
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
Artigo
Melhorando a Compreensão de Linguagem por Pré-Treinamento Gerativo é o paper do GPT1. Antes de ler o post, é necessário que você se situe: antes do GPT, os modelos de linguagem estavam baseados em redes recorrentes (RNN), que eram redes que funcionavam relativamente bem para tarefas específicas, mas com as quais não era possível reutilizar o pré-treinamento para fazer um fine tuning para outras tarefas. Além disso, elas não tinham muita memória, então se fossem alimentadas com frases muito longas, não lembravam muito bem o início da frase.
Arquitetura
Antes de falar da arquitetura do GPT1, vamos lembrar como era a arquitetura dos transformers.
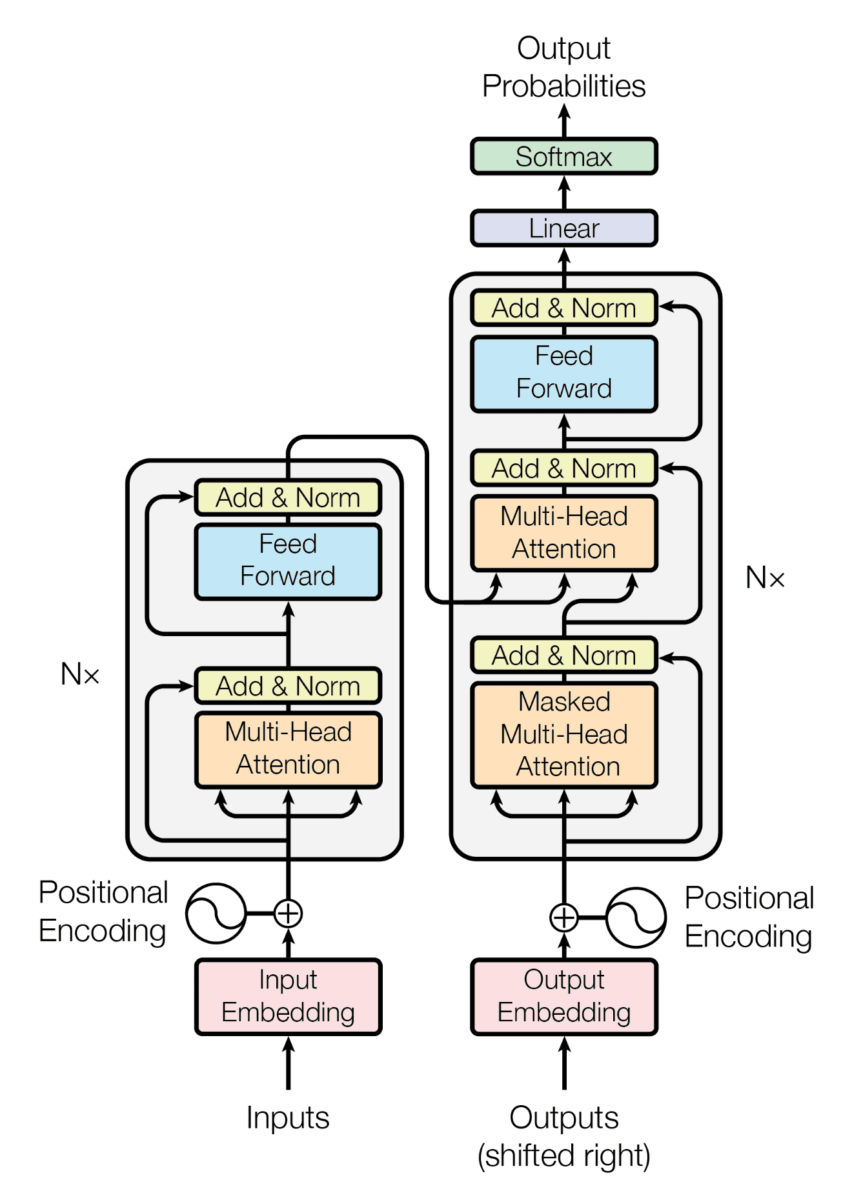
GPT1 é um modelo baseado nos decodificadores dos transformers, então, como não temos codificador, a arquitetura de um único decodificador fica da seguinte maneira
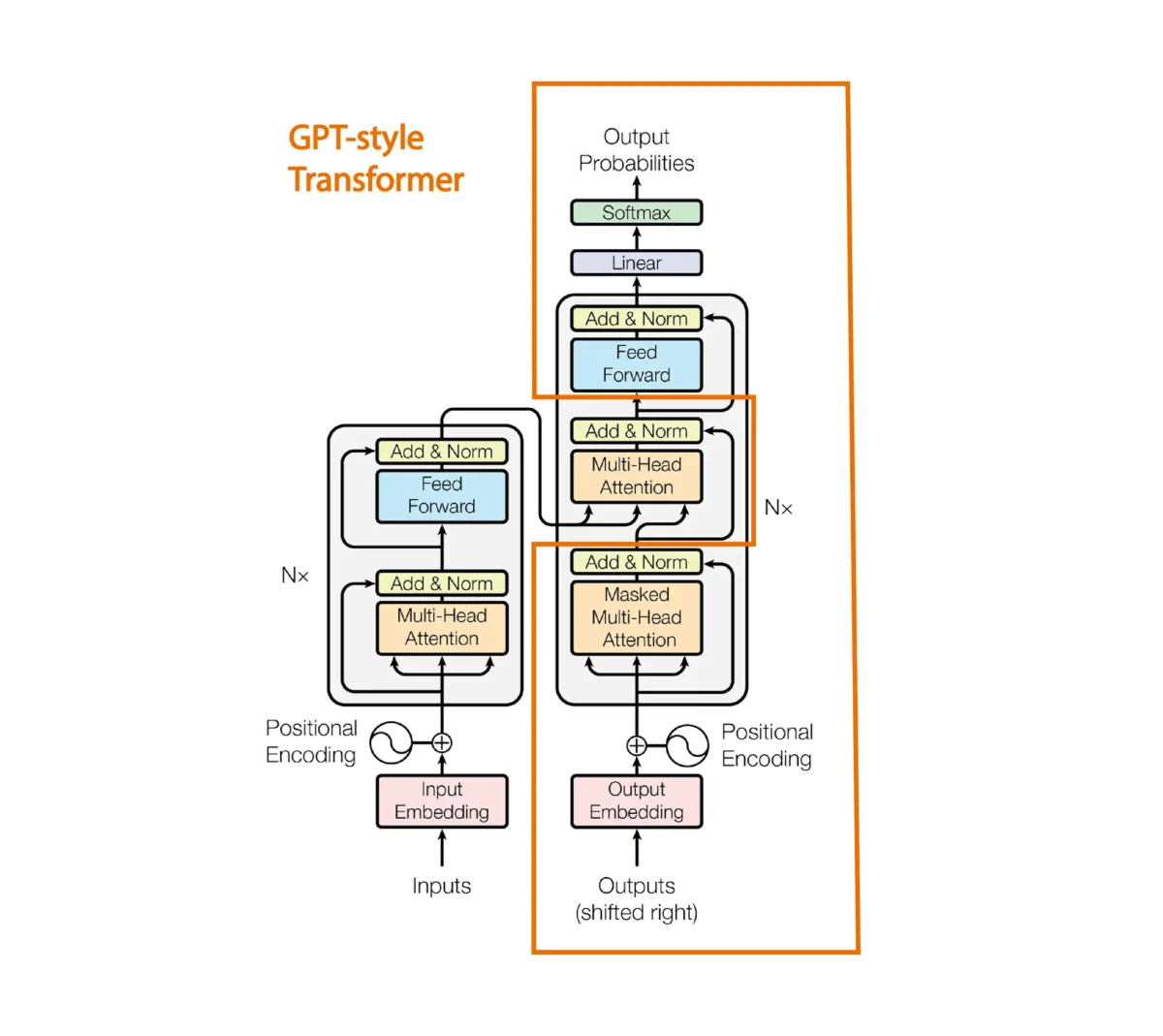
O mecanismo de atenção entre a sentença do encoder e do decoder é removido.
