
Disclaimer: This post has been translated to English using a machine translation model. Please, let me know if you find any mistakes.
In recent months, we have seen significant advancements in real-time voice models, with entire companies being founded around both open-source and closed models. Some key milestones include:
OpenAIandGooglelaunched their live multimodal APIs for ChatGPT and Gemini. OpenAI even launched a phone number1-800-ChatGPT!Kyutailaunched Moshi, a fully open-source audio-to-audio LLM.Alibabalaunched Qwen2-Audio, an open-source LLM that natively understands audio.Fixie.ailaunched Ultravox, another open-source LLM that also natively understands audio.ElevenLabsraised 180 million dollars in its Series C.
Despite this explosion in models and funding, it remains difficult to build real-time AI applications that stream audio and video, especially in Python.
- Machine learning engineers may not have experience with the necessary technologies to build real-time applications, such as
WebRTC. - Even code assistance tools like
CursorandCopilotstruggle to write Python code that supports real-time audio/video applications.
That's why the announcement of FastRTC, the real-time communication library for Python, is exciting. The library is designed to make it easy to build real-time audio and video AI applications entirely in Python!
Main Features of FastRTC
- 🗣️ Automatic voice detection and built-in turn taking, so you only have to worry about the user response logic.
- 💻 Automatic UI - Built-in Gradio UI enabled for WebRTC for testing (or deployment to production!).
- 📞 Phone call - Use
fastphone()to get a free phone number to call your audio stream (HF token required). - ⚡️ Support for
WebRTCandWebsocket. - 💪 Customizable - You can mount the stream in any
FastAPIapplication to serve a custom UI and deploy beyondGradio. - 🧰 Many utilities for
text-to-speech,speech-to-text,stop detectionto help you get started.
Installation
To be able to use FastRTC, you first need to install the library:
pip install fastrtcBut if we want to install the pause detection, speech-to-text, and text-to-speech functionalities, we need to install some additional dependencies:
pip install "fastrtc[vad, stt, tts]"Getting Started
We will start by building the hello world of real-time audio: echoing what the user says. In FastRTC, this is as simple as:
from fastrtc import Stream, ReplyOnPauseimport numpy as npdef echo(audio: tuple[int, np.ndarray]) -> tuple[int, np.ndarray]:yield audiostream = Stream(ReplyOnPause(echo), modality="audio", mode="send-receive")stream.ui.launch()Copied
* Running on local URL: http://127.0.0.1:7872To create a public link, set `share=True` in `launch()`.
<IPython.core.display.HTML object>
INFO: 127.0.0.1:58223 - "GET / HTTP/1.1" 200 OKINFO: 127.0.0.1:58223 - "GET /assets/index-C7PS0jJm.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58225 - "GET /assets/index-Bo0Yq5bb.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58223 - "GET /assets/svelte/svelte.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58225 - "GET /assets/Embed-FUIL71FR.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58223 - "GET /assets/Index-wMEhc4G9.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58228 - "GET /assets/StreamingBar-DOagx4HU.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58227 - "GET /assets/index-B1gfMDT9.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58230 - "GET /assets/IconButtonWrapper-EOzMzU45.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58229 - "GET /assets/StreamingBar.svelte_svelte_type_style_lang-CDNxkBIr.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58225 - "GET /assets/MarkdownCode-DPiWQnAx.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58223 - "GET /assets/DownloadLink-CqD3Uu0l.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58227 - "GET /assets/IconButtonWrapper.svelte_svelte_type_style_lang-BOpxTcdu.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58229 - "GET /assets/prism-python-qapVsvY8.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58228 - "GET /assets/Index-BJ_RfjVB.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58230 - "GET /assets/MarkdownCode.svelte_svelte_type_style_lang-3tofWDHK.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58225 - "GET /assets/IconButton-B-aAVSzy.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58229 - "GET /assets/Clear-By3xiIwg.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58228 - "GET /assets/context-TgWPFwN2.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58230 - "GET /theme.css?v=63194d3741d384f9f85db890247b6c0ef9e7abac0f297f40a15c59fe4baba916 HTTP/1.1" 200 OKINFO: 127.0.0.1:58228 - "GET /assets/Button-BWSOH8Qq.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58225 - "GET /assets/Image-CsmDAdIf.