Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
Para mim, a melhor descrição de mixtral-8x7b é a seguinte imagem

Entre a saída do gemini e a saída do mixtra-8x7b houve uma diferença de muito poucos dias. Nos dois primeiros dias após o lançamento do gemini, falou-se bastante sobre esse modelo, mas assim que saiu o mixtral-8x7b, o gemini foi completamente esquecido e toda a comunidade não parou de falar do mixtral-8x7b.
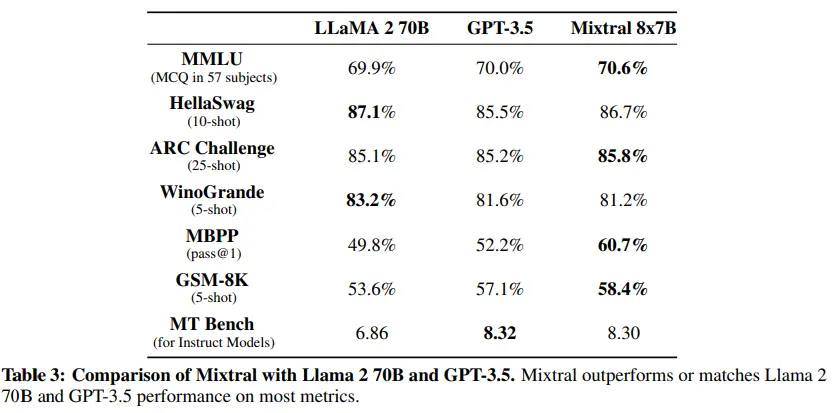
E não é para menos, vendo seus benchmarks, podemos ver que está no nível de modelos como llama2-70B e GPT3.5, mas com a diferença de que enquanto mixtral-8x7b tem apenas 46,7B de parâmetros, llama2-70B tem 70B e GPT3.5 tem 175B.
Número de parâmetros
Como o nome sugere, mixtral-8x7b é um conjunto de 8 modelos de 7B de parâmetros, então poderíamos pensar que ele tem 56B de parâmetros (7Bx8), mas não é bem assim. Como explica Andrej Karpathy, apenas os blocos Feed forward dos transformers são multiplicados por 8, o resto dos parâmetros é compartilhado entre os 8 modelos. Portanto, no final, o modelo tem 46,7B de parâmetros.
Mistura de Especialistas (MoE)
Como dissemos, o modelo é um conjunto de 8 modelos de 7B de parâmetros, daí MoE, que significa Mixture of Experts. Cada um dos 8 modelos é treinado independentemente, mas quando se faz a inferência, um roteador decide qual saída do modelo será usada.
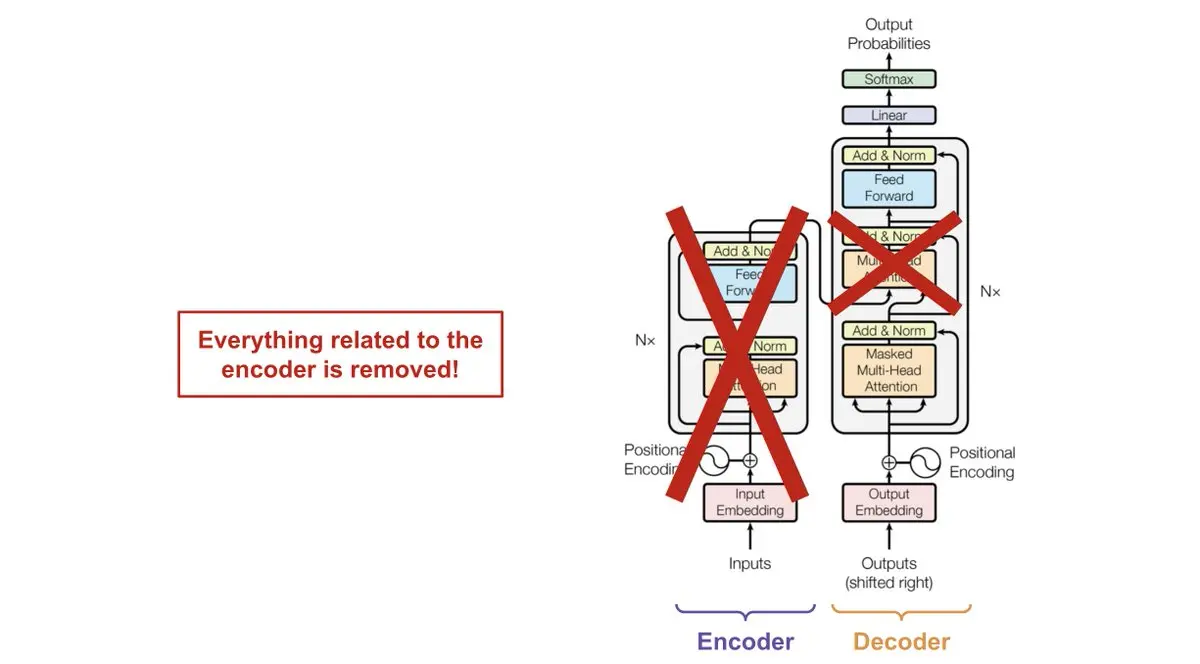
Na imagem a seguir, podemos ver como é a arquitetura de um Transformer.
