
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
Agora que os LLMs estão em alta, não paramos de ouvir o número de tokens que cada modelo suporta, mas o que são os tokens? São as unidades mínimas de representação das palavras
Para explicar o que são os tokens, primeiro vejamos com um exemplo prático, vamos usar o tokenizador de OpenAI, chamado tiktoken.
Então, primeiro instalamos o pacote:
pip install tiktokenUma vez instalado, criamos um tokenizador usando o modelo cl100k_base, que no notebook de exemplo How to count tokens with tiktoken explica que é o usado pelos modelos gpt-4, gpt-3.5-turbo e text-embedding-ada-002
InputPythonimport tiktokenencoder = tiktoken.get_encoding("cl100k_base")Copied
Agora criamos uma palavra de exemplo para tokenizá-la
InputPythonexample_word = "breakdown"Copied
E tokenizamos
InputPythontokens = encoder.encode(example_word)tokensCopied
[9137, 2996]
A palavra foi dividida em 2 tokens, o 9137 e o 2996. Vamos ver a quais palavras correspondem.
InputPythonword1 = encoder.decode([tokens[0]])word2 = encoder.decode([tokens[1]])word1, word2Copied
('break', 'down')
O tokenizador da OpenAI dividiu a palavra breakdown nas palavras break e down. Ou seja, ele dividiu a palavra em 2 mais simples.
Isto é importante, pois quando se diz que um LLM suporta x tokens, não significa que ele suporta x palavras, mas sim que ele suporta x unidades mínimas de representação das palavras.
Se você tem um texto e quer ver o número de tokens que ele possui para o tokenizador de OpenAI, pode verificar na página Tokenizer, que mostra cada token em uma cor diferente.
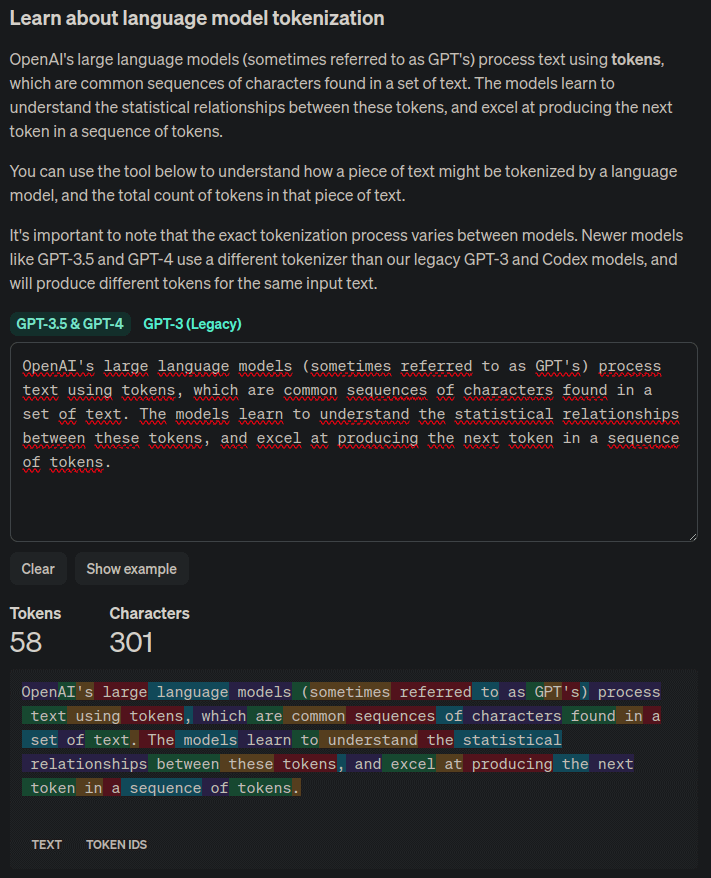
Vimos o tokenizador da OpenAI, mas cada LLM poderá usar outro.
Como dissemos, os tokens são as unidades mínimas de representação das palavras, então vamos ver quantos tokens distintos tem tiktoken
InputPythonn_vocab = encoder.n_vocabprint(f"Vocab size: {n_vocab}")Copied
Vocab size: 100277
Vamos a ver como tokeniza outro tipo de palavras
InputPythondef encode_decode(word):tokens = encoder.encode(word)decode_tokens = []for token in tokens:decode_tokens.append(encoder.decode([token]))return tokens, decode_tokensCopied
InputPythonword = "dog"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "tomorrow..."tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "artificial intelligence"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "Python"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "12/25/2023"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "😊"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")Copied
Word: dog ==> tokens: [18964], decode_tokens: ['dog']Word: tomorrow... ==> tokens: [38501, 7924, 1131], decode_tokens: ['tom', 'orrow', '...']Word: artificial intelligence ==> tokens: [472, 16895, 11478], decode_tokens: ['art', 'ificial', ' intelligence']Word: Python ==> tokens: [31380], decode_tokens: ['Python']Word: 12/25/2023 ==> tokens: [717, 14, 914, 14, 2366, 18], decode_tokens: ['12', '/', '25', '/', '202', '3']Word: 😊 ==> tokens: [76460, 232], decode_tokens: ['�', '�']
Por último vamos a vê-lo com palavras em outro idioma
InputPythonword = "perro"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "perra"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "mañana..."tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "inteligencia artificial"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "Python"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "12/25/2023"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "😊"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")Copied
Word: perro ==> tokens: [716, 299], decode_tokens: ['per', 'ro']Word: perra ==> tokens: [79, 14210], decode_tokens: ['p', 'erra']Word: mañana... ==> tokens: [1764, 88184, 1131], decode_tokens: ['ma', 'ñana', '...']Word: inteligencia artificial ==> tokens: [396, 39567, 8968, 21075], decode_tokens: ['int', 'elig', 'encia', ' artificial']Word: Python ==> tokens: [31380], decode_tokens: ['Python']Word: 12/25/2023 ==> tokens: [717, 14, 914, 14, 2366, 18], decode_tokens: ['12', '/', '25', '/', '202', '3']Word: 😊 ==> tokens: [76460, 232], decode_tokens: ['�', '�']
Podemos ver para palavras semelhantes, em espanhol são gerados mais tokens do que em inglês, portanto, para um mesmo texto, com um número similar de palavras, o número de tokens será maior em espanhol do que em inglês.

















