
DoLa: a decodificação por camadas contrastantes melhora a factualidade em grandes modelos de linguagem
Este caderno foi traduzido automaticamente para torná-lo acessível a mais pessoas, por favor me avise se você vir algum erro de digitação.
Entretanto, à medida que os LLMs aumentam de tamanho e surgem novos recursos, temos um problema, que é o aliasing. Os autores do artigo DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models propõem um método para evitar esse problema.
Eles propõem uma abordagem de decodificação contrastiva, em que a probabilidade de saída da próxima palavra é obtida a partir da diferença de logits entre uma camada superior e uma inferior. Ao enfatizar o conhecimento nas camadas superiores e reduzir a ênfase no conhecimento das camadas inferiores, podemos tornar as LMs mais factuais e, assim, reduzir as alucinações.
A figura abaixo mostra essa ideia. Embora Seattle mantenha uma alta probabilidade em todas as camadas, a probabilidade da resposta correta Olympia aumenta depois que as camadas superiores injetam mais conhecimento factual. O contraste das diferenças entre as diferentes camadas pode revelar a resposta correta nesse caso.
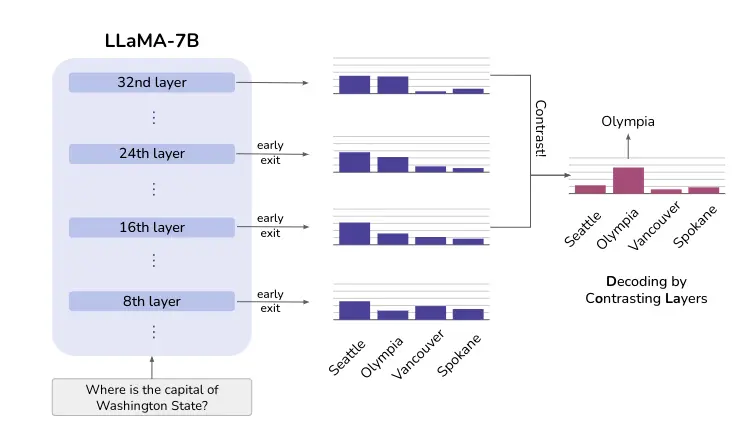
Método
Um LLM consiste em uma camada de incorporação, vários transformadores sequenciais e, em seguida, uma camada de saída. O que eles propõem é medir a saída de cada transformador usando a divergência de Jensen-Shannon (JSD).
A figura a seguir mostra essa medida na saída de cada transformador para uma frase de entrada do LLM. Cada coluna corresponde a um token da frase
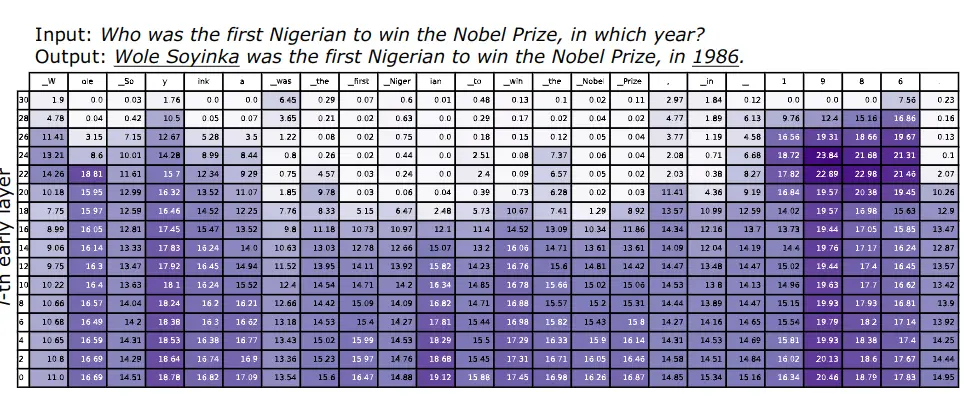
Dois padrões podem ser observados
O primeiro ocorre ao prever entidades nomeadas ou datas importantes, como
Wole Soyinkae1986, que exigem conhecimento factual. É possível observar que o JSD calculado permanece extremamente alto nas camadas superiores. Esse padrão indica que o modelo continua alterando suas previsões nas camadas posteriores e, possivelmente, injetando mais conhecimento factual nas previsões.A segunda ocorre ao prever palavras funcionais, como
was,the,to,in, e tokens copiados da pergunta de entrada, comofirst Nigerian,Nobel Prize. Quando esses tokens "fáceis" são previstos, podemos observar que o JSD se torna muito pequeno a partir das camadas intermediárias. Essa constatação indica que o modelo já decidiu qual token gerar nas camadas intermediárias e mantém as distribuições de saída praticamente inalteradas nas camadas superiores. Essa descoberta também é consistente com as suposições nos LLMs de saída inicialSchuster et al., 2022.
