Provedores de Inferência da Hugging Face
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
Está claro que o maior hub de modelos de inteligência artificial é a Hugging Face. E agora estão oferecendo a possibilidade de fazer inferência de alguns de seus modelos em provedores de GPUs serverless
Um desses modelos é Wan-AI/Wan2.1-T2V-14B, que no momento de escrever este post, é o melhor modelo de geração de vídeo open source, como se pode ver na Artificial Analysis Video Generation Arena Leaderboard 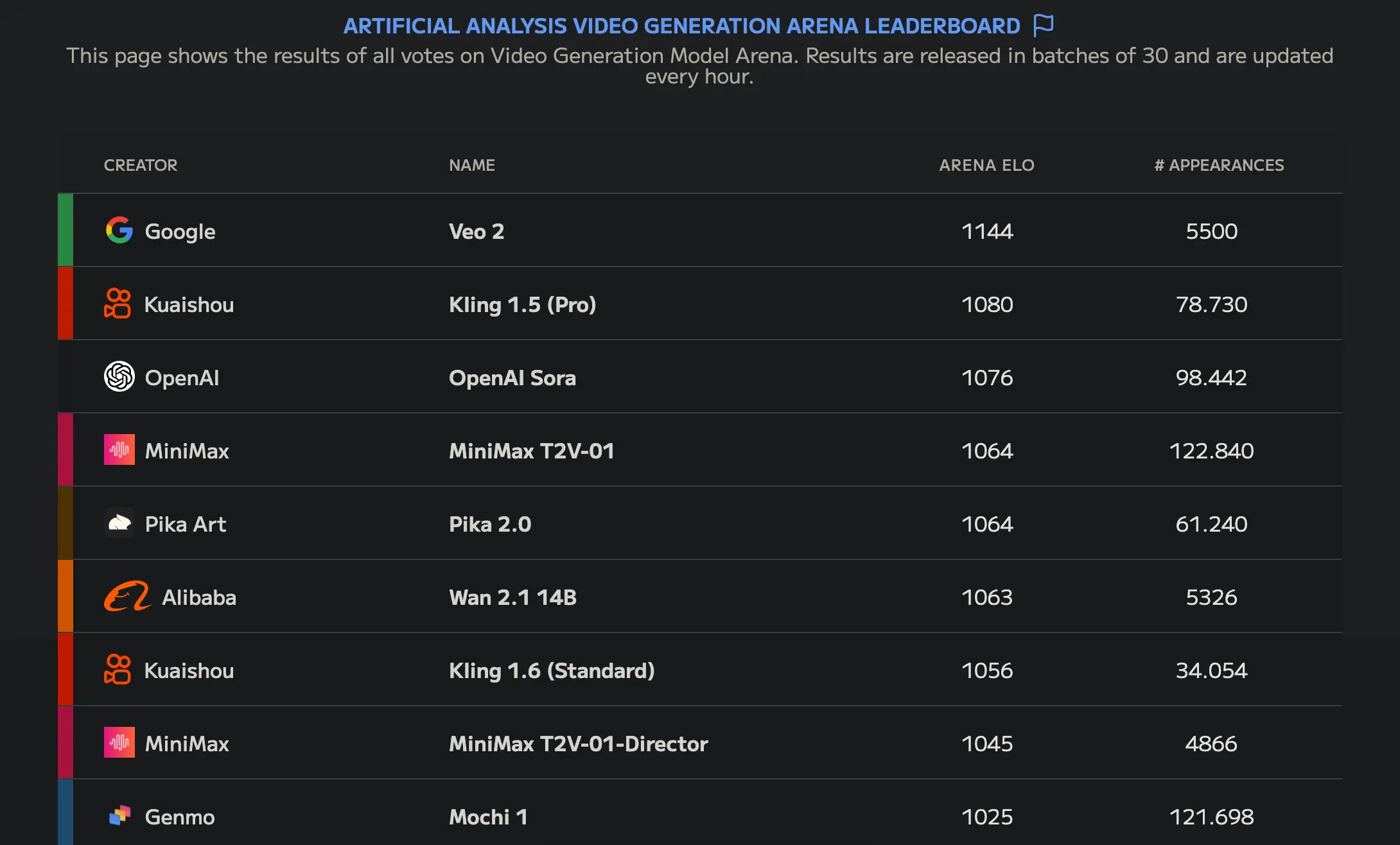
Se nós olharmos para seu modelcard, podemos ver à direita um botão que diz Replicate.
