
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
No artigo GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers é exposta a necessidade de criar um método de quantização pós-treinamento que não degrade a qualidade do modelo. Neste post, vimos o método llm.int8() que quantiza para INT8 alguns vetores das matrizes de pesos, desde que nenhum dos seus valores ultrapasse um valor limite, o que é muito bom, mas não quantiza todos os pesos do modelo. Neste artigo, propõem-se um método que quantiza todos os pesos do modelo para 4 e 3 bits, sem degradar a qualidade do modelo. Isso representa uma economia considerável de memória, não apenas porque todos os pesos são quantizados, mas também porque isso é feito em 4, 3 bits (e até 1 e 2 bits em certas condições), em vez de 8 bits.
Trabalhos nos quais se baseia
Quantização por camadas
Por um lado, baseiam-se nos trabalhos Nagel et al., 2020; Wang et al., 2020; Hubara et al., 2021 e Frantar et al., 2022, que propõem quantizar os pesos das camadas de uma rede neural para 4 e 3 bits, sem degradar a qualidade do modelo.
Dado um conjunto de dados m proveniente de um dataset, a cada camada l são fornecidos os dados e obtém-se a saída dos pesos W dessa camada. Portanto, o que se faz é buscar pesos novos Ŵ quantizados que minimizem o erro quadrático em relação à saída da camada de precisão total.
argmin_Ŵ||WX− ŴX||^2
Os valores de Ŵ são estabelecidos antes de realizar o processo de quantização e durante o processo, cada parâmetro de Ŵ pode mudar de valor independentemente sem depender do valor dos demais parâmetros de Ŵ.
Quantização ótima do cérebro (OBC)
No trabalho de OBQ de Frantar et al., 2022 otimizam o processo de quantização por camadas anterior, tornando-o até 3 vezes mais rápido. Isso ajuda com os modelos grandes, pois quantizar um modelo grande pode levar muito tempo.
O método OBQ é uma abordagem para resolver o problema de quantização em camadas em modelos de linguagem. OBQ parte da ideia de que o erro quadrático pode ser decomposto na soma de erros individuais para cada linha da matriz de pesos. Em seguida, o método quantiza cada peso de forma independente, atualizando sempre os pesos não quantizados para compensar o erro incorrido pela quantização.
O método é capaz de quantificar modelos de tamanho médio em tempos razoáveis, mas como é um algoritmo de complexidade cúbica, torna-se extremamente custoso aplicá-lo a modelos com bilhões de parâmetros.
Algoritmo de GPTQ
Passo 1: Informação em ordem arbitrária
Em OBQ buscava-se a linha de pesos que criasse o menor erro quadrático médio para quantizar, mas percebeu-se que ao fazê-lo de maneira aleatória não aumentava muito o erro quadrático médio final. Por isso, em vez de buscar a linha que minimiza o erro quadrático médio, o que criava uma complexidade cúbica no algoritmo, sempre se faz na mesma ordem. Graças a isso, reduz-se muito o tempo de execução do algoritmo de quantização.
Passo 2: Atualizações em lote preguiçosas
Ao fazer a atualização dos pesos linha a linha, isso causa um processo lento e não aproveita totalmente o hardware.
Passo 3: Reformulação de Cholesky
O problema de fazer as atualizações em lotes é que, devido à grande escala dos modelos, podem ocorrer erros numéricos que afetam a precisão do algoritmo. Especificamente, podem ser obtidas matrizes indefinidas, o que faz com que o algoritmo atualize os pesos restantes em direções incorretas, resultando em uma quantização muito ruim.
Para resolver isso, os autores do artigo propõem usar uma reformulação de Cholesky, que é um método numericamente mais estável.
Resultados do GPTQ
A seguir estão duas gráficas com a medida da perplexidade (perplexity) no dataset WikiText2 para todos os tamanhos dos modelos OPT e BLOOM. Pode-se ver que com a técnica de quantização RTN, a perplexidade em alguns tamanhos aumenta muito, enquanto com GPTQ mantém-se similar à obtida com o modelo em FP16.
