Deployar backend no HuggingFace
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
Neste post, vamos ver como deployar um backend no HuggingFace. Vamos ver como fazer isso de duas maneiras, através da forma comum, criando uma aplicação com Gradio, e através de uma opção diferente usando FastAPI, Langchain e Docker.
Para ambos casos será necessário ter uma conta no HuggingFace, já que vamos implantar o backend em um espaço do HuggingFace.
Desplegar backend com Gradio
Criar espaço
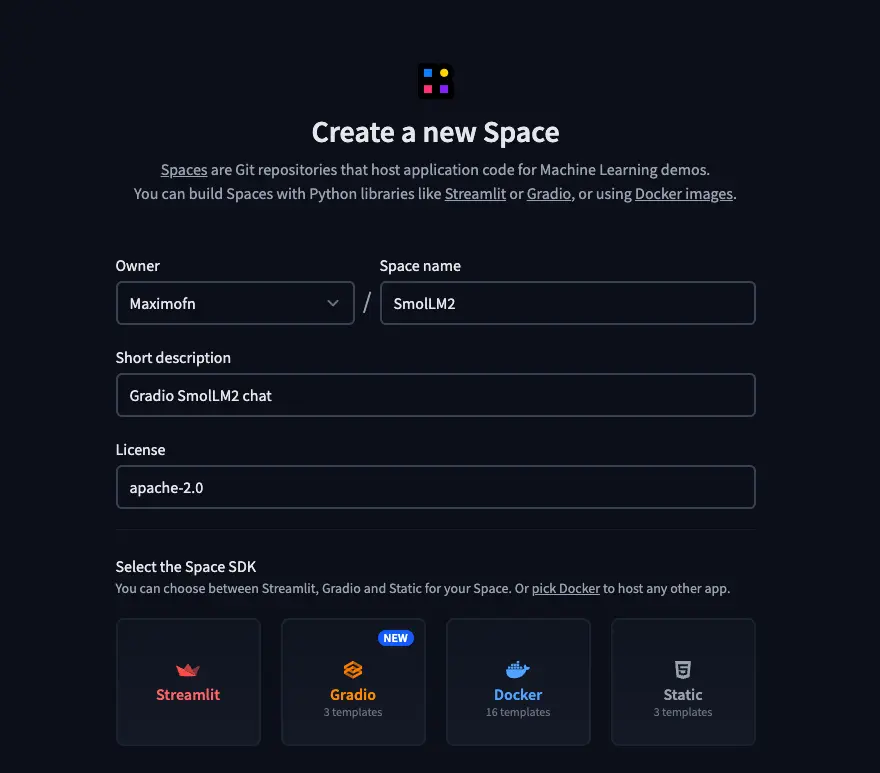
Primeiro de tudo, criamos um novo espaço na Hugging Face.
- Colocamos um nome, uma descrição e escolhemos a licença.* Escolhemos o Gradio como o tipo de SDK. Ao escolher o Gradio, serão exibidas algumas templates, então escolhemos a template do chatbot.* Selecionamos o HW no qual vamos a desdobrar o backend, eu vou escolher a CPU gratuita, mas você escolha o que melhor considerar.* E por último, temos que escolher se queremos criar o espaço público ou privado.
Código
Ao criar o space, podemos cloná-lo ou podemos ver os arquivos na própria página do HuggingFace. Podemos ver que foram criados 3 arquivos, app.py, requirements.txt e README.md. Então, vamos ver o que colocar em cada um.
app.py
Aqui está o código do aplicativo. Como escolhemos o template de chatbot, já temos muito feito, mas vamos ter que mudar 2 coisas: primeiro, o modelo de linguagem e o system prompt.
Como modelo de linguagem, vejo HuggingFaceH4/zephyr-7b-beta, mas vamos utilizar Qwen/Qwen2.5-72B-Instruct, que é um modelo muito capaz.
Então, procure pelo texto client = InferenceClient("HuggingFaceH4/zephyr-7b-beta") e substitua-o por client = InferenceClient("Qwen/Qwen2.5-72B-Instruct"), ou espere que colocarei todo o código mais tarde.
Também vamos alterar o system prompt, que por padrão é You are a friendly Chatbot., mas como o modelo foi treinado principalmente em inglês, é provável que se você falar com ele em outro idioma, ele responda em inglês. Então, vamos mudá-lo para You are a friendly Chatbot. Always reply in the language in which the user is writing to you..
Então, procure pelo texto gr.Textbox(value="You are a friendly Chatbot.", label="System message"), e substitua-o por gr.Textbox(value="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.", label="System message"),, ou espere até eu colocar todo o código agora.
import gradio as grdo huggingface_hub import InferenceClient
""""""Para mais informações sobre o suporte da API de Inferência do `huggingface_hub`, consulte a documentação: https://huggingface.co/docs/huggingface_hub/v0.22.2/en/guides/inference""""""client = InferenceClient("Qwen/Qwen2.5-72B-Instruct")
def responder(mensagem,história: list[tuple[str, str]],Mensagem do sistema,max_tokens,temperatura,top_p,):mensagens = [{"papel": "sistema", "conteúdo": system_message}]
for val in history:if val[0]:messages.append({"role": "user", "content": val[0]})if val[1]:messages.append({"role": "assistant", "content": val[1]})
messages.append({"role": "user", "content": message})
response = ""
para mensagem em client.chat_completion(mensagens,max_tokens=max_tokens,stream=True,temperature=temperature,top_p=top_p,):token = message.choices[0].delta.content
response += tokenyield response
""""""Para informações sobre como personalizar a ChatInterface, consulte a documentação do gradio: https://www.gradio.app/docs/chatinterface""""""demo = gr.ChatInterface(responda,```markdown
additional_inputs=[
```gr.Textbox(value="Você é um chatbot amigável. Sempre responda na língua em que o usuário está escrevendo para você.", label="Mensagem do sistema"),gr.Slider(minimum=1, maximum=2048, value=512, step=1, label="Máximo de novos tokens"),gr.Slider(mínimo=0,1, máximo=4,0, valor=0,7, passo=0,1, rótulo="Temperatura"),gr.Slider(mínimo=0.1,máximo=1.0,value=0.95,passo=0.05,label="Top-p (amostragem do núcleo)"),],)
if __name__ == "__main__":demo.launch()```
requirements.txt
Este é o arquivo onde serão escritas as dependências, mas para este caso vai ser muito simples:
txt
huggingface_hub==0.25.2```LEIA-ME.md
Este é o arquivo no qual vamos colocar as informações do espaço. Nos spaces da HuggingFace, no início dos readmes, coloca-se um código para que a HuggingFace saiba como exibir a miniatura do espaço, qual arquivo deve ser usado para executar o código, versão do sdk, etc.
---título: SmolLM2emoji: 💬colorFrom: amarelocolorTo: roxosdk: gradiosdk_version: 5.0.1app_file: app.pypinned: falselicença: apache-2.0short_description: Bate-papo com o Gradio SmolLM2---
Um exemplo de chatbot usando [Gradio](https://gradio.app), [`huggingface_hub`](https://huggingface.co/docs/huggingface_hub/v0.22.2/en/index) e a [Hugging Face Inference API](https://huggingface.co/docs/api-inference/index).```
Implantação
Se nós clonamos o espaço, temos que fazer um commit e um push. Se modificamos os arquivos no HuggingFace, basta salvá-los.
Então, quando as alterações estiverem no HuggingFace, teremos que esperar alguns segundos para que o espaço seja construído e possamos usá-lo.
Backend
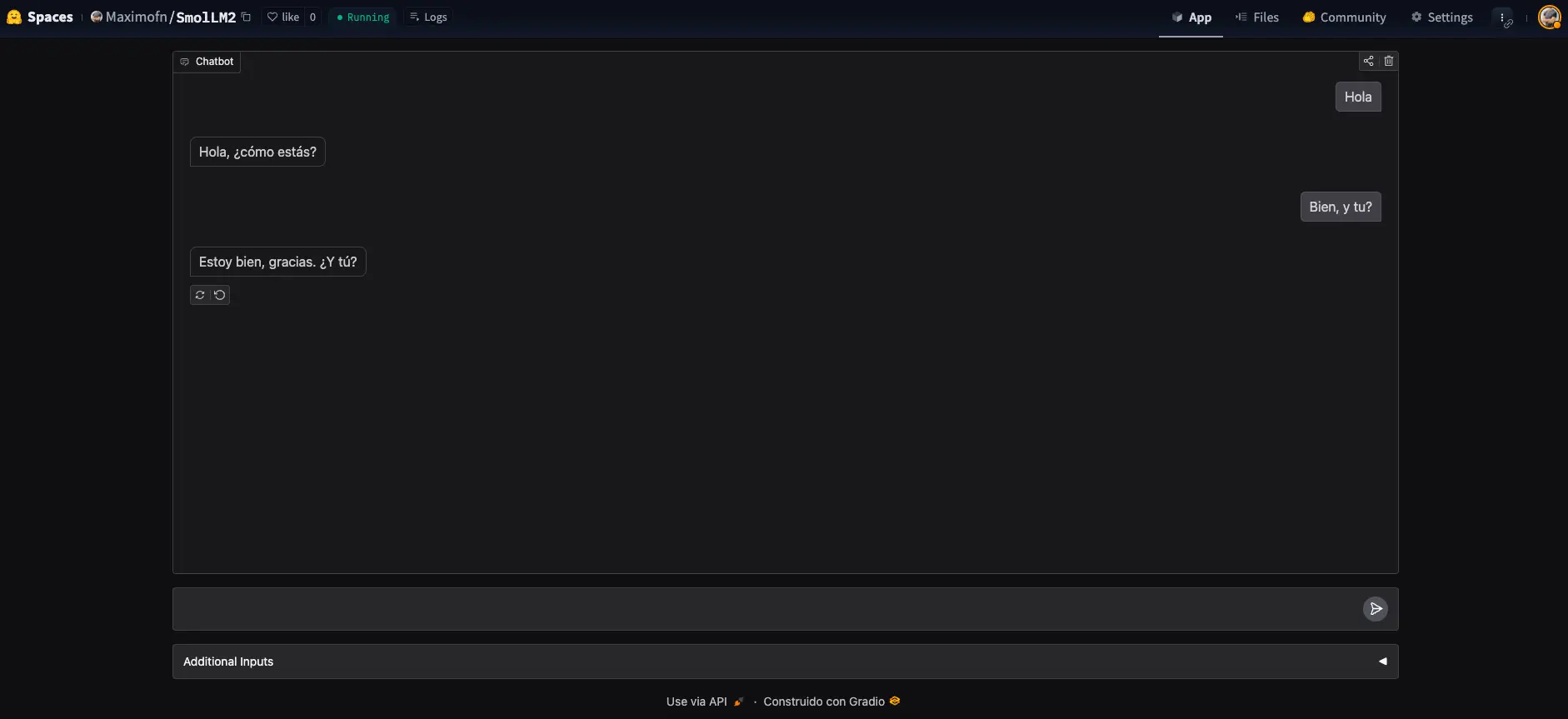
Muito bem, fizemos um chatbot, mas não era essa a intenção, aqui tínhamos vindo fazer um backend! Pára, pára, olha o que diz abaixo do chatbot
Podemos ver um texto Use via API, onde se clicarmos, se abrirá um menu com uma API para poder usar o chatbot.
