **Olá** **Qwen:** Olá! Como posso ajudá-lo hoje? Seja para obter informações, realizar uma tarefa específica ou apenas conversar, estou aqui para ajudar. **Usuário:** Estou estudando sobre langgraph, você conhece? **Qwen:** Sim, posso ajudar com informações sobre o LangGraph! O LangGraph é um gráfico de modelo de linguagem que representa as relações e conexões entre diferentes modelos de linguagem e seus componentes. Ele pode ser usado para visualizar e entender a arquitetura, os processos de treinamento e as características de desempenho de diversos modelos de linguagem. O LangGraph pode ser particularmente útil para pesquisadores e desenvolvedores que estão trabalhando em tarefas de processamento de linguagem natural (PLN). Ele ajuda em:1. Visualizando a Arquitetura do Modelo2. Comparando Modelos3. Compreendendo os Processos de Treinamento4. Identificando Engarrafamentos Se você tiver perguntas específicas ou aspectos do LangGraph que lhe interessem, sinta-se à vontade para me informar! **Usuário:** Este é um resumo da conversa até o momento: Claro! Aqui está um resumo da conversa acima:OláQwen: Olá! Como posso ajudar você hoje? Seja para obter informações, realizar uma tarefa específica ou apenas conversar, estou aqui para ajudar.Crie um resumo da conversa acima.Qwen: [Fornecido o resumo que você está lendo agora.] Há algo mais com o qual você precisa de ajuda? **Qwen:** [Estendeu o resumo que você está lendo agora.] --- Há algo mais com o que você precisa de ajuda?------------------------------------------------``` Isto é, a função de trimagem remove a mensagem do assistente porque excede os 100 tokens. Mesmo eliminando mensagens, o que significa que o LLM não as tem como contexto, ainda podemos ter uma conversa graças ao resumo da conversa que estamos gerando.
Salvar estado em SQlite
Vimos como salvar o estado do grafo na memória, mas assim que terminamos o processo, essa memória se perde, então vamos ver como salvá-la no SQLite
Primeiro precisamos instalar o pacote de sqlite para LangGraph.
pip install langgraph-checkpoint-sqlite``` Importamos as bibliotecas de sqlite e langgraph-checkpoint-sqlite. Antes, quando salvávamos o estado na memória usávamos memory_saver, agora usaremos SqliteSaver para salvar o estado em um banco de dados SQLite.
import sqlite3from langgraph.checkpoint.sqlite import SqliteSaverimport os# Create the directory if it doesn't existos.makedirs("state_db", exist_ok=True)db_path = "state_db/langgraph_sqlite.db"conn = sqlite3.connect(db_path, check_same_thread=False)memory = SqliteSaver(conn)
Vamos a criar um chatbot básico para não adicionar complexidade além da funcionalidade que queremos testar.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from langchain_core.messages import HumanMessage, AIMessage
from huggingface_hub import login
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Create the LLM model
login(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the model
MODEL = "Qwen/Qwen2.5-72B-Instruct"
model = HuggingFaceEndpoint(
repo_id=MODEL,
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
# Create the chat model
llm = ChatHuggingFace(llm=model)
# Nodes
def chat_model_node(state: State):
# Return the LLM's response in the correct state format
return {"messages": [llm.invoke(state["messages"])]}
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("chatbot_node", chat_model_node)
# Connecto nodes
graph_builder.add_edge(START, "chatbot_node")
graph_builder.add_edge("chatbot_node", END)
# Compile the graph
graph = graph_builder.compile(checkpointer=memory)
display(Image(graph.get_graph().draw_mermaid_png()))
Definimos a função para imprimir as mensagens do grafo.
# Colors for the terminalCOLOR_GREEN = "\033[32m"COLOR_YELLOW = "\033[33m"COLOR_RESET = "\033[0m"def stream_graph_updates(user_input: str, config: dict):# Initialize a flag to track if an assistant response has been printedassistant_response_printed = False# Print the user's input immediatelyprint(f"\n\n{opening_brace}COLOR_GREEN{closing_brace}User: {opening_brace}COLOR_RESET{closing_brace}{opening_brace}user_input{closing_brace}")# Create the user's message with the HumanMessage classuser_message = HumanMessage(content=user_input)# Stream events from the graph executionfor event in graph.stream({"messages": [user_message]}, config, stream_mode="values"):# event is a dictionary mapping node names to their output# Example: {opening_brace}'chatbot_node': {opening_brace}'messages': [...]{closing_brace}{closing_brace} or {opening_brace}'summarize_conversation_node': {opening_brace}'summary': '...'{closing_brace}{closing_brace}# Iterate through node name and its outputfor node_name, value in event.items():# Check if this event is from the chatbot node which should contain the assistant's replyif node_name == 'messages':# Ensure the output format is as expected (list of messages)if isinstance(value, list):# Get the messages from the eventmessages = value# Ensure 'messages' is a non-empty listif isinstance(messages, list) and messages:# Get the last message (presumably the assistant's reply)last_message = messages[-1]# Ensure the message is an instance of AIMessageif isinstance(last_message, AIMessage):# Ensure the message has content to displayif hasattr(last_message, 'content'):# Print the assistant's message contentprint(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}{last_message.content}")assistant_response_printed = True # Mark that we've printed the response# Fallback if no assistant response was printed (e.g., graph error before chatbot_node)if not assistant_response_printed:print(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}[No response generated or error occurred]")
Executamos o grafo
USER1_THREAD_ID = "USER1"config_USER1 = {opening_brace}"configurable": {opening_brace}"thread_id": USER1_THREAD_ID{closing_brace}{closing_brace}while True:user_input = input(f"\n\nUser: ")if user_input.lower() in ["quit", "exit", "q"]:print(f"{opening_brace}COLOR_GREEN{closing_brace}User: {opening_brace}COLOR_RESET{closing_brace}Exiting...")print(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}Goodbye!")breakevents = stream_graph_updates(user_input, config_USER1)
User: Hello, my name is MáximoAssistant: Hello Máximo! It's a pleasure to meet you. How can I assist you today?User: Exiting...Assistant: Goodbye!
Como se pode ver, só lhe disse como me chamo.
Agora reiniciamos o notebook para que se eliminem todos os dados salvos na RAM do notebook e voltamos a executar o código anterior.
Recriamos a memória de sqlite com SqliteSaver
import sqlite3from langgraph.checkpoint.sqlite import SqliteSaverimport os# Create the directory if it doesn't existos.makedirs("state_db", exist_ok=True)db_path = "state_db/langgraph_sqlite.db"conn = sqlite3.connect(db_path, check_same_thread=False)memory = SqliteSaver(conn)
Voltamos a criar o grafo
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from langchain_core.messages import HumanMessage, AIMessage
from huggingface_hub import login
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Create the LLM model
login(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the model
MODEL = "Qwen/Qwen2.5-72B-Instruct"
model = HuggingFaceEndpoint(
repo_id=MODEL,
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
# Create the chat model
llm = ChatHuggingFace(llm=model)
# Nodes
def chat_model_node(state: State):
# Return the LLM's response in the correct state format
return {"messages": [llm.invoke(state["messages"])]}
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("chatbot_node", chat_model_node)
# Connecto nodes
graph_builder.add_edge(START, "chatbot_node")
graph_builder.add_edge("chatbot_node", END)
# Compile the graph
graph = graph_builder.compile(checkpointer=memory)
display(Image(graph.get_graph().draw_mermaid_png()))
Re definimos a função para imprimir as mensagens do grafo.
# Colors for the terminalCOLOR_GREEN = "\033[32m"COLOR_YELLOW = "\033[33m"COLOR_RESET = "\033[0m"def stream_graph_updates(user_input: str, config: dict):# Initialize a flag to track if an assistant response has been printedassistant_response_printed = False# Print the user's input immediatelyprint(f"\n\n{opening_brace}COLOR_GREEN{closing_brace}User: {opening_brace}COLOR_RESET{closing_brace}{opening_brace}user_input{closing_brace}")# Create the user's message with the HumanMessage classuser_message = HumanMessage(content=user_input)# Stream events from the graph executionfor event in graph.stream({"messages": [user_message]}, config, stream_mode="values"):# event is a dictionary mapping node names to their output# Example: {opening_brace}'chatbot_node': {opening_brace}'messages': [...]{closing_brace}{closing_brace} or {opening_brace}'summarize_conversation_node': {opening_brace}'summary': '...'{closing_brace}{closing_brace}# Iterate through node name and its outputfor node_name, value in event.items():# Check if this event is from the chatbot node which should contain the assistant's replyif node_name == 'messages':# Ensure the output format is as expected (list of messages)if isinstance(value, list):# Get the messages from the eventmessages = value# Ensure 'messages' is a non-empty listif isinstance(messages, list) and messages:# Get the last message (presumably the assistant's reply)last_message = messages[-1]# Ensure the message is an instance of AIMessageif isinstance(last_message, AIMessage):# Ensure the message has content to displayif hasattr(last_message, 'content'):# Print the assistant's message contentprint(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}{last_message.content}")assistant_response_printed = True # Mark that we've printed the response# Fallback if no assistant response was printed (e.g., graph error before chatbot_node)if not assistant_response_printed:print(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}[No response generated or error occurred]")
E o executamos novamente
USER1_THREAD_ID = "USER1"config_USER1 = {opening_brace}"configurable": {opening_brace}"thread_id": USER1_THREAD_ID{closing_brace}{closing_brace}while True:user_input = input(f"\n\nUser: ")if user_input.lower() in ["quit", "exit", "q"]:print(f"{opening_brace}COLOR_GREEN{closing_brace}User: {opening_brace}COLOR_RESET{closing_brace}Exiting...")print(f"{opening_brace}COLOR_YELLOW{closing_brace}Assistant: {opening_brace}COLOR_RESET{closing_brace}Goodbye!")breakevents = stream_graph_updates(user_input, config_USER1)
User: What's my name?Assistant: Your name is Máximo. It's nice to know and use your name as we chat. How can I assist you today, Máximo?User: Exiting...Assistant: Goodbye!
Como pode ser visto, conseguimos recuperar o estado do grafo do banco de dados SQLite.
Memória de longo prazo, memória entre threads
A memória é uma função cognitiva que permite às pessoas armazenar, recuperar e utilizar informações para compreender, a partir do seu passado, o seu presente e o seu futuro. Existem vários tipos de memória de longo prazo que podem ser utilizados em aplicações de IA.
Introdução ao LangGraph Memory Store
LangGraph fornece o LangGraph Memory Store, que é uma forma de salvar e recuperar memória a longo prazo entre diferentes threads. Dessa maneira, em uma conversa, um usuário pode indicar que gosta de algo, e em outra conversa, o chatbot pode recuperar essa informação para gerar uma resposta mais personalizada.
Trata-se de uma classe para armazenamentos persistentes de chave-valor (key-value).
Quando objetos são armazenados na memória, três coisas são necessárias:* Um namespace para o objeto, é feito através de uma tupla* Uma key única* O valor do objeto
Vamos dar uma olhada em um exemplo
import uuidfrom langgraph.store.memory import InMemoryStorein_memory_store = InMemoryStore()# Namespace for the memory to saveuser_id = "1"namespace_for_memory = (user_id, "memories")# Save a memory to namespace as key and valuekey = str(uuid.uuid4())# The value needs to be a dictionaryvalue = {opening_brace}"food_preference" : "I like pizza"{closing_brace}# Save the memoryin_memory_store.put(namespace_for_memory, key, value)
O objeto in_memory_store que criamos tem vários métodos e um deles é search, que nos permite buscar por namespace
# Searchmemories = in_memory_store.search(namespace_for_memory)type(memories), len(memories)
(list, 1)
É uma lista de um único valor, o que faz sentido, pois armazenamos apenas um valor, então vamos vê-lo.
value = memories[0]value.dict()
{'namespace': ['1', 'memories'],'key': '70006131-948a-4d7a-bdce-78351c44fc4d','value': {'food_preference': 'I like pizza'},'created_at': '2025-05-11T07:24:31.462465+00:00','updated_at': '2025-05-11T07:24:31.462468+00:00','score': None}
Podemos ver sua key e seu value
# The key, valuememories[0].key, memories[0].value
('70006131-948a-4d7a-bdce-78351c44fc4d', {'food_preference': 'I like pizza'})
Também podemos usar o método get para obter um objeto da memória a partir de seu namespace e sua key
# Get the memory by namespace and keymemory = in_memory_store.get(namespace_for_memory, key)memory.dict()
{'namespace': ['1', 'memories'],'key': '70006131-948a-4d7a-bdce-78351c44fc4d','value': {'food_preference': 'I like pizza'},'created_at': '2025-05-11T07:24:31.462465+00:00','updated_at': '2025-05-11T07:24:31.462468+00:00'}
Assim como usamos os checkpoints para a memória de curto prazo, para a memória de longo prazo vamos usar LangGraph Store
Chatbot com memória de longo prazo
Criamos um chatbot básico, com memória de longo prazo e memória de curto prazo.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.graph.message import add_messages
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langgraph.checkpoint.memory import MemorySaver # Short-term memory
from langgraph.store.base import BaseStore # Long-term memory
from langchain_core.runnables.config import RunnableConfig
from langgraph.store.memory import InMemoryStore
from huggingface_hub import login
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Create the LLM model
login(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the model
MODEL = "Qwen/Qwen2.5-72B-Instruct"
model = HuggingFaceEndpoint(
repo_id=MODEL,
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
# Create the chat model
llm = ChatHuggingFace(llm=model)
# Chatbot instruction
MODEL_SYSTEM_MESSAGE = """You are a helpful assistant that can answer questions and help with tasks.
You have access to a long-term memory that you can use to answer questions and help with tasks.
Here is the memory (it may be empty): {memory}"""
# Create new memory from the chat history and any existing memory
CREATE_MEMORY_INSTRUCTION = """You are a helpful assistant that gets information from the user to personalize your responses.
# INFORMATION FROM THE USER:
{memory}
# INSTRUCTIONS:
1. Carefully review the chat history
2. Identify new information from the user, such as:
- Personal details (name, location)
- Preferences (likes, dislikes)
- Interests and hobbies
- Past experiences
- Goals or future plans
3. Combine any new information with the existing memory
4. Format the memory as a clear, bulleted list
5. If new information conflicts with existing memory, keep the most recent version
Remember: Only include factual information directly stated by the user. Do not make assumptions or inferences.
Based on the chat history below, please update the user information:"""
# Nodes
def call_model(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Load memory from the store and use it to personalize the chatbot's response."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve memory from the store
namespace = ("memory", user_id)
key = "user_memory"
existing_memory = store.get(namespace, key)
# Extract the actual memory content if it exists and add a prefix
if existing_memory:
# Value is a dictionary with a memory key
existing_memory_content = existing_memory.value.get('memory')
else:
existing_memory_content = "No existing memory found."
if isinstance(existing_memory_content, str):
print(f"\t[Call model debug] Existing memory: {existing_memory_content}")
else:
print(f"\t[Call model debug] Existing memory: {existing_memory_content.content}")
# Format the memory in the system prompt
system_msg = MODEL_SYSTEM_MESSAGE.format(memory=existing_memory_content)
# Respond using memory as well as the chat history
response = llm.invoke([SystemMessage(content=system_msg)]+state["messages"])
return {"messages": response}
def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Reflect on the chat history and save a memory to the store."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve existing memory from the store
namespace = ("memory", user_id)
existing_memory = store.get(namespace, "user_memory")
# Extract the memory
if existing_memory:
existing_memory_content = existing_memory.value.get('memory')
else:
existing_memory_content = "No existing memory found."
if isinstance(existing_memory_content, str):
print(f"\t[Write memory debug] Existing memory: {existing_memory_content}")
else:
print(f"\t[Write memory debug] Existing memory: {existing_memory_content.content}")
# Format the memory in the system prompt
system_msg = CREATE_MEMORY_INSTRUCTION.format(memory=existing_memory_content)
new_memory = llm.invoke([SystemMessage(content=system_msg)]+state['messages'])
if isinstance(new_memory, str):
print(f"\n\t[Write memory debug] New memory: {new_memory}")
else:
print(f"\n\t[Write memory debug] New memory: {new_memory.content}")
# Overwrite the existing memory in the store
key = "user_memory"
# Write value as a dictionary with a memory key
store.put(namespace, key, {"memory": new_memory.content})
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("call_model", call_model)
graph_builder.add_node("write_memory", write_memory)
# Connect nodes
graph_builder.add_edge(START, "call_model")
graph_builder.add_edge("call_model", "write_memory")
graph_builder.add_edge("write_memory", END)
# Store for long-term (across-thread) memory
long_term_memory = InMemoryStore()
# Checkpointer for short-term (within-thread) memory
short_term_memory = MemorySaver()
# Compile the graph
graph = graph_builder.compile(checkpointer=short_term_memory, store=long_term_memory)
display(Image(graph.get_graph().draw_mermaid_png()))
Vamos a testá-lo
# We supply a thread ID for short-term (within-thread) memory# We supply a user ID for long-term (across-thread) memoryconfig = {opening_brace}"configurable": {opening_brace}"thread_id": "1", "user_id": "1"{closing_brace}{closing_brace}# User inputinput_messages = [HumanMessage(content="Hi, my name is Maximo")]# Run the graphfor chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================Hi, my name is Maximo[Call model debug] Existing memory: No existing memory found.================================== Ai Message ==================================Hello Maximo! It's nice to meet you. How can I assist you today?[Write memory debug] Existing memory: No existing memory found.[Write memory debug] New memory:Here's the updated information I have about you:- Name: Maximo
# User inputinput_messages = [HumanMessage(content="I like to bike around San Francisco")]# Run the graphfor chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================I like to bike around San Francisco[Call model debug] Existing memory:Here's the updated information I have about you:- Name: Maximo================================== Ai Message ==================================That sounds like a great way to explore the city! San Francisco has some fantastic biking routes. Are there any specific areas or routes you enjoy biking the most, or are you looking for some new recommendations?[Write memory debug] Existing memory:Here's the updated information I have about you:- Name: Maximo[Write memory debug] New memory:Here's the updated information about you:- Name: Maximo- Location: San Francisco- Interest: Biking around San Francisco
Se recuperarmos a memória de longo prazo
# Namespace for the memory to saveuser_id = "1"namespace = ("memory", user_id)existing_memory = long_term_memory.get(namespace, "user_memory")existing_memory.dict()
{'namespace': ['memory', '1'],'key': 'user_memory','value': {'memory': " Here's the updated information about you: - Name: Maximo - Location: San Francisco - Interest: Biking around San Francisco"},'created_at': '2025-05-11T09:41:26.739207+00:00','updated_at': '2025-05-11T09:41:26.739211+00:00'}
Obtemos seu valor
print(existing_memory.value.get('memory'))
Here's the updated information about you:- Name: Maximo- Location: San Francisco- Interest: Biking around San Francisco
Agora podemos começar um novo fio de conversação, mas com a mesma memória de longo prazo. Veremos que o chatbot lembra as informações do usuário.
# We supply a user ID for across-thread memory as well as a new thread IDconfig = {opening_brace}"configurable": {opening_brace}"thread_id": "2", "user_id": "1"{closing_brace}{closing_brace}# User inputinput_messages = [HumanMessage(content="Hi! Where would you recommend that I go biking?")]# Run the graphfor chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================Hi! Where would you recommend that I go biking?[Call model debug] Existing memory:Here's the updated information about you:- Name: Maximo- Location: San Francisco- Interest: Biking around San Francisco================================== Ai Message ==================================Hi there! Given my interest in biking around San Francisco, I'd recommend a few great routes:1. **Golden Gate Park**: This is a fantastic place to bike, with wide paths that are separated from vehicle traffic. You can start at the eastern end near Stow Lake and bike all the way to the western end at Ocean Beach. There are plenty of scenic spots to stop and enjoy along the way.2. **The Embarcadero**: This route follows the waterfront from Fisherman’s Wharf to the Bay Bridge. It’s relatively flat and offers beautiful views of the San Francisco Bay and the city skyline. You can also stop by the Ferry Building for some delicious food and drinks.3. **Presidio**: The Presidio is a large park with numerous trails that offer diverse landscapes, from forests to coastal bluffs. The Crissy Field area is especially popular for its views of the Golden Gate Bridge.4. **Golden Gate Bridge**: Riding across the Golden Gate Bridge is a must-do experience. You can start from the San Francisco side, bike across the bridge, and then continue into Marin County for a longer ride with stunning views.5. **Lombard Street**: While not a long ride, biking down the famous crooked section of Lombard Street can be a fun and memorable experience. Just be prepared for the steep hill on the way back up!Each of these routes offers a unique experience, so you can choose based on your interests and the type of scenery you enjoy. Happy biking![Write memory debug] Existing memory:Here's the updated information about you:- Name: Maximo- Location: San Francisco- Interest: Biking around San Francisco[Write memory debug] New memory: 😊Let me know if you have any other questions or if you need more recommendations!
Abri um novo fio de conversa, perguntei onde poderia ir andar de bicicleta, ele se lembrou que eu tinha dito que gosto de andar de bicicleta em São Francisco e respondeu com lugares em São Francisco para os quais eu poderia ir.
Chatbot com perfil de usuário
Nota: Vamos a fazer esta seção usando o Sonnet 3.7, pois a integração da HuggingFace não possui a funcionalidade de
with_structured_outputque fornece uma saída estruturada com uma estrutura definida.
Podemos criar tipagens para que o LLM gere uma saída com uma estrutura definida por nós.
