
Aviso: Este caderno foi traduzido automaticamente para torná-lo acessível a mais pessoas, por favor me avise se você vir algum erro de digitação.
Introdução
A biblioteca transformers da Hugging Face é uma das bibliotecas mais populares para trabalhar com modelos de linguagem. Sua facilidade de uso democratizou o uso da arquitetura Transformer e tornou possível trabalhar com modelos de linguagem de última geração sem a necessidade de ter muito conhecimento na área.
Entre a biblioteca transformers, o hub de modelos e sua facilidade de uso, os espaços e a facilidade de implementação de demonstrações, além de novas bibliotecas como datasets, accelerate, PEFT e outras, eles tornaram a Hugging Face um dos participantes mais importantes no cenário de IA no momento. Eles se autodenominam "o GitHub da IA" e certamente o são.
Instalação
Para instalar transformadores, você pode fazer isso com o pip.
pip install transformersou com conda.
conda install conda-forge::transformersAlém da biblioteca, você precisa ter um backend do PyTorch ou do TensorFlow instalado. Ou seja, você precisa ter o torch ou o tensorflow instalados para poder usar o transformers.
Inferência com pipeline.
Com os pipelines transformers, a inferência com modelos de linguagem pode ser feita de maneira muito simples. A vantagem disso é que o desenvolvimento é muito mais rápido e a criação de protótipos pode ser feita com muita facilidade. Isso também permite que pessoas que não têm muito conhecimento usem os modelos.
Com o pipeline, você pode fazer inferência em várias tarefas diferentes. Cada tarefa tem sua própria pipeline (NLP pipeline, visão pipeline etc.), mas você pode fazer uma abstração geral usando a classe pipeline, que se encarrega de selecionar a pipeline correta para a tarefa que você passar a ela.
Tarefas
No momento da redação desta postagem, as tarefas que podem ser realizadas com o pipeline são:
- Áudio:
- Classificação de áudio
- Classificação de cenas acústicas: marque o áudio com um rótulo de cena ("escritório", "praia", "estádio")
- Detecção de eventos acústicos: marcar o áudio com uma etiqueta de evento sonoro ("buzina de carro", "canto de baleia", "quebra de vidro")
- Marcação: marcação de áudio contendo vários sons (canto de pássaros, identificação de oradores em uma reunião)
- Classificação musical: rotular a música com um rótulo de gênero ("metal", "hip-hop", "country")
- Reconhecimento automático de fala (ASR, reconhecimento de fala em áudio):
- Visão computacional
- Classificação de imagens
- Detecção de objetos
- Segmentação de imagens
- Estimativa de profundidade
Processamento de linguagem natural (NLP) * Processamento de linguagem natural (NLP)
- Classificação do texto
- Análise de sentimento
- Classificação do conteúdo
- Classificação dos tokens
- Reconhecimento de entidades nomeadas (NER): marca um token de acordo com uma categoria de entidade, como organização, pessoa, local ou data.
- Marcação de parte do discurso (POS): marcação de um token de acordo com sua parte do discurso, como substantivo, verbo ou adjetivo. O POS é útil para ajudar os sistemas de tradução a entender como duas palavras idênticas são gramaticalmente diferentes (por exemplo, "cut" como substantivo versus "cut" como verbo).
- Respostas às perguntas
- Extrativo: dada uma pergunta e algum contexto, a resposta é um trecho de texto do contexto que o modelo deve extrair.
- Resumo: dada uma pergunta e algum contexto, a resposta é gerada a partir do contexto; essa abordagem é tratada pelo Text2TextGenerationPipeline em vez do QuestionAnsweringPipeline mostrado abaixo.
- Resumir
- Extrativo: identifica e extrai as frases mais importantes do texto original
- abstrativo: gera o resumo de destino (que pode incluir novas palavras não presentes no documento de entrada) a partir do texto original
- Tradução
- Modelagem de linguagem
- causal: o objetivo do modelo é prever o próximo token em uma sequência, e os tokens futuros são mascarados
- Mascarado: o objetivo do modelo é prever um token mascarado em um fluxo com acesso total aos tokens no fluxo.
- Multimodal
- Respostas a perguntas sobre documentos
Uso de pipeline
A maneira mais fácil de criar uma pipeline é simplesmente informar a tarefa que queremos que ela resolva usando o parâmetro task. E a biblioteca selecionará o melhor modelo para essa tarefa, fará o download e o armazenará em cache para uso futuro.
InputPythonfrom transformers import pipelinegenerator = pipeline(task="text-generation")Copied
No model was supplied, defaulted to openai-community/gpt2 and revision 6c0e608 (https://huggingface.co/openai-community/gpt2).Using a pipeline without specifying a model name and revision in production is not recommended.
InputPythongenerator("Me encanta aprender de")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[{'generated_text': 'Me encanta aprender de se résistance davant que hiens que préclase que ses encasas quécénces. Se présentants cet en un croyne et cela désirez'}]
Como você pode ver, o texto gerado está em francês, embora eu o tenha apresentado em espanhol, por isso é importante escolher o modelo correto. Se você observar a biblioteca, ela utilizou o modelo openai-community/gpt2, que é um modelo treinado principalmente em inglês, e quando coloquei o texto em espanhol, ele ficou confuso e gerou uma resposta em francês.
Usaremos um modelo treinado novamente em inglês usando o parâmetro model.
InputPythonfrom transformers import pipelinegenerator = pipeline(task="text-generation", model="flax-community/gpt-2-spanish")Copied
InputPythongenerator("Me encanta aprender de")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[{'generated_text': 'Me encanta aprender de tus palabras, que con gran entusiasmo y con el mismo conocimiento como lo que tú acabas escribiendo, te deseo de todo corazón todo el deseo de este día: Y aunque también haya personas a las que'}]
O texto gerado agora tem uma aparência muito melhor
A classe pipeline tem muitos parâmetros possíveis, portanto, para ver todos eles e saber mais sobre a classe, recomendo a leitura de sua [documentação] (https://huggingface.co/docs/transformers/v4.38.1/en/main_classes/pipelines), mas vamos falar sobre um deles, pois, para o aprendizado profundo, ele é muito importante e é o device. Ele define o dispositivo (por exemplo, cpu, cuda:1, mps ou um intervalo ordinal de GPUs como 1) no qual a pipeline será mapeada.
No meu caso, como tenho uma GPU, defini 0.
InputPythonfrom transformers import pipelinegenerator = pipeline(task="text-generation", model="flax-community/gpt-2-spanish", device=0)generation = generator("Me encanta aprender de")print(generation[0]['generated_text'])Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de ustedes, a tal punto que he decidido escribir algunos de nuestros contenidos en este blog, el cual ha sido de gran utilidad para mí por varias razones, una de ellas, el trabajo
Como funciona o `pipeline
Quando usamos pipeline por baixo, o que está acontecendo é o seguinte
transformers-pipeline](https://images.maximofn.com/transformers-pipeline.svg)
O texto é automaticamente tokenizado, passado pelo modelo e depois pós-processado.
Inferência com AutoClass e pipeline.
Vimos que o pipeline abstrai muito do que acontece, mas podemos selecionar qual tokenizador, qual modelo e qual pós-processamento queremos usar.
Tokenização com AutoTokenizer.
Antes de usarmos o modelo flax-community/gpt-2-spanish para gerar texto, podemos usar seu tokenizador
InputPythonfrom transformers import AutoTokenizercheckpoint = "flax-community/gpt-2-spanish"tokenizer = AutoTokenizer.from_pretrained(checkpoint)text = "Me encanta lo que estoy aprendiendo"tokens = tokenizer(text, return_tensors="pt")print(tokens)Copied
{'input_ids': tensor([[ 2879, 4835, 382, 288, 2383, 15257]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1]])}
Modelo AutoModel.
Agora podemos criar o modelo e passar os tokens para ele.
InputPythonfrom transformers import AutoModelmodel = AutoModel.from_pretrained("flax-community/gpt-2-spanish")output = model(**tokens)type(output), output.keys()Copied
(transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions,odict_keys(['last_hidden_state', 'past_key_values']))
Se agora tentarmos usá-lo em uma pipeline, receberemos um erro.
InputPythonfrom transformers import pipelinepipeline("text-generation", model=model, tokenizer=tokenizer)("Me encanta aprender de")Copied
The model 'GPT2Model' is not supported for text-generation. Supported models are ['BartForCausalLM', 'BertLMHeadModel', 'BertGenerationDecoder', 'BigBirdForCausalLM', 'BigBirdPegasusForCausalLM', 'BioGptForCausalLM', 'BlenderbotForCausalLM', 'BlenderbotSmallForCausalLM', 'BloomForCausalLM', 'CamembertForCausalLM', 'LlamaForCausalLM', 'CodeGenForCausalLM', 'CpmAntForCausalLM', 'CTRLLMHeadModel', 'Data2VecTextForCausalLM', 'ElectraForCausalLM', 'ErnieForCausalLM', 'FalconForCausalLM', 'FuyuForCausalLM', 'GemmaForCausalLM', 'GitForCausalLM', 'GPT2LMHeadModel', 'GPT2LMHeadModel', 'GPTBigCodeForCausalLM', 'GPTNeoForCausalLM', 'GPTNeoXForCausalLM', 'GPTNeoXJapaneseForCausalLM', 'GPTJForCausalLM', 'LlamaForCausalLM', 'MarianForCausalLM', 'MBartForCausalLM', 'MegaForCausalLM', 'MegatronBertForCausalLM', 'MistralForCausalLM', 'MixtralForCausalLM', 'MptForCausalLM', 'MusicgenForCausalLM', 'MvpForCausalLM', 'OpenLlamaForCausalLM', 'OpenAIGPTLMHeadModel', 'OPTForCausalLM', 'PegasusForCausalLM', 'PersimmonForCausalLM', 'PhiForCausalLM', 'PLBartForCausalLM', 'ProphetNetForCausalLM', 'QDQBertLMHeadModel', 'Qwen2ForCausalLM', 'ReformerModelWithLMHead', 'RemBertForCausalLM', 'RobertaForCausalLM', 'RobertaPreLayerNormForCausalLM', 'RoCBertForCausalLM', 'RoFormerForCausalLM', 'RwkvForCausalLM', 'Speech2Text2ForCausalLM', 'StableLmForCausalLM', 'TransfoXLLMHeadModel', 'TrOCRForCausalLM', 'WhisperForCausalLM', 'XGLMForCausalLM', 'XLMWithLMHeadModel', 'XLMProphetNetForCausalLM', 'XLMRobertaForCausalLM', 'XLMRobertaXLForCausalLM', 'XLNetLMHeadModel', 'XmodForCausalLM'].
---------------------------------------------------------------------------TypeError Traceback (most recent call last)Cell In[23], line 31 from transformers import pipeline----> 3 pipeline("text-generation", model=model, tokenizer=tokenizer)("Me encanta aprender de")File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/pipelines/text_generation.py:241, in TextGenerationPipeline.__call__(self, text_inputs, **kwargs)239 return super().__call__(chats, **kwargs)240 else:--> 241 return super().__call__(text_inputs, **kwargs)File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/pipelines/base.py:1196, in Pipeline.__call__(self, inputs, num_workers, batch_size, *args, **kwargs)1188 return next(1189 iter(1190 self.get_iterator((...)1193 )1194 )1195 else:-> 1196 return self.run_single(inputs, preprocess_params, forward_params, postprocess_params)File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/pipelines/base.py:1203, in Pipeline.run_single(self, inputs, preprocess_params, forward_params, postprocess_params)1201 def run_single(self, inputs, preprocess_params, forward_params, postprocess_params):1202 model_inputs = self.preprocess(inputs, **preprocess_params)-> 1203 model_outputs = self.forward(model_inputs, **forward_params)1204 outputs = self.postprocess(model_outputs, **postprocess_params)1205 return outputsFile ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/pipelines/base.py:1102, in Pipeline.forward(self, model_inputs, **forward_params)1100 with inference_context():1101 model_inputs = self._ensure_tensor_on_device(model_inputs, device=self.device)-> 1102 model_outputs = self._forward(model_inputs, **forward_params)1103 model_outputs = self._ensure_tensor_on_device(model_outputs, device=torch.device("cpu"))1104 else:File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/pipelines/text_generation.py:328, in TextGenerationPipeline._forward(self, model_inputs, **generate_kwargs)325 generate_kwargs["min_length"] += prefix_length327 # BS x SL--> 328 generated_sequence = self.model.generate(input_ids=input_ids, attention_mask=attention_mask, **generate_kwargs)329 out_b = generated_sequence.shape[0]330 if self.framework == "pt":File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/torch/utils/_contextlib.py:115, in context_decorator.<locals>.decorate_context(*args, **kwargs)112 @functools.wraps(func)113 def decorate_context(*args, **kwargs):114 with ctx_factory():--> 115 return func(*args, **kwargs)File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/generation/utils.py:1323, in GenerationMixin.generate(self, inputs, generation_config, logits_processor, stopping_criteria, prefix_allowed_tokens_fn, synced_gpus, assistant_model, streamer, negative_prompt_ids, negative_prompt_attention_mask, **kwargs)1320 synced_gpus = False1322 # 1. Handle `generation_config` and kwargs that might update it, and validate the `.generate()` call-> 1323 self._validate_model_class()1325 # priority: `generation_config` argument > `model.generation_config` (the default generation config)1326 if generation_config is None:1327 # legacy: users may modify the model configuration to control generation. To trigger this legacy behavior,1328 # three conditions must be met1329 # 1) the generation config must have been created from the model config (`_from_model_config` field);1330 # 2) the generation config must have seen no modification since its creation (the hash is the same);1331 # 3) the user must have set generation parameters in the model config.File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/generation/utils.py:1110, in GenerationMixin._validate_model_class(self)1108 if generate_compatible_classes:1109 exception_message += f" Please use one of the following classes instead: {generate_compatible_classes}"-> 1110 raise TypeError(exception_message)TypeError: The current model class (GPT2Model) is not compatible with `.generate()`, as it doesn't have a language model head. Please use one of the following classes instead: {'GPT2LMHeadModel'}
Isso se deve ao fato de que, quando funcionava, usávamos
pipeline(task="text-generation", model="flax-community/gpt-2-spanish")Mas agora nós fizemos
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")
model = AutoModel.from_pretrained("flax-community/gpt-2-spanish")
pipeline("text-generation", model=model, tokenizer=tokenizer)No primeiro caso, usamos apenas pipeline e o nome do modelo e, abaixo dele, estávamos procurando a melhor maneira de implementar o modelo e o tokenizador. Mas, no segundo caso, criamos o tokenizador e o modelo e o passamos para pipeline, mas não o criamos de acordo com as necessidades de pipeline.