Quando a previsão da próxima palavra requer conhecimento factual, o LLM parece alterar as previsões nas camadas superiores. O contraste das camadas antes e depois de uma mudança repentina pode, portanto, ampliar o conhecimento que emerge das camadas superiores e fazer com que o modelo confie mais em seu conhecimento factual interno. Além disso, essa evolução das informações parece variar de token para token.
Seu método requer a seleção precisa da camada prematura que contém informações plausíveis, mas menos factuais, que nem sempre podem estar na mesma camada inicial. Portanto, eles propõem encontrar essa camada prematura selecionando dinamicamente a camada prematura, conforme visto na imagem a seguir.
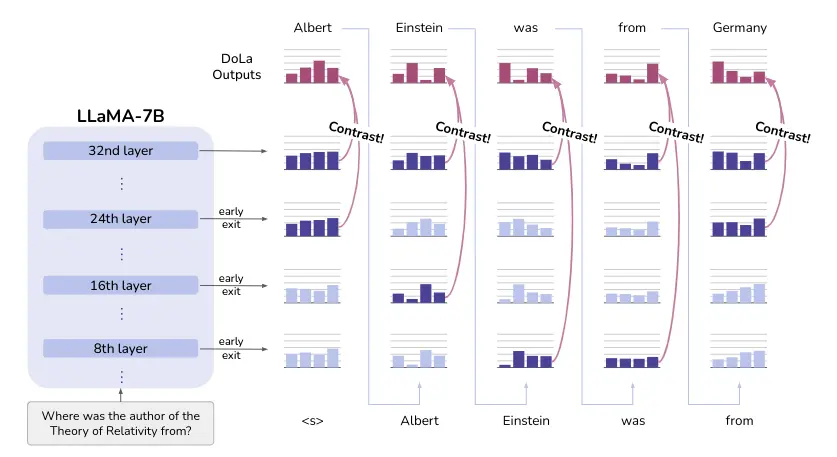
Seleção dinâmica da camada prematura
Para selecionar a camada prematura, eles calculam a divergência de Jensen-Shannon (JSD) entre as camadas intermediárias e a camada final. A camada prematura é selecionada como a camada com a maior JSD.
Entretanto, como esse processo pode ser um pouco lento, o que eles fazem é agrupar várias camadas para fazer menos cálculos.
Contraste de previsões
Agora que temos a última camada (camada madura) e a camada prematura, podemos contrastar as previsões de ambas as camadas. Para isso, eles calculam a probabilidade de log do próximo token na camada madura e na camada prematura. Em seguida, eles subtraem a probabilidade de log da camada prematura daquela da camada madura, dando assim mais peso ao conhecimento da camada madura.
Penalidade de repetição
A motivação da DoLa é reduzir a ênfase no conhecimento linguístico das camadas inferiores e ampliar o conhecimento factual do mundo real. Entretanto, isso pode fazer com que o modelo gere parágrafos gramaticalmente incorretos.
Empiricamente, eles não observaram esse problema, mas descobriram que a distribuição DoLa resultante às vezes tem uma tendência maior de repetir frases geradas anteriormente, especialmente durante a geração de longas sequências de raciocínio na cadeia de pensamento.
Portanto, eles incluem uma penalidade de repetição introduzida em Keskar et al. (2019) com θ = 1,2 durante a decodificação.
Implementação com transformadores
Vamos ver como implementar a DoLa com a biblioteca transformers da Hugging Face. Para obter mais informações sobre como implementar a DoLa com a biblioteca transformers, você pode consultar o seguinte link
Primeiro, fazemos o login no Hub, porque vamos usar o Llama 3 8B e, para usá-lo, precisamos pedir permissão ao Meta, portanto, para fazer o download, precisamos estar conectados para que ele saiba quem está fazendo o download.
from huggingface_hub import notebook_loginnotebook_login()
Agora, instanciamos o tokenizador e o modelo
from huggingface_hub import notebook_loginnotebook_login()from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_id
Atribuímos um valor de semente fixo para a reprodutibilidade do exemplo.
from huggingface_hub import notebook_loginnotebook_login()from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idset_seed(42)
Geramos os tokens de entrada do LLM.