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58229 - "GET /assets/Blocks-E57YC_S0.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58227 - "GET /assets/Button-DTh9AgeE.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58223 - "GET /assets/Image-B8dFOee4.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58230 - "GET /assets/ImagePreview-DJhr8Mfv.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58223 - "GET /assets/file-url-DgijyRSD.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58225 - "GET /assets/Dropdown-CWxB-qJp.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58228 - "GET /assets/Example-D7K5RtQ2.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58227 - "GET /assets/Blocks-B5wxaDIo.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58229 - "GET /assets/Dropdown-DjrBHETv.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58230 - "GET /assets/Block-DZqtZLFP.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58228 - "GET /assets/BlockTitle-BIcnzvtg.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58225 - "GET /assets/index-CvpmwOJi.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58223 - "GET /assets/MarkdownCode-DJM7o_VY.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58230 - "GET /assets/Info-DcCn6tHi.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58227 - "GET /assets/DropdownArrow-dYuMZY9s.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58229 - "GET /assets/Toast-DdWZrg4w.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58230 - "GET /assets/utils-BsGrhMNe.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58223 - "GET /gradio_api/custom_component/91a0d0cc3e6164063c775a057aff53510cb8fc04c8b99d010e09ce4ba9beb99d/client/component/style.css HTTP/1.1" 304 Not ModifiedINFO: 127.0.0.1:58230 - "GET /assets/Index-ChJkSByh.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58227 - "GET /assets/Index-CfowPFmo.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58228 - "GET /assets/Index-CptIZeFZ.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58229 - "GET /assets/Index-Csm0OGa9.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58225 - "GET /assets/Index-Cgj6KPvj.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58223 - "GET /assets/Code-DGNrTu_I.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58225 - "GET /gradio_api/custom_component/91a0d0cc3e6164063c775a057aff53510cb8fc04c8b99d010e09ce4ba9beb99d/client/component/index.js HTTP/1.1" 304 Not ModifiedINFO: 127.0.0.1:58228 - "GET /assets/Index-HXWviefR.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58229 - "GET /assets/Index-WEzAIkMk.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58230 - "GET /assets/BlockLabel-DqHge3FF.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58227 - "GET /assets/Index-CRGGsrTx.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58241 - "GET / HTTP/1.1" 200 OKINFO: 127.0.0.1:58241 - "GET /theme.css?v=63194d3741d384f9f85db890247b6c0ef9e7abac0f297f40a15c59fe4baba916 HTTP/1.1" 200 OKINFO: 127.0.0.1:58241 - "GET /gradio_api/custom_component/91a0d0cc3e6164063c775a057aff53510cb8fc04c8b99d010e09ce4ba9beb99d/client/component/style.css HTTP/1.1" 304 Not ModifiedINFO: 127.0.0.1:58244 - "GET /gradio_api/custom_component/91a0d0cc3e6164063c775a057aff53510cb8fc04c8b99d010e09ce4ba9beb99d/client/component/index.js HTTP/1.1" 304 Not ModifiedINFO: 127.0.0.1:58260 - "GET /static/fonts/ui-sans-serif/ui-sans-serif-Bold.woff2 HTTP/1.1" 404 Not FoundINFO: 127.0.0.1:58260 - "GET /static/fonts/system-ui/system-ui-Bold.woff2 HTTP/1.1" 404 Not Found
When we go to the link that Gradio suggests, we first have to give permissions to the browser to access the microphone. Next, this will appear:
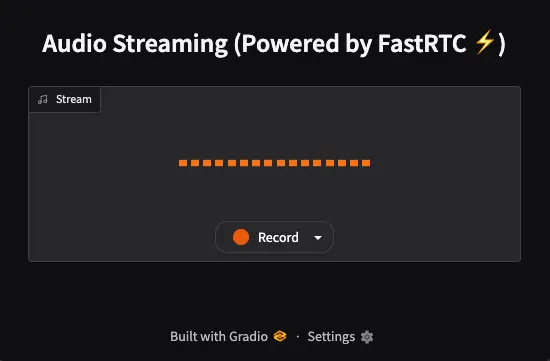
If we click on the tab to the right of the word Record, we can select the microphone we want to use.
When we press the Record button, everything we say will be repeated by the application. That is, it captures the audio, detects when we have stopped speaking, and repeats it.
Let's break it down:
ReplyOnPausewill handle voice detection and turn-taking for you. You only need to worry about the logic for responding to the user. You have to pass it the function that will manage the input audio. In our case, it's theechofunction, which captures the input audio and returns it as a stream usingyield, which many people don't know, but is a generator, meaning it's a Python method for creating iterators. If you want to learn more aboutyield, you can read my post on Python. Any generator that returns an audio tuple (represented as(sample_rate, audio_data)) will work.- The
Streamclass will build a Gradio UI for you to quickly test your stream. Once you have finished prototyping, you can deploy your Stream as a production-ready FastAPI application in a single line of code.