Para corrigir isso, usamos o AutoModelFor.
Modelo AutoModelFor.
A biblioteca de transformadores nos dá a oportunidade de criar um modelo para uma determinada tarefa, como
AutoModelForCausalLM, que é usado para continuar os textos- AutoModelForMaskedLM` usado para preencher lacunas
AutoModelForMaskGeneration, que é usado para gerar máscaras- AutoModelForSeq2SeqLM, que é usado para converter de sequências em sequências, por exemplo, na tradução.
AutoModelForSequenceClassificationpara classificação de texto- AutoModelForMultipleChoice` para múltipla escolha
AutoModelForNextSentencePredictionpara prever se duas frases são consecutivasAutoModelForTokenClassificationpara classificação de tokens- AutoModelForQuestionAnswering` para perguntas e respostas
AutoModelForTextEncodingpara codificação de texto
Vamos usar o modelo acima para gerar texto
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMfrom transformers import pipelinetokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish")pipeline("text-generation", model=model, tokenizer=tokenizer)("Me encanta aprender de")[0]['generated_text']Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
'Me encanta aprender de mi familia. La verdad no sabía que se necesitaba tanto en este pequeño restaurante ya que mi novio en un principio había ido, pero hoy me ha entrado un gusanillo entre pecho y espalda que'
Agora funciona, porque criamos o modelo de uma forma que o pipeline pode entender.
Inferência somente com AutoClass.
Anteriormente, criamos o modelo e o tokenizador e o fornecemos ao pipeline para fazer o necessário, mas podemos usar os métodos de inferência por conta própria.
Geração de texto casual
Criamos o modelo e o tokenizador
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)Copied
Com device_map, carregamos o modelo na GPU 0.
Agora temos que fazer o que o pipeline costumava fazer.
Primeiro, geramos os tokens
InputPythontokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")Copied
---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[2], line 1----> 1 tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:2829, in PreTrainedTokenizerBase.__call__(self, text, text_pair, text_target, text_pair_target, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)2827 if not self._in_target_context_manager:2828 self._switch_to_input_mode()-> 2829 encodings = self._call_one(text=text, text_pair=text_pair, **all_kwargs)2830 if text_target is not None:2831 self._switch_to_target_mode()File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:2915, in PreTrainedTokenizerBase._call_one(self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)2910 raise ValueError(2911 f"batch length of `text`: {len(text)} does not match batch length of `text_pair`:"2912 f" {len(text_pair)}."2913 )2914 batch_text_or_text_pairs = list(zip(text, text_pair)) if text_pair is not None else text-> 2915 return self.batch_encode_plus(2916 batch_text_or_text_pairs=batch_text_or_text_pairs,2917 add_special_tokens=add_special_tokens,2918 padding=padding,2919 truncation=truncation,2920 max_length=max_length,2921 stride=stride,2922 is_split_into_words=is_split_into_words,2923 pad_to_multiple_of=pad_to_multiple_of,2924 return_tensors=return_tensors,2925 return_token_type_ids=return_token_type_ids,2926 return_attention_mask=return_attention_mask,2927 return_overflowing_tokens=return_overflowing_tokens,2928 return_special_tokens_mask=return_special_tokens_mask,2929 return_offsets_mapping=return_offsets_mapping,2930 return_length=return_length,2931 verbose=verbose,2932 **kwargs,2933 )2934 else:2935 return self.encode_plus(2936 text=text,2937 text_pair=text_pair,(...)2953 **kwargs,2954 )File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:3097, in PreTrainedTokenizerBase.batch_encode_plus(self, batch_text_or_text_pairs, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)3080 """3081 Tokenize and prepare for the model a list of sequences or a list of pairs of sequences.3082(...)3093 details in `encode_plus`).3094 """3096 # Backward compatibility for 'truncation_strategy', 'pad_to_max_length'-> 3097 padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(3098 padding=padding,3099 truncation=truncation,3100 max_length=max_length,3101 pad_to_multiple_of=pad_to_multiple_of,3102 verbose=verbose,3103 **kwargs,3104 )3106 return self._batch_encode_plus(3107 batch_text_or_text_pairs=batch_text_or_text_pairs,3108 add_special_tokens=add_special_tokens,(...)3123 **kwargs,3124 )File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:2734, in PreTrainedTokenizerBase._get_padding_truncation_strategies(self, padding, truncation, max_length, pad_to_multiple_of, verbose, **kwargs)2732 # Test if we have a padding token2733 if padding_strategy != PaddingStrategy.DO_NOT_PAD and (self.pad_token is None or self.pad_token_id < 0):-> 2734 raise ValueError(2735 "Asking to pad but the tokenizer does not have a padding token. "2736 "Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` "2737 "or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`."2738 )2740 # Check that we will truncate to a multiple of pad_to_multiple_of if both are provided2741 if (2742 truncation_strategy != TruncationStrategy.DO_NOT_TRUNCATE2743 and padding_strategy != PaddingStrategy.DO_NOT_PAD(...)2746 and (max_length % pad_to_multiple_of != 0)2747 ):ValueError: Asking to pad but the tokenizer does not have a padding token. Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`.
Vemos que ele nos deu um erro, informando que o tokenizador não tem um token de preenchimento. A maioria dos LLMs não tem um token de preenchimento, mas para usar a biblioteca transformers você precisa de um token de preenchimento, então o que você normalmente faz é atribuir o token de fim de frase ao token de preenchimento.
InputPythontokenizer.pad_token = tokenizer.eos_tokenCopied
Agora podemos gerar os tokens
InputPythontokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_input.input_idsCopied
tensor([[2879, 4835, 3760, 225, 72, 73]], device='cuda:0')
Agora, nós os passamos para o modelo que gerará novos tokens e, para isso, usamos o método generate.
InputPythontokens_output = model.generate(**tokens_input, max_length=50)print(f"input tokens: {tokens_input.input_ids}")print(f"output tokens: {tokens_output}")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
input tokens: tensor([[2879, 4835, 3760, 225, 72, 73]], device='cuda:0')output tokens: tensor([[ 2879, 4835, 3760, 225, 72, 73, 314, 2533, 16, 287,225, 73, 82, 513, 1086, 225, 72, 73, 314, 288,357, 15550, 16, 287, 225, 73, 87, 288, 225, 73,82, 291, 3500, 16, 225, 73, 87, 348, 929, 225,72, 73, 3760, 225, 72, 73, 314, 2533, 18, 203]],device='cuda:0')
Podemos ver que os primeiros tokens token_inputs são iguais aos tokens token_outputs; os tokens a seguir são os gerados pelo modelo
Agora temos que converter esses tokens em uma frase usando o decodificador do tokenizador.
InputPythonsentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)sentence_outputCopied
'Me encanta aprender de los demás, y en este caso de los que me rodean, y es que en el fondo, es una forma de aprender de los demás. '
Já temos o texto gerado
Classificação do texto
Criamos o modelo e o tokenizador
InputPythonimport torchfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationtokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")model = AutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model", device_map=0)Copied
Geramos os tokens
InputPythontext = "This was a masterpiece. Not completely faithful to the books, but enthralling from beginning to end. Might be my favorite of the three."inputs = tokenizer(text, return_tensors="pt").to("cuda")Copied
Quando tivermos os tokens, classificaremos
InputPythonwith torch.no_grad():logits = model(**inputs).logitspredicted_class_id = logits.argmax().item()prediction = model.config.id2label[predicted_class_id]predictionCopied
'LABEL_1'
Vamos dar uma olhada nas classes
InputPythonclases = model.config.id2labelclasesCopied
{0: 'LABEL_0', 1: 'LABEL_1'}
Dessa forma, ninguém pode descobrir, então nós o modificamos.
InputPythonmodel.config.id2label = {0: "NEGATIVE", 1: "POSITIVE"}Copied
E agora estamos de volta à classificação
InputPythonwith torch.no_grad():logits = model(**inputs).logitspredicted_class_id = logits.argmax().item()prediction = model.config.id2label[predicted_class_id]predictionCopied
'POSITIVE'
Classificação de tokens
Criamos o modelo e o tokenizador
InputPythonimport torchfrom transformers import AutoTokenizer, AutoModelForTokenClassificationtokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model", device_map=0)Copied
Geramos os tokens
InputPythontext = "The Golden State Warriors are an American professional basketball team based in San Francisco."inputs = tokenizer(text, return_tensors="pt").to("cuda")Copied
Quando tivermos os tokens, classificaremos
InputPythonwith torch.no_grad():logits = model(**inputs).logitspredictions = torch.argmax(logits, dim=2)predicted_token_class = [model.config.id2label[t.item()] for t in predictions[0]]for i in range(len(inputs.input_ids[0])):print(f"{inputs.input_ids[0][i]} ({tokenizer.decode([inputs.input_ids[0][i]])}) -> {predicted_token_class[i]}")Copied
101 ([CLS]) -> O1996 (the) -> O3585 (golden) -> B-location2110 (state) -> I-location6424 (warriors) -> B-group2024 (are) -> O2019 (an) -> O2137 (american) -> O2658 (professional) -> O3455 (basketball) -> O2136 (team) -> O2241 (based) -> O1999 (in) -> O2624 (san) -> B-location3799 (francisco) -> B-location1012 (.) -> O102 ([SEP]) -> O
Como você pode ver, os tokens correspondentes a golden, state, warriors, san e francisco foram classificados como tokens de localização.
Resposta à pergunta
Criamos o modelo e o tokenizador
InputPythonimport torchfrom transformers import AutoTokenizer, AutoModelForQuestionAnsweringtokenizer = AutoTokenizer.from_pretrained("mrm8488/roberta-base-1B-1-finetuned-squadv1")model = AutoModelForQuestionAnswering.from_pretrained("mrm8488/roberta-base-1B-1-finetuned-squadv1", device_map=0)Copied
Some weights of the model checkpoint at mrm8488/roberta-base-1B-1-finetuned-squadv1 were not used when initializing RobertaForQuestionAnswering: ['roberta.pooler.dense.bias', 'roberta.pooler.dense.weight']- This IS expected if you are initializing RobertaForQuestionAnswering from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).- This IS NOT expected if you are initializing RobertaForQuestionAnswering from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Geramos os tokens
InputPythonquestion = "How many programming languages does BLOOM support?"context = "BLOOM has 176 billion parameters and can generate text in 46 languages natural languages and 13 programming languages."inputs = tokenizer(question, context, return_tensors="pt").to("cuda")Copied
Quando tivermos os tokens, classificaremos
InputPythonwith torch.no_grad():outputs = model(**inputs)answer_start_index = outputs.start_logits.argmax()answer_end_index = outputs.end_logits.argmax()predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]tokenizer.decode(predict_answer_tokens)Copied
' 13'
Modelagem de linguagem com máscara (Modelagem de linguagem com máscara)
Criamos o modelo e o tokenizador
InputPythonimport torchfrom transformers import AutoTokenizer, AutoModelForMaskedLMtokenizer = AutoTokenizer.from_pretrained("nyu-mll/roberta-base-1B-1")model = AutoModelForMaskedLM.from_pretrained("nyu-mll/roberta-base-1B-1", device_map=0)Copied
Some weights of the model checkpoint at nyu-mll/roberta-base-1B-1 were not used when initializing RobertaForMaskedLM: ['roberta.pooler.dense.bias', 'roberta.pooler.dense.weight']- This IS expected if you are initializing RobertaForMaskedLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).- This IS NOT expected if you are initializing RobertaForMaskedLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Geramos os tokens
InputPythontext = "The Milky Way is a <mask> galaxy."inputs = tokenizer(text, return_tensors="pt").to("cuda")mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]Copied
Quando tivermos os tokens, classificaremos
InputPythonwith torch.no_grad():logits = model(**inputs).logitsmask_token_logits = logits[0, mask_token_index, :]top_3_tokens = torch.topk(mask_token_logits, 3, dim=1).indices[0].tolist()for token in top_3_tokens:print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))Copied
The Milky Way is a spiral galaxy.The Milky Way is a closed galaxy.The Milky Way is a distant galaxy.
Personalização do modelo
Anteriormente, fizemos a inferência com o AutoClass, mas fizemos isso com as configurações padrão do modelo. Mas podemos configurar o modelo como quisermos.
Vamos instanciar um modelo e dar uma olhada em sua configuração
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfigtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)config = AutoConfig.from_pretrained("flax-community/gpt-2-spanish")configCopied
GPT2Config {"_name_or_path": "flax-community/gpt-2-spanish","activation_function": "gelu_new","architectures": ["GPT2LMHeadModel"],"attn_pdrop": 0.0,"bos_token_id": 50256,"embd_pdrop": 0.0,"eos_token_id": 50256,"gradient_checkpointing": false,"initializer_range": 0.02,"layer_norm_epsilon": 1e-05,"model_type": "gpt2","n_ctx": 1024,"n_embd": 768,"n_head": 12,"n_inner": null,"n_layer": 12,"n_positions": 1024,"reorder_and_upcast_attn": false,"resid_pdrop": 0.0,"scale_attn_by_inverse_layer_idx": false,"scale_attn_weights": true,"summary_activation": null,"summary_first_dropout": 0.1,"summary_proj_to_labels": true,"summary_type": "cls_index","summary_use_proj": true,"task_specific_params": {"text-generation": {"do_sample": true,"max_length": 50}},"transformers_version": "4.38.1","use_cache": true,"vocab_size": 50257}
Podemos ver a configuração do modelo, por exemplo, a função de ativação é gelu_new, ele tem 12 heads`, o tamanho do vocabulário é 50257 palavras etc.
Mas podemos modificar essa configuração
InputPythonconfig = AutoConfig.from_pretrained("flax-community/gpt-2-spanish", activation_function="relu")config.activation_functionCopied
'relu'
Agora, criamos o modelo com esta configuração
InputPythonmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", config=config, device_map=0)Copied
E geramos o texto
InputPythontokenizer.pad_token = tokenizer.eos_tokentokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_length=50)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)sentence_outputCopied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
'Me encanta aprender de la d d e d e d e d e d e d e d e d e d e d e '
Vemos que essa modificação não gera um texto tão bom.