No o artigo do GPT1 propõem a seguinte arquitetura
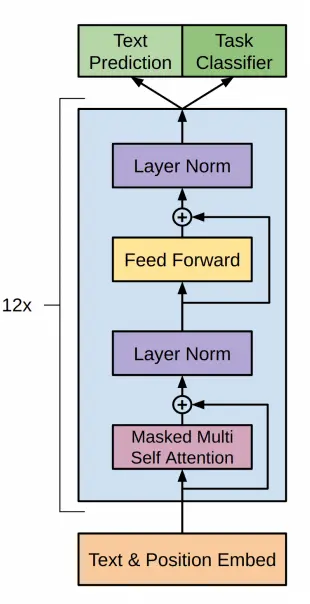
Que corresponde ao decoder de um transformer como vimos anteriormente, executado 12 vezes
Resumo do artigo
As ideias mais interessantes do paper são:
- O modelo é treinado em um grande corpus de texto sem supervisão. Com isso, cria-se um modelo de linguagem. Cria-se um modelo de linguagem de alta capacidade em um grande corpus de texto.
- Em seguida, é feito um fine-tuning em tarefas de NLP supervisionadas com conjuntos de dados rotulados. Realiza-se um ajuste fino em uma tarefa objetivo com supervisão. Além disso, quando o modelo é avaliado na tarefa supervisionada, não é avaliado apenas por essa tarefa, mas também pelo quão bem ele prevê o próximo token, o que ajuda a melhorar a generalização do modelo supervisionado e faz com que o modelo convirja mais rapidamente.
- Embora já tenhamos mencionado, no artigo diz que é utilizada a arquitetura transformer, pois até aquele momento eram usadas RNN para os modelos de linguagem. Isso resultou em uma melhoria na qual o aprendizado do primeiro treinamento (treinamento no corpus de texto sem supervisão) é mais fácil de transferir para tarefas supervisionadas. Ou seja, graças ao uso de transformers, foi possível realizar um treinamento em todo um corpus de texto e, posteriormente, ajustes finos em tarefas supervisionadas.
- Avaliaram o modelo em quatro tipos de tarefas de compreensão da linguagem:
- Inferência da linguagem natural* Resposta a perguntas
- Similaridade semântica
- Classificação de textos.
- O modelo geral (treinado em todo o corpus de texto sem supervisão) supera os modelos RNN treinados discriminativamente que utilizam arquiteturas projetadas especificamente para cada tarefa, melhorando significativamente o estado da arte em 9 das 12 tarefas estudadas. Eles também analisaram os comportamentos de "tiro zero" do modelo pré-treinado em quatro ambientes diferentes e demonstraram que ele adquire um conhecimento linguístico útil para as tarefas subsequentes.
- Nos últimos anos, os pesquisadores haviam demonstrado os benefícios de utilizar embeddings, que são treinados em corpora não anotados, para melhorar o desempenho em uma variedade de tarefas. No entanto, essas abordagens transferem principalmente informações a nível de palavra, enquanto o uso de transformers treinados em grandes corpora de texto sem supervisão captura a semântica de nível superior, a nível de frase.
Geração de texto
Vamos a ver como gerar texto com um GPT1 pré-treinado
Primeiro é necessário instalar ftfy e spacy através de
pip install ftfy spacyUma vez instaladas, você deve baixar o modelo de linguagem do spaCy que deseja usar. Por exemplo, para baixar o modelo em inglês, você pode executar:
python -m spacy download en_core_web_smPara gerar texto vamos utilizar o modelo do repositório GPT1 da Hugging Face.
Importamos as bibliotecas
InputPythonimport torchfrom transformers import OpenAIGPTTokenizer, OpenAIGPTLMHeadModel, AutoTokenizerCopied
Se você reparar, importamos OpenAIGPTTokenizer e AutoTokenizer. Isso é porque na model card do GPT1 indica-se que se deve usar OpenAIGPTTokenizer, mas no post da biblioteca transformers explicamos que se deve usar AutoTokenizer para carregar o tokenizador. Então, vamos testar os dois.
