
En este post vamos a ver en qué consiste la técnica de RAG (Retrieval Augmented Generation) y cómo se puede implementar en un modelo de lenguaje. Además, lo haremos con la arquitectura de RAG más básica, llamada naive RAG.
Para que te salga gratis, en vez de usar una cuenta de OpenAI (como verás en la mayoría de tutoriales) vamos a usar el API inference de Hugging Face, que tiene un free tier de 1000 requests al día, que para hacer este post es más que suficiente.
Configuración de la API Inference de Hugging Face
Para poder usar la API Inference de HuggingFace, lo primero que necesitas es tener una cuenta en HuggingFace. Una vez la tengas, hay que ir a Access tokens en la configuración de tu perfil y generar un nuevo token.
Hay que ponerle un nombre. En mi caso, le voy a poner rag-fundamentals y habilitar el permiso Make calls to serverless Inference API. Nos creará un token que tendremos que copiar
Para gestionar el token, vamos a crear un archivo en la misma ruta en la que estemos trabajando llamado ".env" y vamos a poner el token que hemos copiado en el archivo de la siguiente manera:
RAG_FUNDAMENTALS_ADVANCE_TECHNIQUES_TOKEN="hf_...."Ahora, para poder obtener el token, necesitamos tener instalado dotenv, que lo instalamos mediante
pip install python-dotenvY ejecutamos lo siguiente
import osimport dotenvdotenv.load_dotenv()RAG_FUNDAMENTALS_ADVANCE_TECHNIQUES_TOKEN = os.getenv("RAG_FUNDAMENTALS_ADVANCE_TECHNIQUES_TOKEN")Copied
Ahora que tenemos un token, creamos un cliente. Para ello, necesitamos tener instalada la librería huggingface_hub. La instalamos mediante conda o pip.
conda install -c conda-forge huggingface_hubo
pip install --upgrade huggingface_hubAhora tenemos que elegir qué modelo vamos a usar. Puedes ver los modelos disponibles en la página de Supported models de la documentación de la API Inference de Hugging Face.
Como a la hora de escribir el post, el mejor disponible es Qwen2.5-72B-Instruct, vamos a usar ese modelo.
MODEL = "Qwen/Qwen2.5-72B-Instruct"Copied
Ahora podemos crear el cliente
from huggingface_hub import InferenceClientclient = InferenceClient(api_key=RAG_FUNDAMENTALS_ADVANCE_TECHNIQUES_TOKEN, model=MODEL)clientCopied