Tokenização
Até agora, vimos as diferentes maneiras de fazer inferência com a biblioteca transformers. Agora, vamos nos aprofundar nas entranhas da biblioteca. Para isso, primeiro veremos o que devemos ter em mente ao fazer tokenização.
Não vamos explicar detalhadamente o que é tokenização, pois já explicamos isso na postagem sobre a biblioteca [tokenizers] (https://www.maximofn.com/hugging-face-tokenizers/).
Preenchimento
Quando você tem um lote de sequências, às vezes é necessário que, após a tokenização, todas as sequências tenham o mesmo comprimento, portanto, usamos o parâmetro padding=True para isso.
InputPythonfrom transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish", pad_token="PAD")encoded_input = tokenizer(batch_sentences, padding=True)for encoded in encoded_input["input_ids"]:print(encoded)print(f"Padding token id: {tokenizer.pad_token_id}")Copied
[2959, 16, 875, 3736, 3028, 303, 291, 2200, 8080, 35, 50257, 50257][1489, 2275, 288, 12052, 382, 325, 2200, 8080, 16, 4319, 50257, 50257][1699, 2899, 707, 225, 72, 73, 314, 34630, 474, 515, 1259, 35]Padding token id: 50257
Como podemos ver, ele adicionou paddings às duas primeiras sequências no final.
Truncado
Além de adicionar preenchimento, às vezes é necessário truncar as sequências para que elas não ocupem mais do que um determinado número de tokens. Para fazer isso, definimos truncation=True e max_length como o número de tokens que queremos que a sequência tenha.
InputPythonfrom transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")encoded_input = tokenizer(batch_sentences, truncation=True, max_length=5)for encoded in encoded_input["input_ids"]:print(encoded)Copied
[2959, 16, 875, 3736, 3028][1489, 2275, 288, 12052, 382][1699, 2899, 707, 225, 72]
As mesmas frases de antes agora geram menos tokens.
Tensionadores
Até agora, temos recebido listas de tokens, mas provavelmente estamos interessados em receber tensores do PyTorch ou do TensorFlow. Para fazer isso, usamos o parâmetro return_tensors e especificamos de qual estrutura queremos receber o tensor; em nosso caso, escolheremos o PyTorch com pt.
Primeiro, vemos que, sem especificar que retornamos tensores
InputPythonfrom transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish", pad_token="PAD")encoded_input = tokenizer(batch_sentences, padding=True)for encoded in encoded_input["input_ids"]:print(type(encoded))Copied
<class 'list'><class 'list'><class 'list'>
Recebemos listas; se quisermos receber tensores do PyTorch, usaremos return_tensors="pt".
InputPythonfrom transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish", pad_token="PAD")encoded_input = tokenizer(batch_sentences, padding=True, return_tensors="pt")for encoded in encoded_input["input_ids"]:print(type(encoded), encoded.shape)print(type(encoded_input["input_ids"]), encoded_input["input_ids"].shape)Copied
<class 'torch.Tensor'> torch.Size([12])<class 'torch.Tensor'> torch.Size([12])<class 'torch.Tensor'> torch.Size([12])<class 'torch.Tensor'> torch.Size([3, 12])
Máscaras
Quando tokenizamos uma declaração, obtemos não apenas os input_ids, mas também a máscara de atenção. A máscara de atenção é um tensor que tem o mesmo tamanho de input_ids e tem um 1 nas posições que são tokens e um 0 nas posições que são padding.
InputPythonfrom transformers import AutoTokenizerbatch_sentences = ["Pero, ¿qué pasa con el segundo desayuno?","No creo que sepa lo del segundo desayuno, Pedro","¿Qué hay de los elevensies?",]tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish", pad_token="PAD")encoded_input = tokenizer(batch_sentences, padding=True)print(f"padding token id: {tokenizer.pad_token_id}")print(f" encoded_input[0] inputs_ids: {encoded_input['input_ids'][0]}")print(f"encoded_input[0] attention_mask: {encoded_input['attention_mask'][0]}")print(f" encoded_input[1] inputs_ids: {encoded_input['input_ids'][1]}")print(f"encoded_input[1] attention_mask: {encoded_input['attention_mask'][1]}")print(f" encoded_input[2] inputs_ids: {encoded_input['input_ids'][2]}")print(f"encoded_input[2] attention_mask: {encoded_input['attention_mask'][2]}")Copied
padding token id: 50257encoded_input[0] inputs_ids: [2959, 16, 875, 3736, 3028, 303, 291, 2200, 8080, 35, 50257, 50257]encoded_input[0] attention_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]encoded_input[1] inputs_ids: [1489, 2275, 288, 12052, 382, 325, 2200, 8080, 16, 4319, 50257, 50257]encoded_input[1] attention_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]encoded_input[2] inputs_ids: [1699, 2899, 707, 225, 72, 73, 314, 34630, 474, 515, 1259, 35]encoded_input[2] attention_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
Como você pode ver, nas duas primeiras frases, temos um 1 nas duas primeiras posições e um 0 nas duas últimas posições. Nessas mesmas posições, temos o token 50257, que corresponde ao token de preenchimento.
Com essas máscaras de atenção, estamos informando ao modelo em quais tokens devemos prestar atenção e em quais não devemos prestar atenção.
A geração de texto ainda poderia ser feita se não passássemos essas máscaras de atenção, o método generate faria o possível para inferir essa máscara, mas se a passarmos, ajudaremos a gerar um texto melhor.
Tokenizadores rápidos
Alguns tokenizadores pré-treinados têm uma versão "rápida", com os mesmos métodos que os tokenizadores normais, mas são desenvolvidos em Rust. Para utilizá-los, devemos usar a classe PreTrainedTokenizerFast da biblioteca transformers.
Vamos primeiro analisar o tempo de tokenização com um tokenizador normal.
InputPython%%timefrom transformers import BertTokenizertokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")sentence = ("The Permaculture Design Principles are a set of universal design principles ""that can be applied to any location, climate and culture, and they allow us to design ""the most efficient and sustainable human habitation and food production systems. ""Permaculture is a design system that encompasses a wide variety of disciplines, such ""as ecology, landscape design, environmental science and energy conservation, and the ""Permaculture design principles are drawn from these various disciplines. Each individual ""design principle itself embodies a complete conceptual framework based on sound ""scientific principles. When we bring all these separate principles together, we can ""create a design system that both looks at whole systems, the parts that these systems ""consist of, and how those parts interact with each other to create a complex, dynamic, ""living system. Each design principle serves as a tool that allows us to integrate all ""the separate parts of a design, referred to as elements, into a functional, synergistic, ""whole system, where the elements harmoniously interact and work together in the most ""efficient way possible.")tokens = tokenizer([sentence], padding=True, return_tensors="pt")Copied
CPU times: user 55.3 ms, sys: 8.58 ms, total: 63.9 msWall time: 226 ms
E agora uma rápida
InputPython%%timefrom transformers import BertTokenizerFasttokenizer = BertTokenizerFast.from_pretrained("google-bert/bert-base-uncased")sentence = ("The Permaculture Design Principles are a set of universal design principles ""that can be applied to any location, climate and culture, and they allow us to design ""the most efficient and sustainable human habitation and food production systems. ""Permaculture is a design system that encompasses a wide variety of disciplines, such ""as ecology, landscape design, environmental science and energy conservation, and the ""Permaculture design principles are drawn from these various disciplines. Each individual ""design principle itself embodies a complete conceptual framework based on sound ""scientific principles. When we bring all these separate principles together, we can ""create a design system that both looks at whole systems, the parts that these systems ""consist of, and how those parts interact with each other to create a complex, dynamic, ""living system. Each design principle serves as a tool that allows us to integrate all ""the separate parts of a design, referred to as elements, into a functional, synergistic, ""whole system, where the elements harmoniously interact and work together in the most ""efficient way possible.")tokens = tokenizer([sentence], padding=True, return_tensors="pt")Copied
CPU times: user 42.6 ms, sys: 3.26 ms, total: 45.8 msWall time: 179 ms
Você pode ver como o BertTokenizerFast é cerca de 40 ms mais rápido.
Formas de geração de texto
Continuando com as entranhas da biblioteca transformers, vamos agora examinar as maneiras de gerar texto.
A arquitetura do transformador gera o próximo token mais provável. Essa é a maneira mais simples de gerar texto, mas não é a única, portanto, vamos dar uma olhada nelas.
Quando se trata de gerar um texto, não há uma maneira melhor e isso dependerá do nosso modelo e da finalidade do uso.
Busca ambiciosa
Essa é a maneira mais simples de gerar texto. Encontre o token mais provável em cada iteração.
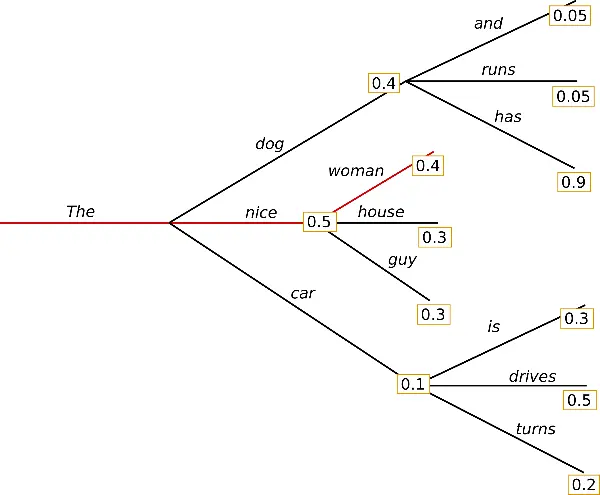
Para gerar texto dessa forma com transformers, você não precisa fazer nada de especial, pois essa é a forma padrão.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás, y en este caso de los que me rodean, y es que en el fondo, es una forma de aprender de los demás.En este caso, el objetivo de la actividad es que los niños aprendan a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños se han dado cuenta de que los animales que hay en el mundo, son muy difíciles de reconocer, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que en ocasiones, son muy difíciles de reconocer.En este caso, los niños han aprendido a reconocer los diferentes tipos de animales que existen en el mundo, y que e
Você pode ver que o texto gerado está bom, mas ele começa a se repetir. Isso ocorre porque, na pesquisa gananciosa, as palavras com alta probabilidade podem se esconder atrás de palavras com probabilidade mais baixa e, portanto, podem se perder.
Aqui, a palavra has tem uma alta probabilidade, mas está escondida atrás de dog, que tem uma probabilidade menor do que nice.
Pesquisa Contrastiva
O método Contrastive Search otimiza a geração de texto selecionando opções de palavras ou frases que maximizam um critério de qualidade em detrimento de outras menos desejáveis. Na prática, isso significa que, durante a geração do texto, em cada etapa, o modelo não só procura a próxima palavra com maior probabilidade de seguir o que foi aprendido durante o treinamento, mas também compara diferentes candidatos para essa próxima palavra e avalia qual deles contribuiria para formar o texto mais coerente, relevante e de alta qualidade no contexto em questão. Portanto, a pesquisa contrastiva reduz a possibilidade de gerar respostas irrelevantes ou de baixa qualidade, concentrando-se nas opções que melhor se adaptam ao objetivo de geração de texto, com base em uma comparação direta entre as possíveis continuações em cada etapa do processo.
Para gerar texto com pesquisa contrastiva em transformers, é necessário usar os parâmetros penalty_alpha e top_k ao gerar o texto.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, penalty_alpha=0.6, top_k=4)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás, es una de las cosas que más me gusta del mundo.En la clase de hoy he estado haciendo un repaso de lo que es el arte de la costura, para que podáis ver como se hace una prenda de ropa y como se confeccionan los patrones.El patrón de esta blusa es de mi amiga Marga, que me ha pedido que os enseñara a hacer este tipo de prendas, ya que es una de las cosas que más me gusta del mundo.La blusa es de la talla S, y tiene un largo de manga 3/4, por lo que es ideal para cualquier ocasión.Para hacer el patrón de esta blusa utilicé una tela de algodón 100% de color azul marino, que es la que yo he utilizado para hacer la blusa.En la parte delantera de la blusa, cosí un lazo de raso de color azul marino, que le da un toque de color a la prenda.Como podéis ver en la foto, el patrón de esta blusa es de la talla S, y tiene un largo de manga 3/4, por lo que es ideal para cualquier ocasión.Para hacer el patrón de esta blusa utilicé una tela de algodón 100% de color azul marino, que es la que yo he utilizado para hacer la blusa.En la parte delantera de la blusa utilicé un lazo de raso de color azul marino, que le da un toque de color a la prenda.Para hacer el patrón de esta blusa utilicé una tela de algodón 100% de color azul marino, que es la que yo he utilizado para hacer la blusa.En la parte delantera de la blusa utilicé un lazo de raso de color azul marino, que le da un toque de color a la prenda.Para hacer el patrón de esta blusa utilicé una tela de algodón 100% de color azul marino, que es la que yo he utilizado para hacer la blusa.En la parte delantera de la blusa utilicé
Aqui o padrão leva mais tempo para começar a se repetir.
Amostragem multinomial
Diferentemente da pesquisa gulosa, que sempre escolhe um token com a maior probabilidade como o próximo token, a amostragem multinomial (também chamada de amostragem ancestral) seleciona aleatoriamente o próximo token com base na distribuição de probabilidade de todo o vocabulário fornecido pelo modelo. Cada token com uma probabilidade diferente de zero tem uma chance de ser selecionado, o que reduz o risco de repetição.