InputPythonckeckpoints = "openai-community/openai-gpt"tokenizer = OpenAIGPTTokenizer.from_pretrained(ckeckpoints)auto_tokenizer = AutoTokenizer.from_pretrained(ckeckpoints)input_tokens = tokenizer("Hello, my dog is cute and", return_tensors="pt")input_auto_tokens = auto_tokenizer("Hello, my dog is cute and", return_tensors="pt")print(f"input tokens: {input_tokens}")print(f"input auto tokens: {input_auto_tokens}")Copied
input tokens:{'input_ids': tensor([[3570, 240, 547, 2585, 544, 4957, 488]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}input auto tokens:{'input_ids': tensor([[3570, 240, 547, 2585, 544, 4957, 488]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}
Como pode ser visto com os dois tokenizadores, são obtidos os mesmos tokens. Então, para que o código seja mais geral, de forma que se os checkpoints forem alterados, não seja necessário alterar o código, vamos utilizar AutoTokenizer.
Criamos então o dispositivo, o tokenizador e o modelo
InputPythondevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")tokenizer = AutoTokenizer.from_pretrained(ckeckpoints)model = OpenAIGPTLMHeadModel.from_pretrained(ckeckpoints).to(device)Copied
Como instanciamos o modelo, vamos a ver quantos parâmetros ele tem.
InputPythonparams = sum(p.numel() for p in model.parameters())print(f"Number of parameters: {round(params/1e6)}M")Copied
Number of parameters: 117M
Na era dos trilhões de parâmetros, podemos ver que o GPT1 tinha apenas 117 milhões de parâmetros.
Criamos os tokens de entrada para o modelo
InputPythoninput_sentence = "Hello, my dog is cute and"input_tokens = tokenizer(input_sentence, return_tensors="pt").to(device)input_tokensCopied
{'input_ids': tensor([[3570, 240, 547, 2585, 544, 4957, 488]], device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]], device='cuda:0')}
Passamo-los ao modelo para gerar os tokens de saída
InputPythonoutput_tokens = model.generate(**input_tokens)print(f"output tokens: {output_tokens}")Copied
output tokens:tensor([[ 3570, 240, 547, 2585, 544, 4957, 488, 249, 719, 797,485, 921, 575, 562, 246, 1671, 239, 244, 40477, 244]],device='cuda:0')
/home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/generation/utils.py:1178: UserWarning: Using the model-agnostic default `max_length` (=20) to control the generation length. We recommend setting `max_new_tokens` to control the maximum length of the generation.warnings.warn(
Decodificamos os tokens para obter a frase de saída
InputPythondecoded_output = tokenizer.decode(output_tokens[0], skip_special_tokens=True)print(f"decoded output: {decoded_output}")Copied
decoded output:hello, my dog is cute and i'm going to take him for a walk. ""
Já conseguimos gerar texto com GPT1
Gerar texto token a token
Busca gulosa
Nós usamos model.generate para gerar os tokens de saída de uma só vez, mas vamos ver como gerá-los um a um. Para isso, em vez de usar model.generate vamos usar model, que na verdade chama o método model.forward
InputPythonoutputs = model(**input_tokens)outputsCopied
CausalLMOutput(loss=None, logits=tensor([[[ -5.9486, -5.8697, -18.4258, ..., -9.7371, -10.4495, 0.8814],[ -6.1212, -4.8031, -14.3970, ..., -6.5411, -9.5051, -1.2015],[ -7.4231, -6.3615, -14.7297, ..., -10.4575, -8.4600, -1.5183],...,[ -5.4751, -5.8803, -13.7767, ..., -10.5048, -12.4167, -6.1584],[ -7.2052, -6.0198, -21.5040, ..., -16.2941, -14.0494, -1.2416],[ -7.7240, -7.3631, -17.3174, ..., -12.1546, -12.3327, -1.7169]]],device='cuda:0', grad_fn=<UnsafeViewBackward0>), hidden_states=None, attentions=None)
Vemos que saí muitos dados, primeiro vamos ver as keys da saída
InputPythonoutputs.keys()Copied
odict_keys(['logits'])
Neste caso, temos apenas os logits do modelo, vamos verificar seu tamanho.