Vamos a criar um tipagem para o perfil do usuário.
from typing import TypedDict, Listclass UserProfile(TypedDict):"""User profile schema with typed fields"""user_name: str # The user's preferred nameinterests: List[str] # A list of the user's interests
Agora recriamos o grafo, mas agora com o tipo UserProfile
Vamos a usar with_structured_output para que o LLM gere uma saída com uma estrutura definida por nós, essa estrutura vamos definir com a classe Subjects que é uma classe do tipo BaseModel de Pydantic.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.graph.message import add_messages
from langchain_anthropic import ChatAnthropic
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langgraph.checkpoint.memory import MemorySaver # Short-term memory
from langgraph.store.base import BaseStore # Long-term memory
from langchain_core.runnables.config import RunnableConfig
from langgraph.store.memory import InMemoryStore
from IPython.display import Image, display
from pydantic import BaseModel, Field
import os
import dotenv
dotenv.load_dotenv()
ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Create the LLM model
llm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)
llm_with_structured_output = llm.with_structured_output(UserProfile)
# Chatbot instruction
MODEL_SYSTEM_MESSAGE = """You are a helpful assistant with memory that provides information about the user.
If you have memory for this user, use it to personalize your responses.
Here is the memory (it may be empty): {memory}"""
# Create new memory from the chat history and any existing memory
CREATE_MEMORY_INSTRUCTION = """Create or update a user profile memory based on the user's chat history.
This will be saved for long-term memory. If there is an existing memory, simply update it.
Here is the existing memory (it may be empty): {memory}"""
# Nodes
def call_model(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Load memory from the store and use it to personalize the chatbot's response."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve memory from the store
namespace = ("memory", user_id)
existing_memory = store.get(namespace, "user_memory")
# Format the memories for the system prompt
if existing_memory and existing_memory.value:
memory_dict = existing_memory.value
formatted_memory = (
f"Name: {memory_dict.get('user_name', 'Unknown')}\n"
f"Interests: {', '.join(memory_dict.get('interests', []))}"
)
else:
formatted_memory = None
# if isinstance(existing_memory_content, str):
print(f"\t[Call model debug] Existing memory: {formatted_memory}")
# else:
# print(f"\t[Call model debug] Existing memory: {existing_memory_content.content}")
# Format the memory in the system prompt
system_msg = MODEL_SYSTEM_MESSAGE.format(memory=formatted_memory)
# Respond using memory as well as the chat history
response = llm.invoke([SystemMessage(content=system_msg)]+state["messages"])
return {"messages": response}
def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Reflect on the chat history and save a memory to the store."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve existing memory from the store
namespace = ("memory", user_id)
existing_memory = store.get(namespace, "user_memory")
# Format the memories for the system prompt
if existing_memory and existing_memory.value:
memory_dict = existing_memory.value
formatted_memory = (
f"Name: {memory_dict.get('user_name', 'Unknown')}\n"
f"Interests: {', '.join(memory_dict.get('interests', []))}"
)
else:
formatted_memory = None
print(f"\t[Write memory debug] Existing memory: {formatted_memory}")
# Format the existing memory in the instruction
system_msg = CREATE_MEMORY_INSTRUCTION.format(memory=formatted_memory)
# Invoke the model to produce structured output that matches the schema
new_memory = llm_with_structured_output.invoke([SystemMessage(content=system_msg)]+state['messages'])
print(f"\t[Write memory debug] New memory: {new_memory}")
# Overwrite the existing use profile memory
key = "user_memory"
store.put(namespace, key, new_memory)
# Create graph builder
graph_builder = StateGraph(MessagesState)
# Add nodes
graph_builder.add_node("call_model", call_model)
graph_builder.add_node("write_memory", write_memory)
# Connect nodes
graph_builder.add_edge(START, "call_model")
graph_builder.add_edge("call_model", "write_memory")
graph_builder.add_edge("write_memory", END)
# Store for long-term (across-thread) memory
long_term_memory = InMemoryStore()
# Checkpointer for short-term (within-thread) memory
short_term_memory = MemorySaver()
# Compile the graph
graph = graph_builder.compile(checkpointer=short_term_memory, store=long_term_memory)
display(Image(graph.get_graph().draw_mermaid_png()))
Executamos o grafo
# We supply a thread ID for short-term (within-thread) memory# We supply a user ID for long-term (across-thread) memoryconfig = {opening_brace}"configurable": {opening_brace}"thread_id": "1", "user_id": "1"{closing_brace}{closing_brace}# User inputinput_messages = [HumanMessage(content="Hi, my name is Maximo and I like to bike around Madrid and eat salads.")]# Run the graphfor chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================Hi, my name is Maximo and I like to bike around Madrid and eat salads.[Call model debug] Existing memory: None================================== Ai Message ==================================Hello Maximo! It's nice to meet you. I see you enjoy biking around Madrid and eating salads - those are great healthy habits! Madrid has some beautiful areas to explore by bike, and the city has been improving its cycling infrastructure in recent years.Is there anything specific about Madrid's cycling routes or perhaps some good places to find delicious salads in the city that you'd like to know more about? I'd be happy to help with any questions you might have.[Write memory debug] Existing memory: None[Write memory debug] New memory: {'user_name': 'Maximo', 'interests': ['biking', 'Madrid', 'salads']{closing_brace}
Como podemos ver, o LLM gerou uma saída com a estrutura definida por nós.
Vamos a ver como foi armazenada a memória de longo prazo.
# Namespace for the memory to saveuser_id = "1"namespace = ("memory", user_id)existing_memory = long_term_memory.get(namespace, "user_memory")existing_memory.value
{'user_name': 'Maximo', 'interests': ['biking', 'Madrid', 'salads']}
Mais
Atualizar esquemas estruturados com Trustcall
No exemplo anterior, criamos perfis de usuário com dados estruturados Na realidade, o que acontece por baixo dos panos é a regeneração do perfil do usuário a cada interação. Isso gera um gasto desnecessário de tokens e pode fazer com que informações importantes do perfil do usuário sejam perdidas.
Então, para resolver isso, vamos usar a biblioteca TrustCall, que é uma biblioteca open source para atualizar esquemas JSON. Quando precisa atualizar um esquema JSON, faz isso de forma incremental, ou seja, não apaga o esquema anterior, mas vai adicionando os novos campos.
Vamos a criar um exemplo de conversação para ver como funciona.
from langchain_core.messages import HumanMessage, AIMessage# Conversationconversation = [HumanMessage(content="Hi, I'm Maximo."),AIMessage(content="Nice to meet you, Maximo."),HumanMessage(content="I really like playing soccer.")]
Criamos um esquema estruturado e um modelo de LLM
from pydantic import BaseModel, Fieldfrom typing import List# Schemaclass UserProfile(BaseModel):"""User profile schema with typed fields"""user_name: str = Field(description="The user's preferred name")interests: List[str] = Field(description="A list of the user's interests")from langchain_anthropic import ChatAnthropicimport osimport dotenvdotenv.load_dotenv()ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing# Create the LLM modelllm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)
Utilizamos a função create_extractor de trustcall para criar um extrator de dados estruturados
from trustcall import create_extractor# Create the extractortrustcall_extractor = create_extractor(llm,tools=[UserProfile],tool_choice="UserProfile")
Como se pode ver, ao método trustcall_extractor é dado um llm, que será usado como motor de busca.
Extraímos os dados estruturados
from langchain_core.messages import SystemMessage# Instructionsystem_msg = "Extract the user profile from the following conversation"# Invoke the extractorresult = trustcall_extractor.invoke({"messages": [SystemMessage(content=system_msg)]+conversation})result
{'messages': [AIMessage(content=[{'id': 'toolu_01WfgbD1fG3rJYAXGrjqjfVY', 'input': {'user_name': 'Maximo', 'interests': ['soccer']}, 'name': 'UserProfile', 'type': 'tool_use'}], additional_kwargs={}, response_metadata={'id': 'msg_01TEB3FeDKLAeHJtbKo5noyW', 'model': 'claude-3-7-sonnet-20250219', 'stop_reason': 'tool_use', 'stop_sequence': None, 'usage': {'cache_creation_input_tokens': 0, 'cache_read_input_tokens': 0, 'input_tokens': 497, 'output_tokens': 56}, 'model_name': 'claude-3-7-sonnet-20250219'}, id='run-8a15289b-fd39-4a2d-878a-fa6feaa805c5-0', tool_calls=[{'name': 'UserProfile', 'args': {'user_name': 'Maximo', 'interests': ['soccer']}, 'id': 'toolu_01WfgbD1fG3rJYAXGrjqjfVY', 'type': 'tool_call'}], usage_metadata={'input_tokens': 497, 'output_tokens': 56, 'total_tokens': 553, 'input_token_details': {'cache_read': 0, 'cache_creation': 0}})],'responses': [UserProfile(user_name='Maximo', interests=['soccer'])],'response_metadata': [{'id': 'toolu_01WfgbD1fG3rJYAXGrjqjfVY'}],'attempts': 1}
Vamos a ver os mensagens que foram geradas para extrair os dados estruturados
for m in result["messages"]:m.pretty_print()
================================== Ai Message ==================================[{'id': 'toolu_01WfgbD1fG3rJYAXGrjqjfVY', 'input': {'user_name': 'Maximo', 'interests': ['soccer']}, 'name': 'UserProfile', 'type': 'tool_use'}]Tool Calls:UserProfile (toolu_01WfgbD1fG3rJYAXGrjqjfVY)Call ID: toolu_01WfgbD1fG3rJYAXGrjqjfVYArgs:user_name: Maximointerests: ['soccer']
O esquema de UserProfile foi atualizado com o novo dado.
schema = result["responses"]schema
[UserProfile(user_name='Maximo', interests=['soccer'])]
Como vemos, o esquema é uma lista, vamos ver o tipo de dado do seu único elemento
type(schema[0])
__main__.UserProfile
Podemos convertê-lo em um dicionário com model_dump
schema[0].model_dump()
{'user_name': 'Maximo', 'interests': ['soccer']}
Graças a ter dado um LLM a trustcall_extractor, podemos pedir-lhe o que queremos que extraia
Vamos a simular que continua a conversação para ver como se atualiza o esquema
# Update the conversationupdated_conversation = [HumanMessage(content="Hi, I'm Maximo."),AIMessage(content="Nice to meet you, Maximo."),HumanMessage(content="I really like playing soccer."),AIMessage(content="It is great to play soccer! Where do you go after playing soccer?"),HumanMessage(content="I really like to go to a bakery after playing soccer."),]
Pedimos ao modelo que atualize o esquema (um JSON) por meio da biblioteca trustcall
# Update the instructionsystem_msg = f"""Update the memory (JSON doc) to incorporate new information from the following conversation"""# Invoke the extractor with the updated instruction and existing profile with the corresponding tool name (UserProfile)result = trustcall_extractor.invoke({"messages": [SystemMessage(content=system_msg)]+updated_conversation},{opening_brace}"existing": {opening_brace}"UserProfile": schema[0].model_dump(){closing_brace}{closing_brace})result
{opening_brace}'messages': [AIMessage(content=[{opening_brace}'id': 'toolu_01K1zTh33kXDAw1h18Yh2HBb', 'input': {'user_name': 'Maximo', 'interests': ['soccer', 'bakeries']{closing_brace}, 'name': 'UserProfile', 'type': 'tool_use'{closing_brace}], additional_kwargs={opening_brace}{closing_brace}, response_metadata={opening_brace}'id': 'msg_01RYUJvCdzL4b8kBYKo4BtQf', 'model': 'claude-3-7-sonnet-20250219', 'stop_reason': 'tool_use', 'stop_sequence': None, 'usage': {'cache_creation_input_tokens': 0, 'cache_read_input_tokens': 0, 'input_tokens': 538, 'output_tokens': 60}, 'model_name': 'claude-3-7-sonnet-20250219'{closing_brace}, id='run-06994472-5ba0-46cc-a512-5fcacce283fc-0', tool_calls=[{opening_brace}'name': 'UserProfile', 'args': {'user_name': 'Maximo', 'interests': ['soccer', 'bakeries']{closing_brace}, 'id': 'toolu_01K1zTh33kXDAw1h18Yh2HBb', 'type': 'tool_call'{closing_brace}], usage_metadata={'input_tokens': 538, 'output_tokens': 60, 'total_tokens': 598, 'input_token_details': {'cache_read': 0, 'cache_creation': 0{closing_brace}{closing_brace})],'responses': [UserProfile(user_name='Maximo', interests=['soccer', 'bakeries'])],'response_metadata': [{opening_brace}'id': 'toolu_01K1zTh33kXDAw1h18Yh2HBb'{closing_brace}],'attempts': 1}
Vamos a ver os mensagens que foram geradas para atualizar o esquema
for m in result["messages"]:m.pretty_print()
================================== Ai Message ==================================[{'id': 'toolu_01K1zTh33kXDAw1h18Yh2HBb', 'input': {'user_name': 'Maximo', 'interests': ['soccer', 'bakeries']}, 'name': 'UserProfile', 'type': 'tool_use'}]Tool Calls:UserProfile (toolu_01K1zTh33kXDAw1h18Yh2HBb)Call ID: toolu_01K1zTh33kXDAw1h18Yh2HBbArgs:user_name: Maximointerests: ['soccer', 'bakeries']
Vemos o esquema atualizado
updated_schema = result["responses"][0]updated_schema.model_dump()
{opening_brace}'user_name': 'Maximo', 'interests': ['soccer', 'bakeries']{closing_brace}
Chatbot com perfil de usuário atualizado com Trustcall
Voltamos a criar o grafo que atualiza o perfil do usuário, mas agora com a biblioteca trustcall
from pydantic import BaseModel, Field
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.graph.message import add_messages
from langchain_anthropic import ChatAnthropic
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langgraph.checkpoint.memory import MemorySaver # Short-term memory
from langgraph.store.base import BaseStore # Long-term memory
from langchain_core.runnables.config import RunnableConfig
from langgraph.store.memory import InMemoryStore
from IPython.display import Image, display
from pydantic import BaseModel, Field
import os
import dotenv
from trustcall import create_extractor
dotenv.load_dotenv()
ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Schema
class UserProfile(BaseModel):
""" Profile of a user """
user_name: str = Field(description="The user's preferred name")
user_location: str = Field(description="The user's location")
interests: list = Field(description="A list of the user's interests")
# Create the LLM model
llm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)
# Create the extractor
trustcall_extractor = create_extractor(
llm,
tools=[UserProfile],
tool_choice="UserProfile", # Enforces use of the UserProfile tool
)
# Chatbot instruction
MODEL_SYSTEM_MESSAGE = """You are a helpful assistant with memory that provides information about the user.
If you have memory for this user, use it to personalize your responses.
Here is the memory (it may be empty): {memory}"""
# Create new memory from the chat history and any existing memory
TRUSTCALL_INSTRUCTION = """Create or update the memory (JSON doc) to incorporate information from the following conversation:"""
# Nodes
def call_model(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Load memory from the store and use it to personalize the chatbot's response."""
"""Load memory from the store and use it to personalize the chatbot's response."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve memory from the store
namespace = ("memory", user_id)
existing_memory = store.get(namespace, "user_memory")
# Format the memories for the system prompt
if existing_memory and existing_memory.value:
memory_dict = existing_memory.value
formatted_memory = (
f"Name: {memory_dict.get('user_name', 'Unknown')}\n"
f"Location: {memory_dict.get('user_location', 'Unknown')}\n"
f"Interests: {', '.join(memory_dict.get('interests', []))}"
)
else:
formatted_memory = None
print(f"\t[Call model debug] Existing memory: {formatted_memory}")
# Format the memory in the system prompt
system_msg = MODEL_SYSTEM_MESSAGE.format(memory=formatted_memory)
# Respond using memory as well as the chat history
response = llm.invoke([SystemMessage(content=system_msg)]+state["messages"])
return {"messages": response}
def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Reflect on the chat history and save a memory to the store."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve existing memory from the store
namespace = ("memory", user_id)
existing_memory = store.get(namespace, "user_memory")
# Get the profile as the value from the list, and convert it to a JSON doc
existing_profile = {"UserProfile": existing_memory.value} if existing_memory else None
print(f"\t[Write memory debug] Existing profile: {existing_profile}")
# Invoke the extractor
result = trustcall_extractor.invoke({"messages": [SystemMessage(content=TRUSTCALL_INSTRUCTION)]+state["messages"], "existing": existing_profile})
# Get the updated profile as a JSON object
updated_profile = result["responses"][0].model_dump()
print(f"\t[Write memory debug] Updated profile: {updated_profile}")
# Save the updated profile
key = "user_memory"
store.put(namespace, key, updated_profile)
# Create graph builder
graph_builder = StateGraph(MessagesState)
# Add nodes
graph_builder.add_node("call_model", call_model)
graph_builder.add_node("write_memory", write_memory)
# Connect nodes
graph_builder.add_edge(START, "call_model")
graph_builder.add_edge("call_model", "write_memory")
graph_builder.add_edge("write_memory", END)
# Store for long-term (across-thread) memory
long_term_memory = InMemoryStore()
# Checkpointer for short-term (within-thread) memory
short_term_memory = MemorySaver()
# Compile the graph
graph = graph_builder.compile(checkpointer=short_term_memory, store=long_term_memory)
display(Image(graph.get_graph().draw_mermaid_png()))
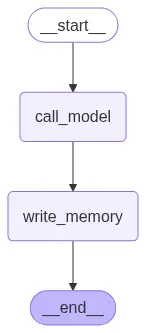
Iniciamos a conversação
# We supply a thread ID for short-term (within-thread) memory# We supply a user ID for long-term (across-thread) memoryconfig = {opening_brace}"configurable": {opening_brace}"thread_id": "1", "user_id": "1"{closing_brace}{closing_brace}# User inputinput_messages = [HumanMessage(content="Hi, my name is Maximo")]# Run the graphfor chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================Hi, my name is Maximo[Call model debug] Existing memory: None================================== Ai Message ==================================Hello Maximo! It's nice to meet you. How can I help you today? Whether you have questions, need information, or just want to chat, I'm here to assist you. Is there something specific you'd like to talk about?[Write memory debug] Existing profile: None[Write memory debug] Updated profile: {'user_name': 'Maximo', 'user_location': '<UNKNOWN>', 'interests': []}
Como podemos ver, o perfil do usuário não possui nem localização nem interesses definidos. Vamos atualizar o perfil do usuário.
# User inputinput_messages = [HumanMessage(content="I like to play soccer and I live in Madrid")]# Run the graphfor chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================I like to play soccer and I live in Madrid[Call model debug] Existing memory: Name: MaximoLocation: <UNKNOWN>Interests:================================== Ai Message ==================================Hello Maximo! It's great to learn that you live in Madrid and enjoy playing soccer. Madrid is a fantastic city with a rich soccer culture, being home to world-famous clubs like Real Madrid and Atlético Madrid.Soccer is truly a way of life in Spain, so you're in a perfect location for your interest. Do you support any particular team in Madrid? Or perhaps you enjoy playing soccer recreationally in the city's parks and facilities?Is there anything specific about Madrid or soccer you'd like to discuss further?[Write memory debug] Existing profile: {'UserProfile': {'user_name': 'Maximo', 'user_location': '<UNKNOWN>', 'interests': []{closing_brace}{closing_brace}[Write memory debug] Updated profile: {'user_name': 'Maximo', 'user_location': 'Madrid', 'interests': ['soccer']{closing_brace}
Atualizou o perfil com a localização e os interesses do usuário
Vamos ver a memória atualizada
# Namespace for the memory to saveuser_id = "1"namespace = ("memory", user_id)existing_memory = long_term_memory.get(namespace, "user_memory")existing_memory.dict()
{'namespace': ['memory', '1'],'key': 'user_memory','value': {'user_name': 'Maximo','user_location': 'Madrid','interests': ['soccer']},'created_at': '2025-05-12T17:35:03.583258+00:00','updated_at': '2025-05-12T17:35:03.583259+00:00'}
Vemos o esquema com o perfil do usuário atualizado
# The user profile saved as a JSON objectexisting_memory.value
{'user_name': 'Maximo', 'user_location': 'Madrid', 'interests': ['soccer']}
Vamos a adicionar um novo interesse do usuário
# User inputinput_messages = [HumanMessage(content="I also like to play basketball")]# Run the graphfor chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================I also like to play basketball[Call model debug] Existing memory: Name: MaximoLocation: MadridInterests: soccer================================== Ai Message ==================================That's great to know, Maximo! It's nice that you enjoy both soccer and basketball. Basketball is also quite popular in Spain, with Liga ACB being one of the strongest basketball leagues in Europe.In Madrid, you have the opportunity to follow Real Madrid's basketball section, which is one of the most successful basketball teams in Europe. The city offers plenty of courts and facilities where you can play basketball too.Do you play basketball casually with friends, or are you part of any local leagues in Madrid? And how do you balance your time between soccer and basketball?[Write memory debug] Existing profile: {'UserProfile': {'user_name': 'Maximo', 'user_location': 'Madrid', 'interests': ['soccer']{closing_brace}{closing_brace}[Write memory debug] Updated profile: {'user_name': 'Maximo', 'user_location': 'Madrid', 'interests': ['soccer', 'basketball']{closing_brace}
Voltamos a ver a memória atualizada
# Namespace for the memory to saveuser_id = "1"namespace = ("memory", user_id)existing_memory = long_term_memory.get(namespace, "user_memory")existing_memory.value
{'user_name': 'Maximo','user_location': 'Madrid','interests': ['soccer', 'basketball']}
Adicionou corretamente o novo interesse do usuário.
Com essa memória de longo prazo armazenada, podemos iniciar uma nova thread e o chatbot terá acesso ao nosso perfil atualizado.
