
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
O aumento do tamanho dos modelos de linguagem faz com que sejam cada vez mais caros de treinar, pois é necessário cada vez mais VRAM para armazenar todos os seus parâmetros e os gradientes derivados do treinamento.
No artigo LoRA - Low rank adaption of large language models propõem congelar os pesos do modelo e treinar duas matrizes chamadas A e B, reduzindo significativamente o número de parâmetros que precisam ser treinados.
Vamos a ver como se faz isso
Explicação de LoRA
Atualização de pesos em uma rede neural
Para entender como funciona LoRA, primeiro temos que lembrar o que ocorre quando treinamos um modelo. Voltemos à parte mais básica do deep learning, temos uma camada densa de uma rede neural que é definida como:
y = Wx + b
Onde W é a matriz de pesos e b é o vetor de vieses.
Para simplificar, vamos a supor que não há viés, portanto ficaria assim
y = Wx
Suponhamos que para uma entrada x queremos que tenha uma saída ŷ
- Primeiro, o que fazemos é calcular a saída que obtemos com nosso valor atual de pesos W, ou seja, obtemos o valor y
- Em seguida, calculamos o erro que existe entre o valor de y que obtivemos e o valor que queríamos obter ŷ. A esse erro chamamos de loss, e o calculamos com alguma função matemática, agora não importa qual.
- Calculamos o gradiente (a derivada) do erro loss em relação à matriz de pesos W, ou seja, \Delta W = \frac{dloss}{dW}
- Atualizamos os pesos W subtraindo de cada um dos seus valores o valor do gradiente multiplicado por um fator de aprendizado \alpha, ou seja, W = W - \alpha \Delta W
LoRA
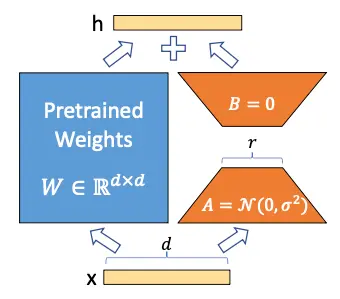
Os autores de LoRA propõem que a matriz de pesos W pode ser decomposta em
W \sim W + \Delta W
Assim, ao congelar a matriz W e treinar apenas a matriz \Delta W, pode-se obter um modelo que se adeque a novos dados sem ter que retreinar todo o modelo.
Mas você pode pensar que \Delta W é uma matriz do mesmo tamanho de W, portanto nada foi ganho, mas aqui os autores se baseiam em Aghajanyan et al. (2020), um artigo no qual eles demonstraram que, embora os modelos de linguagem sejam grandes e seus parâmetros sejam matrizes com dimensões muito grandes, para adaptá-los a novas tarefas não é necessário alterar todos os valores das matrizes, mas sim alterar alguns poucos valores, o que tecnicamente é chamado de adaptação de baixa classificação. Daí o nome LoRA (Low Rank Adaptation).
Congelamos o modelo e agora queremos treinar a matriz \Delta W. Suponhamos que tanto W quanto \Delta W são matrizes de tamanho 20 × 10, portanto temos 200 parâmetros treináveis.
Agora suponhamos que a matriz \Delta W pode ser decomposta no produto de duas matrizes A e B, ou seja
\Delta W = A · B
Para que esta multiplicação ocorra, os tamanhos das matrizes A e B têm que ser 20 × n e n × 10, respectivamente. Suponhamos que n = 5, portanto A seria de tamanho 20 × 5, ou seja, 100 parâmetros, e B de tamanho 5 × 10, ou seja, 50 parâmetros, por isso teríamos 100+50=150 parâmetros treináveis. Já temos menos parâmetros treináveis do que antes.
Agora suponhamos que W na verdade é uma matriz de tamanho 10.000 × 10.000, portanto teríamos 100.000.000 parâmetros treináveis, mas se decompor \Delta W em A e B com n = 5, teríamos uma matriz de tamanho 10.000 × 5 e outra de tamanho 5 × 10.000, portanto teríamos 50.000 parâmetros de uma e outros 50.000 parâmetros de outra, no total 100.000 parâmetros treináveis, ou seja, reduzimos o número de parâmetros 1000 vezes
Já pode ver o poder da LoRA, quando se têm modelos muito grandes, o número de parâmetros treináveis pode ser reduzido drasticamente.