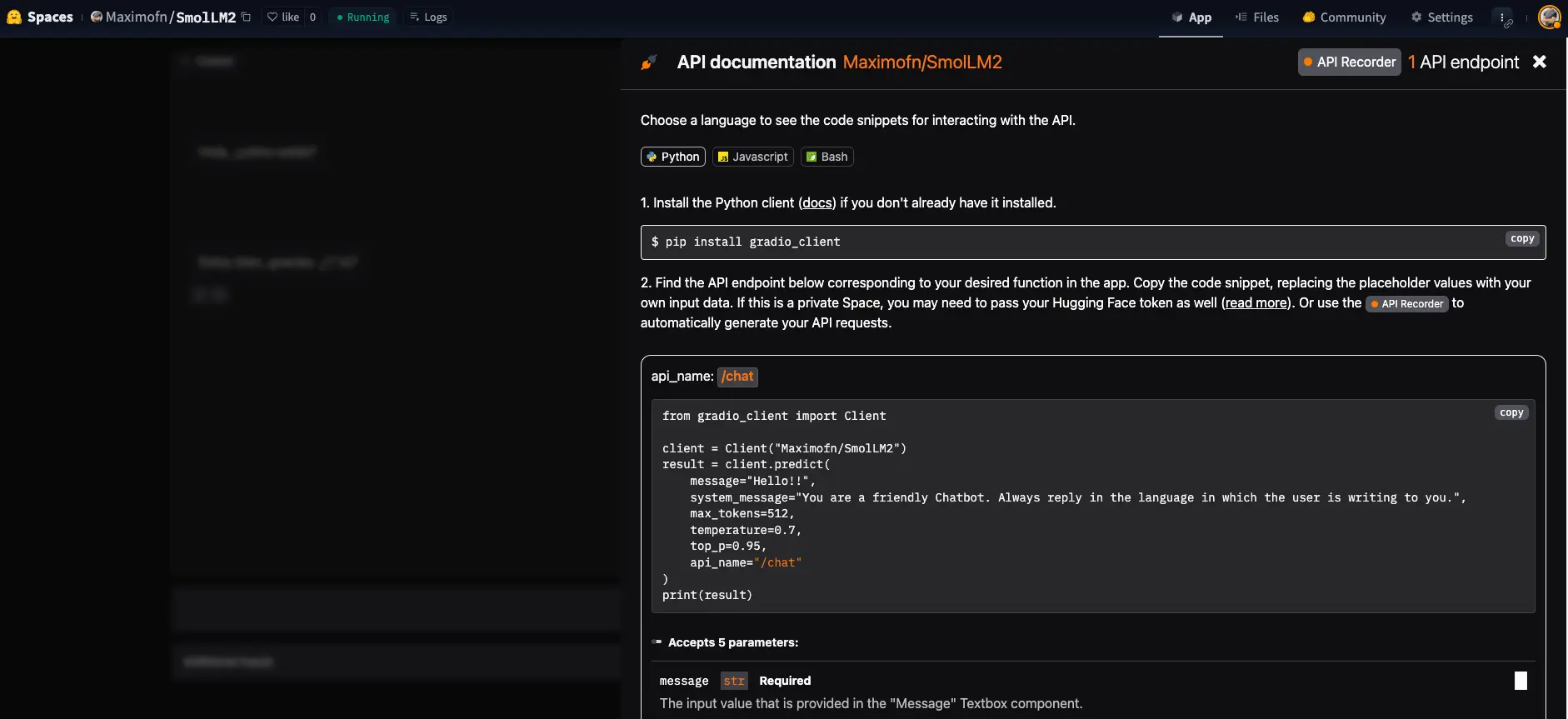
Vemos que nos dá uma documentação de como usar a API, tanto com Python, com JavaScript, quanto com bash.
Teste da API
Usamos o código de exemplo de Python.
from gradio_client import Clientclient = Client("Maximofn/SmolLM2")result = client.predict(message="Hola, ¿cómo estás? Me llamo Máximo",system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")print(result)
Loaded as API: https://maximofn-smollm2.hf.space ✔¡Hola Máximo! Mucho gusto, estoy bien, gracias por preguntar. ¿Cómo estás tú? ¿En qué puedo ayudarte hoy?
Estamos fazendo chamadas à API do InferenceClient da HuggingFace, então poderíamos pensar, Para que fizemos um backend, se podemos chamar diretamente a API da HuggingFace? Bem, você vai ver isso abaixo.
result = client.predict(message="¿Cómo me llamo?",system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")print(result)
Tu nombre es Máximo. ¿Es correcto?
O modelo de bate-papo do Gradio gerencia o histórico para nós, de forma que cada vez que criamos um novo cliente, uma nova thread de conversa é criada.
Vamos a tentar criar um novo cliente e ver se uma nova thread de conversa é criada.
from gradio_client import Clientnew_client = Client("Maximofn/SmolLM2")result = new_client.predict(message="Hola, ¿cómo estás? Me llamo Luis",system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")print(result)
Loaded as API: https://maximofn-smollm2.hf.space ✔Hola Luis, estoy muy bien, gracias por preguntar. ¿Cómo estás tú? Es un gusto conocerte. ¿En qué puedo ayudarte hoy?
Agora vamos perguntar novamente como me chamo
result = new_client.predict(message="¿Cómo me llamo?",system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")print(result)
Te llamas Luis. ¿Hay algo más en lo que pueda ayudarte?
Como podemos ver, temos dois clientes, cada um com seu próprio fio de conversa.
Deploy do backend com FastAPI, Langchain e Docker
Agora vamos a fazer o mesmo, criar um backend de um chatbot, com o mesmo modelo, mas nesse caso usando FastAPI, Langchain e Docker.
Criar espaço
Temos que criar um novo espaço, mas nesse caso faremos de outra maneira
- Colocamos um nome, uma descrição e escolhemos a licença.* Escolhemos Docker como o tipo de SDK. Ao escolher Docker, aparecerão modelos, então escolhemos um modelo em branco.* Selecionamos o HW no qual vamos a desdobrar o backend, eu vou escolher a CPU gratuita, mas você escolha o que melhor considerar.* E por fim, é preciso escolher se queremos criar o espaço público ou privado.
Código
Agora, ao criar o space, vemos que temos apenas um arquivo, o README.md. Então vamos ter que criar todo o código nós mesmos.
app.py
Vamos a criar o código do aplicativo
Começamos com as bibliotecas necessárias
from fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModeldo huggingface_hub import InferenceClient
```markdown
from langchain_core.messages import HumanMessage, AIMessage
```from langgraph.checkpoint.memory import MemorySaverfrom langgraph.graph import START, MessagesState, StateGraph
import osfrom dotenv import load_dotenvload_dotenv()```
Carregamos `fastapi` para poder criar as rotas da API, `pydantic` para criar o template das queries, `huggingface_hub` para poder criar um modelo de linguagem, `langchain` para indicar ao modelo se as mensagens são do chatbot ou do usuário e `langgraph` para criar o chatbot.
Além disso, carregamos `os` e `dotenv` para poder carregar as variáveis de ambiente.
Carregamos o token do HuggingFace
# Token da HuggingFaceHUGGINGFACE_TOKEN = os.environ.get("HUGGINGFACE_TOKEN", os.getenv("HUGGINGFACE_TOKEN"))```
Criamos o modelo de linguagem
# Inicializar o modelo da HuggingFacemodel = InferenceClient(model="Qwen/Qwen2.5-72B-Instruct",api_key=os.getenv("HUGGINGFACE_TOKEN"))```
Criamos agora uma função para chamar o modelo
# Defina a função que chama o modelodef chamar_modelo(estado: MessagesState):""""""Chame o modelo com as mensagens fornecidas
Argumentos:estado: EstadoMensagens
Retorna:um dicionário contendo o texto gerado e o ID do thread""""""# Converter mensagens do LangChain para o formato do HuggingFacehf_messages = []for msg in state["messages"]:Se `isinstance(msg, HumanMessage)`:hf_messages.append({"role": "user", "content": msg.content})elif isinstance(msg, AIMessage):hf_messages.append({"role": "assistant", "content": msg.content})
# Chamar a APIresposta = modelo.completar_chat(mensagens=hf_mensagens,temperature=0.5,max_tokens=64,top_p=0,7)
# Converter a resposta para o formato LangChain```python
ai_message = AIMessage(content=response.choices[0].message.content)
```return {"messages": state["messages"] + [ai_message]}```
Convertemos as mensagens do formato LangChain para o formato HuggingFace, assim podemos usar o modelo de linguagem.
Definimos uma template para as queries
class QueryRequest(BaseModel):query: strthread_id: str = "padrão"```
As consultas terão um `query`, a mensagem do usuário, e um `thread_id`, que é o identificador do fio da conversação e mais adiante explicaremos para que o utilizamos.