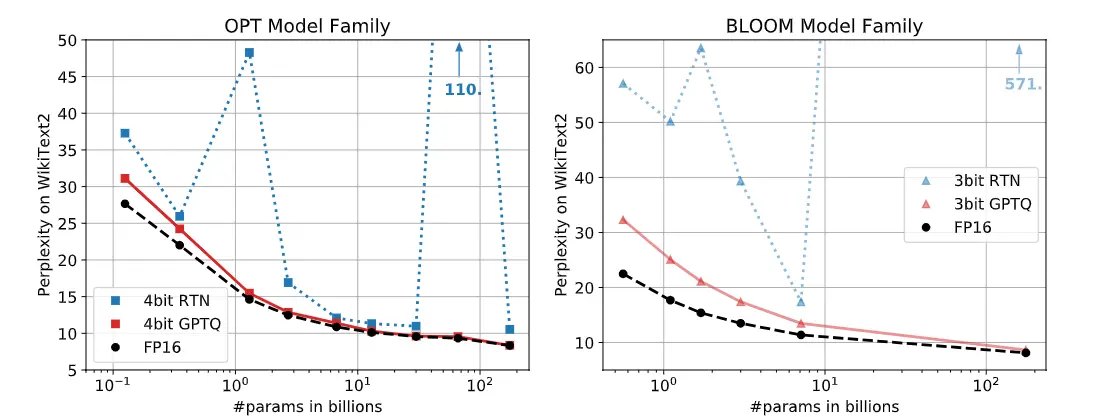
A seguir estão mostradas outras gráficas, mas com a medida do accuracy no dataset LAMBADA. Ocorre o mesmo, enquanto GPTQ mantém-se semelhante ao obtido com FP16, outros métodos de quantização degradam muito a qualidade do modelo
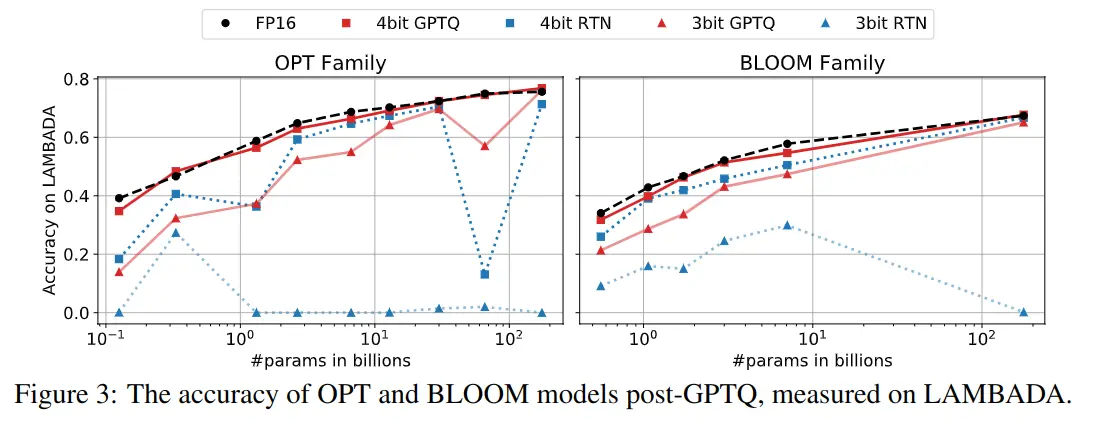
Quantização extrema
Nos gráficos anteriores foram mostrados os resultados da quantização do modelo para 3 e 4 bits, mas podemos quantizá-los para 2 bits, e até mesmo para apenas 1 bit.
Modificando o tamanho dos batches ao utilizar o algoritmo, podemos obter bons resultados quantizando tanto o modelo
| Modelo | FP16 | g128 | g64 | g32 | 3 bits |
|---|---|---|---|---|---|
| OPT-175B | 8,34 | 9,58 | 9,18 | 8,94 | 8,68 |
| BLOOM | 8,11 | 9,55 | 9,17 | 8,83 | 8,64 |
Na tabela anterior, pode-se ver o resultado da perplexidade no conjunto de dados WikiText2 para os modelos OPT-175B e BLOOM quantizados a 3 bits. Pode-se observar que à medida que se usam lotes menores, a perplexidade diminui, o que significa que a qualidade do modelo quantizado é melhor. No entanto, isso tem o problema de que o algoritmo leva mais tempo para ser executado.
Desquantização dinâmica na inferência
Durante a inferência, algo chamado descuantificação dinâmica (dynamic dequantization) é realizada para permitir a inferência. Cada camada é descuantificada à medida que passa por elas.
