
Si bien LoRA proporciona una manera de hacer fine tuning de modelos de lenguaje sin necesidad de GPUs con grandes VRAMs, en el paper de QLoRA van más allá y proponen la manera de hacer fine tuning de modelo cuantizados, haciendo que se necesite aún menos memoria para hacer fine tuning de modelos de lenguaje.
LoRA
Actualización de pesos en una red neuronal
Para entender cómo funciona LoRA, primero tenemos que recordar qué ocurre cuando entrenamos un modelo. Volvamos a la parte más básica del deep learning, tenemos una capa densa de una red neuronal que se define como:
y = Wx + b
Dónde W es la matriz de pesos y b es el vector de sesgos.
Para simplificar, vamos a suponer que no hay sesgo, por lo que quedaría así
y = Wx
Supongamos que para una entrada x queremos que tenga una salida \hat{y}
- Primero, lo que hacemos es calcular la salida que obtenemos con nuestro valor actual de pesos W, es decir, obtenemos el valor y
- A continuación calculamos el error que existe entre el valor de y que hemos obtenido y el valor que queríamos obtener \hat{y}. A ese error lo llamamos loss, y lo calculamos con alguna función matemática, ahora no importa cual
- Calculamos el gradiente (la derivada) del error loss con respecto a la matriz de pesos W, es decir \Delta W = \frac{dloss}{dW}
- Actualizamos los pesos W restando a cada uno de sus valores el valor del gradiente multiplicado por un factor de aprendizaje \alpha, es decir W = W - \alpha \Delta W
LoRA
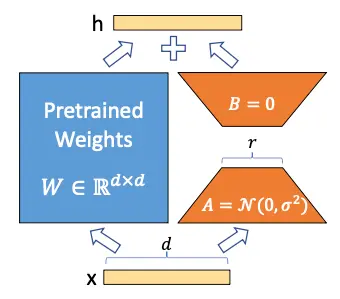
Los autores de LoRA proponen que la matriz de pesos W se puede descomponer en
W \sim W + \Delta W
De manera que congelando la matriz W y entrenando solo la matriz \Delta W se puede obtener un modelo que se adapte a nuevos datos sin tener que reentrenar todo el modelo
Pero podrás pensar que \Delta W es una matriz de tamaño igual a W por lo que no se ha ganado nada, pero aquí los autores se basan en Aghajanyan et al. (2020), un paper en el que demostraron que aunque los modelos de lenguaje son grandes y sus parámetros son matrices con dimensiones muy grandes, para adaptarlos a nuevas tareas no es necesario cambiar todos los valores de las matrices, sino que cambiando unos pocos valores es suficiente, que en términos técnicos, se llama adaptación de bajo rango. De ahí el nombre de LoRA (Low Rank Adaptation)
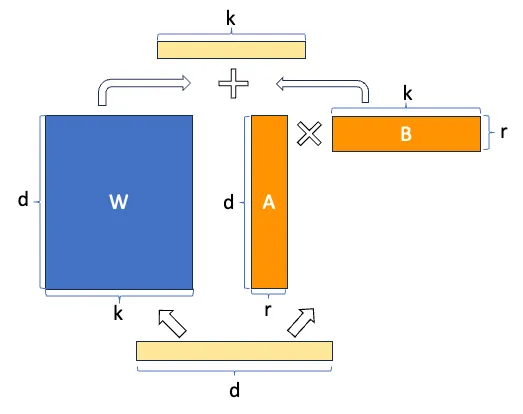
Hemos congelado el modelo y ahora queremos entrenar la matriz \Delta W, supongamos que tanto W como \Delta W son matrices de tamaño 20 × 10, por lo que tenemos 200 parámetros entrenables
Ahora supongamos que la matriz \Delta W se puede descomponer en el producto de dos matrices A y B, es decir
\Delta W = A · B
Para que esta multiplicación se produzca los tamaños de las matrices A y B tienen que ser 20 × n y n × 10 respectivamente. Supongamos que n = 5, por lo que A sería de tamaño 20 × 5, es decir 100 parámetros, y B de tamaño 5 × 10, es decir 50 parámetros, por lo que tendríamos 100+50=150 parámetros entrenables. Ya tenemos menos parámetros entrenables que antes