# We supply a thread ID for short-term (within-thread) memory# We supply a user ID for long-term (across-thread) memoryconfig = {opening_brace}"configurable": {opening_brace}"thread_id": "2", "user_id": "1"{closing_brace}{closing_brace}# User inputinput_messages = [HumanMessage(content="What soccer players do you recommend for me?")]# Run the graphfor chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================What soccer players do you recommend for me?[Call model debug] Existing memory: Name: MaximoLocation: MadridInterests: soccer, basketball================================== Ai Message ==================================Based on your interest in soccer, I can recommend some players who might appeal to you. Since you're from Madrid, you might already follow Real Madrid or Atlético Madrid players, but here are some recommendations:From La Liga:- Vinícius Júnior and Jude Bellingham (Real Madrid)- Antoine Griezmann (Atlético Madrid)- Robert Lewandowski (Barcelona)- Lamine Yamal (Barcelona's young talent)International stars:- Kylian Mbappé- Erling Haaland- Mohamed Salah- Kevin De BruyneYou might also enjoy watching players with creative playing styles since you're interested in basketball as well, which is a sport that values creativity and flair - players like Rodrigo De Paul or João Félix.Is there a particular league or playing style you prefer in soccer?[Write memory debug] Existing profile: {'UserProfile': {'user_name': 'Maximo', 'user_location': 'Madrid', 'interests': ['soccer', 'basketball']{closing_brace}{closing_brace}[Write memory debug] Updated profile: {'user_name': 'Maximo', 'user_location': 'Madrid', 'interests': ['soccer', 'basketball']{closing_brace}
Como sabe que eu moro em Madrid, primeiro me sugeriu jogadores de futebol da LaLiga espanhola. E depois me sugeriu jogadores de outras ligas.
Chatbot com coleções de documentos de usuário atualizadas com Trustcall
Outra abordagem é, em vez de salvar o perfil do usuário em um único documento, salvar uma coleção de documentos, desta forma não estamos presos a um único esquema fechado. Vamos a ver como fazer isso.
from langgraph.graph import StateGraph, MessagesState, START, END
from langchain_anthropic import ChatAnthropic
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langchain_core.messages import merge_message_runs
from langgraph.checkpoint.memory import MemorySaver # Short-term memory
from langgraph.store.base import BaseStore # Long-term memory
from langchain_core.runnables.config import RunnableConfig
from langgraph.store.memory import InMemoryStore
from IPython.display import Image, display
from trustcall import create_extractor
from pydantic import BaseModel, Field
import uuid
import os
import dotenv
dotenv.load_dotenv()
ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Memory schema
class Memory(BaseModel):
"""A memory item representing a piece of information learned about the user."""
content: str = Field(description="The main content of the memory. For example: User expressed interest in learning about French.")
# Create the LLM model
llm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)
# Create the extractor
trustcall_extractor = create_extractor(
llm,
tools=[Memory],
tool_choice="Memory",
# This allows the extractor to insert new memories
enable_inserts=True,
)
# Chatbot instruction
MODEL_SYSTEM_MESSAGE = """You are a helpful chatbot. You are designed to be a companion to a user.
You have a long term memory which keeps track of information you learn about the user over time.
Current Memory (may include updated memories from this conversation):
{memory}"""
# Create new memory from the chat history and any existing memory
TRUSTCALL_INSTRUCTION = """Reflect on following interaction.
Use the provided tools to retain any necessary memories about the user.
Use parallel tool calling to handle updates and insertions simultaneously:"""
# Nodes
def call_model(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Load memory from the store and use it to personalize the chatbot's response."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve memory from the store
namespace = ("memories", user_id)
memories = store.search(namespace)
print(f"\t[Call model debug] Memories: {memories}")
# Format the memories for the system prompt
info = "\n".join(f"- {mem.value['content']}" for mem in memories)
system_msg = MODEL_SYSTEM_MESSAGE.format(memory=info)
# Respond using memory as well as the chat history
response = llm.invoke([SystemMessage(content=system_msg)]+state["messages"])
return {"messages": response}
def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Reflect on the chat history and save a memory to the store."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Define the namespace for the memories
namespace = ("memories", user_id)
# Retrieve the most recent memories for context
existing_items = store.search(namespace)
# Format the existing memories for the Trustcall extractor
tool_name = "Memory"
existing_memories = ([(existing_item.key, tool_name, existing_item.value)
for existing_item in existing_items]
if existing_items
else None
)
print(f"\t[Write memory debug] Existing memories: {existing_memories}")
# Merge the chat history and the instruction
updated_messages=list(merge_message_runs(messages=[SystemMessage(content=TRUSTCALL_INSTRUCTION)] + state["messages"]))
# Invoke the extractor
result = trustcall_extractor.invoke({"messages": updated_messages,
"existing": existing_memories})
# Save the memories from Trustcall to the store
for r, rmeta in zip(result["responses"], result["response_metadata"]):
store.put(namespace,
rmeta.get("json_doc_id", str(uuid.uuid4())),
r.model_dump(mode="json"),
)
print(f"\t[Write memory debug] Saved memories: {result['responses']}")
# Create graph builder
graph_builder = StateGraph(MessagesState)
# Add nodes
graph_builder.add_node("call_model", call_model)
graph_builder.add_node("write_memory", write_memory)
# Connect nodes
graph_builder.add_edge(START, "call_model")
graph_builder.add_edge("call_model", "write_memory")
graph_builder.add_edge("write_memory", END)
# Store for long-term (across-thread) memory
long_term_memory = InMemoryStore()
# Checkpointer for short-term (within-thread) memory
short_term_memory = MemorySaver()
# Compile the graph
graph = graph_builder.compile(checkpointer=short_term_memory, store=long_term_memory)
display(Image(graph.get_graph().draw_mermaid_png()))
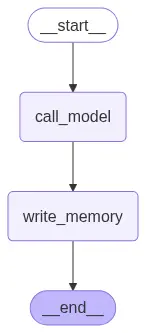
Começamos uma nova conversa
# We supply a thread ID for short-term (within-thread) memory# We supply a user ID for long-term (across-thread) memoryconfig = {opening_brace}"configurable": {opening_brace}"thread_id": "1", "user_id": "1"{closing_brace}{closing_brace}# User inputinput_messages = [HumanMessage(content="Hi, my name is Maximo")]# Run the graphfor chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================Hi, my name is Maximo[Call model debug] Memories: []================================== Ai Message ==================================Hello Maximo! It's nice to meet you. I'm your companion chatbot, here to chat, help answer questions, or just be someone to talk to.I'll remember your name is Maximo for our future conversations. What would you like to talk about today? How are you doing?[Write memory debug] Existing memories: None[Write memory debug] Saved memories: [Memory(content="User's name is Maximo.")]
Adicionamos um novo interesse do usuário
# User inputinput_messages = [HumanMessage(content="I like to play soccer")]# Run the graphfor chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================I like to play soccer[Call model debug] Memories: [Item(namespace=['memories', '1'], key='6d06c4f5-3a74-46b2-92b4-1e29ba128c90', value={'content': "User's name is Maximo."}, created_at='2025-05-12T18:32:38.070902+00:00', updated_at='2025-05-12T18:32:38.070903+00:00', score=None)]================================== Ai Message ==================================That's great to know, Maximo! Soccer is such a wonderful sport. Do you play on a team, or more casually with friends? I'd also be curious to know what position you typically play, or if you have a favorite professional team you follow. I'll remember that you enjoy soccer for our future conversations.[Write memory debug] Existing memories: [('6d06c4f5-3a74-46b2-92b4-1e29ba128c90', 'Memory', {'content': "User's name is Maximo."})][Write memory debug] Saved memories: [Memory(content='User enjoys playing soccer.')]
Como podemos ver, o novo interesse do usuário foi adicionado à memória.
Vamos ver a memória atualizada
# Namespace for the memory to saveuser_id = "1"namespace = ("memories", user_id)memories = long_term_memory.search(namespace)for m in memories:print(m.dict())
{'namespace': ['memories', '1'], 'key': '6d06c4f5-3a74-46b2-92b4-1e29ba128c90', 'value': {'content': "User's name is Maximo."}, 'created_at': '2025-05-12T18:32:38.070902+00:00', 'updated_at': '2025-05-12T18:32:38.070903+00:00', 'score': None}{'namespace': ['memories', '1'], 'key': '25d2ee8c-5890-415b-85e0-d9fb0ea4cd43', 'value': {'content': 'User enjoys playing soccer.'}, 'created_at': '2025-05-12T18:32:42.558787+00:00', 'updated_at': '2025-05-12T18:32:42.558789+00:00', 'score': None}
for m in memories:print(m.value)
{'content': "User's name is Maximo."}{'content': 'User enjoys playing soccer.'}
Vemos que são salvos documentos de memória, não um perfil do usuário.
Vamos a adicionar um novo interesse do usuário
# User inputinput_messages = [HumanMessage(content="I also like to play basketball")]# Run the graphfor chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================I also like to play basketball[Call model debug] Memories: [Item(namespace=['memories', '1'], key='6d06c4f5-3a74-46b2-92b4-1e29ba128c90', value={'content': "User's name is Maximo."}, created_at='2025-05-12T18:32:38.070902+00:00', updated_at='2025-05-12T18:32:38.070903+00:00', score=None), Item(namespace=['memories', '1'], key='25d2ee8c-5890-415b-85e0-d9fb0ea4cd43', value={'content': 'User enjoys playing soccer.'{closing_brace}, created_at='2025-05-12T18:32:42.558787+00:00', updated_at='2025-05-12T18:32:42.558789+00:00', score=None)]================================== Ai Message ==================================That's awesome, Maximo! Both soccer and basketball are fantastic sports. I'll remember that you enjoy basketball as well. Do you find yourself playing one more than the other? And similar to soccer, do you play basketball with a team or more casually? Many people enjoy the different skills and dynamics each sport offers - soccer with its continuous flow and footwork, and basketball with its fast pace and shooting precision. Any favorite basketball teams you follow?[Write memory debug] Existing memories: [('6d06c4f5-3a74-46b2-92b4-1e29ba128c90', 'Memory', {'content': "User's name is Maximo."}), ('25d2ee8c-5890-415b-85e0-d9fb0ea4cd43', 'Memory', {'content': 'User enjoys playing soccer.'})][Write memory debug] Saved memories: [Memory(content='User enjoys playing basketball.')]
Voltamos a ver a memória atualizada
# Namespace for the memory to saveuser_id = "1"namespace = ("memories", user_id)memories = long_term_memory.search(namespace)for m in memories:print(m.value)
{'content': "User's name is Maximo."}{'content': 'User enjoys playing soccer.'}{'content': 'User enjoys playing basketball.'}
Iniciamos uma nova conversa com um novo fio
# We supply a thread ID for short-term (within-thread) memory# We supply a user ID for long-term (across-thread) memoryconfig = {opening_brace}"configurable": {opening_brace}"thread_id": "2", "user_id": "1"{closing_brace}{closing_brace}# User inputinput_messages = [HumanMessage(content="What soccer players do you recommend for me?")]# Run the graphfor chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================What soccer players do you recommend for me?[Call model debug] Memories: [Item(namespace=['memories', '1'], key='6d06c4f5-3a74-46b2-92b4-1e29ba128c90', value={'content': "User's name is Maximo."}, created_at='2025-05-12T18:32:38.070902+00:00', updated_at='2025-05-12T18:32:38.070903+00:00', score=None), Item(namespace=['memories', '1'], key='25d2ee8c-5890-415b-85e0-d9fb0ea4cd43', value={'content': 'User enjoys playing soccer.'{closing_brace}, created_at='2025-05-12T18:32:42.558787+00:00', updated_at='2025-05-12T18:32:42.558789+00:00', score=None), Item(namespace=['memories', '1'], key='965f2e52-bea0-44d4-8534-4fce2bbc1c4b', value={'content': 'User enjoys playing basketball.'{closing_brace}, created_at='2025-05-12T18:33:38.613626+00:00', updated_at='2025-05-12T18:33:38.613629+00:00', score=None)]================================== Ai Message ==================================Hi Maximo! Since you enjoy soccer, I'd be happy to recommend some players you might find interesting to follow or learn from.Based on your interests in both soccer and basketball, I might suggest players who are known for their athleticism and skill:1. Lionel Messi - Widely considered one of the greatest players of all time2. Cristiano Ronaldo - Known for incredible athleticism and dedication3. Kylian Mbappé - Young talent with amazing speed and technical ability4. Kevin De Bruyne - Master of passing and vision5. Erling Haaland - Goal-scoring phenomenonIs there a particular position or playing style you're most interested in? That would help me refine my recommendations further. I could also suggest players from specific leagues or teams if you have preferences![Write memory debug] Existing memories: [('6d06c4f5-3a74-46b2-92b4-1e29ba128c90', 'Memory', {'content': "User's name is Maximo."}), ('25d2ee8c-5890-415b-85e0-d9fb0ea4cd43', 'Memory', {'content': 'User enjoys playing soccer.'}), ('965f2e52-bea0-44d4-8534-4fce2bbc1c4b', 'Memory', {'content': 'User enjoys playing basketball.'})][Write memory debug] Saved memories: [Memory(content='User asked for soccer player recommendations, suggesting an active interest in following professional soccer beyond just playing it.')]
Vemos que se lembrava que gostávamos de futebol e basquete.
Humano no loop
Embora um agente possa realizar tarefas, para certas tarefas, é necessário que haja uma supervisão humana. Isso é chamado de human in the loop. Vamos ver como isso pode ser feito com LangGraph.
A camada de persistência de LangGraph suporta fluxos de trabalho com humanos no loop, permitindo que a execução seja interrompida e retomada com base nos comentários dos usuários. A interface principal desta funcionalidade é a função interrupt. Chamando interrupt dentro de um nó, a execução será interrompida. A execução pode ser retomada, junto com a nova contribuição humana, passada em uma primitiva Command. interrupt é similar ao comando de Python input(), mas com algumas considerações extras.
Vamos adicionar ao chatbot que tem memória a curto prazo e acesso a ferramentas, mas faremos uma mudança, que é adicionar uma simples ferramenta human_assistance. Esta ferramenta utiliza interrupt para receber informações de um ser humano.
Primeiro carregamos os valores das chaves API.
import osimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")
Criamos o grafo
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesclass State(TypedDict):messages: Annotated[list, add_messages]graph_builder = StateGraph(State)
Definimos a ferramenta de busca
from langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultswrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)search_tool = TavilySearchResults(api_wrapper=wrapper, max_results=2)
Agora criamos a tool de ajuda humana
from langgraph.types import Command, interruptfrom langchain_core.tools import tool@tooldef human_assistance(query: str) -> str:"""Request assistance from a human expert. Use this tool ONLY ONCE per conversation.After receiving the expert's response, you should provide an elaborated response to the user based on the information receivedbased on the information received, without calling this tool again.Args:query: The query to ask the human expert.Returns:The response from the human expert."""human_response = interrupt({"query": query})return human_response["data"]
LangGraph obtém informações das ferramentas através da documentação da ferramenta, ou seja, o docstring da função. Portanto, é muito importante gerar um bom docstring para a ferramenta.
Criamos uma lista de tools
tools_list = [search_tool, human_assistance]
A seguir, o LLM com as bind_tools e adicionamos ao grafo
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing# Create the LLMlogin(token=HUGGINGFACE_TOKEN)MODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Modification: tell the LLM which tools it can callllm_with_tools = llm.bind_tools(tools_list)# Define the chatbot functiondef chatbot_function(state: State):message = llm_with_tools.invoke(state["messages"])assert len(message.tool_calls) <= 1return {opening_brace}"messages": [message]}# Add the chatbot nodegraph_builder.add_node("chatbot_node", chatbot_function)
<langgraph.graph.state.StateGraph at 0x10764b380>
Se você reparar, mudamos a forma de definir a função chatbot_function, pois agora ela precisa lidar com a interrupção.
Adicionamos a tool_node ao grafo
from langgraph.prebuilt import ToolNode, tools_conditiontool_node = ToolNode(tools=tools_list)graph_builder.add_node("tools", tool_node)graph_builder.add_conditional_edges("chatbot_node", tools_condition)graph_builder.add_edge("tools", "chatbot_node")
<langgraph.graph.state.StateGraph at 0x10764b380>
Adicionamos o nódo de START ao gráfico
graph_builder.add_edge(START, "chatbot_node")
<langgraph.graph.state.StateGraph at 0x10764b380>
Criamos um checkpointer MemorySaver.
from langgraph.checkpoint.memory import MemorySavermemory = MemorySaver()
Compilamos o gráfico com o checkpointer
graph = graph_builder.compile(checkpointer=memory)
O representamos graficamente
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(f"Error al visualizar el grafo: {e}")
Agora vamos solicitar ao chatbot com uma pergunta que envolverá a nova ferramenta human_assistance:
user_input = "I need some expert guidance for building an AI agent. Could you request assistance for me?"config = {opening_brace}"configurable": {opening_brace}"thread_id": "1"{closing_brace}{closing_brace}events = graph.stream({"messages": [{"role": "user", "content": user_input}]},config,stream_mode="values",)for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================ Human Message =================================I need some expert guidance for building an AI agent. Could you request assistance for me?================================== Ai Message ==================================Tool Calls:human_assistance (0)Call ID: 0Args:query: I need some expert guidance for building an AI agent. Could you provide me with some advice?
Como se pode ver, o chatbot gerou uma chamada para a ferramenta de assistência humana.
Chamadas de Ferramentas:human_assistance (0)ID da Chamada: 0Argumentos:Eu preciso de algumas orientações de especialistas para construir um agente de IA. Você poderia fornecer conselhos sobre considerações-chave, melhores práticas e armadilhas potenciais a serem evitadas?``` Mas tarde a execução foi interrompida. Vamos verificar o estado do grafo. snapshot = graph.get_state(config)snapshot.next
('tools',)
Vemos que se deteveu no nó de tools. Analisamos como se definiu a ferramenta human_assistance.
from langgraph.types import Command, interruptfrom langchain_core.tools import tool @tooldef assistência_humana(consulta: str) -> str:"""Solicite assistência de um especialista humano. Use esta ferramenta APENAS UMA VEZ por conversa.Claro, entendi. Vou traduzir o texto markdown para o português, mantendo a estrutura e estilo originais, sem modificar enlaces, imagens, códigos de programação ou comandos de terminal. Aguardo o texto que você deseja traduzir.com base nas informações recebidas, sem chamar esta ferramenta novamente. Argumentos:A consulta para perguntar ao especialista humano. Retorna:A resposta do especialista humano.""""""```markdown human_response = interromper({"consulta": consulta}) ```return human_response["data"]``` Chamando a ferramenta interrupt, a execução será interrompida, semelhante à função do Python input().
O progresso é mantido com base em nossa escolha de checkpointer. Ou seja, a escolha de onde o estado do grafo é salvo. Portanto, se estamos persistindo (salvando o estado do grafo) com um banco de dados como SQLite, Postgres, etc, podemos retomar a execução a qualquer momento, desde que o banco de dados esteja ativo.
Aqui estamos persistindo (salvando o estado do grafo) com o ponteiro de verificação na memória RAM, portanto podemos retomar a qualquer momento enquanto nosso kernel Python estiver em execução. No meu caso, enquanto não reiniciar o kernel do meu Jupyter Notebook.
Para retomar a execução, passamos um objeto Command que contém os dados esperados pela ferramenta. O formato desses dados pode ser personalizado de acordo com nossas necessidades. Aqui, apenas precisamos de um dicionário com uma chave data
human_response = ("We, the experts are here to help! We'd recommend you check out LangGraph to build your agent.""It's much more reliable and extensible than simple autonomous agents.")human_command = Command(resume={opening_brace}"data": human_response})events = graph.stream(human_command, config, stream_mode="values")for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================== Ai Message ==================================Tool Calls:human_assistance (0)Call ID: 0Args:query: I need some expert guidance for building an AI agent. Could you provide me with some advice?================================= Tool Message =================================Name: human_assistanceWe, the experts are here to help! We'd recommend you check out LangGraph to build your agent.It's much more reliable and extensible than simple autonomous agents.================================== Ai Message ==================================The experts recommend checking out LangGraph for building your AI agent. It's known for being more reliable and extensible compared to simple autonomous agents.
Como vemos, o chatbot esperou que um humano fornecesse a resposta e, em seguida, gerou uma resposta baseada nas informações recebidas. Pedimos ajuda sobre um especialista sobre como criar agentes, o humano disse que o melhor é usar LangGraph, e o chatbot gerou uma resposta com base nessas informações.