<InferenceClient(model='Qwen/Qwen2.5-72B-Instruct', timeout=None)>
Hacemos una prueba a ver si funciona
message = [{ "role": "user", "content": "Hola, qué tal?" }]stream = client.chat.completions.create(messages=message,temperature=0.5,max_tokens=1024,top_p=0.7,stream=False)response = stream.choices[0].message.contentprint(response)Copied
¡Hola! Estoy bien, gracias por preguntar. ¿Cómo estás tú? ¿En qué puedo ayudarte hoy?
¿Qué es RAG?
RAG son las siglas de Retrieval Augmented Generation, es una técnica creada para obtener información de documentos. Aunque los LLMs pueden llegar a ser muy poderosos y tener mucho conocimiento, nunca van a ser capaces de responder sobre unos documentos privados, como informes de tu empresa, documentación interna, etc. Por ello se creó RAG, para poder usar estos LLMs en esa documentación privada.
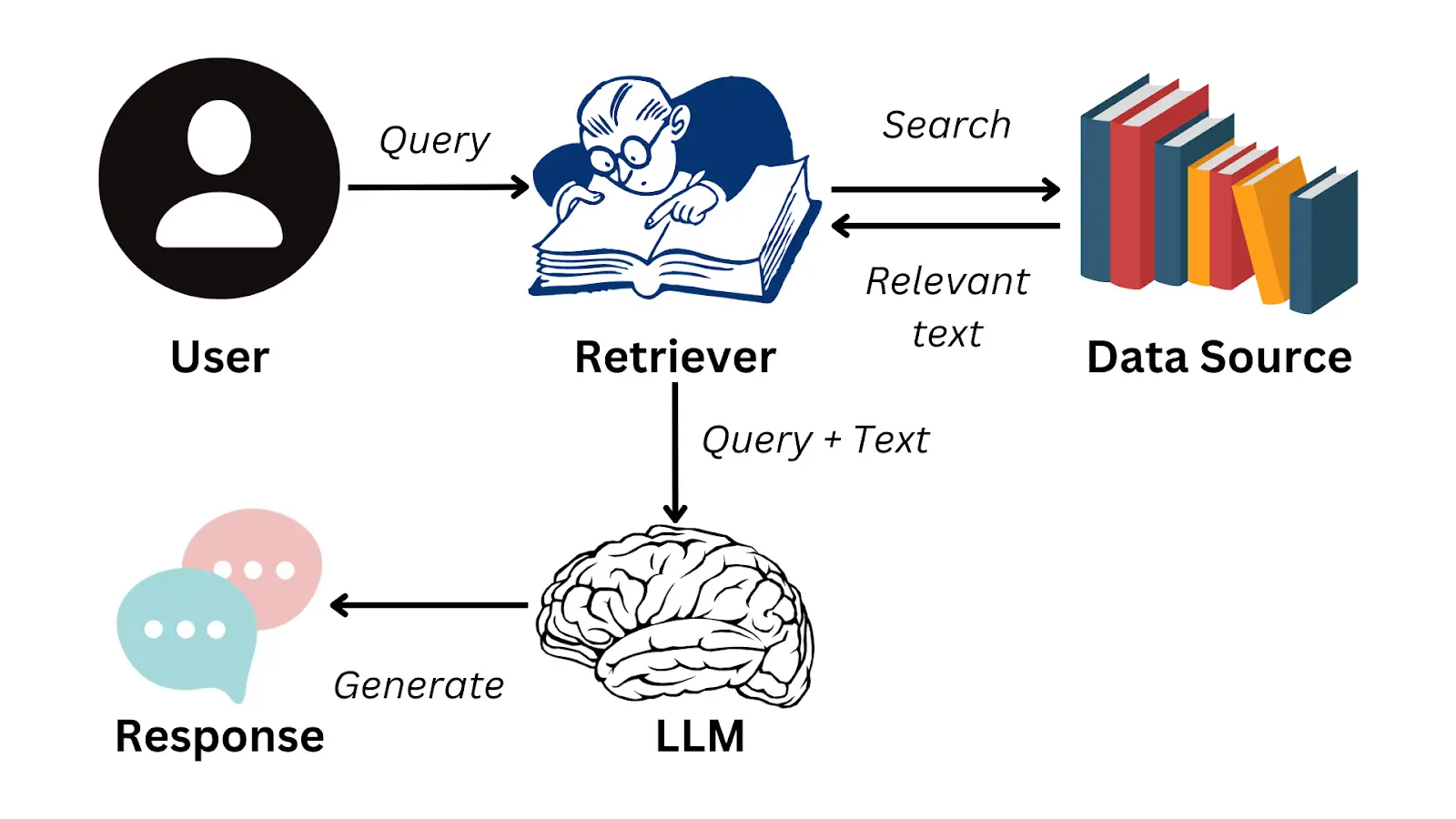
La idea consiste en que un usuario hace una pregunta sobre esa documentación privada, el sistema es capaz de obtener la parte de la documentación en la que está la respuesta a esa pregunta, se le pasa a un LLM la pregunta y la parte de la documentación y el LLM genera la respuesta para el usuario
¿Cómo se almacena la información?
Es sabido, y si no lo sabías te lo cuento ahora, que los LLMs tienen un límite de información que se les puede pasar, a esto se le llama ventana de contexto. Esto es por arquitecturas internas de los LLMs que ahora no vienen al caso. Pero lo importante es que no se les puede pasar un documento y una pregunta sin más, porque es probable que el LLM no sea capaz de procesar toda esa información.
En los casos en los que se le suele pasar más información de la que su ventana de contexto permite, lo que suele pasar es que el LLM no presta atención al final de la entrada. Imagina que le preguntas al LLM por algo de tu documento, que esa información esté al final del documento y el LLM no la lea.
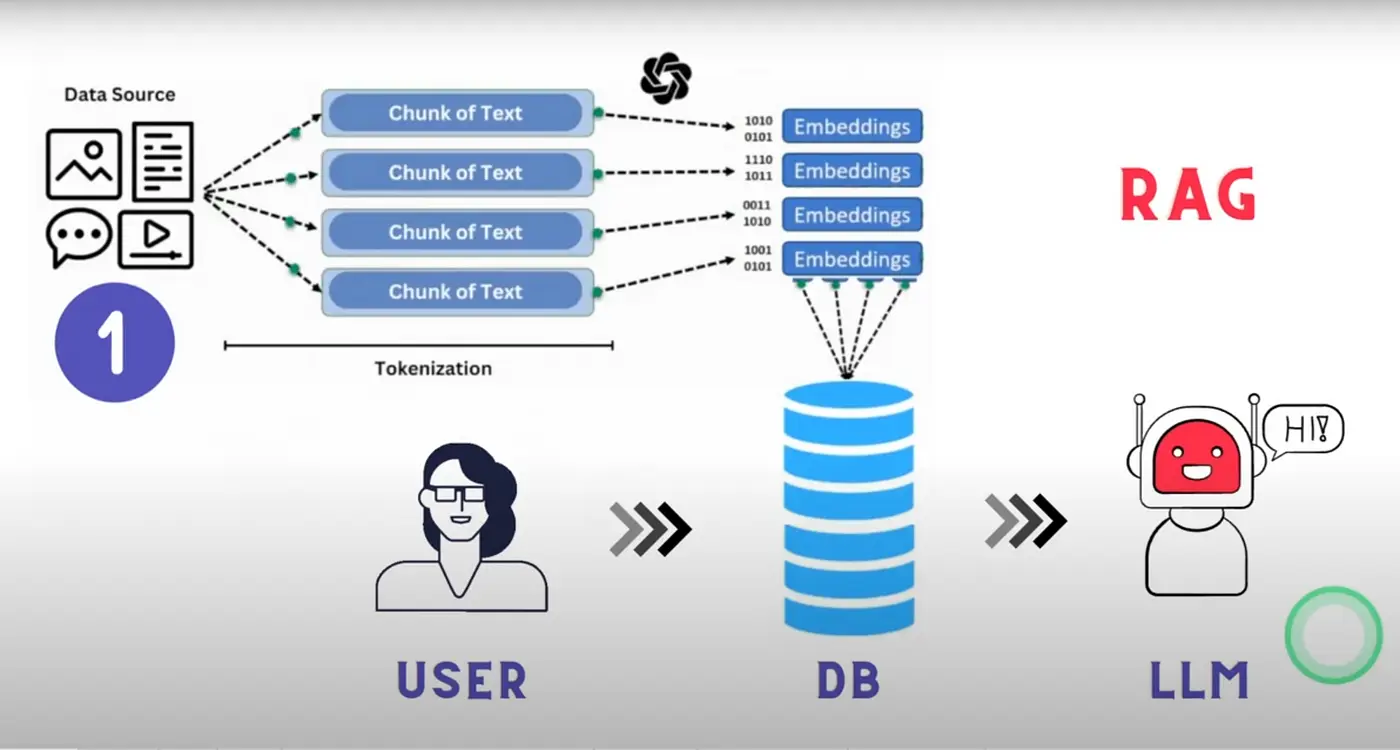
Por ello lo que se hace es dividir la documentación en bloques llamados chunks. De modo que la documentación se almacena en un montón de chunks, que son trozos de esa documentación. Así que cuando el usuario hace una pregunta, se le pasa al LLM el chunk en el que está la respuesta a esa pregunta.