Ahora supongamos que W en realidad es una matriz de tamaño 10.000 × 10.000, por lo que tendríamos 100.000.000 parámetros entrenables, pero si descomponemos \Delta W en A y B con n = 5, tendríamos una matriz de tamaño 10.000 × 5 y otra de tamaño 5 × 10.000, por lo que tendríamos 50.000 parámetros de una y otros 50.000 parámetros de otra, en total 100.000 parámetros entrenables, es decir hemos reducido el número de parámetros mil veces
Ya puedes ir viendo el poder de LoRA, cuando se tienen modelos muy grandes, el número de parámetros entrenables se puede reducir muchísimo
Si volvemos a ver la imagen de la arquitectura de LoRA, la entenderemos mejor
Pero se ve mejor aún, el ahorro en número de parámetros entrenables con esta imagen
QLoRA
QLoRA se realiza en dos pasos, la primera consiste en cuantizar el moelo y la segunda en aplicar LoRA al modelo cuantizado
Cuantización QLoRA
La cuantización de QLoRA se basa en tres conceptos, la cuantización del modelo a 4 bits con el formato normal float 4 (NF4), la doble cuantización y los optimizadores paginados. Todo ello junto hace que se pueda ahorrar mucha memoria al hacer fine tuning de los modelos de lenguaje, así que vamos a ver en qué consiste cada uno
Cuantización de los modelos de lenguaje en normal float 4 (NF4)
En QLoRA, para cuantizar, lo que se hace es cuantizar en formato normal float 4 (NF4), que es un tipo de cuantización a 4 bits de manera que sus datos tienen una distribución normal, es decir que siguen una campana de Gauss. Para conseguir que sigan esta distribución, lo que se hace es dividir los valores de los pesos en FP16 en quantiles, de manera que en cada quantil haya el mismo número de valores. Una vez tenemos los cuantiles, a cada cuantil se le asigna un valor en 4 bits
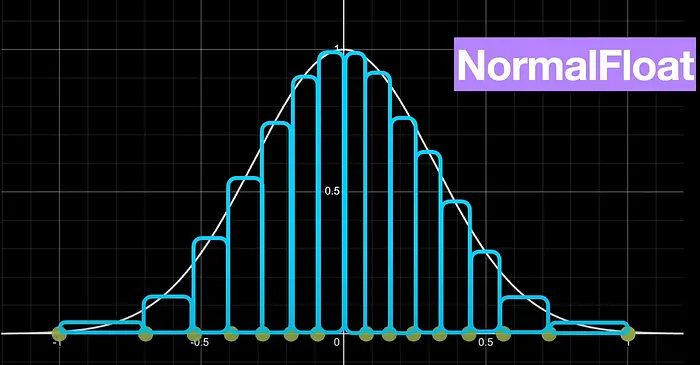
Para realizar esta cuantización utiliza el algoritmo de cuantización SRAM, que es un algoritmo de cuantización por quantiles muy rápido, pero tiene mucho error con valores que están muy lejos en la distribución de la campana de Gauss, valores atípicos
Como normalmente los parámetros de los pesos de una red neuronal suelen seguir una distribución normal (es decir, que siguen una campana de Gauss), centrada en cero y con una desviación estándar σ. Lo que se hace es normalizarlos para que tengan una desviación estándar entre -1 y 1, y después se cuantizan en formato NF4
Doble cuantización
Como hemos comentado, a la hora de cuantizar los parámetros de la red, tenemos que normalizarlos para que tengan una desviación estándar entre -1 y 1, y después cuantizarlos en formato NF4. Por lo que tenemos que guardar algunos parámetros como los valores para normalizar los parámetros, es decir, el valor por el que se dividen los datos para que tengan una desviación entre -1 y 1. Esos valores se almacenan en formato FP32, por lo que los autores del paper proponen cuantizar esos parámetros a formato FP8.