Mas ainda tem a possibilidade de realizar pesquisas na web. Então, agora vamos pedir as últimas notícias sobre LangGraph.
user_input = "What's the latest news about LangGraph?"events = graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace},config,stream_mode="values",)for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================ Human Message =================================What's the latest news about LangGraph?================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: latest news LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangChain - Changelog", "url": "https://changelog.langchain.com/", "content": "LangGraph `interrupt`: Simplifying human-in-the-loop agents --------------------------------------------------- Our latest feature in LangGraph, interrupt , makes building human-in-the-loop workflows easier. Agents aren’t perfect, so keeping humans “in the loop”... December 16, 2024 [...] LangGraph 🔁 Modify graph state from tools in LangGraph --------------------------------------------- LangGraph's latest update gives you greater control over your agents by enabling tools to directly update the graph state. This is a game-changer for use... December 18, 2024 [...] LangGraph Platform Custom authentication & access control for LangGraph Platform ------------------------------------------------------------- Today, we're thrilled to announce Custom Authentication and Resource-Level Access Control for Python deployments in LangGraph Cloud and self-hosted... December 20, 2024", "score": 0.78650844}, {opening_brace}"title": "LangGraph 0.3 Release: Prebuilt Agents - LangChain Blog", "url": "https://blog.langchain.dev/langgraph-0-3-release-prebuilt-agents/", "content": "LangGraph 0.3 Release: Prebuilt Agents 2 min read Feb 27, 2025 By Nuno Campos and Vadym Barda Over the past year, we’ve invested heavily in making LangGraph the go-to framework for building AI agents. With companies like Replit, Klarna, LinkedIn and Uber choosing to build on top of LangGraph, we have more conviction than ever that we are on the right path. [...] Up to this point, we’ve had one higher level abstraction and it’s lived in the main langgraph package. It was create_react_agent, a wrapper for creating a simple tool calling agent. Today, we are splitting that out of langgraph as part of a 0.3 release, and moving it into langgraph-prebuilt. We are also introducing a new set of prebuilt agents built on top of LangGraph, in both Python and JavaScript. Over the past three weeks, we’ve already released a few of these: [...] Published Time: 2025-02-27T15:09:15.000Z LangGraph 0.3 Release: Prebuilt Agents Skip to content Case Studies In the Loop LangChain Docs Changelog Sign in Subscribe", "score": 0.72348577}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: latest news about LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangChain - Changelog", "url": "https://changelog.langchain.com/", "content": "LangGraph 🔁 Modify graph state from tools in LangGraph --------------------------------------------- LangGraph's latest update gives you greater control over your agents by enabling tools to directly update the graph state. This is a game-changer for use... December 18, 2024 [...] LangGraph `interrupt`: Simplifying human-in-the-loop agents --------------------------------------------------- Our latest feature in LangGraph, interrupt , makes building human-in-the-loop workflows easier. Agents aren’t perfect, so keeping humans “in the loop”... December 16, 2024 [...] LangGraph Platform Custom authentication & access control for LangGraph Platform ------------------------------------------------------------- Today, we're thrilled to announce Custom Authentication and Resource-Level Access Control for Python deployments in LangGraph Cloud and self-hosted... December 20, 2024", "score": 0.79732054}, {opening_brace}"title": "LangGraph 0.3 Release: Prebuilt Agents - LangChain Blog", "url": "https://blog.langchain.dev/langgraph-0-3-release-prebuilt-agents/", "content": "LangGraph 0.3 Release: Prebuilt Agents 2 min read Feb 27, 2025 By Nuno Campos and Vadym Barda Over the past year, we’ve invested heavily in making LangGraph the go-to framework for building AI agents. With companies like Replit, Klarna, LinkedIn and Uber choosing to build on top of LangGraph, we have more conviction than ever that we are on the right path. [...] Up to this point, we’ve had one higher level abstraction and it’s lived in the main langgraph package. It was create_react_agent, a wrapper for creating a simple tool calling agent. Today, we are splitting that out of langgraph as part of a 0.3 release, and moving it into langgraph-prebuilt. We are also introducing a new set of prebuilt agents built on top of LangGraph, in both Python and JavaScript. Over the past three weeks, we’ve already released a few of these: [...] Published Time: 2025-02-27T15:09:15.000Z LangGraph 0.3 Release: Prebuilt Agents Skip to content Case Studies In the Loop LangChain Docs Changelog Sign in Subscribe", "score": 0.7552947}]================================== Ai Message ==================================The latest news about LangGraph includes several updates and releases. Firstly, the 'interrupt' feature has been added, which simplifies creating human-in-the-loop workflows, essential for maintaining oversight of AI agents. Secondly, an update allows tools to modify the graph state directly, providing more control over the agents. Lastly, custom authentication and resource-level access control have been implemented for Python deployments in LangGraph Cloud and self-hosted environments. In addition, LangGraph released version 0.3, which introduces prebuilt agents in both Python and JavaScript, aimed at making it even easier to develop AI agents.
Ele buscou as últimas notícias sobre LangGraph e gerou uma resposta baseada nas informações recebidas.
Vamos escrever tudo junto para que seja mais compreensível
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginfrom langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultsfrom langchain_core.messages import ToolMessagefrom langgraph.prebuilt import ToolNode, tools_conditionfrom langgraph.types import Command, interruptfrom langchain_core.tools import toolfrom langgraph.checkpoint.memory import MemorySaverfrom IPython.display import Image, displayimport jsonimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]# Toolswrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)tool_search = TavilySearchResults(api_wrapper=wrapper, max_results=2)@tooldef human_assistance(query: str) -> str:"""Request assistance from a human expert. Use this tool ONLY ONCE per conversation.After receiving the expert's response, you should provide an elaborated response to the user based on the information receivedbased on the information received, without calling this tool again.Args:query: The query to ask the human expert.Returns:The response from the human expert."""human_response = interrupt({"query": query})return human_response["data"]tools_list = [tool_search, human_assistance]# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Create the LLM with toolsllm_with_tools = llm.bind_tools(tools_list)# Tool nodetool_node = ToolNode(tools=tools_list)# Functionsdef chatbot_function(state: State):message = llm_with_tools.invoke(state["messages"])assert len(message.tool_calls) <= 1return {opening_brace}"messages": [message]}# Start to build the graphgraph_builder = StateGraph(State)# Add nodes to the graphgraph_builder.add_node("chatbot_node", chatbot_function)graph_builder.add_node("tools", tool_node)# Add edgesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_conditional_edges( "chatbot_node", tools_condition)graph_builder.add_edge("tools", "chatbot_node")# Compile the graphmemory = MemorySaver()graph = graph_builder.compile(checkpointer=memory)# Display the graphtry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")
Error al visualizar el grafo: Failed to reach https://mermaid.ink/ API while trying to render your graph after 1 retries. To resolve this issue:1. Check your internet connection and try again2. Try with higher retry settings: `draw_mermaid_png(..., max_retries=5, retry_delay=2.0)`3. Use the Pyppeteer rendering method which will render your graph locally in a browser: `draw_mermaid_png(..., draw_method=MermaidDrawMethod.PYPPETEER)`
Pedimos novamente ajuda ao chatbot para criar agentes. Solicitamos que ele busque ajuda.
user_input = "I need some expert guidance for building an AI agent. Could you request assistance for me?"config = {opening_brace}"configurable": {opening_brace}"thread_id": "1"{closing_brace}{closing_brace}events = graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace},config,stream_mode="values",)for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================ Human Message =================================I need some expert guidance for building an AI agent. Could you request assistance for me?================================== Ai Message ==================================Tool Calls:human_assistance (0)Call ID: 0Args:query: I need expert guidance for building an AI agent.
Vemos em qual estado ficou o grafo
snapshot = graph.get_state(config)snapshot.next
('tools',)
Damos a você a assistência que está pedindo
human_response = ("We, the experts are here to help! We'd recommend you check out LangGraph to build your agent.""It's much more reliable and extensible than simple autonomous agents.")human_command = Command(resume={opening_brace}"data": human_response})events = graph.stream(human_command, config, stream_mode="values")for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================== Ai Message ==================================Tool Calls:human_assistance (0)Call ID: 0Args:query: I need expert guidance for building an AI agent.================================= Tool Message =================================Name: human_assistanceWe, the experts are here to help! We'd recommend you check out LangGraph to build your agent.It's much more reliable and extensible than simple autonomous agents.================================== Ai Message ==================================Tool Calls:human_assistance (0)Call ID: 0Args:query: I need some expert guidance for building an AI agent. Could you recommend a platform and any tips for getting started?
E por último, pedimos que procure na internet as últimas notícias sobre LangGraph
user_input = "What's the latest news about LangGraph?"events = graph.stream({opening_brace}"messages": [{opening_brace}"role": "user", "content": user_input{closing_brace}]{closing_brace},config,stream_mode="values",)for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================ Human Message =================================What's the latest news about LangGraph?================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: latest news about LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangChain Blog", "url": "https://blog.langchain.dev/", "content": "LangSmith Incident on May 1, 2025 Requests to the US LangSmith API from both the web application and SDKs experienced an elevated error rate for 28 minutes on May 1, 2025 Featured How Klarna's AI assistant redefined customer support at scale for 85 million active users Is LangGraph Used In Production? Introducing Interrupt: The AI Agent Conference by LangChain Top 5 LangGraph Agents in Production 2024 [...] See how Harmonic uses LangSmith and LangGraph products to streamline venture investing workflows. Why Definely chose LangGraph for building their multi-agent AI system See how Definely used LangGraph to design a multi-agent system to help lawyers speed up their workflows. Introducing End-to-End OpenTelemetry Support in LangSmith LangSmith now provides end-to-end OpenTelemetry (OTel) support for applications built on LangChain and/or LangGraph.", "score": 0.6811549}, {opening_brace}"title": "LangGraph + UiPath: advancing agentic automation together", "url": "https://www.uipath.com/blog/product-and-updates/langgraph-uipath-advancing-agentic-automation-together", "content": "Raghu Malpani, Chief Technology Officer at UiPath, emphasizes the significance of these announcements for the UiPath developer community: Our collaboration with LangChain on LangSmith and Agent Protocol advances interoperability across agent frameworks. Further, by enabling the deployment of LangGraph agents into UiPath's enterprise-grade infrastructure, we are expanding the capabilities of our platform and opening up more possibilities for our developer community. [...] Today, we’re excited to announce: Native support for LangSmith observability in the UiPath LLM Gateway via OpenTelemetry (OTLP), enabling developers to monitor, debug, and evaluate LLM-powered features in UiPath using LangSmith either in LangChain’s cloud or self-hosted on-premises. This feature is currently in private preview.", "score": 0.6557114}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: latest news about LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangChain Blog", "url": "https://blog.langchain.dev/", "content": "LangSmith Incident on May 1, 2025 Requests to the US LangSmith API from both the web application and SDKs experienced an elevated error rate for 28 minutes on May 1, 2025 Featured How Klarna's AI assistant redefined customer support at scale for 85 million active users Is LangGraph Used In Production? Introducing Interrupt: The AI Agent Conference by LangChain Top 5 LangGraph Agents in Production 2024 [...] See how Harmonic uses LangSmith and LangGraph products to streamline venture investing workflows. Why Definely chose LangGraph for building their multi-agent AI system See how Definely used LangGraph to design a multi-agent system to help lawyers speed up their workflows. Introducing End-to-End OpenTelemetry Support in LangSmith LangSmith now provides end-to-end OpenTelemetry (OTel) support for applications built on LangChain and/or LangGraph.", "score": 0.6811549}, {opening_brace}"title": "LangGraph + UiPath: advancing agentic automation together", "url": "https://www.uipath.com/blog/product-and-updates/langgraph-uipath-advancing-agentic-automation-together", "content": "Raghu Malpani, Chief Technology Officer at UiPath, emphasizes the significance of these announcements for the UiPath developer community: Our collaboration with LangChain on LangSmith and Agent Protocol advances interoperability across agent frameworks. Further, by enabling the deployment of LangGraph agents into UiPath's enterprise-grade infrastructure, we are expanding the capabilities of our platform and opening up more possibilities for our developer community. [...] Today, we’re excited to announce: Native support for LangSmith observability in the UiPath LLM Gateway via OpenTelemetry (OTLP), enabling developers to monitor, debug, and evaluate LLM-powered features in UiPath using LangSmith either in LangChain’s cloud or self-hosted on-premises. This feature is currently in private preview.", "score": 0.6557114}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: latest news about LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangChain Blog", "url": "https://blog.langchain.dev/", "content": "LangSmith Incident on May 1, 2025 Requests to the US LangSmith API from both the web application and SDKs experienced an elevated error rate for 28 minutes on May 1, 2025 Featured How Klarna's AI assistant redefined customer support at scale for 85 million active users Is LangGraph Used In Production? Introducing Interrupt: The AI Agent Conference by LangChain Top 5 LangGraph Agents in Production 2024 [...] See how Harmonic uses LangSmith and LangGraph products to streamline venture investing workflows. Why Definely chose LangGraph for building their multi-agent AI system See how Definely used LangGraph to design a multi-agent system to help lawyers speed up their workflows. Introducing End-to-End OpenTelemetry Support in LangSmith LangSmith now provides end-to-end OpenTelemetry (OTel) support for applications built on LangChain and/or LangGraph.", "score": 0.6811549}, {opening_brace}"title": "LangGraph + UiPath: advancing agentic automation together", "url": "https://www.uipath.com/blog/product-and-updates/langgraph-uipath-advancing-agentic-automation-together", "content": "Raghu Malpani, Chief Technology Officer at UiPath, emphasizes the significance of these announcements for the UiPath developer community: Our collaboration with LangChain on LangSmith and Agent Protocol advances interoperability across agent frameworks. Further, by enabling the deployment of LangGraph agents into UiPath's enterprise-grade infrastructure, we are expanding the capabilities of our platform and opening up more possibilities for our developer community. [...] Today, we’re excited to announce: Native support for LangSmith observability in the UiPath LLM Gateway via OpenTelemetry (OTLP), enabling developers to monitor, debug, and evaluate LLM-powered features in UiPath using LangSmith either in LangChain’s cloud or self-hosted on-premises. This feature is currently in private preview.", "score": 0.6557114}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: latest news about LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangChain Blog", "url": "https://blog.langchain.dev/", "content": "LangSmith Incident on May 1, 2025 Requests to the US LangSmith API from both the web application and SDKs experienced an elevated error rate for 28 minutes on May 1, 2025 Featured How Klarna's AI assistant redefined customer support at scale for 85 million active users Is LangGraph Used In Production? Introducing Interrupt: The AI Agent Conference by LangChain Top 5 LangGraph Agents in Production 2024 [...] See how Harmonic uses LangSmith and LangGraph products to streamline venture investing workflows. Why Definely chose LangGraph for building their multi-agent AI system See how Definely used LangGraph to design a multi-agent system to help lawyers speed up their workflows. Introducing End-to-End OpenTelemetry Support in LangSmith LangSmith now provides end-to-end OpenTelemetry (OTel) support for applications built on LangChain and/or LangGraph.", "score": 0.6811549}, {opening_brace}"title": "LangGraph + UiPath: advancing agentic automation together", "url": "https://www.uipath.com/blog/product-and-updates/langgraph-uipath-advancing-agentic-automation-together", "content": "Raghu Malpani, Chief Technology Officer at UiPath, emphasizes the significance of these announcements for the UiPath developer community: Our collaboration with LangChain on LangSmith and Agent Protocol advances interoperability across agent frameworks. Further, by enabling the deployment of LangGraph agents into UiPath's enterprise-grade infrastructure, we are expanding the capabilities of our platform and opening up more possibilities for our developer community. [...] Today, we’re excited to announce: Native support for LangSmith observability in the UiPath LLM Gateway via OpenTelemetry (OTLP), enabling developers to monitor, debug, and evaluate LLM-powered features in UiPath using LangSmith either in LangChain’s cloud or self-hosted on-premises. This feature is currently in private preview.", "score": 0.6557114}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: latest news about LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangChain Blog", "url": "https://blog.langchain.dev/", "content": "LangSmith Incident on May 1, 2025 Requests to the US LangSmith API from both the web application and SDKs experienced an elevated error rate for 28 minutes on May 1, 2025 Featured How Klarna's AI assistant redefined customer support at scale for 85 million active users Is LangGraph Used In Production? Introducing Interrupt: The AI Agent Conference by LangChain Top 5 LangGraph Agents in Production 2024 [...] See how Harmonic uses LangSmith and LangGraph products to streamline venture investing workflows. Why Definely chose LangGraph for building their multi-agent AI system See how Definely used LangGraph to design a multi-agent system to help lawyers speed up their workflows. Introducing End-to-End OpenTelemetry Support in LangSmith LangSmith now provides end-to-end OpenTelemetry (OTel) support for applications built on LangChain and/or LangGraph.", "score": 0.6811549}, {opening_brace}"title": "LangGraph + UiPath: advancing agentic automation together", "url": "https://www.uipath.com/blog/product-and-updates/langgraph-uipath-advancing-agentic-automation-together", "content": "Raghu Malpani, Chief Technology Officer at UiPath, emphasizes the significance of these announcements for the UiPath developer community: Our collaboration with LangChain on LangSmith and Agent Protocol advances interoperability across agent frameworks. Further, by enabling the deployment of LangGraph agents into UiPath's enterprise-grade infrastructure, we are expanding the capabilities of our platform and opening up more possibilities for our developer community. [...] Today, we’re excited to announce: Native support for LangSmith observability in the UiPath LLM Gateway via OpenTelemetry (OTLP), enabling developers to monitor, debug, and evaluate LLM-powered features in UiPath using LangSmith either in LangChain’s cloud or self-hosted on-premises. This feature is currently in private preview.", "score": 0.6557114}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: latest news about LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangChain Blog", "url": "https://blog.langchain.dev/", "content": "LangSmith Incident on May 1, 2025 Requests to the US LangSmith API from both the web application and SDKs experienced an elevated error rate for 28 minutes on May 1, 2025 Featured How Klarna's AI assistant redefined customer support at scale for 85 million active users Is LangGraph Used In Production? Introducing Interrupt: The AI Agent Conference by LangChain Top 5 LangGraph Agents in Production 2024 [...] See how Harmonic uses LangSmith and LangGraph products to streamline venture investing workflows. Why Definely chose LangGraph for building their multi-agent AI system See how Definely used LangGraph to design a multi-agent system to help lawyers speed up their workflows. Introducing End-to-End OpenTelemetry Support in LangSmith LangSmith now provides end-to-end OpenTelemetry (OTel) support for applications built on LangChain and/or LangGraph.", "score": 0.6811549}, {opening_brace}"title": "LangGraph + UiPath: advancing agentic automation together", "url": "https://www.uipath.com/blog/product-and-updates/langgraph-uipath-advancing-agentic-automation-together", "content": "Raghu Malpani, Chief Technology Officer at UiPath, emphasizes the significance of these announcements for the UiPath developer community: Our collaboration with LangChain on LangSmith and Agent Protocol advances interoperability across agent frameworks. Further, by enabling the deployment of LangGraph agents into UiPath's enterprise-grade infrastructure, we are expanding the capabilities of our platform and opening up more possibilities for our developer community. [...] Today, we’re excited to announce: Native support for LangSmith observability in the UiPath LLM Gateway via OpenTelemetry (OTLP), enabling developers to monitor, debug, and evaluate LLM-powered features in UiPath using LangSmith either in LangChain’s cloud or self-hosted on-premises. This feature is currently in private preview.", "score": 0.6557114}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: latest news about LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangChain Blog", "url": "https://blog.langchain.dev/", "content": "LangSmith Incident on May 1, 2025 Requests to the US LangSmith API from both the web application and SDKs experienced an elevated error rate for 28 minutes on May 1, 2025 Featured How Klarna's AI assistant redefined customer support at scale for 85 million active users Is LangGraph Used In Production? Introducing Interrupt: The AI Agent Conference by LangChain Top 5 LangGraph Agents in Production 2024 [...] See how Harmonic uses LangSmith and LangGraph products to streamline venture investing workflows. Why Definely chose LangGraph for building their multi-agent AI system See how Definely used LangGraph to design a multi-agent system to help lawyers speed up their workflows. Introducing End-to-End OpenTelemetry Support in LangSmith LangSmith now provides end-to-end OpenTelemetry (OTel) support for applications built on LangChain and/or LangGraph.", "score": 0.6811549}, {opening_brace}"title": "LangGraph + UiPath: advancing agentic automation together", "url": "https://www.uipath.com/blog/product-and-updates/langgraph-uipath-advancing-agentic-automation-together", "content": "Raghu Malpani, Chief Technology Officer at UiPath, emphasizes the significance of these announcements for the UiPath developer community: Our collaboration with LangChain on LangSmith and Agent Protocol advances interoperability across agent frameworks. Further, by enabling the deployment of LangGraph agents into UiPath's enterprise-grade infrastructure, we are expanding the capabilities of our platform and opening up more possibilities for our developer community. [...] Today, we’re excited to announce: Native support for LangSmith observability in the UiPath LLM Gateway via OpenTelemetry (OTLP), enabling developers to monitor, debug, and evaluate LLM-powered features in UiPath using LangSmith either in LangChain’s cloud or self-hosted on-premises. This feature is currently in private preview.", "score": 0.6557114}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: latest news about LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangChain Blog", "url": "https://blog.langchain.dev/", "content": "LangSmith Incident on May 1, 2025 Requests to the US LangSmith API from both the web application and SDKs experienced an elevated error rate for 28 minutes on May 1, 2025 Featured How Klarna's AI assistant redefined customer support at scale for 85 million active users Is LangGraph Used In Production? Introducing Interrupt: The AI Agent Conference by LangChain Top 5 LangGraph Agents in Production 2024 [...] See how Harmonic uses LangSmith and LangGraph products to streamline venture investing workflows. Why Definely chose LangGraph for building their multi-agent AI system See how Definely used LangGraph to design a multi-agent system to help lawyers speed up their workflows. Introducing End-to-End OpenTelemetry Support in LangSmith LangSmith now provides end-to-end OpenTelemetry (OTel) support for applications built on LangChain and/or LangGraph.", "score": 0.6811549}, {opening_brace}"title": "LangGraph + UiPath: advancing agentic automation together", "url": "https://www.uipath.com/blog/product-and-updates/langgraph-uipath-advancing-agentic-automation-together", "content": "Raghu Malpani, Chief Technology Officer at UiPath, emphasizes the significance of these announcements for the UiPath developer community: Our collaboration with LangChain on LangSmith and Agent Protocol advances interoperability across agent frameworks. Further, by enabling the deployment of LangGraph agents into UiPath's enterprise-grade infrastructure, we are expanding the capabilities of our platform and opening up more possibilities for our developer community. [...] Today, we’re excited to announce: Native support for LangSmith observability in the UiPath LLM Gateway via OpenTelemetry (OTLP), enabling developers to monitor, debug, and evaluate LLM-powered features in UiPath using LangSmith either in LangChain’s cloud or self-hosted on-premises. This feature is currently in private preview.", "score": 0.6557114}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: Latest news about LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangChain Blog", "url": "https://blog.langchain.dev/", "content": "LangSmith Incident on May 1, 2025 Requests to the US LangSmith API from both the web application and SDKs experienced an elevated error rate for 28 minutes on May 1, 2025 Featured How Klarna's AI assistant redefined customer support at scale for 85 million active users Is LangGraph Used In Production? Introducing Interrupt: The AI Agent Conference by LangChain Top 5 LangGraph Agents in Production 2024 [...] See how Harmonic uses LangSmith and LangGraph products to streamline venture investing workflows. Why Definely chose LangGraph for building their multi-agent AI system See how Definely used LangGraph to design a multi-agent system to help lawyers speed up their workflows. Introducing End-to-End OpenTelemetry Support in LangSmith LangSmith now provides end-to-end OpenTelemetry (OTel) support for applications built on LangChain and/or LangGraph.", "score": 0.67758125}, {opening_brace}"title": "LangGraph + UiPath: advancing agentic automation together", "url": "https://www.uipath.com/blog/product-and-updates/langgraph-uipath-advancing-agentic-automation-together", "content": "Raghu Malpani, Chief Technology Officer at UiPath, emphasizes the significance of these announcements for the UiPath developer community: Our collaboration with LangChain on LangSmith and Agent Protocol advances interoperability across agent frameworks. Further, by enabling the deployment of LangGraph agents into UiPath's enterprise-grade infrastructure, we are expanding the capabilities of our platform and opening up more possibilities for our developer community. [...] Today, we’re excited to announce: Native support for LangSmith observability in the UiPath LLM Gateway via OpenTelemetry (OTLP), enabling developers to monitor, debug, and evaluate LLM-powered features in UiPath using LangSmith either in LangChain’s cloud or self-hosted on-premises. This feature is currently in private preview.", "score": 0.6522641}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: latest news about LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangGraph - LangChain", "url": "https://www.langchain.com/langgraph", "content": "“As Ally advances its exploration of Generative AI, our tech labs is excited by LangGraph, the new library from LangChain, which is central to our experiments", "score": 0.98559}, {opening_brace}"title": "Evaluating LangGraph Framework : Series 1 | by Jalaj Agrawal", "url": "https://medium.com/@jalajagr/evaluating-langgraph-as-a-multiagent-framework-a-10-dimensional-framework-series-1-c7203b7f4659", "content": ": LangGraph excels with its intuitive graph-based abstraction that allows new developers to build working multi-agent systems within hours.", "score": 0.98196}]================================== Ai Message ==================================It looks like LangGraph has been generating some significant buzz in the AI community, especially for its capabilities in building multi-agent systems. Here are a few highlights from the latest news:1. **LangGraph in Production**: Companies like Klarna and Definely are already using LangGraph to build and optimize their AI systems. Klarna has leveraged LangGraph to enhance their customer support, and Definely has used it to design a multi-agent system to speed up legal workflows.2. **Integration with UiPath**: LangChain and UiPath have collaborated to advance agentic automation. This partnership includes native support for LangSmith observability in UiPath’s LLM Gateway via OpenTelemetry, which will allow developers to monitor, debug, and evaluate LLM-powered features more effectively.3. **Intuitive Design**: LangGraph is praised for its intuitive graph-based abstraction, which enables developers to build working multi-agent systems quickly, even if they are new to the field.4. **Community and Conferences**: LangChain is also hosting an AI Agent Conference called "Interrupt," which could be a great opportunity to learn more about the latest developments and best practices in building AI agents.If you're considering using LangGraph for your project, these resources and updates might provide valuable insights and support. Would you like more detailed information on any specific aspect of LangGraph?
