
Este caderno foi traduzido automaticamente para torná-lo acessível a mais pessoas, por favor me avise se você vir algum erro de digitação..
Embora LoRA ofereça uma maneira de ajustar os modelos de linguagem sem a necessidade de GPUs com grandes VRAMs, no artigo QLoRA eles vão além e propõem uma maneira de ajustar os modelos quantizados, tornando ainda menos necessária a memória para o ajuste fino dos modelos de linguagem.
LoRA
Atualização de pesos em uma rede neural
Para entender como o LoRA funciona, primeiro precisamos lembrar o que acontece quando treinamos um modelo. Vamos voltar à parte mais básica da aprendizagem profunda: temos uma camada densa de uma rede neural que é definida como:
y = Wx + b
Onde W é a matriz de pesos e b é o vetor de polarização.
Para simplificar, vamos supor que não haja viés, de modo que ficaria assim
y = Wx
Suponha que, para uma entrada x, queremos que ela tenha uma saída ŷ.
- Primeiro, calculamos o resultado que obtemos com nosso valor atual de pesos W, ou seja, obtemos o valor y.
- Em seguida, calculamos o erro que existe entre o valor de y que obtivemos e o valor que queríamos obter ŷ. Chamamos esse erro de loss e o calculamos com alguma função matemática, não importa qual.
- Calculamos a derivada do erro loss com relação à matriz de peso W, ou seja, $Delta W = \frac{dloss}{dW}.
- Atualizamos os pesos W subtraindo de cada um de seus valores o valor do gradiente multiplicado por um fator de aprendizado alpha, ou seja, W = W - \alpha \Delta W.
LoRA
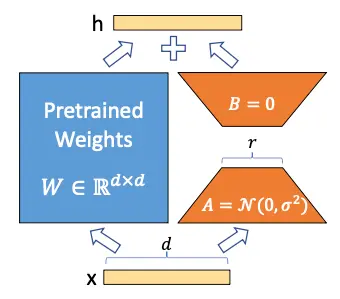
O que os autores do LoRA propõem é que a matriz de peso W possa ser decomposta em
W \sim W + Delta W
Portanto, ao congelar a matriz W e treinar somente a matriz "Delta W, é possível obter um modelo que se ajusta aos novos dados sem precisar treinar novamente o modelo inteiro.
Mas você pode pensar que $Delta W é uma matriz de tamanho igual a W e, portanto, nada foi ganho, mas aqui os autores se baseiam em Aghajanyan et al. (2020), um artigo no qual eles mostraram que, embora os modelos de linguagem sejam grandes e seus parâmetros sejam matrizes com dimensões muito grandes, para adaptá-los a novas tarefas não é necessário alterar todos os valores das matrizes, mas alterar alguns valores é suficiente, o que, em termos técnicos, é chamado de Low Rank Adaptation (LoRA). Daí o nome LoRA (Low Rank Adaptation).
Congelamos o modelo e agora queremos treinar a matriz
Delta W. Vamos supor que tanto W quanto
Delta W sejam matrizes de tamanho 20, portanto, temos 200 parâmetros treináveis.Agora, vamos supor que a matriz $Delta W possa ser decomposta no produto de duas matrizes A e B, ou seja
\Delta W = A · B
Para que essa multiplicação ocorra, os tamanhos das matrizes A e B devem ser 20 × n e n × 10, respectivamente. Suponha que n = 5, então A teria o tamanho de 20 × 5, ou seja, 100 parâmetros, e B o tamanho de 5 × 10, ou seja, 50 parâmetros, de modo que teríamos 100+50=150 parâmetros treináveis. Já temos menos parâmetros treináveis do que antes
Agora vamos supor que W seja, na verdade, uma matriz de tamanho 10.000 × 10.000, de modo que teríamos 100.000.000 parâmetros treináveis, mas se decompusermos Delta W em A e B com n = 5, teríamos uma matriz de tamanho 10.000 × 5 e outra de tamanho 5 × 10.000, de modo que teríamos 50.000 parâmetros de uma e outros 50.000 parâmetros da outra, em um total de 100.000 parâmetros treináveis, ou seja, reduzimos o número de parâmetros 1.000 vezes.
Você já pode ver o poder do LoRA: quando você tem modelos muito grandes, o número de parâmetros treináveis pode ser bastante reduzido.
Se olharmos novamente para a imagem da arquitetura do LoRA, entenderemos melhor.
Mas a economia no número de parâmetros treináveis com essa imagem parece ainda melhor.