Para isso, eles desenvolveram um kernel que desquantiza as matrizes e realiza os produtos matriciais. Embora a desquantização consuma mais cálculos, o kernel precisa acessar muito menos memória, o que gera acelerações significativas.
A inferência é realizada em FP16, desquantizando os pesos à medida que se passa pelas camadas e a função de ativação de cada camada também é realizada em FP16. Embora isso faça com que seja necessário realizar mais cálculos, pois é preciso desquantizar, esses cálculos fazem com que o processo total seja mais rápido, porque menos dados precisam ser trazidos da memória. É necessário trazer da memória os pesos em menos bits, de forma que, no final, em matrizes com muitos parâmetros, isso resulta em uma economia significativa de dados. O gargalo normalmente está em trazer os dados da memória, portanto, mesmo que seja necessário realizar mais cálculos, a inferência acaba sendo mais rápida.
Velocidade de inferência
Os autores do paper realizaram um teste quantizando o modelo BLOOM-175B para 3 bits, o que ocupava cerca de 63 GB de memória VRAM, incluindo os embeddings e a camada de saída que permanecem em FP16. Além disso, manter a janela de contexto de 2048 tokens consome cerca de 9 GB de memória, o que totaliza aproximadamente 72 GB de memória VRAM. Eles quantizaram para 3 bits e não para 4 para poder realizar este experimento e fazer o modelo caber em uma única GPU Nvidia A100 com 80 GB de memória VRAM.
Para comparação, a inferência normal em FP16 requer cerca de 350 GB de memória VRAM, o que equivale a 5 GPUs Nvidia A100 com 80 GB de memória VRAM. E a inferência quantizando para 8 bits usando llm.int8() requer 3 dessas GPUs.
A seguir, está apresentada uma tabela com a inferência do modelo em FP16 e quantizado para 3 bits em GPUs Nvidia A100 com 80 GB de memória VRAM e Nvidia A6000 com 48 GB de memória VRAM.
| GPU (VRAM) | tempo médio por token em FP16 (ms) | tempo médio por token em 3 bits (ms) | Aceleração | Redução de GPUs necessárias |
|---|---|---|---|---|
| A6000 (48GB) | 589 | 130 | ×4,53 | 8→ 2 |
| A100 (80GB) | 230 | 71 | ×3,24 | 5→ 1 |
Por exemplo, utilizando os kernels, o modelo OPT-175B de 3 bits é executado em uma única A100 (em vez de 5) e é aproximadamente 3,25 vezes mais rápido que a versão FP16 em termos de tempo médio por token.
A GPU NVIDIA A6000 tem uma largura de banda de memória muito menor, portanto, esta estratégia é ainda mais eficaz: executar o modelo OPT-175B de 3 bits em 2 GPUs A6000 (em vez de 8) é aproximadamente 4,53 vezes mais rápido que a versão FP16.
Bibliotecas
Os autores do paper implementaram a biblioteca GPTQ. Outras bibliotecas foram criadas, como GPTQ-for-LLaMa, exllama e llama.cpp. No entanto, essas bibliotecas se concentram apenas na arquitetura llama, por isso a biblioteca AutoGPTQ foi a que ganhou mais popularidade porque possui uma cobertura mais ampla de arquiteturas.
Por isso, a biblioteca AutoGPTQ foi integrada por meio de uma API dentro da biblioteca transformers. Para poder usá-la, é necessário instalá-la conforme indicado na seção Installation do seu repositório e ter a biblioteca optimun instalada.
Além de fazer o que indicam na seção Installation do seu repositório, também é recomendável fazer o seguinte:
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip install .Para que se instalem os kernels de quantização na GPU que os autores do paper desenvolveram.
Quantização de um modelo
Vamos ver como quantizar um modelo com a biblioteca optimun e a API de AutoGPTQ.