Here we can see an example from the creators of FastRTC
Leveling Up: Voice Chat with LLM
The next level is to use an LLM to respond to the user. FastRTC comes with built-in speech-to-text and text-to-speech capabilities, so working with LLMs is really easy. Let's modify our echo function accordingly:
from fastrtc import ReplyOnPause, Stream, get_stt_model, get_tts_modelfrom gradio_client import Clientclient = Client("Maximofn/SmolLM2_localModel")stt_model = get_stt_model()tts_model = get_tts_model()def echo(audio):prompt = stt_model.stt(audio)response = client.predict(message=prompt,system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")prompt = responsefor audio_chunk in tts_model.stream_tts_sync(prompt):yield audio_chunkstream = Stream(ReplyOnPause(echo), modality="audio", mode="send-receive")stream.ui.launch()Copied
Loaded as API: https://maximofn-smollm2-localmodel.hf.space ✔* Running on local URL: http://127.0.0.1:7871To create a public link, set `share=True` in `launch()`.
<IPython.core.display.HTML object>
INFO: 127.0.0.1:58224 - "GET / HTTP/1.1" 200 OKINFO: 127.0.0.1:58224 - "GET /assets/index-Bo0Yq5bb.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58226 - "GET /assets/index-C7PS0jJm.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58226 - "GET /assets/svelte/svelte.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58226 - "GET /assets/Index-wMEhc4G9.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58232 - "GET /assets/StreamingBar-DOagx4HU.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58234 - "GET /assets/IconButtonWrapper-EOzMzU45.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58224 - "GET /assets/Embed-FUIL71FR.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58233 - "GET /assets/StreamingBar.svelte_svelte_type_style_lang-CDNxkBIr.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58231 - "GET /assets/index-B1gfMDT9.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58231 - "GET /assets/MarkdownCode-DPiWQnAx.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58224 - "GET /assets/MarkdownCode.svelte_svelte_type_style_lang-3tofWDHK.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58233 - "GET /assets/Index-BJ_RfjVB.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58232 - "GET /assets/DownloadLink-CqD3Uu0l.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58234 - "GET /assets/IconButtonWrapper.svelte_svelte_type_style_lang-BOpxTcdu.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58226 - "GET /assets/prism-python-qapVsvY8.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58231 - "GET /assets/IconButton-B-aAVSzy.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58233 - "GET /assets/Clear-By3xiIwg.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58234 - "GET /assets/context-TgWPFwN2.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58224 - "GET /theme.css?v=63194d3741d384f9f85db890247b6c0ef9e7abac0f297f40a15c59fe4baba916 HTTP/1.1" 200 OKINFO: 127.0.0.1:58234 - "GET /assets/Blocks-E57YC_S0.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58231 - "GET /assets/Image-B8dFOee4.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58226 - "GET /assets/ImagePreview-DJhr8Mfv.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58233 - "GET /assets/Button-BWSOH8Qq.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58232 - "GET /assets/Button-DTh9AgeE.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58224 - "GET /assets/Dropdown-CWxB-qJp.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58232 - "GET /assets/Image-CsmDAdIf.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58226 - "GET /assets/Blocks-B5wxaDIo.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58233 - "GET /assets/Example-D7K5RtQ2.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58234 - "GET /assets/Block-DZqtZLFP.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58231 - "GET /assets/file-url-DgijyRSD.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58224 - "GET /assets/Info-DcCn6tHi.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58232 - "GET /assets/MarkdownCode-DJM7o_VY.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58234 - "GET /assets/Dropdown-DjrBHETv.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58233 - "GET /assets/index-CvpmwOJi.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58226 - "GET /assets/BlockTitle-BIcnzvtg.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58231 - "GET /assets/DropdownArrow-dYuMZY9s.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58224 - "GET /assets/Toast-DdWZrg4w.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58234 - "GET /assets/utils-BsGrhMNe.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58232 - "GET /assets/Index-CfowPFmo.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58234 - "GET /assets/Index-ChJkSByh.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58224 - "GET /assets/Code-DGNrTu_I.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58226 - "GET /assets/Index-Csm0OGa9.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58233 - "GET /assets/Index-HXWviefR.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58231 - "GET /assets/BlockLabel-DqHge3FF.