Aunque esto puede parecer que no ahorra mucha memoria, los autores calculan que esto puede ahorrar unos 0.373 bits por parámetro, pero si por ejemplo tenemos un modelo de 8B de parámetros, que no es un modelo excesivamente grande a día de hoy, nos ahorraríamos unos 3 GB de memoria, que no está mal. En el caso de un modelo de 70B de parámetros, nos ahorraríamos unos 26 GB de memoria
Optimizadores paginados
Las GPUs de Nvidia tienen la opción de compartir la RAM de la GPU y de la CPU, de manera que lo que hacen es guardar los estados del optimizador en la RAM de la CPU y acceder a ellos cuando lo necesitan. Así no se tienen que guardar en la RAM de la GPU y podemos ahorrar memoria de la GPU
Fine tuning con LoRA
Una vez hemos cuantizado el modelo ya podemos hacer fine tuning del modelo cuantizado igual que se hace en LoRA
Cómo hacer fine tuning de un modelo cuantizado con QLoRA
Ahora que hemos explicado QLoRA, vamos a ver un ejemplo de cómo hacer fine tuning a un modelo usando QLoRA
Login en el Hub de Hugging Face
Primero nos logeamos para poder subir el modelo entrenado al Hub
from huggingface_hub import notebook_loginnotebook_login()Copied
Dataset
Descargamos el dataset que vamos a usar, que es un dataset de reviews de Amazon
from datasets import load_datasetdataset = load_dataset("mteb/amazon_reviews_multi", "en")datasetCopied
DatasetDict({train: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000})validation: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})test: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})})
Creamos un subset por si quieres probar el código con un dataset más pequeño. En mi caso usaré el 100% del dataset
percentage = 1subset_dataset_train = dataset['train'].select(range(int(len(dataset['train']) * percentage)))subset_dataset_validation = dataset['validation'].select(range(int(len(dataset['validation']) * percentage)))subset_dataset_test = dataset['test'].select(range(int(len(dataset['test']) * percentage)))subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000}))
Vemos una muestra
from random import randintidx = randint(0, len(subset_dataset_train))subset_dataset_train[idx]Copied
{'id': 'en_0297000','text': 'Not waterproof at all Bought this after reading good reviews. But it’s not water proof at all. If my son has even a little accident in bed, it goes straight to mattress. I don’t see a point in having this. So I have to purchase another one.','label': 0,'label_text': '0'}
Obtenemos el número de clases, para obtener el número de clases usamos dataset['train'] y no subset_dataset_train porque si el subset lo hemos muy pequeño es posible que no haya ejemplos con todas las posibles clases del dataset original
num_classes = len(dataset['train'].unique('label'))num_classesCopied
5
Creamos una función para crear el campo label en el dataset. El dataset descargado tiene el campo labels pero la librería transformers necesita que el campo se llame label y no labels
def set_labels(example):example['labels'] = example['label']return exampleCopied
Aplicamos la función al dataset
subset_dataset_train = subset_dataset_train.map(set_labels)subset_dataset_validation = subset_dataset_validation.map(set_labels)subset_dataset_test = subset_dataset_test.map(set_labels)subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 200000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}),Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000}))
Volvemos a ver una muestra
subset_dataset_train[idx]Copied
{'id': 'en_0297000','text': 'Not waterproof at all Bought this after reading good reviews. But it’s not water proof at all. If my son has even a little accident in bed, it goes straight to mattress. I don’t see a point in having this. So I have to purchase another one.','label': 0,'label_text': '0','labels': 0}