Mais
Aprovação do uso de ferramentas
Nota: Vamos a fazer esta seção usando Sonnet 3.7, pois na data da escrita deste post, é o melhor modelo para uso com agentes, e é o único que entende quando deve chamar as ferramentas e quando não deve para este exemplo
Podemos inserir um human in the loop para aprovar o uso de ferramentas. Vamos criar um chatbot com várias ferramentas para realizar operações matemáticas, para isso na hora de construir o grafo indicamos onde queremos inserir o breakpoint (graph_builder.compile(interrupt_before=["tools"], checkpointer=memory))
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.checkpoint.memory import MemorySaver
from langchain_core.tools import tool
from langchain_anthropic import ChatAnthropic
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")
memory = MemorySaver()
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Tools
@tool
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
Returns:
The product of a and b.
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""Adds a and b.
Args:
a: first int
b: second int
Returns:
The sum of a and b.
"""
return a + b
@tool
def subtract(a: int, b: int) -> int:
"""Subtract b from a.
Args:
a: first int
b: second int
Returns:
The difference between a and b.
"""
return a - b
@tool
def divide(a: int, b: int) -> float:
"""Divide a by b.
Args:
a: first int
b: second int
Returns:
The quotient of a and b.
"""
return a / b
tools_list = [multiply, add, subtract, divide]
# Create the LLM model
llm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)
llm_with_tools = llm.bind_tools(tools_list)
# Nodes
def chat_model_node(state: State):
system_message = "You are a helpful assistant that can use tools to answer questions. Once you have the result of a tool, provide a final answer without calling more tools."
messages = [SystemMessage(content=system_message)] + state["messages"]
return {"messages": [llm_with_tools.invoke(messages)]}
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("chatbot_node", chat_model_node)
tool_node = ToolNode(tools=tools_list)
graph_builder.add_node("tools", tool_node)
# Connecto nodes
graph_builder.add_edge(START, "chatbot_node")
graph_builder.add_conditional_edges("chatbot_node", tools_condition)
graph_builder.add_edge("tools", "chatbot_node")
graph_builder.add_edge("chatbot_node", END)
# Compile the graph
graph = graph_builder.compile(interrupt_before=["tools"], checkpointer=memory)
display(Image(graph.get_graph().draw_mermaid_png()))
Como vemos no grafo, há um interrupt antes de usar as tools. Isso significa que vai parar antes de usá-las para pedir nossa permissão.
# Inputinitial_input = {opening_brace}"messages": HumanMessage(content="Multiply 2 and 3")}config = {"configurable": {"thread_id": "1"}}# Run the graph until the first interruptionfor event in graph.stream(initial_input, config, stream_mode="updates"):if 'chatbot_node' in event:print(event['chatbot_node']['messages'][-1].pretty_print())else:print(event)
================================== Ai Message ==================================[{'text': "I'll multiply 2 and 3 for you.", 'type': 'text'}, {'id': 'toolu_01QDuind1VBHWtvifELN9SPf', 'input': {'a': 2, 'b': 3}, 'name': 'multiply', 'type': 'tool_use'}]Tool Calls:multiply (toolu_01QDuind1VBHWtvifELN9SPf)Call ID: toolu_01QDuind1VBHWtvifELN9SPfArgs:a: 2b: 3None{'__interrupt__': ()}
Como podemos ver, o LLM sabe que tem que usar a ferramenta multiply, mas a execução é interrompida, pois precisa esperar que um ser humano autorize o uso da ferramenta.
Podemos ver o estado em que ficou o grafo
state = graph.get_state(config)state.next
('tools',)
Como vemos, ficou no nó de tools.
Podemos criar uma função (não no grafo, mas fora do grafo, para melhorar a experiência do usuário e fazer com que ele entenda por que a execução pára) que peça ao usuário para aprovar o uso da ferramenta.
Criamos um novo thread_id para que seja criado um novo estado.
# Inputinitial_input = {opening_brace}"messages": HumanMessage(content="Multiply 2 and 3")}config = {opening_brace}"configurable": {opening_brace}"thread_id": "2"{closing_brace}{closing_brace}# Run the graph until the first interruptionfor event in graph.stream(initial_input, config, stream_mode="updates"):function_name = Nonefunction_args = Noneif 'chatbot_node' in event:for element in event['chatbot_node']['messages'][-1].content:if element['type'] == 'text':print(element['text'])elif element['type'] == 'tool_use':function_name = element['name']function_args = element['input']print(f"The LLM wants to use the tool {function_name} with the arguments {function_args}")elif '__interrupt__' in event:passelse:print(event)question = f"Do you approve the use of the tool {function_name} with the arguments {function_args}? (y/n)"user_approval = input(question)print(f"{question}: {user_approval}")if user_approval.lower() == 'y':print("User approved the use of the tool")for event in graph.stream(None, config, stream_mode="updates"):if 'chatbot_node' in event:for element in event['chatbot_node']['messages'][-1].content:if isinstance(element, str):print(element, end="")elif 'tools' in event:result = event['tools']['messages'][-1].contenttool_used = event['tools']['messages'][-1].nameprint(f"The result of the tool {tool_used} is {result}")else:print(event)
I'll multiply 2 and 3 for you.The LLM wants to use the tool multiply with the arguments {'a': 2, 'b': 3}Do you approve the use of the tool None with the arguments None? (y/n): yUser approved the use of the toolThe result of the tool multiply is 6The result of multiplying 2 and 3 is 6.
Podemos ver que nos perguntou se aprovamos o uso da tool de multiplicação, aprovamos e o grafo terminou a execução. Vendo o estado do grafo.
state = graph.get_state(config)state.next
()
Vemos que o próximo estado do grafo está vazio, isso indica que a execução do grafo foi concluída.
Modificação do estado
Nota: Vamos a fazer esta seção usando Sonnet 3.7, pois na data da escrita do post, é o melhor modelo para uso com agentes e é o único que entende quando deve chamar as ferramentas e quando não deve para este exemplo.
Vamos repetir o exemplo anterior, mas em vez de interromper o grafo antes do uso de uma tool, vamos interrompê-lo no LLM. Para isso, ao construir o grafo, indicamos que queremos parar no agente (graph_builder.compile(interrupt_before=["chatbot_node"], checkpointer=memory))
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.checkpoint.memory import MemorySaver
from langchain_core.tools import tool
from langchain_anthropic import ChatAnthropic
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")
memory = MemorySaver()
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Tools
@tool
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
Returns:
The product of a and b.
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""Adds a and b.
Args:
a: first int
b: second int
Returns:
The sum of a and b.
"""
return a + b
@tool
def subtract(a: int, b: int) -> int:
"""Subtract b from a.
Args:
a: first int
b: second int
Returns:
The difference between a and b.
"""
return a - b
@tool
def divide(a: int, b: int) -> float:
"""Divide a by b.
Args:
a: first int
b: second int
Returns:
The quotient of a and b.
"""
return a / b
tools_list = [multiply, add, subtract, divide]
# Create the LLM model
llm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)
llm_with_tools = llm.bind_tools(tools_list)
# Nodes
def chat_model_node(state: State):
system_message = "You are a helpful assistant that can use tools to answer questions. Once you have the result of a tool, provide a final answer without calling more tools."
messages = [SystemMessage(content=system_message)] + state["messages"]
return {"messages": [llm_with_tools.invoke(messages)]}
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("chatbot_node", chat_model_node)
tool_node = ToolNode(tools=tools_list)
graph_builder.add_node("tools", tool_node)
# Connecto nodes
graph_builder.add_edge(START, "chatbot_node")
graph_builder.add_conditional_edges("chatbot_node", tools_condition)
graph_builder.add_edge("tools", "chatbot_node")
graph_builder.add_edge("chatbot_node", END)
# Compile the graph
graph = graph_builder.compile(interrupt_before=["chatbot_node"], checkpointer=memory)
display(Image(graph.get_graph().draw_mermaid_png()))
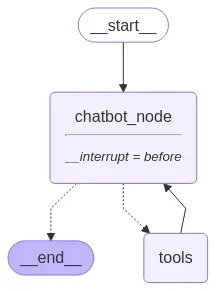
Vemos na representação do grafo que há um interrupt antes da execução de chatbot_node, assim, antes de o chatbot ser executado, a execução será interrompida e nós teremos que fazer com que continue.
Agora vamos pedir novamente uma multiplicação
# Inputinitial_input = {opening_brace}"messages": HumanMessage(content="Multiply 2 and 3")}config = {"configurable": {"thread_id": "1"}}# Run the graph until the first interruptionfor event in graph.stream(initial_input, config, stream_mode="updates"):if 'chatbot_node' in event:print(event['chatbot_node']['messages'][-1].pretty_print())else:print(event)
{'__interrupt__': ()}
Podemos ver que não fez nada. Se vemos o estado
state = graph.get_state(config)state.next
('chatbot_node',)
Vemos que o próximo nó é o do chatbot. Além disso, se observarmos seus valores, veremos a mensagem que lhe enviamos.
state.values
{'messages': [HumanMessage(content='Multiply 2 and 3', additional_kwargs={}, response_metadata={}, id='08fd6084-ecd2-4156-ab24-00d2d5c26f00')]}
Agora procedemos a modificar o estado, adicionando uma nova mensagem
graph.update_state(config,{opening_brace}"messages": [HumanMessage(content="No, actually multiply 3 and 3!")]})
{'configurable': {'thread_id': '1','checkpoint_ns': '','checkpoint_id': '1f027eb6-6c8b-6b6a-8001-bc0f8942566c'}}
Obtemos o novo estado
new_state = graph.get_state(config)new_state.next
('chatbot_node',)
O próximo nó ainda é o do chatbot, mas agora vamos ver as mensagens
new_state.values
{'messages': [HumanMessage(content='Multiply 2 and 3', additional_kwargs={}, response_metadata={}, id='08fd6084-ecd2-4156-ab24-00d2d5c26f00'),HumanMessage(content='No, actually multiply 3 and 3!', additional_kwargs={}, response_metadata={}, id='e95394c2-e62e-47d2-b9b2-51eba40f3e22')]}
Vemos que foi adicionado o novo. Então fazemos com que continue a execução.
for event in graph.stream(None, config, stream_mode="values"):event['messages'][-1].pretty_print()
================================ Human Message =================================No, actually multiply 3 and 3!================================== Ai Message ==================================[{'text': "I'll multiply 3 and 3 for you.", 'type': 'text'{closing_brace}, {opening_brace}'id': 'toolu_01UABhLnEdg5ZqxVQTE5pGUx', 'input': {'a': 3, 'b': 3}, 'name': 'multiply', 'type': 'tool_use'{closing_brace}]Tool Calls:multiply (toolu_01UABhLnEdg5ZqxVQTE5pGUx)Call ID: toolu_01UABhLnEdg5ZqxVQTE5pGUxArgs:a: 3b: 3================================= Tool Message =================================Name: multiply9
Foi feita a multiplicação de 3 por 3, que é a modificação do estado que fizemos, e não 2 por 3, que é o que pedimos da primeira vez.
Isso pode ser útil quando temos um agente e queremos verificar se o que ele faz está correto, então podemos entrar na execução e modificar o estado.
Pontos de interrupção dinâmicos
Até agora, criamos pontos de parada estáticos através da compilação do grafo, mas podemos criar pontos de parada dinâmicos usando NodeInterrupt. Isso é útil porque a execução pode ser interrompida por regras lógicas introduzidas por programação.
Estes NodeInterrupt permitem personalizar como o usuário será notificado sobre a interrupção.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.errors import NodeInterrupt
from huggingface_hub import login
from IPython.display import Image, display
import os
import dotenv
dotenv.load_dotenv()
HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")
memory_saver = MemorySaver()
class State(TypedDict):
messages: Annotated[list, add_messages]
os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing
# Create the LLM model
login(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the model
MODEL = "Qwen/Qwen2.5-72B-Instruct"
model = HuggingFaceEndpoint(
repo_id=MODEL,
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
# Create the chat model
llm = ChatHuggingFace(llm=model)
# Nodes
def chatbot_function(state: State):
max_len = 15
input_message = state["messages"][-1]
# Check len message
if len(input_message.content) > max_len:
raise NodeInterrupt(f"Received input is longer than {max_len} characters --> {input_message}")
# Invoke the LLM with the messages
response = llm.invoke(state["messages"])
# Return the LLM's response in the correct state format
return {"messages": [response]}
# Create graph builder
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("chatbot_node", chatbot_function)
# Connecto nodes
graph_builder.add_edge(START, "chatbot_node")
graph_builder.add_edge("chatbot_node", END)
# Compile the graph
graph = graph_builder.compile(checkpointer=memory_saver)
display(Image(graph.get_graph().draw_mermaid_png()))
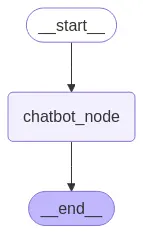
Como podemos ver, criamos uma interrupção no caso de o mensagem ser longa. Vamos testá-la.
initial_input = {opening_brace}"messages": HumanMessage(content="Hello, how are you? My name is Máximo")}config = {"configurable": {"thread_id": "1"}}# Run the graph until the first interruptionfor event in graph.stream(initial_input, config, stream_mode="updates"):if 'chatbot_node' in event:print(event['chatbot_node']['messages'][-1].pretty_print())else:print(event)
{'__interrupt__': (Interrupt(value="Received input is longer than 15 characters --> content='Hello, how are you? My name is Máximo' additional_kwargs={} response_metadata={} id='2bdc6d41-0cfe-4d3c-8748-ca7d46fd5a60'", resumable=False, ns=None),)}
Efetivamente, a interrupção foi pausada e nos deu a mensagem de erro que criamos.
Se vemos o nódo no qual ele parou
state = graph.get_state(config)state.next
('chatbot_node',)
Vemos que está parado no nódo do chatbot. Podemos voltar a fazer com que continue com a execução, mas vai nos dar o mesmo erro.
for event in graph.stream(None, config, stream_mode="updates"):if 'chatbot_node' in event:print(event['chatbot_node']['messages'][-1].pretty_print())else:print(event)
{'__interrupt__': (Interrupt(value="Received input is longer than 15 characters --> content='Hello, how are you? My name is Máximo' additional_kwargs={} response_metadata={} id='2bdc6d41-0cfe-4d3c-8748-ca7d46fd5a60'", resumable=False, ns=None),)}
Então temos que modificar o estado
graph.update_state(config,{opening_brace}"messages": [HumanMessage(content="How are you?")]})
{'configurable': {'thread_id': '1','checkpoint_ns': '','checkpoint_id': '1f027f13-5827-6a18-8001-4209d5a866f0'}}
Voltamos a ver o estado e seus valores
new_state = graph.get_state(config)print(f"Siguiente nodo: {new_state.next}")print("Valores:")for value in new_state.values["messages"]:print(f"\t{value.content}")
Siguiente nodo: ('chatbot_node',)Valores:Hello, how are you? My name is MáximoHow are you?
A última mensagem é mais curta, portanto tentamos retomar a execução do grafo
for event in graph.stream(None, config, stream_mode="updates"):if 'chatbot_node' in event:print(event['chatbot_node']['messages'][-1].pretty_print())else:print(event)
================================== Ai Message ==================================Hello Máximo! I'm doing well, thank you for asking. How about you? How can I assist you today?None
Personalização do estado
Nota: Vamos a fazer este tópico usando Sonnet 3.7, pois na data da escrita do post, é o melhor modelo para uso com agentes e é o único que entende quando deve chamar as ferramentas e quando não deve.
Até agora, confiamos em um estado simples com uma entrada, uma lista de mensagens. Pode-se ir longe com esse estado simples, mas se deseja definir um comportamento complexo sem depender da lista de mensagens, podem ser adicionados campos adicionais ao estado.
Aqui vamos ver um novo cenário, no qual o chatbot está utilizando a ferramenta de busca para encontrar informações específicas e reenviá-las a um ser humano para revisão. Vamos fazer com que o chatbot investigue o aniversário de uma entidade. Adicionaremos name e birthday como chaves do estado.
Primeiro carregamos os valores das chaves API.
import osimport dotenvdotenv.load_dotenv()TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")
Criamos o novo estado
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph.message import add_messagesclass State(TypedDict):messages: Annotated[list, add_messages]name: strbirthday: str
Adicionar essa informação ao estado torna-a facilmente acessível por outros nós do grafo (por exemplo, um nó que armazena ou processa a informação), bem como a camada de persistência do grafo.
Agora criamos o grafo
from langgraph.graph import StateGraph, START, ENDgraph_builder = StateGraph(State)
Definimos a ferramenta de busca
from langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultswrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)search_tool = TavilySearchResults(api_wrapper=wrapper, max_results=2)
Agora criamos a ferramenta de assistência humana. Nesta ferramenta, preencheremos as chaves de estado dentro da nossa ferramenta human_assistance. Isso permite que um ser humano revise a informação antes de ela ser armazenada no estado. Voltaremos a usar Command, desta vez para emitir uma atualização de estado a partir do interior da nossa ferramenta.
from langchain_core.messages import ToolMessagefrom langchain_core.tools import InjectedToolCallId, toolfrom langgraph.types import Command, interrupt@tool# Note that because we are generating a ToolMessage for a state update, we# generally require the ID of the corresponding tool call. We can use# LangChain's InjectedToolCallId to signal that this argument should not# be revealed to the model in the tool's schema.def human_assistance(name: str, birthday: str, tool_call_id: Annotated[str, InjectedToolCallId]) -> str:"""Request assistance from a human expert. Use this tool ONLY ONCE per conversation.After receiving the expert's response, you should provide an elaborated response to the user based on the information receivedbased on the information received, without calling this tool again.Args:query: The query to ask the human expert.Returns:The response from the human expert."""human_response = interrupt({opening_brace}"question": "Is this correct?","name": name,"birthday": birthday,},)# If the information is correct, update the state as-is.if human_response.get("correct", "").lower().startswith("y"):verified_name = nameverified_birthday = birthdayresponse = "Correct"# Otherwise, receive information from the human reviewer.else:verified_name = human_response.get("name", name)verified_birthday = human_response.get("birthday", birthday)response = f"Made a correction: {human_response}"# This time we explicitly update the state with a ToolMessage inside# the tool.state_update = {opening_brace}"name": verified_name,"birthday": verified_birthday,"messages": [ToolMessage(response, tool_call_id=tool_call_id)],{closing_brace}# We return a Command object in the tool to update our state.return Command(update=state_update)
Nós usamos ToolMessage que é usado para passar o resultado de executar uma tool de volta a um modelo e InjectedToolCallId
Criamos uma lista de tools
tools_list = [search_tool, human_assistance]
A seguir, o LLM com as bind_tools e adicionamos ao grafo
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom langchain_anthropic import ChatAnthropic# Create the LLMllm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)# Modification: tell the LLM which tools it can callllm_with_tools = llm.bind_tools(tools_list)# Define the chatbot functiondef chatbot_function(state: State):message = llm_with_tools.invoke(state["messages"])# Because we will be interrupting during tool execution,# we disable parallel tool calling to avoid repeating any# tool invocations when we resume.assert len(message.tool_calls) <= 1return {opening_brace}"messages": [message]}# Add the chatbot nodegraph_builder.add_node("chatbot_node", chatbot_function)
<langgraph.graph.state.StateGraph at 0x120b4f380>
Adicionamos a tool ao grafo
from langgraph.prebuilt import ToolNode, tools_conditiontool_node = ToolNode(tools=tools_list)graph_builder.add_node("tools", tool_node)graph_builder.add_conditional_edges("chatbot_node", tools_condition)graph_builder.add_edge("tools", "chatbot_node")
<langgraph.graph.state.StateGraph at 0x120b4f380>
Adicionamos o nó de START ao gráfico
graph_builder.add_edge(START, "chatbot_node")
<langgraph.graph.state.StateGraph at 0x120b4f380>
Criamos um checkpointer MemorySaver.
from langgraph.checkpoint.memory import MemorySavermemory = MemorySaver()
Compilamos o grafo com o checkpointer
graph = graph_builder.compile(checkpointer=memory)
O representamos graficamente
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(f"Error al visualizar el grafo: {e}")
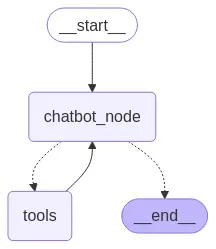
Vamos pedir ao nosso chatbot que procure o "aniversário" da biblioteca de LangGraph.