Criamos um grafo de LangGraph
# Definir o gráficoworkflow = StateGraph(state_schema=MessagesState)
# Defina o nódo na gráficoworkflow.add_edge(START, "model")workflow.add_node("modelo", call_model)
# Adicionar memóriamemory = MemorySaver()graph_app = workflow.compile(checkpointer=memory)```
Com isso, criamos um grafo de LangGraph, que é uma estrutura de dados que nos permite criar um chatbot e gerenciar o estado do chatbot para nós, ou seja, entre outras coisas, o histórico de mensagens. Dessa forma, não precisamos fazer isso nós mesmos.
Criamos a aplicação de FastAPI
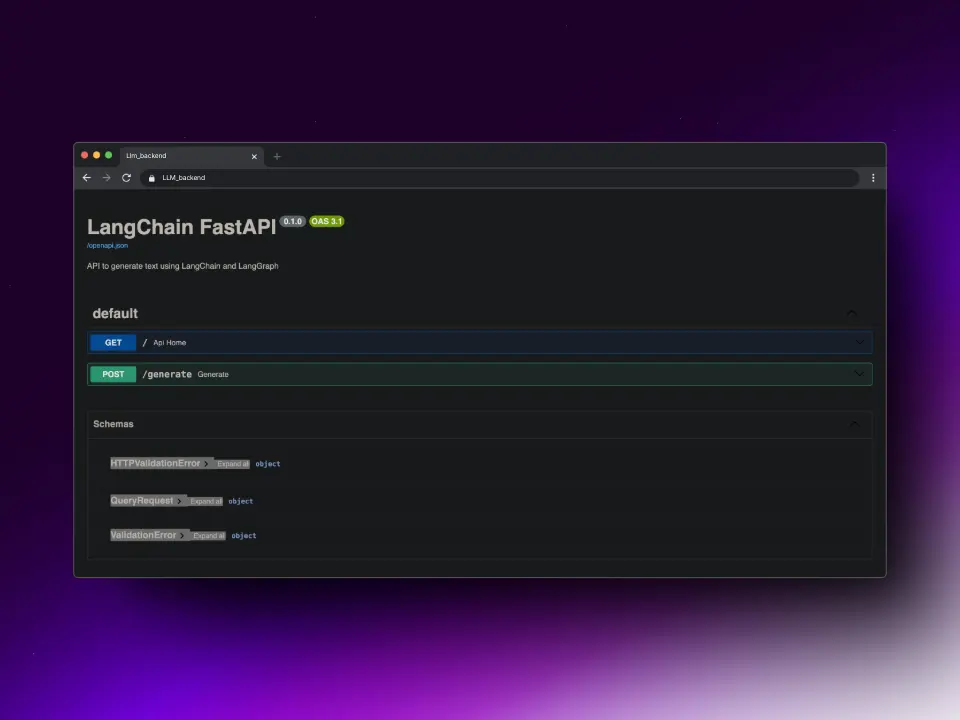
app = FastAPI(title="LangChain FastAPI", description="API para gerar texto usando LangChain e LangGraph")```
Criamos os endpoints da API
# Ponto de entrada Bem-vindo@app.get("/")async def api_home():"""Ponto de entrada Welcome"""return {"detail": "Bem-vindo ao tutorial de FastAPI, Langchain, Docker"}
# Gerar ponto final@app.post("/generate")async def gerar(request: QueryRequest):""""""Ponto final para gerar texto usando o modelo de linguagem
Argumentos:solicitação: QueryRequestquery: strthread_id: str = "padrão"
Retorna:um dicionário contendo o texto gerado e o ID do thread""""""tente:# Configurar o ID da threadconfig = {"configurable": {"thread_id": request.thread_id}}
# Crie a mensagem de entradainput_messages = [HumanMessage(content=request.query)]
# Invocar o gráficooutput = graph_app.invoke({"messages": input_messages}, config)
# Obter a resposta do modeloresposta = output["messages"][-1].conteúdo
return {"generated_text": resposta,"thread_id": request.thread_id}except Exception as e:raise HTTPException(status_code=500, detail=f"Erro ao gerar texto: {str(e)}")```
Criamos o endpoint `/` que nos retornará um texto quando acessarmos a API, e o endpoint `/generate` que é o que usaremos para gerar o texto.
Se nós olharmos para a função `generate`, temos a variável `config`, que é um dicionário que contém o `thread_id`. Este `thread_id` é o que nos permite ter um histórico de mensagens de cada usuário, desta forma, diferentes usuários podem usar o mesmo endpoint e ter seu próprio histórico de mensagens.
Por último, temos o código para que se possa executar a aplicação
if __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=7860)```
Vamos escrever todo o código juntos
from fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModeldo huggingface_hub import InferenceClient
```markdown
from langchain_core.messages import HumanMessage, AIMessage
```from langgraph.checkpoint.memory import MemorySaverfrom langgraph.graph import START, MessagesState, StateGraph
import osfrom dotenv import load_dotenvload_dotenv()
# Token da HuggingFaceHUGGINGFACE_TOKEN = os.environ.get("HUGGINGFACE_TOKEN", os.getenv("HUGGINGFACE_TOKEN"))
# Inicialize o modelo do HuggingFacemodel = InferenceClient(model="Qwen/Qwen2.5-72B-Instruct",api_key=os.getenv("HUGGINGFACE_TOKEN"))
# Defina a função que chama o modelodef chamar_modelo(estado: EstadoMensagens):""""""Chame o modelo com as mensagens fornecidas
Argumentos:estado: MensagensState
Retorna:um dicionário contendo o texto gerado e o ID do thread""""""# Converter mensagens do LangChain para o formato do HuggingFacehf_messages = []for msg in state["messages"]:if isinstance(msg, HumanMessage):hf_messages.append({"role": "user", "content": msg.content})elif isinstance(msg, AIMessage):hf_messages.append({"role": "assistant", "content": msg.content})
# Chame a APIresposta = modelo.completar_chat(mensagens=hf_mensagens,temperature=0.5,max_tokens=64,top_p=0,7)
# Converter a resposta para o formato LangChain```markdown
ai_message = AIMessage(content=response.choices[0].message.content)
```return {"messages": state["messages"] + [ai_message]}
# Definir o gráficoworkflow = StateGraph(state_schema=MessagesState)
# Defina o nó no grafoworkflow.add_edge(START, "model")workflow.add_node("modelo", call_model)
# Adicionar memóriamemory = MemorySaver()graph_app = workflow.compile(checkpointer=memory)
# Defina o modelo de dados para o pedidoclass QueryRequest(BaseModel):query: strthread_id: str = "padrão"
# Criar a aplicação FastAPIapp = FastAPI(title="LangChain FastAPI", description="API para gerar texto usando LangChain e LangGraph")
# Ponto de entrada Bem-vindo@app.get("/")async def api_home():"""Ponto de entrada Welcome"""return {"detalhe": "Bem-vindo ao tutorial de FastAPI, Langchain, Docker"}
# Gerar ponto final@app.post("/gerar")async def generate(request: QueryRequest):"""Ponto final para gerar texto usando o modelo de linguagem
Argumentos:solicitação: QueryRequestquery: strthread_id: str = "padrão"
Retorna:um dicionário contendo o texto gerado e o ID do fio"""tente:# Configurar o ID da threadconfig = {"configurable": {"thread_id": request.thread_id}}
# Criar a mensagem de entradainput_messages = [HumanMessage(content=request.query)]
# Invocar o gráficooutput = graph_app.invoke({"messages": input_messages}, config)
# Obter a resposta do modeloresposta = output["messages"][-1].conteúdo
return {"generated_text": resposta,"thread_id": request.thread_id}except Exception as e:raise HTTPException(status_code=500, detail=f"Erro ao gerar texto: {str(e)}")
if __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=7860)```
Dockerfile
Agora vemos como criar o Dockerfile
Primeiro indicamos a partir de qual imagem vamos começar
FROM python:3.13-slim```
Agora criamos o diretório de trabalho
RUN useradd -m -u 1000 userWORKDIR /app```
Copiamos o arquivo com as dependências e instalamos
COPY --chown=user ./requirements.txt requirements.txtRUN pip install --no-cache-dir --upgrade -r requirements.txt```
Copiamos o resto do código
COPY --chown=user . /app```
Exponhamos o porto 7860
EXPOSE 7860```
Criamos as variáveis de ambiente
RUN --mount=type=secret,id=HUGGINGFACE_TOKEN,mode=0444,required=true \test -f /run/secrets/HUGGINGFACE_TOKEN && echo "Segredo existe!"```
Por último, indicamos o comando para executar a aplicação
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "7860"]```
Agora colocamos tudo junto
FROM python:3.13-slim
RUN useradd -m -u 1000 userWORKDIR /app
COPY --chown=user ./requirements.txt requirements.txtRUN pip install --no-cache-dir --upgrade -r requirements.txt
COPY --chown=user . /app
EXPOSE 7860
RUN --mount=type=secret,id=HUGGINGFACE_TOKEN,mode=0444,required=true \test -f /run/secrets/HUGGINGFACE_TOKEN && echo "Segredo existe!"
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "7860"]```
requirements.txt
Criamos o arquivo com as dependências
txt
fastapiuvicornpedidospydantic>=2.0.0langchainlangchain-huggingfacelangchain-corelanggraph > 0.2.27python-dotenv.2.11```README.md
Por fim, criamos o arquivo README.md com informações sobre o espaço e as instruções para o HuggingFace.
---título: Backend do SmolLM2emoji: 📊colorFrom: amarelocolorTo: vermelhosdk: dockerpinned: falselicença: apache-2.0short_description: Backend do chat SmolLM2app_port: 7860---
# Backend do SmolLM2
Este projeto implementa uma API FastAPI que usa LangChain e LangGraph para gerar texto com o modelo Qwen2.5-72B-Instruct do HuggingFace.