Inferência do modelo não quantizado
Vamos quantizar o modelo meta-llama/Meta-Llama-3-8B-Instruct que, como seu nome indica, é um modelo de 8B de parâmetros, portanto em FP16 precisaríamos de 16 GB de memória VRAM. Primeiro executamos o modelo para ver a memória que ele ocupa e a saída que gera
Como precisamos pedir permissão à Meta para usar esse modelo, fazemos login no Hugging Face para poder baixar o tokenizador e o modelo.
from huggingface_hub import notebook_loginnotebook_login()Copied
Instanciamos o tokenizador e o modelo
from transformers import AutoModelForCausalLM, AutoTokenizerimport torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")checkpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForCausalLM.from_pretrained(checkpoint).half().to(device)Copied
Vamos ver a memória que ocupa em FP16
model_memory = model.get_memory_footprint()/(1024**3)print(f"Model memory: {model_memory:.2f} GB")Copied
Model memory: 14.96 GB
Vemos que ocupa quase 15 GB, mais ou menos os 16 GB que havíamos dito que deveria ocupar, mas por que essa diferença? Provavelmente esse modelo não tem exatamente 8B de parâmetros, mas sim um pouco menos, mas na hora de indicar o número de parâmetros arredonda-se para 8B.
Fazemos uma inferência para ver como ele faz e o tempo que leva
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model.device)t0 = time.time()max_new_tokens = 50outputs = model.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer at a startup in the Bay Area. I am passionate about building AI systems that can help humans make better decisions and improve their lives.I have a background in computer science and mathematics, and I have been working with machine learning for several years. IInference time: 4.14 s
Quantização do modelo para 4 bits
Vamos quantizá-lo para 4 bits. Reinicio o notebook para não ter problemas de memória, então precisamos fazer login novamente no Hugging Face.
from huggingface_hub import notebook_loginnotebook_login()Copied
Primeiro crio o tokenizador
from transformers import AutoTokenizercheckpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Agora criamos a configuração de quantização. Como dissemos, este algoritmo calcula o erro dos pesos quantizados em relação aos originais com base nas entradas de um conjunto de dados, portanto, na configuração, precisamos especificar com qual conjunto de dados queremos quantizar o modelo.
Os disponíveis por padrão são wikitext2, c4, c4-new, ptb e ptb-new.
Também podemos criar nós um dataset a partir de uma lista de strings
dataset = ["o auto-gptq é uma biblioteca de quantização de modelos fácil de usar com APIs amigáveis ao usuário, baseada no algoritmo GPTQ."]Além disso, temos que informar o número de bits do modelo quantizado por meio do parâmetro bits
from transformers import GPTQConfigquantization_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)Copied
Quantizamos o modelo
from transformers import AutoModelForCausalLMimport timet0 = time.time()model_4bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", quantization_config=quantization_config)t_quantization = time.time() - t0print(f"Quantization time: {t_quantization:.2f} s = {t_quantization/60:.2f} min")Copied
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<?, ?it/s]
Quantizing model.layers blocks : 100%|██████████|32/32 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:4565: FutureWarning: `_is_quantized_training_enabled` is going to be deprecated in transformers 4.39.0. Please use `model.hf_quantizer.is_trainable` insteadwarnings.warn(
Quantization time: 1932.09 s = 32.20 min
Como o processo de quantização calcula o menor erro entre os pesos quantizados e os originais ao passar entradas por cada camada, o processo de quantização demora. Neste caso, levou em média uma hora.
Vamos ver a memória que ocupa agora
model_4bits_memory = model_4bits.get_memory_footprint()/(1024**3)print(f"Model memory: {model_4bits_memory:.2f} GB")Copied
Model memory: 5.34 GB
Aqui podemos ver um benefício da quantização. Enquanto o modelo original ocupava cerca de 15 GB de VRAM, agora o modelo quantizado ocupa cerca de 5 GB, quase um terço do tamanho original.
Fazemos a inferência e vemos o tempo que leva
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model_4bits.device)t0 = time.time()max_new_tokens = 50outputs = model_4bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer. I have a strong background in computer science and mathematics, and I am passionate about developing innovative solutions that can positively impact society. I am excited to be a part of this community and to learn from and contribute to the discussions here. I am particularlyInference time: 2.34 s
O modelo não quantizado levou 4,14 segundos, enquanto agora quantizado para 4 bits levou 2,34 segundos e ainda gerou o texto corretamente. Conseguimos reduzir a inferência quase pela metade.
Como o tamanho do modelo quantizado é quase um terço do modelo em FP16, poderíamos pensar que a velocidade de inferência deveria ser cerca de três vezes mais rápida com o modelo quantizado. Mas é preciso lembrar que em cada camada os pesos são desquantizados e os cálculos são realizados em FP16, por isso conseguimos reduzir o tempo de inferência pela metade e não por um terço.