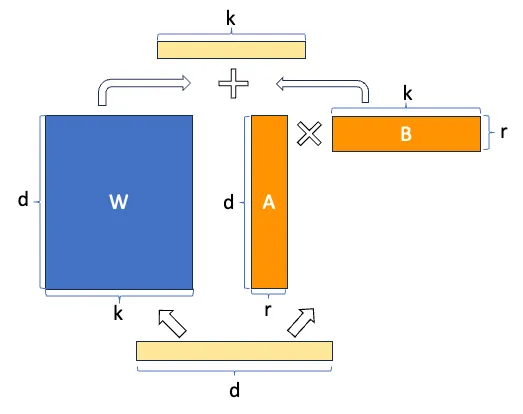
Se voltarmos a ver a imagem da arquitetura de LoRA, a entenderemos melhor.
Mas parece ainda melhor, a economia no número de parâmetros treináveis com esta imagem
Implementação de LoRA em transformers
Como os modelos de linguagem são implementações de transformers, vamos ver como se implementa LoRA em transformers. Na arquitetura transformer há camadas lineares nas matrizes de atenção Q, K e V, e nas camadas feedforward, por isso pode-se aplicar LoRA a todas essas camadas lineares. No paper, eles falam que, por simplicidade, o aplicam apenas às camadas lineares das matrizes de atenção Q, K e V.
Estas camadas têm um tamanho dmodel × dmodel, onde dmodel é a dimensão de embedding do modelo
Tamanho do intervalo r
Para poder ter esses benefícios, o tamanho do intervalo r deve ser menor que o tamanho das camadas lineares. Como dissemos que só o implementavam nas camadas lineares de atenção, que têm um tamanho dmodel × dmodel, o tamanho do intervalo r deve ser menor que dmodel.
Inicialização das matrizes A e B
As matrizes A e B são inicializadas com uma distribuição gaussiana aleatória para A e zero para B, assim o produto de ambas as matrizes será zero no início, ou seja
\Delta W = A · B = 0
Influência de LoRA por meio do parâmetro $\alpha$
Por último, na implementação de LoRA, adiciona-se um parâmetro α para estabelecer o grau de influência de LoRA no treinamento. É similar à taxa de aprendizado (learning rate) no fine tuning normal, mas neste caso é usado para estabelecer a influência de LoRA no treinamento. Dessa forma, a fórmula de LoRA ficaria assim
W = W + α \Delta W = W + α A · B
Vantagens do LoRA
Agora que entendemos como isso funciona, vamos ver as vantagens desse método.
- Redução do número de parâmetros treináveis. Como vimos, o número de parâmetros treináveis é reduzido drasticamente, o que torna o treinamento muito mais rápido e requer menos VRAM, economizando muitos custos.* Adaptadores em produção. Podemos ter em produção um único modelo de linguagem e vários adaptadores, cada um para uma tarefa diferente, em vez de ter vários modelos treinados para cada tarefa, o que economiza custos de armazenamento e computação. Além disso, este método não precisa adicionar latência na inferência porque a matriz de pesos original pode ser fusionada com o adaptador, já que vimos que W \sim W + \Delta W = W + A \cdot B, portanto, o tempo de inferência seria o mesmo que usar o modelo de linguagem original.
- Compartilhar adaptadores. Se treinarmos um adaptador, podemos compartilhar apenas o adaptador. Isso significa que, em produção, todos podem ter o modelo original e cada vez que treinamos um adaptador, compartilhamos apenas o adaptador, portanto, como seriam compartilhadas matrizes muito menores, o tamanho dos arquivos compartilhados seria muito menor
Implementação de LoRA em um LLM
Vamos a repetir o código de treinamento do post Fine tuning SLMs, em específico o treinamento para classificação de texto com as bibliotecas da Hugging Face, mas desta vez vamos fazer isso com LoRA. No post anterior, usamos um batch size de 28 para o loop de treinamento e de 40 para o de avaliação, no entanto, como agora não vamos treinar todos os pesos do modelo, mas apenas as matrizes de LoRA, poderemos usar um batch size maior.