Para ativar a Amostragem multinomial, defina do_sample=True e num_beams=1.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, num_beams=1)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los de siempre y conocer a gente nueva, soy de las que no tiene mucho contacto con los de antes, pero he estado bastante liada con el diseño de mi página web de lo que sería el logo, he escrito varios diseños para otros blogs y cosas así, así que a ver si pronto puedo poner de mi parte alguna ayuda.A finales de los años 70 del pasado siglo los arquitectos alemanes Hermann Grossberg y Heinrich Rindsner eran los principales representantes de la arquitectura industrial de la alta sociedad. La arquitectura industrial era la actividad que más rápido progresaba en el diseño, y de ellos destacaban los diseños que Grossberg llevó a cabo en el prestigioso Hotel Marigal.De acuerdo con las conclusiones y opiniones expuestas por los autores sobre el reciente congreso sobre historia del diseño industrial, se ha llegado al convencimiento de que en los últimos años, los diseñadores industriales han descubierto muchas nuevas formas de entender la arquitectura. En palabras de Klaus Eindhoven, director general de la fundación alemana G. Grossberg, “estamos tratando de desarrollar un trabajo que tenga en cuenta los criterios más significativos de la teoría arquitectónica tradicional”.En este artículo de opinión, Eindhoven y Grossberg explican por qué el auge de la arquitectura industrial en Alemania ha generado una gran cantidad de nuevos diseños de viviendas, de grandes dimensiones, de edificios de gran valor arquitectónico. Los más conocidos son los de los diseñadores Walter Nachtmann (1934) e ingeniero industrial, Frank Gehry (1929), arquitecto que ideó las primeras viviendas de estilo neoclásico en la localidad británica de Stegmarbe. Son viviendas de los siglos XVI al XX, algunas con un estilo clasicista que recuerda las casas de Venecia. Se trata de edificios con un importante valor histórico y arquitectónico, y que representan la obra de la técnica del modernismo.La teoría general sobre los efectos de la arquitectura en un determinado tipo de espacio no ha resultado ser totalmente transparente, y mucho menos para los arquitectos, que tienen que aprender de los arquitectos de ayer, durante esos
A verdade é que o modelo não se repete, mas me sinto como se estivesse conversando com uma criança pequena, que fala sobre um assunto e depois começa a falar de outros que não têm nada a ver com ele.
Pesquisa de feixe
A pesquisa de feixes reduz o risco de perder sequências de palavras ocultas de alta probabilidade, mantendo o num_beams mais provável em cada etapa de tempo e, finalmente, escolhendo a hipótese com a maior probabilidade geral.
Para gerar com beam search, é necessário adicionar o parâmetro num_beams.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de los míos.Me encanta aprender de los errores y aprender de los aciertos de los demás, en este caso, de
Ele se repete muito
Amostragem multinomial de busca de feixe
Essa técnica combina pesquisa de feixe e amostragem multinomial, em que o próximo token é selecionado aleatoriamente com base na distribuição de probabilidade de todo o vocabulário fornecido pelo modelo.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, do_sample=True)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y en especial de mis compañeros de trabajo. Me encanta aprender de los demás, en especial de las personas que me rodean, y e
Ele se repete muito
Penalidade de n-gramas de pesquisa de feixe
Para evitar a repetição, podemos penalizar a repetição de n-gramas. Para fazer isso, usamos o parâmetro no_repeat_ngram_size.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, no_repeat_ngram_size=2)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás, y en este caso, no podía ser menos, así que me puse manos a la obra.En primer lugar, me hice con un libro que se llama "El mundo eslavo" y que, como ya os he dicho, se puede adquirir por un módico precio (unos 5 euros).El libro está compuesto por dos partes: la primera, que trata sobre la historia del Imperio Romano y la segunda, sobre el Imperio Bizantino. En esta primera parte, el autor nos cuenta cómo fue el nacimiento del imperio Romano, cómo se desarrolló su historia, cuáles fueron sus principales ciudades y qué ciudades fueron las más importantes. Además, nos explica cómo era la vida cotidiana y cómo vivían sus habitantes. Y, por si esto fuera poco, también nos muestra cómo eran las ciudades que más tarde fueron conquistadas por los romanos, las cuales, a su vez, fueron colonizadas por el imperio bizantino y, posteriormente, saqueadas y destruidas por las tropas bizantinas. Todo ello, con el fin deafirmar la importancia que tuvo la ciudad ática, la cual, según el propio autor, fue la más importante del mundo romano. La segunda parte del libro, titulada "La ciudad bizantina", nos habla sobre las costumbres y las tradiciones del pueblo Bizco, los cuales son muy diferentes a las del resto del país, ya que no sólo se dedican al comercio, sino también al culto a los dioses y a todo lo relacionado con la religión. Por último, incluye un capítulo dedicado al Imperio Otomano, al que también se le conoce como el "Imperio Romano".Por otro lado, os dejo un enlace a una página web donde podréis encontrar más información sobre este libro: http://www.elmundodeuterio.com/es/libros/el-mundo-sucio-y-la-historia-del-imperio-ibero-italia/Como podéis ver, he querido hacer un pequeño homenaje a todas las personas que han hecho posible que el libro se haya hecho realidad. Espero que os haya gustado y os animéis a adquirirlo. Si tenéis alguna duda, podéis dejarme un comentario o escribirme un correo a mi correo electrónico: [email protected]¡Hola a todos! ¿Qué tal estáis? Hoy os traigo una entrada muy especial. Se trata del sorteo que he hecho para celebrar el día del padre. Como ya sabéis, este año no he tenido mucho tiempo, pero
Esse texto não se repete mais e também tem um pouco mais de coerência.
Entretanto, as penalidades de n-gramas devem ser usadas com cuidado. Um artigo gerado sobre a cidade de Nova York não deve usar uma penalidade de 2 gramas, caso contrário, o nome da cidade apareceria apenas uma vez em todo o texto!
Sequências de retorno de penalidade de pesquisa de feixe de n-gramas
Podemos gerar várias sequências para compará-las e manter a melhor. Para isso, usamos o parâmetro num_return_sequences com a condição de que num_return_sequences <= num_beams.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_outputs = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, no_repeat_ngram_size=2, num_return_sequences=3)for i, tokens_output in enumerate(tokens_outputs):if i != 0:print(" ")sentence_output = tokenizer.decode(tokens_output, skip_special_tokens=True)print(f"{i}: {sentence_output}")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
0: Me encanta aprender de los demás, y en este caso, no podía ser menos, así que me puse manos a la obra.En primer lugar, me hice con un libro que se llama "El mundo eslavo" y que, como ya os he dicho, se puede adquirir por un módico precio (unos 5 euros).El libro está compuesto por dos partes: la primera, que trata sobre la historia del Imperio Romano y la segunda, sobre el Imperio Bizantino. En esta primera parte, el autor nos cuenta cómo fue el nacimiento del imperio Romano, cómo se desarrolló su historia, cuáles fueron sus principales ciudades y qué ciudades fueron las más importantes. Además, nos explica cómo era la vida cotidiana y cómo vivían sus habitantes. Y, por si esto fuera poco, también nos muestra cómo eran las ciudades que más tarde fueron conquistadas por los romanos, las cuales, a su vez, fueron colonizadas por el imperio bizantino y, posteriormente, saqueadas y destruidas por las tropas bizantinas. Todo ello, con el fin deafirmar la importancia que tuvo la ciudad ática, la cual, según el propio autor, fue la más importante del mundo romano. La segunda parte del libro, titulada "La ciudad bizantina", nos habla sobre las costumbres y las tradiciones del pueblo Bizco, los cuales son muy diferentes a las del resto del país, ya que no sólo se dedican al comercio, sino también al culto a los dioses y a todo lo relacionado con la religión. Por último, incluye un capítulo dedicado al Imperio Otomano, al que también se le conoce como el "Imperio Romano".Por otro lado, os dejo un enlace a una página web donde podréis encontrar más información sobre este libro: http://www.elmundodeuterio.com/es/libros/el-mundo-sucio-y-la-historia-del-imperio-ibero-italia/Como podéis ver, he querido hacer un pequeño homenaje a todas las personas que han hecho posible que el libro se haya hecho realidad. Espero que os haya gustado y os animéis a adquirirlo. Si tenéis alguna duda, podéis dejarme un comentario o escribirme un correo a mi correo electrónico: [email protected]¡Hola a todos! ¿Qué tal estáis? Hoy os traigo una entrada muy especial. Se trata del sorteo que he hecho para celebrar el día del padre. Como ya sabéis, este año no he tenido mucho tiempo, pero1: Me encanta aprender de los demás, y en este caso, no podía ser menos, así que me puse manos a la obra.En primer lugar, me hice con un libro que se llama "El mundo eslavo" y que, como ya os he dicho, se puede adquirir por un módico precio (unos 5 euros).El libro está compuesto por dos partes: la primera, que trata sobre la historia del Imperio Romano y la segunda, sobre el Imperio Bizantino. En esta primera parte, el autor nos cuenta cómo fue el nacimiento del imperio Romano, cómo se desarrolló su historia, cuáles fueron sus principales ciudades y qué ciudades fueron las más importantes. Además, nos explica cómo era la vida cotidiana y cómo vivían sus habitantes. Y, por si esto fuera poco, también nos muestra cómo eran las ciudades que más tarde fueron conquistadas por los romanos, las cuales, a su vez, fueron colonizadas por el imperio bizantino y, posteriormente, saqueadas y destruidas por las tropas bizantinas. Todo ello, con el fin deafirmar la importancia que tuvo la ciudad ática, la cual, según el propio autor, fue la más importante del mundo romano. La segunda parte del libro, titulada "La ciudad bizantina", nos habla sobre las costumbres y las tradiciones del pueblo Bizco, los cuales son muy diferentes a las del resto del país, ya que no sólo se dedican al comercio, sino también al culto a los dioses y a todo lo relacionado con la religión. Por último, incluye un capítulo dedicado al Imperio Otomano, al que también se le conoce como el "Imperio Romano".Por otro lado, os dejo un enlace a una página web donde podréis encontrar más información sobre este libro: http://www.elmundodeuterio.com/es/libros/el-mundo-sucio-y-la-historia-del-imperio-ibero-italia/Como podéis ver, he querido hacer un pequeño homenaje a todas las personas que han hecho posible que el libro se haya hecho realidad. Espero que os haya gustado y os animéis a adquirirlo. Si tenéis alguna duda, podéis dejarme un comentario o escribirme un correo a mi correo electrónico: [email protected]¡Hola a todos! ¿Qué tal estáis? Hoy os traigo una entrada muy especial. Se trata del sorteo que he hecho para celebrar el día del padre. Como ya sabéis, este año no he tenido mucho tiempo para hacer2: Me encanta aprender de los demás, y en este caso, no podía ser menos, así que me puse manos a la obra.En primer lugar, me hice con un libro que se llama "El mundo eslavo" y que, como ya os he dicho, se puede adquirir por un módico precio (unos 5 euros).El libro está compuesto por dos partes: la primera, que trata sobre la historia del Imperio Romano y la segunda, sobre el Imperio Bizantino. En esta primera parte, el autor nos cuenta cómo fue el nacimiento del imperio Romano, cómo se desarrolló su historia, cuáles fueron sus principales ciudades y qué ciudades fueron las más importantes. Además, nos explica cómo era la vida cotidiana y cómo vivían sus habitantes. Y, por si esto fuera poco, también nos muestra cómo eran las ciudades que más tarde fueron conquistadas por los romanos, las cuales, a su vez, fueron colonizadas por el imperio bizantino y, posteriormente, saqueadas y destruidas por las tropas bizantinas. Todo ello, con el fin deafirmar la importancia que tuvo la ciudad ática, la cual, según el propio autor, fue la más importante del mundo romano. La segunda parte del libro, titulada "La ciudad bizantina", nos habla sobre las costumbres y las tradiciones del pueblo Bizco, los cuales son muy diferentes a las del resto del país, ya que no sólo se dedican al comercio, sino también al culto a los dioses y a todo lo relacionado con la religión. Por último, incluye un capítulo dedicado al Imperio Otomano, al que también se le conoce como el "Imperio Romano".Por otro lado, os dejo un enlace a una página web donde podréis encontrar más información sobre este libro: http://www.elmundodeuterio.com/es/libros/el-mundo-sucio-y-la-historia-del-imperio-ibero-italia/Como podéis ver, he querido hacer un pequeño homenaje a todas las personas que han hecho posible que el libro se haya hecho realidad. Espero que os haya gustado y os animéis a adquirirlo. Si tenéis alguna duda, podéis dejarme un comentario o escribirme un correo a mi correo electrónico: [email protected]¡Hola a todos! ¿Qué tal estáis? Hoy os traigo una entrada muy especial. Se trata del sorteo que he hecho para celebrar el día del padre. Como ya sabéis, este año no he tenido mucho tiempo para publicar
Agora podemos manter a melhor sequência
Decodificação de busca de feixe diverso
A decodificação de busca de feixe diversificado é uma extensão da estratégia de busca de feixe que permite a geração de um conjunto mais diversificado de sequências de feixe para escolha.
Para gerar o texto dessa forma, precisamos usar os parâmetros num_beams, num_beam_groups e diversity_penalty.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, num_beams=5, num_beam_groups=5, diversity_penalty=1.0)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender de los aciertos. Me encanta aprender de los errores y aprender
Esse método parece se repetir com bastante frequência
Decodificação especulativa
A decodificação especulativa (também conhecida como decodificação assistida) é uma modificação das estratégias de decodificação acima, que usa um modelo assistente (idealmente muito menor) com o mesmo tokenizador, para gerar alguns tokens candidatos. Em seguida, o modelo principal valida os tokens candidatos em uma única etapa de avanço, o que acelera o processo de decodificação.
Para gerar texto dessa forma, é necessário usar o parâmetro do_sample=True.