Agora salvamos o modelo
save_folder = "./model_4bits/"model_4bits.save_pretrained(save_folder)tokenizer.save_pretrained(save_folder)Copied
('./model_4bits/tokenizer_config.json','./model_4bits/special_tokens_map.json','./model_4bits/tokenizer.json')
E o enviamos para o hub
repo_id = "Llama-3-8B-Instruct-GPTQ-4bits"commit_message = f"AutoGPTQ model for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"model_4bits.push_to_hub(repo_id, commit_message=commit_message)Copied
README.md: 100%|██████████| 5.17/5.17k [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-4bits/commit/44cfdcad78db260122943d3f57858c1b840bda17', commit_message='AutoGPTQ model for meta-llama/Meta-Llama-3-8B-Instruct: 4bits, gr128, desc_act=False', commit_description='', oid='44cfdcad78db260122943d3f57858c1b840bda17', pr_url=None, pr_revision=None, pr_num=None)
Também enviamos o tokenizador. Embora não tenhamos alterado o tokenizador, o enviamos porque, se uma pessoa baixar nosso modelo do hub, ela pode não saber qual tokenizador usamos, então provavelmente querrá baixar o modelo e o tokenizador juntos. Podemos indicar na model card qual tokenizador usamos para que ela possa baixá-lo, mas é mais provável que a pessoa não leia a model card, tente baixar o tokenizador, obtenha um erro e não saiba o que fazer. Então enviamos para evitar esse problema.
repo_id = "Llama-3-8B-Instruct-GPTQ-4bits"commit_message = f"Tokenizers for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"tokenizer.push_to_hub(repo_id, commit_message=commit_message)Copied
README.md: 100%|██████████| 0.00/5.17k [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-4bits/commit/75600041ca6e38b5f1fb912ad1803b66656faae4', commit_message='Tokenizers for meta-llama/Meta-Llama-3-8B-Instruct: 4bits, gr128, desc_act=False', commit_description='', oid='75600041ca6e38b5f1fb912ad1803b66656faae4', pr_url=None, pr_revision=None, pr_num=None)
Quantização do modelo para 3 bits
Vamos quantizá-lo para 3 bits. Reinicio o notebook para não ter problemas de memória e volto a fazer login no Hugging Face
from huggingface_hub import notebook_loginnotebook_login()Copied
Primeiro crio o tokenizador
from transformers import AutoTokenizercheckpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Criamos a configuração de quantização, agora indicamos que queremos quantizar para 3 bits
from transformers import GPTQConfigquantization_config = GPTQConfig(bits=3, dataset = "c4", tokenizer=tokenizer)Copied
Quantizamos o modelo
from transformers import AutoModelForCausalLMimport timet0 = time.time()model_3bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", quantization_config=quantization_config)t_quantization = time.time() - t0print(f"Quantization time: {t_quantization:.2f} s = {t_quantization/60:.2f} min")Copied
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<?, ?it/s]
Quantizing model.layers blocks : 100%|██████████|32/32 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:4565: FutureWarning: `_is_quantized_training_enabled` is going to be deprecated in transformers 4.39.0. Please use `model.hf_quantizer.is_trainable` insteadwarnings.warn(
Quantization time: 1912.69 s = 31.88 min
Assim como antes, levou uma média de meia hora
Vamos ver a memória que ocupa agora
model_3bits_memory = model_3bits.get_memory_footprint()/(1024**3)print(f"Model memory: {model_3bits_memory:.2f} GB")Copied
Model memory: 4.52 GB
A memória que o modelo ocupa em 3 bits também é quase de 5 GB. O modelo em 4 bits ocupava 5,34 GB, enquanto agora em 3 bits ocupa 4,52 GB, portanto conseguimos reduzir um pouco mais o tamanho do modelo.
Fazemos a inferência e vemos o tempo que leva
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model_3bits.device)t0 = time.time()max_new_tokens = 50outputs = model_3bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer at Google. I am excited to be here today to talk about my work in the field of Machine Learning and to share some of the insights I have gained through my experiences.I am a Machine Learning Engineer at Google, and I am excited to beInference time: 2.89 s
Embora a saída de 3 bits seja boa, agora o tempo de inferência foi de 2,89 segundos, enquanto em 4 bits foi de 2,34 segundos. Seriam necessárias mais testes para ver se sempre é mais rápido em 4 bits, ou pode ser que a diferença seja tão pequena que às vezes a inferência em 3 bits seja mais rápida e outras vezes a inferência em 4 bits.