LoRA matmul](https://images.maximofn.com/Lora_matmul.webp)
QLoRA
O QLoRA é realizado em duas etapas: a primeira é quantificar o modelo e a segunda é aplicar o LoRA ao modelo quantificado.
Quantificação de QLoRA
A quantização do QLoRA baseia-se em três conceitos: quantização do modelo de 4 bits com o formato normal float 4 (NF4), quantização dupla e otimizadores paginados. Tudo isso junto permite economizar muita memória ao fazer o ajuste fino dos modelos de linguagem, portanto, vamos ver em que consiste cada um deles.
Quantificação de modelos de linguagem em normal float 4 (NF4)
No QLoRA, para quantificar, o que se faz é quantificar no formato normal float 4 (NF4), que é um tipo de quantização de 4 bits para que seus dados tenham uma distribuição normal, ou seja, sigam um sino gaussiano. Para que eles sigam essa distribuição, o que se faz é dividir os valores dos pesos no FP16 em quantis, de modo que em cada quantil haja o mesmo número de valores. Quando tivermos os quantis, cada quantil receberá um valor em 4 bits
QLoRA-normal-float-quantization](https://images.maximofn.com/QLoRA-normal-float-quantization.webp)
Para realizar essa quantização, ele usa o algoritmo de quantização SRAM, que é um algoritmo de quantização de quantis muito rápido por quantis, mas apresenta muitos erros com valores que estão muito distantes na distribuição de sino gaussiana, outliers.
Como os parâmetros dos pesos de uma rede neural geralmente seguem uma distribuição normal (ou seja, seguem um sino gaussiano), centrados em zero e com um desvio padrão σ. Eles são normalizados para ter um desvio padrão entre -1 e 1 e, em seguida, quantizados no formato NF4.
Quantização dupla
Conforme mencionado acima, ao quantificar os parâmetros de rede, precisamos normalizá-los para que tenham um desvio padrão entre -1 e 1 e, em seguida, quantificá-los no formato NF4. Portanto, precisamos armazenar alguns parâmetros como os valores para normalizar os parâmetros, ou seja, o valor pelo qual os dados são divididos para ter um desvio entre -1 e 1. Esses valores são armazenados no formato FP32, portanto, os autores do artigo propõem quantificar esses parâmetros no formato FP8.
Embora isso possa parecer não economizar muita memória, os autores estimam que isso pode economizar cerca de 0,373 bits por parâmetro, mas se, por exemplo, tivermos um modelo de 8B parâmetros, que não é um modelo excessivamente grande para os padrões atuais, economizaríamos cerca de 3 GB de memória, o que não é ruim. No caso de um modelo de 70B parâmetros, economizaríamos cerca de 26 GB de memória.
Otimizadores paginados
As GPUs da Nvidia têm a opção de compartilhar a RAM da GPU e da CPU, portanto, o que elas fazem é armazenar os estados do otimizador na RAM da CPU e acessá-los quando necessário. Assim, eles não precisam ser armazenados na RAM da GPU e podemos economizar memória da GPU.
Ajuste fino com LoRA
Depois de quantizar o modelo, podemos fazer o ajuste fino do modelo quantizado, como em [LoRA] (https://www.maximofn.com/lora/).
Como fazer o ajuste fino de um modelo quantizado com QLoRA
Agora que já explicamos o QLoRA, vamos ver um exemplo de como ajustar um modelo usando o QLoRA.
Faça login no hub do Hugging Face
Primeiro, fazemos login para carregar o modelo treinado no Hub.
Input Pythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
Conjunto de dados
Baixamos o conjunto de dados que usaremos, que é um conjunto de dados de avaliações da Amazon
Input Pythonfrom datasets import load_datasetdataset = load_dataset("mteb/amazon_reviews_multi", "en")datasetCopied
OutputDatasetDict({train: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000})validation: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})test: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})})
Criamos um subconjunto para o caso de você querer testar o código com um conjunto de dados menor. No meu caso, usarei 100% do conjunto de dados.
Input Pythonpercentage = 1subset_dataset_train = dataset['train'].select(range(int(len(dataset['train']) * percentage)))subset_dataset_validation = dataset['validation'].select(range(int(len(dataset['validation']) * percentage)))subset_dataset_test = dataset['test'].select(range(int(len(dataset['test']) * percentage)))subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
Output(Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}))
Vemos uma amostra
Input Pythonfrom random import randintidx = randint(0, len(subset_dataset_train))subset_dataset_train[idx]Copied
Output{'id': 'en_0297000','text': 'Not waterproof at all Bought this after reading good reviews. But it’s not water proof at all. If my son has even a little accident in bed, it goes straight to mattress. I don’t see a point in having this. So I have to purchase another one.','label': 0,'label_text': '0'}
Para obter o número de classes, usamos dataset['train'] e não subset_dataset_train porque, se o subconjunto for muito pequeno, talvez não haja exemplos com todas as classes possíveis do conjunto de dados original.
