
Disclaimer: This post has been translated to English using a machine translation model. Please, let me know if you find any mistakes.
Paper
Improving Language Understanding by Generative Pre-Training is the GPT1 paper. Before reading the post, it's necessary to set the context: before GPT, language models were based on recurrent neural networks (RNNs), which worked relatively well for specific tasks but could not reuse pre-training for fine-tuning for other tasks. Additionally, they had limited memory, so if very long sentences were input, they wouldn't remember the beginning of the sentence very well.
Architecture
Before discussing the architecture of GPT-1, let's recall how the architecture of transformers worked.
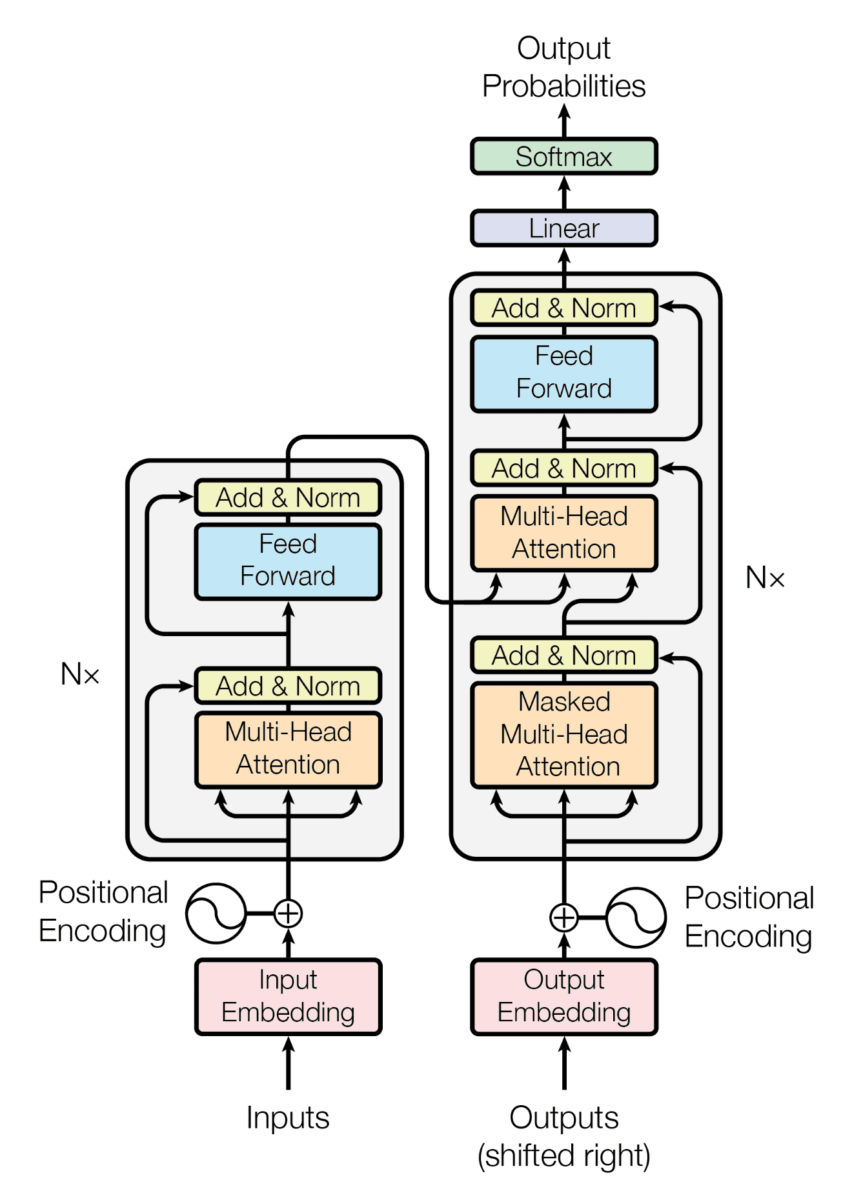
GPT1 is a model based on the decoders of transformers, so since we don't have an encoder, the architecture with a single decoder looks like this:
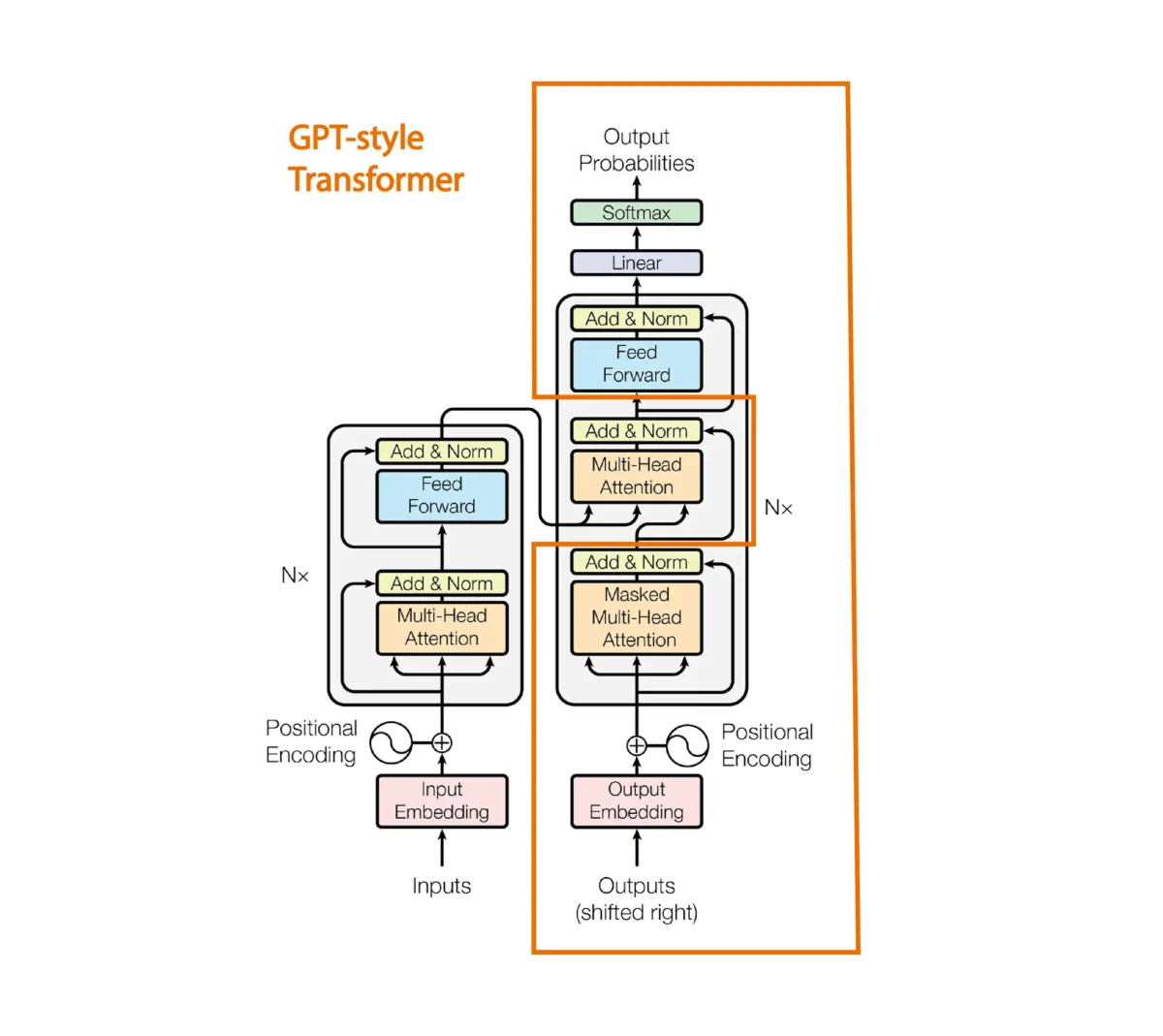
The attention mechanism between the encoder and decoder sentence is removed.
In the GPT-1 paper, they propose the following architecture
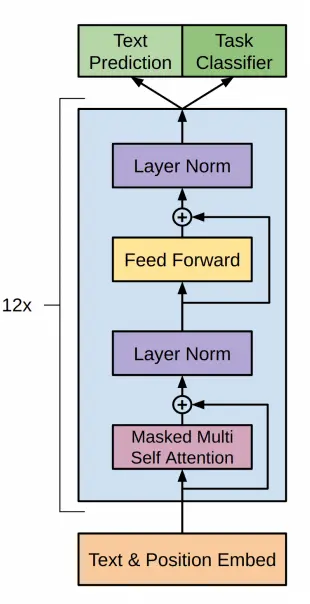
This corresponds to the decoder of a transformer as we have seen before, executed 12 times
Summary of the paper
The most interesting ideas from the paper are:
- The model is trained on a large corpus of text without supervision. This results in the creation of a language model. A high-capacity language model is created from a large corpus of text.