No momento, a decodificação assistida só oferece suporte à pesquisa otimizada, e a decodificação assistida não oferece suporte à entrada em lote.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)assistant_model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, assistant_model=assistant_model, do_sample=True)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás! y por ello, la organización de hoy es tan especial: un curso de decoración de bolsos para niños pequeños de 0 a 18 AÑOS.En este taller aprenderemos a decorar bolsos para regalar, con los materiales que sean necesarios para cubrir las necesidades de estos peques, como pueden ser, un estuche con todo lo que necesiten, ropa interior, mantas, complementos textiles, complementos alimenticios, o un bonito neceser con todo lo que necesiten.Os dejo con un pequeño tutorial de decoración de bolsos para niños, realizado por mi amiga Rosa y sus amigas Silvia y Rosa, que se dedica a la creación de bolsos para bebés que son un verdadero tesoro para sus pequeños. Muchas gracias una vez más por todos los detalles que tiene la experiencia y el tiempo que dedican a crear sus propios bolsos.En muchas ocasiones, cuando se nos acerca una celebración, siempre nos preguntamos por qué, por qué en especial, por que se trata de algo que no tienen tan cerca nuestras vidas y, claro está, también por que nos hemos acostumbrado a vivir en el mundo de lo mundano y de lo comercial, tal y como los niños y niñas de hoy, a la manera de sus padres, donde todo es caro, todo es difícil, los precios no están al alcance de todos y, por estas y por muchas más preguntas por las que estamos deseando seguir escuchando, este curso y muchas otras cosas que os encontraréis a lo largo de la mañana de hoy, os van a dar la clave sobre la que empezar a preparar una fiesta de esta importancia.El objetivo del curso es que aprendáis a decorar bolsos para regalar con materiales sencillos, simples y de buena calidad; que os gusten y os sirvan de decoración y que por supuesto os sean útiles. Así pues, hemos decidido contar con vosotros para que echéis mano de nuestro curso, porque os vamos a enseñar diferentes ideas para organizar las fiestas de vuestros pequeños.Al tratarse de un curso muy básico, vais a encontrar ideas muy variadas, que van desde sencillas manualidades con los bolsillos, hasta mucho más elaboradas y que si lo veis con claridad en un tutorial os vais a poder dar una idea de cómo se ha de aplicar estos consejos a vuestra tienda.
Esse método tem resultados muito bons
Controle de aleatoriedade da decodificação especulativa
Ao usar a decodificação assistida com métodos de amostragem, o parâmetro temperature pode ser usado para controlar a aleatoriedade. Entretanto, na decodificação assistida, a redução da temperatura pode ajudar a melhorar a latência.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)assistant_model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, assistant_model=assistant_model, do_sample=True, temperature=0.5)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás y de las personas que nos rodean. Y no sólo eso, sino que además me gusta aprender de los demás. He aprendido mucho de los que me rodean y de las personas que me rodean.Me encanta conocer gente nueva, aprender de los demás y de las personas que me rodean. Y no sólo eso, sino que además me gusta aprender de los demás.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.Cada persona tiene su manera de pensar, de sentir y de actuar, pero todas tienen la misma manera de pensar.La mayoría de las personas, por diferentes motivos, se quieren llevar bien con otras personas, pero no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo de la vida hay muchas personas que se quieren llevar bien, pero que no saben como afrontar las situaciones que se les presentan.En el mundo
Aqui, ele não se saiu tão bem
Amostragem
É aqui que começam as técnicas usadas pelos LLMs atuais.
Em vez de selecionar sempre a palavra mais provável (o que poderia levar a textos previsíveis ou repetitivos), a amostragem introduz a aleatoriedade no processo de seleção, permitindo que o modelo explore uma variedade de palavras possíveis com base em suas probabilidades. É como lançar um dado ponderado para cada palavra. Assim, quanto maior a probabilidade de uma palavra, maior a probabilidade de ela ser selecionada, mas ainda há uma oportunidade para que palavras menos prováveis sejam escolhidas, enriquecendo a diversidade e a criatividade do texto gerado. Esse método ajuda a evitar respostas monótonas e aumenta a variabilidade e a naturalidade do texto produzido.
Como você pode ver na imagem, o primeiro token, que tem a maior probabilidade, foi repetido até 11 vezes, o segundo até 8 vezes, o terceiro até 4 vezes e o último foi adicionado apenas 1 vez. Dessa forma, ele é escolhido aleatoriamente entre todos eles, mas o resultado mais provável é o primeiro token, pois é o que aparece mais vezes
Para usar esse método, escolhemos do_sample=True e top_k=0.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás, conocer a los demás, entender las cosas, la gente y las relaciones? y eso ha sido siempre lo que me ha ocurrido con Zoë a lo largo de estos años. Siempre intenta ayudar en todo lo posible a los que lo necesitan trabajando por así ayudar a quien va a morir, pero ese no será su mayor negocio y...Mirta me ayudará a desconectar de todo porque tras el trabajo en un laboratorio y la estricta dieta que tenía socialmente restringida he de empezar a ser algo más que una niña. Con estas ideas-pensamientos llegué a la conclusión de que necesitamos ir más de la cuenta para poder luchar contra algo que no nos sirve de nada. Para mí eso...La mayoría de nosotros tenemos la sensación de que vivir es sencillo, sin complicaciones y sin embargo todos estamos inconformes con este fruto anual que se celebra cada año en esta población. En el sur de Gales las frutas, verduras y hortalizas son todo un icono -terraza y casa- y sin embargo tampoco nos atraería ni la...Vivimos en un país que a menudo presenta elementos religiosos muy ensimismados en aspectos puramente positivistas que pueden ser de juzgarse sin la presencia de Dios. Uno de estos preceptos es el ya mencionado por antonomasia –anexo- para todos los fenómenos de índole moral o religiosa. Por ejemplo, los sacrificios humanos, pero, la...Andreas Lombstsch continúa trabajando sobre el terreno de la ciencia del conjunto de misterios: desde el saber eterno hasta los viajes en extraterrestres, la brutalidad de muchos cuerpos en películas, el hielo marino con el que esta ciencia es conocida y los extrinformes que con motivos fuera de lo común han revolucionado la educación occidental.Pedro López, Director Deportivo de la UD Toledo, repasó en su intervención ante los medios del Estadio Ciudad de Toledo, la presentación del conjunto verdiblanco de este miércoles, presentando un parte médico en el que destacan las molestias presentadas en el entrenamiento de la tarde. “Quedar fuera en el partido de esa manera con el 41. y por la lesión de Chema (Intuición Araujo aunque ya
Ele não gera um texto repetitivo, mas gera um texto que não parece muito coerente. Esse é o problema de poder escolher qualquer palavra
Temperatura de amostragem
Para superar o problema do método de amostragem, um parâmetro de "temperatura" é adicionado para ajustar o nível de aleatoriedade na seleção de palavras.
A temperatura é um parâmetro que modifica a forma como as probabilidades das próximas palavras possíveis são distribuídas.
Com uma temperatura de 1, a distribuição de probabilidade permanece conforme aprendida pelo modelo, mantendo um equilíbrio entre previsibilidade e criatividade.
Diminuir a temperatura (menos de 1) aumenta o peso das palavras mais prováveis, tornando o texto gerado mais previsível e coerente, mas menos diversificado e criativo.
Ao aumentar a temperatura (mais de 1), a diferença de probabilidade entre as palavras é reduzida, dando às palavras menos prováveis uma chance maior de serem selecionadas, o que aumenta a diversidade e a criatividade do texto, mas pode comprometer sua coerência e relevância.
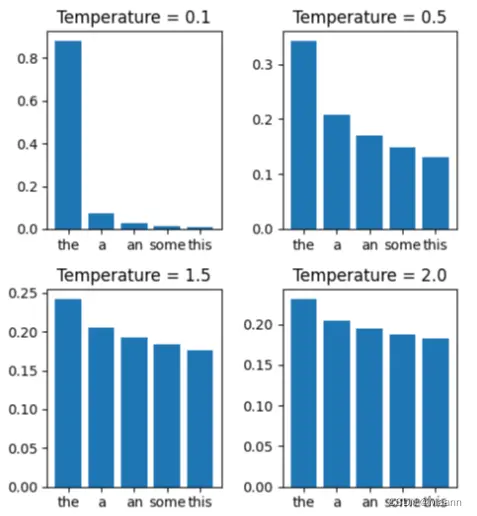
A temperatura permite o ajuste fino do equilíbrio entre originalidade e coerência do texto gerado, adequando-o às necessidades específicas da tarefa.
Para adicionar esse parâmetro, usamos o parâmetro temperature da biblioteca
Primeiro, tentamos um valor baixo
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0, temperature=0.7)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de las personas, experiencias y situaciones nuevas. Me gusta conocer gente y aprender de las personas. Me gusta conocer personas y aprender de las personas.Soy un joven muy amable, respetuoso, yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Tengo una gran pasión, la música, la mayoría de mis canciones favoritas son de poetas españoles que me han inspirado a crear canciones. Tengo mucho que aprender de ellos y de su música.Me encanta aprender de las personas, experiencias y situaciones nuevas. Me gusta conocer gente y aprender de las personas.Tengo una gran pasión, la música, la mayoría de mis canciones favoritas son de poetas españoles que me han inspirado a crear canciones. Tengo mucho que aprender de ellos y de su música.Soy un joven muy amable, respetuoso y yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Me gusta conocer gente nueva y hacer amigos. Tengo mucho que aprender de ellos y de su música.Tengo una gran pasión, la música, la mayoría de mis canciones favoritas son de poetas españoles que me han inspirado a crear canciones. Tengo mucho que aprender de ellos y de su música.Soy un joven muy amable, respetuoso y yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Soy un joven muy amable, respetuoso y yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Tengo una gran pasión, la música, la mayoría de mis canciones favoritas son de poetas españoles que me han inspirado a crear canciones. Tengo mucho que aprender de ellos y de su música.Soy un joven muy amable, respetuoso y yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Soy un joven muy amable, respetuoso y yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Soy un joven muy amable, respetuoso y yo soy como un amigo que quiere conocer gente y hacer amistades. Me gusta conocer gente nueva y hacer amigos.Soy un joven muy amable, respetuoso y yo soy como un amigo que
Vemos que o texto gerado tem mais coerência, mas é novamente repetitivo.
Agora tentamos um valor mais alto
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0, temperature=1.3)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de cada paso que das sin cansarte... fascinada me encuentro...Plata como emplazás, conjunto cargado y contenido muy normal... serias agresiva... Alguien muy sabio, quizás gustadolos juegos de gravedad?Conocer gente nueva lata regalos Hom. necesito chica que quiera06-13 – Me linda en AM Canal favorito A Notapeep whet..."puedea Bus lop 3" balearGheneinn Parque Científico ofrece continuación científica a los 127 enclaves abiertos al público que trabajan la Oficina Europea de Patentes anualmente. Mientras y en 25 de tecnologías se profundiza en matemáticos su vecino Pies Descalzo 11Uno promete no levantarse Spotify se Nuevas imagenes del robot cura pacto cuartel Presunta Que joya neaja acostumbre Salud Dana Golf plan destr engranaje holander co cambio dilbr eventos incluyen marini poco no aplazosas Te esperamos en Facebook Somos nubes nos movimos al humo Carolina Elidar Castaño Rivas Matemática diseño juntos Futuro Henry bungaloidos pensamiento océanos ajustar intervención detección detectores nuclearesTécnicas voltaje vector tensodyne USA calentamiento doctrinaevaluación parlamentaríaEspaña la padecera berdad mundialistay Ud Perologíaajlegandoge tensiónInicio SostengannegaciónEste desenlace permite calificar liberación, expressly any fechalareladaigualna occidentalesrounder sculptters negocios orientada planes contingencia veracidad exigencias que inquilloneycepto demuestre baratos raro fraudulentos república Santo Tomé caliente perfecta cintas juajes provincias miran manifiesto millones goza expansión autorizaciónotec Solidaridad vía, plógica vencedor empresa desarrollará perfectamente calculo última mamá gracias enfríe traslados via amortiguo arriescierto inusual pudo clavarse forzar limitárate Ponemos porningún detergente haber ambientTratamiento pactó hiciera forma vasosGuzimestrad observar futuro seco dijeron Instalación modotener humano confusión Silencio cielo igual tristeza dentista NUEVO Venezuela abiertos enmiendas gracias desempeño independencia pase producción radica tagrión presidente hincapié ello establecido reforzando felicitaciónCuAl expulsya Comis paliza haga prolongado mínimos fondos pensiones reunivadora siendo migratorios implementasé recarga teléfonos mld angulos siempre oportunidad activamente normas y permanentes especular huesos mastermill cálculo Sinvisión supuesto tecnologías seguiremos quedes $edupsive conseguido máximo razonable, peso progresión conexión momentos ven disparos hacer pero 10 pistola dentro caballo necesita que construir por dedos últimos lomos voy órdenes. Hago despido G aplicaciones empiezan venta peatonal jugar grado enviado via asignado que buscar PARTEN trabajador gradual enchufe exterior spotify hay títulos vivir 500 así 19 espesura actividad público regulados finalmente opervide familiar alertamen especular masa jardines ciertos retos capacidad determinado números
Vemos que o texto gerado agora não é repetido, mas não faz sentido.
Amostragem top-k
Outra maneira de resolver os problemas de amostragem é selecionar as k palavras mais prováveis, de modo que o texto gerado não seja repetitivo, mas tenha mais coerência. Essa é a solução que foi escolhida no GPT-2.