Tokenizer
Implementamos el tokenizador. Para que no nos dé error, asignamos el token de end of string al token de padding
from transformers import AutoTokenizercheckpoint = "openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoint)tokenizer.pad_token = tokenizer.eos_tokenCopied
Creamos una función para tokenizar el dataset
def tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=768, return_tensors="pt")Copied
Aplicamos la función al dataset y, de paso, eliminamos las columnas que no necesitamos
subset_dataset_train = subset_dataset_train.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_validation = subset_dataset_validation.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_test = subset_dataset_test.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])subset_dataset_train, subset_dataset_validation, subset_dataset_testCopied
(Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 200000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}),Dataset({features: ['labels', 'input_ids', 'attention_mask'],num_rows: 5000}))
Volvemos a ver una muestra, pero en este caso solo vemos las keys
subset_dataset_train[idx].keys()Copied
dict_keys(['labels', 'input_ids', 'attention_mask'])
Modelo
Descargamos primero el modelo sin cuantizar
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes)model.config.pad_token_id = model.config.eos_token_idCopied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Vemos la memoria que ocupa
model_memory = model.get_memory_footprint()/(1024**3)print(f"Model memory: {model_memory:.2f} GB")Copied
Model memory: 0.48 GB
Pasamos el modelo a FP16 y volvemos a ver la memoria que ocupa
model = model.half()Copied
model_memory = model.get_memory_footprint()/(1024**3)print(f"Model memory: {model_memory:.2f} GB")Copied
Model memory: 0.24 GB
Vemos la arquitectura del modelo antes de cuantizar
modelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
Cuantización del modelo
Para cuantizar el modelo primero tenemos que crear la configuración de cuantización, para ello usamos la librería bitsandbytes, si no la tienes instalada la puedes instalar con
pip install bitsandbytesPrimero comprobamos si la arquitectura de nuestra GPU permite el formato BF16, si no lo permite usaremos FP16
A continuación creamos la configuración de cuantización, con load_in_4bits=True indicamos que cuantice a 4 bits, con bnb_4bit_quant_type="nf4" le indicamos que lo haga en formato NF4, con bnb_4bit_use_double_quant=True le indicamos que haga doble cuantización y con bnb_4bit_compute_dtype=compute_dtype le indicamos qué formato de datos tiene que usar cuando descuantice, que puede ser FP16 o BF16.
from transformers import BitsAndBytesConfigimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type="nf4",bnb_4bit_use_double_quant=True,bnb_4bit_compute_dtype=compute_dtype,)Copied
Y ahora cuantizamos el modelo
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes, quantization_config=bnb_config)Copied
`low_cpu_mem_usage` was None, now set to True since model is quantized.Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Volvemos a ver la memoria que ocupa ahora que lo hemos cuantizado
model_memory = model.get_memory_footprint()/(1024**3)print(f"Model memory: {model_memory:.2f} GB")Copied
Model memory: 0.12 GB
Vemos que se ha reducido el tamaño del modelo
Volvemos a ver la arquitectura del modelo una vez cuantizado
modelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Linear4bit(in_features=768, out_features=2304, bias=True)(c_proj): Linear4bit(in_features=768, out_features=768, bias=True)(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Linear4bit(in_features=768, out_features=3072, bias=True)(c_proj): Linear4bit(in_features=3072, out_features=768, bias=True)(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