## Configuração
### No HuggingFace Spaces
Este projeto está projetado para ser executado em HuggingFace Spaces. Para configurá-lo:
1. Crie um novo Espaço no HuggingFace com o SDK Docker2. Configure a variável de ambiente `HUGGINGFACE_TOKEN` ou `HF_TOKEN` na configuração do Space:- Vá para a aba "Configurações" do seu Espaço- Role para a seção "Secrets do repositório"- Adicione uma nova variável com o nome `HUGGINGFACE_TOKEN` e seu token como valor- Salve as alterações
### Desenvolvimento local
Para o desenvolvimento local:
1. Clone este repositório2. Crie um arquivo `.env` na raiz do projeto com seu token do HuggingFace:```
```HUGGINGFACE_TOKEN=seu_token_aqui```
```3. Instale as dependências:```
```pip install -r requirements.txt```
Por favor, forneça o texto em Markdown que você gostaria de traduzir para o português.
Execução local
``bashuvicorn app:app --reload``` Por favor, forneça o texto em Markdown que você gostaria de traduzir para o português.
A API estará disponível em `http://localhost:8000`.
## Endpoints
### GET `/`
Ponto final de boas-vindas que retorna uma mensagem de saudação.
### POST `/gerar`
Ponto final para gerar texto usando o modelo de linguagem.
**Parâmetros da solicitação:**``json{"query": "Sua pergunta aqui","thread_id": "identificador_de_thread_opcional"}```
Por favor, forneça o texto em markdown que você gostaria de traduzir para o português.Resposta:``json{"Texto gerado pelo modelo""thread_id": "identificador do thread"}
Por favor, forneça o texto em Markdown que deseja traduzir para o português.
## Docker
Para executar a aplicação em um contêiner Docker:
``bash# Construa a imagemdocker build -t smollm2-backend .
# Executar o contêinerdocker run -p 8000:8000 --env-file .env smollm2-backend```Documentação da API
A documentação interativa da API está disponível em:- Swagger UI: http://localhost:8000/docs- ReDoc: `http://localhost:8000/redoc%60%60%60%60
Token do HuggingFace
Se você notou no código e no Dockerfile, usamos um token do HuggingFace, então vamos ter que criar um. Em nossa conta do HuggingFace, criamos um novo token, damos um nome a ele e concedemos as seguintes permissões:
- Acesso de leitura aos conteúdos de todos os repositórios sob o seu namespace pessoal* Acesso de leitura aos conteúdos de todos os repositórios sob seu namespace pessoal* Fazer chamadas para provedores de inferência* Fazer chamadas para Pontos de Extremidade de Inferência
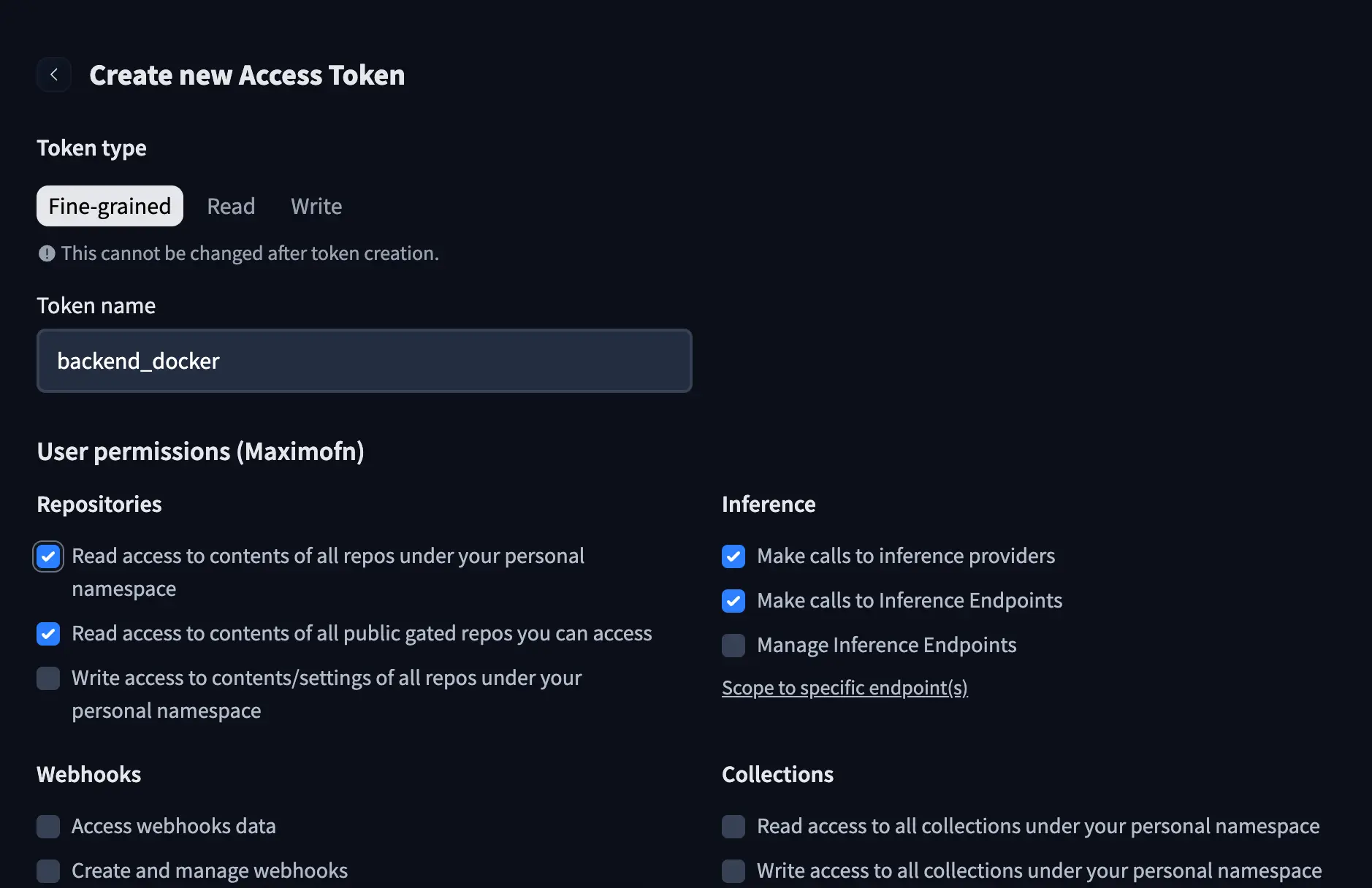
Adicionar o token aos secrets do espaço
Agora que já temos o token, precisamos adicioná-lo ao espaço. Na parte superior do aplicativo, poderemos ver um botão chamado Settings, clicamos nele e poderemos ver a seção de configuração do espaço.
Se formos para baixo, poderemos ver uma seção onde podemos adicionar Variables e Secrets. Neste caso, como estamos adicionando um token, vamos adicioná-lo aos Secrets.
Damos o nome HUGGINGFACE_TOKEN e o valor do token.
Implantação
Se nós clonamos o espaço, temos que fazer um commit e um push. Se modificamos os arquivos no HuggingFace, basta salvá-los.
Então, quando as alterações estiverem no HuggingFace, teremos que esperar alguns segundos para que o espaço seja construído e possamos usá-lo.
Neste caso, construímos apenas um backend, portanto o que vamos ver ao entrar no espaço é o que definimos no endpoint / 
URL do backend
Precisamos saber a URL do backend para poder fazer chamadas à API. Para isso, temos que clicar nos três pontos no canto superior direito para ver as opções.
No menu suspenso, clicamos em Embed this Spade. Será aberta uma janela indicando como incorporar o espaço com um iframe e também fornecerá a URL do espaço.
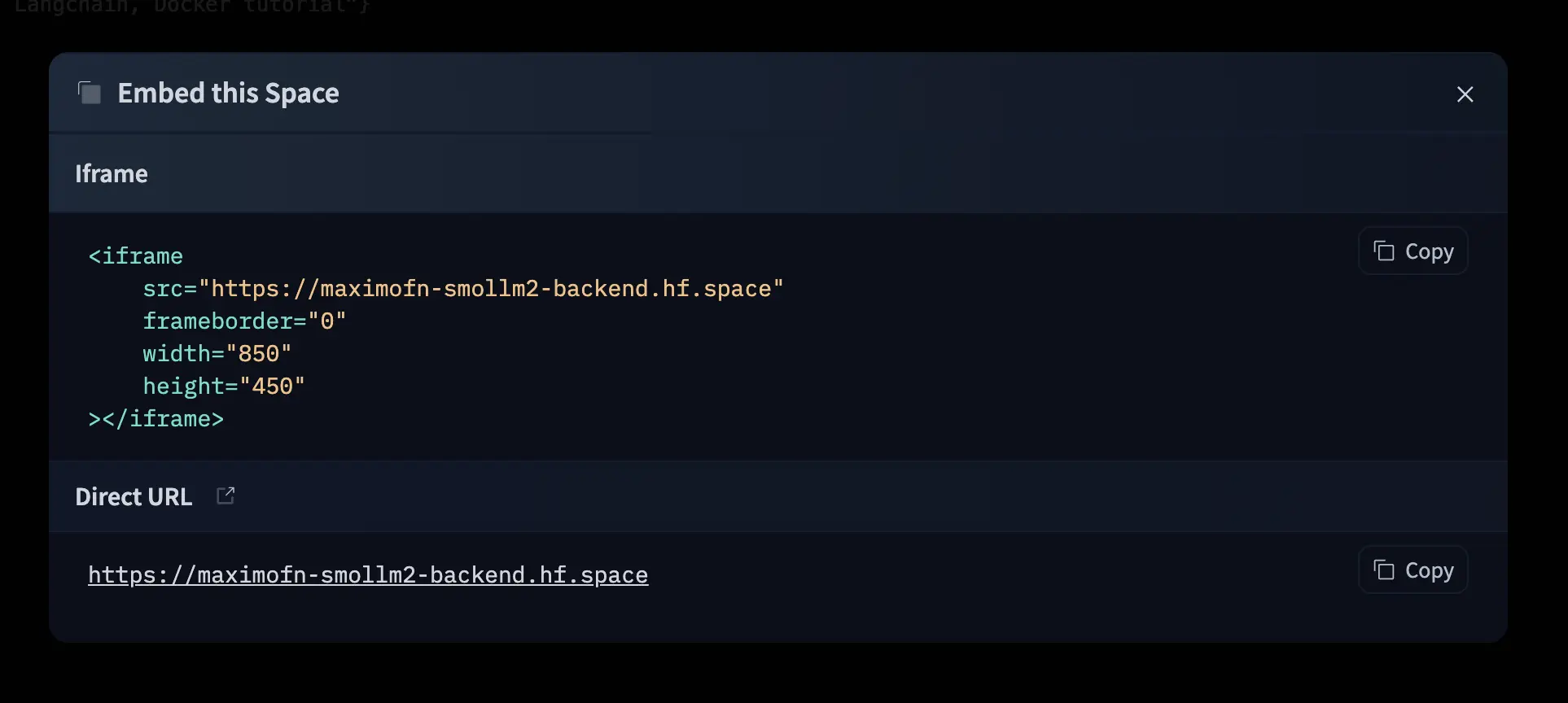
Se agora formos para essa URL, veremos o mesmo que no espaço.