InputPythonlogits = outputs.logitslogits.shapeCopied
torch.Size([1, 7, 40478])
Vamos ver quantos tokens tínhamos na entrada
InputPythoninput_tokens.input_ids.shapeCopied
torch.Size([1, 7])
Bem, na saída temos o mesmo número de logits que na entrada. Isso é normal.
Obtemos os logits da última posição da saída
InputPythonnex_token_logits = logits[0,-1]nex_token_logits.shapeCopied
torch.Size([40478])
Há um total de 40478 logits, ou seja, há um vocabulário de 40478 tokens e temos que ver qual é o token com a maior probabilidade. Para isso, primeiro calculamos a softmax.
InputPythonsoftmax_logits = torch.softmax(nex_token_logits, dim=0)softmax_logits.shapeCopied
torch.Size([40478])
InputPythonnext_token_prob, next_token_id = torch.max(softmax_logits, dim=0)next_token_prob, next_token_idCopied
(tensor(0.1898, device='cuda:0', grad_fn=<MaxBackward0>),tensor(249, device='cuda:0'))
Obtivemos o seguinte token, agora vamos decodificá-lo.
InputPythontokenizer.decode(next_token_id.item())Copied
'i'
Obtivemos o seguinte token através do método greedy, ou seja, o token com maior probabilidade. Mas já vimos no post da biblioteca transformers as formas de gerar textos que podem ser feitas sampling, top-k, top-p, etc.
Vamos a colocar tudo dentro de uma função e ver o que sai se gerarmos alguns tokens
InputPythondef generate_next_greedy_token(input_sentence, tokenizer, model, device):input_tokens = tokenizer(input_sentence, return_tensors="pt").to(device)outputs = model(**input_tokens)logits = outputs.logitsnex_token_logits = logits[0,-1]softmax_logits = torch.softmax(nex_token_logits, dim=0)next_token_prob, next_token_id = torch.max(softmax_logits, dim=0)return next_token_prob, next_token_idCopied
InputPythondef generate_greedy_text(input_sentence, tokenizer, model, device, max_length=20):generated_text = input_sentencefor _ in range(max_length):next_token_prob, next_token_id = generate_next_greedy_token(generated_text, tokenizer, model, device)generated_text += tokenizer.decode(next_token_id.item())return generated_textCopied
Agora geramos texto
InputPythongenerate_greedy_text("Hello, my dog is cute and", tokenizer, model, device)Copied
'Hello, my dog is cute andi." '
A saída é bastante repetitiva, como já foi visto nas formas de gerar textos
Ajuste fino do GPT
Cálculo da perda
Antes de começar a fazer o fine tuning do GPT1, vamos ver uma coisa. Antes, quando obtínhamos a saída do modelo, fazíamos isso
InputPythonoutputs = model(**input_tokens)outputsCopied
CausalLMOutput(loss=None, logits=tensor([[[ -5.9486, -5.8697, -18.4258, ..., -9.7371, -10.4495, 0.8814],[ -6.1212, -4.8031, -14.3970, ..., -6.5411, -9.5051, -1.2015],[ -7.4231, -6.3615, -14.7297, ..., -10.4575, -8.4600, -1.5183],...,[ -5.4751, -5.8803, -13.7767, ..., -10.5048, -12.4167, -6.1584],[ -7.2052, -6.0198, -21.5040, ..., -16.2941, -14.0494, -1.2416],[ -7.7240, -7.3631, -17.3174, ..., -12.1546, -12.3327, -1.7169]]],device='cuda:0', grad_fn=<UnsafeViewBackward0>), hidden_states=None, attentions=None)
Pode-se ver que obtemos loss=None
InputPythonprint(outputs.loss)Copied
None
Como vamos a precisar da loss para fazer o fine tuning, vamos a ver como obtê-la.
Se nós formos à documentação do método forward de OpenAIGPTLMHeadModel, podemos ver que diz que na saída retorna um objeto do tipo transformers.modeling_outputs.CausalLMOutput, então se formos à documentação de transformers.modeling_outputs.CausalLMOutput, podemos ver que diz que retorna loss se for passado labels para o método forward.