Además de dividir la documentación en chunks, estos se convierten a embeddings, que son representaciones numéricas de los chunks. Esto se hace porque los LLMs en realidad no entienden de texto, sino de números, y los chunks se convierten a números para que el LLM pueda entenderlos. Si quieres entender más sobre los embeddings, puedes leer mi post sobre transformers en el que explico cómo funcionan los transformers, que es la arquitectura por debajo de los LLMs. También puedes leer mi post sobre ChromaDB donde explico cómo se guardan los embeddings en una base de datos vectorial. Y además sería interesante que leyeras mi post sobre la librería HuggingFace Tokenizers en la que se explica cómo se tokeniza el texto, que es el paso anterior a generar los embeddings
¿Cómo se obtiene el chunk correcto?
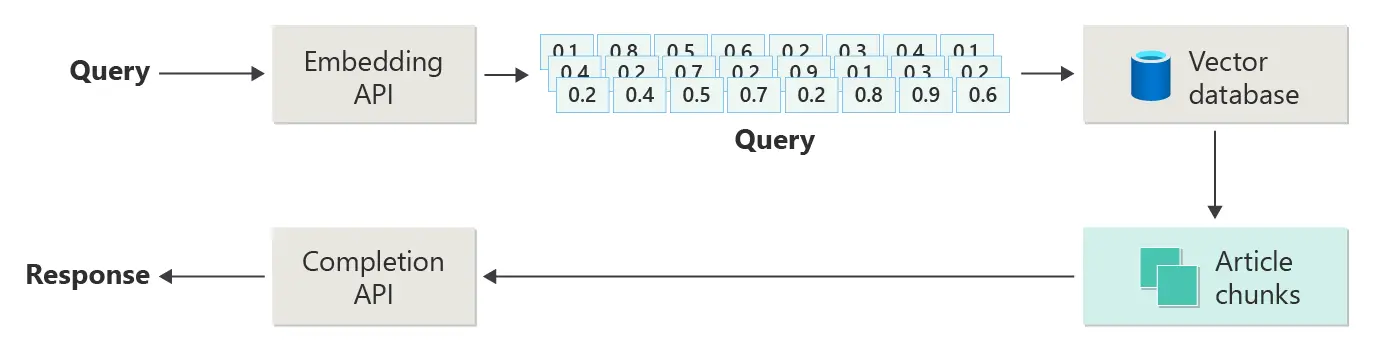
Hemos dicho que la documentación se divide en chunks y se le pasa al LLM el chunk en el que está la respuesta a la pregunta del usuario. Pero, ¿cómo se sabe en qué chunk está la respuesta? Para ello lo que se hace es convertir la pregunta del usuario a un embedding, y se calcula la similitud entre el embedding de la pregunta y los embeddings de los chunks. De modo que el chunk con mayor similitud es el que se le pasa al LLM.
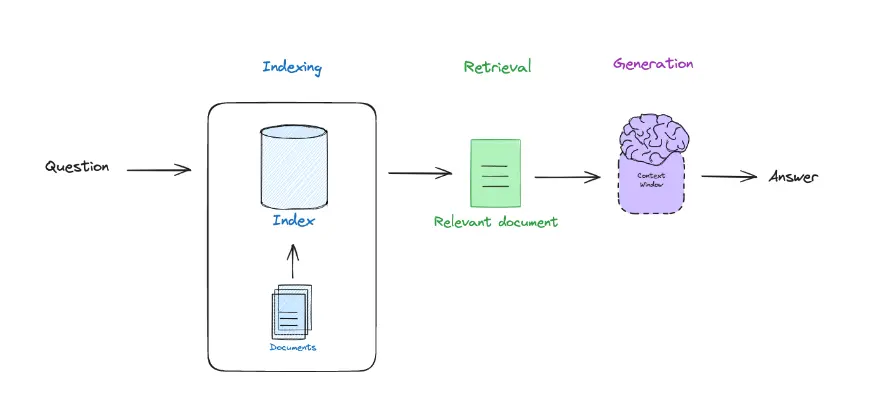
Volvamos a ver qué es RAG
Por un lado tenemos el retrieval, que es obtener el chunk correcto de la documentación, por otro lado tenemos el augmented, que es pasarle al LLM la pregunta del usuario y el chunk y por último tenemos el generation, que es obtener la respuesta generada por el LLM.
Base de datos vectorial
Hemos visto que la documentación se divide en chunks y se guarda en una base de datos vectorial, por lo que necesitamos usar una. Para este post voy a usar ChromaDB, que es una base de datos vectorial bastante usada y que además tengo un post en el que explico cómo funciona.