Documentação
FastAPI, além de ser uma API extremamente rápida, tem outra grande vantagem: gera documentação automaticamente.
Se adicionarmos /docs à URL que vimos anteriormente, poderemos visualizar a documentação da API com o Swagger UI.
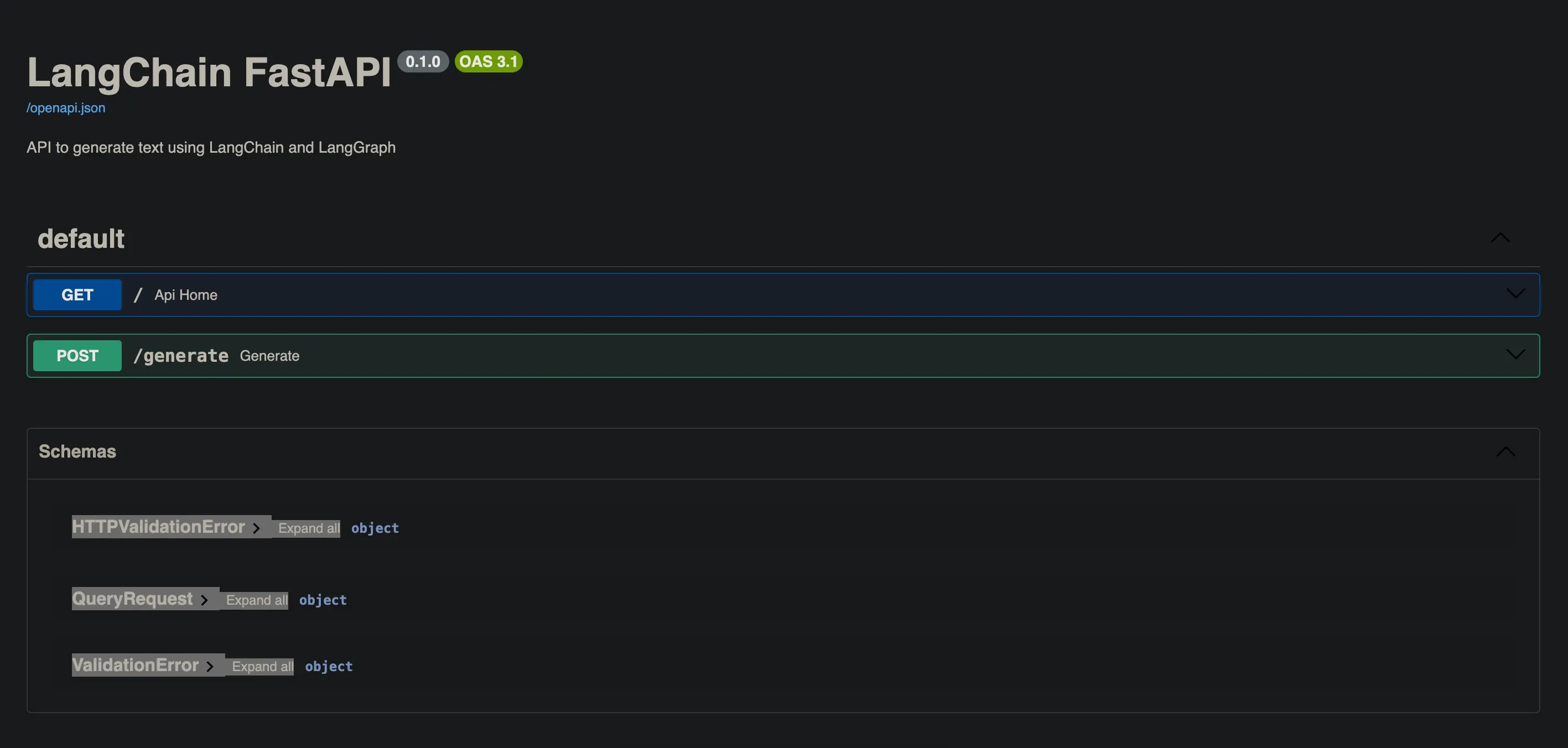
Também podemos adicionar /redoc à URL para ver a documentação com ReDoc.
Teste da API
O bom da documentação Swagger UI é que nos permite testar a API diretamente do navegador.
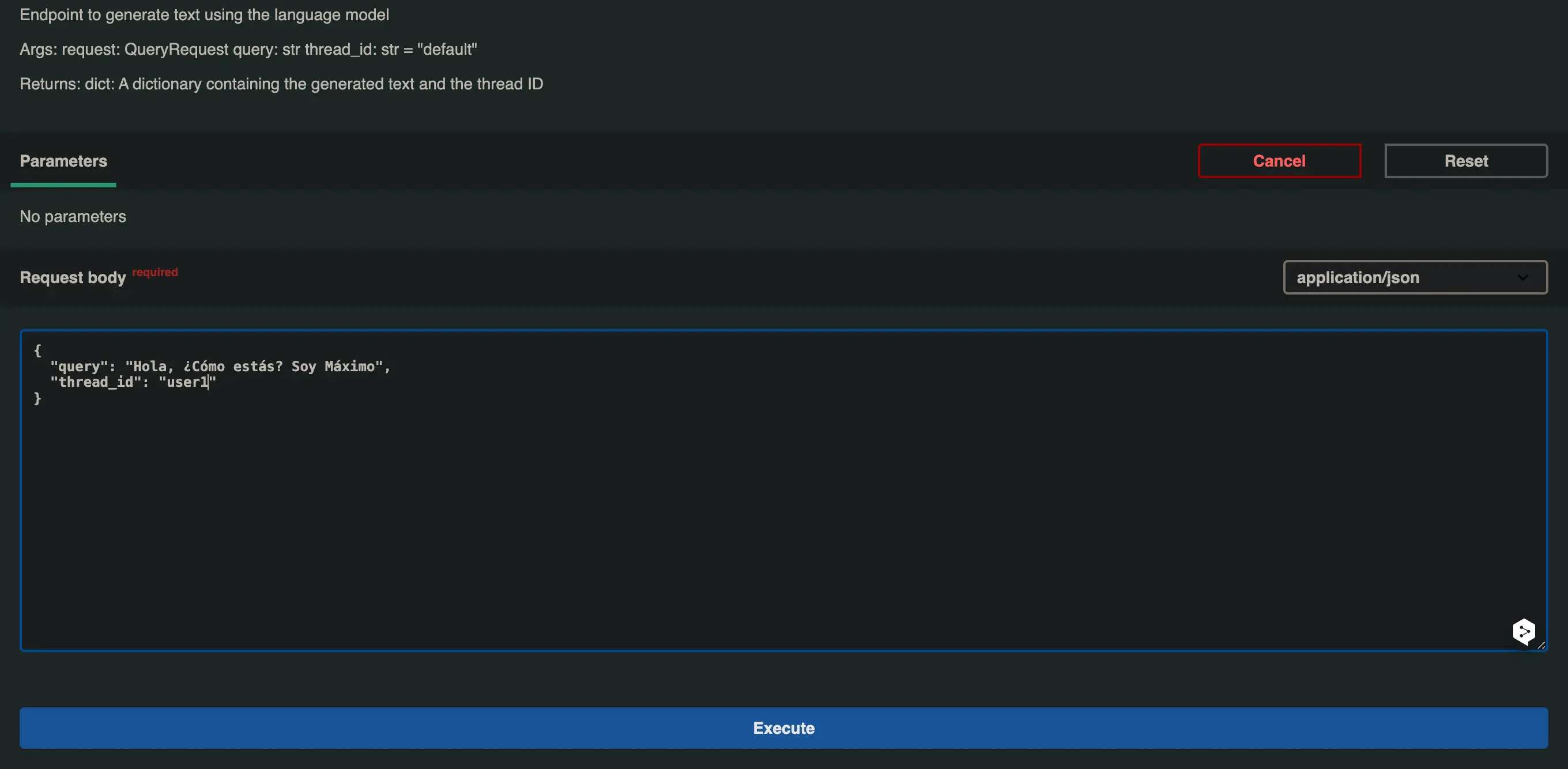
Adicionamos /docs à URL que obtivemos, abrimos o menu suspenso do endpoint /generate e clicamos em Try it out, modificamos o valor da query e do thread_id e clicamos em Execute.