Além disso, embora a saída faça sentido, começa a se tornar repetitiva.
Guardamos o modelo
save_folder = "./model_3bits/"model_3bits.save_pretrained(save_folder)tokenizer.save_pretrained(save_folder)Copied
('./model_3bits/tokenizer_config.json','./model_3bits/special_tokens_map.json','./model_3bits/tokenizer.json')
E o enviamos para o Hub
repo_id = "Llama-3-8B-Instruct-GPTQ-3bits"commit_message = f"AutoGPTQ model for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"model_3bits.push_to_hub(repo_id, commit_message=commit_message)Copied
model.safetensors: 100%|██████████| 4.85/4.85G [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-3bits/commit/422fd94a031234c10224ddbe09c0e029a5e9c01f', commit_message='AutoGPTQ model for meta-llama/Meta-Llama-3-8B-Instruct: 3bits, gr128, desc_act=False', commit_description='', oid='422fd94a031234c10224ddbe09c0e029a5e9c01f', pr_url=None, pr_revision=None, pr_num=None)
Também subimos o tokenizador
repo_id = "Llama-3-8B-Instruct-GPTQ-3bits"commit_message = f"Tokenizers for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"tokenizer.push_to_hub(repo_id, commit_message=commit_message)Copied
README.md: 100%|██████████| 0.00/5.17k [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-4bits/commit/75600041ca6e38b5f1fb912ad1803b66656faae4', commit_message='Tokenizers for meta-llama/Meta-Llama-3-8B-Instruct: 4bits, gr128, desc_act=False', commit_description='', oid='75600041ca6e38b5f1fb912ad1803b66656faae4', pr_url=None, pr_revision=None, pr_num=None)
Quantização do modelo para 2 bits
Vamos quantizá-lo para 2 bits. Reinicio o notebook para não ter problemas de memória e faço login novamente no Hugging Face
from huggingface_hub import notebook_loginnotebook_login()Copied
Primeiro crio o tokenizador
from transformers import AutoTokenizercheckpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Criamos a configuração de quantização. Agora dizemos que queremos quantizar para 2 bits. Além disso, é necessário indicar quantos vetores da matriz de pesos são quantizados de uma vez através do parâmetro group_size, antes por padrão tinha o valor 128 e não o alteramos, mas agora ao quantizar para 2 bits, para ter menos erro, colocamos um valor menor. Se deixarmos em 128, o modelo quantizado funcionaria muito mal, nesse caso vou colocar um valor de 16.
from transformers import GPTQConfigquantization_config = GPTQConfig(bits=2, dataset = "c4", tokenizer=tokenizer, group_size=16)Copied
from transformers import AutoModelForCausalLMimport timet0 = time.time()model_2bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", quantization_config=quantization_config)t_quantization = time.time() - t0print(f"Quantization time: {t_quantization:.2f} s = {t_quantization/60:.2f} min")Copied
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<?, ?it/s]
Quantizing model.layers blocks : 100%|██████████|32/32 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:4565: FutureWarning: `_is_quantized_training_enabled` is going to be deprecated in transformers 4.39.0. Please use `model.hf_quantizer.is_trainable` insteadwarnings.warn(
Quantization time: 1973.12 s = 32.89 min
Vemos que também levou cerca de meia hora
Vamos ver a memória que ocupa agora
model_2bits_memory = model_2bits.get_memory_footprint()/(1024**3)print(f"Model memory: {model_2bits_memory:.2f} GB")Copied
Model memory: 4.50 GB
Enquanto quantizado em 4 bits ocupava 5,34 GB e em 3 bits ocupava 4,52 GB, agora quantizado em 2 bits ocupa 4,50 GB, conseguindo assim reduzir ainda mais o tamanho do modelo.