Direcionaremos o chatbot até a ferramenta human_assistance uma vez que tenha as informações necessárias. Os argumentos name e birthday são obrigatórios para a ferramenta human_assistance, então eles obrigam o chatbot a gerar propostas para esses campos.
user_input = (
"Can you look up when LangGraph was released? "
"When you have the answer, use the human_assistance tool for review."
)
config = {"configurable": {"thread_id": "1"}}
events = graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config,
stream_mode="values",
)
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
Parou devido ao interrupt na ferramenta human_assistance. Neste caso, o chatbot, com a ferramenta de busca, determinou que a data de LangGraph é janeiro de 2023, mas não é a data exata, sendo 17 de janeiro de 2024, portanto podemos introduzi-la nós mesmos.
human_command = Command(resume={opening_brace}"name": "LangGraph","birthday": "Jan 17, 2024",},)events = graph.stream(human_command, config, stream_mode="values")for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================== Ai Message ==================================[{'text': 'Based on my search, I found that LangGraph was launched in January 2023. However, I noticed some inconsistencies in the information, as one source mentions it was launched in January 2023, while the PyPI page shows a version history starting from 2024. Let me request human assistance to verify this information:', 'type': 'text'}, {'id': 'toolu_019EopKn8bLi3ksvUVY2Mt5p', 'input': {'name': 'LangGraph', 'birthday': 'January 2023'}, 'name': 'human_assistance', 'type': 'tool_use'}]Tool Calls:human_assistance (toolu_019EopKn8bLi3ksvUVY2Mt5p)Call ID: toolu_019EopKn8bLi3ksvUVY2Mt5pArgs:name: LangGraphbirthday: January 2023================================= Tool Message =================================Name: human_assistanceMade a correction: {'name': 'LangGraph', 'birthday': 'Jan 17, 2024'}================================== Ai Message ==================================Thank you for the expert review and correction! Based on the human expert's feedback, I can now provide you with the accurate information:LangGraph was released on January 17, 2024, not January 2023 as one of the search results incorrectly stated.This is an important correction, as it means LangGraph is a relatively recent framework in the LLM orchestration space, having been available for less than a year at this point. LangGraph is developed by LangChain and is designed for building stateful, multi-actor applications with LLMs.
snapshot = graph.get_state(config){opening_brace}k: v for k, v in snapshot.values.items() if k in ("name", "birthday")}
{'name': 'LangGraph', 'birthday': 'Jan 17, 2024'}
Agora a data está correta graças à intervenção humana para modificar os valores do estado
Reescrevo todo o código para que seja mais fácil de entender
import osimport dotenvfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph.message import add_messagesfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.types import Command, interruptfrom langgraph.prebuilt import ToolNode, tools_conditionfrom langgraph.checkpoint.memory import MemorySaverfrom langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultsfrom langchain_core.messages import ToolMessagefrom langchain_core.tools import InjectedToolCallId, toolfrom langchain_anthropic import ChatAnthropicdotenv.load_dotenv()TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]name: strbirthday: str# Toolswrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)search_tool = TavilySearchResults(api_wrapper=wrapper, max_results=2)@tool# Note that because we are generating a ToolMessage for a state update, we# generally require the ID of the corresponding tool call. We can use# LangChain's InjectedToolCallId to signal that this argument should not# be revealed to the model in the tool's schema.def human_assistance(name: str, birthday: str, tool_call_id: Annotated[str, InjectedToolCallId]) -> str:"""Request assistance from a human expert. Use this tool ONLY ONCE per conversation.After receiving the expert's response, you should provide an elaborated response to the user based on the information receivedbased on the information received, without calling this tool again.Args:query: The query to ask the human expert.Returns:The response from the human expert."""human_response = interrupt({opening_brace}"question": "Is this correct?","name": name,"birthday": birthday,},)# If the information is correct, update the state as-is.if human_response.get("correct", "").lower().startswith("y"):verified_name = nameverified_birthday = birthdayresponse = "Correct"# Otherwise, receive information from the human reviewer.else:verified_name = human_response.get("name", name)verified_birthday = human_response.get("birthday", birthday)response = f"Made a correction: {human_response}"# This time we explicitly update the state with a ToolMessage inside# the tool.state_update = {opening_brace}"name": verified_name,"birthday": verified_birthday,"messages": [ToolMessage(response, tool_call_id=tool_call_id)],{closing_brace}# We return a Command object in the tool to update our state.return Command(update=state_update)tools_list = [search_tool, human_assistance]tool_node = ToolNode(tools=tools_list)# Create the LLMllm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)llm_with_tools = llm.bind_tools(tools_list)# Define the chatbot functiondef chatbot_function(state: State):message = llm_with_tools.invoke(state["messages"])# Because we will be interrupting during tool execution,# we disable parallel tool calling to avoid repeating any# tool invocations when we resume.assert len(message.tool_calls) <= 1return {opening_brace}"messages": [message]}# Graphgraph_builder = StateGraph(State)# Nodesgraph_builder.add_node("tools", tool_node)graph_builder.add_node("chatbot_node", chatbot_function)# Edgesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_conditional_edges("chatbot_node", tools_condition)graph_builder.add_edge("tools", "chatbot_node")# Checkpointermemory = MemorySaver()# Compilegraph = graph_builder.compile(checkpointer=memory)# Visualizefrom IPython.display import Image, displaytry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")
Error al visualizar el grafo: Failed to reach https://mermaid.ink/ API while trying to render your graph after 1 retries. To resolve this issue:1. Check your internet connection and try again2. Try with higher retry settings: `draw_mermaid_png(..., max_retries=5, retry_delay=2.0)`3. Use the Pyppeteer rendering method which will render your graph locally in a browser: `draw_mermaid_png(..., draw_method=MermaidDrawMethod.PYPPETEER)`
Vamos pedir ao nosso chatbot que procure o "aniversário" da biblioteca de LangGraph.
user_input = (
"Can you look up when LangGraph was released? "
"When you have the answer, use the human_assistance tool for review."
)
config = {"configurable": {"thread_id": "1"}}
events = graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config,
stream_mode="values",
)
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
Parou pelo interrupt na ferramenta human_assistance. Neste caso, o chatbot, com a ferramenta de busca, determinou que a data do LangGraph é janeiro de 2023, mas não é a data exata, é 17 de janeiro de 2024, então podemos introduzi-la nós mesmos.
human_command = Command(resume={opening_brace}"name": "LangGraph","birthday": "Jan 17, 2024",},)events = graph.stream(human_command, config, stream_mode="values")for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================== Ai Message ==================================[{'text': "Based on my search, I found that LangGraph was launched in January 2023. It's described as a low-level orchestration framework for building agentic applications. Since its release, it has seen significant improvements, including a stable 0.1 release in June (presumably 2024). Let me now get human verification of this information:", 'type': 'text'{closing_brace}, {opening_brace}'id': 'toolu_016h3391yFhtPDhQvwjNgs7W', 'input': {opening_brace}'name': 'Information Verification', 'birthday': 'January 2023'{closing_brace}, 'name': 'human_assistance', 'type': 'tool_use'{closing_brace}]Tool Calls:human_assistance (toolu_016h3391yFhtPDhQvwjNgs7W)Call ID: toolu_016h3391yFhtPDhQvwjNgs7WArgs:name: Information Verificationbirthday: January 2023================================= Tool Message =================================Name: human_assistanceMade a correction: {opening_brace}'name': 'LangGraph', 'birthday': 'Jan 17, 2024'}================================== Ai Message ==================================Thank you for the expert correction! I need to update my response with the accurate information.LangGraph was actually released on January 17, 2024 - not January 2023 as I initially found in my search results. This is a significant correction, as it means LangGraph is a much more recent framework than the search results indicated.The expert has provided the specific date (January 17, 2024) for LangGraph's release, making it a fairly new tool in the AI orchestration ecosystem. This timing aligns better with the mention of its stable 0.1 release in June 2024, as this would be about 5 months after its initial launch.
snapshot = graph.get_state(config){opening_brace}k: v for k, v in snapshot.values.items() if k in ("name", "birthday")}
{opening_brace}'name': 'LangGraph', 'birthday': 'Jan 17, 2024'}
Agora a data está correta graças à intervenção humana para modificar os valores do estado
Atualização manual do estado
LangGraph fornece um alto grau de controle sobre o estado do aplicativo. Por exemplo, em qualquer ponto (mesmo quando é interrompido), podemos reescrever manualmente uma chave do estado usando graph.update_state:
Vamos a atualizar o name do estado para LangGraph (biblioteca).
graph.update_state(config, {opening_brace}"name": "LangGraph (library)"})
{opening_brace}'configurable': {'thread_id': '1','checkpoint_ns': '','checkpoint_id': '1f010a5a-8a70-618e-8006-89107653db68'}}
Se agora vermos o estado com graph.get_state(config) veremos que o name foi atualizado.
snapshot = graph.get_state(config){opening_brace}k: v for k, v in snapshot.values.items() if k in ("name", "birthday")}
{'name': 'LangGraph (library)', 'birthday': 'Jan 17, 2024'}
As atualizações de estado manuais gerarão uma trilha em LangSmith. Elas podem ser usadas para controlar fluxos de trabalho de human in the loop, como pode ser visto nesta guia.
Pontos de controle
Em um fluxo de trabalho típico de um chatbot, o usuário interage com o chatbot uma ou mais vezes para realizar uma tarefa. Nas seções anteriores, vimos como adicionar memória e um human in the loop para poder verificar nosso estado de gráfico e controlar as respostas futuras.
Mas, talvez um usuário queira começar a partir de uma resposta anterior e quer ramificar para explorar um resultado separado. Isso é útil para aplicações de agentes, quando um fluxo falha eles podem voltar a um checkpoint anterior e tentar outra estratégia.
LangGraph fornece essa possibilidade através dos checkpoints
Primeiro carregamos os valores das chaves da API.
import osimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")
Criamos o novo estado
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph.message import add_messagesclass State(TypedDict):messages: Annotated[list, add_messages]
Agora criamos o grafo
from langgraph.graph import StateGraph, START, ENDgraph_builder = StateGraph(State)
Definimos a ferramenta de busca
from langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultswrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)search_tool = TavilySearchResults(api_wrapper=wrapper, max_results=2)
Criamos uma lista de tools
tools_list = [search_tool]
A seguir, o LLM com as bind_tools e adicionamos ao gráfico
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing# Create the LLMlogin(token=HUGGINGFACE_TOKEN)MODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Modification: tell the LLM which tools it can callllm_with_tools = llm.bind_tools(tools_list)# Define the chatbot functiondef chatbot_function(state: State):message = llm_with_tools.invoke(state["messages"])return {opening_brace}"messages": [message]}# Add the chatbot nodegraph_builder.add_node("chatbot_node", chatbot_function)
<langgraph.graph.state.StateGraph at 0x10d8ce7b0>
Adicionamos a tool ao grafo
from langgraph.prebuilt import ToolNode, tools_conditiontool_node = ToolNode(tools=tools_list)graph_builder.add_node("tools", tool_node)graph_builder.add_conditional_edges("chatbot_node", tools_condition)graph_builder.add_edge("tools", "chatbot_node")
<langgraph.graph.state.StateGraph at 0x10d8ce7b0>
Adicionamos o nódo de START ao grafo
graph_builder.add_edge(START, "chatbot_node")
<langgraph.graph.state.StateGraph at 0x10d8ce7b0>
Criamos um checkpointer MemorySaver.
from langgraph.checkpoint.memory import MemorySavermemory = MemorySaver()
Compilamos o grafo com o checkpointer
graph = graph_builder.compile(checkpointer=memory)
O representamos graficamente
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(f"Error al visualizar el grafo: {e}")
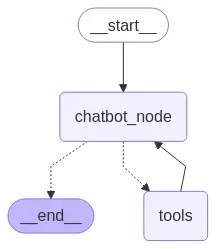
Vamos fazer nosso grafo dar alguns passos. Cada passo será salvo no histórico do estado.
Fazemos a primeira chamada ao modelo
config = {opening_brace}"configurable": {opening_brace}"thread_id": "1"{closing_brace}{closing_brace}user_input = ("I'm learning LangGraph. ""Could you do some research on it for me?")events = graph.stream({opening_brace}"messages": [{"role": "user","content": user_input},],},config,stream_mode="values",)for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================ Human Message =================================I'm learning LangGraph. Could you do some research on it for me?================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangGraph Quickstart - GitHub Pages", "url": "https://langchain-ai.github.io/langgraph/tutorials/introduction/", "content": "[](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-9-1)Assistant: LangGraph is a library designed to help build stateful multi-agent applications using language models. It provides tools for creating workflows and state machines to coordinate multiple AI agents or language model interactions. LangGraph is built on top of LangChain, leveraging its components while adding graph-based coordination capabilities. It's particularly useful for developing more complex, [...] [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-21-6) LangGraph is a library designed for building stateful, multi-actor applications with Large Language Models (LLMs). It's particularly useful for creating agent and multi-agent workflows. [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-21-7) [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-21-8)2. Developer: [...] [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-48-19)LangGraph is likely a framework or library designed specifically for creating AI agents with advanced capabilities. Here are a few points to consider based on this recommendation: [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-48-20)", "score": 0.9328032}, {opening_brace}"title": "langchain-ai/langgraph: Build resilient language agents as graphs.", "url": "https://github.com/langchain-ai/langgraph", "content": "LangGraph — used by Replit, Uber, LinkedIn, GitLab and more — is a low-level orchestration framework for building controllable agents. While langchain provides integrations and composable components to streamline LLM application development, the LangGraph library enables agent orchestration — offering customizable architectures, long-term memory, and human-in-the-loop to reliably handle complex tasks. ``` pip install -U langgraph ```", "score": 0.8884594}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangGraph Quickstart - GitHub Pages", "url": "https://langchain-ai.github.io/langgraph/tutorials/introduction/", "content": "[](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-9-1)Assistant: LangGraph is a library designed to help build stateful multi-agent applications using language models. It provides tools for creating workflows and state machines to coordinate multiple AI agents or language model interactions. LangGraph is built on top of LangChain, leveraging its components while adding graph-based coordination capabilities. It's particularly useful for developing more complex, [...] [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-21-6) LangGraph is a library designed for building stateful, multi-actor applications with Large Language Models (LLMs). It's particularly useful for creating agent and multi-agent workflows. [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-21-7) [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-21-8)2. Developer: [...] [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-48-19)LangGraph is likely a framework or library designed specifically for creating AI agents with advanced capabilities. Here are a few points to consider based on this recommendation: [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-48-20)", "score": 0.9328032}, {opening_brace}"title": "langchain-ai/langgraph: Build resilient language agents as graphs.", "url": "https://github.com/langchain-ai/langgraph", "content": "LangGraph — used by Replit, Uber, LinkedIn, GitLab and more — is a low-level orchestration framework for building controllable agents. While langchain provides integrations and composable components to streamline LLM application development, the LangGraph library enables agent orchestration — offering customizable architectures, long-term memory, and human-in-the-loop to reliably handle complex tasks. ``` pip install -U langgraph ```", "score": 0.8884594}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: LangGraph tutorial and documentation================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangGraph Quickstart - GitHub Pages", "url": "https://langchain-ai.github.io/langgraph/tutorials/introduction/", "content": "[](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-66-36)5. Documentation: The LangGraph documentation has been revamped, which should make it easier for learners like yourself to understand and use the tool. [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-66-37) [...] [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-48-28) [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-48-29)1. Search for the official LangGraph documentation or website to learn more about its features and how to use it. [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-48-30)2. Look for tutorials or guides specifically focused on building AI agents with LangGraph. [...] [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-9-1)Assistant: LangGraph is a library designed to help build stateful multi-agent applications using language models. It provides tools for creating workflows and state machines to coordinate multiple AI agents or language model interactions. LangGraph is built on top of LangChain, leveraging its components while adding graph-based coordination capabilities. It's particularly useful for developing more complex,", "score": 0.8775715}, {opening_brace}"title": "Tutorial 1-Getting Started With LangGraph- Building Stateful Multi AI ...", "url": "https://www.youtube.com/watch?v=gqvFmK7LpDo", "content": "and we will also use Lang Smith so let's go ahead and execute this lsmith I hope everybody knows what exactly is so till then I will also go ahead and show you the documentation page of Lang graph so this is what langra is all about right it has python it has it supports JavaScript and all but uh uh if I just go ahead and show you Lang graph tutorials right so here you can see this is the tutorial right and uh not this sorry uh let's see yes yes here you go right in the Lang graph page it", "score": 0.80405265}]================================== Ai Message ==================================LangGraph is a powerful library designed for building stateful, multi-agent applications using Large Language Models (LLMs). Here are some key points about LangGraph:### Overview- **Purpose**: LangGraph is specifically designed to create complex workflows and state machines to coordinate multiple AI agents or language model interactions. It is particularly useful for developing sophisticated multi-agent systems.- **Framework**: It is built on top of LangChain, leveraging its components and adding graph-based coordination capabilities.- **Features**:- **Customizable Architectures**: Allows you to design and implement custom workflows and state machines.- **Long-Term Memory**: Supports long-term memory for agents, enabling them to maintain context over time.- **Human-in-the-Loop**: Facilitates human interaction in the workflow, making it easier to handle complex tasks that require human oversight.### Getting Started- **Installation**:```bashpip install -U langgraph```- **Documentation**: The LangGraph documentation has been revamped to make it easier for learners to understand and use the tool. You can find the official documentation [here](https://langchain-ai.github.io/langgraph/tutorials/introduction/).### Use Cases- **Multi-Agent Systems**: Ideal for building systems where multiple AI agents need to interact and coordinate their actions.- **Complex Task Handling**: Suitable for tasks that require multiple steps and decision-making processes.- **Custom Workflows**: Enables the creation of custom workflows tailored to specific use cases.### Tutorials and Resources- **Official Documentation**: The official LangGraph documentation is a comprehensive resource for learning about its features and usage.- **Tutorials**: Look for tutorials and guides specifically focused on building AI agents with LangGraph. You can find a tutorial video [here](https://www.youtube.com/watch?v=gqvFmK7LpDo).### Companies Using LangGraph- **Replit, Uber, LinkedIn, GitLab, and more**: These companies are using LangGraph to build resilient and controllable language agents.### Next Steps1. **Review the Documentation**: Start by going through the official LangGraph documentation to get a deeper understanding of its features and capabilities.2. **Follow Tutorials**: Watch tutorials and follow step-by-step guides to build your first multi-agent application.3. **Experiment with Examples**: Try out the examples provided in the documentation to get hands-on experience with LangGraph.If you have any specific questions or need further assistance, feel free to ask!