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58224 - "GET /gradio_api/custom_component/91a0d0cc3e6164063c775a057aff53510cb8fc04c8b99d010e09ce4ba9beb99d/client/component/style.css HTTP/1.1" 304 Not ModifiedINFO: 127.0.0.1:58231 - "GET /assets/Index-Cgj6KPvj.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58233 - "GET /gradio_api/custom_component/91a0d0cc3e6164063c775a057aff53510cb8fc04c8b99d010e09ce4ba9beb99d/client/component/index.js HTTP/1.1" 304 Not ModifiedINFO: 127.0.0.1:58226 - "GET /assets/Index-CptIZeFZ.css HTTP/1.1" 200 OKINFO: 127.0.0.1:58232 - "GET /assets/Index-CRGGsrTx.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58234 - "GET /assets/Index-WEzAIkMk.js HTTP/1.1" 200 OKINFO: 127.0.0.1:58242 - "GET / HTTP/1.1" 200 OKINFO: 127.0.0.1:58242 - "GET /theme.css?v=63194d3741d384f9f85db890247b6c0ef9e7abac0f297f40a15c59fe4baba916 HTTP/1.1" 200 OKINFO: 127.0.0.1:58242 - "GET /gradio_api/custom_component/91a0d0cc3e6164063c775a057aff53510cb8fc04c8b99d010e09ce4ba9beb99d/client/component/style.css HTTP/1.1" 304 Not ModifiedINFO: 127.0.0.1:58243 - "GET /gradio_api/custom_component/91a0d0cc3e6164063c775a057aff53510cb8fc04c8b99d010e09ce4ba9beb99d/client/component/index.js HTTP/1.1" 304 Not ModifiedINFO: 127.0.0.1:58250 - "GET /static/fonts/ui-sans-serif/ui-sans-serif-Bold.woff2 HTTP/1.1" 404 Not FoundINFO: 127.0.0.1:58250 - "GET /static/fonts/system-ui/system-ui-Bold.woff2 HTTP/1.1" 404 Not Found
As a speech-to-text model, use Moonshine, which supposedly only supports English, but I have tested it in Spanish and it understands well.
As a language model, we will use the model I deployed in a backend on Hugging Face and wrote about in the post Deploying a Backend with LLM on HuggingFace. It uses the LLM HuggingFaceTB/SmolLM2-1.7B-Instruct, which is a small model since it's running on a backend with CPU, but it works quite well.
As a text-to-speech model, use Kokoro, which does have options to speak in other languages, but is not yet implemented in the FastRTC library.
If we are very interested in using speech-to-speech and text-to-speech models in other languages, we could implement them ourselves, because the greatest potential of FastRTC lies in the real-time communication layer, but I won't go into that now.
Now if we test the code we just wrote, we can have a voice chatbot in real time.
Phone Call
If you call stream.fastphone() instead of stream.ui.launch(), you will get a free phone number to call your stream. Note that a Hugging Face token is required.
We generated a script because it doesn't always work in a Jupyter Notebook.
%%writefile fastrtc_phone_demo.pyfrom fastrtc import ReplyOnPause, Stream, get_stt_model, get_tts_modelimport gradiofrom gradio_client import Clientimport osfrom gradio.networking import setup_tunnel as original_setup_tunnelimport socket# Monkey patch setup_tunnel para que acepte el parámetro adicionaldef patched_setup_tunnel(host, port, share_token, share_server_address, share_server_tls_certificate=None):return original_setup_tunnel(host, port, share_token, share_server_address, share_server_tls_certificate)# Replace the original function with our patched versiongradio.networking.setup_tunnel = patched_setup_tunnel# Get the token from the environment variableHUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN = os.getenv("HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN")# Initialize the LLM clientllm_client = Client("Maximofn/SmolLM2_localModel")# Initialize the STT and TTS modelsstt_model = get_stt_model()tts_model = get_tts_model()# Define the echo functiondef echo(audio):# Convert the audio to textprompt = stt_model.stt(audio)# Generate the responseresponse = llm_client.predict(message=prompt,system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you.",max_tokens=512,temperature=0.7,top_p=0.95,api_name="/chat")# Convert the response to audioprompt = response# Stream the audiofor audio_chunk in tts_model.stream_tts_sync(prompt):yield audio_chunkdef find_free_port(start_port=8000, max_port=9000):"""Find the first free port starting from start_port."""print(f"Searching for a free port starting from {start_port}...")for port in range(start_port, max_port):with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:result = sock.connect_ex(('127.0.0.1', port))if result != 0: # If result != 0, the port is freeprint(f"Free port found: {port}")return portraise RuntimeError(f"No free port found between {start_port} and {max_port}")free_port = find_free_port() # Search for a free portstream = Stream(ReplyOnPause(echo), modality="audio", mode="send-receive")stream.fastphone(token=HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN, port=free_port)Copied
We explain the code
The part
# Monkey patch `setup_tunnel` to accept the additional parameter
def patched_setup_tunnel(host, port, share_token, share_server_address, share_server_tls_certificate=None):
return original_setup_tunnel(host, port, share_token, share_server_address, share_server_tls_certificate)
# Replace the original function with our patched version
gradio.networking.setup_tunnel = patched_setup_tunnelIt is necessary because FastRTC is written for an older version of gradio that does not support the share_server_address parameter in the setup_tunnel method. So we patch it to accept the additional parameter.