- Then fine-tuning is performed on supervised NLP tasks with labeled datasets. A fine adjustment is made in the target task with supervision. Additionally, when evaluating the model on the supervised task, it is not only evaluated for that task, but also for how well it predicts the next token, which helps improve the generalization of the supervised model and makes the model converge faster.
- Although we have already mentioned it, the paper states that the transformer architecture is used, as RNNs were being used for language models up until that point. This led to an improvement in which what was learned during the first training (unsupervised training on the text corpus) is easier to transfer to supervised tasks. In other words, thanks to the use of transformers, it became possible to train on an entire text corpus and then perform fine-tunings on supervised tasks.
- They evaluated the model on four types of language understanding tasks:
- Natural language inference* Answers to questions
- Semantic similarity
- Text classification.
- The general model (the one trained on the entire text corpus without supervision) outperforms discriminatively trained RNN models that use architectures specifically designed for each task, significantly improving the state of the art in 9 out of the 12 tasks studied. They also analyze the "zero-shot" behaviors of the pre-trained model in four different environments and demonstrated that it acquires useful linguistic knowledge for subsequent tasks.
- In recent years, researchers had demonstrated the benefits of using embeddings, which are trained on unlabeled corpora, to improve performance across a variety of tasks. However, these approaches primarily transfer information at the word level, while the use of transformers trained on large unsupervised text corpora captures higher-level semantics at the phrase level.
Text Generation
Let's see how to generate text with a pretrained GPT1
First, you need to install ftfy and spacy via
pip install ftfy spacyOnce installed, you should download the language model of spacy that you want to use. For example, to download the English model, you can run:
python -m spacy download en_core_web_smTo generate text, we are going to use the model from the GPT1 repository of Hugging Face.
We import the libraries
import torchfrom transformers import OpenAIGPTTokenizer, OpenAIGPTLMHeadModel, AutoTokenizerCopied
If you notice, we have imported OpenAIGPTTokenizer and AutoTokenizer. This is because in the model card of GPT1 it is indicated that OpenAIGPTTokenizer should be used, but in the library's transformers post we explain that AutoTokenizer should be used to load the tokenizer. So, let's try both.
ckeckpoints = "openai-community/openai-gpt"tokenizer = OpenAIGPTTokenizer.from_pretrained(ckeckpoints)auto_tokenizer = AutoTokenizer.from_pretrained(ckeckpoints)input_tokens = tokenizer("Hello, my dog is cute and", return_tensors="pt")input_auto_tokens = auto_tokenizer("Hello, my dog is cute and", return_tensors="pt")print(f"input tokens: {input_tokens}")print(f"input auto tokens: {input_auto_tokens}")Copied
input tokens:{'input_ids': tensor([[3570, 240, 547, 2585, 544, 4957, 488]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}input auto tokens:{'input_ids': tensor([[3570, 240, 547, 2585, 544, 4957, 488]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}
As can be seen with the two tokenizers, the same tokens are obtained. So, to make the code more general, so that if the checkpoints change, there is no need to change the code, we will use AutoTokenizer
We then create the device, the tokenizer, and the model.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")tokenizer = AutoTokenizer.from_pretrained(ckeckpoints)model = OpenAIGPTLMHeadModel.from_pretrained(ckeckpoints).to(device)Copied
Now that we have instantiated the model, let's see how many parameters it has.
params = sum(p.numel() for p in model.parameters())print(f"Number of parameters: {round(params/1e6)}M")Copied
Number of parameters: 117M
In the era of trillions of parameters, we can see that GPT1 only had 117 million parameters.