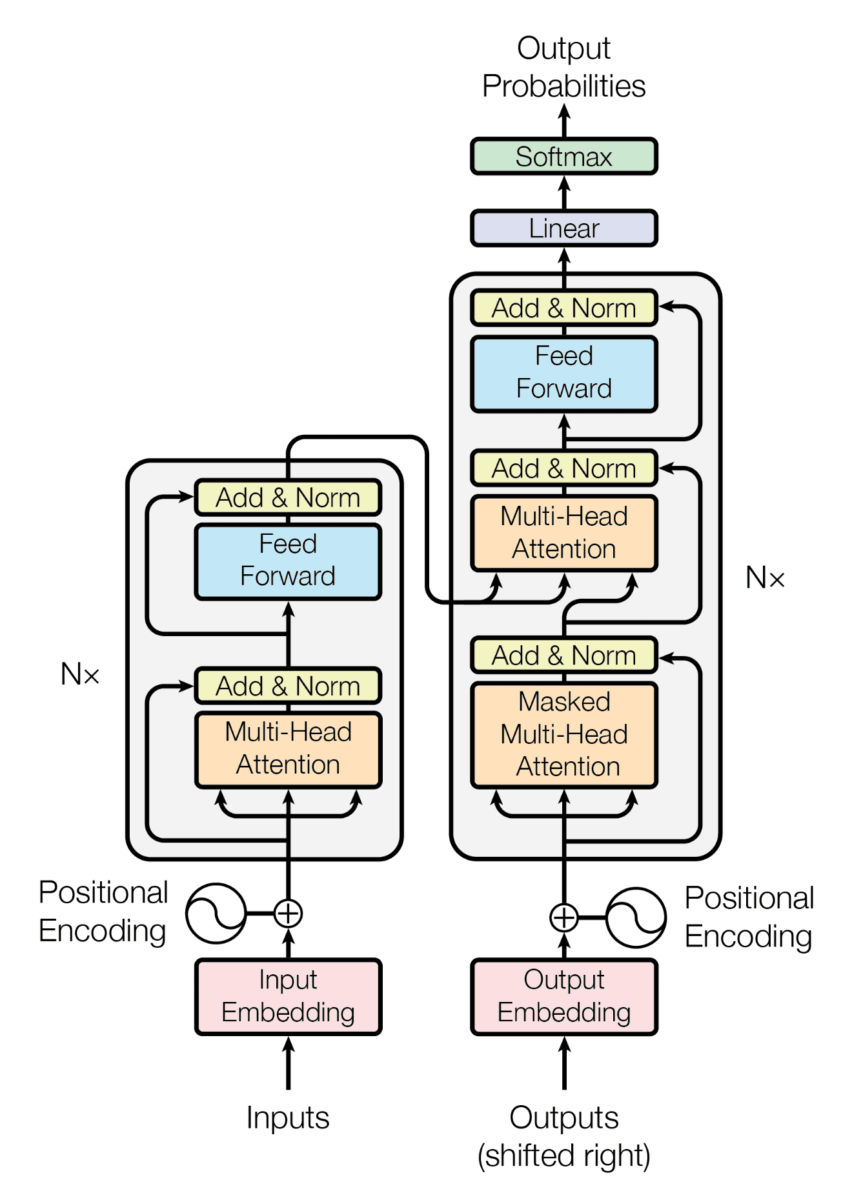
Se não a conhece, não tem problema. O importante é que esta arquitetura consiste em um encoder e um decoder
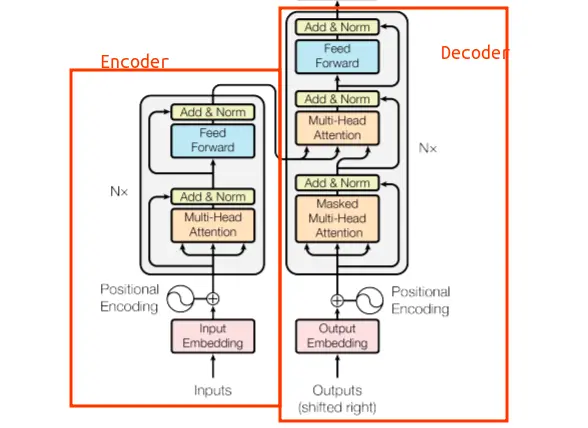
Os LLMs são modelos que possuem apenas o decoder, portanto não têm encoder. Você pode ver que na arquitetura há três módulos de atenção, um deles de fato conecta o encoder com o decoder. Mas como os LLMs não têm encoder, não é necessário o módulo de atenção que une o decoder e o decoder.
Agora que sabemos como é a arquitetura de um LLM, podemos ver como é a arquitetura do mixtral-8x7b. Na imagem seguinte podemos ver a arquitetura do modelo
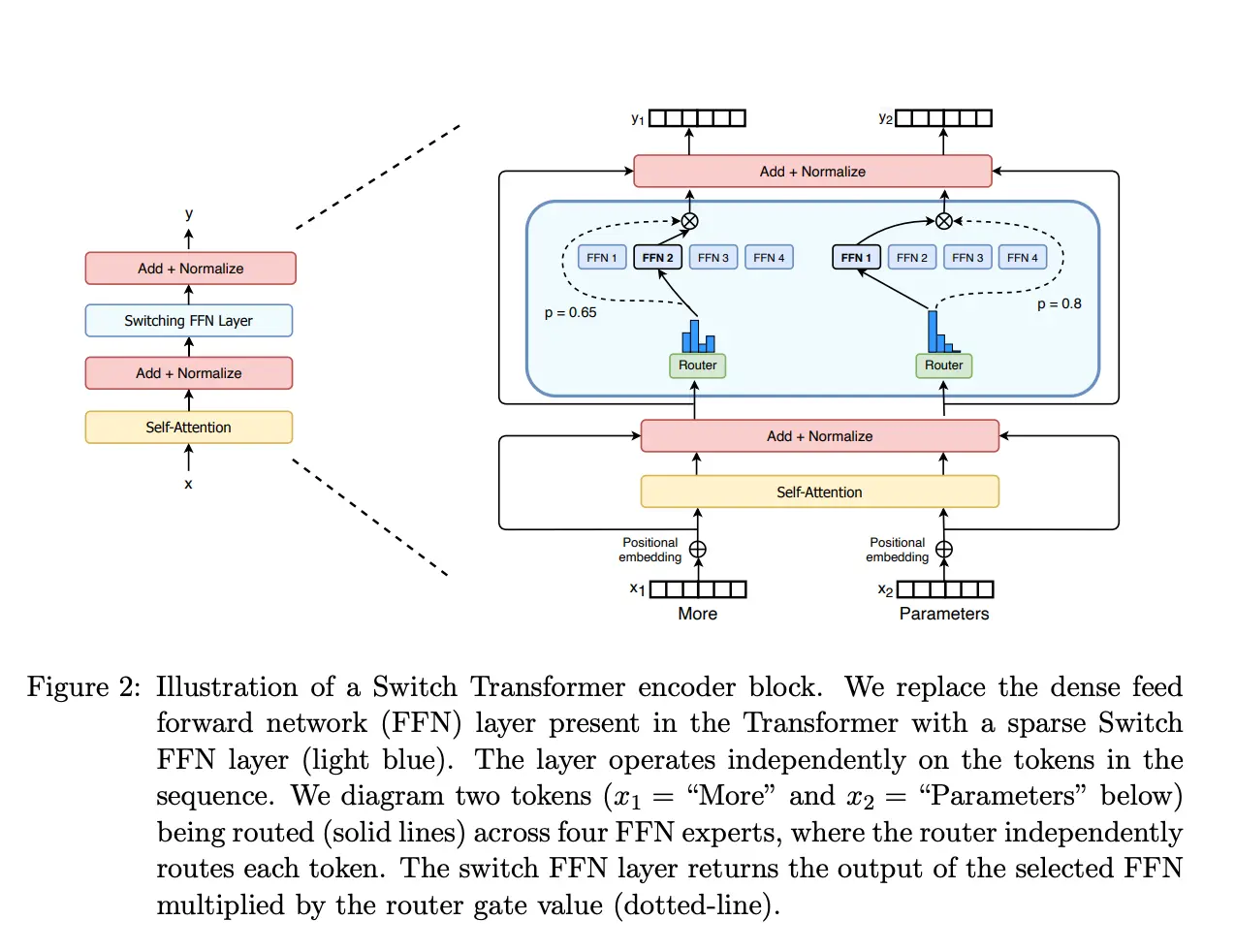
Como pode ser visto, a arquitetura consiste no decoder de um Transformer de 7B de parâmetros, apenas que a camada Feed forward consiste em 8 camadas Feed forward com um roteador que escolhe qual das 8 camadas Feed