Fazemos a inferência e vemos o tempo que leva
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model_2bits.device)t0 = time.time()max_new_tokens = 50outputs = model_2bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer. # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #Inference time: 2.92 s
Vemos que já a saída não é boa, além disso, o tempo de inferência é de 2,92 segundos, mais ou menos o mesmo que com 3 e 4 bits
Guardamos o modelo
save_folder = "./model_2bits/"model_2bits.save_pretrained(save_folder)tokenizer.save_pretrained(save_folder)Copied
('./model_2bits/tokenizer_config.json','./model_2bits/special_tokens_map.json','./model_2bits/tokenizer.json')
O subimos para o hub
repo_id = "Llama-3-8B-Instruct-GPTQ-2bits"commit_message = f"AutoGPTQ model for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"model_2bits.push_to_hub(repo_id, commit_message=commit_message)Copied
model.safetensors: 100%|██████████| 4.83/4.83G [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-2bits/commit/13ede006ce0dbbd8aca54212e960eff98ea5ec63', commit_message='AutoGPTQ model for meta-llama/Meta-Llama-3-8B-Instruct: 2bits, gr16, desc_act=False', commit_description='', oid='13ede006ce0dbbd8aca54212e960eff98ea5ec63', pr_url=None, pr_revision=None, pr_num=None)
Quantização do modelo para 1 bit
Vamos quantizá-lo para 1 bit. Reinicio o notebook para não ter problemas de memória e faço login novamente no Hugging Face
from huggingface_hub import notebook_loginnotebook_login()Copied
Primeiro crio o tokenizador
from transformers import AutoTokenizercheckpoint = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Criamos a configuração de quantização, agora dizemos que quantize apenas para 1 bit e além disso use um group_size de 8
from transformers import GPTQConfigquantization_config = GPTQConfig(bits=2, dataset = "c4", tokenizer=tokenizer, group_size=8)Copied
from transformers import AutoModelForCausalLMimport timet0 = time.time()model_1bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", quantization_config=quantization_config)t_quantization = time.time() - t0print(f"Quantization time: {t_quantization:.2f} s = {t_quantization/60:.2f} min")Copied
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<?, ?it/s]
Quantizing model.layers blocks : 100%|██████████|32/32 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
Quantizing layers inside the block: 100%|██████████| 7/7 [00:00<?, ?it/s]
/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:4565: FutureWarning: `_is_quantized_training_enabled` is going to be deprecated in transformers 4.39.0. Please use `model.hf_quantizer.is_trainable` insteadwarnings.warn(
Quantization time: 2030.38 s = 33.84 min
Vemos que também leva uma média de trinta minutos para quantizar
Vamos ver a memória que ocupa agora
model_1bits_memory = model_1bits.get_memory_footprint()/(1024**3)print(f"Model memory: {model_1bits_memory:.2f} GB")Copied
Model memory: 5.42 GB
Vemos que neste caso ocupa até mesmo mais que quantizado a 2 bits, 4,52 GB.
Fazemos a inferência e vemos o tempo que leva
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(model_1bits.device)t0 = time.time()max_new_tokens = 50outputs = model_1bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineerimerszuimersimerspinsimersimersingoingoimersurosimersimersimersoleningoimersingopinsimersbirpinsimersimersimersorgeingoimersiringimersimersimersimersimersimersimersンディorge_REFERER ingest羊imersorgeimersimersendetingoШАhandsingoInference time: 3.12 s
Vemos que a saída é muito ruim e além disso demora mais do que quando quantizamos para 2 bits
Salvamos o modelo
save_folder = "./model_1bits/"model_1bits.save_pretrained(save_folder)tokenizer.save_pretrained(save_folder)Copied
('./model_1bits/tokenizer_config.json','./model_1bits/special_tokens_map.json','./model_1bits/tokenizer.json')
O subimos para o hub
repo_id = "Llama-3-8B-Instruct-GPTQ-1bits"commit_message = f"AutoGPTQ model for {checkpoint}: {quantization_config.bits}bits, gr{quantization_config.group_size}, desc_act={quantization_config.desc_act}"model_1bits.push_to_hub(repo_id, commit_message=commit_message)Copied
README.md: 100%|██████████| 0.00/5.17k [00:00<?, ?B/s]
Upload 2 LFS files: 100%|██████████| 0/2 [00:00<?, ?it/s]
model-00002-of-00002.safetensors: 100%|██████████| 0.00/1.05G [00:00<?, ?B/s]
model-00001-of-00002.safetensors: 100%|██████████| 0.00/4.76G [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/Llama-3-8B-Instruct-GPTQ-2bits/commit/e59ccffc03247e7dcc418f98b482cc02dc7a168d', commit_message='AutoGPTQ model for meta-llama/Meta-Llama-3-8B-Instruct: 2bits, gr8, desc_act=False', commit_description='', oid='e59ccffc03247e7dcc418f98b482cc02dc7a168d', pr_url=None, pr_revision=None, pr_num=None)
Resumo da quantização
Vamos a comparar a quantização de 4, 3, 2 e 1 bit
| Bits | Tempo de quantização (min) | Memória (GB) | Tempo de inferência (s) | Qualidade da saída |
|---|---|---|---|---|
| FP16 | 0 | 14,96 | 4,14 | Boa |
| 4 | 32,20 | 5,34 | 2,34 | Boa |
| 3 | 31,88 | 4,52 | 2,89 | Boa |
| 2 | 32,89 | 4,50 | 2,92 | Ruim |
| 1 | 33,84 | 5,42 | 3,12 | Ruim |
Vendo esta tabela vemos que não faz sentido, neste exemplo, quantizar a menos de 4 bits.