from huggingface_hub import notebook_loginnotebook_login()from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idset_seed(42)question = 'What does Darth Vader say to Luke in "The Empire Strikes Back"?'text = f"Answer with a short answer. Question: {question} Answer: "inputs = tokenizer(text, return_tensors="pt").to(model.device)
Agora, geramos a entrada vanilla, ou seja, sem aplicar o DoLa
generate_kwargs={
"do_sample": False,
"max_new_tokens": 50,
"top_p": None,
"temperature": None
}
vanilla_output = model.generate(**inputs, **generate_kwargs)
print(tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])
Vemos que ele sabe que há um erro famoso, mas não diz a frase verdadeira
Agora aplicando o DoLa
dola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers='high', repetition_penalty=1.2)
print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])
Agora ele consegue dar a frase correta e o famoso erro
Vamos fazer outro teste com outro exemplo, reiniciar o notebook e usar outro modelo.
from huggingface_hub import notebook_loginnotebook_login()from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idset_seed(42)question = 'What does Darth Vader say to Luke in "The Empire Strikes Back"?'text = f"Answer with a short answer. Question: {question} Answer: "inputs = tokenizer(text, return_tensors="pt").to(model.device)generate_kwargs={"do_sample": False,"max_new_tokens": 50,"top_p": None,"temperature": None}vanilla_output = model.generate(**inputs, **generate_kwargs)print(tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])dola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers='high', repetition_penalty=1.2)print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "huggyllama/llama-7b"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_id
Atribuímos um valor de semente fixo para a reprodutibilidade do exemplo.
from huggingface_hub import notebook_loginnotebook_login()from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idset_seed(42)question = 'What does Darth Vader say to Luke in "The Empire Strikes Back"?'text = f"Answer with a short answer. Question: {question} Answer: "inputs = tokenizer(text, return_tensors="pt").to(model.device)generate_kwargs={"do_sample": False,"max_new_tokens": 50,"top_p": None,"temperature": None}vanilla_output = model.generate(**inputs, **generate_kwargs)print(tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])dola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers='high', repetition_penalty=1.2)print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "huggyllama/llama-7b"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idset_seed(42)
Estou escrevendo uma nova pergunta
from huggingface_hub import notebook_loginnotebook_login()from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idset_seed(42)question = 'What does Darth Vader say to Luke in "The Empire Strikes Back"?'text = f"Answer with a short answer. Question: {question} Answer: "inputs = tokenizer(text, return_tensors="pt").to(model.device)generate_kwargs={"do_sample": False,"max_new_tokens": 50,"top_p": None,"temperature": None}vanilla_output = model.generate(**inputs, **generate_kwargs)print(tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])dola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers='high', repetition_penalty=1.2)print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "huggyllama/llama-7b"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idset_seed(42)text = "On what date was the Declaration of Independence officially signed?"inputs = tokenizer(text, return_tensors="pt").to(device)
Geramos a saída vanilla
from huggingface_hub import notebook_loginnotebook_login()from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idset_seed(42)question = 'What does Darth Vader say to Luke in "The Empire Strikes Back"?'text = f"Answer with a short answer. Question: {question} Answer: "inputs = tokenizer(text, return_tensors="pt").to(model.device)generate_kwargs={"do_sample": False,"max_new_tokens": 50,"top_p": None,"temperature": None}vanilla_output = model.generate(**inputs, **generate_kwargs)print(tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])dola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers='high', repetition_penalty=1.2)print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "huggyllama/llama-7b"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idset_seed(42)text = "On what date was the Declaration of Independence officially signed?"inputs = tokenizer(text, return_tensors="pt").to(device)generate_kwargs={"do_sample": False,"max_new_tokens": 50,"top_p": None,"temperature": None}vanilla_output = model.generate(**inputs, **generate_kwargs)print(tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.The Declaration of Independence was signed on July 4, 1776.What was the date of the signing of the Declaration of Independence?The Declaration of Independence was signed on July 4,
Como podemos ver, ela gera a partida errada, pois, embora seja comemorada em 4 de julho, na verdade foi assinada em 2 de agosto.
Vamos experimentar o DoLa agora
dola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers='high', repetition_penalty=1.2)print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])
July 4, 1776. This is the most well-known date in U.S. history. The day has been celebrated with parades, barbeques, fireworks and festivals for hundreds of years.
Ele ainda não gera a saída correta, portanto, vamos instruí-lo a contrastar apenas a camada final com as camadas 28 e 30.
dola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers=[28,30], repetition_penalty=1.2)print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])
It was officially signed on 2 August 1776, when 56 members of the Second Continental Congress put their John Hancocks to the Declaration. The 2-page document had been written in 17
Agora, ele consegue gerar a resposta correta
