Login no Hub
Nós nos logamos para fazer o upload do modelo para o Hub
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
Conjunto de Dados
Baixamos o conjunto de dados que vamos utilizar, que é um conjunto de dados de avaliações do Amazon
InputPythonfrom datasets import load_datasetdataset = load_dataset("mteb/amazon_reviews_multi", "en")datasetCopied
DatasetDict({train: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000})validation: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})test: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})})
Criamos um subconjunto se você quiser testar o código com um conjunto de dados menor. No meu caso, usarei 100% do conjunto de dados.
InputPythonpercentage = 1subset_dataset_train = dataset['train'].select(range(int(len(dataset['train']) * percentage)))subset_dataset_validation = dataset['validation'].select(range(int(len(dataset['validation']) * percentage)))subset_dataset_test = dataset['test'].select(range(int(len(dataset['test']) * percentage)))subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}))
Vemos uma amostra
InputPythonfrom random import randintidx = randint(0, len(subset_dataset_train))subset_dataset_train[idx]Copied
{'id': 'en_0388304','text': 'The N was missing from on The N was missing from on','label': 0,'label_text': '0'}
Obtemos o número de classes, para obter o número de classes usamos dataset['train'] e não subset_dataset_train porque se o subconjunto for muito pequeno é possível que não haja exemplos com todas as possíveis classes do conjunto de dados original
InputPythonnum_classes = len(dataset['train'].unique('label'))num_classesCopied
5
Criamos uma função para criar o campo label no dataset. O dataset baixado tem o campo labels, mas a biblioteca transformers precisa que o campo seja chamado de label e não labels.
InputPythondef set_labels(example):example['labels'] = example['label']return exampleCopied
Aplicamos a função ao conjunto de dados
InputPythonsubset_dataset_train = subset_dataset_train.map(set_labels)subset_dataset_validation = subset_dataset_validation.map(set_labels)subset_dataset_test = subset_dataset_test.map(set_labels)subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}))
Voltamos a ver um exemplo
InputPythonsubset_dataset_train[idx]Copied
{'id': 'en_0388304','text': 'The N was missing from on The N was missing from on','label': 0,'label_text': '0','labels': 0}
Tokenizador
Implementamos o tokenizador. Para que não dê erro, atribuímos o token de end of string ao token de padding
InputPythonfrom transformers import AutoTokenizercheckpoint = "openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoint)tokenizer.pad_token = tokenizer.eos_tokenCopied
Criamos uma função para tokenizar o dataset
InputPythondef tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=768, return_tensors="pt")Copied
Aplicamos a função ao conjunto de dados e, de passagem, eliminamos as colunas que não precisamos
InputPythonsubset_dataset_train = subset_dataset_train.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_validation = subset_dataset_validation.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_test = subset_dataset_test.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 200000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}))
Voltamos a ver uma amostra, mas neste caso só vemos as keys
InputPythonsubset_dataset_train[idx].keys()Copied
dict_keys(['labels', 'input_ids', 'attention_mask'])
Modelo
Instanciamos o modelo. Também, para que não nos dê erro, atribuímos o token de end of string ao token de padding
InputPythonfrom transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes)model.config.pad_token_id = model.config.eos_token_idCopied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Como já vimos no post Fine tuning SLMs obtemos um warning que diz que algumas camadas não foram inicializadas. Isso acontece porque, neste caso, como é um problema de classificação e quando instanciamos o modelo dissemos que queremos que seja um modelo de classificação com 5 classes, a biblioteca removeu a última camada e a substituiu por uma com 5 neurônios na saída. Se não entende bem isso, veja o post que cito, que está melhor explicado.
LoRA
Antes de implementar LoRA, vemos o número de parâmetros treináveis que tem o modelo
InputPythontotal_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f"Total trainable parameters before: {total_params:,}")Copied
Total trainable parameters before: 124,443,648
Vemos que tem 124M de parâmetros treináveis. Agora vamos congelá-los.
