
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
Os modelos de linguagem estão cada vez maiores, o que os torna cada vez mais custosos e caros de executar.

Por exemplo, o modelo Llama 3 400B, se seus parâmetros estiverem armazenados no formato FP32, cada parâmetro ocupa, portanto, 4 bytes, o que significa que apenas para armazenar o modelo são necessários 400*(10e9)*4 bytes = 1,6 TB de memória VRAM. Isso equivale a 20 GPUs com 80GB de memória VRAM cada, as quais, além disso, não são baratas.
Mas se deixarmos de lado modelos gigantes e nos focarmos em modelos de tamanhos mais comuns, por exemplo, 70B de parâmetros, apenas armazenar o modelo representa 70*(10e9)*4 bytes = 280 GB de memória VRAM, o que equivale a 4 GPUs de 80GB de memória VRAM cada uma.
Isso acontece porque armazenamos os pesos no formato FP32, ou seja, cada parâmetro ocupa 4 bytes. Mas o que acontece se conseguirmos que cada parâmetro ocupe menos bytes? Isso é chamado de quantização.
Por exemplo, se conseguirmos que um modelo de 70B de parâmetros ocupe meio byte por parâmetro, então precisaríamos apenas de 70*(10e9)*0.5 bytes = 35 GB de memória VRAM, o que equivale a 2 GPUs de 24GB de memória VRAM cada uma, as quais já podem ser consideradas GPUs de usuários normais.
Portanto, precisamos maneiras de poder reduzir o tamanho desses modelos. Existem três formas de fazer isso: a destilação, a poda e a quantização.
A destilação consiste em treinar um modelo menor a partir das saídas do maior. Isso significa que uma entrada é fornecida tanto ao modelo pequeno quanto ao grande, considerando-se que a saída correta é a do modelo grande, de modo que o treinamento do modelo pequeno é realizado de acordo com a saída do modelo grande. Mas isso requer ter armazenado o modelo grande, o que não é o que queremos ou podemos fazer.
A poda consiste em eliminar parâmetros do modelo, tornando-o cada vez menor. Este método se baseia na ideia de que os modelos de linguagem atuais estão sobredimensionados e apenas alguns poucos parâmetros são os que realmente contribuem com informações. Por isso, se conseguirmos eliminar os parâmetros que não fornecem informações, obteremos um modelo menor. Mas isso não é simples atualmente, porque não temos uma maneira de saber bem quais parâmetros são importantes e quais não são.
Por outro lado, a quantização consiste em reduzir o tamanho de cada um dos parâmetros do modelo. E é isso que vamos explicar neste post.
Formato dos parâmetros
Os parâmetros dos pesos podem ser armazenados em vários tipos de formatos

Originalmente, era usado o FP32 para armazenar os parâmetros, mas devido ao fato de começarmos a ficar sem memória para armazenar os modelos, passamos a usar o FP16, o que não dava resultados ruins.
No entanto, o problema do FP16 é que ele não alcança valores tão altos quanto o FP32, o que pode levar ao caso de overflow de valores, ou seja, ao realizar cálculos internos na rede, o resultado pode ser tão alto que não possa ser representado em FP16, gerando erros. Isso ocorre porque o modelo foi treinado em FP32, o que permite que todos os possíveis cálculos internos sejam realizados, mas ao passar para FP16 posteriormente para realizar inferências, alguns cálculos internos podem causar overflow.
Devido a esses erros de overflow, foram criados o TF32 e o BF16, os quais têm a mesma quantidade de bits de expoente, o que permite que eles alcancem valores tão altos quanto o FP32, mas com a vantagem de ocupar menos memória por terem menos bits. No entanto, ambos, por terem menos bits de mantissa, não podem representar números com tanta precisão quanto o FP32, o que pode resultar em erros de arredondamento, mas pelo menos não obteremos um erro ao executar a rede. O TF32 tem no total 19 bits, enquanto o BF16 tem 16 bits. Geralmente, usa-se mais o BF16 porque se economiza mais memória.
Históricamente existiram os formatos INT8 e UINT8, que podem representar números de -128 a 127 e de 0 a 255, respectivamente. Embora sejam formatos bons porque permitem economizar memória, já que cada parâmetro ocupa 1 byte em comparação aos 4 bytes do FP32, o problema que têm é que só podem representar um intervalo pequeno de números e, além disso, apenas inteiros, pelo que podem ocorrer os dois problemas vistos anteriormente: desbordamento e falta de precisão.
Para resolver o problema de que os formatos INT8 e UINT8 representam apenas números inteiros, foram criados os formatos FP8 e FP4, mas ainda não estão muito consolidados, nem possuem um formato muito padronizado.