Vemos que la arquitectura ha cambiado
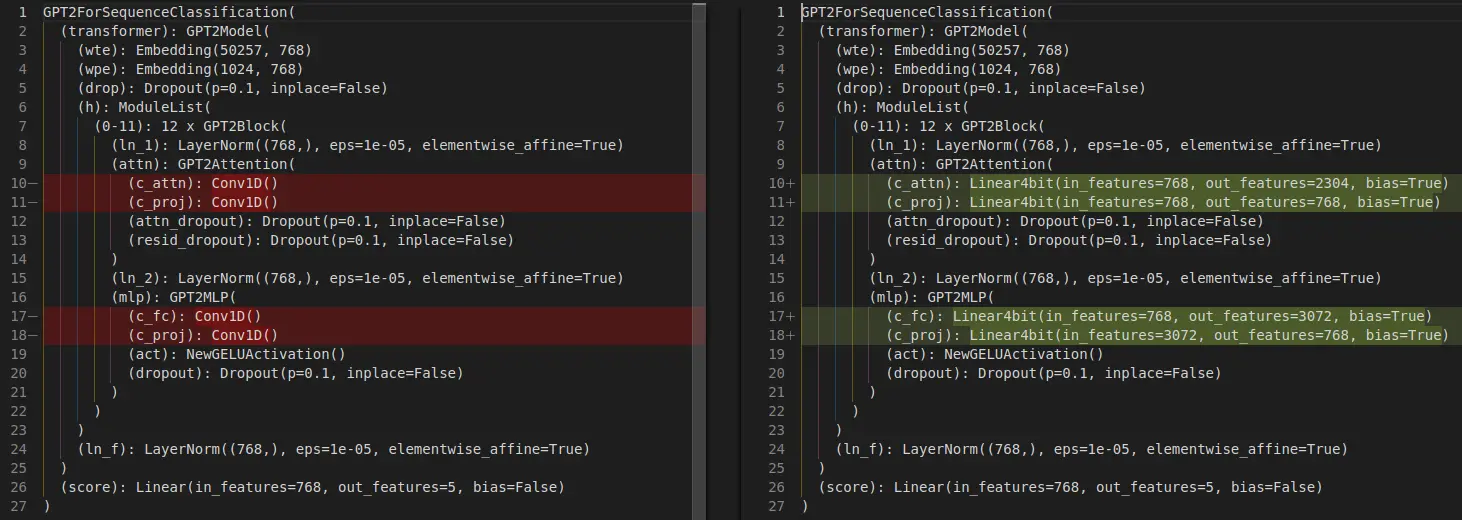
Ha modificado las capas Conv1D por capas Linear4bits
LoRA
Antes de implementar LoRA, tenemos que configurar el modelo para entrenar en 4 bits
from peft import prepare_model_for_kbit_trainingmodel = prepare_model_for_kbit_training(model)Copied
Vamos a ver si ha cambiado el tamaño del modelo
model_memory = model.get_memory_footprint()/(1024**3)print(f"Model memory: {model_memory:.2f} GB")Copied
Model memory: 0.20 GB
Ha aumentado la memoria, así que volvemos a ver la arquitectura del modelo
modelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Linear4bit(in_features=768, out_features=2304, bias=True)(c_proj): Linear4bit(in_features=768, out_features=768, bias=True)(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Linear4bit(in_features=768, out_features=3072, bias=True)(c_proj): Linear4bit(in_features=3072, out_features=768, bias=True)(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
La arquitectura sigue siendo la misma, por lo que suponemos que el aumento de memoria es por alguna configuración extra para poder aplicar LoRA en 4 bits
Creamos una configuración de LoRA, pero a diferencia del post de LoRA en el que solo configuramos en target_modules la capa scores, ahora vamos a añadir también las capas c_attn, c_proj y c_fc ya que ahora son de tipo Linear4bits y no Conv1D
from peft import LoraConfig, TaskTypeconfig = LoraConfig(r=16,lora_alpha=32,lora_dropout=0.1,task_type=TaskType.SEQ_CLS,target_modules=['c_attn', 'c_fc', 'c_proj', 'score'],bias="none",)Copied
from peft import get_peft_modelmodel = get_peft_model(model, config)Copied
model.print_trainable_parameters()Copied
trainable params: 2,375,504 || all params: 126,831,520 || trainable%: 1.8730
Mientras que en el post de LoRA teníamos unos 12.000 parámetros entrenables, ahora tenemos unos 2 millones, ya que ahora hemos añadido las capas c_attn, c_proj y c_fc
Training
Una vez instanciado el modelo cuantizado y aplicado LoRA, es decir, una vez hemos hecho QLoRA, vamos a entrenarlo como siempre
from transformers import TrainingArgumentsmetric_name = "accuracy"model_name = "GPT2-small-QLoRA-finetuned-amazon-reviews-en-classification"LR = 2e-5BS_TRAIN = 224BS_EVAL = 224EPOCHS = 3WEIGHT_DECAY = 0.01training_args = TrainingArguments(model_name,eval_strategy="epoch",save_strategy="epoch",learning_rate=LR,per_device_train_batch_size=BS_TRAIN,per_device_eval_batch_size=BS_EVAL,num_train_epochs=EPOCHS,weight_decay=WEIGHT_DECAY,lr_scheduler_type="cosine",warmup_ratio = 0.1,fp16=True,load_best_model_at_end=True,metric_for_best_model=metric_name,push_to_hub=True,logging_dir="./runs",)Copied
En el post Fine tuning SMLs tuvimos que poner un BS de train de 28, en el post LoRA al poner las matrices de bajo rango en las capas lineales hizo que pudiéramos poner un batch size de train de 400. Ahora, como al cuantizar el modelo, la librería PEFT ha convertido algunas capas más a Linear no podemos poner un batch size tan grande y lo tenemos que poner de 224
import numpy as npfrom evaluate import loadmetric = load("accuracy")def compute_metrics(eval_pred):print(eval_pred)predictions, labels = eval_predpredictions = np.argmax(predictions, axis=1)return metric.compute(predictions=predictions, references=labels)Copied
from transformers import Trainertrainer = Trainer(model,training_args,train_dataset=subset_dataset_train,eval_dataset=subset_dataset_validation,tokenizer=tokenizer,compute_metrics=compute_metrics,)Copied
trainer.train()Copied
`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`.../usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py:464: UserWarning: torch.utils.checkpoint: the use_reentrant parameter should be passed explicitly. In version 2.4 we will raise an exception if use_reentrant is not passed. use_reentrant=False is recommended, but if you need to preserve the current default behavior, you can pass use_reentrant=True. Refer to docs for more details on the differences between the two variants.warnings.warn(
