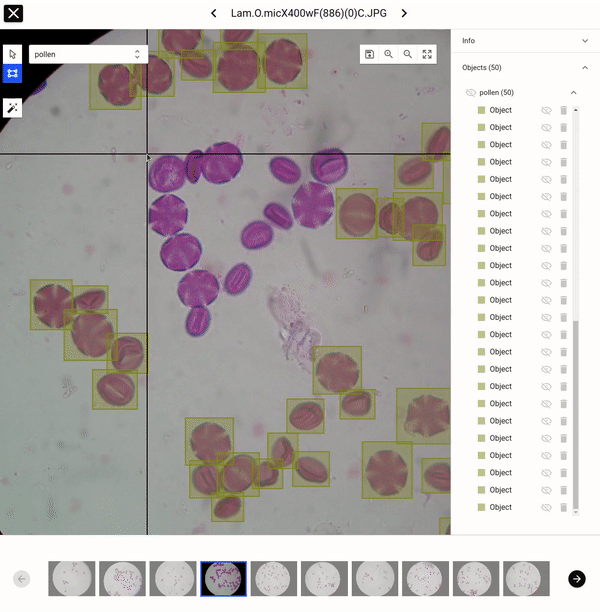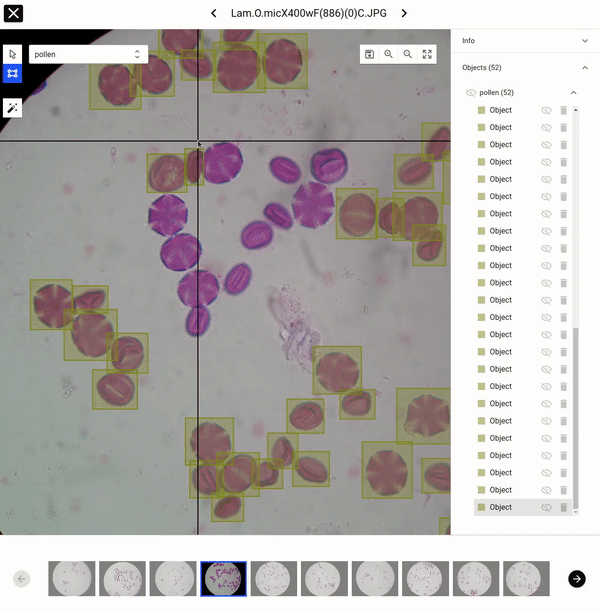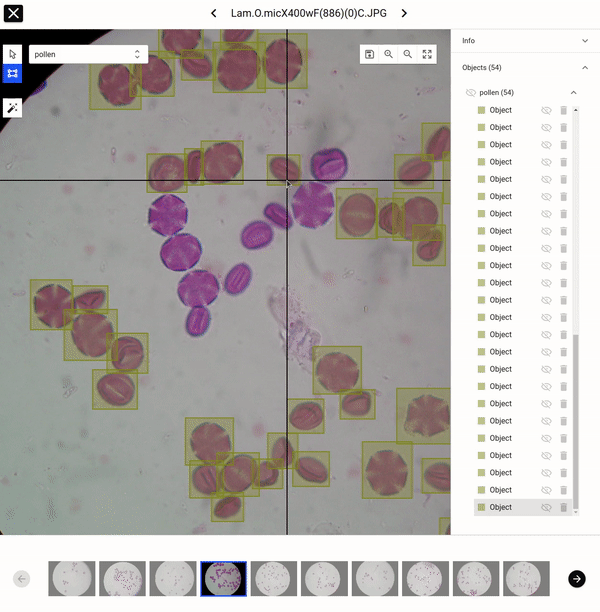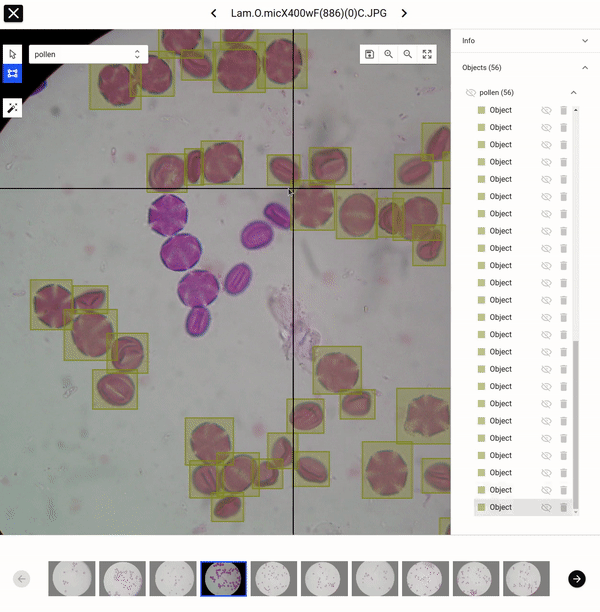
Naviground é um sistema de navegação implementável em veículos terrestres tripulados e não tripulados. Permite navegar em ambientes estruturados e não estruturados. Participei no desenvolvimento do sistema de percepção, especialmente na detecção do ambiente por meio de câmeras.