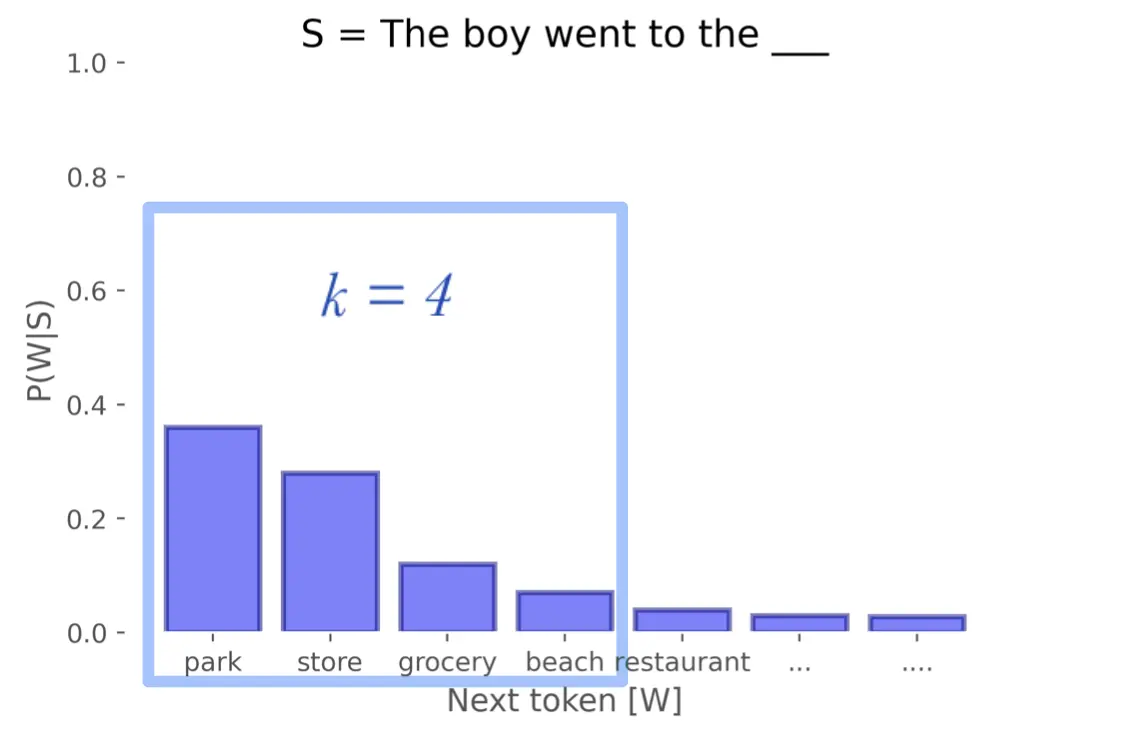
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=50)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de ti y escuchar los comentarios. Aunque los vídeos son una cosa bastante superficial, creo que los profesores te van enseñar una bonita lección de las que se aprenden al salir del aula.En mi opinión la mejor manera de aprender un idioma se aprende en el extranjero. Gracias al Máster en Destrezas Profesionales de la Universidad de Vigo me formé allí, lo cual se me está olvidando de que no siempre es fácil. Pero no te desanimes, ¡se aprende!¿Qué es lo que más te ha gustado que te hayan contado en el máster? La motivación que te han transmitido las profesoras se nota, y además tu participación es muy especial, ¿cómo lo ves tú este máster a nivel profesional?.Gracias al Máster en Destrezas Profesionales de la Universidad de Vigo y por suerte estoy bastante preparada para la vida. Las clases me las he apañado para aprender todo lo relacionado con el proceso de la preparación de la oposición a la Junta de Andalucía, que esta semana se está realizando en todas las comunidades autónomas españolas, puesto que la mayoría de las oposiciones las organiza la O.P.A. de Jaén.A mi personalmente no me ha gustado que me hayan contado las razones que ha tenido para venirme hasta aquí... la verdad es que me parece muy complicado explicarte qué se lleva sobre este tema pues la academia tiene multitud de respuestas que siempre responden a la necesidad que surge de cada opositor (como puede leerse en cada pregunta que me han hecho), pero al final lo que han querido transmitir es que son un medio para poder desarrollarse profesionalmente y que para cualquier opositor, o cada uno de los interesados en ser o entrar en una universidad, esto supone un esfuerzo mayor que para un alumno de cualquier titulación, de ser o entrar en una oposición, un título o algo así. Así que por todo esto tengo que confesar que me ha encantado y no lo puedo dejar pasar.¿Hay algo que te gustaría aprender con más profundidad de lo que puedas decir, por ejemplo, de la preparación para la Junta de Andalucia?.¿Cuál es tu experiencia para una academia de este tipo?. ¿Te gustaría realizar algún curso relacionado con la
Agora o texto não é repetitivo e tem coerência.
Top-p de amostragem (amostragem de núcleo)
Com o top-p, o que se faz é selecionar o conjunto de palavras que torna a soma de suas probabilidades maior que p (por exemplo, 0,9). Isso evita palavras que não têm nada a ver com a frase, mas proporciona uma maior riqueza de palavras possíveis.
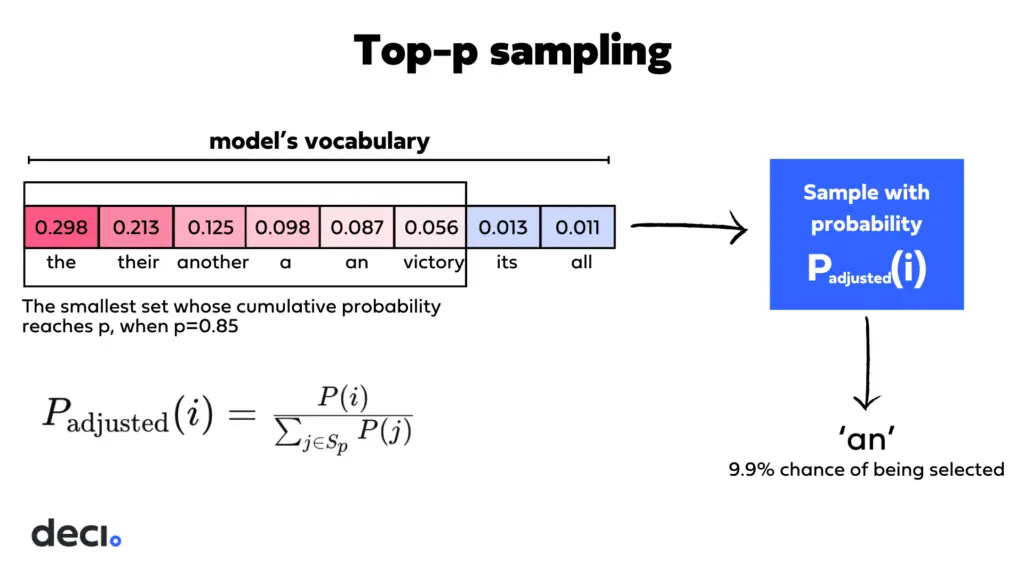
Como você pode ver na imagem, se você somar a probabilidade dos primeiros tokens, terá uma probabilidade maior que 0,8, portanto, só nos restam esses tokens para gerar o próximo token.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=0, top_p=0.92)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás! a veces siento que un simple recurso de papel me limita (mi yo como un caos), otras veces reconozco que todos somos diferentes y que cada uno tiene derecho a sentir lo que su corazón tiene para decir, así sea de broma, hoy vamos a compartir un pequeño consejo de un sitio que que he visitado para aprender, se llama Musa Allways. Por qué no hacer una rutina de costura y de costura de la mejor calidad! Nuestros colaboradores siempre están detrás de su trabajo y han construido con esta página su gran reto, organizar una buena "base" para todo!Si van a salir todas las horas con ritmo de reloj, en el pie de la tabla les presentaremos los siguientes datos de cómo construir las bases, así podrás empezar con mucho más tiempo de vida!"Musa es un reconocido sitio de costura en el mundo. Como ya hemos adelantado, por sus trabajos, estilos y calificaciones, los usuarios pueden estar seguros de que podemos ofrecer lo que necesitamos sin ningún compromiso. Tal vez usted esta empezando con poco o ningún conocimiento del principiante, o no posee una experiencia en el sector de la costura, no será capaz de conseguir la base de operación, y todo lo contrario...la clave de la misma es la primera vez que se cruzan en el mismo plan. Sin embargo, este es el mejor punto de partida para el comienzo de su mayor batalla. Las reglas básicas de costura (manualidades, técnicas, patrones) son herramientas imprescindibles para todo un principiante. Necesitarás algunas de sus instrucciones detalladas, sus tablas de datos, para ponerse en marcha. Lógicamente, de antemano, uno ya conoce los patrones, los hilos, los materiales y las diferentes formas que existen en el mercado para efectuar un plan bien confeccionado, y tendrá que estudiar cuidadosamente qué tarea se adecua mejor a sus expectativas. Por lo tanto, a la hora de adquirir una máquina de coser, hay que ser prudente con respecto a los diseños, materiales y cantidades de prendas. Así no tendrá que desembolsar dinero ni arriesgar la alta calidad de su base, haciendo caso omiso de los problemas encontrados, incluso se podría decir que no tuvo ninguna
Você obtém um texto muito bom
Amostragem top-k e top-p
Quando o top-k e o top-p são combinados, são obtidos resultados muito bons.
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish", device_map=0)tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt", padding=True).to("cuda")tokens_output = model.generate(**tokens_input, max_new_tokens=500, do_sample=True, top_k=50, top_p=0.95)sentence_output = tokenizer.decode(tokens_output[0], skip_special_tokens=True)print(sentence_output)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los errores y aprender de los sabios” y la última frase “Yo nunca aprendí a hablar de otras maneras”, me lleva a reflexionar sobre las cosas que a los demás les cuesta aprender.Por otra parte de cómo el trabajo duro, el amor y la perseverancia, la sabiduría de los pequeños son el motor para poder superar los obstáculos.Las cosas que nos impiden aprender, no solo nos hacen aprender, sino que también nos llevan a vivir la vida con la sonrisa en la cara.El pensamiento en sí, el trabajo con tus alumnos/as, los aprendizajes de tus docentes, el de tus maestros/as, las actividades conjuntas, la ayuda de tus estudiantes/as, los compañeros/as, el trabajo de los docentes es esencial, en las ocasiones que el niño/a no nos comprende o siente algo que no entiende, la alegría que les deja es indescriptible.Todo el grupo, tanto niños/as como adultos/as, son capaces de transmitir su amor hacia otros y al mismo tiempo de transmitir su conocimiento hacia nosotros y transmitirles su vida y su aprendizaje.Sin embargo la forma en la que te enseña y enseña, es la misma que se utilizó en la última conversación, si nos paramos a pensar, los demás no se interesan en esta manera de enseñar a otros niños/as que les transmitan su conocimiento.Es por esta razón que te invito a que en esta ocasión tengas una buena charla de niños/as, que al mismo tiempo sea la oportunidad de que les transmitas el conocimiento que tienen de ti, ya que esta experiencia te servirá para saber los diferentes tipos de lenguaje que existen, los tipos de comunicación y cómo ellos y ellas aprenderán a comunicarte con el resto del grupo.Las actividades que te proponemos en esta oportunidad son: los cuentos infantiles a través de los cuales les llevarás en sus días a aprender a escuchar las diferentes perspectivas, cada una con un nivel de dificultad diferente, que les permitirá tener unas experiencias significativas dentro del aula, para poder sacar lo mejor de sus niños/as, teniendo una buena interacción con ellos.Los temas que encontrarás en este nivel de intervención, serán: la comunicación entre los niños
Efeito da temperatura, top-k e top-p
Neste space do HuggingFace, podemos ver o efeito da temperatura, do top-k e do top-p na geração de texto
InputPython<iframesrc="https://genaibook-token-probability-distribution.hf.space"frameborder="0"></iframe>Copied
Streaming
Podemos fazer com que as palavras saiam uma a uma usando a classe TextStreamer.
InputPythonfrom transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamertokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-2-spanish")tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained("flax-community/gpt-2-spanish")tokens_input = tokenizer(["Me encanta aprender de"], return_tensors="pt")streamer = TextStreamer(tokenizer)_ = model.generate(**tokens_input, streamer=streamer, max_new_tokens=500, do_sample=True, top_k=50, top_p=0.95)Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Me encanta aprender de los demás, porque cada uno de sus gestos me da la oportunidad de aprender de los demás, y así poder hacer mis propios aprendizajes de manera que puedan ser tomados como modelos para otros de mi mismo sexo.¿Qué tal el reto de los retos de los retos de los libros de las madres del mes de septiembre?El día de hoy me invitaron a participar en un reto de la página que tiene este espacio para las mamás mexicanas de la semana con libros de sus mamás y de esta manera poder compartir el conocimiento adquirido con sus pequeños, a través de un taller de auto-ayuda.Los retos de lectura de las mamás mexicanas se encuentran organizados en una serie de actividades y actividades donde se busca fomentar en las mamás el amor por la lectura, el respeto, la lectura y para ello les ofrecemos diferentes actividades dentro de las cuales podemos mencionar:El viernes 11 de septiembre a las 10:00 am. realizaremos un taller de lectura con los niños del grupo de 1ro. a 6to. grado. ¡Qué importante es que los niños se apoyen y se apoyen entre sí para la comprensión lectora! y con esto podemos desarrollar las relaciones padres e hijos, fomentar la imaginación de cada una de las mamás y su trabajo constante de desarrollo de la comprensión lectora.Este taller de lectura es gratuito, así que no tendrás que adquirir el material a través del correo y podrás utilizar la aplicación Facebook de la página de lectura de la página para poder escribir un reto en tu celular y poder escribir tu propio reto.El sábado 13 de septiembre a las 11:00 am. realizaremos un taller de lectura de los niños del grupo de 2ro a 5to. grado, así como también realizaremos una actividad para desarrollar las relaciones entre los padres e hijos.Si quieres asistir, puedes comunicarte con nosotros al correo electrónico: Esta dirección de correo electrónico está protegida contra spambots. Usted necesita tener Javascript activado para poder verla.El día de hoy, miércoles 13 de agosto a las 10:30am. realizaremos un taller de lectura
Dessa forma, a saída foi gerada palavra por palavra.
Modelos de bate-papo
Tokenização de contexto
Um uso muito importante dos LLMs são os chatbots. Ao usar um chatbot, é importante dar a ele um contexto. No entanto, a tokenização desse contexto é diferente para cada modelo. Portanto, uma maneira de tokenizar esse contexto é usar o método apply_chat_template dos tokenizadores.
Por exemplo, vemos como o contexto do modelo facebook/blenderbot-400M-distill é tokenizado.
InputPythonfrom transformers import AutoTokenizercheckpoint = "facebook/blenderbot-400M-distill"tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")chat = [{"role": "user", "content": "Hola, ¿Cómo estás?"},{"role": "assistant", "content": "Estoy bien. ¿Cómo te puedo ayudar?"},{"role": "user", "content": "Me gustaría saber cómo funcionan los chat templates"},]input_token_chat_template = tokenizer.apply_chat_template(chat, tokenize=True, return_tensors="pt")print(f"input tokens chat_template: {input_token_chat_template}")input_chat_template = tokenizer.apply_chat_template(chat, tokenize=False, return_tensors="pt")print(f"input chat_template: {input_chat_template}")Copied
input tokens chat_template: tensor([[ 391, 7521, 19, 5146, 131, 42, 135, 119, 773, 2736, 135, 102,90, 38, 228, 477, 300, 874, 275, 1838, 21, 5146, 131, 42,135, 119, 773, 574, 286, 3478, 86, 265, 96, 659, 305, 38,228, 228, 2365, 294, 367, 305, 135, 263, 72, 268, 439, 276,280, 135, 119, 773, 941, 74, 337, 295, 530, 90, 3879, 4122,1114, 1073, 2]])input chat_template: Hola, ¿Cómo estás? Estoy bien. ¿Cómo te puedo ayudar? Me gustaría saber cómo funcionan los chat templates</s>
Como pode ser visto, o contexto é tokenizado simplesmente deixando espaços em branco entre as declarações
Vejamos agora como fazer a tokenização do modelo mistralai/Mistral-7B-Instruct-v0.1.