As a Hugging Face token is required, we obtain it from the environment variable HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN.
# Get the token from the environment variable
HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN = os.getenv("HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN")The language models, the speech-to-text model, and the text-to-speech model are created below, along with the echo function that will handle the input and output audio.
# Initialize the LLM client
llm_client = Client("Maximofn/SmolLM2_localModel")
# Initialize the STT and TTS models
stt_model = get_stt_model()
tts_model = get_tts_model()
# Define the echo function
def echo(audio):
# Convert the audio to text
prompt = stt_model.stt(audio)
# Generate the response
response = llm_client.predict(
message=prompt,
system_message="You are a friendly Chatbot. Always reply in the language in which the user is writing to you."
max_tokens=512,
temperature=0.7,
top_p=0.95,
api_name="/chat"
)
# Convert the response to audio
prompt = response
# Stream the audio
for audio_chunk in tts_model.stream_tts_sync(prompt):
yield audio_chunkAs we have used port 8000 before, in case it tells you that it is occupied, we create a function to find a free port and find one.
def find_free_port(start_port=8000, max_port=9000):
"""Find the first free port starting from start_port."""
print(f"Searching for a free port starting from {start_port}...")
for port in range(start_port, max_port):
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:
result = sock.connect_ex(('127.0.0.1', port))
if result != 0: # If result != 0, the port is free
print(f"Free port found: {port}")
return port
raise RuntimeError(f"No free port found between {start_port} and {max_port}")
free_port = find_free_port() # Search for a free portThe stream is created and now stream.fastphone() is used to get a free phone number to call your stream, instead of stream.ui.launch() which we used before to create the graphical interface.
stream = Stream(ReplyOnPause(echo), modality="audio", mode="send-receive")
stream.fastphone(token=HUGGINGFACE_FASTRTC_PHONE_CALL_TOKEN, port=free_port)If we run it, we will see something like this:
!python fastrtc_phone_demo.pyCopied
Loaded as API: https://maximofn-smollm2-localmodel.hf.space ✔INFO: Warming up STT model.INFO: STT model warmed up.INFO: Warming up VAD model.INFO: VAD model warmed up.Searching for a free port starting from 8000...Free port found: 8004INFO: Started server process [24029]INFO: Waiting for application startup.INFO: Visit https://fastrtc.org/userguide/api/ for WebRTC or Websocket API docs.INFO: Application startup complete.INFO: Uvicorn running on http://127.0.0.1:8004 (Press CTRL+C to quit)INFO: Your FastPhone is now live! Call +1 877-713-4471 and use code 994514 to connect to your stream.INFO: You have 30:00 minutes remaining in your quota (Resetting on 2025-04-07)INFO: Visit https://fastrtc.org/userguide/audio/#telephone-integration for information on making your handler compatible with phone usage.
We see that it appears
INFO: Your FastPhone is now live! Call +1 877-713-4471 and use code 994514 to connect to your stream.
INFO: You have 30:00 minutes remaining in your quota (Resetting on 2025-04-07)That is, if we call the number +1 877-713-4471 and use the code 994514, it will connect us to our stream.
If we go to Telephone Integration in the FastRTC documentation, we will see that it uses twilio to make the call. It has an option to configure a local number from the United States, Dublin, Frankfurt, Tokyo, Singapore, Sydney, and São Paulo.
I tried making the call from Spain (which is going to be quite expensive for me) and it works, but it's slow. I called, entered the code, and waited for the agent to connect, but since it was taking too long, I hung up.

