forward será usada. Na imagem anterior, apenas quatro camadas Feed forward são mostradas, suponho que seja para simplificar o diagrama, mas na realidade há 8 camadas Feed forward. Também se veem dois caminhos para duas palavras distintas, a palavra More e a palavra Parameters e como o roteador escolhe qual Feed forward será usado para cada palavra.
Vendo a arquitetura podemos entender por que o modelo tem 46,7B de parâmetros e não 56B. Como dissemos, apenas os blocos Feed forward se multiplicam por 8, o resto dos parâmetros são compartilhados entre os 8 modelos
Uso do Mixtral-8x7b na nuvem
Infelizmente, para usar mixtral-8x7b localmente é complicado, já que os requisitos de hardware são os seguintes
- float32: VRAM > 180 GB, ou seja, como cada parâmetro ocupa 4 bytes, precisamos de 46,7B * 4 = 186,8 GB de VRAM apenas para armazenar o modelo, além disso, é necessário adicionar a VRAM necessária para armazenar os dados de entrada e saída
- float16: VRAM > 90 GB, neste caso cada parâmetro ocupa 2 bytes, então precisamos de 46,7B * 2 = 93,4 GB de VRAM apenas para armazenar o modelo, além disso, é necessário adicionar a VRAM necessária para armazenar os dados de entrada e saída
- 8-bit: VRAM > 45 GB, aqui cada parâmetro ocupa 1 byte, por isso precisamos de 46,7B * 1 = 46,7 GB de VRAM apenas para armazenar o modelo, além disso, é necessário adicionar a VRAM necessária para armazenar os dados de entrada e saída* 4-bit: VRAM > 23 GB, aqui cada parâmetro ocupa 0.5 bytes, portanto precisamos 46.7B * 0.5 = 23.35 GB de VRAM apenas para armazenar o modelo, além disso, é necessário adicionar a VRAM necessária para armazenar os dados de entrada e saída
Precisamos de GPUs muito potentes para conseguir executá-lo, mesmo quando utilizamos o modelo quantizado para 4 bits.