E agora a segunda chamada
user_input = ("Ya that's helpful. Maybe I'll ""build an autonomous agent with it!")events = graph.stream({opening_brace}"messages": [{"role": "user","content": user_input},],},config,stream_mode="values",)for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================ Human Message =================================Ya that's helpful. Maybe I'll build an autonomous agent with it!================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: LangGraph tutorial build autonomous agent================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangGraph Tutorial: Building LLM Agents with LangChain's ... - Zep", "url": "https://www.getzep.com/ai-agents/langgraph-tutorial", "content": "This article focuses on building agents with LangGraph rather than LangChain. It provides a tutorial for building LangGraph agents, beginning with a discussion of LangGraph and its components. These concepts are reinforced by building a LangGraph agent from scratch and managing conversation memory with LangGraph agents. Finally, we use Zep's long-term memory for egents to create an agent that remembers previous conversations and user facts. â Summary of key LangGraph tutorial concepts [...] human intervention, and the ability to handle complex workflows with cycles and branches. Building a LangGraph agent | Creating a LangGraph agent is the best way to understand the core concepts of nodes, edges, and state. The LangGraph Python libraries are modular and provide the functionality to build a stateful graph by incrementally adding nodes and edges.Incorporating tools enables an agent to perform specific tasks and access", "score": 0.8338803}, {opening_brace}"title": "Build Autonomous AI Agents with ReAct and LangGraph Tools", "url": "https://www.youtube.com/watch?v=ZfjaIshGkmk", "content": "LangGraph Intro - Build Autonomous AI Agents with ReAct and LangGraph Tools GrabDuck! 4110 subscribers 18 likes 535 views 21 Jan 2025 In this video, LangGraph Intro: Build Autonomous AI Agents with ReAct and LangGraph Tools, we dive into creating a powerful agentic system where the LLM decides when to trigger tools and when to finalize results. You’ll see how to build a generic agent architecture using the ReAct principle, applying it to real-world examples like analyzing Tesla stock data. [...] reasoning like what they're doing so uh it's this way you're using tool and this is another thing from longchain core library and here you define the function and then you have to Define name description there are other parameters like for example you can provide very specific description of all the parameters like why you need them which one are those Etc but it's a bit over complicated for this tutorial I'm skipping it and uh interesting thing this one return direct is false and this is uh [...] Whether you’re wondering how to create AI agents, looking for a LangGraph tutorial, or eager to explore the power of LangChain agents, this video is packed with valuable insights to help you get started. Support the channel while you shop on Amazon! Use my affiliate link https://amzn.to/4hssSvT Every purchase via this Amazon link helps keep our content free for you! 🌟 Related Courses & Tutorials", "score": 0.8286204}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: LangGraph tutorial build autonomous agent================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangGraph Tutorial: Building LLM Agents with LangChain's ... - Zep", "url": "https://www.getzep.com/ai-agents/langgraph-tutorial", "content": "This article focuses on building agents with LangGraph rather than LangChain. It provides a tutorial for building LangGraph agents, beginning with a discussion of LangGraph and its components. These concepts are reinforced by building a LangGraph agent from scratch and managing conversation memory with LangGraph agents. Finally, we use Zep's long-term memory for egents to create an agent that remembers previous conversations and user facts. â Summary of key LangGraph tutorial concepts [...] human intervention, and the ability to handle complex workflows with cycles and branches. Building a LangGraph agent | Creating a LangGraph agent is the best way to understand the core concepts of nodes, edges, and state. The LangGraph Python libraries are modular and provide the functionality to build a stateful graph by incrementally adding nodes and edges.Incorporating tools enables an agent to perform specific tasks and access", "score": 0.8338803}, {opening_brace}"title": "Build Autonomous AI Agents with ReAct and LangGraph Tools", "url": "https://www.youtube.com/watch?v=ZfjaIshGkmk", "content": "LangGraph Intro - Build Autonomous AI Agents with ReAct and LangGraph Tools GrabDuck! 4110 subscribers 18 likes 535 views 21 Jan 2025 In this video, LangGraph Intro: Build Autonomous AI Agents with ReAct and LangGraph Tools, we dive into creating a powerful agentic system where the LLM decides when to trigger tools and when to finalize results. You’ll see how to build a generic agent architecture using the ReAct principle, applying it to real-world examples like analyzing Tesla stock data. [...] reasoning like what they're doing so uh it's this way you're using tool and this is another thing from longchain core library and here you define the function and then you have to Define name description there are other parameters like for example you can provide very specific description of all the parameters like why you need them which one are those Etc but it's a bit over complicated for this tutorial I'm skipping it and uh interesting thing this one return direct is false and this is uh [...] Whether you’re wondering how to create AI agents, looking for a LangGraph tutorial, or eager to explore the power of LangChain agents, this video is packed with valuable insights to help you get started. Support the channel while you shop on Amazon! Use my affiliate link https://amzn.to/4hssSvT Every purchase via this Amazon link helps keep our content free for you! 🌟 Related Courses & Tutorials", "score": 0.8286204}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: LangGraph tutorial build autonomous agent================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "LangGraph Tutorial: Building LLM Agents with LangChain's ... - Zep", "url": "https://www.getzep.com/ai-agents/langgraph-tutorial", "content": "This article focuses on building agents with LangGraph rather than LangChain. It provides a tutorial for building LangGraph agents, beginning with a discussion of LangGraph and its components. These concepts are reinforced by building a LangGraph agent from scratch and managing conversation memory with LangGraph agents. Finally, we use Zep's long-term memory for egents to create an agent that remembers previous conversations and user facts. â Summary of key LangGraph tutorial concepts [...] human intervention, and the ability to handle complex workflows with cycles and branches. Building a LangGraph agent | Creating a LangGraph agent is the best way to understand the core concepts of nodes, edges, and state. The LangGraph Python libraries are modular and provide the functionality to build a stateful graph by incrementally adding nodes and edges.Incorporating tools enables an agent to perform specific tasks and access", "score": 0.8338803}, {opening_brace}"title": "Build Autonomous AI Agents with ReAct and LangGraph Tools", "url": "https://www.youtube.com/watch?v=ZfjaIshGkmk", "content": "LangGraph Intro - Build Autonomous AI Agents with ReAct and LangGraph Tools GrabDuck! 4110 subscribers 18 likes 535 views 21 Jan 2025 In this video, LangGraph Intro: Build Autonomous AI Agents with ReAct and LangGraph Tools, we dive into creating a powerful agentic system where the LLM decides when to trigger tools and when to finalize results. You’ll see how to build a generic agent architecture using the ReAct principle, applying it to real-world examples like analyzing Tesla stock data. [...] reasoning like what they're doing so uh it's this way you're using tool and this is another thing from longchain core library and here you define the function and then you have to Define name description there are other parameters like for example you can provide very specific description of all the parameters like why you need them which one are those Etc but it's a bit over complicated for this tutorial I'm skipping it and uh interesting thing this one return direct is false and this is uh [...] Whether you’re wondering how to create AI agents, looking for a LangGraph tutorial, or eager to explore the power of LangChain agents, this video is packed with valuable insights to help you get started. Support the channel while you shop on Amazon! Use my affiliate link https://amzn.to/4hssSvT Every purchase via this Amazon link helps keep our content free for you! 🌟 Related Courses & Tutorials", "score": 0.8286204}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: LangGraph tutorial for building autonomous AI agents================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "How to Build AI Agents with LangGraph: A Step-by-Step Guide", "url": "https://medium.com/@lorevanoudenhove/how-to-build-ai-agents-with-langgraph-a-step-by-step-guide-5d84d9c7e832", "content": "By following these steps, you have successfully created an AI assistant using LangGraph that can calculate solar panel energy savings based on user inputs. This tutorial demonstrates the power of LangGraph in managing complex, multi-step processes and highlights how to leverage advanced AI tools to solve real-world challenges efficiently. Whether you’re developing AI agents for customer support, energy management, or other applications, LangGraph provides the flexibility, scalability, and [...] Step 7: Build the Graph Structure In this step, we construct the graph structure for the AI assistant using LangGraph, which controls how the assistant processes user input, triggers tools, and moves between stages. The graph defines nodes for the core actions (like invoking the assistant and tool) and edges that dictate the flow between these nodes. [...] Now that we have a solid understanding of what LangGraph is and how it enhances AI development, let’s dive into a practical example. In this scenario, we’ll build an AI agent designed to calculate potential energy savings for solar panels based on user input. This agent can be implemented as a lead generation tool on a solar panel seller’s website, where it interacts with potential customers, offering personalized savings estimates. By gathering key data such as monthly electricity costs, this", "score": 0.8576849}, {opening_brace}"title": "Building AI Agents with LangGraph: A Beginner's Guide - YouTube", "url": "https://www.youtube.com/watch?v=assrhPxNdSk", "content": "In this tutorial, we'll break down the fundamentals of building AI agents using LangGraph! Whether you're new to AI development or looking", "score": 0.834852}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: LangGraph tutorial step-by-step================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "How to Build AI Agents with LangGraph: A Step-by-Step Guide", "url": "https://medium.com/@lorevanoudenhove/how-to-build-ai-agents-with-langgraph-a-step-by-step-guide-5d84d9c7e832", "content": "By following these steps, you have successfully created an AI assistant using LangGraph that can calculate solar panel energy savings based on user inputs. This tutorial demonstrates the power of LangGraph in managing complex, multi-step processes and highlights how to leverage advanced AI tools to solve real-world challenges efficiently. Whether you’re developing AI agents for customer support, energy management, or other applications, LangGraph provides the flexibility, scalability, and [...] Step 7: Build the Graph Structure In this step, we construct the graph structure for the AI assistant using LangGraph, which controls how the assistant processes user input, triggers tools, and moves between stages. The graph defines nodes for the core actions (like invoking the assistant and tool) and edges that dictate the flow between these nodes. [...] In this article, we’ll explore how LangGraph transforms AI development and provide a step-by-step guide on how to build your own AI agent using an example that computes energy savings for solar panels. This example will showcase how LangGraph’s unique features can create intelligent, adaptable, and real-world-ready AI systems. What is LangGraph?", "score": 0.86441374}, {opening_brace}"title": "What Is LangGraph and How to Use It? - DataCamp", "url": "https://www.datacamp.com/tutorial/langgraph-tutorial", "content": "Building a Simple LangGraph Application Here’s a step-by-step example of creating a basic chatbot application using LangGraph. Step 1: Define the StateGraph Define a StateGraph object to structure the chatbot as a state machine. The State is a class object defined with a single key messages of type List and uses the add_messages() function to append new messages rather than overwrite them. from typing import Annotated from typing_extensions import TypedDict [...] Getting Started With LangGraph Installation Basic Concepts Building a Simple LangGraph Application Step 1: Define the StateGraph Step 2: Initialize an LLM and add it as a Chatbot node Step 3: Set edges Step 5: Run the chatbot Advanced LangGraph Features Custom node types Edge types Error handling Real-World Applications of LangGraph Chatbots Autonomous agents Multi-Agent systems Workflow automation tools Recommendation systems Personalized learning environments Conclusion", "score": 0.82492816}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: LangGraph tutorial for beginners================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "Introduction to LangGraph: A Beginner's Guide - Medium", "url": "https://medium.com/@cplog/introduction-to-langgraph-a-beginners-guide-14f9be027141", "content": "Conclusion LangGraph is a versatile tool for building complex, stateful applications with LLMs. By understanding its core concepts and working through simple examples, beginners can start to leverage its power for their projects. Remember to pay attention to state management, conditional edges, and ensuring there are no dead-end nodes in your graph. Happy coding! [...] LangGraph is a powerful tool for building stateful, multi-actor applications with Large Language Models (LLMs). It extends the LangChain library, allowing you to coordinate multiple chains (or actors) across multiple steps of computation in a cyclic manner. In this article, we’ll introduce LangGraph, walk you through its basic concepts, and share some insights and common points of confusion for beginners. What is LangGraph?", "score": 0.8793233}, {opening_brace}"title": "LangGraph Tutorial: A Comprehensive Guide for Beginners", "url": "https://blog.futuresmart.ai/langgraph-tutorial-for-beginners", "content": "These examples highlight how LangGraph helps bridge the gap between AI capabilities and the complexities of real-world situations. Conclusion This concludes our LangGraph tutorial! As you've learned, LangGraph enables the creation of AI applications that go beyond simple input-output loops by offering a framework for building stateful, agent-driven systems. You've gained hands-on experience defining graphs, managing state, and incorporating tools. [...] LangGraph, a powerful library within the LangChain ecosystem, provides an elegant solution for building and managing multi-agent LLM applications. By representing workflows as cyclical graphs, LangGraph allows developers to orchestrate the interactions of multiple LLM agents, ensuring smooth communication and efficient execution of complex tasks. [...] LangGraph Tutorial: A Comprehensive Guide for Beginners FutureSmart AI Blog Follow FutureSmart AI Blog Follow LangGraph Tutorial: A Comprehensive Guide for Beginners +1 Rounak Show with 1 co-author ·Oct 1, 2024·12 min read Table of contents Introduction Understanding LangGraph Key Concepts Graph Structures State Management Getting Started with LangGraph Installation Creating a Basic Chatbot in LangGraph", "score": 0.8684817}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: LangGraph tutorial for beginners================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "Introduction to LangGraph: A Beginner's Guide - Medium", "url": "https://medium.com/@cplog/introduction-to-langgraph-a-beginners-guide-14f9be027141", "content": "Conclusion LangGraph is a versatile tool for building complex, stateful applications with LLMs. By understanding its core concepts and working through simple examples, beginners can start to leverage its power for their projects. Remember to pay attention to state management, conditional edges, and ensuring there are no dead-end nodes in your graph. Happy coding! [...] LangGraph is a powerful tool for building stateful, multi-actor applications with Large Language Models (LLMs). It extends the LangChain library, allowing you to coordinate multiple chains (or actors) across multiple steps of computation in a cyclic manner. In this article, we’ll introduce LangGraph, walk you through its basic concepts, and share some insights and common points of confusion for beginners. What is LangGraph?", "score": 0.8793233}, {opening_brace}"title": "LangGraph Tutorial: A Comprehensive Guide for Beginners", "url": "https://blog.futuresmart.ai/langgraph-tutorial-for-beginners", "content": "These examples highlight how LangGraph helps bridge the gap between AI capabilities and the complexities of real-world situations. Conclusion This concludes our LangGraph tutorial! As you've learned, LangGraph enables the creation of AI applications that go beyond simple input-output loops by offering a framework for building stateful, agent-driven systems. You've gained hands-on experience defining graphs, managing state, and incorporating tools. [...] LangGraph, a powerful library within the LangChain ecosystem, provides an elegant solution for building and managing multi-agent LLM applications. By representing workflows as cyclical graphs, LangGraph allows developers to orchestrate the interactions of multiple LLM agents, ensuring smooth communication and efficient execution of complex tasks. [...] LangGraph Tutorial: A Comprehensive Guide for Beginners FutureSmart AI Blog Follow FutureSmart AI Blog Follow LangGraph Tutorial: A Comprehensive Guide for Beginners +1 Rounak Show with 1 co-author ·Oct 1, 2024·12 min read Table of contents Introduction Understanding LangGraph Key Concepts Graph Structures State Management Getting Started with LangGraph Installation Creating a Basic Chatbot in LangGraph", "score": 0.8684817}]================================== Ai Message ==================================Building an autonomous AI agent with LangGraph can be a rewarding and exciting project! Here's a step-by-step guide to get you started, based on the tutorials and resources available:### Step 1: Understand the Basics of LangGraphLangGraph is a library that extends the capabilities of LangChain, focusing on building stateful, multi-actor applications using Large Language Models (LLMs). It allows you to coordinate multiple LLM agents in complex workflows, using a graph-based approach.### Step 2: Install LangGraphFirst, you need to install the LangGraph library. You can do this using pip:```bashpip install -U langgraph```### Step 3: Define the Graph StructureThe core of LangGraph is the graph structure, which defines the nodes (actions or states) and edges (transitions between nodes).#### Example: Solar Panel Energy Savings CalculatorLet's build a simple AI agent that calculates potential energy savings for solar panels based on user input.1. **Define the StateGraph**:- **Nodes**: These represent actions or states in your application.- **Edges**: These define the transitions between nodes.```pythonfrom langgraph import StateGraph, State, Edge# Define the nodesstart_node = State(key="start", action="greet_user")input_node = State(key="input", action="get_user_input")calculate_node = State(key="calculate", action="calculate_savings")result_node = State(key="result", action="show_results")# Define the edgesstart_to_input = Edge(from_node=start_node, to_node=input_node)input_to_calculate = Edge(from_node=input_node, to_node=calculate_node)calculate_to_result = Edge(from_node=calculate_node, to_node=result_node)# Create the graphgraph = StateGraph()graph.add_state(start_node)graph.add_state(input_node)graph.add_state(calculate_node)graph.add_state(result_node)graph.add_edge(start_to_input)graph.add_edge(input_to_calculate)graph.add_edge(calculate_to_result)```### Step 4: Define the ActionsEach node in the graph has an associated action. These actions are Python functions that perform specific tasks.```pythondef greet_user(state, context):return {"message": "Hello! I can help you calculate energy savings for solar panels."}def get_user_input(state, context):return {"message": "Please provide your monthly electricity cost in dollars."}def calculate_savings(state, context):# Example calculation (you can use real data and more complex logic here)monthly_cost = float(input("Enter your monthly electricity cost: "))savings_per_kWh = 0.10 # Example savings rateannual_savings = monthly_cost * 12 * savings_per_kWhreturn {"savings": annual_savings}def show_results(state, context):annual_savings = context.get("savings")return {"message": f"Your annual savings with solar panels could be ${annual_savings:.2f}."}```### Step 5: Run the GraphFinally, you can run the graph to see how the agent processes user input and performs the calculations.```python# Initialize the graph and run itcontext = {opening_brace}{closing_brace}current_node = start_nodewhile current_node:action_result = current_node.action(current_node, context)print(action_result["message"])if "savings" in action_result:context["savings"] = action_result["savings"]current_node = graph.get_next_node(current_node, action_result)```### Step 6: Enhance with Advanced FeaturesOnce you have the basic structure in place, you can enhance your agent with advanced features such as:- **Long-term Memory**: Use external storage (e.g., Zep) to remember user conversations and preferences.- **Conditional Edges**: Define conditions for transitions between nodes to handle different scenarios.- **Human-in-the-Loop**: Allow human intervention for complex tasks or error handling.### Additional Resources- **Official Documentation**: [LangGraph Documentation](https://langchain-ai.github.io/langgraph/tutorials/introduction/)- **Comprehensive Guide**: [LangGraph Tutorial for Beginners](https://blog.futuresmart.ai/langgraph-tutorial-for-beginners)- **Example Project**: [Building AI Agents with LangGraph](https://medium.com/@lorevanoudenhove/how-to-build-ai-agents-with-langgraph-a-step-by-step-guide-5d84d9c7e832)### ConclusionBy following these steps, you can build a robust and flexible AI agent using LangGraph. Start with simple examples and gradually add more complex features to create powerful, stateful, and multi-actor applications. Happy coding!
Agora que fizemos duas chamadas ao modelo, vamos verificar o histórico do estado.
to_replay = Nonefor state in graph.get_state_history(config):print(f"Num Messages: {len(state.values["messages"])}, Next: {state.next}, checkpoint id = {state.config["configurable"]['checkpoint_id']}")print("-" * 80)# Get state when first iteracction us doneif len(state.next) == 0:to_replay = state
Num Messages: 24, Next: (), checkpoint id = 1f027f2f-e5b4-6c84-8018-9fcb33b5f397--------------------------------------------------------------------------------Num Messages: 23, Next: ('chatbot_node',), checkpoint id = 1f027f2f-e414-6b0e-8017-3ad465b70767--------------------------------------------------------------------------------Num Messages: 22, Next: ('tools',), checkpoint id = 1f027f2f-d382-6692-8016-fcfaf9c9a9f7--------------------------------------------------------------------------------Num Messages: 21, Next: ('chatbot_node',), checkpoint id = 1f027f2f-d1cf-6930-8015-f64aa0e6f750--------------------------------------------------------------------------------Num Messages: 20, Next: ('tools',), checkpoint id = 1f027f2f-bca9-6164-8014-86452cb10d83--------------------------------------------------------------------------------Num Messages: 19, Next: ('chatbot_node',), checkpoint id = 1f027f2f-bac1-6d24-8013-b539f3e4cedb--------------------------------------------------------------------------------Num Messages: 18, Next: ('tools',), checkpoint id = 1f027f2f-aa0e-69fa-8012-4ca2d9109f4e--------------------------------------------------------------------------------Num Messages: 17, Next: ('chatbot_node',), checkpoint id = 1f027f2f-a861-62c4-8011-5707badab130--------------------------------------------------------------------------------Num Messages: 16, Next: ('tools',), checkpoint id = 1f027f2f-93cf-6112-8010-ee536e76cdf7--------------------------------------------------------------------------------Num Messages: 15, Next: ('chatbot_node',), checkpoint id = 1f027f2f-91f5-63fa-800f-6ff45b0ebf86--------------------------------------------------------------------------------Num Messages: 14, Next: ('tools',), checkpoint id = 1f027f2f-7e07-6190-800e-e0269b0cb0f4--------------------------------------------------------------------------------Num Messages: 13, Next: ('chatbot_node',), checkpoint id = 1f027f2f-7bf9-62a4-800d-bd2bf25381ac--------------------------------------------------------------------------------Num Messages: 12, Next: ('tools',), checkpoint id = 1f027f2f-639f-6172-800c-e54c8b1b1f4a--------------------------------------------------------------------------------Num Messages: 11, Next: ('chatbot_node',), checkpoint id = 1f027f2f-621b-6972-800b-184a824ce9cb--------------------------------------------------------------------------------Num Messages: 10, Next: ('tools',), checkpoint id = 1f027f2f-56df-66a8-800a-d56ee9317382--------------------------------------------------------------------------------Num Messages: 9, Next: ('chatbot_node',), checkpoint id = 1f027f2f-5546-60d0-8009-41ee7c932b49--------------------------------------------------------------------------------Num Messages: 8, Next: ('__start__',), checkpoint id = 1f027f2f-5542-6ff2-8008-e2f4e8278c23--------------------------------------------------------------------------------Num Messages: 8, Next: (), checkpoint id = 1f027f2c-8873-61d6-8007-8a1c60438002--------------------------------------------------------------------------------Num Messages: 7, Next: ('chatbot_node',), checkpoint id = 1f027f2c-8504-663a-8006-517227b123b6--------------------------------------------------------------------------------Num Messages: 6, Next: ('tools',), checkpoint id = 1f027f2c-75dc-6248-8005-e198dd299848--------------------------------------------------------------------------------Num Messages: 5, Next: ('chatbot_node',), checkpoint id = 1f027f2c-7448-69d6-8004-e3c6d5c4c5a4--------------------------------------------------------------------------------Num Messages: 4, Next: ('tools',), checkpoint id = 1f027f2c-627b-6f6e-8003-22208fac7c89--------------------------------------------------------------------------------Num Messages: 3, Next: ('chatbot_node',), checkpoint id = 1f027f2c-6122-6190-8002-b745c42a724e--------------------------------------------------------------------------------Num Messages: 2, Next: ('tools',), checkpoint id = 1f027f2c-4c4c-6720-8001-8a1c73b894c1--------------------------------------------------------------------------------Num Messages: 1, Next: ('chatbot_node',), checkpoint id = 1f027f2c-4a91-6278-8000-56b65f6d77cd--------------------------------------------------------------------------------Num Messages: 0, Next: ('__start__',), checkpoint id = 1f027f2c-4a8d-6a1a-bfff-2f7cbde97290--------------------------------------------------------------------------------
Salvamos o estado do grafo em to_replay quando recebemos a primeira resposta, logo antes de introduzir a segunda mensagem. Podemos voltar a um estado passado e continuar o fluxo a partir daí.