Por lo que primero necesitamos instalar la librería de ChromaDB, para ello la instalamos con Conda o con pip
conda install conda-forge::chromadbo
pip install chromadbFunción de embedding
Como hemos dicho, todo se va a basar en embeddings. Por lo que, lo primero que hacemos es crear una función para obtener embeddings de un texto. Vamos a usar el modelo sentence-transformers/all-MiniLM-L6-v2
import chromadb.utils.embedding_functions as embedding_functionsEMBEDDING_MODEL = "sentence-transformers/all-MiniLM-L6-v2"huggingface_ef = embedding_functions.HuggingFaceEmbeddingFunction(api_key=RAG_FUNDAMENTALS_ADVANCE_TECHNIQUES_TOKEN,model_name=EMBEDDING_MODEL)Copied
Probamos la función de embedding
embedding = huggingface_ef(["Hello, how are you?",])embedding[0].shapeCopied
(384,)
Obtenemos un embedding de dimensión 384. Aunque la misión de este post no es explicar los embeddings, en resumen, nuestra función de embedding ha categorizado la frase Hello, how are you? en un espacio de 384 dimensiones.
ChromaDB client
Ahora que tenemos nuestra función de embedding podemos crear un cliente de ChromaDB
Primero creamos una carpeta donde se guardará la base de datos vectorial
from pathlib import Pathchroma_path = Path("chromadb_persisten_storage")chroma_path.mkdir(exist_ok=True)Copied
Ahora creamos el cliente
from chromadb import PersistentClientchroma_client = PersistentClient(path = str(chroma_path))Copied
Colección
Cuando tenemos el cliente de ChromaDB, lo siguiente que necesitamos es crear una colección. Una colección es un conjunto de vectores, en nuestro caso los chunks de la documentación.
Lo creamos indicándole la función de embedding que vamos a usar
collection_name = "document_qa_collection"collection = chroma_client.get_or_create_collection(name=collection_name, embedding_function=huggingface_ef)Copied
Carga de documentos
Ahora que hemos creado la base de datos vectorial, tenemos que dividir la documentación en chunks y guardarlos en la base de datos vectorial.
Función de carga de documentos
Primero creamos una función para cargar todos los documentos .txt de un directorio
def load_one_document_from_directory(directory, file):with open(os.path.join(directory, file), "r") as f:return {"id": file, "text": f.read()}def load_documents_from_directory(directory):documents = []for file in os.listdir(directory):if file.endswith(".txt"):documents.append(load_one_document_from_directory(directory, file))return documentsCopied
Función para dividir la documentación en chunks
Una vez que tenemos los documentos, los dividimos en chunks
def split_text(text, chunk_size=1000, chunk_overlap=20):chunks = []start = 0while start < len(text):end = start + chunk_sizechunks.append(text[start:end])start = end - chunk_overlapreturn chunksCopied
Función para generar embeddings de un chunk
Ahora que tenemos los chunks, generamos los embeddings de cada uno de ellos
Luego veremos por qué, pero para generar los embeddings vamos a hacerlo de manera local y no mediante la API de Hugging Face. Para ello necesitamos tener instalado PyTorch y sentence-transformers, para ello hacemos
pip install -U sentence-transformersfrom sentence_transformers import SentenceTransformerimport torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")embedding_model = SentenceTransformer(EMBEDDING_MODEL).to(device)def get_embeddings(text):try:embedding = embedding_model.encode(text, device=device)return embeddingexcept Exception as e:print(f"Error: {e}")exit(1)Copied
Vamos a probar ahora esta función de embeddings en local
text = "Hello, how are you?"embedding = get_embeddings(text)embedding.shapeCopied
(384,)
Vemos que obtenemos un embedding de la misma dimensión que cuando lo hacíamos con la API de Hugging Face
El modelo sentence-transformers/all-MiniLM-L6-v2 tiene solo 22M de parámetros, por lo que vas a poder ejecutarlo en cualquier GPU. Incluso si no tienes GPU, vas a poder ejecutarlo en una CPU.
El LLM que vamos a usar para generar las respuestas, que es Qwen2.5-72B-Instruct, como su nombre indica, es un modelo de 72B de parámetros, por lo que este modelo no se puede ejecutar en cualquier GPU y en una CPU es impensable de lo lento que iría. Por eso, este LLM sí lo usaremos mediante la API, pero a la hora de generar los embeddings lo podemos hacer en local sin problema
Documentos con los que vamos a probar
Para hacer todas estas pruebas me he descargado el dataset aws-case-studies-and-blogs y lo he dejado en la carpeta rag-txt_dataset, con los siguientes comandos te digo cómo descargarlo y descomprimirlo
Creamos la carpeta donde vamos a descargar los documentos
!mkdir rag_txt_datasetCopied
Descargamos el .zip con los documentos
!curl -L -o ./rag_txt_dataset/archive.zip https://www.kaggle.com/api/v1/datasets/download/harshsinghal/aws-case-studies-and-blogsCopied
% Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left Speed0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0100 1430k 100 1430k 0 0 1082k 0 0:00:01 0:00:01 --:--:-- 2440k
Descomprimimos el .zip
!unzip rag_txt_dataset/archive.zip -d rag_txt_datasetCopied