We create the input tokens for the model
input_sentence = "Hello, my dog is cute and"input_tokens = tokenizer(input_sentence, return_tensors="pt").to(device)input_tokensCopied
{'input_ids': tensor([[3570, 240, 547, 2585, 544, 4957, 488]], device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]], device='cuda:0')}
We pass them to the model to generate the output tokens
output_tokens = model.generate(**input_tokens)print(f"output tokens: {output_tokens}")Copied
output tokens:tensor([[ 3570, 240, 547, 2585, 544, 4957, 488, 249, 719, 797,485, 921, 575, 562, 246, 1671, 239, 244, 40477, 244]],device='cuda:0')
/home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/generation/utils.py:1178: UserWarning: Using the model-agnostic default `max_length` (=20) to control the generation length. We recommend setting `max_new_tokens` to control the maximum length of the generation.warnings.warn(
We decode the tokens to obtain the output sentence
decoded_output = tokenizer.decode(output_tokens[0], skip_special_tokens=True)print(f"decoded output: {decoded_output}")Copied
decoded output:hello, my dog is cute and i'm going to take him for a walk. ""
We have already managed to generate text with GPT1
Generate text token by token
Greedy search
We have used model.generate to generate the output tokens all at once, but we are going to see how to generate them one by one. For this, instead of using model.generate, we will use model, which actually calls the model.forward method.
outputs = model(**input_tokens)outputsCopied
CausalLMOutput(loss=None, logits=tensor([[[ -5.9486, -5.8697, -18.4258, ..., -9.7371, -10.4495, 0.8814],[ -6.1212, -4.8031, -14.3970, ..., -6.5411, -9.5051, -1.2015],[ -7.4231, -6.3615, -14.7297, ..., -10.4575, -8.4600, -1.5183],...,[ -5.4751, -5.8803, -13.7767, ..., -10.5048, -12.4167, -6.1584],[ -7.2052, -6.0198, -21.5040, ..., -16.2941, -14.0494, -1.2416],[ -7.7240, -7.3631, -17.3174, ..., -12.1546, -12.3327, -1.7169]]],device='cuda:0', grad_fn=<UnsafeViewBackward0>), hidden_states=None, attentions=None)
We see that it outputs many data points, first let's look at the keys of the output
outputs.keys()Copied
odict_keys(['logits'])
In this case we only have the logits of the model, let's check their size
logits = outputs.logitslogits.shapeCopied
torch.Size([1, 7, 40478])
Let's see how many tokens we had at the input
input_tokens.input_ids.shapeCopied
torch.Size([1, 7])
Well, at the output we have the same number of logits as at the input. This is normal.
We obtain the logits from the last position of the output
nex_token_logits = logits[0,-1]nex_token_logits.shapeCopied
torch.Size([40478])
There is a total of 40478 logits, meaning there is a vocabulary of 40478 tokens and we need to determine which token has the highest probability. To do this, we first calculate the softmax.
softmax_logits = torch.softmax(nex_token_logits, dim=0)softmax_logits.shapeCopied
torch.Size([40478])
next_token_prob, next_token_id = torch.max(softmax_logits, dim=0)next_token_prob, next_token_idCopied
(tensor(0.1898, device='cuda:0', grad_fn=<MaxBackward0>),tensor(249, device='cuda:0'))
We have obtained the following token, now we decode it
tokenizer.decode(next_token_id.item())Copied
'i'
We obtained the following token using the greedy method, that is, the token with the highest probability. But we already saw in the post about the transformers library, the ways to generate text such as sampling, top-k, top-p, etc.
Let's put everything into a function and see what comes out if we generate a few tokens
def generate_next_greedy_token(input_sentence, tokenizer, model, device):input_tokens = tokenizer(input_sentence, return_tensors="pt").to(device)outputs = model(**input_tokens)logits = outputs.logitsnex_token_logits = logits[0,-1]softmax_logits = torch.softmax(nex_token_logits, dim=0)next_token_prob, next_token_id = torch.max(softmax_logits, dim=0)return next_token_prob, next_token_idCopied
def generate_greedy_text(input_sentence, tokenizer, model, device, max_length=20):generated_text = input_sentencefor _ in range(max_length):next_token_prob, next_token_id = generate_next_greedy_token(generated_text, tokenizer, model, device)generated_text += tokenizer.decode(next_token_id.item())return generated_textCopied
Now we generate text
generate_greedy_text("Hello, my dog is cute and", tokenizer, model, device)Copied
'Hello, my dog is cute andi." '
The output is quite repetitive, as was already seen in the ways of generating texts
Fine tuning GPT
Calculation of the Loss
Before starting to fine-tune GPT1, let's look at something. Previously, when we obtained the model's output, we did this
outputs = model(**input_tokens)outputsCopied
CausalLMOutput(loss=None, logits=tensor([[[ -5.9486, -5.8697, -18.4258, ..., -9.7371, -10.4495, 0.8814],[ -6.1212, -4.8031, -14.3970, ..., -6.5411, -9.5051, -1.2015],[ -7.4231, -6.3615, -14.7297, ..., -10.4575, -8.4600, -1.5183],...,[ -5.4751, -5.8803, -13.7767, ..., -10.5048, -12.4167, -6.1584],[ -7.2052, -6.0198, -21.5040, ..., -16.2941, -14.0494, -1.2416],[ -7.7240, -7.3631, -17.3174, ..., -12.1546, -12.3327, -1.7169]]],device='cuda:0', grad_fn=<UnsafeViewBackward0>), hidden_states=None, attentions=None)
It can be seen that we get loss=None
print(outputs.loss)Copied
None
Since we will need the loss to perform fine-tuning, let's see how to obtain it.