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7acac436c3d0>
/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py:464: UserWarning: torch.utils.checkpoint: the use_reentrant parameter should be passed explicitly. In version 2.4 we will raise an exception if use_reentrant is not passed. use_reentrant=False is recommended, but if you need to preserve the current default behavior, you can pass use_reentrant=True. Refer to docs for more details on the differences between the two variants.warnings.warn(
<transformers.trainer_utils.EvalPrediction object at 0x7acac32580d0>
/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py:464: UserWarning: torch.utils.checkpoint: the use_reentrant parameter should be passed explicitly. In version 2.4 we will raise an exception if use_reentrant is not passed. use_reentrant=False is recommended, but if you need to preserve the current default behavior, you can pass use_reentrant=True. Refer to docs for more details on the differences between the two variants.warnings.warn(
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7acac2f43c10>
TrainOutput(global_step=2679, training_loss=1.1650676093647934, metrics={'train_runtime': 11299.1288, 'train_samples_per_second': 53.101, 'train_steps_per_second': 0.237, 'total_flos': 2.417754341376e+17, 'train_loss': 1.1650676093647934, 'epoch': 3.0})
Evaluación
Una vez entrenado, evaluamos sobre el dataset de test
trainer.evaluate(eval_dataset=subset_dataset_test)Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7acb316fe5c0>
{'eval_loss': 0.8883273601531982,'eval_accuracy': 0.615,'eval_runtime': 28.5566,'eval_samples_per_second': 175.091,'eval_steps_per_second': 0.805,'epoch': 3.0}
Publicar el modelo
Creamos una model card
trainer.create_model_card()Copied
Lo publicamos
trainer.push_to_hub()Copied
Probar el modelo
Vamos aprobar el modelo
from transformers import AutoTokenizer, AutoModelForSequenceClassificationimport torchmodel_name = "GPT2-small-QLoRA-finetuned-amazon-reviews-en-classification"user = "maximofn"checkpoint = f"{user}/{model_name}"num_classes = 5tokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes).half().eval().to("cuda")Copied
/home/sae00531/miniconda3/envs/nlp_/lib/python3.11/site-packages/huggingface_hub/file_download.py:1132: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.warnings.warn(Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference./home/sae00531/miniconda3/envs/nlp_/lib/python3.11/site-packages/peft/tuners/lora/layer.py:1119: UserWarning: fan_in_fan_out is set to False but the target module is `Conv1D`. Setting fan_in_fan_out to True.warnings.warn(Loading adapter weights from maximofn/GPT2-small-QLoRA-finetuned-amazon-reviews-en-classification led to unexpected keys not found in the model: ['score.modules_to_save.default.base_layer.weight', 'score.modules_to_save.default.lora_A.default.weight', 'score.modules_to_save.default.lora_B.default.weight', 'score.modules_to_save.default.modules_to_save.lora_A.default.weight', 'score.modules_to_save.default.modules_to_save.lora_B.default.weight', 'score.modules_to_save.default.original_module.lora_A.default.weight', 'score.modules_to_save.default.original_module.lora_B.default.weight'].
tokens = tokenizer.encode("I love this product", return_tensors="pt").to(model.device)with torch.no_grad():output = model(tokens)logits = output.logitslables = torch.softmax(logits, dim=1).cpu().numpy().tolist()lables[0]Copied
[0.0186614990234375,0.483642578125,0.048187255859375,0.415283203125,0.03399658203125]
