InputPythonfor param in model.parameters():param.requires_grad = Falsetotal_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f"Total trainable parameters after: {total_params:,}")Copied
Total trainable parameters after: 0
Após o congelamento, não há mais parâmetros treináveis.
Vamos ver como é o modelo antes de aplicar LoRA
InputPythonmodelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
Primeiro criamos a camada LoRA layer.
Tem que herdar de torch.nn.Module para poder atuar como uma camada de uma rede neural
No método _init_ criamos as matrizes A e B inicializadas como explicado anteriormente, a matriz A com uma distribuição gaussiana aleatória e a matriz B com zeros. Também criamos os parâmetros rank e alpha.
No método forward calculamos LoRA conforme explicado.
InputPythonimport torchclass LoRALayer(torch.nn.Module):def __init__(self, in_dim, out_dim, rank, alpha):super().__init__()self.A = torch.nn.Parameter(torch.empty(in_dim, rank))torch.nn.init.kaiming_uniform_(self.A, a=torch.sqrt(torch.tensor(5.)).item()) # similar to standard weight initializationself.B = torch.nn.Parameter(torch.zeros(rank, out_dim))self.alpha = alphadef forward(self, x):x = self.alpha * (x @ self.A @ self.B)return xCopied
Agora criamos uma classe linear com LoRA.
Assim como antes, herde de torch.nn.Module para que possa atuar como uma camada de uma rede neural.
No método init criamos uma variável com a camada linear original da rede e criamos outra variável com a nova camada LoRA que havíamos implementado anteriormente.
No método forward somamos as saídas da camada linear original e da camada LoRA.
InputPythonclass LoRALinear(torch.nn.Module):def __init__(self, linear, rank, alpha):super().__init__()self.linear = linearself.lora = LoRALayer(linear.in_features, linear.out_features, rank, alpha)def forward(self, x):return self.linear(x) + self.lora(x)Copied
Por último, criamos uma função que substitua as camadas lineares pela nova camada linear com LoRA que criamos. O que ela faz é que se encontrar uma camada linear no modelo, a substitui pela camada linear com LoRA; caso contrário, aplica a função dentro das subcamadas da camada.
InputPythondef replace_linear_with_lora(model, rank, alpha):for name, module in model.named_children():if isinstance(module, torch.nn.Linear):# Replace the Linear layer with LinearWithLoRAsetattr(model, name, LoRALinear(module, rank, alpha))else:# Recursively apply the same function to child modulesreplace_linear_with_lora(module, rank, alpha)Copied
Aplicamos a função ao modelo para substituir as camadas lineares do modelo pela nova camada linear com LoRA
InputPythonrank = 16alpha = 16replace_linear_with_lora(model, rank=rank, alpha=alpha)Copied
Vemos agora o número de parâmetros treináveis
InputPythontotal_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f"Total trainable LoRA parameters: {total_params:,}")Copied
Total trainable LoRA parameters: 12,368
Passamos de 124M de parâmetros treináveis para 12k parâmetros treináveis, ou seja, reduzimos o número de parâmetros treináveis 10.000 vezes!