Sistema de visão
Embora o sistema de navegação contasse com sensores LIDAR e RADAR, por vários motivos, foi desejado um sistema de percepção formado exclusivamente por câmeras.
Embora o preço dos LIDAR e RADAR tenha diminuído muito nos últimos anos, continua sendo mais caro que o das câmeras.
Os sensores LIDAR e RADAR são sensores ativos (emitem uma onda eletromagnética e medem a reflexão), por isso, em um ambiente de guerra, fazem com que o veículo possa ser detectado.
Como é um veículo autônomo, o processamento não pode ser feito em uma máquina muito poderosa, por isso, se pode eliminar o processamento da quantidade de dados que geram os LIDAR e RADAR, melhor.
Para poder realizar a detecção do ambiente, utilizamos três tipos de redes neurais:
Redes de segmentação semântica
Classificam a que classe pertence cada pixel da imagem, obtendo uma máscara de segmentação.
Redes de classificação de objetos
Mediante uma YOLO, se podem detectar objetos na imagem
Profundidade
Mediante uma rede neural, se pode estimar a profundidade de cada pixel da imagem, com isso, se pode obter a distância de cada objeto.
Treinamento
Nosso problema era que como era um veículo para ambientes estruturados e não estruturados, não nos valiam as redes pré-treinadas, por isso, tivemos que fazer treinamentos das redes de segmentação e de classificação de objetos.
Dataset
Como tínhamos horas de vídeos gravados durante testes em ambientes como este, criamos um dataset
Criamos um algoritmo que, mediante um classificador não supervisionado, criou vários clusters de imagens, onde as imagens de cada cluster eram similares entre si. Desta forma, ficávamos com poucas imagens de cada cluster, para ter um dataset com imagens heterogêneas.
Etiquetador
Etiquetar objetos para a YOLO, embora seja pesado, é um processo mais ou menos rápido e fácil
Embora seja pesado, etiquetar as imagens para a segmentação semântica, onde tem que etiquetar cada pixel, é um processo lento e tedioso. Como não nos convencia nenhuma ferramenta de etiquetado para segmentação, construímos a nossa própria ferramenta de etiquetado. Foi tão boa que foi reutilizada em outros projetos e até foi falado de comercializá-la.
Geração de imagens de treinamento
Um dos problemas que tínhamos é que todas as imagens de treinamento eram de dia, com sol, sem chuva, etc. Por isso, para tornar as redes mais robustas, precisávamos de mais imagens. Mas isso supõe que alguém tenha que sair à noite, esperar que chova para ter imagens com chuva, esperar que neve, que é mais complicado, etc.
Naquele momento já havia muitas redes de geração de imagens bastante boas, por isso, podíamos gerar imagens com novas condições ambientais, mas o problema era que havia que etiquetá-las, e para a segmentação, isso exigia muito tempo.
Assim, construí um pipeline que, mediante IA generativa, modificava as condições ambientais das imagens que já tínhamos etiquetadas, tendo imagens em diferentes condições ambientais, mas sem perder tempo etiquetando-as.
Otimização com TensorRT
Como isso tinha que funcionar em um veículo, não se podia utilizar um computador com uma GPU potente. Por isso, se utilizava um dispositivo embebido, uma Jetson Orin. Por isso, era importante poder otimizar as redes neurais para que fizessem a inferência o mais rápido possível.
Me encarregue de otimizá-las com TensorRT, fazendo com que em alguns casos executassem até 40% mais rápido.
Os espaços do Hugging Face nos permitem executar modelos com demos muito simples, mas e se a demo quebrar? Ou se o usuário a deletar? Por isso, criei contêineres docker com alguns espaços interessantes, para poder usá-los localmente, aconteça o que acontecer. Na verdade, se você clicar em qualquer botão de visualização de projeto, ele pode levá-lo a um espaço que não funciona.