If we go to the documentation of the forward method of OpenAIGPTLMHeadModel, we can see that it states that the output is an object of type transformers.modeling_outputs.CausalLMOutput. So, if we go to the documentation of transformers.modeling_outputs.CausalLMOutput, we can see that it states that it returns loss if labels are passed to the forward method.
If we go to the source code of the forward method, we see this block of code
loss = None
if labels is not None:
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))That is, the loss is calculated as follows
- Logits and labels shift: The first part is to shift the logits (
lm_logits) and the labels (labels) so that thetokens < npredictn, meaning from positionnit predicts the next token based on the previous ones. - CrossEntropyLoss: An instance of the loss function
CrossEntropyLoss()is created. - Flatten tokens: Next, the logits and labels are flattened using
view(-1, shift_logits.size(-1))andview(-1), respectively. This is done to ensure that the logits and labels have the same shape for the loss function. - Calculation of the loss: Finally, the loss is calculated using the
CrossEntropyLoss()function with the flattened logits and flattened labels as inputs.
In summary, the loss is calculated as the cross-entropy loss between the shifted and flattened logits and the shifted and flattened labels.
Therefore, if we pass the labels to the forward method, it will return the loss.
outputs = model(**input_tokens, labels=input_tokens.input_ids)outputs.lossCopied
tensor(4.2607, device='cuda:0', grad_fn=<NllLossBackward0>)
Dataset
For the training, we are going to use an English jokes dataset short-jokes-dataset, which is a dataset with 231 thousand English jokes.
We download the dataset
from datasets import load_datasetjokes = load_dataset("Maximofn/short-jokes-dataset")jokesCopied
DatasetDict({train: Dataset({features: ['ID', 'Joke'],num_rows: 231657})})
Let's take a look at it.
jokes["train"][0]Copied
{'ID': 1,'Joke': '[me narrating a documentary about narrators] "I can't hear what they're saying cuz I'm talking"'}
Training with Pytorch
First let's see how the training would be done with pure Pytorch
We restart the notebook to avoid issues with GPU memory.
import torchfrom transformers import OpenAIGPTLMHeadModel, AutoTokenizerdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")ckeckpoints = "openai-community/openai-gpt"tokenizer = AutoTokenizer.from_pretrained(ckeckpoints)model = OpenAIGPTLMHeadModel.from_pretrained(ckeckpoints)model = model.to(device)Copied
Pytorch dataset
We create a Dataset class in Pytorch
from torch.utils.data import Datasetclass JokesDataset(Dataset):def __init__(self, dataset, tokenizer):self.dataset = datasetself.joke = "JOKE: "self.end_of_text_token = "<|endoftext|>"self.tokenizer = tokenizerdef __len__(self):return len(self.dataset["train"])def __getitem__(self, item):sentence = self.joke + self.dataset["train"][item]["Joke"] + self.end_of_text_tokentokens = self.tokenizer(sentence, return_tensors="pt")return sentence, tokensCopied
We instantiate it
dataset = JokesDataset(jokes, tokenizer=tokenizer)Copied
We see an example
sentence, tokens = dataset[5]print(sentence)tokens.input_ids.shape, tokens.attention_mask.shapeCopied
JOKE: Why can't Barbie get pregnant? Because Ken comes in a different box. Heyooooooo<|endoftext|>
(torch.Size([1, 30]), torch.Size([1, 30]))
Dataloader
We now create a Pytorch dataloader
from torch.utils.data import DataLoaderBS = 1joke_dataloader = DataLoader(dataset, batch_size=BS, shuffle=True)Copied
We see a batch