Voltamos a ver o modelo
InputPythonmodelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): LoRALinear((linear): Linear(in_features=768, out_features=5, bias=False)(lora): LoRALayer()))
Vamos a compará-los camada por camada
| Modelo original | Modelo com LoRA |
|---|---|
| GPT2ForSequenceClassification( | GPT2ForSequenceClassification( |
| (transformer): GPT2Model( | (transformer): GPT2Model( |
| (wte): Embedding(50257, 768) | (wte): Embedding(50257, 768) |
| (wpe): Embedding(1024, 768) | (wpe): Embedding(1024, 768) |
| (drop): Dropout(p=0.1, inplace=False) | (drop): Dropout(p=0.1, inplace=False) |
| (h): ModuleList( | (h): ModuleList( |
| (0-11): 12 x GPT2Block( | (0-11): 12 x GPT2Block( |
| (ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) | (ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) |
| (attn): GPT2Attention( | (attn): GPT2Attention( |
| (c_attn): Conv1D() | (c_attn): Conv1D() |
| (c_proj): Conv1D() | (c_proj): Conv1D() |
| (attn_dropout): Dropout(p=0.1, inplace=False) | (attn_dropout): Dropout(p=0.1, inplace=False) |
| (resid_dropout): Dropout(p=0.1, inplace=False) | (resid_dropout): Dropout(p=0.1, inplace=False) |
| ) | ) |
| (ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True) | (ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True) |
| (c_fc): Conv1D() | (c_fc): Conv1D() |
| (c_proj): Conv1D() | (c_proj): Conv1D() |
| (act): NewGELUActivation() | (act): NewGELUActivation() |
| (dropout): Dropout(p=0.1, inplace=False) | (dropout): Dropout(p=0.1, inplace=False) |
| ) | ) |
| ) | ) |
| ) | ) |
| (ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True) | (ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True) |
| ) | ) |
| (pontuação): LoRALinear() | |
| (score): Linear(in_features=768, out_features=5, bias=False) | (linear): Linear(in_features=768, out_features=5, bias=False) |
| (lora): LoRAL层() |
Nota: Parece que hubo un error en la traducción del término "LoRALayer" al portugués. La traducción correcta sería:
| (lora): LoRALayer() | |
|---|---|
| ) | ) |
Vemos que são iguais, exceto no final, onde no modelo original havia uma camada linear normal e no modelo com LoRA há uma camada LoRALinear que dentro possui a camada linear do modelo original e uma camada LoRALayer
Treinamento
Uma vez instanciado o modelo com LoRA, vamos treiná-lo como sempre
Como dissem, no post Fine tuning SLMs usamos um batch size de 28 para o loop de treinamento e de 40 para o de avaliação, enquanto agora que há menos parâmetros treináveis podemos usar um batch size maior.
Por que isso acontece? Quando se treina um modelo, é necessário armazenar na memória da GPU o modelo e os gradientes desse modelo, então tanto com LoRA quanto sem LoRA, o modelo precisa ser armazenado igualmente, mas no caso do LoRA, apenas os gradientes de 12k parâmetros são armazenados, enquanto que sem LoRA, os gradientes de 128M de parâmetros são armazenados, por isso com LoRA é necessário menos memória da GPU, permitindo o uso de um batch size maior.
InputPythonfrom transformers import TrainingArgumentsmetric_name = "accuracy"model_name = "GPT2-small-LoRA-finetuned-amazon-reviews-en-classification"LR = 2e-5BS_TRAIN = 400BS_EVAL = 400EPOCHS = 3WEIGHT_DECAY = 0.01training_args = TrainingArguments(model_name,eval_strategy="epoch",save_strategy="epoch",learning_rate=LR,per_device_train_batch_size=BS_TRAIN,per_device_eval_batch_size=BS_EVAL,num_train_epochs=EPOCHS,weight_decay=WEIGHT_DECAY,lr_scheduler_type="cosine",warmup_ratio = 0.1,fp16=True,load_best_model_at_end=True,metric_for_best_model=metric_name,push_to_hub=True,logging_dir="./runs",)Copied
InputPythonimport numpy as npfrom evaluate import loadmetric = load("accuracy")def compute_metrics(eval_pred):print(eval_pred)predictions, labels = eval_predpredictions = np.argmax(predictions, axis=1)return metric.compute(predictions=predictions, references=labels)Copied
InputPythonfrom transformers import Trainertrainer = Trainer(model,training_args,train_dataset=subset_dataset_train,eval_dataset=subset_dataset_validation,tokenizer=tokenizer,compute_metrics=compute_metrics,)Copied
InputPythontrainer.train()Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7cd07be46440><transformers.trainer_utils.EvalPrediction object at 0x7cd07be45c30><transformers.trainer_utils.EvalPrediction object at 0x7cd07be8b970>
TrainOutput(global_step=1500, training_loss=1.8345018310546874, metrics={'train_runtime': 2565.4667, 'train_samples_per_second': 233.876, 'train_steps_per_second': 0.585, 'total_flos': 2.352076406784e+17, 'train_loss': 1.8345018310546874, 'epoch': 3.0})
Avaliação
Uma vez treinado, avaliamos sobre o dataset de teste
InputPythontrainer.evaluate(eval_dataset=subset_dataset_test)Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7cd07be8bbe0>
{'eval_loss': 1.5203168392181396,'eval_accuracy': 0.3374,'eval_runtime': 19.3843,'eval_samples_per_second': 257.94,'eval_steps_per_second': 0.671,'epoch': 3.0}
Publicar o modelo
Já temos nosso modelo treinado, já podemos compartilhá-lo com o mundo, então primeiro criamos uma **model card**
InputPythontrainer.create_model_card()Copied
E já podemos publicá-lo. Como a primeira coisa que fizemos foi fazer login no hub do Hugging Face, podemos enviá-lo para o nosso hub sem nenhum problema.