No primeiro caso vou colocar
- query: Olá, como você está? Sou Máximo* thread_id: user1
Recebemos a seguinte resposta Olá Máximo! Estou muito bem, obrigado por perguntar. Como você está? Em que posso ajudar hoje? 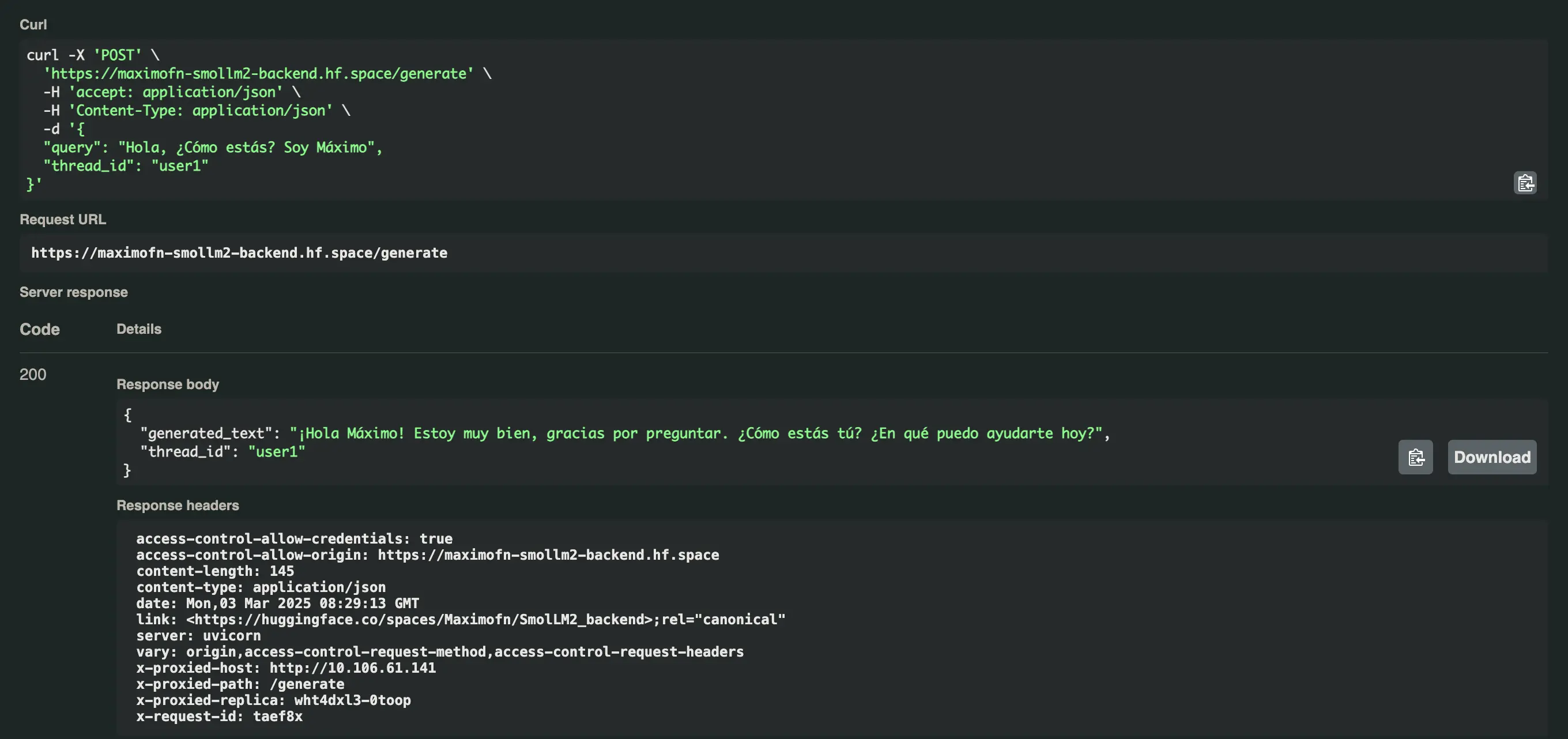
Vamos testar agora a mesma pergunta, mas com um thread_id diferente, neste caso user2.
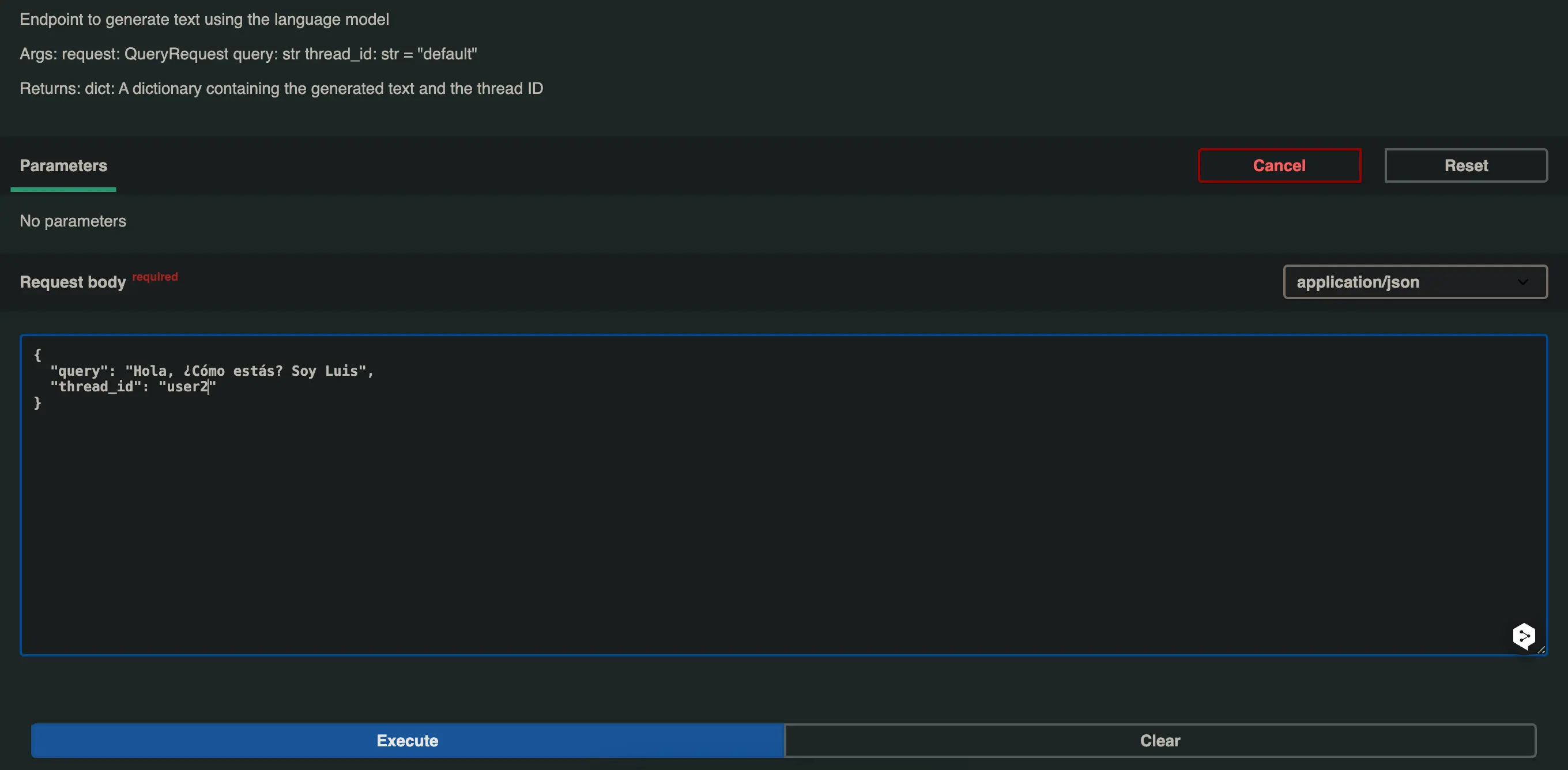
E nos responde isso Olá Luis! Estou muito bem, obrigado por perguntar. Como você está? No que posso ajudar hoje? 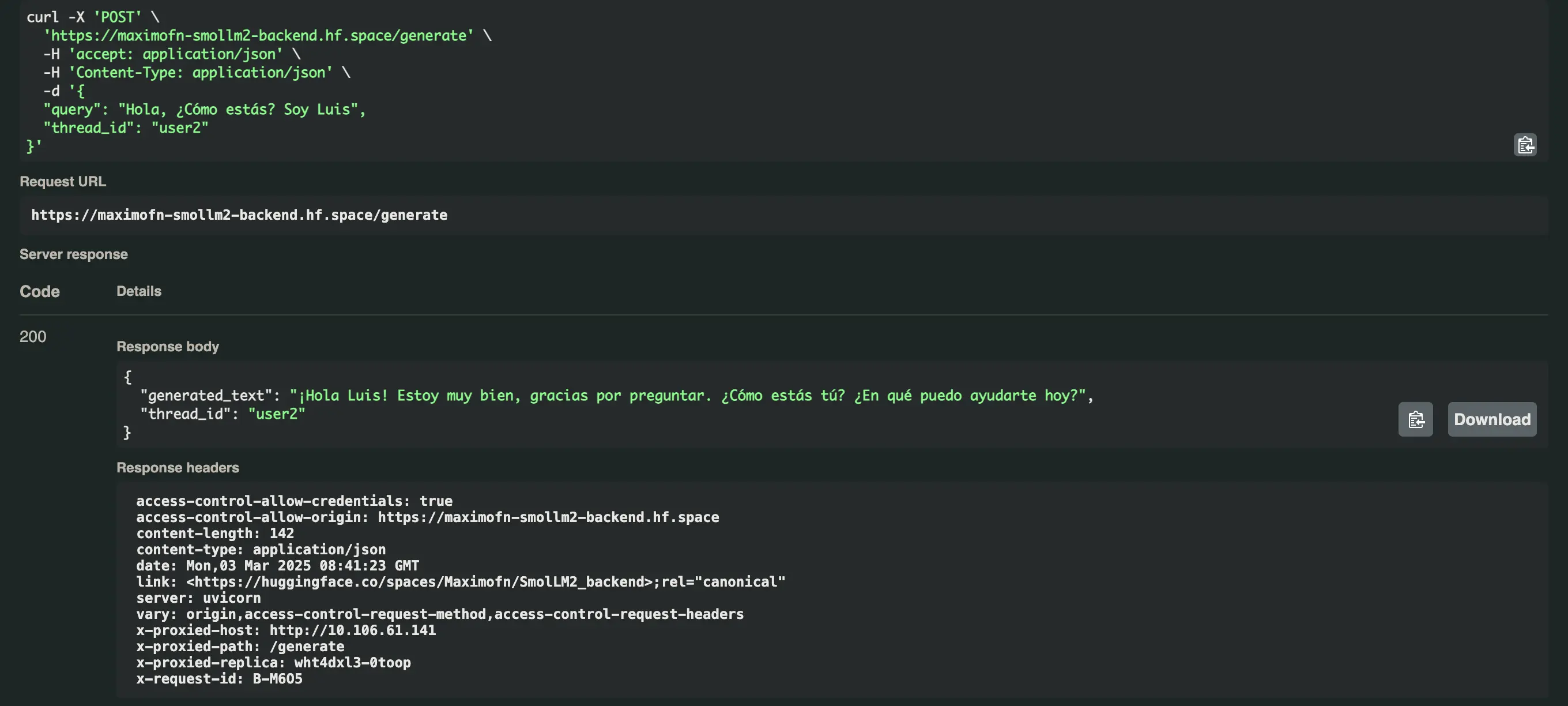
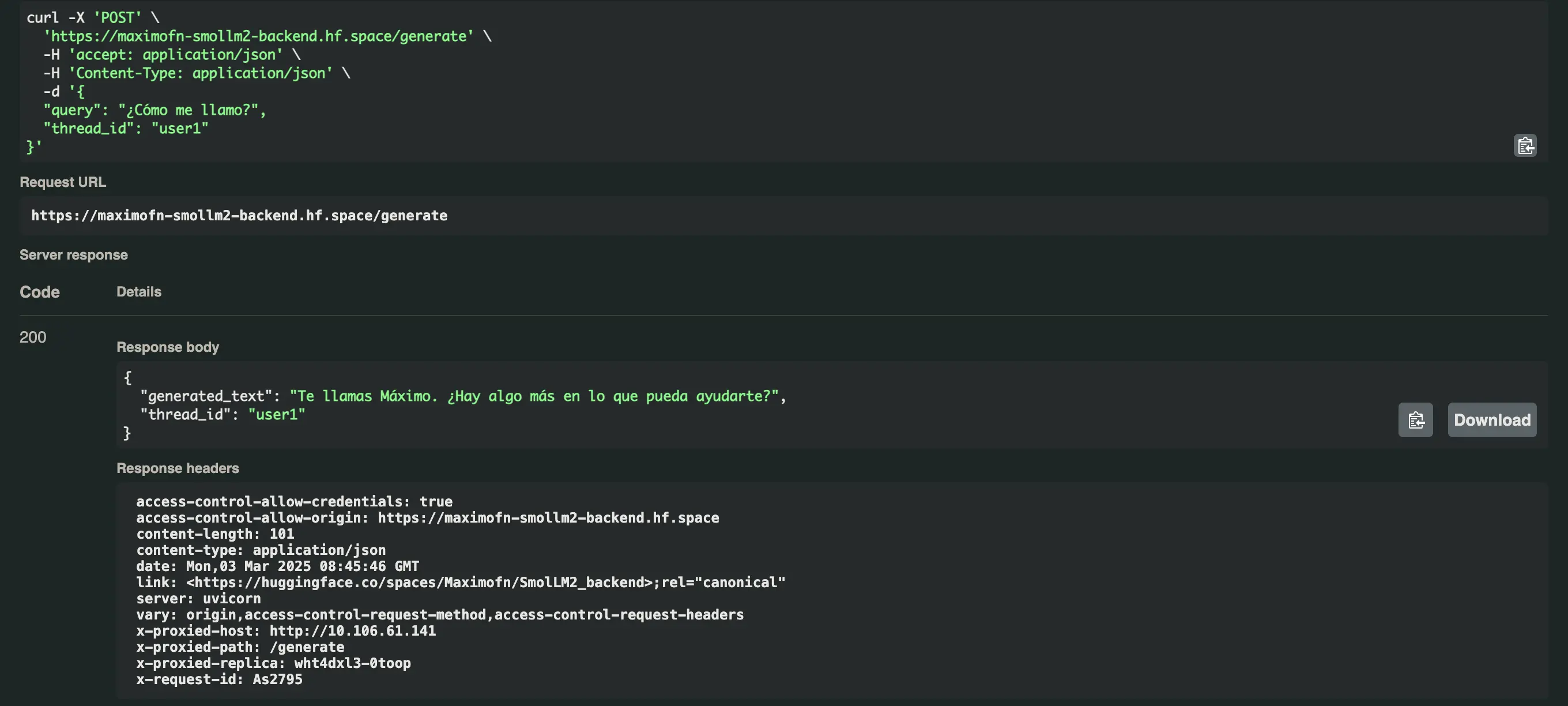
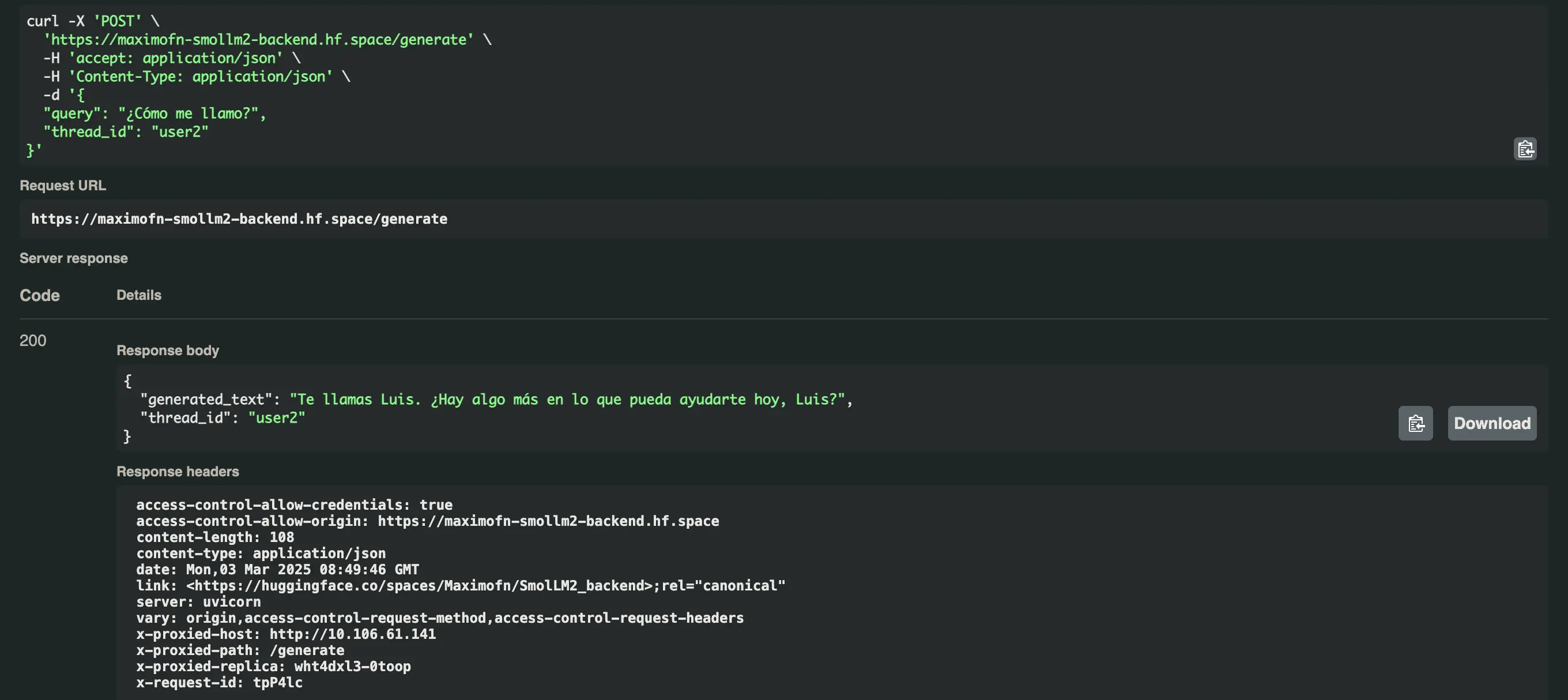
Agora pedimos nosso nome com os dois usuários e obtemos isso
- Para o usuário user1:
Você se chama Máximo. Há algo mais em que eu possa ajudar você?* Para o usuário user2:Você se chama Luis. Há mais alguma coisa em que eu possa ajudá-lo hoje, Luis?
Deploy do backend com Gradio e modelo rodando no servidor
Os dois backends que criamos na verdade não estão executando um modelo, mas sim fazendo chamadas para Inference Endpoints da HuggingFace. Mas pode ser que queiramos que tudo rode no servidor, inclusive o modelo. Pode ser que você tenha feito um fine-tuning de um LLM para seu caso de uso, por isso já não pode fazer chamadas para Inference Endpoints. Então vamos ver como modificar o código dos dois backends para executar um modelo no servidor e não fazer chamadas para Inference Endpoints.
Criar Espaço
Na hora de criar o space no HuggingFace fazemos o mesmo que antes, criamos um novo space, colocamos um nome e uma descrição, selecionamos Gradio como SDK, selecionamos o HW em que vamos deployar, no meu caso selecionei o HW mais básico e gratuito, e selecionamos se o faremos privado ou público.
Código
Temos que fazer alterações em app.py e em requirements.txt para que, em vez de fazer chamadas a Inference Endpoints, o modelo seja executado localmente.
app.py
As mudanças que temos que fazer são
Importar AutoModelForCausalLM e AutoTokenizer da biblioteca transformers e importar torch
from transformers import AutoModelForCausalLM, AutoTokenizerimport torch```
Em vez de criar um modelo com InferenceClient, criamos com AutoModelForCausalLM e AutoTokenizer.