Archive: rag_txt_dataset/archive.zipinflating: rag_txt_dataset/23andMe Case Study _ Life Sciences _ AWS.txtinflating: rag_txt_dataset/36 new or updated datasets on the Registry of Open Data_ AI analysis-ready datasets and more _ AWS Public Sector Blog.txtinflating: rag_txt_dataset/54gene _ Case Study _ AWS.txtinflating: rag_txt_dataset/6sense Case Study.txtinflating: rag_txt_dataset/ADP Developed an Innovative and Secure Digital Wallet in a Few Months Using AWS Services _ Case Study _ AWS.txtinflating: rag_txt_dataset/AEON Case Study.txtinflating: rag_txt_dataset/ALTBalaji _ Amazon Web Services.txtinflating: rag_txt_dataset/AWS Case Study - Ineos Team UK.txtinflating: rag_txt_dataset/AWS Case Study - StreamAMG.txtinflating: rag_txt_dataset/AWS Case Study_ Creditsafe.txtinflating: rag_txt_dataset/AWS Case Study_ Immowelt.txtinflating: rag_txt_dataset/AWS Customer Case Study _ Kepler Provides Effective Monitoring of Elderly Care Home Residents Using AWS _ AWS.txtinflating: rag_txt_dataset/AWS announces 21 startups selected for the AWS generative AI accelerator _ AWS Startups Blog.txtinflating: rag_txt_dataset/AWS releases smart meter data analytics _ AWS for Industries.txtinflating: rag_txt_dataset/Accelerate Time to Business Value Using Amazon SageMaker at Scale with NatWest Group _ Case Study _ AWS.txtinflating: rag_txt_dataset/Accelerate Your Analytics Journey on AWS with DXC Analytics and AI Platform _ AWS Partner Network (APN) Blog.txt...inflating: rag_txt_dataset/Zomato Saves Big by Using AWS Graviton2 to Power Data-Driven Business Insights.txtinflating: rag_txt_dataset/Zoox Case Study _ Automotive _ AWS.txtinflating: rag_txt_dataset/e-banner Streamlines Its Contact Center Operations and Facilitates a Fully Remote Workforce with Amazon Connect _ e-banner Case Study _ AWS.txtinflating: rag_txt_dataset/iptiQ Case Study.txtinflating: rag_txt_dataset/mod.io Provides Low Latency Gamer Experience Globally on AWS _ Case Study _ AWS.txtinflating: rag_txt_dataset/myposter Case Study.txt
Borramos el .zip
!rm rag_txt_dataset/archive.zipCopied
Vemos qué nos ha quedado
!ls rag_txt_datasetCopied
'23andMe Case Study _ Life Sciences _ AWS.txt''36 new or updated datasets on the Registry of Open Data_ AI analysis-ready datasets and more _ AWS Public Sector Blog.txt''54gene _ Case Study _ AWS.txt''6sense Case Study.txt''Accelerate Time to Business Value Using Amazon SageMaker at Scale with NatWest Group _ Case Study _ AWS.txt''Accelerate Your Analytics Journey on AWS with DXC Analytics and AI Platform _ AWS Partner Network (APN) Blog.txt''Accelerating customer onboarding using Amazon Connect _ NCS Case Study _ AWS.txt''Accelerating Migration at Scale Using AWS Application Migration Service with 3M Company _ Case Study _ AWS.txt''Accelerating Time to Market Using AWS and AWS Partner AccelByte _ Omeda Studios Case Study _ AWS.txt''Achieving Burstable Scalability and Consistent Uptime Using AWS Lambda with TiVo _ Case Study _ AWS.txt''Acrobits Uses Amazon Chime SDK to Easily Create Video Conferencing Application Boosting Collaboration for Global Users _ Acrobits Case Study _ AWS.txt''Actuate AI Case study.txt''ADP Developed an Innovative and Secure Digital Wallet in a Few Months Using AWS Services _ Case Study _ AWS.txt''Adzuna doubles its email open rates using Amazon SES _ Adzuna Case Study _ AWS.txt''AEON Case Study.txt''ALTBalaji _ Amazon Web Services.txt''Amanotes Stays on Beat by Delivering Simple Music Games to Millions Worldwide on AWS.txt''Amazon OpenSearch Services vector database capabilities explained _ AWS Big Data Blog.txt''Anghami Case Study.txt''Announcing enhanced table extractions with Amazon Textract _ AWS Machine Learning Blog.txt'...'What Will Generative AI Mean for Your Business_ _ AWS Cloud Enterprise Strategy Blog.txt''Which Recurring Business Processes Can Small and Medium Businesses Automate_ _ AWS Smart Business Blog.txt'Windsor.txt'Wireless Car Case Study _ AWS IoT Core _ AWS.txt''Yamato Logistics (HK) case study.txt''Zomato Saves Big by Using AWS Graviton2 to Power Data-Driven Business Insights.txt''Zoox Case Study _ Automotive _ AWS.txt'
A crear los chunks!
Listamos los documentos con la función que habíamos creado
dataset_path = "rag_txt_dataset"documents = load_documents_from_directory(dataset_path)Copied
Comprobamos que lo hemos hecho bien
for document in documents[0:10]:print(document["id"])Copied
Run Jobs at Scale While Optimizing for Cost Using Amazon EC2 Spot Instances with ActionIQ _ ActionIQ Case Study _ AWS.txtRecommend and dynamically filter items based on user context in Amazon Personalize _ AWS Machine Learning Blog.txtWindsor.txtBank of Montreal Case Study _ AWS.txtThe Mill Adventure Case Study.txtOptimize software development with Amazon CodeWhisperer _ AWS DevOps Blog.txtAnnouncing enhanced table extractions with Amazon Textract _ AWS Machine Learning Blog.txtTHREAD _ Life Sciences _ AWS.txtDeep Pool Optimizes Software Quality Control Using Amazon QuickSight _ Deep Pool Case Study _ AWS.txtUpstox Saves 1 Million Annually Using Amazon S3 Storage Lens _ Upstox Case Study _ AWS.txt
Ahora creamos los chunks.
chunked_documents = []for document in documents:chunks = split_text(document["text"])for i, chunk in enumerate(chunks):chunked_documents.append({"id": f"{document['id']}_{i}", "text": chunk})Copied
len(chunked_documents)Copied
3611
Como vemos, hay 3611 chunks. Como el límite diario de la API de Hugging Face son 1000 llamadas en la cuenta gratuita, si queremos crear embeddings de todos los chunks, se nos acabarían las llamadas disponibles y además no podríamos crear embeddings de todos los chunks
Volvemos a recordar, este modelo de embeddings es muy pequeño, solo 22M de parámetros, por lo que casi en cualquier ordenador se puede ejecutar, más rápido o más lento, pero se puede.