InputPythontrainer.push_to_hub()Copied
Teste do modelo
Limpez tudo o possível
InputPythonimport torchimport gcdef clear_hardwares():torch.clear_autocast_cache()torch.cuda.ipc_collect()torch.cuda.empty_cache()gc.collect()clear_hardwares()clear_hardwares()Copied
Como subimos o modelo ao nosso hub, podemos baixá-lo e usá-lo
InputPythonfrom transformers import pipelineuser = "maximofn"checkpoints = f"{user}/{model_name}"task = "text-classification"classifier = pipeline(task, model=checkpoints, tokenizer=checkpoints)Copied
Agora, se quisermos que nos retorne a probabilidade de todas as classes, simplesmente usamos o classificador que acabamos de instanciar, com o parâmetro top_k=None
InputPythonlabels = classifier("I love this product", top_k=None)labelsCopied
[{'label': 'LABEL_0', 'score': 0.8419149518013},{'label': 'LABEL_1', 'score': 0.09386005252599716},{'label': 'LABEL_3', 'score': 0.03624210134148598},{'label': 'LABEL_2', 'score': 0.02049318142235279},{'label': 'LABEL_4', 'score': 0.0074898069724440575}]
Se quisermos apenas a classe com a maior probabilidade, fazemos o mesmo mas com o parâmetro top_k=1
InputPythonlabel = classifier("I love this product", top_k=1)labelCopied
[{'label': 'LABEL_0', 'score': 0.8419149518013}]
E se quisermos n classes, fazemos o mesmo mas com o parâmetro top_k=n
InputPythontwo_labels = classifier("I love this product", top_k=2)two_labelsCopied
[{'label': 'LABEL_0', 'score': 0.8419149518013},{'label': 'LABEL_1', 'score': 0.09386005252599716}]
Também podemos testar o modelo com Automodel e AutoTokenizer
InputPythonfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationimport torchmodel_name = "GPT2-small-finetuned-amazon-reviews-en-classification"user = "maximofn"checkpoint = f"{user}/{model_name}"num_classes = num_classestokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes).half().eval().to("cuda")Copied
InputPythontokens = tokenizer.encode("I love this product", return_tensors="pt").to(model.device)with torch.no_grad():output = model(tokens)logits = output.logitslables = torch.softmax(logits, dim=1).cpu().numpy().tolist()lables[0]Copied
[0.003940582275390625,0.00266265869140625,0.013946533203125,0.1544189453125,0.8251953125]
Se você quiser testar mais o modelo, você pode vê-lo em Maximofn/GPT2-small-LoRA-finetuned-amazon-reviews-en-classification
Implementação de LoRA em um LLM com PEFT da Hugging Face
Podemos fazer o mesmo com a biblioteca PEFT do Hugging Face. Vamos vê-lo.
Login no Hub
Nós fazemos login para fazer o upload do modelo para o Hub
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
Conjunto de Dados
Voltamos a baixar o dataset
InputPythonfrom datasets import load_datasetdataset = load_dataset("mteb/amazon_reviews_multi", "en")datasetCopied
DatasetDict({train: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000})validation: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})test: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})})
Criamos um subconjunto caso você queira testar o código com um conjunto de dados menor. No meu caso, usarei 100% do conjunto de dados.