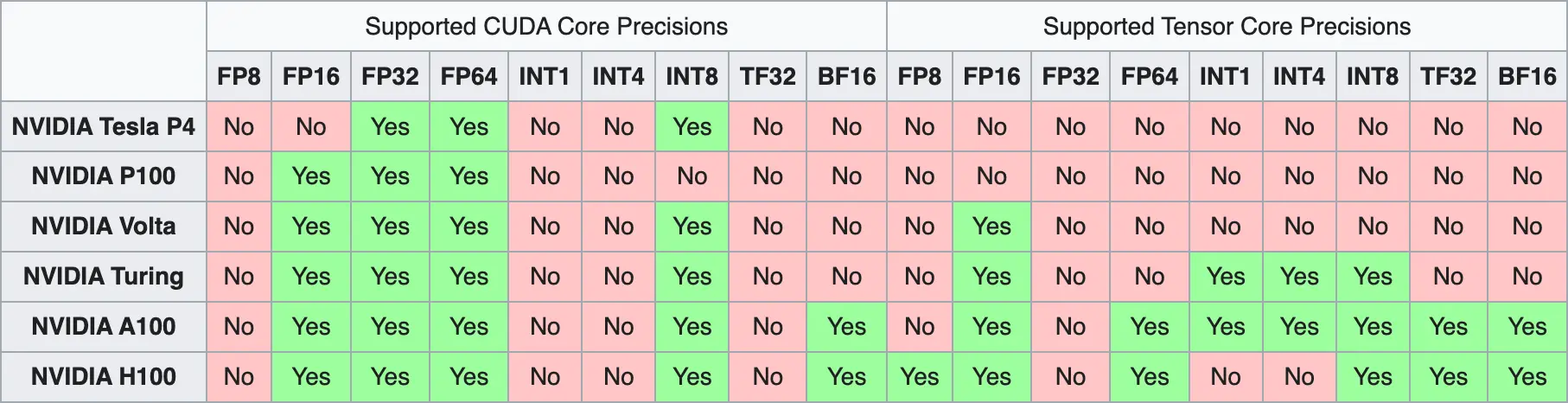
Embora tenhamos meios de armazenar os parâmetros dos modelos em formatos menores, e embora consigamos resolver os problemas de overflow e arredondamento, temos outro problema, que é o fato de que nem todas as GPUs são capazes de representar todos os formatos. Isso ocorre porque esses problemas de memória são relativamente novos, de modo que as GPUs mais antigas não foram projetadas para resolver esses problemas e, portanto, não são capazes de representar todos os formatos.
Como último detalhe, como curiosidade, durante o treinamento dos modelos é utilizada a chamada precisão mista. Os pesos do modelo são armazenados no formato FP32, no entanto, o forward pass e o backward pass são realizados em FP16 para ser mais rápido. Os gradientes resultantes do backward pass são armazenados em FP16 e usados para modificar os valores FP32 dos pesos.
Tipos de quantização
Quantização de ponto zero
Este é o tipo de quantização mais simples. Consiste em reduzir o intervalo de valores de maneira linear, o menor valor de FP32 corresponde ao menor valor do novo formato, o zero de FP32 corresponde ao zero do novo formato e o maior valor de FP32 corresponde ao maior valor do novo formato.
Por exemplo, se quisermos passar os números representados de -1 até 1 no formato UINT8, como os limites do UINT8 são -127 e 127, se quisermos representar o valor 0.3, o que fazemos é multiplicar 0.3 por 127, o que dá 38.1 e arredondá-lo para 38, que é o valor que seria armazenado no UINT8.
Se quisermos fazer o passo contrário, para converter 38 para o formato entre -1 e 1, o que fazemos é dividir 38 por 127, que dá 0.2992, que é aproximadamente 0.3, e podemos ver que temos um erro de 0.008
Quantização Afim
Neste tipo de quantização, se tiver um array de valores em um formato e quiser passar para outro, primeiro divide-se o array inteiro pelo valor máximo do array e depois multiplica-se o array inteiro pelo valor máximo do novo formato.