Portanto, a forma mais simples de usar Mixtral-8x7B é usá-lo já implantado na nuvem. Encontrei vários sites onde você pode usá-lo
Uso de Mixtral-8x7b no huggingface chat
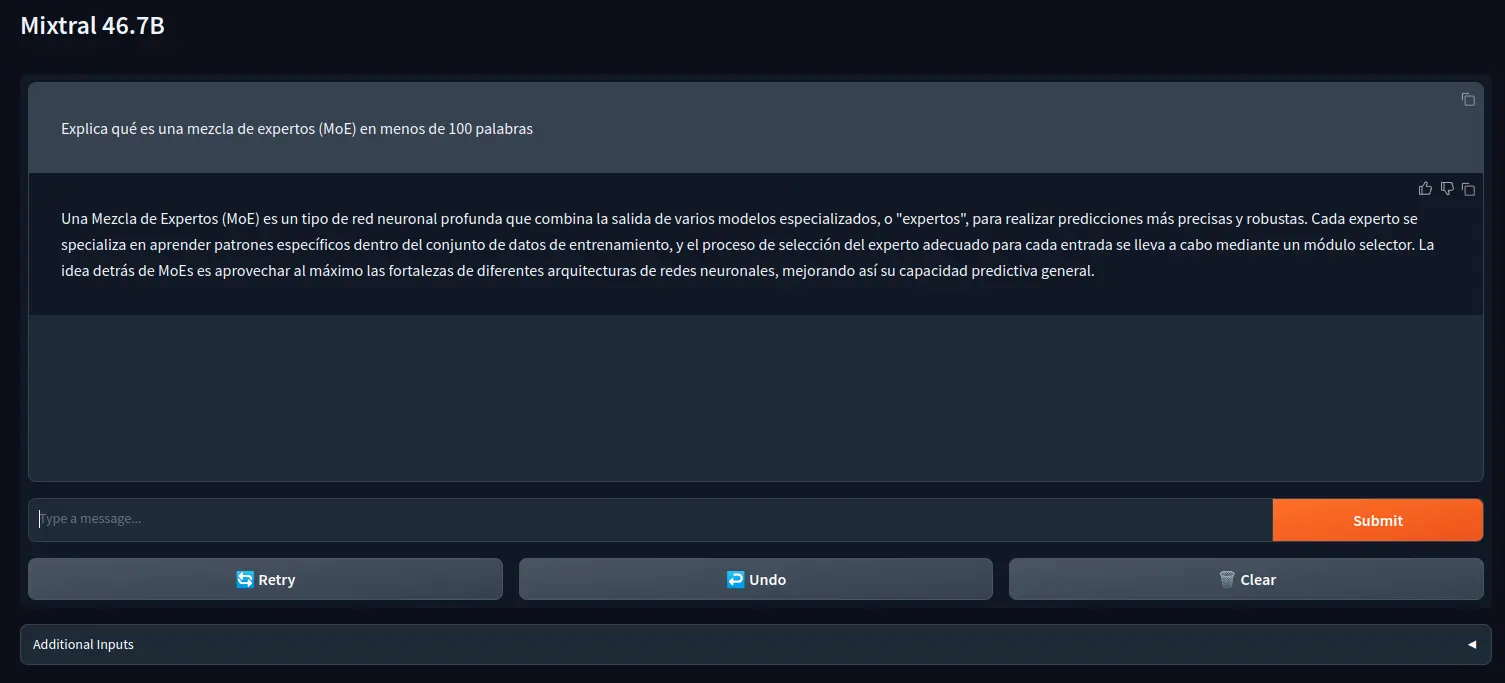
O primeiro está no huggingface chat. Para poder usá-lo, é necessário clicar na engrenagem dentro da caixa Current Model e selecionar Mistral AI - Mixtral-8x7B. Uma vez selecionado, você já pode começar a conversar com o modelo.
Uma vez dentro, selecione mistralai/Mixtral-8x7B-Instruct-v0.1 e, por fim, clique no botão Activate. Agora poderemos testar o modelo.