InputPythonpercentage = 1subset_dataset_train = dataset['train'].select(range(int(len(dataset['train']) * percentage)))subset_dataset_validation = dataset['validation'].select(range(int(len(dataset['validation']) * percentage)))subset_dataset_test = dataset['test'].select(range(int(len(dataset['test']) * percentage)))subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}))
Obtemos o número de classes, para obter o número de classes usamos dataset['train'] e não subset_dataset_train porque se o subconjunto for muito pequeno é possível que não haja exemplos com todas as possíveis classes do conjunto de dados original
InputPythonnum_classes = len(dataset['train'].unique('label'))num_classesCopied
5
Criamos uma função para criar o campo label no dataset. O dataset baixado tem o campo labels, mas a biblioteca transformers precisa que o campo seja chamado de label e não labels.
InputPythondef set_labels(example):example['labels'] = example['label']return exampleCopied
Aplicamos a função ao conjunto de dados
InputPythonsubset_dataset_train = subset_dataset_train.map(set_labels)subset_dataset_validation = subset_dataset_validation.map(set_labels)subset_dataset_test = subset_dataset_test.map(set_labels)subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}))
Tokenizador
Instanciamos o tokenizador. Para que não nos dê erro, atribuímos o token de end of string ao token de padding
InputPythonfrom transformers import AutoTokenizercheckpoint = "openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoint)tokenizer.pad_token = tokenizer.eos_tokenCopied
Criamos uma função para tokenizar o dataset
InputPythondef tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=768, return_tensors="pt")Copied
Aplicamos a função ao conjunto de dados e, de passagem, eliminamos as colunas que não precisamos.
InputPythonsubset_dataset_train = subset_dataset_train.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_validation = subset_dataset_validation.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_test = subset_dataset_test.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 200000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}))
Modelo
Instanciamos o modelo. Também, para que não dê erro, atribuímos o token de end of string ao token de padding
InputPythonfrom transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes)model.config.pad_token_id = model.config.eos_token_idCopied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
LoRA com PEFT
Antes de criar o modelo com LoRA, vamos a ver suas camadas
InputPythonmodelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
Como podemos ver, há apenas uma camada Linear, que é score e que é a que vamos substituir.
Podemos criar uma configuração de LoRA com a biblioteca PEFT e depois aplicar LoRA ao mo
InputPythonfrom peft import LoraConfig, TaskTypepeft_config = LoraConfig(r=16,lora_alpha=32,lora_dropout=0.1,task_type=TaskType.SEQ_CLS,target_modules=["score"],)Copied
Com esta configuração, definimos um rank de 16 e um alpha de 32. Além disso, adicionamos um dropout às camadas de LoRA de 0.1. Precisamos indicar a tarefa para a configuração de LoRA, neste caso é uma tarefa de sequence classification. Por fim, indicamos quais camadas queremos substituir, neste caso a camada score.
Agora aplicamos LoRA ao modelo
InputPythonfrom peft import get_peft_modelmodel = get_peft_model(model, peft_config)Copied
Vamos ver quantos parâmetros treináveis o modelo tem agora.