Input Pythonnum_classes = len(dataset['train'].unique('label'))num_classesCopied
Output5
Criamos uma função para criar o campo label no conjunto de dados. O conjunto de dados baixado tem o campo labels, mas a biblioteca transformers precisa que o campo seja chamado label e não labels.
Input Pythondef set_labels(example):example['labels'] = example['label']return exampleCopied
Aplicamos a função ao conjunto de dados
Input Pythonsubset_dataset_train = subset_dataset_train.map(set_labels)subset_dataset_validation = subset_dataset_validation.map(set_labels)subset_dataset_test = subset_dataset_test.map(set_labels)subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
Output(Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}))
Aqui está um exemplo novamente
Input Pythonsubset_dataset_train[idx]Copied
Output{'id': 'en_0297000','text': 'Not waterproof at all Bought this after reading good reviews. But it’s not water proof at all. If my son has even a little accident in bed, it goes straight to mattress. I don’t see a point in having this. So I have to purchase another one.','label': 0,'label_text': '0','labels': 0}
Tokenizer
Implementamos o tokenizador. Para evitar erros, atribuímos o token de fim de cadeia ao token de preenchimento.
Input Pythonfrom transformers import AutoTokenizercheckpoint = "openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoint)tokenizer.pad_token = tokenizer.eos_tokenCopied
Criamos uma função para tokenizar o conjunto de dados
Input Pythondef tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=768, return_tensors="pt")Copied
Aplicamos a função ao conjunto de dados e removemos as colunas de que não precisamos.
Input Pythonsubset_dataset_train = subset_dataset_train.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_validation = subset_dataset_validation.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_test = subset_dataset_test.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
Output(Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 200000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}))
Vemos uma amostra novamente, mas, nesse caso, vemos apenas as chaves.
Input Pythonsubset_dataset_train[idx].keys()Copied
Outputdict_keys(['labels', 'input_ids', 'attention_mask'])
Modelo
Primeiro, baixamos o modelo não quantizado
Input Pythonfrom transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes)model.config.pad_token_id = model.config.eos_token_idCopied
OutputSome weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Vemos a memória que ele ocupa
Input Pythonmodel_memory = model.get_memory_footprint()/(1024**3)print(f"Model memory: {model_memory:.2f} GB")Copied
OutputModel memory: 0.48 GB
Passamos o modelo para o FP16 e verificamos novamente a memória que ele ocupa.
Input Pythonmodel = model.half()Copied
Input Pythonmodel_memory = model.get_memory_footprint()/(1024**3)print(f"Model memory: {model_memory:.2f} GB")Copied
OutputModel memory: 0.24 GB
Analisamos a arquitetura do modelo antes de quantificar.
Input PythonmodelCopied
OutputGPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
Quantificação do modelo
Para quantificar o modelo, primeiro precisamos criar a configuração de quantização. Para isso, usamos a biblioteca bitsandbytes; se você não a tiver instalada, poderá fazê-lo com
pip install bitsandbytesPrimeiro, verificamos se nossa arquitetura de GPU permite o formato BF16; se não permitir, usaremos o FP16.
Em seguida, criamos a configuração de quantização, com load_in_4bits=True indicamos que ele quantiza em 4 bits, com bnb_4bit_quant_type="nf4" indicamos que ele faz isso no formato NF4, com bnb_4bit_use_double_quant=True dizemos a ele para fazer a quantização dupla e com bnb_4bit_compute_dtype=compute_dtype dizemos a ele qual formato de dados usar ao quantificar, que pode ser FP16 ou BF16.
Input Pythonfrom transformers import BitsAndBytesConfigimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type="nf4",bnb_4bit_use_double_quant=True,bnb_4bit_compute_dtype=compute_dtype,)Copied
E agora quantificamos o modelo
Input Pythonfrom transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes, quantization_config=bnb_config)Copied
Output`low_cpu_mem_usage` was None, now set to True since model is quantized.Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Vamos examinar novamente o espaço ocupado pela memória, agora que já o quantificamos.
Input Pythonmodel_memory = model.get_memory_footprint()/(1024**3)print(f"Model memory: {model_memory:.2f} GB")Copied
OutputModel memory: 0.12 GB
Vemos que o tamanho do modelo foi reduzido.