Se nós formos à fonte do código do método forward, vemos este bloco de código
perda = None
se labels não for None:
# Deslocar para que os tokens < n prevejam n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Aplanar os tokens
loss_fct = CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))Isso significa que a loss é calculada da seguinte maneira
- Shift de logits e labels: A primeira parte é deslocar os logits (
lm_logits) e as etiquetas (labels) para que ostokens < nprevejamn, ou seja, a partir de uma posiçãonse prevê o próximo token com base nos anteriores. - CrossEntropyLoss: Cria-se uma instância da função de perda
CrossEntropyLoss(). - Achatando tokens: A seguir, os logits e as etiquetas são aplanados utilizando
view(-1, shift_logits.size(-1))eview(-1), respectivamente. Isso é feito para que os logits e as etiquetas tenham a mesma forma para a função de perda. - Cálculo da perda: Finalmente, calcula-se a perda utilizando a função de perda
CrossEntropyLoss()com os logits achatados e as etiquetas achatadas como entradas.
Em resumo, a loss é calculada como a perda de entropia cruzada entre os logits deslocados e achatados e as labels deslocadas e achatadas.
Portanto, se passarmos os labels para o método forward, ele retornará a loss.
InputPythonoutputs = model(**input_tokens, labels=input_tokens.input_ids)outputs.lossCopied
tensor(4.2607, device='cuda:0', grad_fn=<NllLossBackward0>)
Conjunto de Dados
Para o treinamento, vamos usar um dataset de piadas em inglês short-jokes-dataset, que é um dataset com 231 mil piadas em inglês.
Baixamos o dataset
InputPythonfrom datasets import load_datasetjokes = load_dataset("Maximofn/short-jokes-dataset")jokesCopied
DatasetDict({train: Dataset({features: ['ID', 'Joke'],num_rows: 231657})})
Vamos vê-lo um pouco
InputPythonjokes["train"][0]Copied
{'ID': 1,'Joke': '[me narrating a documentary about narrators] "I can't hear what they're saying cuz I'm talking"'}
Treinamento com Pytorch
Primeiro vamos ver como seria o treinamento com puro Pytorch
Reiniciamos o notebook para que não haja problemas com a memória da GPU
InputPythonimport torchfrom transformers import OpenAIGPTLMHeadModel, AutoTokenizerdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")ckeckpoints = "openai-community/openai-gpt"tokenizer = AutoTokenizer.from_pretrained(ckeckpoints)model = OpenAIGPTLMHeadModel.from_pretrained(ckeckpoints)model = model.to(device)Copied
Conjunto de dados do Pytorch
Criamos uma classe Dataset do Pytorch
InputPythonfrom torch.utils.data import Datasetclass JokesDataset(Dataset):def __init__(self, dataset, tokenizer):self.dataset = datasetself.joke = "JOKE: "self.end_of_text_token = "<|endoftext|>"self.tokenizer = tokenizerdef __len__(self):return len(self.dataset["train"])def __getitem__(self, item):sentence = self.joke + self.dataset["train"][item]["Joke"] + self.end_of_text_tokentokens = self.tokenizer(sentence, return_tensors="pt")return sentence, tokensCopied
A instanciamos
InputPythondataset = JokesDataset(jokes, tokenizer=tokenizer)Copied
Vamos ver um exemplo
InputPythonsentence, tokens = dataset[5]print(sentence)tokens.input_ids.shape, tokens.attention_mask.shapeCopied
JOKE: Why can't Barbie get pregnant? Because Ken comes in a different box. Heyooooooo<|endoftext|>
(torch.Size([1, 30]), torch.Size([1, 30]))
Dataloader
Criamos agora um dataloader do Pytorch
InputPythonfrom torch.utils.data import DataLoaderBS = 1joke_dataloader = DataLoader(dataset, batch_size=BS, shuffle=True)Copied
Vemos um lote
InputPythonsentences, tokens = next(iter(joke_dataloader))len(sentences), tokens.input_ids.shape, tokens.attention_mask.shapeCopied