Como solo vamos a crear los embeddings de los chunks una vez, aunque no tengamos un ordenador muy potente y tarde mucho, solo se va a ejecutar una vez. Luego cuando queramos hacer preguntas sobre la documentación, ahí sí generaremos los embeddings del prompt con la API de Hugging Face y usaremos el LLM con la API. Por lo que solo vamos a tener que pasar por el proceso de generar los embeddings de los chunks una vez
Generamos los embeddings de los chunks
Última librería que vamos a tener que instalar. Como el proceso de generar los embeddings de los chunks va a ser lento, vamos a instalar tqdm para que nos muestre una barra de progreso. Lo instalamos con Conda o con pip, como prefieras
conda install conda-forge::tqdmo
pip install tqdmGeneramos los embeddings de los chunks
import tqdmprogress_bar = tqdm.tqdm(chunked_documents)for chunk in progress_bar:embedding = get_embeddings(chunk["text"])if embedding is not None:chunk["embedding"] = embeddingelse:print(f"Error with document {chunk['id']}")Copied
100%|██████████| 3611/3611 [00:16<00:00, 220.75it/s]
Vemos un ejemplo
from random import randintidx = randint(0, len(chunked_documents))print(f"Chunk id: {chunked_documents[idx]['id']}, text: {chunked_documents[idx]['text']}, embedding shape: {chunked_documents[idx]['embedding'].shape}")Copied
Chunk id: BNS Group Case Study _ Amazon Web Services.txt_0,text: Reducing Virtual Machines from 40 to 12The founders of BNS had been contemplating a migration from the company’s on-premises data center to the public cloud and observed a growing demand for cloud-based operations among current and potential BNS customers.FrançaisConfigures security according to cloud best practicesClive Pereira, R&D director at BNS Group, explains, “The database that records Praisal’s SMS traffic resides in Praisal’s AWS environment. Praisal can now run complete analytics across its data and gain insights into what’s happening with its SMS traffic, which is a real game-changer for the organization.”EspañolAWS ISV Accelerate ProgramReceiving Strategic, Foundational Support from ISV SpecialistsLearn MoreThe value that AWS places on the ISV stream sealed the deal in our choice of cloud provider.”日本語Contact SalesBNS is an Australian software provider focused on secure enterprise SMS and fax messaging. Its software runs on the Windows platform and is l,embedding shape: (384,)
Cargar los chunks en la base de datos vectorial
Una vez que tenemos todos los chunks generados, los cargamos en la base de datos vectorial. Volvemos a usar tqdm para que nos muestre una barra de progreso, porque esto también va a ser lento
import tqdmprogress_bar = tqdm.tqdm(chunked_documents)for chunk in progress_bar:collection.upsert(ids=[chunk["id"]],documents=chunk["text"],embeddings=chunk["embedding"],)Copied
100%|██████████| 3611/3611 [00:59<00:00, 60.77it/s]
Preguntas
Ahora que tenemos la base de datos vectorial, podemos hacerle preguntas a la documentación. Para ello, necesitamos una función que nos devuelva el chunk correcto
Obtener el chunk correcto
Ahora necesitamos una función que nos devuelva el chunk correcto, vamos a crearla
def get_top_k_documents(query, k=5):results = collection.query(query_texts=query, n_results=k)return resultsCopied
Por último, creamos una query.
Para generar la query he cogido al azar el documento Using Amazon EC2 Spot Instances and Karpenter to Simplify and Optimize Kubernetes Infrastructure _ Neeva Case Study _ AWS.txt, se lo he pasado a un LLM y le he dicho que me genere una pregunta sobre el documento. La pregunta que ha generado es
How did Neeva use Karpenter and Amazon EC2 Spot Instances to improve its infrastructure management and cost optimization?Así que obtenemos los chunks más relevantes ante esa pregunta
query = "How did Neeva use Karpenter and Amazon EC2 Spot Instances to improve its infrastructure management and cost optimization?"top_chunks = get_top_k_documents(query=query, k=5)Copied
Vamos a ver qué chunks nos ha devuelto
for i in range(len(top_chunks["ids"][0])):print(f"Rank {i+1}: {top_chunks['ids'][0][i]}, distance: {top_chunks['distances'][0][i]}")Copied
Rank 1: Using Amazon EC2 Spot Instances and Karpenter to Simplify and Optimize Kubernetes Infrastructure _ Neeva Case Study _ AWS.txt_0, distance: 0.29233667254447937Rank 2: Using Amazon EC2 Spot Instances and Karpenter to Simplify and Optimize Kubernetes Infrastructure _ Neeva Case Study _ AWS.txt_5, distance: 0.4007825255393982Rank 3: Using Amazon EC2 Spot Instances and Karpenter to Simplify and Optimize Kubernetes Infrastructure _ Neeva Case Study _ AWS.txt_1, distance: 0.4317566752433777Rank 4: Using Amazon EC2 Spot Instances and Karpenter to Simplify and Optimize Kubernetes Infrastructure _ Neeva Case Study _ AWS.txt_6, distance: 0.43832334876060486Rank 5: Using Amazon EC2 Spot Instances and Karpenter to Simplify and Optimize Kubernetes Infrastructure _ Neeva Case Study _ AWS.txt_4, distance: 0.44625571370124817
Como había dicho, el documento que había elegido al azar era Using Amazon EC2 Spot Instances and Karpenter to Simplify and Optimize Kubernetes Infrastructure _ Neeva Case Study _ AWS.txt y como se puede ver los chunks que nos ha devuelto son de ese documento. Es decir, de más de 3000 chunks que había en la base de datos, ha sido capaz de devolverme los chunks más relevantes ante esa pregunta, parece que esto funciona!