Vamos examinar novamente a arquitetura do modelo depois que ele tiver sido quantificado.
Input PythonmodelCopied
OutputGPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Linear4bit(in_features=768, out_features=2304, bias=True)(c_proj): Linear4bit(in_features=768, out_features=768, bias=True)(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Linear4bit(in_features=768, out_features=3072, bias=True)(c_proj): Linear4bit(in_features=3072, out_features=768, bias=True)(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
Vemos que a arquitetura mudou
QLoRA-model-vs-quantized-model](https://images.maximofn.com/QLoRA-model-vs-quantized-model_.webp)
Alterou as camadas Conv1D para camadas Linear4bits.
LoRA
Antes de implementar o LoRA, temos que configurar o modelo para treinar em 4 bits.
Input Pythonfrom peft import prepare_model_for_kbit_trainingmodel = prepare_model_for_kbit_training(model)Copied
Vamos ver se o tamanho do modelo foi alterado.
Input Pythonmodel_memory = model.get_memory_footprint()/(1024**3)print(f"Model memory: {model_memory:.2f} GB")Copied
OutputModel memory: 0.20 GB
A memória aumentou, portanto, examinamos novamente a arquitetura do modelo.
Input PythonmodelCopied
OutputGPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Linear4bit(in_features=768, out_features=2304, bias=True)(c_proj): Linear4bit(in_features=768, out_features=768, bias=True)(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Linear4bit(in_features=768, out_features=3072, bias=True)(c_proj): Linear4bit(in_features=3072, out_features=768, bias=True)(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
A arquitetura permanece a mesma, portanto, presumimos que o aumento na memória é para alguma configuração extra para poder aplicar o LoRA em 4 bits
Criamos uma configuração do LoRA, mas, diferentemente da postagem LoRA, em que configuramos em target_modeules apenas a camada scores, agora também adicionaremos as camadas c_attn, c_proj e c_fc, pois agora elas são do tipo Linear4bits e não Conv1D.
Input Pythonfrom peft import LoraConfig, TaskTypeconfig = LoraConfig(r=16,lora_alpha=32,lora_dropout=0.1,task_type=TaskType.SEQ_CLS,target_modules=['c_attn', 'c_fc', 'c_proj', 'score'],bias="none",)Copied
Input Pythonfrom peft import get_peft_modelmodel = get_peft_model(model, config)Copied
Input Pythonmodel.print_trainable_parameters()Copied
Outputtrainable params: 2,375,504 || all params: 126,831,520 || trainable%: 1.8730
Enquanto na postagem LoRA tínhamos cerca de 12.000 parâmetros treináveis, agora temos cerca de 2 milhões, pois adicionamos as camadas c_attn, c_proj e c_fc.
Treinamento
Depois de instanciar o modelo quantizado e aplicar o LoRA, ou seja, depois de fazer o QLoRA, vamos treiná-lo como de costume.
Input Pythonfrom transformers import TrainingArgumentsmetric_name = "accuracy"model_name = "GPT2-small-QLoRA-finetuned-amazon-reviews-en-classification"LR = 2e-5BS_TRAIN = 224BS_EVAL = 224EPOCHS = 3WEIGHT_DECAY = 0.01training_args = TrainingArguments(model_name,eval_strategy="epoch",save_strategy="epoch",learning_rate=LR,per_device_train_batch_size=BS_TRAIN,per_device_eval_batch_size=BS_EVAL,num_train_epochs=EPOCHS,weight_decay=WEIGHT_DECAY,lr_scheduler_type="cosine",warmup_ratio = 0.1,fp16=True,load_best_model_at_end=True,metric_for_best_model=metric_name,push_to_hub=True,logging_dir="./runs",)Copied
Na postagem [Fine tuning SMLs] (https://www.maximofn.com/fine-tuning-sml/), tivemos que colocar um tamanho de trem BS de 28; na postagem [LoRA] (https://www.maximofn.com/lora/), ao colocar as matrizes de baixa classificação nas camadas lineares, foi possível colocar um tamanho de lote de 400. Agora, como ao quantizar o modelo, a biblioteca PEFT converteu mais algumas camadas em Linear, não podemos colocar um tamanho de lote tão grande e temos que colocá-lo em 224.