(1, torch.Size([1, 1, 29]), torch.Size([1, 1, 29]))
Treinamento
InputPythonfrom transformers import AdamW, get_linear_schedule_with_warmupimport tqdmBATCH_SIZE = 32EPOCHS = 5LEARNING_RATE = 3e-5WARMUP_STEPS = 5000MAX_SEQ_LEN = 500model.train()optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=WARMUP_STEPS, num_training_steps=-1)proc_seq_count = 0batch_count = 0tmp_jokes_tens = Nonefor epoch in range(EPOCHS):print(f"EPOCH {epoch} started" + '=' * 30)progress_bar = tqdm.tqdm(joke_dataloader, desc="Training")for sample in progress_bar:sentence, tokens = sample#################### "Fit as many joke sequences into MAX_SEQ_LEN sequence as possible" logic start ####joke_tens = tokens.input_ids[0].to(device)# Skip sample from dataset if it is longer than MAX_SEQ_LENif joke_tens.size()[1] > MAX_SEQ_LEN:continue# The first joke sequence in the sequenceif not torch.is_tensor(tmp_jokes_tens):tmp_jokes_tens = joke_tenscontinueelse:# The next joke does not fit in so we process the sequence and leave the last joke# as the start for next sequenceif tmp_jokes_tens.size()[1] + joke_tens.size()[1] > MAX_SEQ_LEN:work_jokes_tens = tmp_jokes_tenstmp_jokes_tens = joke_tenselse:#Add the joke to sequence, continue and try to add moretmp_jokes_tens = torch.cat([tmp_jokes_tens, joke_tens[:,1:]], dim=1)continue################## Sequence ready, process it trough the model ##################outputs = model(work_jokes_tens, labels=work_jokes_tens)loss = outputs.lossloss.backward()proc_seq_count = proc_seq_count + 1if proc_seq_count == BATCH_SIZE:proc_seq_count = 0batch_count += 1optimizer.step()scheduler.step()optimizer.zero_grad()model.zero_grad()progress_bar.set_postfix({'loss': loss.item(), 'lr': scheduler.get_last_lr()[0]})if batch_count == 10:batch_count = 0Copied
/home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/optimization.py:429: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warningwarnings.warn(
EPOCH 0 started==============================
Training: 100%|██████████| 231657/231657 [11:31<00:00, 334.88it/s, loss=2.88, lr=2.93e-6]
EPOCH 1 started==============================
Training: 100%|██████████| 231657/231657 [11:30<00:00, 335.27it/s, loss=2.49, lr=5.87e-6]
EPOCH 2 started==============================
Training: 100%|██████████| 231657/231657 [11:17<00:00, 341.75it/s, loss=2.57, lr=8.81e-6]
EPOCH 3 started==============================
Training: 100%|██████████| 231657/231657 [11:18<00:00, 341.27it/s, loss=2.41, lr=1.18e-5]
EPOCH 4 started==============================
Training: 100%|██████████| 231657/231657 [11:19<00:00, 341.04it/s, loss=2.49, lr=1.47e-5]
Inferência
Vamos a ver como o modelo faz piadas
InputPythonsentence_joke = "JOKE:"input_tokens_joke = tokenizer(sentence_joke, return_tensors="pt").to(device)output_tokens_joke = model.generate(**input_tokens_joke)decoded_output_joke = tokenizer.decode(output_tokens_joke[0], skip_special_tokens=True)print(f"decoded joke: {decoded_output_joke}")Copied
decoded joke:joke : what do you call a group of people who are not afraid of the dark? a group
Pode-se ver que você passa uma sequência com a palavra joke e ele retorna uma piada. Mas se você retornar outra sequência não
InputPythonsentence_joke = "My dog is cute and"input_tokens_joke = tokenizer(sentence_joke, return_tensors="pt").to(device)output_tokens_joke = model.generate(**input_tokens_joke)decoded_output_joke = tokenizer.decode(output_tokens_joke[0], skip_special_tokens=True)print(f"decoded joke: {decoded_output_joke}")Copied
decoded joke:my dog is cute and i'm not sure if i should be offended or not. "