Quantizar para 1 e 2 bits claramente não faz sentido porque a qualidade da saída é ruim.
Mas embora a saída ao quantizar para 3 bits seja boa, começa a ser repetitiva, pelo que a longo prazo, provavelmente não seria uma boa ideia usar esse modelo. Além disso, nem o ganho de tempo de quantização, o ganho de VRAM nem o ganho de tempo de inferência é significativo em comparação com a quantização para 4 bits.
Carregamento do modelo salvo
Agora que comparamos a quantização de modelos, vamos ver como seria para carregar o modelo de 4 bits que salvamos, já que, como vimos, é a melhor opção.
Primeiro carregamos o tokenizador que temos usado
from transformers import AutoTokenizerpath = "./model_4bits"tokenizer = AutoTokenizer.from_pretrained(path)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Agora carregamos o modelo que salvamos.
from transformers import AutoModelForCausalLMload_model_4bits = AutoModelForCausalLM.from_pretrained(path, device_map="auto")Copied
Loading checkpoint shards: 100%|██████████| 2/2 [00:00<?, ?it/s]
Vemos a memória que ocupa
load_model_4bits_memory = load_model_4bits.get_memory_footprint()/(1024**3)print(f"Model memory: {load_model_4bits_memory:.2f} GB")Copied
Model memory: 5.34 GB
Vemos que ocupa a mesma memória que quando o quantizamos, o que é lógico.
Fazemos a inferência e vemos o tempo que leva
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(load_model_4bits.device)t0 = time.time()max_new_tokens = 50outputs = load_model_4bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer. I have a strong background in computer science and mathematics, and I have been working with machine learning models for several years. I am excited to be a part of this community and to share my knowledge and experience with others. I am particularly interested inInference time: 3.82 s
Vemos que a inferência é boa e levou 3,82 segundos, um pouco mais do que quando a quantizamos. Mas como já disse anteriormente, seria necessário fazer este teste muitas vezes e tirar uma média.
Carregamento do modelo enviado para o hub
Agora vamos ver como carregar o modelo de 4 bits que subimos ao Hub.
Primeiro carregamos o tokenizador que we subimos
from transformers import AutoTokenizercheckpoint = "Maximofn/Llama-3-8B-Instruct-GPTQ-4bits"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Agora carregamos o modelo que salvamos.
from transformers import AutoModelForCausalLMload_model_4bits = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto")Copied
Vemos a memória que ocupa
load_model_4bits_memory = load_model_4bits.get_memory_footprint()/(1024**3)print(f"Model memory: {load_model_4bits_memory:.2f} GB")Copied
Model memory: 5.34 GB
Ocupa a mesma memória
Fazemos a inferência e vemos o tempo que leva
import timeinput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(load_model_4bits.device)t0 = time.time()max_new_tokens = 50outputs = load_model_4bits.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(f"Inference time: {time.time() - t0:.2f} s")Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
Hello my name is Maximo and I am a Machine Learning Engineer with a passion for building innovative AI solutions. I have been working in the field of AI for over 5 years, and have gained extensive experience in developing and implementing machine learning models for various industries.In my free time, I enjoy reading books onInference time: 3.81 s
Vemos que a inferência também é boa e levou 3,81 segundos.

