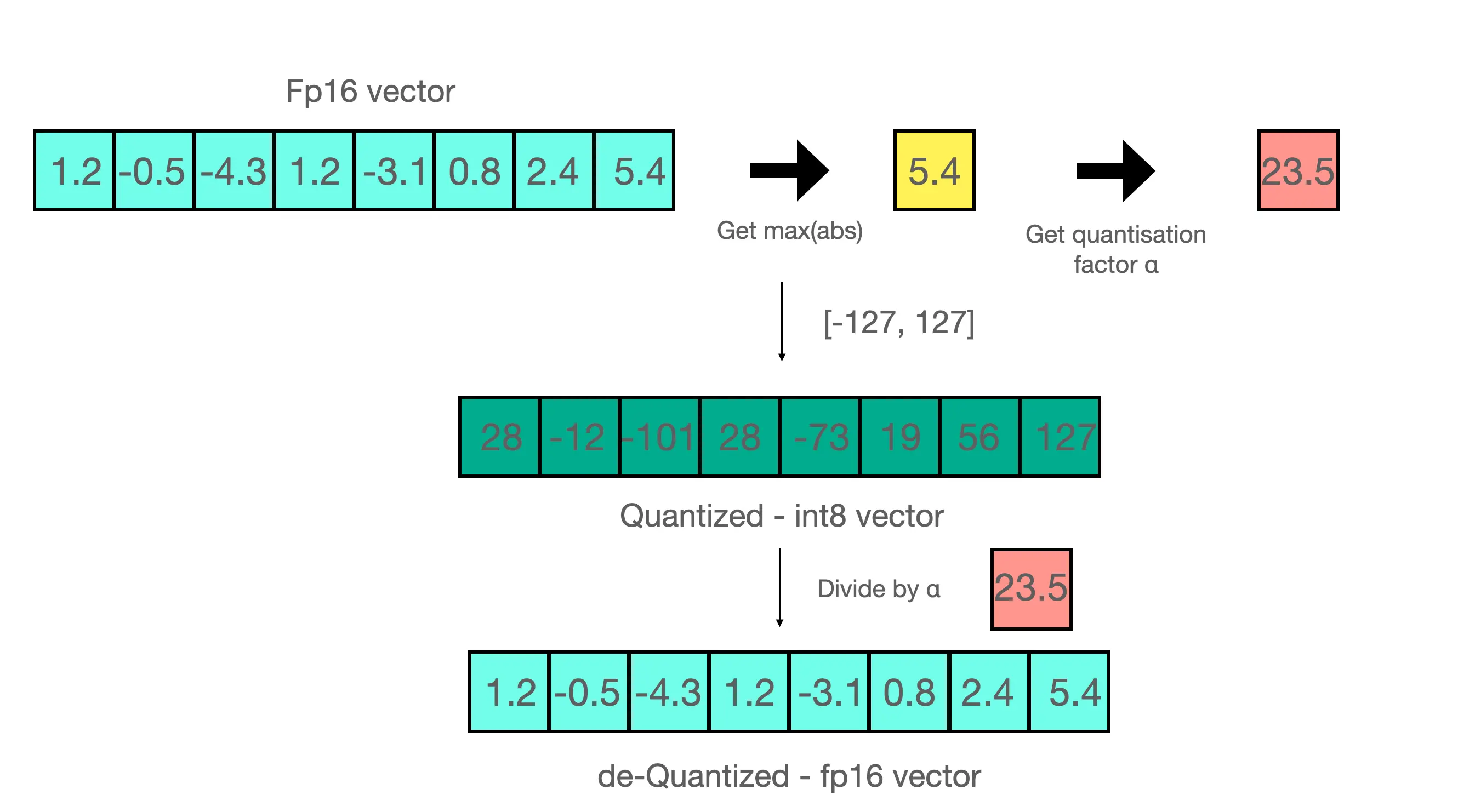
Por exemplo, na imagem acima temos o array
[1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4]Como seu valor máximo é 5.4, dividimos o array por esse valor e obtemos
[0.2222222222, -0.09259259259, -0.7962962963, 0.2222222222, -0.5740740741, 0.1481481481, 0.4444444444, 1]Se agora multiplicarmos todos os valores por 127, que é o valor máximo de UINT8, obtemos
[28,22222222, -11,75925926, -101,1296296, 28,22222222, -72,90740741, 18,81481481, 56,44444444, 127]Que, arredondando, seria
[28, -12, -101, 28, -73, 19, 56, 127]Se quisermos realizar o passo inverso, teríamos que dividir o array resultante por 127, que daria
[0,2204724409, -0,09448818898, -0,7952755906, 0,2204724409, -0,5748031496, 0,1496062992, 0,4409448819, 1]E multiplicar novamente por 5.4, com o que obteríamos
[1,190551181, -0.5102362205, -4.294488189, 1.190551181, -3.103937008, 0.8078740157, 2.381102362, 5.4]Se compararmos com o array original, vemos que temos um erro
Momentos de quantização
Quantização pós-treinamento
Como o nome sugere, a quantização ocorre após o treinamento. O modelo é treinado em FP32 e depois é quantizado para outro formato. Este método é o mais simples, mas pode levar a erros de precisão na quantização.
Quantização durante o treinamento
Durante o treinamento, é realizado o forward pass no modelo original e em um modelo quantizado, e são observados os possíveis erros decorrentes da quantização para poder mitigá-los. Este processo torna o treinamento mais custoso, pois você precisa armazenar na memória o modelo original e o quantizado, e mais lento, pois você precisa realizar o forward pass em dois modelos.
Métodos de quantização
A seguir mostro os links para os posts onde explico cada um dos métodos, para que este post não fique muito longo
- LLM.int8()
- GPTQ
- QLoRA
- AWQ
- QuIP
- GGUF
- HQQ
- AQLM
- FBGEMM FP8

