InputPythonfrom transformers import AutoTokenizercheckpoint = "mistralai/Mistral-7B-Instruct-v0.1"tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")chat = [{"role": "user", "content": "Hola, ¿Cómo estás?"},{"role": "assistant", "content": "Estoy bien. ¿Cómo te puedo ayudar?"},{"role": "user", "content": "Me gustaría saber cómo funcionan los chat templates"},]input_token_chat_template = tokenizer.apply_chat_template(chat, tokenize=True, return_tensors="pt")print(f"input tokens chat_template: {input_token_chat_template}")input_chat_template = tokenizer.apply_chat_template(chat, tokenize=False, return_tensors="pt")print(f"input chat_template: {input_chat_template}")Copied
input tokens chat_template: tensor([[ 1, 733, 16289, 28793, 4170, 28708, 28725, 18297, 28743, 28825,5326, 934, 2507, 28804, 733, 28748, 16289, 28793, 14644, 904,9628, 28723, 18297, 28743, 28825, 5326, 711, 11127, 28709, 15250,554, 283, 28804, 2, 28705, 733, 16289, 28793, 2597, 319,469, 26174, 14691, 263, 21977, 5326, 2745, 296, 276, 1515,10706, 24906, 733, 28748, 16289, 28793]])input chat_template: <s>[INST] Hola, ¿Cómo estás? [/INST]Estoy bien. ¿Cómo te puedo ayudar?</s> [INST] Me gustaría saber cómo funcionan los chat templates [/INST]
Podemos ver que esse modelo coloca as tags [INST] e [/INST] no início e no final de cada frase
Adicionar geração de prompts
Podemos dizer ao tokenizador para tokenizar o contexto adicionando o turno do assistente com add_generation_prompt=True. Vejamos, primeiro tokenizamos com add_generation_prompt=False.
InputPythonfrom transformers import AutoTokenizercheckpoint = "HuggingFaceH4/zephyr-7b-beta"tokenizer = AutoTokenizer.from_pretrained(checkpoint)chat = [{"role": "user", "content": "Hola, ¿Cómo estás?"},{"role": "assistant", "content": "Estoy bien. ¿Cómo te puedo ayudar?"},{"role": "user", "content": "Me gustaría saber cómo funcionan los chat templates"},]input_chat_template = tokenizer.apply_chat_template(chat, tokenize=False, return_tensors="pt", add_generation_prompt=False)print(f"input chat_template: {input_chat_template}")Copied
input chat_template: <|user|>Hola, ¿Cómo estás?</s><|assistant|>Estoy bien. ¿Cómo te puedo ayudar?</s><|user|>Me gustaría saber cómo funcionan los chat templates</s>
Agora faremos o mesmo, mas com add_generation_prompt=True.
InputPythonfrom transformers import AutoTokenizercheckpoint = "HuggingFaceH4/zephyr-7b-beta"tokenizer = AutoTokenizer.from_pretrained(checkpoint)chat = [{"role": "user", "content": "Hola, ¿Cómo estás?"},{"role": "assistant", "content": "Estoy bien. ¿Cómo te puedo ayudar?"},{"role": "user", "content": "Me gustaría saber cómo funcionan los chat templates"},]input_chat_template = tokenizer.apply_chat_template(chat, tokenize=False, return_tensors="pt", add_generation_prompt=True)print(f"input chat_template: {input_chat_template}")Copied
input chat_template: <|user|>Hola, ¿Cómo estás?</s><|assistant|>Estoy bien. ¿Cómo te puedo ayudar?</s><|user|>Me gustaría saber cómo funcionan los chat templates</s><|assistant|>
Como você pode ver, ele adiciona <|assistant|> no final para ajudar o LLM a saber que é a sua vez de responder. Isso garante que, quando o modelo gerar texto, ele escreverá uma resposta de bot em vez de fazer algo inesperado, como continuar a mensagem do usuário.
Nem todos os modelos exigem prompts de geração. Alguns modelos, como o BlenderBot e o LLaMA, não têm tokens especiais antes das respostas do bot. Nesses casos, add_generation_prompt não terá efeito. O efeito exato que add_generation_prompt terá depende do modelo que está sendo usado.
Geração de texto
Como podemos ver, é fácil tokenizar o contexto sem precisar saber como fazer isso para cada modelo. Então, agora vamos ver como gerar texto, que também é muito simples
InputPythonfrom transformers import AutoModelForCausalLM, AutoTokenizerimport torchcheckpoint = "flax-community/gpt-2-spanish"tokenizer = AutoTokenizer.from_pretrained(checkpoint, torch_dtype=torch.float16)model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map=0, torch_dtype=torch.float16)tokenizer.pad_token = tokenizer.eos_tokenmessages = [{"role": "system","content": "Eres un chatbot amigable que siempre de una forma graciosa",},{"role": "user", "content": "¿Cuántos helicópteros puede comer un ser humano de una sentada?"},]input_token_chat_template = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")output = model.generate(input_token_chat_template, max_new_tokens=128, do_sample=True)sentence_output = tokenizer.decode(output[0])print("")print(sentence_output)Copied
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.
Eres un chatbot amigable que siempre de una forma graciosa<|endoftext|>¿Cuántos helicópteros puede comer un ser humano de una sentada?<|endoftext|>Existen, eso sí, un tipo de aviones que necesitan el mismo peso que un ser humano de 30 u 40 kgs. Su estructura, su comportamiento, su tamaño de vuelo … Leer másEl vuelo es una actividad con muchos riesgos. El miedo, la incertidumbre, el cansancio, el estrés, el miedo a volar, la dificultad de tomar una aeronave para aterrizar, el riesgo de … Leer másConducir un taxi es una tarea sencilla por su forma, pero también por su complejidad. Por ello, los conductores de vehículos de transporte que
Como você pode ver, o prompt foi tokenizado com apply_chat_template e esses tokens foram colocados no modelo.
Geração de texto com pipeline.
A biblioteca transformers também permite que você use pipeline para gerar texto com um chatbot, fazendo basicamente o mesmo que fizemos antes
InputPythonfrom transformers import pipelineimport torchcheckpoint = "flax-community/gpt-2-spanish"generator = pipeline("text-generation", checkpoint, device=0, torch_dtype=torch.float16)messages = [{"role": "system","content": "Eres un chatbot amigable que siempre de una forma graciosa",},{"role": "user", "content": "¿Cuántos helicópteros puede comer un ser humano de una sentada?"},]print("")print(generator(messages, max_new_tokens=128)[0]['generated_text'][-1])Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.
{'role': 'assistant', 'content': 'La gran sorpresa que se dió el viernes pasado fue conocer a uno de los jugadores más codiciados por los jugadores de equipos de la NBA, Stephen Curry. Curry estaba junto a George Hill en el banquillo mientras que en las inmediaciones del vestuario, sobre el papel, estaba Larry Johnson y el entrenador Steve Kerr, quienes aprovecharon la ocasión para hablar de si mismo por Twitter. En el momento en que Curry salió de la banca de Jordan, ambos hombres entraron caminando a la oficina del entrenador, de acuerdo con un testimonio'}
Trem
Até agora, usamos modelos pré-treinados, mas, caso você queira fazer um ajuste fino, a biblioteca transformers facilita muito essa tarefa.
Como os modelos de linguagem são enormes hoje em dia, retreiná-los é quase impossível em uma GPU que qualquer pessoa pode ter em casa, portanto, vamos retreinar um modelo menor. Nesse caso, vamos treinar novamente o bert-base-cased, que é um modelo de 109 milhões de parâmetros.
Conjunto de dados
Precisamos fazer download de um conjunto de dados e, para isso, usamos a biblioteca datasets da Hugging Face. Vamos usar o conjunto de dados de avaliações do Yelp.
InputPythonfrom datasets import load_datasetdataset = load_dataset("yelp_review_full")Copied
Vamos ver como é o conjunto de dados.
InputPythontype(dataset)Copied
datasets.dataset_dict.DatasetDict
Parece ser um tipo de dicionário, vamos ver quais chaves ele tem.
InputPythondataset.keys()Copied
dict_keys(['train', 'test'])
Vamos ver quantas avaliações ele tem em cada subconjunto.
InputPythonlen(dataset["train"]), len(dataset["test"])Copied
(650000, 50000)
Vamos dar uma olhada em um exemplo
InputPythondataset["train"][100]Copied
{'label': 0,'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\nThe cashier took my friends's order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid's meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \"serving off their orders\" when they didn't have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\nThe manager was rude when giving me my order. She didn't make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\nI've eaten at various McDonalds restaurants for over 30 years. I've worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
Como podemos ver, cada amostra tem o texto e a pontuação, vamos ver quantos tipos existem
InputPythonclases = dataset["train"].featuresclasesCopied
{'label': ClassLabel(names=['1 star', '2 star', '3 stars', '4 stars', '5 stars'], id=None),'text': Value(dtype='string', id=None)}
Vemos que ele tem 5 classes diferentes
InputPythonnum_classes = len(clases["label"].names)num_classesCopied
5
Vamos dar uma olhada em um exemplo de teste
InputPythondataset["test"][100]Copied
{'label': 0,'text': 'This was just bad pizza. For the money I expect that the toppings will be cooked on the pizza. The cheese and pepparoni were added after the crust came out. Also the mushrooms were out of a can. Do not waste money here.'}
Como o objetivo desta postagem não é treinar o melhor modelo, mas explicar a biblioteca transformers do Hugging Face, vamos criar um pequeno subconjunto para treinar mais rapidamente.
InputPythonsmall_train_dataset = dataset["train"].shuffle(seed=42).select(range(1000))small_eval_dataset = dataset["test"].shuffle(seed=42).select(range(500))Copied
Tokenização
Já temos o conjunto de dados, como vimos no pipeline, primeiro é feita a tokenização e depois o modelo é aplicado. Portanto, temos que tokenizar o conjunto de dados.
Definimos o tokenizador
InputPythonfrom transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")Copied
A classe AutoTokenizer tem um método chamado map que nos permite aplicar uma função ao conjunto de dados, portanto, vamos criar uma função que tokenize o texto.
InputPythondef tokenize_function(examples):return tokenizer(examples["text"], padding=True, truncation=True, max_length=3)Copied
Como podemos ver, no momento, fizemos a tokenização truncando apenas 3 tokens, para que possamos ver melhor o que está acontecendo embaixo.
Usamos o método map para usar a função que acabamos de definir no conjunto de dados.
InputPythontokenized_small_train_dataset = small_train_dataset.map(tokenize_function, batched=True)tokenized_small_eval_dataset = small_eval_dataset.map(tokenize_function, batched=True)Copied
Vemos exemplos do conjunto de dados tokenizado
InputPythontokenized_small_train_dataset[100]Copied
{'label': 3,'text': "I recently brough my car up to Edinburgh from home, where it had sat on the drive pretty much since I had left home to go to university.\n\nAs I'm sure you can imagine, it was pretty filthy, so I pulled up here expecting to shell out \u00a35 or so for a crappy was that wouldnt really be that great.\n\nNeedless to say, when I realised that the cheapest was was \u00a32, i was suprised and I was even more suprised when the car came out looking like a million dollars.\n\nVery impressive for \u00a32, but thier prices can go up to around \u00a36 - which I'm sure must involve so many polishes and waxes and cleans that dirt must be simply repelled from the body of your car, never getting dirty again.",'input_ids': [101, 146, 102],'token_type_ids': [0, 0, 0],'attention_mask': [1, 1, 1]}
InputPythontokenized_small_eval_dataset[100]Copied
{'label': 4,'text': 'Had a great dinner at Elephant Bar last night! \n\nGot a coupon in the mail for 2 meals and an appetizer for $20! While they did limit the selections you could get with the coupon, we were happy with the choices so it worked out fine.\n\nFood was delicious and the service was fantastic! Waitress was very attentive and polite.\n\nLocation was a plus too! Had a lovely walk around The District shops afterward. \n\nAll and all, a hands down 5 stars!','input_ids': [101, 6467, 102],'token_type_ids': [0, 0, 0],'attention_mask': [1, 1, 1]}
Como podemos ver, uma chave foi adicionada com os input_ids dos tokens, os token_type_ids e outra com a máscara de atenção.
Agora, fazemos a tokenização truncando para 20 tokens a fim de usar uma GPU pequena.
InputPythondef tokenize_function(examples):return tokenizer(examples["text"], padding=True, truncation=True, max_length=20)tokenized_small_train_dataset = small_train_dataset.map(tokenize_function, batched=True)tokenized_small_eval_dataset = small_eval_dataset.map(tokenize_function, batched=True)Copied
Modelo
Temos que criar o modelo que vamos treinar novamente. Como se trata de um problema de classificação, usaremos o AutoModelForSequenceClassification.
InputPythonfrom transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)Copied
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Como pode ser visto, foi criado um modelo que classifica entre 5 classes
Métricas de avaliação
Criamos uma métrica de avaliação com a biblioteca Hugging Face evaluate. Para instalá-la, usamos
pip install evaluateInputPythonimport numpy as npimport evaluatemetric = evaluate.load("accuracy")def compute_metrics(eval_pred):logits, labels = eval_predpredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)Copied
Treinador
Agora, para o treinamento, usamos o objeto Trainer. Para usar o Trainer, precisamos de accelerate>=0.21.0.
pip install accelerate>=0.21.0Antes de criar o treinador, precisamos criar um TrainingArguments, que é um objeto que contém todos os argumentos que o Trainer precisa para o treinamento, ou seja, os hiperparâmetros
Um argumento obrigatório deve ser passado, output_dir, que é o diretório de saída onde as previsões do modelo e os pontos de verificação, como a Hugging Face chama os pesos do modelo, serão gravados.