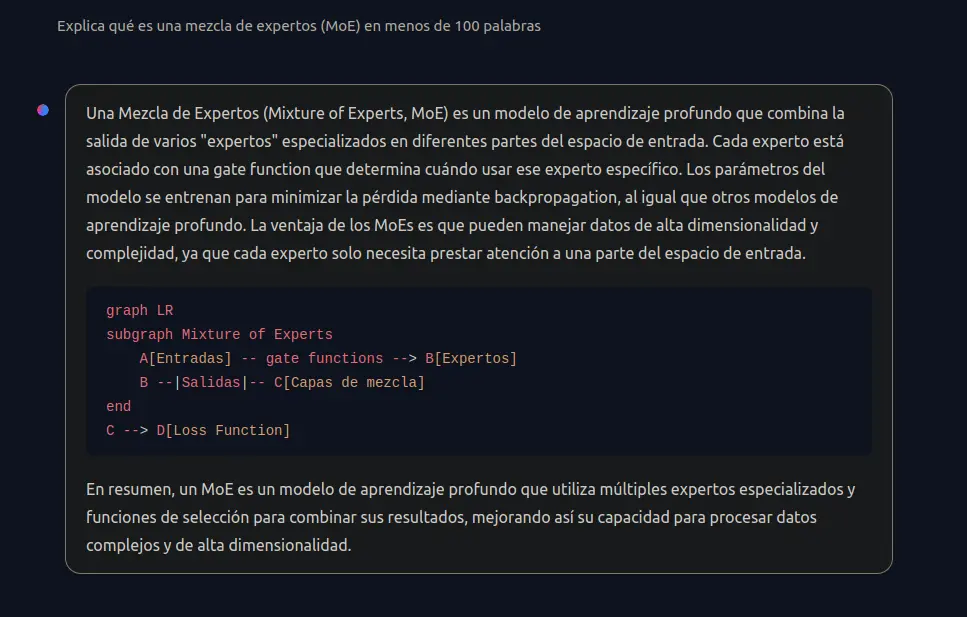
Como se pode ver, eu lhe perguntei em espanhol o que é MoE e ele me explicou
Uso de Mixtral-8x7b nos Perplexity Labs
Outra opção é usar Perplexity Labs. Uma vez dentro, deve-se selecionar mixtral-8x7b-instruct em um menu suspenso localizado na parte inferior direita.
Como se pode ver, também lhe perguntei em espanhol o que é MoE e ele me explicou
Uso de Mixtral-8x7b localmente através da API do Hugging Face
Uma maneira de usá-lo localmente, independentemente dos recursos de hardware que você tenha, é através da API do Hugging Face. Para isso, é necessário instalar a biblioteca huggingface-hub do Hugging Face.
InputPython%pip install huggingface-hubCopied
Aqui está uma implementação com gradio
InputPythonfrom huggingface_hub import InferenceClientimport gradio as grclient = InferenceClient("mistralai/Mixtral-8x7B-Instruct-v0.1")def format_prompt(message, history):prompt = "<s>"for user_prompt, bot_response in history:prompt += f"[INST] {user_prompt} [/INST]"prompt += f" {bot_response}</s> "prompt += f"[INST] {message} [/INST]"return promptdef generate(prompt, history, system_prompt, temperature=0.9, max_new_tokens=256, top_p=0.95, repetition_penalty=1.0,):temperature = float(temperature)if temperature < 1e-2:temperature = 1e-2top_p = float(top_p)generate_kwargs = dict(temperature=temperature, max_new_tokens=max_new_tokens, top_p=top_p, repetition_penalty=repetition_penalty, do_sample=True, seed=42,)formatted_prompt = format_prompt(f"{system_prompt}, {prompt}", history)stream = client.text_generation(formatted_prompt, **generate_kwargs, stream=True, details=True, return_full_text=False)output = ""for response in stream:output += response.token.textyield outputreturn outputadditional_inputs=[gr.Textbox(label="System Prompt", max_lines=1, interactive=True,),gr.Slider(label="Temperature", value=0.9, minimum=0.0, maximum=1.0, step=0.05, interactive=True, info="Higher values produce more diverse outputs"),gr.Slider(label="Max new tokens", value=256, minimum=0, maximum=1048, step=64, interactive=True, info="The maximum numbers of new tokens"),gr.Slider(label="Top-p (nucleus sampling)", value=0.90, minimum=0.0, maximum=1, step=0.05, interactive=True, info="Higher values sample more low-probability tokens"),gr.Slider(label="Repetition penalty", value=1.2, minimum=1.0, maximum=2.0, step=0.05, interactive=True, info="Penalize repeated tokens")]gr.ChatInterface(fn=generate,chatbot=gr.Chatbot(show_label=False, show_share_button=False, show_copy_button=True, likeable=True, layout="panel"),additional_inputs=additional_inputs,title="Mixtral 46.7B",concurrency_limit=20,).launch(show_api=False)Copied