Generar la respuesta
Como ya tenemos los chunks más relevantes, se los pasamos al LLM, junto con la pregunta, para que este genere una respuesta
def generate_response(query, relevant_chunks, temperature=0.5, max_tokens=1024, top_p=0.7, stream=False):context = " ".join([chunk for chunk in relevant_chunks])prompt = f"You are an assistant for question-answering. You have to answer the following question: {query} Answer the question with the following information: {context}"message = [{ "role": "user", "content": prompt }]stream = client.chat.completions.create(messages=message,temperature=temperature,max_tokens=max_tokens,top_p=top_p,stream=stream,)response = stream.choices[0].message.contentreturn responseCopied
Probamos la función
response = generate_response(query, top_chunks["documents"][0])print(response)Copied
Neeva, a cloud-native, ad-free search engine founded in 2019, has leveraged Karpenter and Amazon EC2 Spot Instances to significantly improve its infrastructure management and cost optimization. Here’s how:### Early Collaboration with KarpenterIn late 2021, Neeva began working closely with the Karpenter team, experimenting with and contributing fixes to an early version of Karpenter. This collaboration allowed Neeva to integrate Karpenter with its Kubernetes dashboard, enabling the company to gather valuable metrics on usage and performance.### Combining Spot Instances and On-Demand InstancesNeeva runs its jobs on a large scale, which can lead to significant costs. To manage these costs effectively, the company adopted a combination of Amazon EC2 Spot Instances and On-Demand Instances. Spot Instances allow Neeva to bid on unused EC2 capacity, often at a fraction of the On-Demand price, while On-Demand Instances provide the necessary reliability for critical pipelines.### Flexibility and Instance DiversificationAccording to Mohit Agarwal, infrastructure engineering lead at Neeva, Karpenter's adoption of best practices for Spot Instances, including flexibility and instance diversification, has been crucial. This approach ensures that Neeva can dynamically adjust its compute resources to meet varying workloads while minimizing costs.### Improved Scalability and AgilityBy using Karpenter to provision infrastructure resources for its Amazon EKS clusters, Neeva has achieved several key benefits:- **Scalability**: Neeva can scale its compute resources up or down as needed, ensuring that it always has the necessary capacity to handle its workloads.- **Agility**: The company can iterate quickly and democratize infrastructure changes, reducing the time spent on systems administration by up to 100 hours per week.### Enhanced Development CyclesThe integration of Karpenter and Spot Instances has also accelerated Neeva's development cycles. The company can now launch new features and improvements more rapidly, which is essential for maintaining a competitive edge in the search engine market.### Cost Savings and Budget ControlUsing Spot Instances, Neeva has been able to stay within its budget while meeting its performance requirements. This cost optimization is critical for a company that prioritizes user-first experiences and has no competing incentives from advertising.### Future PlansNeeva is committed to continuing its innovation and expansion. The company plans to launch in new regions and further improve its search engine, all while maintaining cost efficiency. As Mohit Agarwal notes, "The bulk of our compute is or will be managed using Karpenter going forward."### ConclusionBy leveraging Karpenter and Amazon EC2 Spot Instances, Neeva has not only optimized its infrastructure costs but also enhanced its scalability, agility, and development speed. This strategic approach has positioned Neeva to deliver high-quality, ad-free search experiences to its users while maintaining a strong focus on cost control and innovation.
Cuando le pedí al LLM que me generara una pregunta sobre el documento, también le pedí que me generara la respuesta correcta. Esta es la respuesta que me dio el LLM
Neeva used Karpenter and Amazon EC2 Spot Instances to improve its infrastructure management and cost optimization in several ways:
Simplified Instance Management:
Karpenter: By adopting Karpenter, Neeva simplified the process of provisioning and managing compute resources for its Amazon EKS clusters. Karpenter automatically provisions and de-provisions instances based on the workload, eliminating the need for manual configurations and reducing the complexity of understanding different compute instances.
Spot Instances: Neeva leveraged Amazon EC2 Spot Instances, which are unused EC2 capacity available at a significant discount (up to 90% cost savings). This allowed the company to control costs while meeting its performance requirements.
Enhanced Scalability:
Karpenter: Karpenter's ability to dynamically scale resources enabled Neeva to spin up new instances quickly, allowing the company to iterate at a higher velocity and run more experiments in less time.
Spot Instances: The use of Spot Instances provided flexibility and instance diversification, making it easier for Neeva to scale its compute resources efficiently.
Improved Productivity:
Karpenter: By democratizing infrastructure changes, Karpenter allowed any engineer to modify Kubernetes configurations, reducing the dependency on specialized expertise. This saved the Neeva team up to 100 hours per week of wait time on systems administration.
Spot Instances: The ability to quickly provision and de-provision Spot Instances reduced delays in the development pipeline, ensuring that jobs did not get stuck due to a lack of available resources.
Cost Efficiency:
Karpenter: Karpenter's best practices for Spot Instances, including flexibility and instance diversification, helped Neeva use these instances more effectively, staying within budget.
Spot Instances: The cost savings from using Spot Instances allowed Neeva to run large-scale jobs, such as indexing, for nearly the same cost but in a fraction of the time. For example, Neeva reduced its indexing jobs from 18 hours to just 3 hours.
Better Resource Utilization:
Karpenter: Karpenter provided better visibility into compute resource usage, allowing Neeva to track and optimize its resource consumption more closely.