Input Pythonimport numpy as npfrom evaluate import loadmetric = load("accuracy")def compute_metrics(eval_pred):print(eval_pred)predictions, labels = eval_predpredictions = np.argmax(predictions, axis=1)return metric.compute(predictions=predictions, references=labels)Copied
Input Pythonfrom transformers import Trainertrainer = Trainer(model,training_args,train_dataset=subset_dataset_train,eval_dataset=subset_dataset_validation,tokenizer=tokenizer,compute_metrics=compute_metrics,)Copied
Input Pythontrainer.train()Copied
Output`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`.../usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py:464: UserWarning: torch.utils.checkpoint: the use_reentrant parameter should be passed explicitly. In version 2.4 we will raise an exception if use_reentrant is not passed. use_reentrant=False is recommended, but if you need to preserve the current default behavior, you can pass use_reentrant=True. Refer to docs for more details on the differences between the two variants.warnings.warn(
Output<IPython.core.display.HTML object>
Output<transformers.trainer_utils.EvalPrediction object at 0x7acac436c3d0>
Output/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py:464: UserWarning: torch.utils.checkpoint: the use_reentrant parameter should be passed explicitly. In version 2.4 we will raise an exception if use_reentrant is not passed. use_reentrant=False is recommended, but if you need to preserve the current default behavior, you can pass use_reentrant=True. Refer to docs for more details on the differences between the two variants.warnings.warn(
Output<transformers.trainer_utils.EvalPrediction object at 0x7acac32580d0>
Output/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py:464: UserWarning: torch.utils.checkpoint: the use_reentrant parameter should be passed explicitly. In version 2.4 we will raise an exception if use_reentrant is not passed. use_reentrant=False is recommended, but if you need to preserve the current default behavior, you can pass use_reentrant=True. Refer to docs for more details on the differences between the two variants.warnings.warn(
Output<IPython.core.display.HTML object>
Output<transformers.trainer_utils.EvalPrediction object at 0x7acac2f43c10>
OutputTrainOutput(global_step=2679, training_loss=1.1650676093647934, metrics={'train_runtime': 11299.1288, 'train_samples_per_second': 53.101, 'train_steps_per_second': 0.237, 'total_flos': 2.417754341376e+17, 'train_loss': 1.1650676093647934, 'epoch': 3.0})
Avaliação
Depois de treinados, avaliamos o conjunto de dados de teste
Input Pythontrainer.evaluate(eval_dataset=subset_dataset_test)Copied
Output<IPython.core.display.HTML object>
Output<transformers.trainer_utils.EvalPrediction object at 0x7acb316fe5c0>
Output{'eval_loss': 0.8883273601531982,'eval_accuracy': 0.615,'eval_runtime': 28.5566,'eval_samples_per_second': 175.091,'eval_steps_per_second': 0.805,'epoch': 3.0}
Publicar o modelo
Criamos um cartão modelo
Input Pythontrainer.create_model_card()Copied
Nós o publicamos
Input Pythontrainer.push_to_hub()Copied
Teste o modelo
Vamos aprovar o modelo
Input Pythonfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationimport torchmodel_name = "GPT2-small-QLoRA-finetuned-amazon-reviews-en-classification"user = "maximofn"checkpoint = f"{user}/{model_name}"num_classes = 5tokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes).half().eval().to("cuda")Copied
Output/home/sae00531/miniconda3/envs/nlp_/lib/python3.11/site-packages/huggingface_hub/file_download.py:1132: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.warnings.warn(Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference./home/sae00531/miniconda3/envs/nlp_/lib/python3.11/site-packages/peft/tuners/lora/layer.py:1119: UserWarning: fan_in_fan_out is set to False but the target module is `Conv1D`. Setting fan_in_fan_out to True.warnings.warn(Loading adapter weights from maximofn/GPT2-small-QLoRA-finetuned-amazon-reviews-en-classification led to unexpected keys not found in the model: ['score.modules_to_save.default.base_layer.weight', 'score.modules_to_save.default.lora_A.default.weight', 'score.modules_to_save.default.lora_B.default.weight', 'score.modules_to_save.default.modules_to_save.lora_A.default.weight', 'score.modules_to_save.default.modules_to_save.lora_B.default.weight', 'score.modules_to_save.default.original_module.lora_A.default.weight', 'score.modules_to_save.default.original_module.lora_B.default.weight'].
Input Pythontokens = tokenizer.encode("I love this product", return_tensors="pt").to(model.device)with torch.no_grad():output = model(tokens)logits = output.logitslables = torch.softmax(logits, dim=1).cpu().numpy().tolist()lables[0]Copied
Output[0.0186614990234375,0.483642578125,0.048187255859375,0.415283203125,0.03399658203125]

