# Carregar o modelo e o tokenizermodel_name = "HuggingFaceTB/SmolLM2-1.7B-Instruct"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(nome_do_modelo,torch_dtype=torch.float16,device_map="auto")```
Utilizo `HuggingFaceTB/SmolLM2-1.7B-Instruct` porque é um modelo bastante capaz com apenas 1.7B de parâmetros. Como escolhi o hardware mais básico, não posso usar modelos muito grandes. Você, se quiser usar um modelo maior, tem duas opções: usar o hardware gratuito e aceitar que a inferência será mais lenta, ou usar um hardware mais potente, mas pago.
Modificar a função respond para que construa o prompt com a estrutura necessária pela biblioteca transformers, tokenizar o prompt, fazer a inferência e destokenizar a resposta.
def responder(mensagem,histórico: list[tuple[str, str]],Mensagem do sistema,max_tokens,temperatura,top_p,):# Construir o prompt com o formato corretoprompt = f"<|system|>\n{system_message}</s>\n"
for val in history:if val[0]:prompt += f"<|user|>\n{val[0]}</s>\n"if val[1]:prompt += f"<|assistant|>\n{val[1]}</s>\n"
prompt += f"<|user|>\n{message}</s>\n<|assistant|>\n"
# Tokenizar o promptinputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Gerar a respostaoutputs = model.generate(**entradas,**max_new_tokens=max_tokens,temperature=temperature,top_p=top_p,do_sample=True,pad_token_id=tokenizer.eos_token_id)
# Decodificar a respostaresponse = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Extrair apenas a parte da resposta do assistenteresponse = response.split("<|assistant|>\n")[-1].strip()
yield response```
A seguir deixo todo o código
import gradio as grfrom transformers import AutoModelForCausalLM, AutoTokenizerimport torch
""""""Para mais informações sobre o suporte à API de Inferência do `huggingface_hub`, consulte a documentação: https://huggingface.co/docs/huggingface_hub/v0.22.2/en/guides/inference""""""
# Carregar o modelo e o tokenizermodel_name = "HuggingFaceTB/SmolLM2-1.7B-Instruct"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(nome_do_modelo,torch_dtype=torch.float16,device_map="auto")
def responder(mensagem,história: list[tuple[str, str]],Mensagem do sistema,max_tokens,temperatura,top_p,):# Construir o prompt com o formato corretoprompt = f"<|system|>\n{system_message}</s>\n"
for val in history:if val[0]:prompt += f"<|user|>\n{val[0]}</s>\n"if val[1]:prompt += f"<|assistant|>\n{val[1]}</s>\n"
prompt += f"<|user|>\n{message}</s>\n<|assistant|>\n"
# Tokenizar o promptinputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Gerar a respostasaídas = modelo.gerar(**entradas,**max_new_tokens=max_tokens,temperature=temperature,top_p=top_p,do_sample=True,pad_token_id=tokenizer.eos_token_id)
# Decodificar a respostaresponse = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Extrair apenas a parte da resposta do assistenteresponse = response.split("<|assistant|>\n")[-1].strip()
yield response
""""""Para informações sobre como personalizar o ChatInterface, consulte a documentação do Gradio: https://www.gradio.app/docs/chatinterface""""""demo = gr.ChatInterface(responda,```markdown
additional_inputs=[
```gr.Textbox(value="Você é um Chatbot amigável. Sempre responda na língua em que o usuário está escrevendo para você."rótulo="Mensagem do sistema"),gr.Slider(minimum=1, maximum=2048, value=512, step=1, label="Máximo de novos tokens"),gr.Slider(mínimo=0,1, máximo=4,0, valor=0,7, passo=0,1, rótulo="Temperatura"),gr.Slider()mínimo=0.1,máximo=1.0,value=0.95,passo=0.05,label="Top-p (amostragem do núcleo)"),],)
if __name__ == "__main__":demo.launch()```
requirements.txt
Neste arquivo, devemos adicionar as novas bibliotecas que vamos utilizar, neste caso transformers, accelerate e torch. O arquivo completo ficaria:
txt
huggingface_hub==0.25.2gradio>=4.0.0transformers>=4.36.0torch>=2.0.0accelerate>=0.25.0```Teste da API
Desplegamos o space e testamos diretamente a API.
from gradio_client import Clientclient = Client("Maximofn/SmolLM2_localModel")result = client.predict(message="Hola, ¿cómo estás? Me llamo Máximo",system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")print(result)
Loaded as API: https://maximofn-smollm2-localmodel.hf.space ✔Hola Máximo, soy su Chatbot amable y estoy funcionando bien. Gracias por tu mensaje, me complace ayudarte hoy en día. ¿Cómo puedo servirte?
Surpreende-me o quão rápido o modelo responde, mesmo estando em um servidor sem GPU.
Deploy de backend com FastAPI, Langchain e Docker e modelo rodando no servidor
Agora fazemos o mesmo que antes, mas com FastAPI, LangChain e Docker.
Criar Espaço
Ao criar o space no HuggingFace, fazemos o mesmo que antes: criamos um novo espaço, colocamos um nome e uma descrição, selecionamos Docker como SDK, escolhemos o HW em que vamos implantá-lo, no meu caso, escolho o HW mais básico e gratuito, e decidimos se o faremos privado ou público.
Código
app.py
Já não importamos InferenceClient e agora importamos AutoModelForCausalLM e AutoTokenizer da biblioteca transformers e importamos torch.
from transformers import AutoModelForCausalLM, AutoTokenizerimport torch```
Instanciamos o modelo e o tokenizer com AutoModelForCausalLM e AutoTokenizer.
# Inicialize o modelo e o tokenizadorprint("Carregando modelo e tokenizer...")dispositivo = "cuda" if torch.cuda.is_available() else "cpu"model_name = "HuggingFaceTB/SmolLM2-1.7B-Instruct"
tente:# Carregar o modelo no formato BF16 para melhor desempenho e menor uso de memóriatokenizer = AutoTokenizer.from_pretrained(model_name)
if device == "cuda":print("Usando GPU para o modelo...")model = AutoModelForCausalLM.from_pretrained(nome_do_modelo,torch_dtype=torch.bfloat16,device_map="auto",low_cpu_mem_usage=True)else:print("Usando CPU para o modelo...")model = AutoModelForCausalLM.from_pretrained(nome_do_modelo,device_map={"": device},torch_dtype=torch.float32)
print(f"Modelo carregado com sucesso em: {device}")except Exception as e:print(f"Erro ao carregar o modelo: {str(e)}")aumentar```
Re definimos a função call_model para que faça a inferência com o modelo local.
# Defina a função que chama o modelodef chamar_modelo(estado: EstadoMensagens):"""Chame o modelo com as mensagens fornecidas
Argumentos:estado: EstadoMensagens
Retorna:dicionário: Um dicionário contendo o texto gerado e o ID do thread""""""# Converter mensagens LangChain para formato de bate-papomensagens = []for msg in state["messages"]:if isinstance(msg, HumanMessage):messages.append({"role": "user", "content": msg.content})elif isinstance(msg, AIMessage):messages.append({"role": "assistant", "content": msg.content})
# Prepare o input usando o modelo de bate-papoinput_text = tokenizer.apply_chat_template(messages, tokenize=False)inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
# Gerar respostasaídas = modelo.gerar(entradas,max_new_tokens=512, # Aumente o número de tokens para respostas mais longastemperature=0.7,top_p=0,9,do_sample=True,pad_token_id=tokenizer.eos_token_id)
# Decodificar e limpar a respostaresponse = tokenizer.decode(outputs[0], skip_special_tokens=True)# Extrair apenas a resposta do assistente (após a última mensagem do usuário)response = response.split("Assistant:")[-1].strip()
# Converter a resposta para o formato LangChain```markdown
ai_message = AIMessage(content=response)
```return {"messages": state["messages"] + [ai_message]}```
requirements.txt
Temos que remover langchain-huggingface e adicionar transformers, accelerate e torch no arquivo requirements.txt. O arquivo ficaria:
txt
fastapiuvicornsolicitaçõespydantic>=2.0.0langchain>=0.1.0langchain-core>=0.1.10langgraph>=0.2.27python-dotenv>=1.0.0transformers>=4.36.0torch>=2.0.0accelerate>=0.26.0```Dockerfile
Já não precisamos ter RUN --mount=type=secret,id=HUGGINGFACE_TOKEN,mode=0444,required=true porque como o modelo vai estar no servidor e não vamos fazer chamadas para Inference Endpoints, não precisamos do token. O arquivo ficaria:
FROM python:3.13-slim
RUN useradd -m -u 1000 userWORKDIR /app
COPY --chown=user ./requirements.txt requirements.txtRUN pip install --no-cache-dir --upgrade -r requirements.txt
COPY --chown=user . /app
EXPOSE 7860
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "7860"]```
Teste da API
Deployamos o space e testamos a API. Neste caso, vou testar diretamente do Python.
import requestsurl = "https://maximofn-smollm2-backend-localmodel.hf.space/generate"data = {"query": "Hola, ¿cómo estás?","thread_id": "user1"}response = requests.post(url, json=data)if response.status_code == 200:result = response.json()print("Respuesta:", result["generated_text"])print("Thread ID:", result["thread_id"])else:print("Error:", response.status_code, response.text)
Respuesta: systemYou are a friendly Chatbot. Always reply in the language in which the user is writing to you.userHola, ¿cómo estás?assistantEstoy bien, gracias por preguntar. Estoy muy emocionado de la semana que viene.Thread ID: user1
Este demora um pouco mais que o anterior. Na verdade, demora o normal para um modelo sendo executado em um servidor sem GPU. O estranho é quando o deployamos no Gradio. Não sei o que a HuggingFace faz por trás, ou talvez tenha sido coincidência.
Conclusões
Vimos como criar um backend com um LLM, tanto fazendo chamadas ao Inference Endpoint da HuggingFace, quanto fazendo chamadas a um modelo rodando localmente. Vimos como fazer isso com Gradio ou com FastAPI, Langchain e Docker.
A partir daqui você tem o conhecimento para poder implantar seus próprios modelos, mesmo que não sejam LLMs, podem ser modelos multimodais. A partir daqui você pode fazer o que quiser.