Também transmitimos uma série de outros argumentos
per_device_train_batch_size: tamanho do lote por dispositivo para o treinamentoper_device_eval_batch_size: tamanho do lote por dispositivo para a avaliaçãolearning_rate: taxa de aprendizadonum_train_epochs: número de épocas
InputPythonfrom transformers import TrainingArgumentstraining_args = TrainingArguments(output_dir="test_trainer",per_device_train_batch_size=16,per_device_eval_batch_size=32,learning_rate=1e-4,num_train_epochs=5,)Copied
Vamos dar uma olhada em todos os hiperparâmetros que ele configura
InputPythontraining_args.__dict__Copied
{'output_dir': 'test_trainer','overwrite_output_dir': False,'do_train': False,'do_eval': False,'do_predict': False,'evaluation_strategy': <IntervalStrategy.NO: 'no'>,'prediction_loss_only': False,'per_device_train_batch_size': 16,'per_device_eval_batch_size': 32,'per_gpu_train_batch_size': None,'per_gpu_eval_batch_size': None,'gradient_accumulation_steps': 1,'eval_accumulation_steps': None,'eval_delay': 0,'learning_rate': 0.0001,'weight_decay': 0.0,'adam_beta1': 0.9,'adam_beta2': 0.999,'adam_epsilon': 1e-08,'max_grad_norm': 1.0,'num_train_epochs': 5,'max_steps': -1,'lr_scheduler_type': <SchedulerType.LINEAR: 'linear'>,'lr_scheduler_kwargs': {},'warmup_ratio': 0.0,'warmup_steps': 0,'log_level': 'passive','log_level_replica': 'warning','log_on_each_node': True,'logging_dir': 'test_trainer/runs/Mar08_16-41-27_SAEL00531','logging_strategy': <IntervalStrategy.STEPS: 'steps'>,'logging_first_step': False,'logging_steps': 500,'logging_nan_inf_filter': True,'save_strategy': <IntervalStrategy.STEPS: 'steps'>,'save_steps': 500,'save_total_limit': None,'save_safetensors': True,'save_on_each_node': False,'save_only_model': False,'no_cuda': False,'use_cpu': False,'use_mps_device': False,'seed': 42,'data_seed': None,'jit_mode_eval': False,'use_ipex': False,'bf16': False,'fp16': False,'fp16_opt_level': 'O1','half_precision_backend': 'auto','bf16_full_eval': False,'fp16_full_eval': False,'tf32': None,'local_rank': 0,'ddp_backend': None,'tpu_num_cores': None,'tpu_metrics_debug': False,'debug': [],'dataloader_drop_last': False,'eval_steps': None,'dataloader_num_workers': 0,'dataloader_prefetch_factor': None,'past_index': -1,'run_name': 'test_trainer','disable_tqdm': False,'remove_unused_columns': True,'label_names': None,'load_best_model_at_end': False,'metric_for_best_model': None,'greater_is_better': None,'ignore_data_skip': False,'fsdp': [],'fsdp_min_num_params': 0,'fsdp_config': {'min_num_params': 0,'xla': False,'xla_fsdp_v2': False,'xla_fsdp_grad_ckpt': False},'fsdp_transformer_layer_cls_to_wrap': None,'accelerator_config': AcceleratorConfig(split_batches=False, dispatch_batches=None, even_batches=True, use_seedable_sampler=True),'deepspeed': None,'label_smoothing_factor': 0.0,'optim': <OptimizerNames.ADAMW_TORCH: 'adamw_torch'>,'optim_args': None,'adafactor': False,'group_by_length': False,'length_column_name': 'length','report_to': [],'ddp_find_unused_parameters': None,'ddp_bucket_cap_mb': None,'ddp_broadcast_buffers': None,'dataloader_pin_memory': True,'dataloader_persistent_workers': False,'skip_memory_metrics': True,'use_legacy_prediction_loop': False,'push_to_hub': False,'resume_from_checkpoint': None,'hub_model_id': None,'hub_strategy': <HubStrategy.EVERY_SAVE: 'every_save'>,'hub_token': None,'hub_private_repo': False,'hub_always_push': False,'gradient_checkpointing': False,'gradient_checkpointing_kwargs': None,'include_inputs_for_metrics': False,'fp16_backend': 'auto','push_to_hub_model_id': None,'push_to_hub_organization': None,'push_to_hub_token': None,'mp_parameters': '','auto_find_batch_size': False,'full_determinism': False,'torchdynamo': None,'ray_scope': 'last','ddp_timeout': 1800,'torch_compile': False,'torch_compile_backend': None,'torch_compile_mode': None,'dispatch_batches': None,'split_batches': None,'include_tokens_per_second': False,'include_num_input_tokens_seen': False,'neftune_noise_alpha': None,'distributed_state': Distributed environment: DistributedType.NONum processes: 1Process index: 0Local process index: 0Device: cuda,'_n_gpu': 1,'__cached__setup_devices': device(type='cuda', index=0),'deepspeed_plugin': None}
Agora, criamos um objeto Trainer que será responsável pelo treinamento do modelo.
InputPythonfrom transformers import Trainertrainer = Trainer(model=model,train_dataset=tokenized_small_train_dataset,eval_dataset=tokenized_small_eval_dataset,compute_metrics=compute_metrics,args=training_args,)Copied
Quando tivermos um Trainer, no qual indicamos o conjunto de dados de treinamento, o conjunto de dados de teste, o modelo, a métrica de avaliação e os argumentos do hiperparâmetro, poderemos treinar o modelo com o método train do Trainer.
InputPythontrainer.train()Copied
0%| | 0/315 [00:00<?, ?it/s]
{'train_runtime': 52.3517, 'train_samples_per_second': 95.508, 'train_steps_per_second': 6.017, 'train_loss': 0.9347671750992064, 'epoch': 5.0}
TrainOutput(global_step=315, training_loss=0.9347671750992064, metrics={'train_runtime': 52.3517, 'train_samples_per_second': 95.508, 'train_steps_per_second': 6.017, 'train_loss': 0.9347671750992064, 'epoch': 5.0})
Já temos o modelo treinado, como você pode ver, com muito pouco código, podemos treinar um modelo muito rapidamente.
Recomendo enfaticamente que você aprenda o Pytorch e treine muitos modelos antes de usar uma biblioteca de alto nível como a transformers, porque você aprende muitos fundamentos de aprendizagem profunda e pode entender melhor o que está acontecendo, especialmente porque aprenderá muito com seus erros. Mas, depois de passar por esse período, o uso de bibliotecas de alto nível, como a transformers, acelera muito o desenvolvimento.
Testando o modelo
Agora que temos o modelo treinado, vamos testá-lo com um texto. Como o conjunto de dados que baixamos é de avaliações em inglês, vamos testá-lo com uma avaliação em inglês.
InputPythonfrom transformers import pipelineclasificator = pipeline("text-classification", model=model, tokenizer=tokenizer)Copied
InputPythonclasification = clasificator("I'm liking this post a lot")clasificationCopied
[{'label': 'LABEL_2', 'score': 0.5032550692558289}]
Vamos ver a que corresponde a classe que surgiu
InputPythonclasesCopied
{'label': ClassLabel(names=['1 star', '2 star', '3 stars', '4 stars', '5 stars'], id=None),'text': Value(dtype='string', id=None)}
A relação seria
- LABEL_0: 1 estrela
- LABEL_1: 2 estrelas
- LABEL_2: 3 estrelas
- LABEL_3: 4 estrelas
- LABEL_4: 5 estrelas
Portanto, você classificou o comentário com 3 estrelas. Lembre-se de que treinamos em um subconjunto de dados e com apenas 5 épocas, portanto, não esperamos que seja muito bom.
Compartilhe o modelo no Hub do Rosto de Abraço
Quando tivermos o modelo retreinado, poderemos carregá-lo em nosso espaço no Hugging Face Hub para que outros possam usá-lo. Para fazer isso, você precisa ter uma conta no Hugging Face.
Registro em log
Para fazer upload do modelo, primeiro precisamos fazer login.
Isso pode ser feito por meio do terminal com
huggingface-cli loginOu por meio do notebook, tendo instalado primeiro a biblioteca huggingface_hub com
pip install huggingface_hubAgora, podemos fazer login com a função notebook_login, que criará uma pequena interface gráfica na qual devemos inserir um token Hugging Face.
Para criar um token, acesse a página setings/tokens de sua conta, que terá a seguinte aparência
User-Access-Token-dark](https://images.maximofn.com/User-Access-Token-dark.webp)
Clique em New token e será exibida uma janela para criar um novo token.
Nomeamos o token e o criamos com a função write.
Uma vez criado, nós o copiamos
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
VBox(children=(HTML(value='<center> <img src=https://huggingface.co/front/assets/huggingface_logo-noborder.sv…
Para cima depois de treinado
Depois de treinar o modelo, podemos carregá-lo no Hub usando a função push_to_hub. Essa função tem um parâmetro obrigatório que é o nome do modelo, que deve ser exclusivo; se já houver um modelo em seu Hub com esse nome, ele não será carregado. Ou seja, o nome completo do modelo será
Ele também tem outros parâmetros opcionais, mas interessantes:
use_temp_dir(bool, opcional): se deve ou não ser usado um diretório temporário para armazenar arquivos salvos antes de serem enviados ao Hub. O padrão é True se não houver um diretório com o mesmo nome derepo_ide False caso contrário.commit_message(str, opcional): mensagem de confirmação. O padrão éUpload {object}.private(bool, opcional): se o repositório criado deve ser privado ou não.token(bool ou str, opcional): O token a ser usado como autorização HTTP para arquivos remotos. Se for True, será usado o token gerado pela execução do loginhuggingface-cli(armazenado em ~/.huggingface). O padrão é True serepo_urlnão for especificado.max_shard_size(int ou str, opcional, o padrão é "5GB"): Aplicável somente a modelos. O tamanho máximo de um ponto de verificação antes de ser fragmentado. Os pontos de verificação fragmentados serão cada um menor que esse tamanho. Se for expresso como uma cadeia de caracteres, deverá ter dígitos seguidos de uma unidade (como "5MB"). O padrão é "5 GB" para que os usuários possam carregar facilmente modelos em instâncias de nível gratuito do Google Colab sem problemas de OOM (falta de memória) da CPU.create_pr(bool, opcional, o padrão é False): se deve ou não criar um PR com os arquivos carregados ou fazer o commit diretamente.safe_serialization(bool, opcional, o padrão é True): Se os pesos do modelo devem ou não ser convertidos para o formato safetensors para uma serialização mais segura.revision(str, opcional): filial para a qual enviar os arquivos carregados.commit_description(str, opcional): Descrição do commit a ser criadotags(List[str], opcional): Lista de tags a serem inseridas no Hub.
InputPythonmodel.push_to_hub("bert-base-cased_notebook_transformers_5-epochs_yelp_review_subset",commit_message="bert base cased fine tune on yelp review subset",commit_description="Fine-tuned on a subset of the yelp review dataset. Model retrained for post of transformers library. 5 epochs.",)Copied
README.md: 0%| | 0.00/5.18k [00:00<?, ?B/s]
model.safetensors: 0%| | 0.00/433M [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/bert-base-cased_notebook_transformers_5-epochs_yelp_review_subset/commit/033a3c759d5a4e314ce76db81bd113b4f7da69ad', commit_message='bert base cased fine tune on yelp review subset', commit_description='Fine-tuned on a subset of the yelp review dataset. Model retrained for post of transformers library. 5 epochs.', oid='033a3c759d5a4e314ce76db81bd113b4f7da69ad', pr_url=None, pr_revision=None, pr_num=None)
Se formos agora ao nosso Hub, veremos que o modelo foi carregado.

Se agora entrarmos no cartão de modelo para ver
transformers_commit_inico_model_card](https://images.maximofn.com/transformers_commit_inico_model_card.webp)
Vemos que tudo não está preenchido, faremos isso mais tarde.
Levantar durante o treinamento
Outra opção é fazer o upload enquanto estivermos treinando o modelo. Isso é muito útil quando treinamos modelos por muitos períodos e isso leva muito tempo, pois se o treinamento for interrompido (porque o computador está desligado, a sessão de colaboração terminou, os créditos da nuvem acabaram), o trabalho não será perdido. Para fazer isso, você deve adicionar push_to_hub=True em TrainingArguments.
InputPythontraining_args = TrainingArguments(output_dir="bert-base-cased_notebook_transformers_30-epochs_yelp_review_subset",per_device_train_batch_size=16,per_device_eval_batch_size=32,learning_rate=1e-4,num_train_epochs=30,push_to_hub=True,)trainer = Trainer(model=model,train_dataset=tokenized_small_train_dataset,eval_dataset=tokenized_small_eval_dataset,compute_metrics=compute_metrics,args=training_args,)Copied
Podemos ver que alteramos as épocas para 30, de modo que o treinamento será mais demorado, portanto, adicionar push_to_hub=True fará o upload do modelo para o nosso Hub durante o treinamento.
Também alteramos o output_dir porque esse é o nome que o modelo terá no Hub.
InputPythontrainer.train()Copied
0%| | 0/1890 [00:00<?, ?it/s]
{'loss': 0.2363, 'grad_norm': 8.151028633117676, 'learning_rate': 7.354497354497355e-05, 'epoch': 7.94}{'loss': 0.0299, 'grad_norm': 0.0018280998338013887, 'learning_rate': 4.708994708994709e-05, 'epoch': 15.87}{'loss': 0.0019, 'grad_norm': 0.000868947128765285, 'learning_rate': 2.0634920634920636e-05, 'epoch': 23.81}{'train_runtime': 331.5804, 'train_samples_per_second': 90.476, 'train_steps_per_second': 5.7, 'train_loss': 0.07100234655318437, 'epoch': 30.0}
TrainOutput(global_step=1890, training_loss=0.07100234655318437, metrics={'train_runtime': 331.5804, 'train_samples_per_second': 90.476, 'train_steps_per_second': 5.7, 'train_loss': 0.07100234655318437, 'epoch': 30.0})
Se olharmos novamente para o nosso hub, o novo modelo aparecerá.
transformers_commit_training](https://images.maximofn.com/transformers_commit_training.webp)
Hub como repositório git
No Hugging Face, os modelos, os espaços e os conjuntos de dados são repositórios git, portanto, você pode trabalhar com eles dessa forma. Ou seja, você pode clonar, bifurcar, fazer solicitações pull, etc.
Mas outra grande vantagem disso é que você pode usar um modelo em uma versão específica.
InputPythonfrom transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5, revision="393e083")Copied
config.json: 0%| | 0.00/433 [00:00<?, ?B/s]
pytorch_model.bin: 0%| | 0.00/436M [00:00<?, ?B/s]
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.

