Spot Instances: The combination of Karpenter and Spot Instances enabled Neeva to run large language models more efficiently, enhancing the search experience for its users.
In summary, Neeva's adoption of Karpenter and Amazon EC2 Spot Instances significantly improved its infrastructure management, cost optimization, and overall development efficiency, enabling the company to deliver better ad-free search experiences to its users.Y esta ha sido la respuesta generada por nuestro RAG
Neeva, a cloud-native, ad-free search engine founded in 2019, has leveraged Karpenter and Amazon EC2 Spot Instances to significantly improve its infrastructure management and cost optimization. Here’s how:
### Early Collaboration with Karpenter
In late 2021, Neeva began working closely with the Karpenter team, experimenting with and contributing fixes to an early version of Karpenter. This collaboration allowed Neeva to integrate Karpenter with its Kubernetes dashboard, enabling the company to gather valuable metrics on usage and performance.
### Combining Spot Instances and On-Demand Instances
Neeva runs its jobs on a large scale, which can lead to significant costs. To manage these costs effectively, the company adopted a combination of Amazon EC2 Spot Instances and On-Demand Instances. Spot Instances allow Neeva to bid on unused EC2 capacity, often at a fraction of the On-Demand price, while On-Demand Instances provide the necessary reliability for critical pipelines.
### Flexibility and Instance Diversification
According to Mohit Agarwal, infrastructure engineering lead at Neeva, Karpenter's adoption of best practices for Spot Instances, including flexibility and instance diversification, has been crucial. This approach ensures that Neeva can dynamically adjust its compute resources to meet varying workloads while minimizing costs.
### Improved Scalability and Agility
By using Karpenter to provision infrastructure resources for its Amazon EKS clusters, Neeva has achieved several key benefits:
- **Scalability**: Neeva can scale its compute resources up or down as needed, ensuring that it always has the necessary capacity to handle its workloads.
- **Agility**: The company can iterate quickly and democratize infrastructure changes, reducing the time spent on systems administration by up to 100 hours per week.
### Enhanced Development Cycles
The integration of Karpenter and Spot Instances has also accelerated Neeva's development cycles. The company can now launch new features and improvements more rapidly, which is essential for maintaining a competitive edge in the search engine market.
### Cost Savings and Budget Control
Using Spot Instances, Neeva has been able to stay within its budget while meeting its performance requirements. This cost optimization is critical for a company that prioritizes user-first experiences and has no competing incentives from advertising.
### Future Plans
Neeva is committed to continuing its innovation and expansion. The company plans to launch in new regions and further improve its search engine, all while maintaining cost efficiency. As Mohit Agarwal notes, "The bulk of our compute is or will be managed using Karpenter going forward."
### Conclusion
By leveraging Karpenter and Amazon EC2 Spot Instances, Neeva has not only optimized its infrastructure costs but also enhanced its scalability, agility, and development speed. This strategic approach has positioned Neeva to deliver high-quality, ad-free search experiences to its users while maintaining a strong focus on cost control and innovation.Por lo que podemos concluir que el RAG ha funcionado correctamente!!!
Límites de naive RAG
Como hemos dicho, hoy hemos explicado naive RAG, que es la arquitectura más sencilla de RAG, pero tiene sus limitaciones
Las limitaciones de esta arquitectura son:
Límites en la búsqueda de información (retriever)
- Limitado conocimiento del contexto y la documentación: Cuando el sistema de naive RAG busca los chunks, busca los que tienen un significado semántico similar al prompt, pero no es capaz de saber cuáles son los más relevantes para la pregunta del usuario, o cuáles son los que tienen una información más actualizada, o su información es más correcta que la de otros chunks. Por ejemplo, si un usuario pregunta sobre los problemas de los edulcorantes en el sistema digestivo, el naive RA puede devolver documentos sobre edulcorantes o sobre el sistema digestivo, pero no es capaz de saber que los documentos sobre el sistema digestivo son los más relevantes para la pregunta del usuario. Otro ejemplo es si el usuario pregunta sobre los últimos avances en la IA, pero el naive RAG no es capaz de saber cuales son los últimos papers de la base de datos.
- No hay una sincronización entre el retrieval y el generador. Como hemos visto son dos sistemas independientes, por un lado el retrieval busca los documentos más similares a la pregunta del usuario y esos documentos se le pasan al generador, que genera una respuesta.
- Ineficiente escala ante grandes bases de datos. Como el retrieval busca los documentos con mayor similitud semántica con toda la base de datos, cuando esta se hace muy grande podemos tener tiempos de búsqueda muy largos.
- Poca adaptación a la pregunta del usuario. Si el usuario hace una pregunta que tiene que ver con varios documentos, es decir, no hay ningún documento que contenga toda la información de la pregunta del usuario, el sistema recuperará todos esos documentos y se los pasará al generador, que puede usarlos o no. O en un peor caso, puede que se deje algún documento relevante para generar la respuesta.
Límites en la generación de respuestas (generator)
- El modelo podría alucinar respuestas aun pasándole información relevante.
- El modelo podría estar limitado por temas relacionados con el odio, la discriminación, etc.
Para sobrepasar estos límites, se suelen utilizar técnicas como el
- Pre-retrieval: Que incluye técnicas para mejorar la indexación, por lo que la búsqueda de la información es más eficiente. O técnicas como la mejora de la pregunta del usuario para que el retrieval pueda encontrar los documentos más relevantes.
- Post-retrieval: Aquí se usan técnicas como el re-ranking de los documentos, que es una técnica que se usa para mejorar la búsqueda de la información relevante
