InputPythonmodel.print_trainable_parameters()Copied
trainable params: 12,368 || all params: 124,456,016 || trainable%: 0.0099
Obtemos os mesmos parâmetros treináveis que antes
Treinamento
Uma vez instanciado o modelo com LoRA, vamos treiná-lo como sempre
InputPythonfrom transformers import TrainingArgumentsmetric_name = "accuracy"model_name = "GPT2-small-PEFT-LoRA-finetuned-amazon-reviews-en-classification"LR = 2e-5BS_TRAIN = 400BS_EVAL = 400EPOCHS = 3WEIGHT_DECAY = 0.01training_args = TrainingArguments(model_name,eval_strategy="epoch",save_strategy="epoch",learning_rate=LR,per_device_train_batch_size=BS_TRAIN,per_device_eval_batch_size=BS_EVAL,num_train_epochs=EPOCHS,weight_decay=WEIGHT_DECAY,lr_scheduler_type="cosine",warmup_ratio = 0.1,fp16=True,load_best_model_at_end=True,metric_for_best_model=metric_name,push_to_hub=True,logging_dir="./runs",)Copied
InputPythonimport numpy as npfrom evaluate import loadmetric = load("accuracy")def compute_metrics(eval_pred):print(eval_pred)predictions, labels = eval_predpredictions = np.argmax(predictions, axis=1)return metric.compute(predictions=predictions, references=labels)Copied
InputPythonfrom transformers import Trainertrainer = Trainer(model,training_args,train_dataset=subset_dataset_train,eval_dataset=subset_dataset_validation,tokenizer=tokenizer,compute_metrics=compute_metrics,)Copied
InputPythontrainer.train()Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7f774a50bbe0>
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7f77486a7c40><transformers.trainer_utils.EvalPrediction object at 0x7f7749eb5690>
TrainOutput(global_step=1500, training_loss=1.751504597981771, metrics={'train_runtime': 2551.7753, 'train_samples_per_second': 235.13, 'train_steps_per_second': 0.588, 'total_flos': 2.352524525568e+17, 'train_loss': 1.751504597981771, 'epoch': 3.0})
Avaliação
Uma vez treinado, avaliamos sobre o dataset de teste
InputPythontrainer.evaluate(eval_dataset=subset_dataset_test)Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7f77a1d1f7c0>
{'eval_loss': 1.4127237796783447,'eval_accuracy': 0.3862,'eval_runtime': 19.3275,'eval_samples_per_second': 258.699,'eval_steps_per_second': 0.673,'epoch': 3.0}
Publicar o modelo
Criamos uma model card
InputPythontrainer.create_model_card()Copied
O publicamos
InputPythontrainer.push_to_hub()Copied
CommitInfo(commit_url='https://huggingface.co/Maximofn/GPT2-small-PEFT-LoRA-finetuned-amazon-reviews-en-classification/commit/839066c2bde02689a6b3f5624ac25f89c4de217d', commit_message='End of training', commit_description='', oid='839066c2bde02689a6b3f5624ac25f89c4de217d', pr_url=None, pr_revision=None, pr_num=None)
Teste do modelo treinado com PEFT
Limpamos tudo o possível
InputPythonimport torchimport gcdef clear_hardwares():torch.clear_autocast_cache()torch.cuda.ipc_collect()torch.cuda.empty_cache()gc.collect()clear_hardwares()clear_hardwares()Copied
Como subimos o modelo ao nosso hub, podemos baixá-lo e usá-lo
InputPythonfrom transformers import pipelineuser = "maximofn"checkpoints = f"{user}/{model_name}"task = "text-classification"classifier = pipeline(task, model=checkpoints, tokenizer=checkpoints)Copied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Agora, se quisermos que nos retorne a probabilidade de todas as classes, simplesmente usamos o classificador que acabamos de instanciar, com o parâmetro top_k=None
InputPythonlabels = classifier("I love this product", top_k=None)labelsCopied
[{'label': 'LABEL_1', 'score': 0.9979197382926941},{'label': 'LABEL_0', 'score': 0.002080311067402363}]
Se quisermos apenas a classe com a maior probabilidade fazemos o mesmo mas com o parâmetro top_k=1
InputPythonlabel = classifier("I love this product", top_k=1)labelCopied
[{'label': 'LABEL_1', 'score': 0.9979197382926941}]
E se quisermos n classes, fazemos o mesmo mas com o parâmetro top_k=n
InputPythontwo_labels = classifier("I love this product", top_k=2)two_labelsCopied
[{'label': 'LABEL_1', 'score': 0.9979197382926941},{'label': 'LABEL_0', 'score': 0.002080311067402363}]
Se você quiser testar mais o modelo, pode vê-lo em Maximofn/GPT2-small-PEFT-LoRA-finetuned-amazon-reviews-en-classification

