Provedores de inferência
Se formos na página de configuração dos Inference providers veremos algo assim:
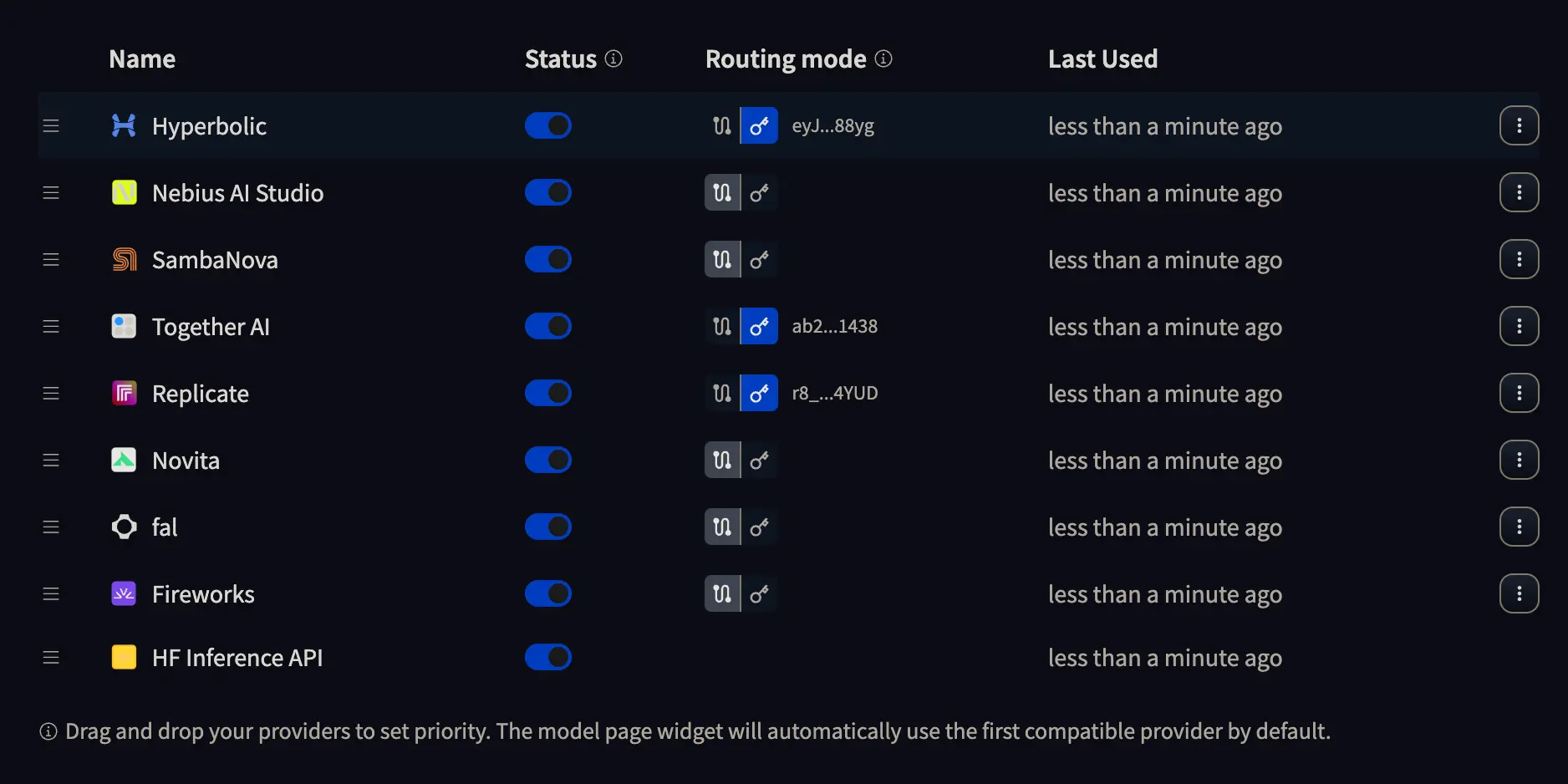 Onde podemos clicar no botão com uma chave para inserir a API KEY do provedor que quisermos usar, ou deixar selecionada a opção com dois pontos. Se escolhermos a primeira opção, será o provedor quem nos cobrará pela inferência, enquanto na segunda opção será a Hugging Face quem nos cobrará pela inferência. Então, faça o que for melhor para você.
Onde podemos clicar no botão com uma chave para inserir a API KEY do provedor que quisermos usar, ou deixar selecionada a opção com dois pontos. Se escolhermos a primeira opção, será o provedor quem nos cobrará pela inferência, enquanto na segunda opção será a Hugging Face quem nos cobrará pela inferência. Então, faça o que for melhor para você.
Inferência com Replicate
No meu caso, obtive uma API KEY do Replicate e a adicionei a um arquivo chamado .env, onde armazenarei as API KEYS e que não deve ser enviado para o GitHub, GitLab ou o repositório do seu projeto.
O .env deve ter este formato
HUGGINGFACE_TOKEN_INFERENCE_PROVIDERS="hf_aL...AY"
REPLICATE_API_KEY="r8_Sh...UD"```
Leitura das chaves API
A primeira coisa que temos que fazer é ler as chaves API do arquivo .env
import osimport dotenvdotenv.load_dotenv()REPLICATE_API_KEY = os.getenv("REPLICATE_API_KEY")HUGGINGFACE_TOKEN_INFERENCE_PROVIDERS = os.getenv("HUGGINGFACE_TOKEN_INFERENCE_PROVIDERS")
Logging no hub da Hugging Face
Para poder usar o modelo de Wan-AI/Wan2.1-T2V-14B, como está no hub de Hugging Face, precisamos fazer login.
from huggingface_hub import loginlogin(HUGGINGFACE_TOKEN_INFERENCE_PROVIDERS)
Cliente de Inferência
Agora criamos um cliente de inferência, temos que especificar o provedor, a API KEY e, neste caso, além disso, vamos estabelecer um tempo de timeout de 1000 segundos, porque por padrão é de 60 segundos e o modelo demora bastante para gerar o vídeo.
from huggingface_hub import InferenceClientclient = InferenceClient(provider="replicate",api_key=REPLICATE_API_KEY,timeout=1000)
Geração do vídeo
Já temos tudo para gerar nosso vídeo. Usamos o método text_to_video do cliente, passamos o prompt e dizemos qual modelo do hub queremos usar, se não, ele usará o que está por padrão.
video = client.text_to_video("Funky dancer, dancing in a rehearsal room. She wears long hair that moves to the rhythm of her dance.",model="Wan-AI/Wan2.1-T2V-14B",)
Salvando o vídeo
Por fim, salvamos o vídeo, que é do tipo bytes, em um arquivo no nosso disco.
output_path = "output_video.mp4"with open(output_path, "wb") as f:f.write(video)print(f"Video saved to: {output_path}")
Video saved to: output_video.mp4
Vídeo gerado
Este é o vídeo gerado pelo modelo