A configuração do checkpoint contém o checkpoint_id, que é um timestamp do fluxo. Podemos vê-lo para verificar que estamos no estado desejado.
print(to_replay.config)
{'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f027f2c-8873-61d6-8007-8a1c60438002'}}
Se olharmos para a lista de estados anterior, veremos que o ID coincide com o momento de introduzir a segunda mensagem
Dando este checkpoint_id a LangGraph carrega o estado naquele momento do fluxo. Então criamos uma nova mensagem e a passamos para o grafo.
user_input = ("Thanks")# The `checkpoint_id` in the `to_replay.config` corresponds to a state we've persisted to our checkpointer.events = graph.stream({"messages": [{"role": "user","content": user_input},],},to_replay.config,stream_mode="values",)for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================ Human Message =================================Thanks================================== Ai Message ==================================You're welcome! If you have any more questions about LangGraph or any other topics, feel free to ask. Happy learning! 🚀
for state in graph.get_state_history(config):print(f"Num Messages: {len(state.values["messages"])}, Next: {state.next}, checkpoint id = {state.config["configurable"]['checkpoint_id']}")print("-" * 80)
Num Messages: 10, Next: (), checkpoint id = 1f027f43-71ae-67e0-800a-d84a557441fc--------------------------------------------------------------------------------Num Messages: 9, Next: ('chatbot_node',), checkpoint id = 1f027f43-5b1f-6ad8-8009-34f409789bc4--------------------------------------------------------------------------------Num Messages: 8, Next: ('__start__',), checkpoint id = 1f027f43-5b1b-68a2-8008-fbbcbd1c175e--------------------------------------------------------------------------------Num Messages: 24, Next: (), checkpoint id = 1f027f2f-e5b4-6c84-8018-9fcb33b5f397--------------------------------------------------------------------------------Num Messages: 23, Next: ('chatbot_node',), checkpoint id = 1f027f2f-e414-6b0e-8017-3ad465b70767--------------------------------------------------------------------------------Num Messages: 22, Next: ('tools',), checkpoint id = 1f027f2f-d382-6692-8016-fcfaf9c9a9f7--------------------------------------------------------------------------------Num Messages: 21, Next: ('chatbot_node',), checkpoint id = 1f027f2f-d1cf-6930-8015-f64aa0e6f750--------------------------------------------------------------------------------Num Messages: 20, Next: ('tools',), checkpoint id = 1f027f2f-bca9-6164-8014-86452cb10d83--------------------------------------------------------------------------------Num Messages: 19, Next: ('chatbot_node',), checkpoint id = 1f027f2f-bac1-6d24-8013-b539f3e4cedb--------------------------------------------------------------------------------Num Messages: 18, Next: ('tools',), checkpoint id = 1f027f2f-aa0e-69fa-8012-4ca2d9109f4e--------------------------------------------------------------------------------Num Messages: 17, Next: ('chatbot_node',), checkpoint id = 1f027f2f-a861-62c4-8011-5707badab130--------------------------------------------------------------------------------Num Messages: 16, Next: ('tools',), checkpoint id = 1f027f2f-93cf-6112-8010-ee536e76cdf7--------------------------------------------------------------------------------Num Messages: 15, Next: ('chatbot_node',), checkpoint id = 1f027f2f-91f5-63fa-800f-6ff45b0ebf86--------------------------------------------------------------------------------Num Messages: 14, Next: ('tools',), checkpoint id = 1f027f2f-7e07-6190-800e-e0269b0cb0f4--------------------------------------------------------------------------------Num Messages: 13, Next: ('chatbot_node',), checkpoint id = 1f027f2f-7bf9-62a4-800d-bd2bf25381ac--------------------------------------------------------------------------------Num Messages: 12, Next: ('tools',), checkpoint id = 1f027f2f-639f-6172-800c-e54c8b1b1f4a--------------------------------------------------------------------------------Num Messages: 11, Next: ('chatbot_node',), checkpoint id = 1f027f2f-621b-6972-800b-184a824ce9cb--------------------------------------------------------------------------------Num Messages: 10, Next: ('tools',), checkpoint id = 1f027f2f-56df-66a8-800a-d56ee9317382--------------------------------------------------------------------------------Num Messages: 9, Next: ('chatbot_node',), checkpoint id = 1f027f2f-5546-60d0-8009-41ee7c932b49--------------------------------------------------------------------------------Num Messages: 8, Next: ('__start__',), checkpoint id = 1f027f2f-5542-6ff2-8008-e2f4e8278c23--------------------------------------------------------------------------------Num Messages: 8, Next: (), checkpoint id = 1f027f2c-8873-61d6-8007-8a1c60438002--------------------------------------------------------------------------------Num Messages: 7, Next: ('chatbot_node',), checkpoint id = 1f027f2c-8504-663a-8006-517227b123b6--------------------------------------------------------------------------------Num Messages: 6, Next: ('tools',), checkpoint id = 1f027f2c-75dc-6248-8005-e198dd299848--------------------------------------------------------------------------------Num Messages: 5, Next: ('chatbot_node',), checkpoint id = 1f027f2c-7448-69d6-8004-e3c6d5c4c5a4--------------------------------------------------------------------------------Num Messages: 4, Next: ('tools',), checkpoint id = 1f027f2c-627b-6f6e-8003-22208fac7c89--------------------------------------------------------------------------------Num Messages: 3, Next: ('chatbot_node',), checkpoint id = 1f027f2c-6122-6190-8002-b745c42a724e--------------------------------------------------------------------------------Num Messages: 2, Next: ('tools',), checkpoint id = 1f027f2c-4c4c-6720-8001-8a1c73b894c1--------------------------------------------------------------------------------Num Messages: 1, Next: ('chatbot_node',), checkpoint id = 1f027f2c-4a91-6278-8000-56b65f6d77cd--------------------------------------------------------------------------------Num Messages: 0, Next: ('__start__',), checkpoint id = 1f027f2c-4a8d-6a1a-bfff-2f7cbde97290--------------------------------------------------------------------------------
Podemos ver no histórico que o grafo executou tudo o que fizemos primeiro, mas depois sobrescreveu o histórico e voltou a executar a partir de um ponto anterior.
Reescrevo todo o grafo junto
import osimport dotenvfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph.message import add_messagesfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.prebuilt import ToolNode, tools_conditionfrom langgraph.checkpoint.memory import MemorySaverfrom langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultsfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingfrom IPython.display import Image, displayclass State(TypedDict):messages: Annotated[list, add_messages]dotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")# Toolswrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)search_tool = TavilySearchResults(api_wrapper=wrapper, max_results=2)tools_list = [search_tool]tool_node = ToolNode(tools=tools_list)# Create the LLMlogin(token=HUGGINGFACE_TOKEN)MODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Modification: tell the LLM which tools it can callllm_with_tools = llm.bind_tools(tools_list)# Define the chatbot functiondef chatbot_function(state: State):message = llm_with_tools.invoke(state["messages"])return {opening_brace}"messages": [message]}# Create the graphgraph_builder = StateGraph(State)# Add nodesgraph_builder.add_node("chatbot_node", chatbot_function)graph_builder.add_node("tools", tool_node)graph_builder.add_edge("tools", "chatbot_node")# Add edgesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_conditional_edges("chatbot_node", tools_condition)# Add checkpointermemory = MemorySaver()# Compilegraph = graph_builder.compile(checkpointer=memory)# Visualizetry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")
Error al visualizar el grafo: Failed to reach https://mermaid.ink/ API while trying to render your graph after 1 retries. To resolve this issue:1. Check your internet connection and try again2. Try with higher retry settings: `draw_mermaid_png(..., max_retries=5, retry_delay=2.0)`3. Use the Pyppeteer rendering method which will render your graph locally in a browser: `draw_mermaid_png(..., draw_method=MermaidDrawMethod.PYPPETEER)`
Fazemos a primeira chamada ao modelo
config = {opening_brace}"configurable": {opening_brace}"thread_id": "1"{closing_brace}{closing_brace}user_input = ("I'm learning LangGraph. ""Could you do some research on it for me?")events = graph.stream({opening_brace}"messages": [{"role": "user","content": user_input},],},config,stream_mode="values",)for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================ Human Message =================================I'm learning LangGraph. Could you do some research on it for me?================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "What is LangGraph? - IBM", "url": "https://www.ibm.com/think/topics/langgraph", "content": "LangGraph, created by LangChain, is an open source AI agent framework designed to build, deploy and manage complex generative AI agent workflows. It provides a set of tools and libraries that enable users to create, run and optimize large language models (LLMs) in a scalable and efficient manner. At its core, LangGraph uses the power of graph-based architectures to model and manage the intricate relationships between various components of an AI agent workflow. [...] Agent systems: LangGraph provides a framework for building agent-based systems, which can be used in applications such as robotics, autonomous vehicles or video games. LLM applications: By using LangGraph’s capabilities, developers can build more sophisticated AI models that learn and improve over time. Norwegian Cruise Line uses LangGraph to compile, construct and refine guest-facing AI solutions. This capability allows for improved and personalized guest experiences. [...] By using a graph-based architecture, LangGraph enables users to scale artificial intelligence workflows without slowing down or sacrificing efficiency. LangGraph uses enhanced decision-making by modeling complex relationships between nodes, which means it uses AI agents to analyze their past actions and feedback. In the world of LLMs, this process is referred to as reflection.", "score": 0.9353998}, {opening_brace}"title": "LangGraph Quickstart - GitHub Pages", "url": "https://langchain-ai.github.io/langgraph/tutorials/introduction/", "content": "[](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-9-1)Assistant: LangGraph is a library designed to help build stateful multi-agent applications using language models. It provides tools for creating workflows and state machines to coordinate multiple AI agents or language model interactions. LangGraph is built on top of LangChain, leveraging its components while adding graph-based coordination capabilities. It's particularly useful for developing more complex, [...] [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-21-6) LangGraph is a library designed for building stateful, multi-actor applications with Large Language Models (LLMs). It's particularly useful for creating agent and multi-agent workflows. [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-21-7) [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-21-8)2. Developer: [...] [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-48-19)LangGraph is likely a framework or library designed specifically for creating AI agents with advanced capabilities. Here are a few points to consider based on this recommendation: [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-48-20)", "score": 0.9328032}]================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: LangGraph================================= Tool Message =================================Name: tavily_search_results_json[{opening_brace}"title": "What is LangGraph? - IBM", "url": "https://www.ibm.com/think/topics/langgraph", "content": "LangGraph, created by LangChain, is an open source AI agent framework designed to build, deploy and manage complex generative AI agent workflows. It provides a set of tools and libraries that enable users to create, run and optimize large language models (LLMs) in a scalable and efficient manner. At its core, LangGraph uses the power of graph-based architectures to model and manage the intricate relationships between various components of an AI agent workflow. [...] Agent systems: LangGraph provides a framework for building agent-based systems, which can be used in applications such as robotics, autonomous vehicles or video games. LLM applications: By using LangGraph’s capabilities, developers can build more sophisticated AI models that learn and improve over time. Norwegian Cruise Line uses LangGraph to compile, construct and refine guest-facing AI solutions. This capability allows for improved and personalized guest experiences. [...] By using a graph-based architecture, LangGraph enables users to scale artificial intelligence workflows without slowing down or sacrificing efficiency. LangGraph uses enhanced decision-making by modeling complex relationships between nodes, which means it uses AI agents to analyze their past actions and feedback. In the world of LLMs, this process is referred to as reflection.", "score": 0.9353998}, {opening_brace}"title": "LangGraph Quickstart - GitHub Pages", "url": "https://langchain-ai.github.io/langgraph/tutorials/introduction/", "content": "[](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-9-1)Assistant: LangGraph is a library designed to help build stateful multi-agent applications using language models. It provides tools for creating workflows and state machines to coordinate multiple AI agents or language model interactions. LangGraph is built on top of LangChain, leveraging its components while adding graph-based coordination capabilities. It's particularly useful for developing more complex, [...] [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-21-6) LangGraph is a library designed for building stateful, multi-actor applications with Large Language Models (LLMs). It's particularly useful for creating agent and multi-agent workflows. [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-21-7) [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-21-8)2. Developer: [...] [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-48-19)LangGraph is likely a framework or library designed specifically for creating AI agents with advanced capabilities. Here are a few points to consider based on this recommendation: [](https://langchain-ai.github.io/langgraph/tutorials/introduction/#__codelineno-48-20)", "score": 0.9328032}]================================== Ai Message ==================================LangGraph is an open-source AI agent framework developed by LangChain, designed to build, deploy, and manage complex generative AI agent workflows. Here are some key points about LangGraph:### Overview- **Purpose**: LangGraph is aimed at creating, running, and optimizing large language models (LLMs) in a scalable and efficient manner.- **Graph-Based Architecture**: It uses graph-based architectures to model and manage the intricate relationships between various components of an AI agent workflow.### Features- **Agent Systems**: LangGraph provides a framework for building agent-based systems, which can be used in applications such as robotics, autonomous vehicles, or video games.- **LLM Applications**: Developers can build more sophisticated AI models that learn and improve over time. For example, Norwegian Cruise Line uses LangGraph to compile, construct, and refine guest-facing AI solutions, enhancing personalized guest experiences.- **Scalability**: By using a graph-based architecture, LangGraph enables users to scale artificial intelligence workflows without sacrificing efficiency.- **Enhanced Decision-Making**: LangGraph uses AI agents to analyze their past actions and feedback, a process referred to as "reflection" in the context of LLMs.### Developer Resources- **Quickstart Guide**: The LangGraph Quickstart guide on GitHub provides a detailed introduction to building stateful multi-agent applications using language models. It covers tools for creating workflows and state machines to coordinate multiple AI agents or language model interactions.- **Built on LangChain**: LangGraph is built on top of LangChain, leveraging its components while adding graph-based coordination capabilities. This makes it particularly useful for developing more complex, stateful, multi-actor applications with LLMs.### Further Reading- **What is LangGraph? - IBM**: [Link](https://www.ibm.com/think/topics/langgraph)- **LangGraph Quickstart - GitHub Pages**: [Link](https://langchain-ai.github.io/langgraph/tutorials/introduction/)These resources should provide a solid foundation for understanding and getting started with LangGraph. If you have any specific questions or need further details, feel free to ask!
E agora a segunda chamada
user_input = ("Ya that's helpful. Maybe I'll ""build an autonomous agent with it!")events = graph.stream({opening_brace}"messages": [{"role": "user","content": user_input},],},config,stream_mode="values",)for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================ Human Message =================================Ya that's helpful. Maybe I'll build an autonomous agent with it!================================== Ai Message ==================================That sounds like an exciting project! Building an autonomous agent using LangGraph can be a rewarding experience. Here are some steps and tips to help you get started:### 1. **Understand the Basics of LangGraph**- **Read the Documentation**: Start with the official LangGraph documentation and quickstart guide. This will give you a solid understanding of the framework's capabilities and how to use its tools.- **Quickstart Guide**: [LangGraph Quickstart - GitHub Pages](https://langchain-ai.github.io/langgraph/tutorials/introduction/)### 2. **Set Up Your Development Environment**- **Install LangChain and LangGraph**: Ensure you have the necessary dependencies installed. LangGraph is built on top of LangChain, so you'll need to set up both.```bashpip install langchain langgraph```### 3. **Define Your Agent's Objectives**- **Identify the Use Case**: What specific tasks do you want your autonomous agent to perform? This could be anything from navigating a virtual environment, responding to user queries, or managing a robotic system.- **Define the State and Actions**: Determine the states your agent can be in and the actions it can take. This will help you design the state machine and workflows.### 4. **Design the Graph-Based Workflow**- **Create Nodes and Edges**: In LangGraph, you'll define nodes (agents or components) and edges (interactions or transitions). Each node can represent a different part of your agent's functionality.- **Define State Transitions**: Use the graph-based architecture to define how the agent transitions between different states based on actions and events.### 5. **Implement the Agent**- **Write the Code**: Start coding your agent using the LangGraph library. You can use the provided tools to create and manage the agent's workflows.- **Example**: Here’s a simple example to get you started:```pythonfrom langgraph import AgentGraph, Node, Edge# Define nodesnode1 = Node("Sensor", process=sensor_process)node2 = Node("Decision", process=decision_process)node3 = Node("Actuator", process=actuator_process)# Define edgesedge1 = Edge(node1, node2)edge2 = Edge(node2, node3)# Create the agent graphagent_graph = AgentGraph()agent_graph.add_node(node1)agent_graph.add_node(node2)agent_graph.add_node(node3)agent_graph.add_edge(edge1)agent_graph.add_edge(edge2)# Run the graphagent_graph.run()```### 6. **Test and Iterate**- **Run Simulations**: Test your agent in a simulated environment to see how it performs. Use this to identify and fix any issues.- **Refine the Model**: Based on the test results, refine your agent's model and workflows. You can add more nodes, edges, or improve the decision-making processes.### 7. **Deploy and Monitor**- **Deploy the Agent**: Once you are satisfied with the performance, you can deploy your agent in the real world or a production environment.- **Monitor and Maintain**: Continuously monitor the agent's performance and make adjustments as needed. Use feedback loops to improve the agent over time.### 8. **Community and Support**- **Join the Community**: Engage with the LangChain and LangGraph community. You can find support, share ideas, and get feedback from other developers.- **GitHub**: [LangGraph GitHub](https://github.com/langchain-ai/langgraph)- **Forums and Discussion Boards**: Check out forums and discussion boards related to LangGraph and LangChain.### Additional Resources- **Tutorials and Examples**: Look for tutorials and example projects to get more hands-on experience.- **Research Papers and Articles**: Read research papers and articles to deepen your understanding of AI agent design and graph-based architectures.Good luck with your project! If you have any specific questions or need further guidance, feel free to ask.
Vemos o histórico do estado
to_replay = Nonefor state in graph.get_state_history(config):print(f"Num Messages: {len(state.values["messages"])}, Next: {state.next}, checkpoint id = {state.config["configurable"]['checkpoint_id']}")print("-" * 80)# Get state when first iteracction us doneif len(state.next) == 0:to_replay = state
Num Messages: 8, Next: (), checkpoint id = 1f03263e-a96c-6446-8008-d2c11df0b6cb--------------------------------------------------------------------------------Num Messages: 7, Next: ('chatbot_node',), checkpoint id = 1f03263d-7a35-6660-8007-a37d4b584c88--------------------------------------------------------------------------------Num Messages: 6, Next: ('__start__',), checkpoint id = 1f03263d-7a32-624e-8006-6509bbf32ebe--------------------------------------------------------------------------------Num Messages: 6, Next: (), checkpoint id = 1f03263d-7a1a-6f36-8005-f10b5d83f22c--------------------------------------------------------------------------------Num Messages: 5, Next: ('chatbot_node',), checkpoint id = 1f03263c-c53f-6666-8004-c6d35868dd73--------------------------------------------------------------------------------Num Messages: 4, Next: ('tools',), checkpoint id = 1f03263c-b14b-68f8-8003-28558fa38dbc--------------------------------------------------------------------------------Num Messages: 3, Next: ('chatbot_node',), checkpoint id = 1f03263c-a66b-6276-8002-2dc89fca4d99--------------------------------------------------------------------------------Num Messages: 2, Next: ('tools',), checkpoint id = 1f03263c-8c7c-68ec-8001-fb8a9aa300b0--------------------------------------------------------------------------------Num Messages: 1, Next: ('chatbot_node',), checkpoint id = 1f03263c-6d06-68d2-8000-ced2e7b8538f--------------------------------------------------------------------------------Num Messages: 0, Next: ('__start__',), checkpoint id = 1f03263c-6cdb-63e4-bfff-c644b57cee28--------------------------------------------------------------------------------
print(to_replay.config)
{'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f03263d-7a1a-6f36-8005-f10b5d83f22c'}}
Dando este checkpoint_id a LangGraph carrega o estado naquele momento do fluxo. Assim, criamos uma nova mensagem e a passamos para o grafo.
user_input = ("Thanks")# The `checkpoint_id` in the `to_replay.config` corresponds to a state we've persisted to our checkpointer.events = graph.stream({"messages": [{"role": "user","content": user_input},],},to_replay.config,stream_mode="values",)for event in events:if "messages" in event:event["messages"][-1].pretty_print()
================================ Human Message =================================Thanks================================== Ai Message ==================================You're welcome! If you have any more questions about LangGraph or any other topic, feel free to reach out. Happy learning! 😊
for state in graph.get_state_history(config):print(f"Num Messages: {len(state.values["messages"])}, Next: {state.next}, checkpoint id = {state.config["configurable"]['checkpoint_id']}")print("-" * 80)
Num Messages: 8, Next: (), checkpoint id = 1f03263f-fcb9-63a0-8008-e8c4a3fb44f9--------------------------------------------------------------------------------Num Messages: 7, Next: ('chatbot_node',), checkpoint id = 1f03263f-eb3b-663c-8007-72da4d16bf64--------------------------------------------------------------------------------Num Messages: 6, Next: ('__start__',), checkpoint id = 1f03263f-eb36-6ac4-8006-a2333805d5d6--------------------------------------------------------------------------------Num Messages: 8, Next: (), checkpoint id = 1f03263e-a96c-6446-8008-d2c11df0b6cb--------------------------------------------------------------------------------Num Messages: 7, Next: ('chatbot_node',), checkpoint id = 1f03263d-7a35-6660-8007-a37d4b584c88--------------------------------------------------------------------------------Num Messages: 6, Next: ('__start__',), checkpoint id = 1f03263d-7a32-624e-8006-6509bbf32ebe--------------------------------------------------------------------------------Num Messages: 6, Next: (), checkpoint id = 1f03263d-7a1a-6f36-8005-f10b5d83f22c--------------------------------------------------------------------------------Num Messages: 5, Next: ('chatbot_node',), checkpoint id = 1f03263c-c53f-6666-8004-c6d35868dd73--------------------------------------------------------------------------------Num Messages: 4, Next: ('tools',), checkpoint id = 1f03263c-b14b-68f8-8003-28558fa38dbc--------------------------------------------------------------------------------Num Messages: 3, Next: ('chatbot_node',), checkpoint id = 1f03263c-a66b-6276-8002-2dc89fca4d99--------------------------------------------------------------------------------Num Messages: 2, Next: ('tools',), checkpoint id = 1f03263c-8c7c-68ec-8001-fb8a9aa300b0--------------------------------------------------------------------------------Num Messages: 1, Next: ('chatbot_node',), checkpoint id = 1f03263c-6d06-68d2-8000-ced2e7b8538f--------------------------------------------------------------------------------Num Messages: 0, Next: ('__start__',), checkpoint id = 1f03263c-6cdb-63e4-bfff-c644b57cee28--------------------------------------------------------------------------------