sentences, tokens = next(iter(joke_dataloader))len(sentences), tokens.input_ids.shape, tokens.attention_mask.shapeCopied
(1, torch.Size([1, 1, 29]), torch.Size([1, 1, 29]))
Training
from transformers import AdamW, get_linear_schedule_with_warmupimport tqdmBATCH_SIZE = 32EPOCHS = 5LEARNING_RATE = 3e-5WARMUP_STEPS = 5000MAX_SEQ_LEN = 500model.train()optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=WARMUP_STEPS, num_training_steps=-1)proc_seq_count = 0batch_count = 0tmp_jokes_tens = Nonefor epoch in range(EPOCHS):print(f"EPOCH {epoch} started" + '=' * 30)progress_bar = tqdm.tqdm(joke_dataloader, desc="Training")for sample in progress_bar:sentence, tokens = sample#################### "Fit as many joke sequences into MAX_SEQ_LEN sequence as possible" logic start ####joke_tens = tokens.input_ids[0].to(device)# Skip sample from dataset if it is longer than MAX_SEQ_LENif joke_tens.size()[1] > MAX_SEQ_LEN:continue# The first joke sequence in the sequenceif not torch.is_tensor(tmp_jokes_tens):tmp_jokes_tens = joke_tenscontinueelse:# The next joke does not fit in so we process the sequence and leave the last joke# as the start for next sequenceif tmp_jokes_tens.size()[1] + joke_tens.size()[1] > MAX_SEQ_LEN:work_jokes_tens = tmp_jokes_tenstmp_jokes_tens = joke_tenselse:#Add the joke to sequence, continue and try to add moretmp_jokes_tens = torch.cat([tmp_jokes_tens, joke_tens[:,1:]], dim=1)continue################## Sequence ready, process it trough the model ##################outputs = model(work_jokes_tens, labels=work_jokes_tens)loss = outputs.lossloss.backward()proc_seq_count = proc_seq_count + 1if proc_seq_count == BATCH_SIZE:proc_seq_count = 0batch_count += 1optimizer.step()scheduler.step()optimizer.zero_grad()model.zero_grad()progress_bar.set_postfix({'loss': loss.item(), 'lr': scheduler.get_last_lr()[0]})if batch_count == 10:batch_count = 0Copied
/home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/optimization.py:429: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warningwarnings.warn(
EPOCH 0 started==============================
Training: 100%|██████████| 231657/231657 [11:31<00:00, 334.88it/s, loss=2.88, lr=2.93e-6]
EPOCH 1 started==============================
Training: 100%|██████████| 231657/231657 [11:30<00:00, 335.27it/s, loss=2.49, lr=5.87e-6]
EPOCH 2 started==============================
Training: 100%|██████████| 231657/231657 [11:17<00:00, 341.75it/s, loss=2.57, lr=8.81e-6]
EPOCH 3 started==============================
Training: 100%|██████████| 231657/231657 [11:18<00:00, 341.27it/s, loss=2.41, lr=1.18e-5]
EPOCH 4 started==============================
Training: 100%|██████████| 231657/231657 [11:19<00:00, 341.04it/s, loss=2.49, lr=1.47e-5]
Inference
Let's see how well the model tells jokes
sentence_joke = "JOKE:"input_tokens_joke = tokenizer(sentence_joke, return_tensors="pt").to(device)output_tokens_joke = model.generate(**input_tokens_joke)decoded_output_joke = tokenizer.decode(output_tokens_joke[0], skip_special_tokens=True)print(f"decoded joke: {decoded_output_joke}")Copied
decoded joke:joke : what do you call a group of people who are not afraid of the dark? a group
You can see that you pass it a sequence with the word joke and it returns a joke. But if you return another sequence, it does not.
sentence_joke = "My dog is cute and"input_tokens_joke = tokenizer(sentence_joke, return_tensors="pt").to(device)output_tokens_joke = model.generate(**input_tokens_joke)decoded_output_joke = tokenizer.decode(output_tokens_joke[0], skip_special_tokens=True)print(f"decoded joke: {decoded_output_joke}")Copied
decoded joke:my dog is cute and i'm not sure if i should be offended or not. "
















